Chapter 6 The Seeing Brain
Overview
- 연구 배경: 시각 인식은 단순한 뇌의 해석이 아닌, 뇌가 환경 정보를 기반으로 주체적으로 구축하는 과정임을 밝혀야 함
- 핵심 방법론:
- 망막에서 시각 정보가 뇌로 전달되는 경로(예: geniculostriate pathway)와 시각 피질(V1)의 계층적 처리 구조 분석
- 뇌 손상 환자(예: cortical blindness, blindsight)를 통한 시각 인식의 생성적 성격 탐구
- 주요 기여:
- 시각 피질의 계층적 처리(예: simple cell → complex cell → hypercomplex cell)와 시각 정보의 구성 방식을 명확히 규명
- 뇌의 다중 경로(예: LGN→V1, superior colliculus 경로)가 시각 인식에 기여하는 방식을 제시
- 실험 결과:
- cortical blindness 환자의 blindsight 현상에서 V1 손상에도 불구하고 움직임 인식 가능, 이는 V5/MT 영역과의 연결 경로 존재를 시사
- Kanizsa 환상에서 V2 영역의 활성화로 시각적 추론의 생성적 특성 증명
- 한계점: 동물 모델 중심 연구로 인간 시각 시스템의 전체적 이해는 제한적이고, 정량적 데이터 부족
📋 목차
대단원 구조
- From Eye to Brain — 눈에서 뇌로: 망막에서 V1까지의 시각 경로
- 1.1 Sensation — 감각의 정의
- 1.2 The primary visual cortex and geniculostriate pathway — V1과 geniculostriate 경로
- 1.3 Cortical and non-cortical routes to seeing — 피질 및 비피질 시각 경로
- Cortical Blindness and “Blindsight” — 피질 실명과 맹시: V1 손상과 무의식적 시각
- 2.1 Blindsight — 맹시 현상
- Functional Specialization of the Visual Cortex Beyond V1 — V1 너머 시각 피질: 색상(V4)과 움직임(V5/MT)
- 3.1 V4: The main color center of the brain — 뇌의 색상 중심지 V4
- 3.2 V5/MT: The main movement center of the brain — 뇌의 움직임 중심지 V5/MT
- Recognizing Objects — 물체 인식: 시각 실인증과 범주 특이성
- 4.1 Case HJA: seeing the parts but not the whole — 부분은 보이나 전체는 못 보는 HJA
- 4.2 Accessing structural descriptions: object constancy — 구조적 설명과 물체 항상성
- 4.3 Category specificity in visual object recognition? — 시각 물체 인식의 범주 특이성
- Recognizing Faces — 얼굴 인식: FFA와 얼굴 특수성
- 5.1 Models of face processing — 얼굴 처리 모델
- 5.2 Evidence that faces are special — 얼굴이 특별하다는 증거
- 5.3 Why are faces special? — 얼굴이 특별한 이유
- Vision Imagined — 시각적 심상: 인식과 상상의 신경 기전
Summary
시각은 눈이 아닌 뇌가 주도적으로 구축하는 과정이다. 뇌는 망막의 2차원 빛 패턴을 3차원 환경 모델로 변환하며, Kanizsa 착시처럼 존재하지 않는 형태도 추론해 인식한다. 본 장에서는 감각(sensation)과 지각(perception)의 구분을 기반으로, 색상/움직임 인식에서 물체/얼굴 인식까지 시각 뇌의 구성적 특성을 탐구한다.
Students who are new to cognitive neuroscience might believe that the eyes do the seeing and the brain merely interprets the image on the retina. is is far from the truth. Although the eyes play an undeniably crucial role in vision, the brain is involved in actively constructing a visual representation of the world that is not a literal reproduction of the paern of light falling on the eyes. For example, the brain divides a continuous paern of light into discrete objects and surfaces, and translates the two-dimensional retinal image into a three-dimensional interactive model of the environment. In fact, the brain is biased to perceive objects when there is not necessarily an
object there. Consider the Kanizsa illusion (p. 108) —it is quite hard to perceive the stimulus as three corners as opposed to one triangle. e brain makes inferences during visual perception that go beyond the raw information given. Psyologists make a distinction between sensation and perception. Sensation refers to the effects of a stimulus on the sensory organs, whereas perception involves the elaboration and interpretation of that sensory stimulus based on, for example, knowledge of how objects are structured. is apter will consider many examples of the constructive nature of the seeing brain, from the perception of visual aributes, su as color and motion, up to the recognition of objects and faces.
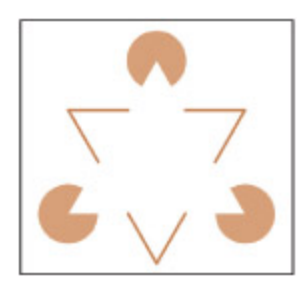
Do you automatically perceive a white triangle that isn’t really there? is is called the Kanizsa illusion.
📊 그림 설명
Kanizsa 착시를 보여주는 그림이다. 세 개의 팩맨 모양(꼭짓점)만 존재하지만, 뇌는 자동적으로 흰색 삼각형을 지각한다. 이는 시각 인식이 망막 정보를 그대로 전달하는 것이 아니라 뇌가 능동적으로 구성하는 과정임을 보여주는 대표적 사례이다.
From Eye to Brain
Summary
망막에서 시각 정보는 rod cells(야간)과 cone cells(주간/색상)에 의해 신경 신호로 변환된다. 망막 신경절 세포의 center-surround receptive field 구조가 엣지 감지의 기초를 형성하며, 이 정보는 시신경을 통해 LGN을 거쳐 **주시각 피질(V1)**로 전달된다(geniculostriate pathway). V1에서는 simple cells, complex cells, hypercomplex cells의 계층적 구조를 통해 점차 복잡한 시각 특징이 추출된다.
Key Terms
Sensation
The effects of a stimulus on the sensory organs.
Sensation(감각)은 외부 자극이 감각 기관에 미치는 직접적 영향을 의미한다.
Perception
The elaboration and interpretation of a sensory stimulus based on, for example, knowledge of how objects are structured.
Perception(지각)은 감각 자극을 물체 구조에 대한 사전 지식을 활용하여 해석하고 구조화하는 과정이다.
Retina
The internal surface of the eyes that consists of multiple layers containing photoreceptors that convert light to neural signals.
망막(retina)은 눈 내부 표면의 다층 구조로, 광수용체(photoreceptors)가 빛을 신경 신호로 변환하는 시각 정보 처리의 첫 번째 단계이다.
Rod cells
A type of photoreceptor specialized for low levels of light intensity, such as those found at night.
Rod cells는 야간 등 저강도 빛 환경에 특화된 광수용체이다.
Cone cells
A type of photoreceptor specialized for high levels of light intensity and detection of different wavelengths.
Cone cells는 고강도 빛(주간) 환경에 특화된 광수용체로, 다양한 파장의 빛을 감지하여 색상 인식에 핵심적으로 기여한다.
Receptive field
The region of space that elicits a response from a given neuron.
Receptive field(수용장)는 특정 뉴런이 반응하는 공간적 영역을 의미한다.
Blind spot
The point at which the optic nerve leaves the eye. There are no rods and cones present there.
Blind spot는 시신경이 눈을 빠져나가는 지점으로, rod cells과 cone cells이 없어 빛을 감지하지 못한다.
Primary visual cortex (or V1)
The first stage of visual processing in the cortex; the region retains the spatial relationships found on the retina and combines simple visual features into more complex ones.
**Primary visual cortex(V1)**는 대뇌 피질에서 시각 처리의 첫 번째 단계로, 망막의 공간적 관계를 보존(retinotopic organization)하면서 단순한 시각 특징을 결합하여 더 복잡한 정보로 변환한다.
Sensation
Summary
Sensation(감각)은 외부 자극이 감각 기관에 미치는 직접적 영향을 의미한다. 감각 기관은 빛, 소리 등 자극을 신경 신호로 변환하여 중추 신경계로 전달하며, 이는 뇌의 시각 정보 해석을 위한 기초 단계이다.
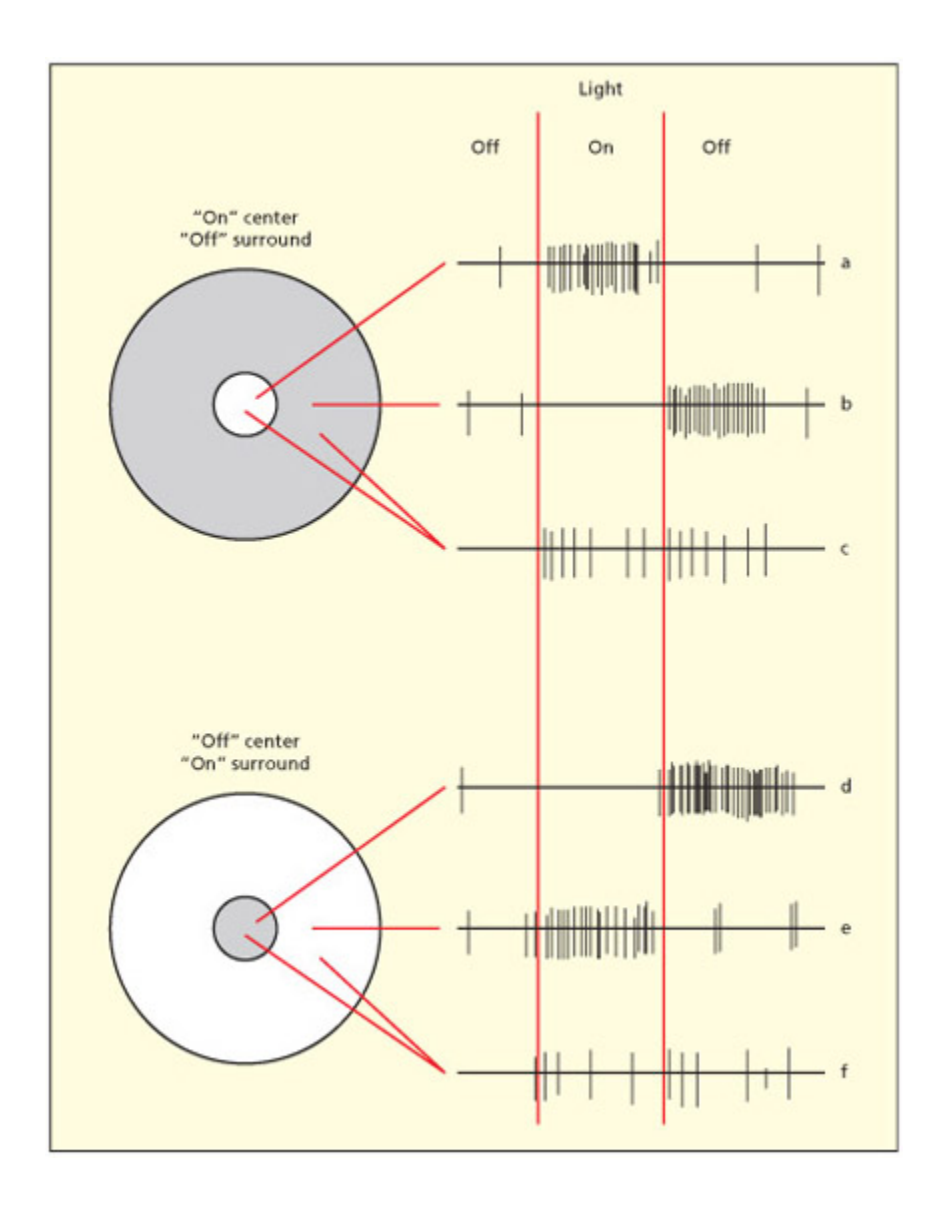
Receptive fields of two retinal ganglion cells. e cell in the upper part of the figure responds when the center is illuminated (on-center, a) and when the surround is darkened (off-surround, b). e cell in the lower part of the figure responds when the center is darkened (off-center, d) and when the surround is illuminated (on-surround, e). Both cells give on- and off-responses when both center and surround are illuminated (c and f), but neither response is as strong as when only center or surround is illuminated.
From Hubel, 1963.
📊 그림 설명
망막 신경절 세포의 center-surround 수용장 구조를 보여준다. 상단 세포는 on-center/off-surround 유형으로 중심에 빛이 들어오면 흥분하고, 하단 세포는 off-center/on-surround 유형으로 반대 반응을 보인다. 이 구조는 균일한 조명보다 **명암 경계(엣지)**에 더 강하게 반응하여, 시각 체계의 엣지 감지 기초를 형성한다.
e retina is the internal surface of the eyes that contains specialized photoreceptors that convert (or transduce) light into neural signals. e photoreceptors are made up of rod cells, whi are specialized for low levels
of light intensity, su as those found at night, and cone cells, whi are more active during daytime and are specialized for detecting different wavelengths of light (from whi the brain can compute color).
Summary
망막의 bipolar cells는 ON/OFF 반응으로 빛/어둠을 감지하고, retinal ganglion cells는 center-surround receptive field를 통해 광도 차이에 반응하여 엣지 감지의 기초를 형성한다. fovea는 cone cells 밀도가 가장 높아 시각 해상도가 최대이며, 이 신호는 시신경을 통해 뇌로 전달된다.
ere is already a stage of neural computation that takes place at the retina itself. Bipolar cells in the retina are a type of neuron that behave in one of two ways: detecting light areas on dark bagrounds (ON) or detecting dark areas on light bagrounds (OFF). A higher level of processing, by retinal ganglion cells, has a more complex set of on and off properties. Most retinal ganglion neurons have a particular aracteristic response to light that is termed a center-surround receptive field. e term receptive field denotes the region of space that elicits a response from a given neuron. One intriguing feature of the receptive fields of these cells, and many others in the visual system, is that they do not respond to light as su (Barlow, 1953; Kuffler & Barlow, 1953). Rather, they respond to differences in light across their receptive field. Light falling in the center of the receptive field may excite the neuron, whereas light in the surrounding area may swit it off (but when the light is removed from this region, the cell is excited again). Other retinal ganglion cells have the opposite profile (on-center off-surround cells). Light over the entire receptive field may elicit no net effect because the center and surround inhibit ea other. ese center-surround cells form the building blos for more advanced processing by the brain, enabling detection of, among other things, edges and orientations.
e output of the retinal ganglion cells is relayed to the brain via the optic nerves. e point at whi the optic nerve leaves the eye is called the blind spot, because there are no rods and cones present there. If you open only one of your eyes (and keep it stationary), there is a spot in whi there is no visual information. Yet, one does not perceive a bla hole in one’s vision. is is another example of the brain filling in missing information. e highest concentration of cones is at a point called the fovea, and the level of detail that can be perceived (or visual acuity) is greatest at this point. Rods are more evenly distributed across the retina (but are not present at the fovea).
The primary visual cortex and geniculostriate pathway
Summary
Geniculostriate pathway는 망막에서 LGN을 거쳐 V1으로 이어지는 주요 시각 경로이다. LGN은 양쪽 눈의 정보를 6개 층으로 분리하며, parvocellular(P) 층은 세부/색상, magnocellular(M) 층은 움직임/넓은 영역에 특화되고, 그 사이의 konio(K) 층은 기능적 특이성이 적다. 우측 시야 정보는 양쪽 눈의 좌측 망막에서 좌측 LGN으로 전달되는 등 교차 구조를 가진다.
To find your blind spots, hold the image about 50 cm away. With your le eye open (right closed), look at the +. Slowly bring the image (or move your head) closer while looking at the + (do not move your eyes). At a certain distance, the dot will disappear from sight … this is when the dot falls on the blind spot of your retina. Reverse the process: Close your le eye and look at the dot with your right eye. Move the image slowly closer to you and the + should disappear.
ere are a number of different pathways from the retina to the brain (for a review, see Stoerig and Cowey, 1997). e dominant visual pathway in the human brain travels to the primary visual cortex at the ba, or posterior, of the brain, via a processing station called the lateral geniculate nucleus (LGN). e LGN is part of the thalamus whi has a more general role in processing sensory information; there is one LGN in ea hemisphere. e primary visual cortex is also referred to as V1, or as the striate cortex because it has a larger than usual stripe running through one layer that can be seen when stained and viewed under a microscope. is particular route is called the geniculostriate pathway.
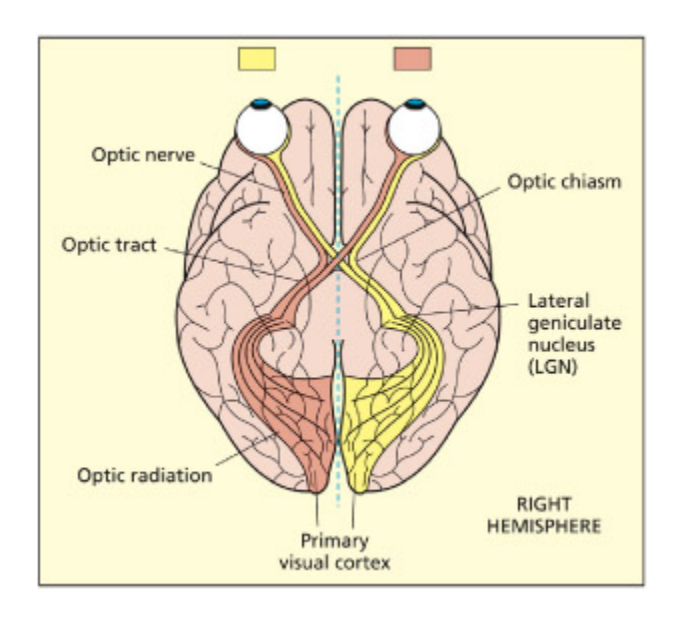
Connections from the retina to the primary visual cortex—the geniculostriate pathway. From Zeki, 1993. © Blawell Publishing. Reproduced with permission.
📊 그림 설명
망막에서 V1까지의 geniculostriate pathway를 도식화한 그림이다. 시각 정보는 망막에서 시신경을 통해 시신경 교차(optic chiasm)를 지나 **외측슬상핵(LGN)**으로 전달되고, 이후 **방사관(optic radiation)**을 거쳐 **주시각 피질(V1)**에 도달한다. 좌시야 정보는 우뇌로, 우시야 정보는 좌뇌로 교차 처리된다.
e neural representation in the lateral geniculate nucleus divides up information on the retinal surface in a number of interesting ways. Objects in the right side of space (termed the right visual field) fall on the le side of the retina of both eyes and project to the le lateral geniculate nucleus. e representation in the lateral geniculate nucleus thus contains information from both the le and right eyes. is information is segregated into the six different neuronal layers of this structure, three for ea eye. e layers of the lateral geniculate nucleus are not only divided according to the eye (le or right) but contain a further subdivision. e upper four layers have small cell bodies and have been termed parvocellular, or P layers, whereas the lower two layers contain larger cell bodies and have been termed magnocellular, or M layers. Parvocellular cells respond to detail and are concerned with color vision. Magnocellular cells are more sensitive to movement than color and respond to larger areas of visual field (Maunsell, 1987). More recently a third type of cell (K or konio) has been documented in the LGN that lies between the magnocellular (magno) and parvocellular (parvo) layers (Hendry & Reid, 2000). ese cells show mu less functional specificity than magno and parvo cells and have a different paern of connectivity.
Eye-Brain Myth 1
Summary
좌측 눈이 공간의 좌측만, 우측 눈이 우측만 담당한다는 것은 오해이다. 실제로 양쪽 눈의 좌측 망막은 모두 우측 공간의 물체를, 우측 망막은 모두 좌측 공간의 물체를 인식한다. 한 눈만 떠도 양측 공간을 모두 볼 수 있다.
Do not make the mistake of believing that the retina of the le eye represents just the le side of space, and the retina of the right eye represents just the right side of space. (If you are still confused, close one eye and keep it fixed—you should be able to see both sides of space with a minor occlusion due to the nose.) Rather, the le side of the le eye and the le side of the right eye both contain an image of objects on the right side of space. e right side of the le eye and the right
side of the right eye both contain an image of objects on the le side of space.
Eye-Brain Myth 2
Summary
시각 뉴런이 TV 픽셀처럼 작동한다는 것은 오해이다. 일부 뉴런은 빛이 제거될 때 반응하며, extrastriate 영역의 뉴런은 특정 색상이나 움직임 방향에만 반응하고 매우 넓은 수용장을 가진다. Hubel과 Wiesel은 V1 뉴런이 광도, 색상, 엣지, 움직임, 깊이 등 다양한 시각 정보를 인코딩함을 밝혀 1981년 노벨상을 수상했다.
If you think that the response of neurons on the retina or in the brain is like the response of pixels in a television screen, then think again. Some visual neurons respond when light is taken away, or when there is a change in light intensity across the region that they respond to. Other neurons in extrastriate areas respond only to certain colors, or movement in certain directions. ese neurons oen have very large receptive fields that do not represent a very precise pixel-like location at all.
e properties of neurons in the primary visual cortex were elucidated by pioneering work by David Hubel and Torsten Wiesel (1959, 1962, 1965, 1968, 1970a), for whi they were awarded the Nobel Prize in Medicine in 1981. e method they used was to record the response of single neurons in the visual cortex of cats and monkeys. Before going on to consider their work, it might be useful to take a step bawards and ask the broader question: “What kinds of visual information need to be coded by neurons?” First of all, neurons need to be able to represent how light or dark something is. In addition, neurons need to represent the color of an object to distinguish, say, between fruit and foliage of comparable lightness/darkness but complementary in color. Edges also need to be detected, and these might be defined as abrupt anges in brightness or color. ese edges might be useful for perceiving the shape of objects. Changes in brightness or color could also reflect movement of an object, and it is conceivable that some neurons may be specialized for extracting this type of visual information. Depth may also be perceived by comparing the two different retinal images.
Key Terms
Simple cells
In vision, cells that respond to light in a particular orientation.
Simple cells는 V1에서 특정 방향(orientation)의 빛 자극에만 반응하는 세포로, LGN의 center-surround 세포들의 조합으로 구성된다.
Complex cells
In vision, cells that respond to light in a particular orientation but do not respond to single points of light.
Complex cells는 특정 방향의 빛에 반응하지만 단일 점의 빛에는 반응하지 않으며, simple cells보다 더 넓은 수용장을 가진다.
Hypercomplex cells
In vision, cells that respond to particular orientations and particular lengths.
Hypercomplex cells는 특정 방향과 길이에 모두 민감한 세포로, complex cells에 억제성 수용장을 추가하여 구성된다.
e neurons in the primary visual cortex (V1) transform the information in the lateral geniculate nucleus into a basic code that enables all of these types of visual information to be extracted by later stages of processing. As with many great discoveries, there was an element of ance. Hubel and Wiesel noted that an oriented cra in a projector slide drove a single cell in V1 wild, i.e. it produced lots of action potentials (cited in Zeki, 1993). ey then systematically went on to show that many of these cells responded only to particular orientations. ese were termed simple cells. e responses of these simple cells could be construed as a combination of the responses of center-surround cells in the lateral geniculate nucleus (Hubel &
Wiesel, 1962). e cells also integrate information across both eyes and respond to similar input to either the le or right eye. Many orientationselective cells were found to be wavelength-sensitive too (Hubel & Wiesel, 1968), thus providing a primitive code from whi to derive color.
Just as center-surround cells might be the building blos of simple cells, Hubel and Wiesel (1962) speculated that simple cells themselves might be combined into what they termed complex cells. ese are orientationselective too, but can be distinguished from simple cells by their larger receptive fields and the fact that complex cells require stimulation across their entire length, whereas simple cells will respond to single points of light within the excitatory region. Outside of V1, another type of cell, termed hypercomplex cells, whi can be built from the responses of several complex cells, was observed (Hubel & Wiesel, 1965). ese cells were also orientation-sensitive, but the length was also critical. e receptive fields of hypercomplex cells may consist of adding excitatory complex cells, but with inhibitory complex cells located at either end to act as “stoppers.” In sum, the response properties of cells in V1 enable more complex visual information (e.g. edges) to be constructed out of more simple information.
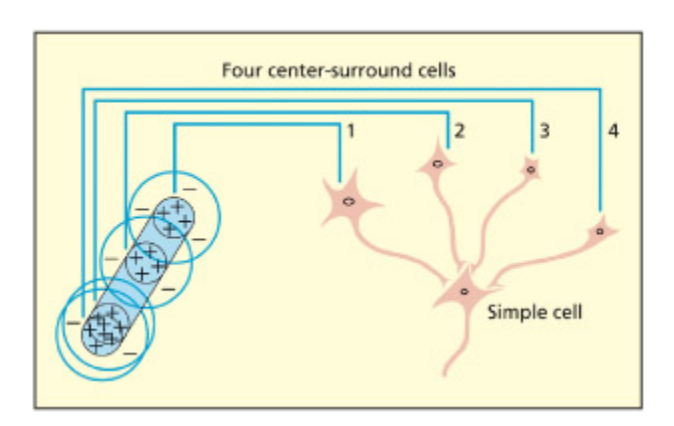
A simple cell in V1 responds to lines of particular length and orientation. Its response may be derived from a combination of responses from different cells with center-surround properties su as those located in the lateral geniculate nucleus.
📊 그림 설명
V1의 simple cell이 특정 방향과 길이의 선분에 반응하는 원리를 보여준다. LGN의 여러 center-surround 세포들이 일렬로 정렬된 수용장을 형성하고, 이들의 입력이 결합되어 simple cell이 특정 방향의 엣지에 선택적으로 반응하게 된다. 이는 Hubel & Wiesel의 계층적 시각 처리 모델의 핵심이다.
From Zeki, 1993. © Blawell Publishing. Reproduced with permission.
e take-home message of the work of Hubel and Wiesel is of a hierarically organized visual system in whi more complex visual features are built (boom-up) from more simple ones. However, this is only half of the story. Information from more complex representations also propagates down the hierary. For instance, in the Kanizsa illusion there are cells in V2 (but not V1) that respond to the illusory “white edges” of the triangle (Von der Heydt et al., 1984). is is assumed to reflect feedba information to V2 from regions in the brain that represent shapes and surfaces (Kogo & Wagemans, 2013).
시험 팁
V1의 세포 계층을 기억하는 법: “S-C-H” = Simple → Complex → Hypercomplex. 각 단계가 이전 단계의 조합으로 구성된다는 점이 핵심이다. Simple cell은 LGN의 center-surround 세포 조합, complex cell은 simple cell 조합, hypercomplex cell은 complex cell 조합이다. 시험에서 “계층적 처리(hierarchical processing)“를 묻는 문제에 자주 출제된다.
주의
Retinotopic organization과 receptive field를 혼동하지 말 것. Retinotopic organization은 V1 전체의 공간 배치 원리(망막 위치가 V1 위치에 대응)이고, receptive field는 개별 뉴런 하나가 반응하는 공간 영역이다. V1 손상 시 특정 시야가 실명되는 이유는 retinotopic organization 때문이다.
Cortical and non-cortical routes to seeing
Summary
망막에서 뇌로 이어지는 경로는 약 10개가 존재한다. LGN→V1 경로가 가장 중요하지만, superior colliculus 경유 경로는 V1보다 빠르게 자극에 반응하여 자동적 주의 전환을 가능하게 한다. 또한 LGN→K세포→V5/MT 경로는 V1을 우회하여 움직임 감지를 담당하며, 이는 cortical blindness 환자의 운동 감별 능력을 설명한다.
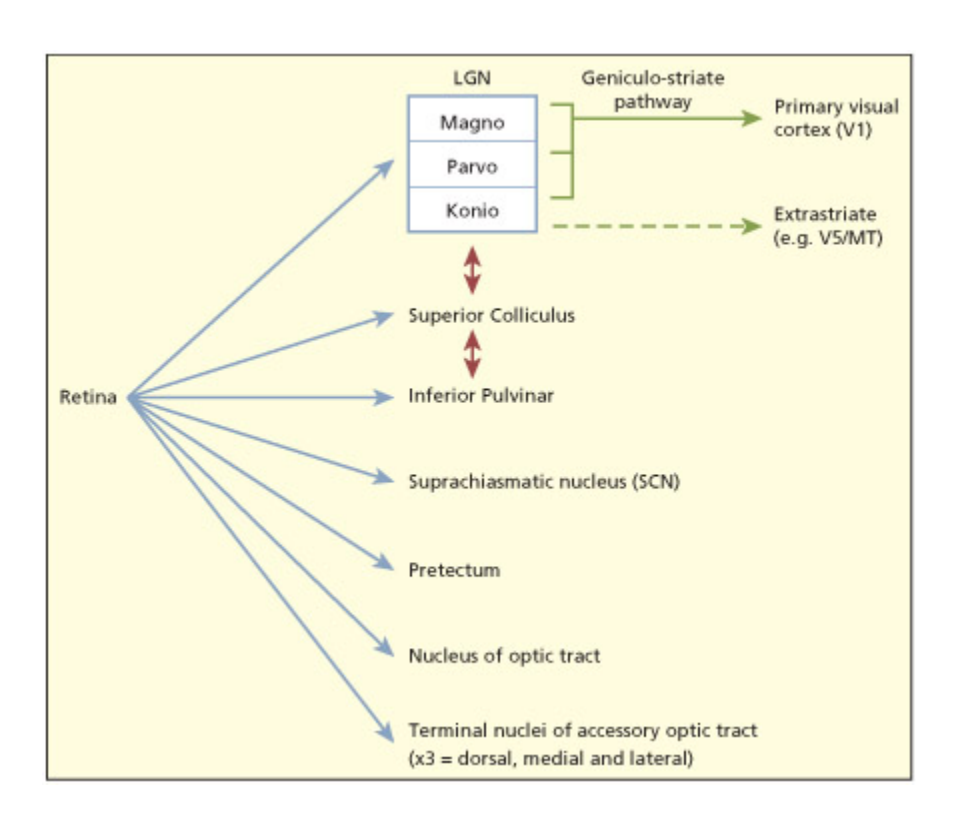
ere are believed to be ten different routes from the retina to different regions of the brain.
📊 그림 설명
망막에서 뇌의 여러 영역으로 연결되는 10가지 시각 경로를 도식화한 그림이다. Geniculostriate pathway(LGN→V1) 외에도 상구(superior colliculus), 시상하부, 전정핵 등 다양한 구조로 정보가 전달된다. 이는 시각이 V1만의 기능이 아니며, blindsight 등 V1 우회 경로의 존재를 설명하는 근거가 된다.
To date, around ten different pathways from the eye to the brain have been discovered, of whi the pathway via the lateral geniculate nucleus to V1 is the most well understood and appears to make the largest contribution to
human visual perception (Stoerig & Cowey, 1997). e other routes are evolutionarily more ancient. Evolution appears not to have replaced these routes with “beer” ones, but has retained them and added new routes that enable finer levels of processing or that serve somewhat different functions. For example, a visual route to the supraiasmatic nucleus (SCN) in the hypothalamus provides information about night and day that is used to configure a biological clo (Klein et al., 1991). Other routes, su as via the superior colliculus and inferior pulvinar, are important for orienting to stimuli (e.g. a sudden flash of light) by initiating automatic body and eye movements (Wurtz et al., 1982). ese laer routes are faster than the route via V1 and can thus provide an early warning signal; for instance, to threatening or unexpected stimuli. is can explain how it is possible to unconsciously turn to look at something but without realizing its importance until aer orienting. More recently, an alternative pathway from the LGN (via the K-cells) to the cortex has been documented that projects to a part of the brain that is specialized for process of visual motion (area V5/MT) without first projecting to V1 (Sinci et al., 2004). is may account for the fact that some patients with cortical blindness can still discriminate motion.
Eye-Brain Myth 3
Summary
망막과 V1의 이미지가 “뒤집혀 있다”는 것은 무의미한 질문이다. “올바른” 방향이란 존재하지 않으며, 뇌의 기능은 환경의 유의미한 정보를 추출하는 것이지 외부 세계의 정확한 복사본을 만드는 것이 아니다.
e image on the retina and the representation of it in V1 are “upside down” with respect to the outside world. As su, one might wonder how the brain turns it the right way up. is question is meaningless because it presupposes that the orientation of things in the outside world is in some way “correct” and the brain’s representation of it is in some way “incorrect.” ere is no “correct” orientation (all orientation is relative) and the brain does not need to turn things around to perceive them appropriately. e function of the seeing brain is to extract relevant information from the environment, not to create a
carbon copy that preserves, among other things, the same relative topto-boom orientation.
Evaluation
Summary
V1은 엣지 등 기본 시각 특징을 감지하여 장면을 물체로 분리하며, 계층적 구조로 단순한 뉴런 반응이 복잡한 반응의 기초가 된다. Geniculostriate 경로 외에도 병렬 경로가 존재하며, V1의 retinotopic organization 때문에 부분 손상 시 특정 시야 영역이 실명된다.
e primary visual cortex (V1) contains cells that enable a basic detection of visual features, su as edges, that are likely to be important for segregating the scene into different objects. ere is some evidence for a hierarical processing of visual features su that responses of earlier neurons in the hierary form the building blos for more advanced responses of neurons higher up in the hierary. A number of other routes operate in parallel to the geniculostriate route to V1. ese may be important for early detection of visual stimuli, among other things.
Partial damage to the primary visual cortex (V1) can result in blindness in specific regions. is is because this region of the brain is retinotopically organized. Area V1 is at the ba of the brain and on the middle surface between the two hemispheres.
📊 그림 설명
V1의 부분 손상이 시야의 특정 영역에 **실명(scotoma)**을 유발하는 원리를 보여준다. V1은 망막위상적으로 조직(retinotopically organized)되어 있어 V1의 특정 부위 손상은 대응하는 시야 영역의 시각 상실로 이어진다. V1은 뇌 후방의 두 반구 사이 내측면에 위치한다.
Adapted from Zeki, 1993.
임상 사례
Superior colliculus 경유 경로의 임상적 의미: 갑자기 날아오는 공을 의식적으로 인식하기 전에 자동으로 고개를 돌리는 반응은 V1보다 빠른 superior colliculus 경로 덕분이다. 이 경로는 진화적으로 더 오래된 “위험 회피 시스템”으로, V1이 손상되어도 이 반사적 반응이 보존될 수 있다.
Cortical Blindness and “Blindsight”
Summary
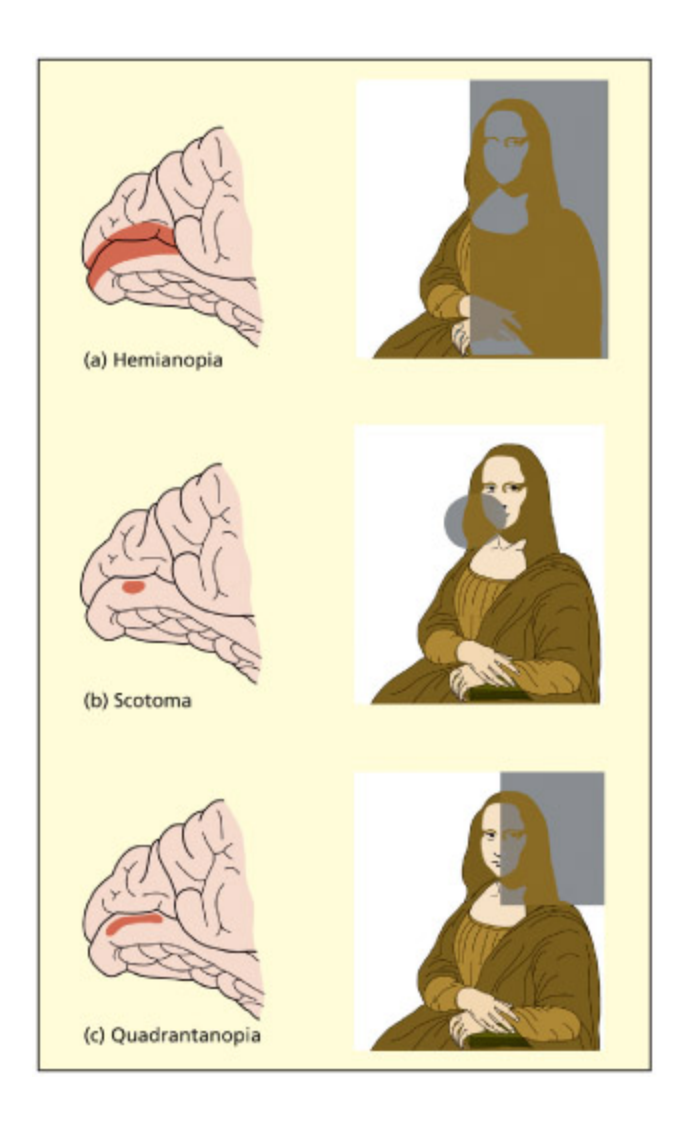
Cortical blindness는 V1 손상으로 인한 시각 상실로, 손상 범위에 따라 hemianopia(반시야), quadrantanopia(사분면), scotoma(국소)로 나뉜다. Blindsight는 V1 손상으로 의식적 시각을 잃었음에도 방향, 움직임, 대비 등을 무의식적으로 판별하는 현상이다. 이는 LGN→V5/MT 등 V1을 우회하는 대체 시각 경로의 작동을 반영하며, 의식적 시각과 무의식적 처리의 기능적 차이를 보여준다.
Key Terms
Hemianopia
Cortical blindness restricted to one half of the visual field (associated with damage to the primary visual cortex in one hemisphere).
Hemianopia는 한 반구의 V1 손상으로 반쪽 시야가 상실되는 피질 실명이다.
Quadrantanopia
Cortical blindness restricted to a quarter of the visual field.
Quadrantanopia는 V1의 부분 손상으로 시야의 사분면이 상실되는 상태이다.
Scotoma
A small region of cortical blindness.
Scotoma는 V1의 국소적 손상으로 인한 작은 영역의 피질 실명이다.
Retinotopic organization
The receptive fields of a set of neurons are organized in such a way as to reflect the spatial organization present in the retina.
Retinotopic organization은 뉴런의 수용장이 망막의 공간적 배열을 보존하는 구조이다.
Blindsight
Summary
Blindsight는 V1 손상으로 의식적 시각을 잃었으나 방향, 움직임, 대비 판별이 가능한 현상이다. 환자 DB는 V1 절제 후 맹시야에서 아무것도 보이지 않는다고 보고했으나, 강제 선택 시 우연 수준을 크게 초과하는 성과를 보였다. 이는 LGN→V5/MT 등 V1 우회 경로의 작동을 반영하며, 무의식적 경로는 조잡한 변별만 가능하여 의식적 시각의 필요성을 설명한다.
A symptom in whi the patient reports not being able to consciously see stimuli in a particular region but can nevertheless perform visual discriminations (e.g. long, short) accurately.
Loss of one eye, or the optic nerve of that eye, results in complete blindness in that eye. e spared eye would still be able to perceive the le and right sides of space and transmit information to the le and right primary visual cortex. But what would be the consequences of complete damage to one side of the primary visual cortex itself? In this instance, there would be cortical blindness for one side of space (if the le cortex is damaged, then the right visual field would be blind, and vice versa). e deficit would be present when using either the le or right eye alone, or both eyes together. is deficit is termed hemianopia (or homonymous hemianopia). Partial damage to the primary visual cortex might affect one subregion of space. As the upper part of V1 (above a line called the calcarine fissure) represents the boom side of space, and the lower part of V1 represents the top part of space—damage here can give rise to cortical blindness in a quarter of the visual field (so-called quadrantanopia). Blindness in a smaller region of space is referred to as a cortical scotoma. Note that the layout of visual information in V1 parallels that found on the retina. at is, points that are close in space on the retina are also close in space in V1. Areas su as V1 are said to be retinotopically organized.
e previous section described how there are several visual routes from the eye to the brain. Ea of these routes makes a different contribution to visual perception. Taking this on board, one might question whether damage to the brain (as opposed to the eyes) could really lead to total blindness unless ea and every one of these visual pathways coincidentally happened to be damaged. In fact, this is indeed the case. Damage to the primary visual cortex does lead to an inability to report visual stimuli presented in the corresponding affected region of space and can be disabling for su a person. Nevertheless, the other remaining visual routes might permit some aspects of visual perception to be performed satisfactorily in exactly the same regions of space that are reported to be blind. is paradoxical situation has been referred to as “blindsight” (Weiskrantz et al., 1974).
Patients exhibiting blindsight deny having seen a visual stimulus even though their behavior implies that the stimulus was in fact seen (for a review, see Cowey, 2004). For example, patient DB had part of his primary
visual cortex (V1) removed to cure a ronic and severe migraine (this was reported in detail by Weiskrantz, 1986). When stimuli were presented in DB’s blind field, he reported seeing nothing. However, if asked to point or move his eyes to the stimulus then he could do so with accuracy, while still maintaining that he saw nothing. DB could perform a number of other discriminations well above ance, su as orientation discrimination (horizontal, vertical, or diagonal), motion detection (static or moving) and contrast discrimination (gray on bla versus gray on white). In all these tasks DB felt as if he was guessing even though he clearly was not. Some form/shape discrimination was possible but appeared to be due to detection of edges and orientations rather than shape itself. For example, DB could discriminate between X and O, but not between X and Δ and not between squares and rectangles that contain lines of similar orientation (but see Marcel, 1998).
How can the performance of patients su as DB be explained? First of all, one needs to eliminate the possibility that the task is being performed by remnants of the primary visual cortex. For example, there could be islands of spared cortex within the supposedly damaged region (Campion et al., 1983). However, many patients have undergone structural MRI and it has been established that no cortex remains in the region corresponding to the “blind” field (Cowey, 2004). Another explanation is that light from the stimulus is scaered into other intact parts of the visual field and is detected by intact parts of the primary visual cortex. For example, some patients may be able to detect stimuli supposedly in their blind field because of light reflected on their nose or other surfaces in the laboratory (Campion et al., 1983). Evidence against this comes from the fact that performance is superior in the “blindsight” region to the natural blind spot (found in us all). is cannot be accounted for by scaered light (see Cowey, 2004). us, the most satisfactory explanation of blindsight is that it reflects the operation of other visual routes from the eye to the brain rather than residual ability of V1. For instance, the ability to detect visual motion in blindsight might be due to direct projections from the LGN to area V5/MT that bypasses V1 (Hesselmann et al., 2010).
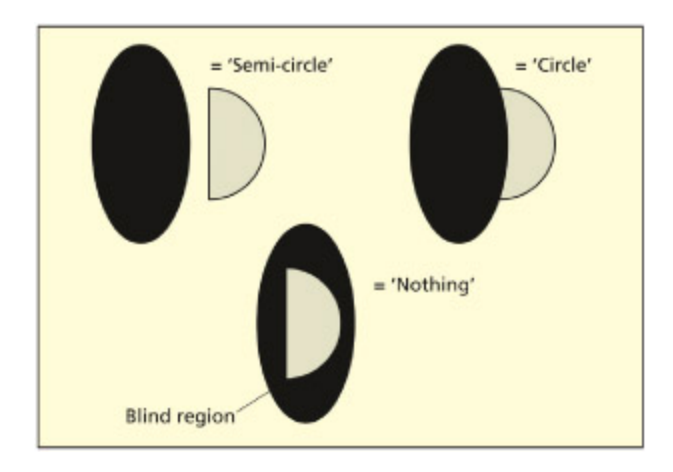
If a visually presented semi-circle abuts a cortical scotoma (the shaded area), then the patient might report a complete circle. us, rather than seeing a gap in their vision, patients with blindsight might fill in the gap using visual information in the spared field. If the semi-circle is presented inside the scotoma, it isn’t seen at all, whereas if it is away from the scotoma, it is perceived normally. Adapted from Torjussen, 1976.
📊 그림 설명
Blindsight 환자의 시각적 채움(filling-in) 현상을 보여준다. 반원이 피질 암점(scotoma) 경계에 걸쳐 제시되면 환자는 완전한 원으로 지각하며, 암점 내부에만 있으면 보이지 않고, 암점 밖에 있으면 정상적으로 지각된다. 이는 뇌가 손상된 시야 영역을 주변 정보로 능동적으로 보완함을 시사한다.
is account raises important questions about the functional importance of conscious versus unconscious visual processes. If unconscious visual processes can discriminate well, then why is the conscious route needed at all? As it turns out, su questions are misguided because the unconscious routes (used in blindsight) are not as efficient and are only capable of coarse discriminations in comparison to the finely tuned discriminations aieved by V1 (see Cowey, 2004). At present, we do not have a full understanding of why some neural processes but not others are associated with conscious visual experiences. Nevertheless, studies of patients with blindsight provide important clues about the relative contribution and functions of the different visual pathways in the brain.
Blindsight ≠ normal vision – awareness of vision
Blindsight = impaired vision + no awareness of vision
시험 팁
Blindsight의 핵심 공식을 기억하자: Blindsight는 “정상 시각 - 의식”이 아니다. 무의식 경로는 조잡한 변별만 가능하므로 정상 시각보다 훨씬 제한적이다. 시험에서 “blindsight가 의식적 시각이 불필요함을 증명하는가?”라고 물으면, 답은 아니오 — 무의식 경로만으로는 세밀한 시각 처리가 불가능하기 때문이다.
임상 사례
환자 DB는 V1 절제 후 맹시야에서 “아무것도 안 보인다”고 보고했지만, 강제 선택 과제에서 방향/움직임/대비를 우연 수준 이상으로 판별했다. 이는 LGN→V5/MT 우회 경로가 작동한 결과이다. 임상에서 blindsight를 검출하려면 반드시 강제 선택 과제(forced-choice task)를 사용해야 하며, 단순 보고만으로는 잔존 시각 능력을 놓칠 수 있다.
Functional Specialization of the Visual Cortex Beyond V1
Summary
V1 너머의 extrastriate cortex는 특정 시각 속성에 기능적으로 특화되어 있다. V4는 색상, V5/MT는 움직임 처리를 담당하며, ventral stream(후두엽→측두엽)은 물체 인식/기억, dorsal stream(후두엽→두정엽)은 시각 유도 행동/주의에 관여한다. 뇌 손상으로 색상만(achromatopsia) 또는 움직임만(akinetopsia) 선택적으로 장애될 수 있다.
Key Terms
Ventral stream
In vision, a pathway extending from the occipital lobes to the temporal lobes involved in object recognition, memory and semantics.
Ventral stream은 후두엽에서 측두엽으로 이어지는 경로로, 물체 인식, 기억, 의미 추출에 관여한다(“what” pathway).
Dorsal stream
In vision, a pathway extending from the occipital lobes to the parietal lobes involved in visually guided action and attention.
Dorsal stream은 후두엽에서 두정엽으로 이어지는 경로로, 시각 유도 행동과 주의에 관여한다(“where/how” pathway).
e neurons in V1 are specialized for detecting edges and orientations, wavelengths and light intensity. ese form the building blos for constructing more complex visual representations based on form (i.e. shape), color and movement. Some of the principal anatomical connections between these regions are shown in the figure below. One important division, discussed in more detail in later apters, is between the ventral stream (involved in object recognition and memory) and the dorsal stream (involved in action and aention). e ventral stream runs along the temporal lobes whereas the dorsal stream terminates in the parietal lobes.
e occipital cortex outside V1 is known as the extrastriate cortex (or prestriate cortex). e receptive fields in these extrastriate visual areas become increasingly broader and less coherently organized in space, with
areas V4 and V5/MT having very broad receptive fields (Zeki, 1969). e extrastriate cortex also contains a number of areas that are specialized for processing specific visual aributes su as color (area V4) and movement (area V5 or MT, standing for medial temporal). To some extent, the brain’s strategy for processing information outside of V1 is to “divide and conquer.” For example, it is possible to have brain damage that impairs color perception (cerebral aromatopsia) or movement perception (cerebral akinetopsia) that preserves other visual functions.
Key Terms
V4
A region of extrastriate cortex associated with color perception.
V4는 extrastriate cortex의 색상 인식 전문 영역으로, 손상 시 cerebral achromatopsia(세계를 회색조로 인식)가 발생한다.
V5 (or MT)
A region of extrastriate cortex associated with motion perception.
V5/MT는 extrastriate cortex의 움직임 인식 전문 영역으로, 손상 시 akinetopsia(움직임 인식 불능)가 발생한다.
Achromatopsia
A failure to perceive color (the world appears in grayscale), not to be confused with color blindness (deficient or absent types of cone cell).
Achromatopsia는 V4 손상으로 세상을 회색조로 인식하는 증상으로, 망막 cone cells 결핍에 의한 색맹(color blindness)과는 구별된다.
Akinetopsia
A failure to perceive visual motion.
Akinetopsia는 V5/MT 손상으로 시각적 움직임을 인식하지 못하는 장애이다.
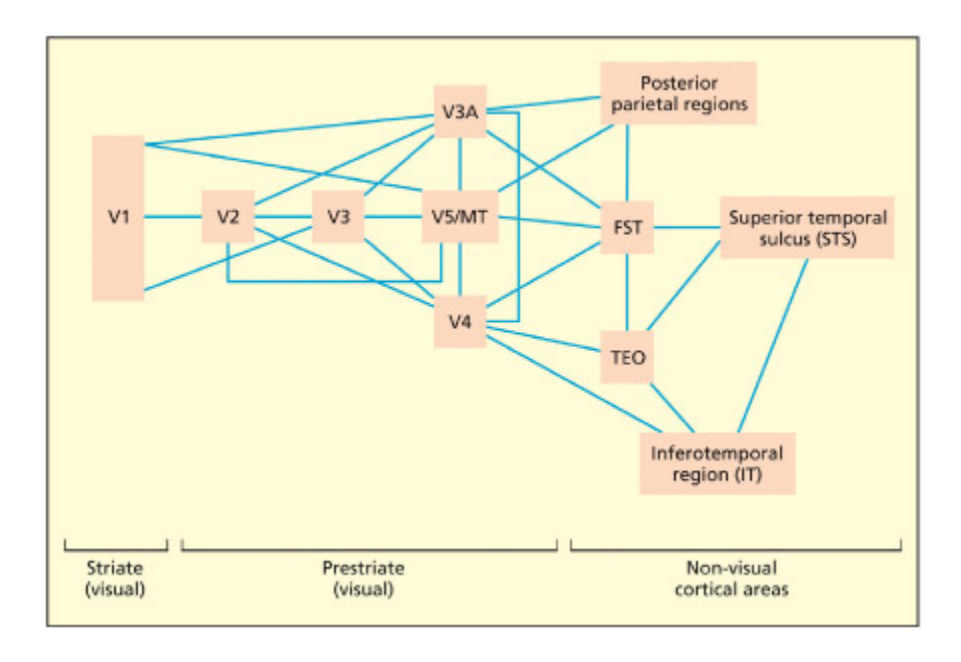
Information from V1 is sent in parallel to a number of other regions in the extrastriate cortex, some of whi are specialized for processing particular visual aributes (e.g. V5/MT for movement). ese extrastriate regions interface with the temporal cortex (involved in object recognition) and parietal cortex (involved in space and aention).
📊 그림 설명
**V1에서 외선조 피질(extrastriate cortex)**로의 병렬 정보 전달을 도식화한 그림이다. V1의 정보는 V5/MT(움직임), V4(색상) 등 특화된 영역으로 동시에 전송된다. 이 영역들은 측두엽(물체 인식)과 두정엽(공간/주의)으로 연결되어, ventral stream과 dorsal stream의 기초를 형성한다.
주의
Ventral stream과 dorsal stream을 단순히 “what vs where”로만 외우면 오답이 나올 수 있다. Dorsal stream은 위치뿐 아니라 “how”(행동 유도) 기능도 수행한다(Goodale & Milner, 1992). 또한 achromatopsia(V4 손상, 색상 상실)와 color blindness(망막 cone cell 결핍)는 완전히 다른 질환이다 — 전자는 뇌 손상, 후자는 망막 이상이다.
V4: The main color center of the brain
Summary
V4는 뇌의 주요 색상 처리 중심지로, 손상 시 achromatopsia가 발생한다. V4는 수용장 내외의 파장 비교를 통해 조명 변화에도 색이 일정하게 보이는 color constancy를 구현하며, 이는 국소적 파장에만 반응하는 V1과 대비된다. fMRI 연구에서 V4의 voxel은 인접 색상에 등급형 선택성을 보여 관계적 색상 코딩을 시사한다.
Area V4 is believed to be the main color center in the human brain because lesions to it result in a la of color vision, so that the world is perceived in shades of gray (Heywood et al., 1998; Zeki, 1990). is is termed cerebral aromatopsia. It is not to be confused with color blindness in whi people (normally men) have difficulty discriminating reds and greens because of a deficiency in certain types of retinal cells. Aromatopsia is rare because there are two V4 areas in the brain and it is unlikely that brain damage would symmetrically affect both hemispheres. Damage to one of the V4s would result in one side of space being seen as colorless (le V4 represents color for the right hemifield and vice versa). Partial damage to V4 can result
in colors that appear “dirty” or “washed out” (Meadows, 1974). In people who have not sustained brain injury, area V4 can be identified by functional imaging by comparing viewing paerns of colored squares (so-called Mondrians, because of a similarity to the work of that artist) with their equivalent gray-scale picture (Zeki et al., 1991). e gray-scale pictures are mated for luminance su that if either image were viewed through a bla and white camera they would appear identical to ea other.
Why is color so important that the brain would set aside an entire region dedicated to it? Moreover, given that the retina contains cells that detect different wavelengths of visible light, why does the brain need a dedicated color processor at all? To answer both of these questions, it is important to understand the concept of color constancy. Color constancy refers to the fact that the color of a surface is perceived as constant even when illuminated in different lighting conditions and even though the physical wavelength composition of light reflected from a surface can be shown (with recording devices) to differ under different conditions. For example, a surface that reflects a high proportion of long-wave “red” light will appear red when illuminated with white, red, green or any other type of light. Color constancy is needed to facilitate recognition of, say, red tomatoes across a wide variety of viewing conditions.
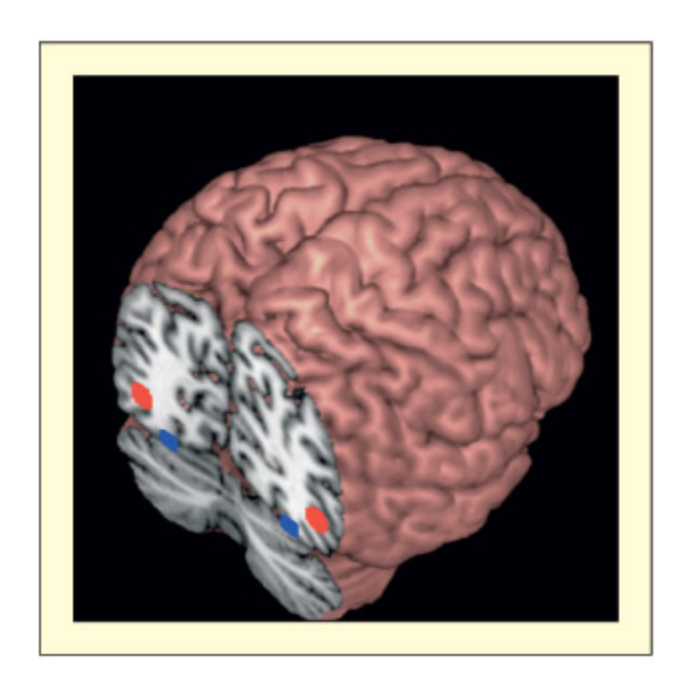
Area V5/MT (in red) lies near the outer surface of both hemispheres and is responsible for perception of visual motion. Area V4 (in blue) lies on the under surface of the brain, in ea hemisphere, and is responsible for the perception of color. is brain is viewed from the ba.
📊 그림 설명
V5/MT(빨간색)와 V4(파란색)의 뇌 내 위치를 후방에서 본 그림이다. V5/MT는 양 반구의 외측면 근처에 위치하여 시각적 움직임을 처리하고, V4는 뇌의 하면(ventral surface)에 위치하여 색상 인식을 담당한다. 두 영역 모두 양측성으로 존재한다.
e derivation of color constancy appears to be the function of V4 (Zeki, 1983). Neurons in V4 may aieve this by comparing the wavelength in their receptive fields with the wavelength in other fields. In this way it is possible to compute the color of a surface while taking into account the illuminating conditions of the whole scene (Land, 1964, 1983). Cells in earlier visual regions (e.g. V1) respond only to the local wavelength in their receptive field and their response would ange if the light source were anged even if the color of the stimulus was not (Zeki, 1983). Aromatopsic patients with damage to V4 are able to use earlier visual processes that are based on wavelength discrimination in the absence of color experience. For example, patient MS could tell if two equiluminant colored pates were the same or different if they abued to form a common edge, but not if they were separated (Heywood et al., 1991). is occurs because wavelength comparisons outside of V4 are made at a local level. Although earlier visual regions respond to wavelength, V4 has some special aracteristics. e neurons in V4 tend to have larger receptive fields than earlier regions. Moreover, evidence from fMRI shows that voxels that are sensitive to one color (e.g. red) tend to have graded selectivity to perceptually neighboring colors (e.g. violets, yellows), but this is not found in earlier visual regions (Brouwer & Heeger, 2009). It suggests that V4 implements a relational coding between colors (analogous to a color wheel) that may also be helpful for color constancy.
It should be pointed out that V4 is not the only color-responsive region of the brain. For example, Zeki and Marini (1998) compared viewing of appropriately colored objects (e.g. red tomato) with inappropriate ones (e.g. blue tomato) and found activation in, among other regions, the hippocampus, whi may code long-term memory representations.
Key Terms
Color constancy
The color of a surface is perceived as constant even when illuminated in different lighting conditions.
Color constancy는 조명 조건이 변해도 표면의 색이 일정하게 인식되는 현상이다. V4가 수용장 간 파장 비교를 통해 광원을 보정함으로써 구현된다.
V5/MT: The main movement center of the brain
Summary
V5/MT는 뇌의 주요 움직임 처리 중심지로, 90%의 세포가 특정 방향의 움직임에만 반응한다. 환자 LM은 양측 V5/MT 손상 후 akinetopsia가 발생하여 세계를 정지 프레임으로 경험했으나, 생물학적 움직임(biological motion) 구분은 가능했다. 이는 생물학적 움직임이 별도 경로로 처리됨을 시사한다.
Key Terms
Biological motion
The ability to detect whether a stimulus is animate or not from movement cues alone.
Biological motion은 움직임 단서만으로 생물/비생물을 구별하는 능력이다. V5/MT 손상 환자 LM도 관절 빛점의 생물학적 움직임을 구분할 수 있어 별도 경로(superior temporal sulcus 등)의 존재가 시사된다.
If participants in a PET scanner view images of moving dots relative to static dots, a region of the extrastriate cortex called V5 (or MT) becomes particularly active (Zeki et al., 1991). Earlier electrophysiological resear on the monkey had found that all cells in this area are sensitive to motion, and that 90 percent of them respond preferentially to a particular direction of motion and will not respond at all to the opposite direction of motion (Zeki, 1974). None were color-sensitive.
Patient LM lost the ability to perceive visual movement aer bilateral damage to area V5/MT (Zihl et al., 1983). is condition is termed
akinetopsia (for a review, see Zeki, 1991). Her visual world consists of a series of still frames: objects may suddenly appear or disappear, a car that is distant may suddenly be seen to be near, and pouring tea into a cup would invariably end in spillage as the level of liquid appears to rise in jumps rather than smoothly.
More recent studies have suggested that other types of movement perception do not rely on V5/MT. For example, LM is able to discriminate biological from non-biological motion (McLeod et al., 1996). e perception of biological motion is assessed by aaing light points to the joints and then recording someone walking/running in the dark. When only the light points are viewed, most people are still able to detect bodily movement (relative to a condition in whi these moving lights are presented jumbled up). LM could discriminate biological from non-biological motion, but could not perceive the overall direction of movement. Separate pathways for this type of motion have been implied by functional imaging (Vaina et al., 2001).
LM was able to detect movement in other sensory modalities (e.g. tou, audition), suggesting that her difficulties were restricted to certain types of visual movement (Zihl et al., 1983). However, functional imaging studies have identified supramodal regions of the brain (in parietal cortex) that appear to respond to movement in three different senses—vision, tou, and hearing (Bremmer et al., 2001).
시험 팁
V4와 V5/MT의 기능을 빠르게 구분하는 법: **V4 = Color(색), V5 = Velocity(속도)**로 연상하면 쉽다. V4 손상 = achromatopsia(세상이 흑백), V5 손상 = akinetopsia(세상이 정지 프레임). 환자 LM은 V5/MT 양측 손상 후 커피를 따를 때 액체가 “얼어붙은 것처럼” 보여 넘치는 일이 반복되었다.
Evaluation
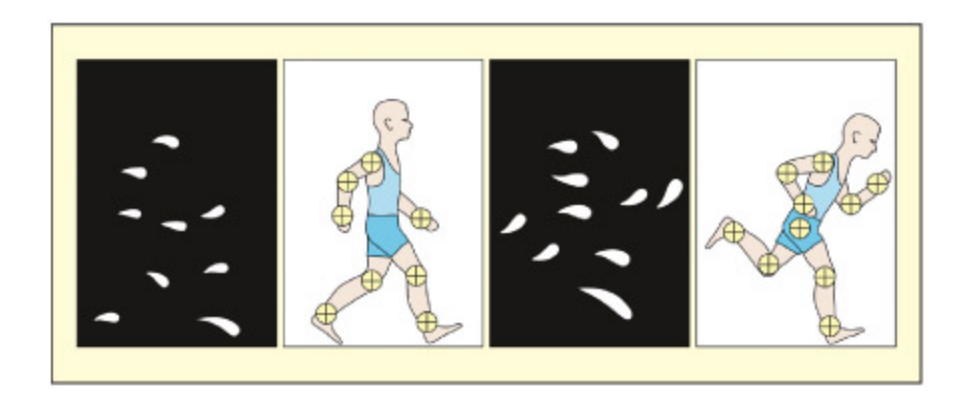
When this array of dots is set in motion, most people can distinguish between biological and nonbiological motion.
📊 그림 설명
생물학적 움직임(biological motion) 인식을 위한 점광원 보행자(point-light walker) 자극이다. 관절 위치에만 점을 부착하여 움직이면 대부분의 사람이 사람의 걷기를 즉시 인식할 수 있다. 이 과제는 **STS(상측두고랑)**와 V5/MT 영역의 기능적 특화를 연구하는 데 사용된다.
One emerging view of visual processing in the brain beyond V1 is that different types of visual information get parsed into more specialized brain regions. us, when one looks at a dog running across the garden, information about its color resides in one region, information about its movement resides in another and information about its identity (this is my dog rather than any dog) resides in yet another, to name but a few. e question of how these different streams of information come ba together (if at all) is not well understood, but may require the involvement of nonvisual processes related to aention (see Chapter 7).
| HowDoestheBrainRespondtoVisualIllusions? | ||
|---|---|---|

Do you see movement in the image on the top when you stare at the center? Do you see a vase or faces on the boom? How does the brain interpret su ambiguities?
📊 그림 설명
두 가지 시각적 착시/양의성을 보여준다. 상단은 정지 이미지에서 움직임 착시를 유발하는 패턴이고, 하단은 Rubin의 꽃병/얼굴 착시로, 동일 자극이 꽃병 또는 두 얼굴로 지각된다. 이러한 **양의적 자극(ambiguous stimuli)**은 시각 인식이 뇌의 능동적 해석 과정임을 보여준다.
Top image by Isia Levant, 1981, www.miaelba.de/ot/mot\_enigma/index.html
When you look at the top figure do you have a sense of motion in the circles even though the image is static? is image is called the Enigma illusion. When you look at the boom image do you see one vase or two faces? Does this image appear to spontaneously flip between one interpretation and the other, even though the image remains constant? Examples su as these reveal how the brain’s perception of the world can differ from the external physical reality. is is, in fact, a normal part of seeing. Visual illusions are in many respects the norm rather than the exception, even though we are not always aware of them as su.
A functional imaging study has shown that parts of the brain specialized for detecting real movement (area V5/MT) also respond to the Enigma illusion (Zeki et al., 1993). A recent study suggests that the illusion is driven by tiny adjustments in eye fixation (Troncoso et al., 2008). An fMRI study using bi-stable stimuli su as the face-vase has shown how different visual and non-visual brain structures cooperate to maintain perceptual stability. e momentary breakdown of activity in these regions is associated with the timing of the subjective perceptual flip (Kleinsmidt et al., 1998). TMS over the right parietal lobes affects the rate of swit between bi-stable images with adjacent regions either promoting stability or generating instability (Kanai et al., 2011). is suggests different top-down biasing influences on perception.
Recognizing Objects
Summary
물체 인식은 4단계로 진행된다: (1) 엣지/선 추출, (2) 깊이/표면 분리(Gestalt grouping), (3) 구조적 설명(structural descriptions)과 매칭하여 object constancy 확보, (4) 의미 부여. Visual agnosia는 이 과정의 손상 위치에 따라 지각 단계의 apperceptive agnosia와 의미 단계의 associative agnosia로 나뉜다.
Key Terms
Structural descriptions
A memory representation of the three-dimensional structure of objects.
Structural descriptions는 물체의 3차원 구조 정보를 기억에 저장한 표현이다. 시각 입력을 이 표현과 매칭하여 시점/조명이 변해도 동일 물체로 인식하는 object constancy를 달성한다.
Apperceptive agnosia
A failure to understand the meaning of objects due to a deficit at the level of object perception.
Apperceptive agnosia는 지각 단계의 결함으로 물체의 의미를 이해하지 못하는 상태이다.
Associative agnosia
A failure to understand the meaning of objects due to a deficit at the level of semantic memory.
Associative agnosia는 물체를 지각할 수는 있으나 의미 기억(semantic memory)과의 연결 결함으로 물체의 의미를 이해하지 못하는 상태이다.
For visual information to be useful it must make contact with knowledge that has been accumulated about the world. ere is a need to recognize places that have been visited and people who have been seen, and to recognize other stimuli in the environment in order to, say, distinguish between edible and non-edible substances. All of these examples can be subsumed under the process of “object recognition.” Although different types of object (e.g. faces) may recruit some different meanisms, there will nevertheless be some common meanisms shared by all objects, given that they are extracted from the same raw visual information.
e figure below describes four basic stages in object recognition that, terminology aside, bear a close resemblance to Marr’s (1976) theory of vision:
-
- e earliest stage in visual processing involves basic elements su as edges and bars of various lengths, contrasts and orientations. is stage has already been considered above.
-
- Later stages involve grouping these elements into higher-order units that code depth cues and segregate surfaces into figure and ground. Some of these meanisms were first described by the Gestalt psyologists and are considered below. It is possible that this stage is also influenced by top-down information based on stored knowledge. ese visual representations, however, represent objects according to the observer’s viewpoint and object constancy is not present.
-
- e viewer-centered description is then mated onto stored threedimensional descriptions of the structure of objects (structural descriptions). is store is oen assumed to represent only certain
viewpoints and thus the mating process entails the computation of object constancy (i.e. an understanding that objects remain the same irrespective of differences in viewing condition). ere may be two different routes to aieving object constancy, depending on whether the view is “normalized” by rotating the object to a standard orientation.
- Finally, meaning is aributed to the stimulus and other information (e.g. the name) becomes available. is will be considered primarily in Chapter 11.
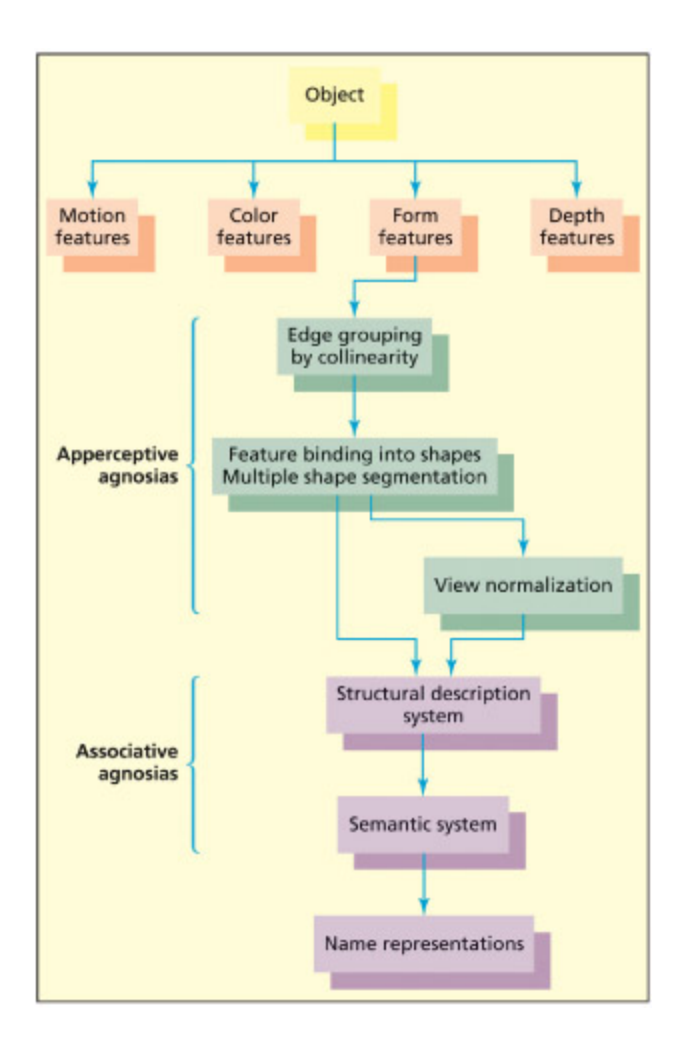
A simple model of visual object recognition.
📊 그림 설명
시각 물체 인식의 기본 모델을 도식화한 그림이다. 시각 입력이 초기 처리(엣지, 색상 등)를 거쳐 구조적 기술(structural description)과 매칭되고, 이를 통해 의미 기억(semantic memory)에 접근하여 물체를 명명하는 과정을 보여준다. 이 모델은 시각 실인증(visual agnosia)의 유형을 분류하는 기초 틀로 사용된다.
From Riddo and Humphreys, 2001.
Disorders of object recognition are referred to as visual agnosia, and these have been traditionally subdivided into apperceptive agnosia and associative agnosia, depending on whether the deficit occurs at stages involved in perceptual processing or stages involving stored visual memory representations (Lissauer, 1890). is classification is perhaps too simple to be of mu use in modern cognitive neuroscience. Models su as the one of Riddo and Humphreys (2001) anowledge that both perception and the stored properties of objects can be broken down into even finer processes. It is also the case that most contemporary models of object recognition allow for interactivity between different processes rather than discrete processing stages. is is broadly consistent with the neuroanatomical data (see earlier) of connections between early and late visual regions and vice versa.
Key Terms
Figure-ground segregation
The process of segmenting a visual display into objects versus background surfaces.
Figure-ground segregation은 시각 장면을 물체와 배경으로 분리하는 과정이다. Gestalt 원리 5가지—근접성, 유사성, 좋은 연속성, 폐쇄성, 공통 운명—가 시각 요소를 결합한다.
Parts and wholes: Gestalt grouping principles
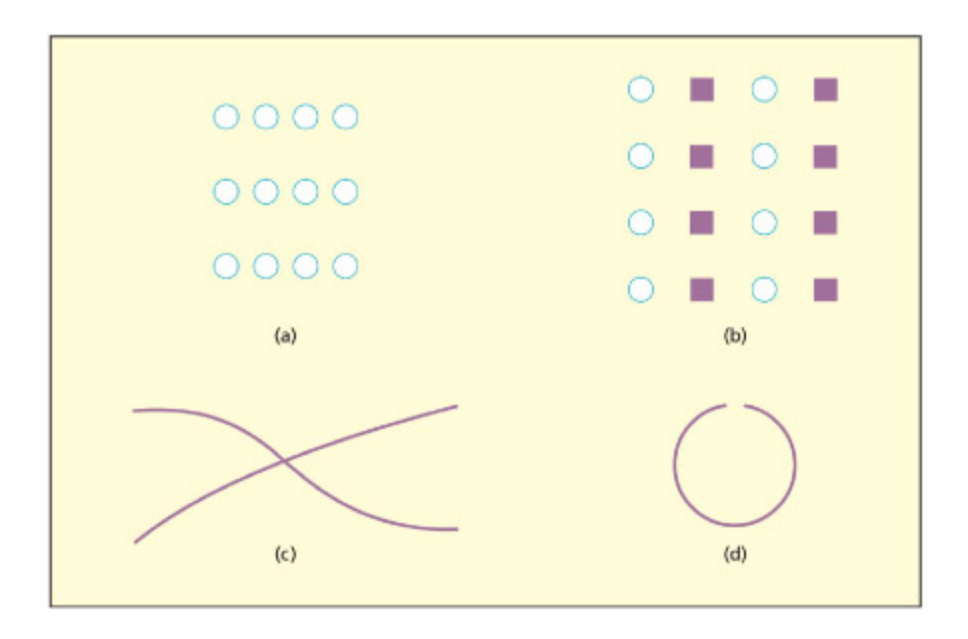
e Gestalt principles of (a) law of proximity, (b) law of similarity, (c) law of good continuation, and (d) law of closure.
📊 그림 설명
게슈탈트 원리 네 가지를 시각적으로 예시한다. (a) 근접성의 법칙: 가까운 요소끼리 그룹으로 지각, (b) 유사성의 법칙: 유사한 요소끼리 묶임, (c) 좋은 연속성의 법칙: 매끄럽게 이어지는 선으로 지각, (d) 폐합의 법칙: 불완전한 형태를 완성된 것으로 지각한다.
In the 1930s, Gestalt psyologists identified a number of principles that explain why certain visual features become grouped together to form perceptual wholes. ese operations form a key stage in translating simple features into three-dimensional descriptions of the world, essential for object recognition. e process of segmenting a visual display into objects versus baground surfaces is also known as figure–ground segregation. e Gestalt approa identified five basic principles to account for how basic visual features are combined:
-
- The law of proximity states that visual elements are more likely to be grouped if they are closer together. For example, the dots in (a) in the figure tend to be perceived as three horizontal lines because they are closer together horizontally than vertically.
-
- The law of similarity states that elements will be grouped together if they share visual aributes (e.g. color, shape). For example, (b) tends to be perceived as vertical columns rather than rows, because elements in columns share both shape and color.
-
- The law of good continuation states that edges are grouped together to avoid anges or interruptions; thus, (c) is two crossing lines rather than > and <.
-
- The law of closure states that missing parts are “filled in”; thus (d) has circular properties in spite of the gap. is law, and the previous one, is important for recognizing objects that are partly occluded.
-
- The law of common fate states that elements that move together tend to be grouped together. A good example of this comes from studies of biological motion perception (e.g. Johansson, 1973). Light points aaed to bodily joints are perceived as movement of a single human figure when viewed in the dark.
Perceptual grouping occurs at multiple levels within the visual hierary (and via interactions between those levels). For instance, grouping of light points based on the known structure and dynamics of the human body occurs only at later stages of visual processing, in this case in the superior temporal sulcus (Grossman et al., 2000). In other instances, there is evidence of grouping effects at the earliest stages of visual processing. Cells in V1 tuned to particular orientations fire more when these orientations are part of the figure than the ground as shown by animal single-cell electrophysiology (Lamme, 1995). Human fMRI shows that V1 as well as higher visual regions are sensitive to the law of good continuation (Altmann et al., 2003). In general, whether grouping occurs early or late will depend on the nature of the stimulus and the extent to whi it depends on stored knowledge of objects (e.g. shape of the human body) or less specific knowledge (e.g. the general properties of surfaces, su as occlusion).
Case HJA: seeing the parts but not the whole
Summary
환자 HJA는 선의 길이/방향/위치 구분은 가능하지만 부분을 전체로 통합하는 능력이 손상된 integrative agnosia의 대표 사례이다. 그림 복사와 기억 기반 그리기는 가능하지만 물체 식별은 불가능하며, Gestalt 원리를 활용한 grouping이 작동하지 않는다. 다만 좋은 연속성 등 초기 단계의 국소적 grouping은 부분적으로 보존되어 있다.
| HJA’s spared abilities | HJA’s impaired abilities |
|---|---|
| HJA’s spared abilities | HJA’s impaired abilities |
|---|---|
| • He is able to copydrawings of objects thathe cannot recognize,suggesting that he can”see” them at some level. | • He is unable to recognize pictures, but gives areasonable description of their parts. Forexample, when shown a carrot:“e boompoint seems solid and the other bits are feathery.It does not seem logical unless it is some sort ofbrush.” |
| • He is able to drawobjects from memory,suggesting that he canaccess structuraldescriptions frommemory, but not vision. | • When shown degraded pictures he does notbenefit from Gestalt principles in the same wayas other people do (Boucart & Humphreys, 1992). |
| • He is able to recognizeobjects from modalitiesother than vision and hasgood verbal knowledgeabout them. | • He is unable to perform an object decision taskin whi“novel” objects are created byrecombining the parts of real objects. |
Perhaps the most detailed study of visual agnosia in the literature is case HJA, whi was reported in a number of studies by Humphreys, Riddo and colleagues (Humphreys & Riddo, 1987; Riddo et al., 1999). HJA was a businessman who suffered a bilateral stroke that le him with severe difficulties in recognizing objects, but with preserved sensory discriminations of length, orientation, and position. A number of tests conducted on HJA support the conclusion that he has difficulty in integrating parts into wholes—a type of apperceptive agnosia on the simple model on p. 120. e evidence in support of this interpretation is summarized in the table below. ese results support the conclusion that HJA has difficulties in using perceptual grouping meanisms to translate his intact perception of lines into more complex visual descriptions required to access stored knowledge. His visual system does not permit him to take
advantage of Gestalt-based grouping meanisms that support normal object recognition. Humphreys and Riddo have termed this integrative agnosia. It isn’t the case that no grouping at all occurs. ere is evidence that local contours may be grouped together, for instance, based on the Gestalt principle of continuation (Giers et al., 2000). is is consistent with the claim that some forms of grouping, and figure–ground segmentation, occur at earlier stages in the visual stream (with these stages largely spared in HJA).
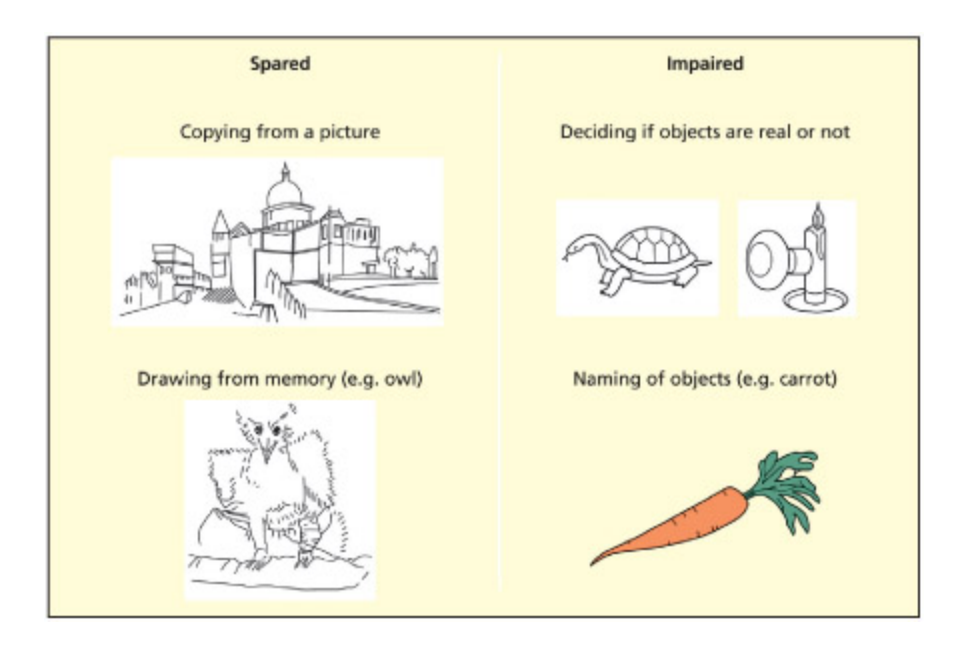
HJA is impaired at deciding if objects are real or made up and naming objects. However, he can copy drawings and draw objects from memory.
📊 그림 설명
통합적 실인증(integrative agnosia) 환자 HJA의 수행을 보여준다. HJA는 물체의 실재 여부 판단과 명명에 실패하지만, 그림 모사와 기억에서 그리기는 정상적으로 수행한다. 이는 시각적 특징들을 하나의 통합된 물체 표상으로 결합하는 과정에 선택적 손상이 있음을 시사한다.
Adapted from Humphreys and Riddo, 1987 and Riddo and Humphreys, 1995.
Accessing structural descriptions: object constancy
Summary
Object constancy는 시점/조명이 변해도 동일 물체로 인식하는 능력이다. 구조적 설명(structural descriptions)과의 매칭을 통해 달성되며, 부품 기반 매칭(Biederman)과 주축 추출(Marr & Nishihara) 두 경로가 병렬적으로 작동한다.
Key Terms
Integrative agnosia
A failure to integrate parts into wholes in visual perception.
Integrative agnosia는 시각의 부분을 전체로 통합하는 능력이 손상된 상태이다. HJA 사례처럼 개별 선분은 인식하나 Gestalt grouping이 작동하지 않아 물체 전체를 인식하지 못한다.
Object constancy
An understanding that objects remain the same, irrespective of differences in viewing condition.
Object constancy는 시점/조명 변화에도 동일 물체로 인식하는 능력이다. 정규 시점(canonical view)에서 인식이 더 빠르며(Palmer et al., 1981), 부품 기반 매칭(Biederman)과 주축 추출(Marr & Nishihara)의 두 경로가 병렬 작동한다.
One of the most important aspects of object recognition is to be able to recognize an object across different viewpoints and different lighting conditions—this is termed object constancy. It is generally agreed that object constancy is brought about by mating the constructed visual representation with a store of object descriptions in memory that carry information about the invariant properties of objects. One suggestion is that the brain stores only structural descriptions in the usual or canonical view, su that the principal axis is in view. Indeed, naming times for objects presented in usual views are faster (Palmer et al., 1981). Clinical tests of object constancy typically involve identifying (i.e. naming) objects drawn from different angles, or mating together different instances of the same object.
A number of different ways in whi this mating to memory process might occur have been put forward. Some researers have argued that object constancy is aieved by mating features or parts of objects to structural descriptions (Biederman, 1987; Warrington & Taylor, 1973). Others have argued that the most important meanism is more holistic and involves extracting the principal axis of an object (Marr & Nishihara, 1978). For example, if the principal axis of a tennis raet is viewed from a foreshortened angle it is harder to recognize. Others have suggested that both processes play a role (Humphreys & Riddo, 1984; Warrington &
James, 1986). e laer seems the most plausible based on the evidence reviewed below.
Key Terms
Object orientation agnosia
An inability to extract the orientation of an object despite adequate object recognition.
Object orientation agnosia는 물체를 인식할 수 있으나 올바른 방향 판단이 불가능한 상태로, 우측 두정엽 손상과 관련된다.
Some visual agnosic patients are able to recognize and name objects from the usual view, but are impaired at recognizing objects presented in unusual views (Humphreys & Riddo, 1984; Warrington & Taylor, 1973). is typically occurs aer damage to the right parietal lobe, whi has a particularly important role in spatial processing. e parietal lobe may contain meanisms that extract the principal axis from an object and then rotate the object to a standard view, thus facilitating mating. Patients with damage to this process would have to rely on a meanism that is independent of the way that the object is viewed. us, in these patients, the route drawn on the right of the model on p. 120 is impaired and the one on the le is spared. Other patients may have more subtle damage to this route su that they do not appear to be visually agnosic in tests of object naming or mating, yet they are unable to decide on the correct orientation for an object or even decide whether two simultaneously presented objects have the same orientation (Harris et al., 2001; Turnbull et al., 2002). ese striking cases of an inability to extract the orientation of an object despite adequate object recognition have been given the name object orientation agnosia. ese patients appear to aieve object constancy by using a viewindependent route that does not extract the orientation (or principal axis) of objects.
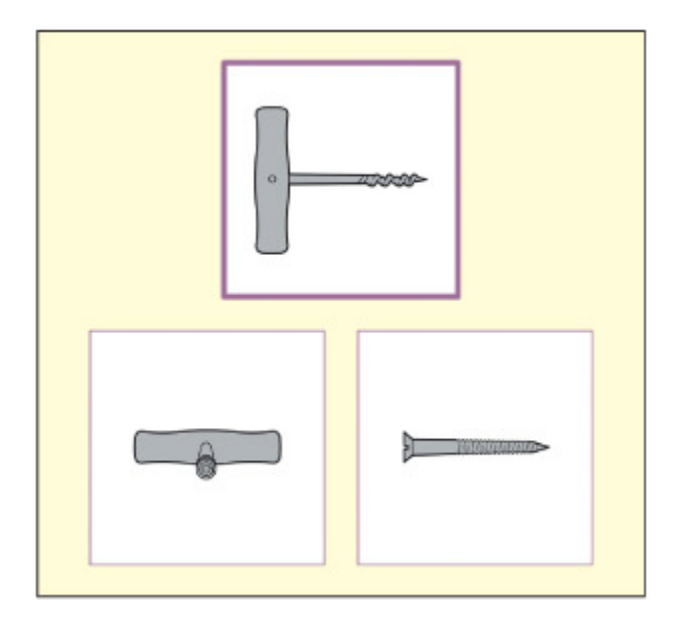
A test of object recognition that requires mating to an unusual view. From Riddo & Humphreys, 1995.
📊 그림 설명
비정상적 시점에서의 물체 인식 검사를 보여준다. 참가자는 일반적이지 않은 각도에서 촬영된 물체 사진을 보고 정상 시점의 물체와 매칭해야 한다. 이 과제는 물체 항상성(object constancy)과 시점 비의존적 표상의 존재 여부를 검증하는 데 사용된다.
An alternative account for the advantage of usual views is that these are more familiar and have more robust neural representations (Karnath et al., 2000; Perre et al., 1998), rather than suggesting two specialized routes. However, recent functional imaging evidence would appear to support the two-routes view, with different hemispheres implicated in ea. is evidence is outlined below.
Neural substrates of object constancy
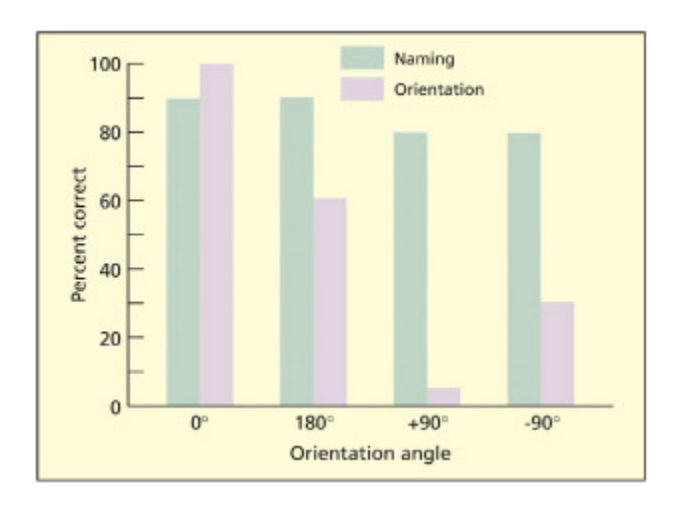
Patient EL with object orientation agnosia could produce the names of items presented in various orientations (green bars), but could not correctly judge whether an object was in its correct orientation (purple bars).
📊 그림 설명
물체 방향 실인증(object orientation agnosia) 환자 EL의 수행을 비교한 막대 그래프이다. EL은 다양한 방향으로 제시된 물체의 이름을 정확히 말할 수 있지만(녹색), 물체가 올바른 방향인지 판단하는 데 실패한다(보라색). 이는 물체 정체성(what)과 물체 방향(how)의 처리가 분리될 수 있음을 보여준다.
From Harris et al., 2001. © e MIT Press. Reproduced with permission.
e inferotemporal cortex (IT) takes its input from the geniculostriate pathway and appears to code the type of information important for object constancy. For example, single-cell recordings show that these cells respond to very specific object aributes, and have large receptive fields that almost always cover the fovea and typically extend to both hemifields (Gross, 1992; Gross et al., 1972). us, the neurons tend to code for specific visual information but are less concerned with the location of the object—an ideal condition for computing object constancy.
An fMRI study used pairs of stimuli of the same object that differed in size, viewpoint, or exemplar in a similar vein to the clinical tests of object constancy discussed above (Vuilleumier et al., 2002a). e logic behind the experiment is that the response of neurons tends to decrease over time if the same stimulus is repeated (priming). us, one can correlate reductions in fMRI signal with repetition of particular object aributes (i.e. whether “same” refers to the same viewpoint, the same size or the same type of object). It was found that the le inferotemporal (or fusiform) region responds irrespective of viewpoint or size, whereas viewpoint (but not size) was important for the comparable region in the right hemisphere. is is
convincing evidence that there are at least two routes to object constancy one that is sensitive to viewpoint and one that is not.
Other resear using fMRI repetition priming confirms viewpointinsensitive regions within inferotemporal cortex, but also finds regions within the parietal lobes that are sensitive to object viewpoint but not to object identity (Valyear et al., 2006). e laer may enable acting upon objects.
Category specificity in visual object recognition?
Summary
Category specificity는 뇌가 얼굴, 장소, 신체 등 다른 범주를 다른 방식/영역으로 표현하는지에 대한 논쟁이다. PPA(장소), EBA(신체), FFA(얼굴) 등 범주별 특화 영역이 발견되었으나, 이것이 강한 도메인 특화(단일 범주만 처리)인지 처리 방식의 상대적 차이인지는 논쟁 중이다.
It has already been suggested that higher visual areas of the brain may be specialized for processing particular visual aributes su as color and motion. But are there higher visual areas of the brain that are specialized for recognizing different categories of object su as animals, faces, places, words and bodies? Chapter 1 outlined Fodor’s (1983) theory that many cognitive functions are carried out by domain-specific modules. e term “domain-specific” refers to the fact that the module is hypothesized to process one, and only one, type of information (e.g. there may be a module that processes faces but not other types of stimuli). Evidence in favor of this strong position has been mustered from dissociations of spared and impaired performance in the recognition of different classes of object, and from the observation that different regions of the brain are optimized for responding to certain classes of stimuli. e notion that the brain represents different categories in different ways is termed category specificity. A parallel debate exists in the literature concerning whether the semantic representation of objects is represented categorically (see Chapter 11), as well as for the structural descriptions of objects. e alternative to the domain-specific hypothesis is that different categories of stimuli require somewhat different kinds of processing (e.g. words are recognized by parts, and faces recognized holistically), and that su differences may be relative rather than absolute.
Key Terms
Category specificity
The notion that the brain represents different categories in different ways (and/or different regions).
Category specificity는 뇌가 다른 범주를 다른 방식/영역으로 표현한다는 개념이다. PPA(장소), EBA(신체) 등이 발견되었으며, 얼굴 인식이 도메인 특화의 가장 강력한 증거를 제공한다.
is apter discusses the domain-specific hypothesis with regards to faces; Chapter 12 discusses a similar proposal with regards to recognizing visual words (Dehaene et al., 2002; Petersen et al., 1990). However, it is worth noting that functional imaging studies have identified other regions that appear to be relatively specialized for the visual recognition of particular categories. ese include the parahippocampal place area (PPA), whi responds to scenes more than objects (Epstein & Kanwisher, 1998), and the extrastriate body area (EBA), whi responds to the human body more than to faces, scenes or objects (Downing et al., 2001). Although these studies argue in favor of some degree of category specificity, it is unclear whether they support domain-specificity in the strong form (i.e. that the regions are only involved in recognizing stimuli from one category). e strongest evidence for domain specificity in object recognition so far has come from face processing, and this is considered next.
Recognizing Faces
Summary
얼굴 인식은 일반 물체 인식과 다르게 특정 개인 식별이 목표이며, 얼굴이 “특별한” 이유에 대해 처리 방식의 차이(holistic processing)와 고유 범주 가설이 경쟁한다. Bruce and Young(1986) 모델이 대표적 이론 틀이다.
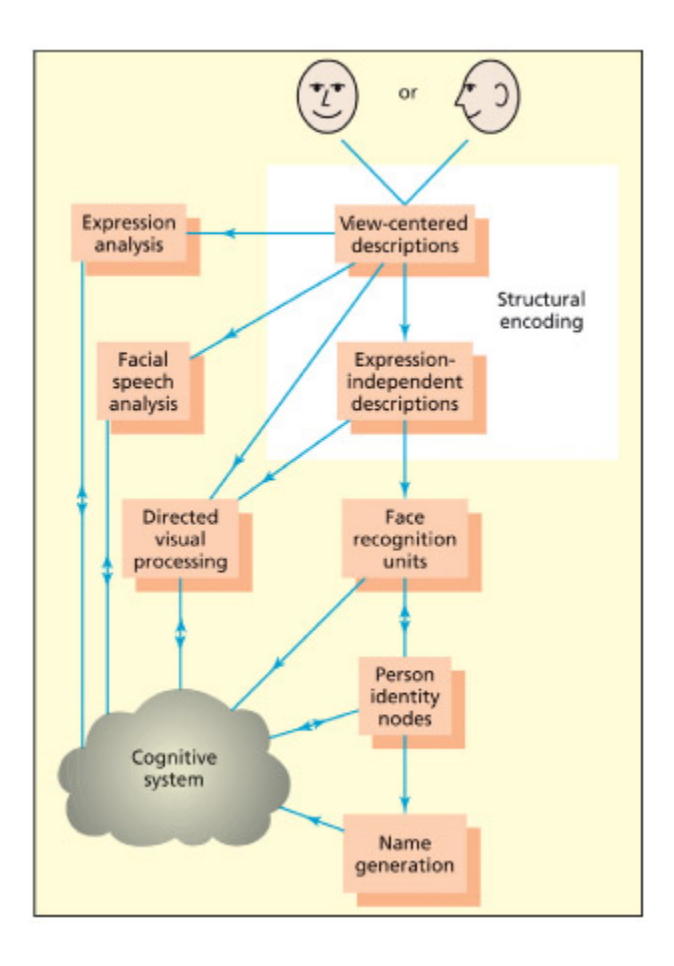
e Bruce and Young (1986) model of face recognition. From Parkin, 1996.
📊 그림 설명
Bruce & Young(1986)의 얼굴 인식 모델을 도식화한 그림이다. 얼굴 인식은 구조적 부호화(structural encoding) → 얼굴 인식 유닛(face recognition units) → 개인 정체성 노드(person identity nodes) → 이름 생성(name generation)의 단계를 거친다. 이 모델은 “얼굴은 아는데 이름이 안 난다”와 같은 일상 경험과 prosopagnosia의 해리 현상을 설명한다.
Although faces are a type of visual object like any other, there is some reason to believe that the process of face recognition may be different from other aspects of object recognition. First of all, the goal in face recognition is normally to identify one particular face (e.g. “that is Bara Obama!”) rather than categorizing a face as su (e.g. “that visual object is a face!”). Second, researers have suggested that faces might be “special” either because of the type of processing they require or because they are a distinct category. Although there is good evidence to suggest that faces do have a different neural substrate from most other objects and can be disproportionately spared or impaired, the reasons why this is so remain a maer of controversy.
Models of face processing
Summary
Bruce and Young(1986) 모델은 얼굴 처리를 구조적 인코딩→FRU(Face Recognition Units)→PIN(Person Identity Nodes)→이름 접근의 단계로 설명한다. Haxby et al.(2000) 모델은 핵심 시스템(후두/측두 영역의 정적/변화 얼굴 특징 처리)과 확장 시스템(주의, 감정, 이름 등)으로 분리한다.
Key Terms
Face recognition units (FRUs)
Stored knowledge of the three-dimensional structure of familiar faces.
FRUs(Face Recognition Units)는 익숙한 얼굴의 구조적 설명을 저장한 표현으로, 시점/조명 변화에도 얼굴을 일관되게 인식하게 한다.
Person identity nodes (PINs)
An abstract description of people that links together perceptual knowledge (e.g. faces) with semantic knowledge.
PINs(Person Identity Nodes)는 FRU 이후 단계로, 얼굴 지각 정보와 의미적 지식(직업, 이름 등)을 연결하는 추상적 표현이다.
Bruce and Young (1986) proposed a cognitive model of face recognition that has largely stood the test of time. ey assume that the earliest level of processing involves computation of a view-dependent structural description, as postulated for object recognition more generally. Following this, a distinction is made between the processing of familiar and unfamiliar faces. Familiar faces are recognized by mating to a store of face-based structural descriptions (whi they term face recognition units). Following this, a more abstract level of representation, termed person identity nodes, accesses semantic (e.g. their occupation) and name information about that individual. A separate route (termed directed visual processing) was postulated to deal with unfamiliar faces. A number of other face-processing routes are postulated to occur in parallel to the route involved in recognizing familiar people. Evidence from neurological patients suggests that recognition of emotional expression, age, and gender is independent of familiar face recognition (Tranel et al., 1988; for electrophysiological data,
see Hasselmo et al., 1989), as is the ability to use lip-reading cues (Campbell et al., 1986).
Key Terms
Fusiform face area (FFA)
An area in the inferior temporal lobes that responds more to faces than other visual objects, and is implicated in processing facial identity.
FFA(Fusiform Face Area)는 하측두엽에 위치하며 얼굴에 특화된 반응을 보이는 영역으로, 특히 익숙한 얼굴의 정체성 인식에 관여한다.
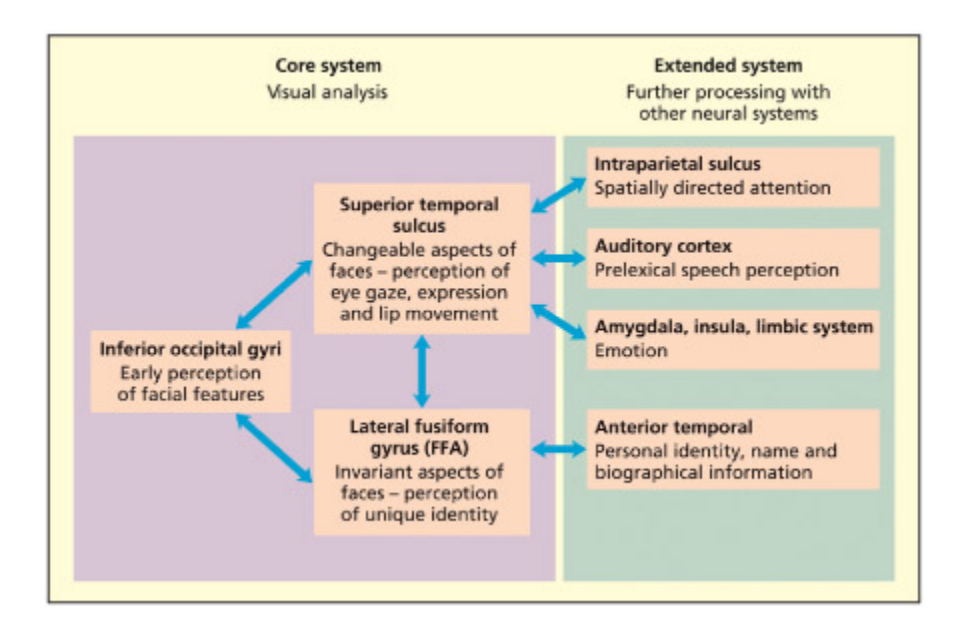
e model of Haxby et al. (2000) divides the neural substrates of face processing into a number of core meanisms (relatively specialized for faces) and an extended system in whi face processing makes contact with more general cognitive meanisms (e.g. concerning emotion, language, action).
📊 그림 설명
Haxby 등(2000)의 얼굴 처리 신경 모델이다. 핵심 체계(core system)에는 얼굴에 비교적 특화된 영역(후두면/방추면/STS)이 포함되고, 확장 체계(extended system)에는 감정(편도체), 언어(전두엽), 행동 의도 등 일반 인지 기제와 연결된 영역들이 포함된다. 얼굴 처리가 단일 영역이 아닌 분산된 신경 네트워크에 의존함을 보여준다.
e model of Haxby et al. (2000) presents a neuroanatomically inspired model of face per ception that contrasts with the purely cognitive account offered by Bruce and Young (1986). In their model, Haxby et al. (2000) consider the core regions involved in face perception to lie in the fusiform
gyrus in humans (corresponding to the inferotemporal cortex iden ti fied in primates) and the superior temporal sulcus. e so-called fusi form face area (FFA) is assumed to be involved in recognizing familiar faces. e superior temporal sulcus (STS) is assumed to process dynamic aspect of faces (su as expression, and lip and gaze movements) that is common to familiar and unfamiliar faces alike. ey also identify an “extended system” to denote other areas of the brain that receive inputs from the core face perception system but are not essential for face perception (e.g. regions support ing semantic knowledge of people).
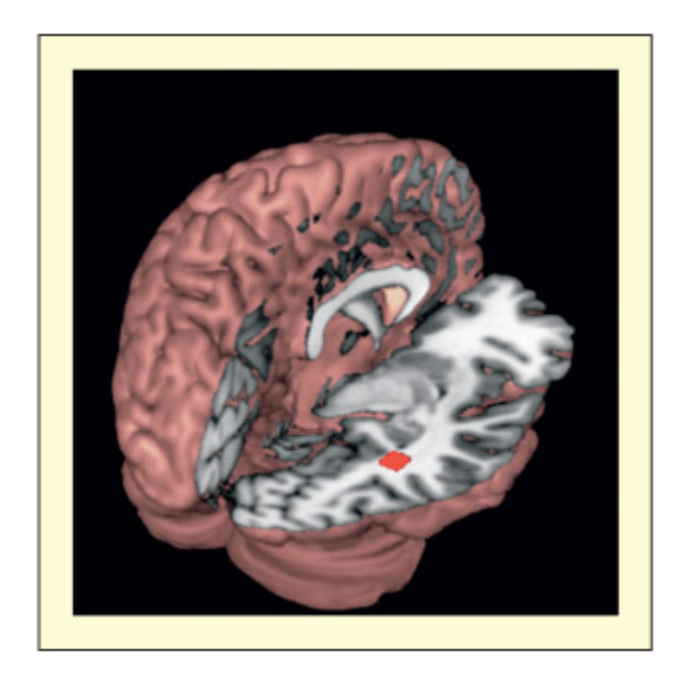
Approximate location of the fusiform face area in the right hemisphere, viewed from the ba.
📊 그림 설명
**방추상 얼굴 영역(FFA)**의 우반구 내 대략적 위치를 뇌 후방에서 본 그림이다. FFA는 측두엽 하면의 방추이랑(fusiform gyrus)에 위치하며, 얼굴에 대해 다른 자극보다 유의미하게 강한 반응을 보인다. 우반구에서 더 강한 반응이 관찰되며, 도메인 특이성(domain-specificity)의 강력한 후보 영역이다.
Evidence that faces are special
Summary
얼굴이 특별하다는 근거는 두 가지이다: (1) 고유한 뇌 영역(FFA)의 존재, (2) prosopagnosia에서 얼굴 인식만 선택적으로 손상되는 현상. 이는 얼굴이 일반 물체와 다른 도메인 특화 처리를 받을 수 있음을 시사한다.
e Bruce and Young (1986) model has a number of similarities with models of object recognition, including distinctions between “apperceptive” and “associa tive” stages, and distinctions between view-independent and viewdependent codes. However, in other respects faces may differ from other objects. Broadly speaking, two lines of evidence have been presented to ba
up the claim. First, that faces have a distinct neural substrate; second (and related to the first), that faces can thus be selectively impaired.
Key Terms
Prosopagnosia
Impairments of face processing that do not reflect difficulties in early visual analysis (also used to refer to an inability to recognize previously familiar faces).
Prosopagnosia는 초기 시각 분석은 정상이나 익숙한 얼굴을 인식하지 못하는 장애이다. De Renzi(1986)의 환자는 아내의 얼굴을 알아보지 못했으나 목소리로는 인식할 수 있었다.
Categorical perception
The tendency to perceive ambiguous or hybrid stimuli as either one thing or the other (rather than as both simultaneously or as a blend).
Categorical perception은 모호한 자극을 한쪽으로만 인식하는 경향이다. FFA는 초기 후두 영역과 달리 범주적 인식을 보인다.
Impairments of face processing that do not reflect difficulties in early visual analysis are termed prosopagnosia (Bodamer, 1947). e term prosopagnosia is also sometimes used specifically to refer to an inability to recognize previously familiar faces. As su, care must be taken to describe the putative cognitive meanism that is impaired rather than relying on simple labeling. e case study reported by De Renzi (1986) had profound difficulties in recognizing the faces of people close to him, including his family, but could recognize them by their voices or other non-facial information. He once remarked to his wife: “Are you [wife’s name]? I guess you are my wife because there are no other women at home, but I want to be reassured.” In contrast, the patient could perform perceptual mating tests involving faces normally. Within the Bruce and Young (1986) model,
his deficit would be located at the face recognition unit stage. e patient’s ability to recognize and name other objects was spared.
e FFA responds to faces more than other stimuli, including bodies, and may be particularly important for recognizing known faces (Kanwisher et al., 1997; Kanwisher & Yovel, 2006). It is for this reason that Kanwisher and colleagues have suggested that this is a strong candidate for domainspecificity (i.e. contains neurons that process only one particular kind of information). e FFA is found bilaterally, with a generally more robust response on the right. e region shows fMRI adaptation (reduced BOLD signal on repeated presentations) when the same face is repeated even if physical aspects of the image anges (see Kanwisher & Yovel, 2006). Unlike earlier regions in the occipital gyrus, that also demonstrate some face specificity, the FFA demonstrates categorical perception. Categorical perception refers to the tendency to perceive ambiguous or hybrid stimuli as either one thing or the other (rather than as both simultaneously or as a blend). Rotshtein et al. (2005) studied this using morphed images of Margaret ater and Marilyn Monroe in an fMRI adaptation study. Physical differences in the image only affect fMRI adaptation when the participants’ percept of the ambiguous face flips between ater and Monroe.
Why are faces special?
Summary
얼굴이 특별한 이유에 대해 네 가지 설명이 제시된다: (1) 작업 난이도, (2) 전체적(holistic) 처리, (3) 범주 내 전문성(visual expertise), (4) 고유 범주(distinct category). 이들은 상호 배타적이지 않으며 다중 요인이 복합적으로 기여할 수 있다.
is section considers four accounts of why faces might be special. ese accounts are not necessarily mutually exclusive and there might be several factors that contribute.
Task difficulty
Summary
작업 난이도만으로는 얼굴의 특수성을 설명할 수 없다. Farah 등(1995a)은 안경 프레임 인식과 얼굴 인식의 난이도를 통제한 실험에서, prosopagnosia 환자 LH가 얼굴만 선택적으로 저하(62% vs 92%)됨을 보여 난이도 설명을 기각했다.
Faces are complex visual stimuli that are very similar to ea other (e.g. they all consist of mouth, nose, eyes, etc.), so are faces special simply by virtue of added task difficulty relative to other kinds of objects? A number of reports
of patients with visual agnosia without prosopagnosia would appear to speak against this view (Rumiati et al., 1994). Farah et al. (1995a) aempted to address the issue of task difficulty directly by creating an object recognition task (using spectacle frames) of comparable difficulty to a face recognition task in controls (both tasks performed at 85 percent correct). ey found that their prosopagnosic participant, LH, was impaired on the face task (62 percent), but not the frames task (92 percent), ruling out a taskdifficulty explanation.
Part-based compared with holistic perceptual processing
Summary
**Farah(1990)**는 물체 인식이 부분 기반-전체 기반 연속체에 위치한다고 제안하며, 얼굴은 holistic, 문자는 part-based 처리에 의존한다고 주장했다. 그러나 이후 단일 물체 무명증, prosopagnosia+alexia 등 다양한 분리 사례가 보고되어 별도의 구조적 지식 저장소 존재 가능성이 제기되었다. 얼굴 선택적 영역은 전체 얼굴과 부분 모두에 반응한다.
Perhaps faces are treated differently from other types of object because they require a special type of processing, rather than being special because they are faces as su. e most influential theory along these lines has been proposed by Farah (1990; Farah et al., 1998). Her thesis is that all object recognition lies on a continuum between recognition by parts and recognition by wholes. Recognition of faces may depend more on holistic processing, whereas recognition of wrien words may depend on more partbased processing (e.g. identifying the sequence of leers in the word); recognition of most other objects lies somewhere in between. Farah’s initial source of evidence came from a meta-analysis of cases with visual agnosia, prosopagnosia, and difficulties in visual word recognition (pure alexia; see Chapter 12). She found no convincing cases of isolated object agnosia (without prosopagnosia or alexia) or prosopagnosia with alexia (without object agnosia), supporting the claim that these lie on a continuum (Farah, 1990).
Subsequent to this, there have been reported cases of isolated object agnosia without prosopagnosia or alexia (Humphreys & Rumiati, 1998; Rumiati et al., 1994), isolated object agnosia and alexia without prosopagnosia (Moscovit et al., 1997), and prosopagnosia and alexia without object agnosia (De Renzi & di Pellegrino, 1998). ese cases support an alternative view in whi there are separate stores of structural
descriptions for objects, faces, and words rather than a continuum between two types of underlying perceptual processes (but see Farah, 1997).
Evidence from human fMRI (Harris & Aguirre, 2008) and monkey electrophysiology (Freiwald et al., 2009) suggests that face-selective regions of the cortex respond to both whole faces and face parts.
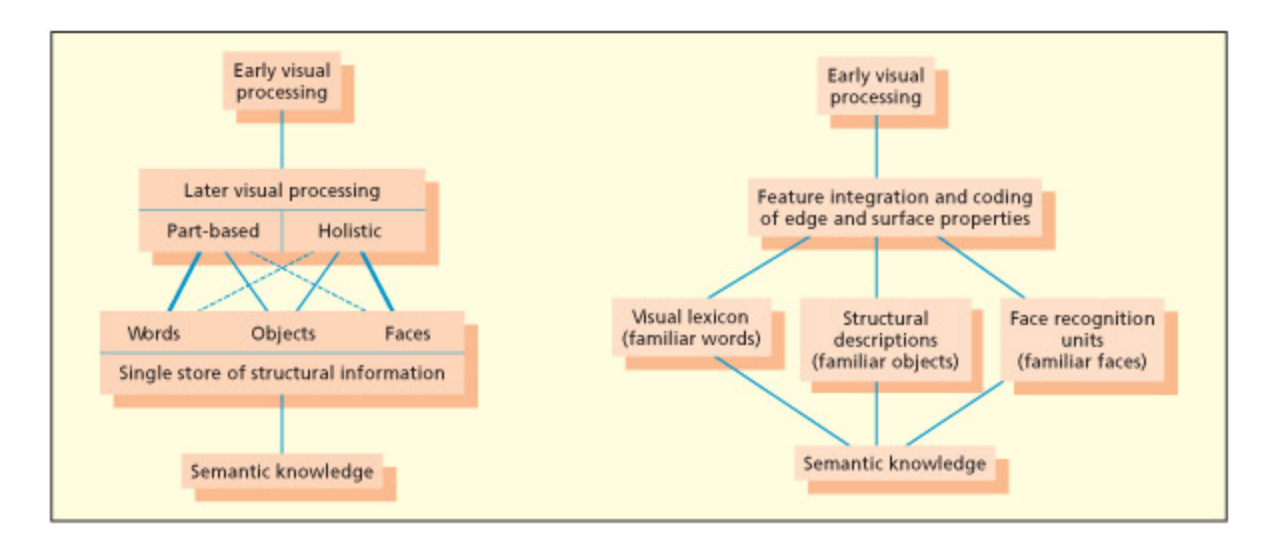
In Farah’s model, differences between recognition of words, objects, and faces reflects different weightings of part-based versus holistic perception (le). Other models have suggested, on the basis of dissociations between object agnosia, prosopagnosia, and alexia, that there may be separate stores of structural knowledge for these categories (right).
📊 그림 설명
Farah의 연속체 모델(좌)과 별도 저장소 모델(우)을 비교한다. Farah 모델에서는 단어(part-based) ↔ 물체 ↔ 얼굴(holistic)이 하나의 연속체 위에 위치한다. 대안 모델에서는 물체 실인증, prosopagnosia, 순수 실독증 간의 삼중 해리에 근거하여, 단어·물체·얼굴 각각에 대한 독립적 구조 지식 저장소가 존재한다고 제안한다.
Visual expertise at within-category discrimination
Summary
Gauthier 등은 얼굴이 범주 내 세밀한 구분(within-category discrimination) 요구로 인해 특별하다고 주장한다. Greebles(인공 물체) 훈련에서 참가자들이 전문가가 되면 holistic 처리로 전환되고, FFA 활성화와 N170 ERP 신호가 나타났다. 이는 얼굴의 특수성이 도메인 자체가 아닌 학습된 전문성의 결과일 수 있음을 시사한다.
A somewhat different account from that of Farah has been put forward principally by Gauthier and colleagues (Diamond & Carey, 1986; Gauthier & Logothetis, 2000; Gauthier & Tarr, 1997; Gauthier et al., 1999). eir account has two key elements: (1) that faces require discrimination within a category (between one face and another), whereas most other object recognition requires a superordinate level of discrimination (e.g. between a cup and comb); and, consequently, that (2) we become “visual experts” at making these fine within-category distinctions through prolonged experience with thousands of exemplars. Like Farah’s explanation, this account assumes that
faces are special because of processing demands rather than because faces are a domain-specific category.
e evidence for this theory comes from training participants to become visual experts at making within-category discriminations of non-face objects, called “Greebles.” As participants become experts they move from part-based to holistic processing, as has oen been proposed for faces (Gauthier & Tarr, 1997). In addition, they have shown that Greeble experts activate the FFA (Gauthier et al., 1999), and similar findings have been reported for experts on natural categories su as cars (McGugin et al., 2012). In addition, Greeble recognition has a aracteristic N170 ERP signal normally only found for faces (Rossion et al., 2002). Gauthier and Logothetis (2000) reported similar training studies in monkeys and found that certain cells (claimed to be analogous to face cells) became sensitive to the whole configuration aer training even though non-facial stimuli were used.
Faces are a distinct category
Summary
얼굴이 고유한 범주라는 근거로 prosopagnosia 환자 RM이 5,000대의 미니카를 구분하면서 얼굴은 인식하지 못한 사례가 있다. 반면 환자 WJ는 얼굴을 구분하지 못하면서 36마리 양을 구분하여 논쟁이 계속된다. 전문성과 처리 방식의 차이로는 완전히 설명되지 않으며, 얼굴이 별도의 구조적 지식 저장소를 가질 가능성이 남아 있다.
Examples of “Greebles.” Greebles can be grouped into two genders and come from various families. To what extent does discriminating against Greebles resemble discriminating against faces? Images provided courtesy of Miael J. Tarr (Carnegie Mellon University, Pisburgh), see www.tarrlab.org.
📊 그림 설명
Greebles는 Gauthier 등이 고안한 인공 물체로, 두 가지 성별과 여러 가족으로 분류된다. 참가자들이 Greeble 구별에 전문가가 되면 holistic 처리로 전환되고 FFA 활성화가 나타나, 얼굴의 특수성이 도메인 자체가 아닌 학습된 범주 내 전문성의 결과일 수 있음을 시사한다.
Although it might indeed be the case that faces make different processing demands on certain perceptual meanisms relative to other classes of
stimuli, there is some evidence to suggest that these accounts are not sufficient to explain the whole picture. Some have argued that what is additionally required is the assumption that faces really are a distinct category and are represented as su in the adult brain. For example, there is evidence of dissociations between faces and other expert categories from ERP studies (Carmel & Bentin, 2002) and human neuropsyology (McNeil & Warrington, 1993; Sergent & Signoret, 1992). Sergent and Signoret (1992) reported a prosopagnosic patient, RM, who had a collection of over 5,000 miniature cars. He was unable to identify any of 300 famous faces, or the face of himself or his wife, or mat unfamiliar faces across viewpoints. Nevertheless, when shown 210 pictures of miniature cars he was able to give the company name, and for 172 he could give the model and approximate year of manufacture. us, although the FFA may tend to represent withincategory exemplars (Gauthier et al., 2000), there could still be scope for finer-grained categorical dissociations. McNeil and Warrington (1993) reported patient WJ, who was unable to distinguish previously familiar faces from unfamiliar ones. Following his stroke, he acquired a flo of 36 sheep, whi testing revealed that he could distinguish from unfamiliar sheep. is case was taken to support the view that faces are a special category independent of the type of perceptual processing, but skeptics may argue that the sheep recognition task could be performed in different ways (e.g. recognizing markings rather than holistic configuration) or that the level of expertise is not mated (e.g. 36 sheep versus many thousands of faces).
Evaluation
ere is good evidence to suggest that face recognition can be spared or impaired relative to the recognition of other objects. To account for this, it might be necessary to assume that faces engage different types of perceptual meanism related to holistic versus part-based processing and might require expert within-category discriminations. Whereas these accounts might be necessary to explain the data, they might not be sufficient. ere
remains some evidence to suggest that there is indeed a separate store of structural descriptions for familiar faces.
The Margaret Thatcher Illusion
Summary
Thatcher illusion은 뒤집힌 얼굴에서 눈/입의 이상을 감지하기 어려운 현상으로, 얼굴이 정립 방향으로 저장되고 holistic 처리에 의존함을 보여준다. Prosopagnosia 환자 LH는 정립/도립 간 차이가 없어 이 정보가 손실되었음을 시사하며, 유아도 태생부터 top-heavy 얼굴 구성을 선호한다.

You should recognize this face instantly even if it is upside down. But what is wrong with the image? Turn it the right way up to find out.
From ompson, 1980. © Pion Limited, London. Reproduced with permission.
📊 그림 설명
Thatcher illusion(마가렛 대처 착시)을 보여준다. 뒤집힌 상태에서는 얼굴이 정상으로 보이지만, 정립시키면 눈과 입이 반전되어 기괴하게 보인다. 이는 얼굴이 정립 방향으로 holistic 처리되며, 도립 시에는 부분 간 관계의 이상을 감지하기 어려움을 보여주는 대표적 시연이다.
What is wrong with this face? Turn it upside down and have a look. In the so-called ater illusion the holistic configuration of the face, in its inverted orientation, disrupts the ability to detect local anomalies in the stimulus su as an inversion of the eyes and mouth (ompson, 1980). e success of the illusion is based on two properties of the face recognition system. First, that faces usually have an upright orientation and may be stored in the brain as su. is explains why the anomaly is detected upon inversion. Second, that faces are processed largely on the basis of surface features and global shape rather than piecemeal from parts.
For most adults, inverted faces are mu harder to identify (Yin, 1969). But, prosopagnosic patients su as LH may show no advantage of upright over inverted faces, suggesting this information is lost (Farah et al., 1995b). Greeble experts tend to show an advantage for processing upright Greebles (Gauthier & Tarr, 1997). Infants show a
preference for a “top heavy” configuration of facial features from birth but, beyond that, do not have a strong preference for how the parts themselves are oriented (Maci Cassia et al., 2004).
Vision Imagined
Summary
시각 심상(visual imagery)은 실제 시각 인식과 유사한 신경 기전을 공유하며, prosopagnosia 환자는 얼굴 상상도 어렵고, 색상 인식 손상 환자는 색상 심상도 손상된다. 그러나 환자 CK는 물체를 시각적으로 인식하지 못하면서도 기억에서 상세히 그릴 수 있어 top-down 경로를 통한 심상 생성이 가능함을 보여준다. Kosslyn 등은 TMS로 V1을 억제하면 선 크기 심상이 방해됨을 보였으나, 얼굴이나 색상 심상은 상위 시각 영역에 더 의존하여, 심상의 신경 기반은 내용에 따라 달라진다.
Close your eyes and imagine a horse galloping le-to-right through a green field and jumping over a fence. To what extent is this “visual imagery” task aieved by using the same meanisms used to visually perceive objects, color, movement, and so on? At one extreme, imagining scenes su as these may not use any of the same meanisms as seeing. But why would the brain develop separate meanisms for seeing a horse and imagining the visual appearance of one? At the other extreme, imagining scenes could use exactly the same meanisms as visual perception. is, of course, raises the question of how it is possible to distinguish between perception and imagination at all, and what prevents us from lapsing into hallucinatory delirium. As is oen the case, the truth may lie somewhere between these extreme viewpoints.
A number of case studies have supported the conclusion that difficulties in visual imagery parallel difficulties in visual perception, su that selective impairments of color, objects, space, and so on tend to be found both in perception and in mental imagery. For example, Levine et al. (1985) document two patients. e first patient had both prosopagnosia and aromatopsia. is was accompanied by an inability to imagine previously known faces or the colors of objects. e other patient was impaired in spatial aspects of vision (e.g. poor visually guided reaing—optic ataxia). is was accompanied by difficulties in spatial imagery (e.g. poor descriptions of routes). Beauvois and Saillant (1985) also report a patient who could not imagine colors, given visual imagery strategies (e.g. “imagine a beautiful snowy landscape—what color is the snow?”), but could retrieve
color “facts” from non-perceptual long-term memory (e.g. “what do people say when asked what color snow is?”).
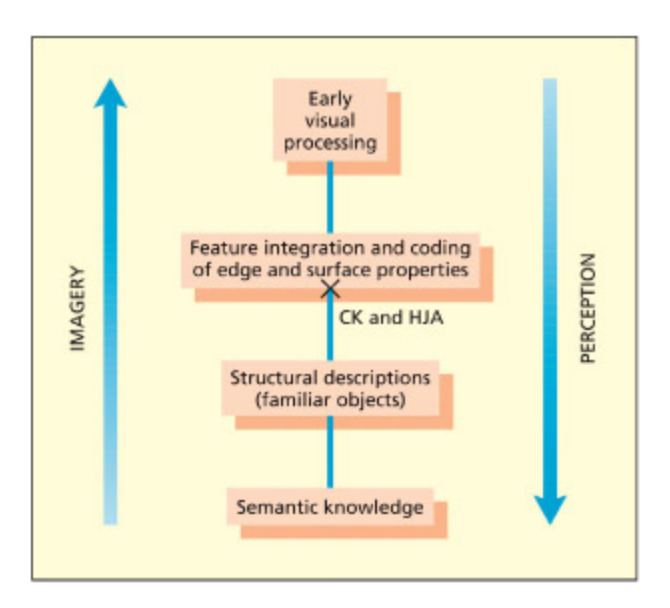
Imagery may involve some of the same structures as perception, but activated in the reverse (“topdown”) direction. CK and HJA can use intact knowledge of object structure to perform the imagery task despite poor perceptual integration. But does imagery need to go ba as far as early visual processing in V1?
📊 그림 설명
시각 심상(imagery)과 시각 인식(perception)의 신경 경로 비교 도식이다. 인식은 bottom-up(V1→고위 영역)으로 진행되는 반면, 심상은 top-down(고위 영역→V1) 방향으로 동일한 구조를 역방향 활성화한다. 환자 CK와 HJA는 지각 통합이 손상되었음에도 기억의 구조 지식을 통해 심상 과제를 수행할 수 있었다.
In contrast to these studies showing close imagery–perception parallels, Behrmann et al. (1994) report a study of patient CK that suggests that visual imagery and visual perception can be dissociated. CK was unable to recognize or name objects from vision, although he could recognize them by other means (e.g. tou), and a number of studies suggested that, like HJA, he had integrative agnosia. In contrast to his poor object recognition he could produce detailed drawings of objects from memory and describe the visual appearance of objects. is imagery– perception dissociation can be accounted for by assuming that CK has access to object structural descriptions top-down (i.e. from mem ory) but not boom-up (i.e. from visual percep tion). Similar findings were initially reported for HJA (Humphreys & Riddo, 1987). However, a subsequent study on HJA some 16 years later suggests that caution is warranted in postulating a strong separation of vision and imagery (Riddo et al., 1999). Although HJA could
initially draw accurately from memory, this ability receded over time (but his memory, in general, remained intact). Presumably, visual input is needed to maintain the structural descriptions over longer periods of time.
e studies above suggest that visual imagery for properties su as color and object shape is normally related to the ability to perceive those aracteristics, although the two may occasionally be disconnected. A more controversial claim that has been made about mental imagery is that the primary visual cortex (V1) is necessary for it (Kosslyn et al., 1995; 1999; 2001). Kosslyn et al. (1995) compared an imagery condition of visualizing objects of different sizes relative to a non-imagery baseline. ey found that there was activity in V1 and, moreover, that the locus of activity was related to the size of the imagined stimulus. (Recall that V1 is retinotopically organized so that images that cover a large area on the retina will cover a large area on V1.) To establish the functional necessity of V1 for imagery, Kosslyn et al. (1999) conducted a TMS study on participants who were making imagery judgments about a previously learned array of line gratings (e.g. parallel lines of different width, length, and orientation). ey found that TMS over V1 did indeed disrupt mental imagery.
How is it possible to reconcile the finding of Kosslyn and colleagues, suggesting that early perceptual processes are important for imagery, with other studies suggesting that later visual processes (e.g. those supporting color or object recognition) are the critical ones? e solution may lie in considering the content of the images. Kosslyn’s experiments involved imagery for lines and retinal size for whi V1 may be important, whereas other studies involved imagery for faces, objects, spatial location and colors, whi are less likely to depend on V1 when activated top-down. us, the extent to whi different perceptual regions are involved in imagery may be related to the different content of what is being imagined.
Summary and Key Points of the Chapter
Summary
V1은 망막 기반 공간 맵으로 엣지/경계를 감지하며, 손상 시 blindsight가 발생한다. V4(색상)와 V5/MT(움직임) 등 고위 영역은 특정 시각 속성에 기능적으로 특화되어 있다. 물체 항상성은 저장된 표상과의 매칭 또는 정신적 회전으로 달성되며, 얼굴 인식은 holistic 처리와 범주 내 개별화 요구로 인해 별도의 신경 자원을 활용한다. 시각 심상은 지각과 유사한 자원을 사용하되, 내용에 따라 관여하는 영역이 달라진다.
- e primary visual cortex (V1) contains a spatial map based on the retinal image and detects edges and boundaries within the visual scene.
- e primary visual cortex may be necessary for conscious awareness of vision. Damage to this area can lead to a condition called blindsight, in whi conscious experiences of vision are abolished, although some visual processing in the “blind” region is still computed by routes that bypass V1.
- Later visual regions are specialized for analyzing particular visual aributes su as color (area V4) and motion (area V5/MT).
- e ability to recognize objects from a wide variety of views (object constancy) may arise from mating visual features to a stored representation of objects or from mentally rotating the seen object to a standard viewpoint. Basic categorical recognition of objects implicates inferotemporal processing, whereas recognizing the orientation may involve the parietal lobes.
- e processing of faces relative to other objects may, to some degree, utilize different neural substrates and cognitive resources. Faces may make more demands on holistic processes, and typically require individuation of particular exemplars. It is also possible that faces are special because they are an evolutionarily salient category.
- Mental imagery utilizes many of the same resources as actually perceiving and, like vision itself, different types of image (e.g. of color, objects, lines) may have different neural substrates.

📊 그림 설명
본 장의 핵심 내용 요약 다이어그램이다. 망막에서 V1까지의 경로, V1 이후의 기능적 특화(V4, V5/MT), ventral/dorsal stream, 물체·얼굴 인식의 신경 기전, 그리고 시각 심상까지 제6장 전체의 주요 개념과 신경 해부학적 구조를 종합적으로 정리한다.
Visit the companion website at www.psypress/cw/ward for:
- References to key papers, readings and useful websites
- Videos including an interview with key psyologists Huber and Wiebel , BBC documentary Brain Story—The Mind’s Eye, a patient’s experience with visual agnosia, and a lecture with author Jamie Ward on The Seeing Brain.
- Multiple oice questions and interactive flashcards to test your knowledge
- Downloadable glossary
Example Essay Questions
Summary
본 장의 에세이 주제들: blindsight와 정상 시각 체계의 관계, V1의 시각 인식 필수 여부, 색상 항상성과 물체 항상성의 신경 기전, 얼굴이 특별한 범주인 이유, 그리고 시각 심상과 시각 인식의 유사점과 차이점.
- What is “blindsight”? What can studying blindsight tell us about the normal visual system?
- To what extent is the primary visual cortex (V1) necessary for visual perception?
- One function of the visual system is to extract constant properties of a stimulus independently from moment-tomoment fluctuations in viewing conditions. Explain how the brain aieves this, using the examples of color constancy and object constancy.
- Are faces “special”? If so, why?
- To what extent is visually imagining like visually perceiving?
Recommended Further Reading
Summary
추천 도서: Farah(2000)는 시각 인지 신경과학 전반을, Peterson & Rhodes(2003)는 얼굴/물체/장면의 분석적·전체적 처리를, Zeki(1993)는 단일세포 데이터와 초기 시각 처리를 중심으로 시각 신경과학을 다룬다.
- Farah, M. J. (2000). The cognitive neuroscience of vision. Oxford, UK: Blawell. is book provides excellent coverage of most topics covered in this apter and a few vision-related topics covered elsewhere (e.g. space and aention; visual word recognition).
- Peterson, M. A. & Rhodes, G. (2003). Perception of faces, objects and scenes: Analytic and holistic processes. Oxford, UK: Oxford University Press. An up-to-date collection of papers that will be of interest to students wanting to pursue more advanced reading.
- Zeki, S. (1993). A vision of the brain. Oxford, UK: Blawell. is is a thorough account of the neuroscience of vision from an historical and contemporary perspective. It is particularly strong on single-cell data and early stages of visual processing.