Summary
NLP를 포함한 전 영역에 걸쳐 현재 AI 학습은 크게 2 step으로 구분되는 데,
- Step 1. Pre-train
- large corpus를 활용해서 language modeling task를 잘 수행할 수 있는 범용 모델이 되도록 학습시킨다
- 워낙 방대하게 학습시키다 보니, 요즘은 emergent behavior라 해서, 별도의 downstream-task를 위한 fine-tune 없이도 대부분의 task에서 우수한 성능을 보여주기도 한다.
- Step 2. Fine-tuning
- 특정 downstream task를 잘 수행하도록 추가적으로 파라미터가 미세하게 조정되도록 학습시키는 과정.
- 일반적으로 domain-specific한 data가 많지 않거나, pre-train만으로는 부족한 성능이 아쉬울 때 하는 방법
Pretraining Decoder
Summary
Language modeling task가 이 decoder의 목표 중 하나.
대부분 auto-regressive하고,
때문에 context 넣어줄 때, timestamp를 고려해서 넣어준다.
→ masked attention해당하는 모델들로는
- GPT, LaMDA
auto-regressive 구조니, 주로
- Dialogue, Summarization
같은 task에 강하다.
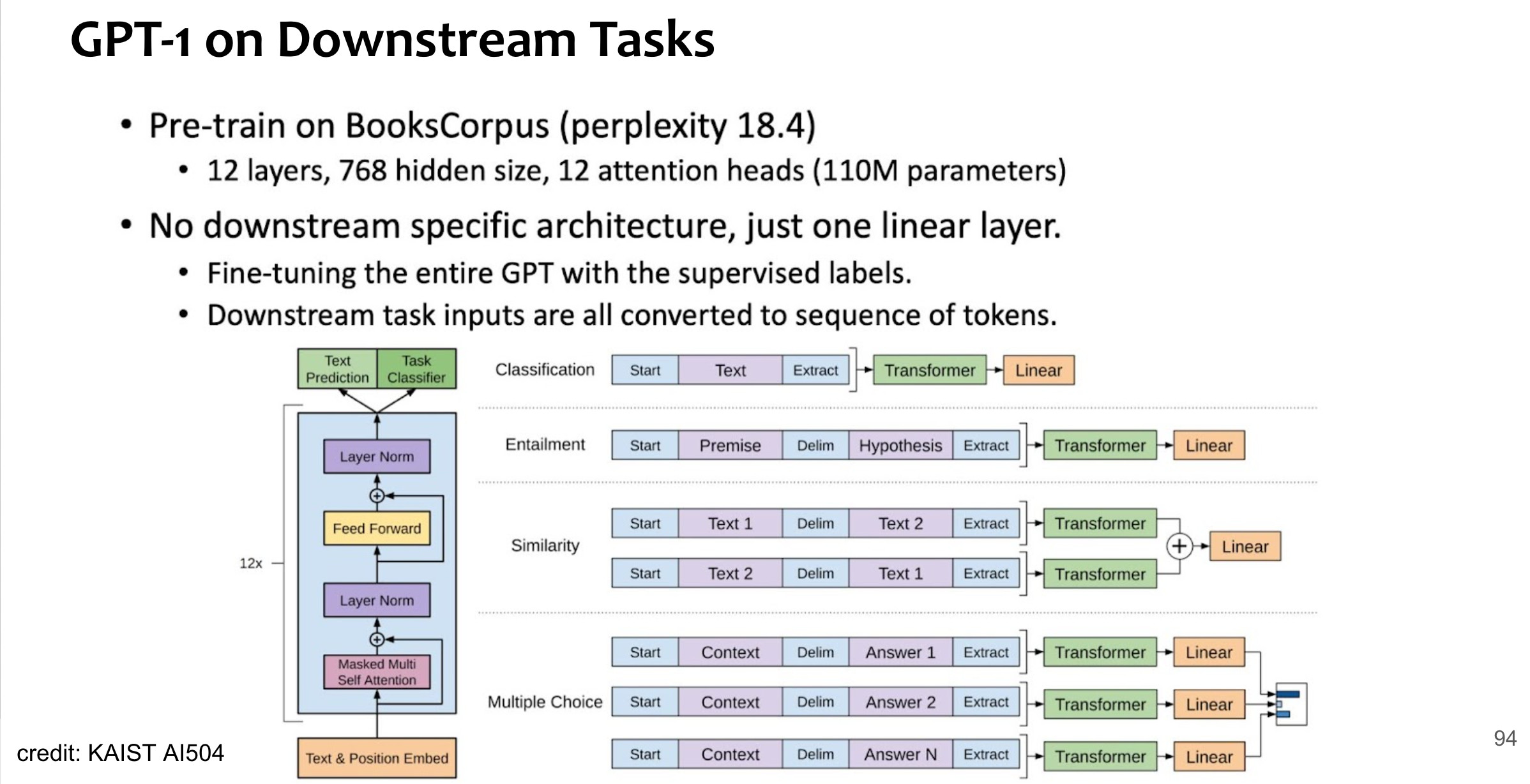
GPT1 in transformer block
NOTE
GPT(Generative Pretrained Tranformer)는 Decoder part만 사용하고,
encoder 부분은 사용하지 않으니, decoder 부분의 encoder-decoder attention 부분이 동작하는 block은 GPT1에서 사용되지 않음.
NOTE
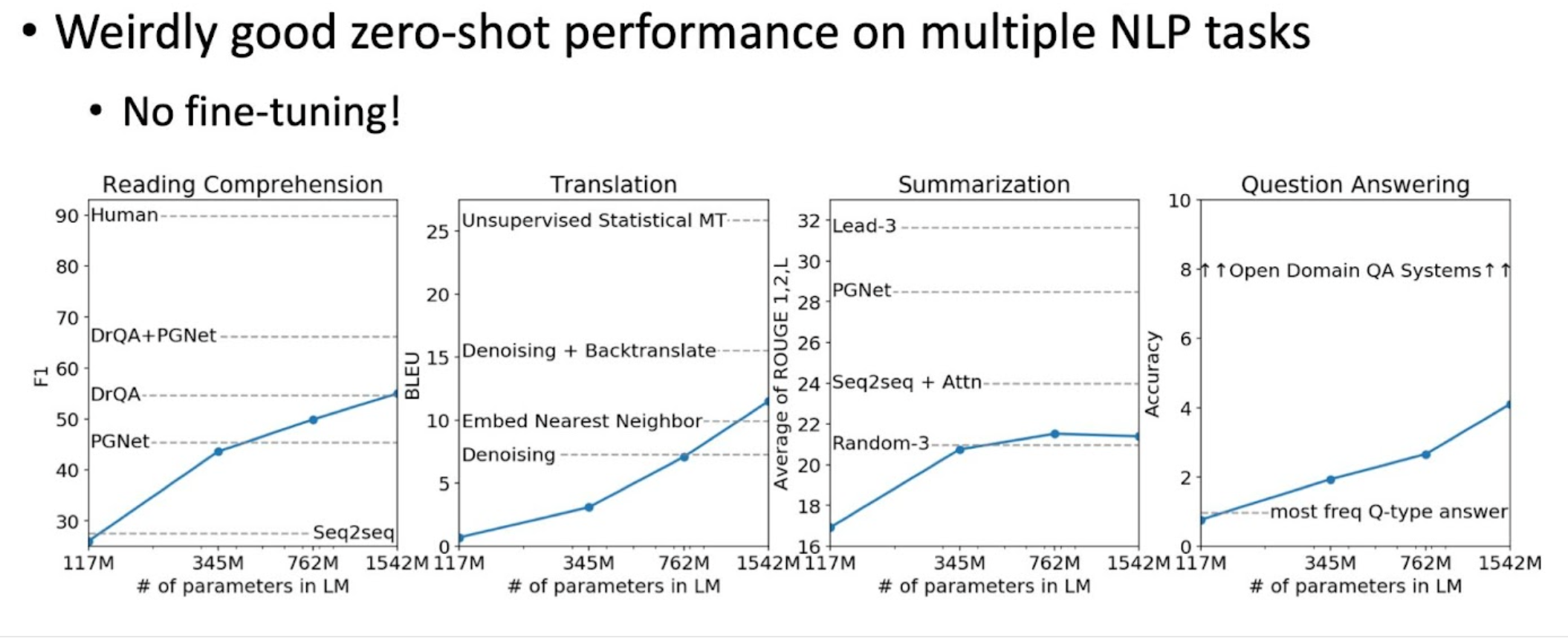
GPT2
NOTE
GPT1 대비 커지기만,,
여기서부터 본격적으로 down-stream task에도 pretrain 만으로도 꽤 괜찮은 성능을 내는 것을 관찰.

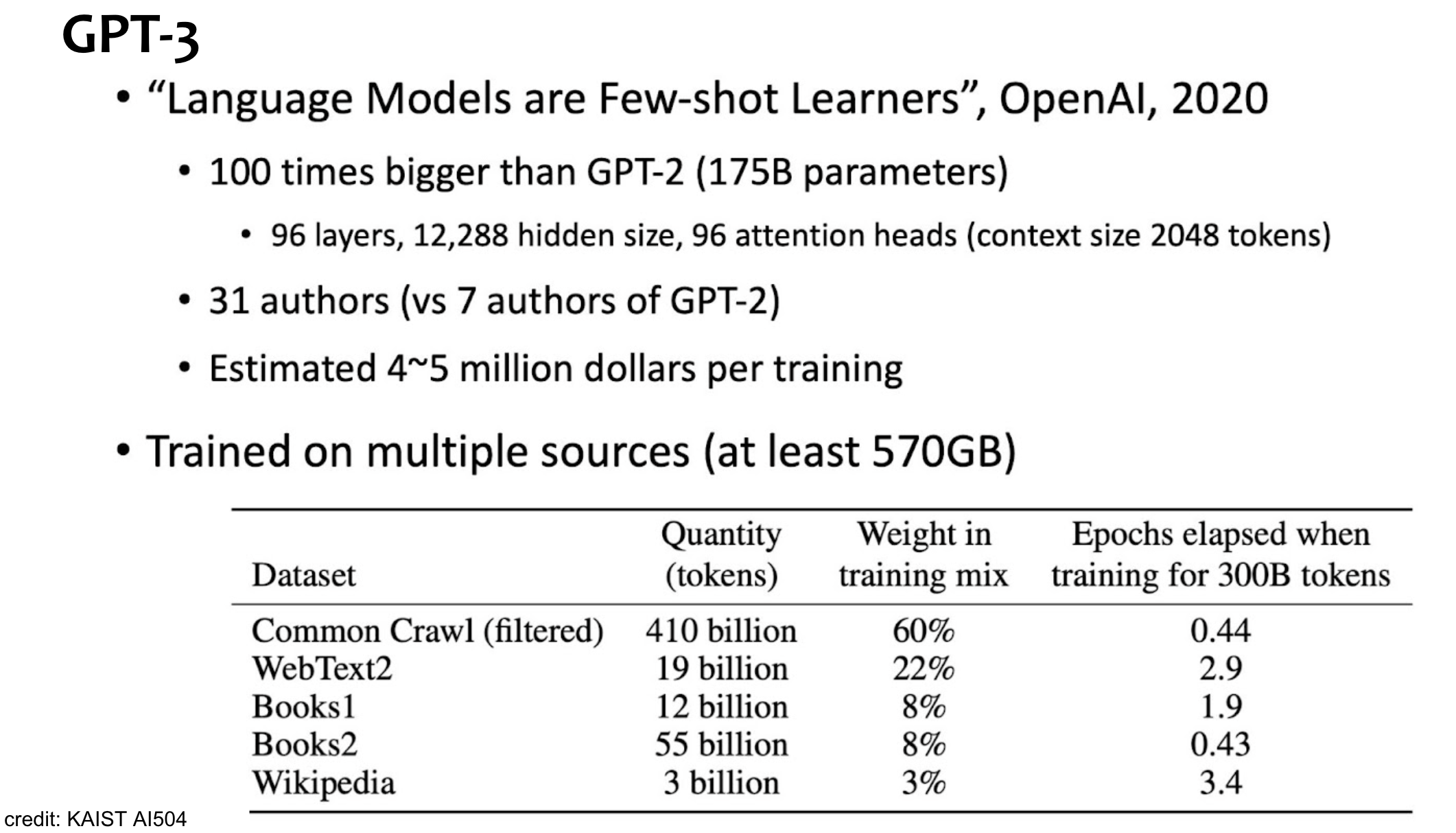
GPT3
Summary
GPT2 대비 100배 커짐.
학습 셋도 더 많고 다양해짐.
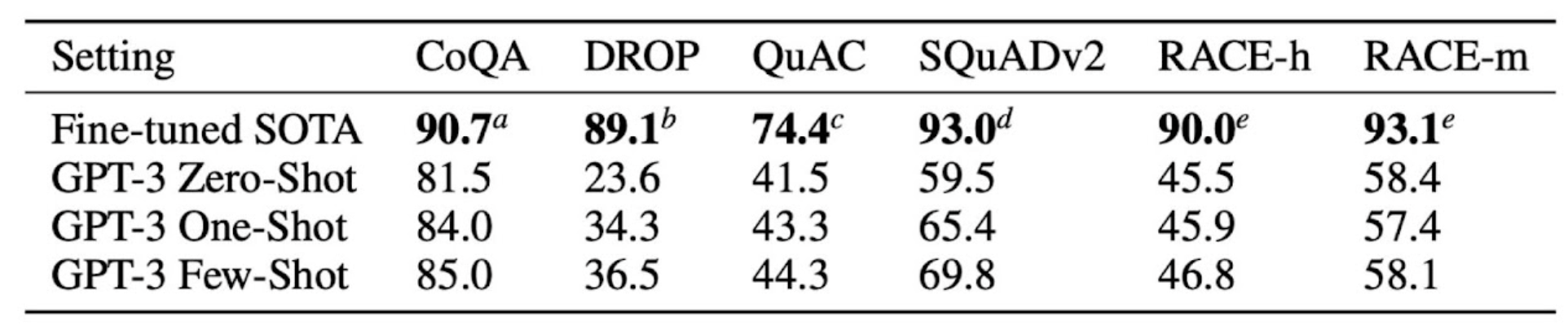
Incontext-Learning
Note
Gradient Descent(GD) 같은 직접적인 파라미터 업데이트 없이도, 모델이 커지니까, context안에서 뭔가 학습하는 것 같은 게 포착됨.
→ prompt 를 어떻게 넣느냐가 중요해짐. → prompt-engineeringN shot learning


Examples of Downstream Tasks
- QA(Question Answering)
- Translation
- Machine Reading Comprehension
Pretraining Encoder
Summary
language modeling처럼 생성하는 게 주 목적이 아닌, 보통 “언어의 이해”를 주 목적으로 한다.
때문에 Bi-directional 하게 input을 넣어주고, attention 역시 mask 처리할 필요가 없다.대표적 모델들로는,
- BERT와
- 그 varaiant들인 RoBERTa, AlBERT 등등..
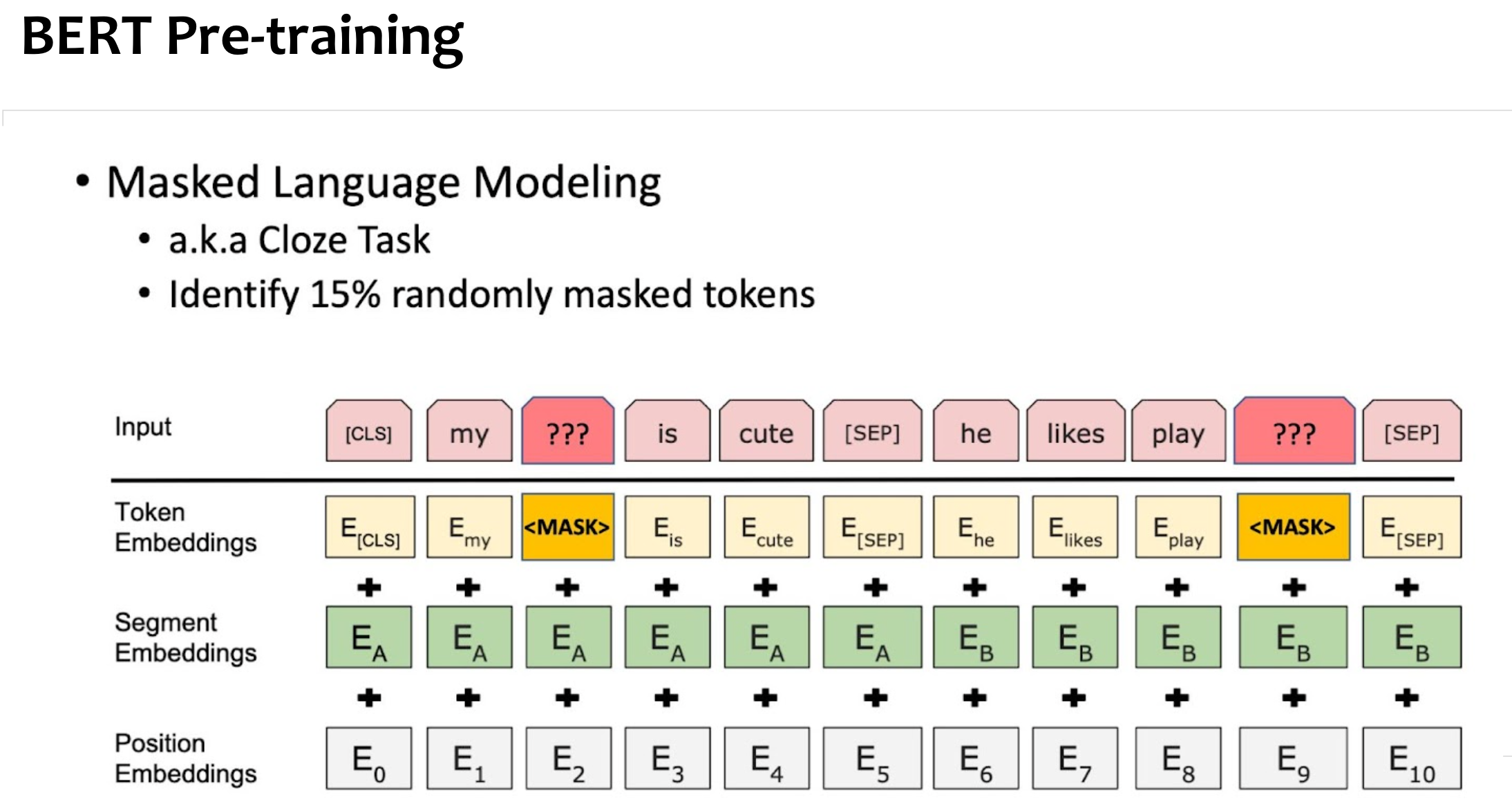
Masked LM(Language Modeling)
NOTE
BERT 계열 모델들 학습시키는 main-task 중 하나로, 문장 중 일부를 masking 처리한 후 그 부분을 모델이 예측하게 만드는 task.
In BERT paper..:
- 15%의 random token을 선택하고,
- 이중 80% 위치에는 mask token을 대체시키고
- 10%는 random token
- 10%는 그대로 둔다.
- →이를 80:10:10 이라고 한다.
BERT pre-train vs fine-tune
NOTE
- 돌아가는 건 똑같고, 구제척인 task만 다르다.
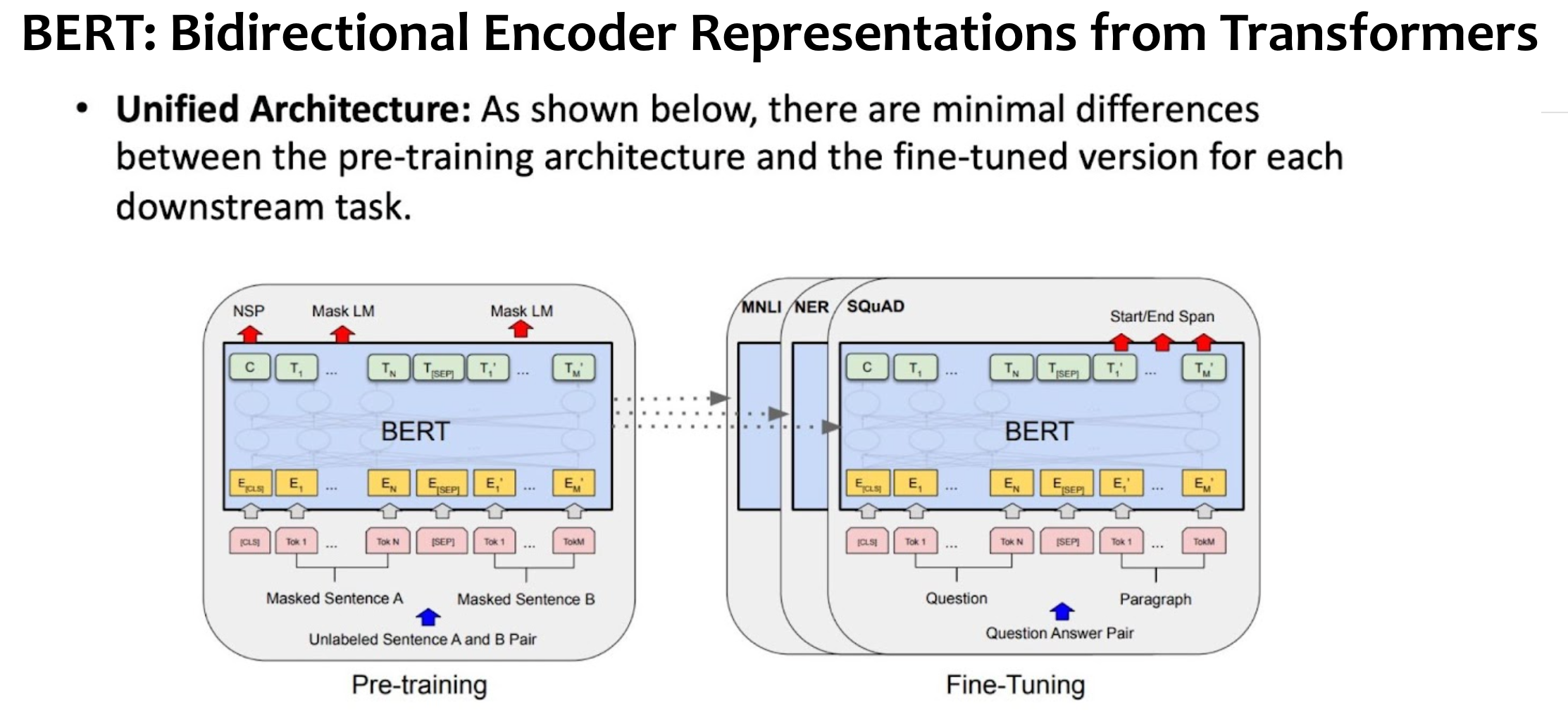
BERT
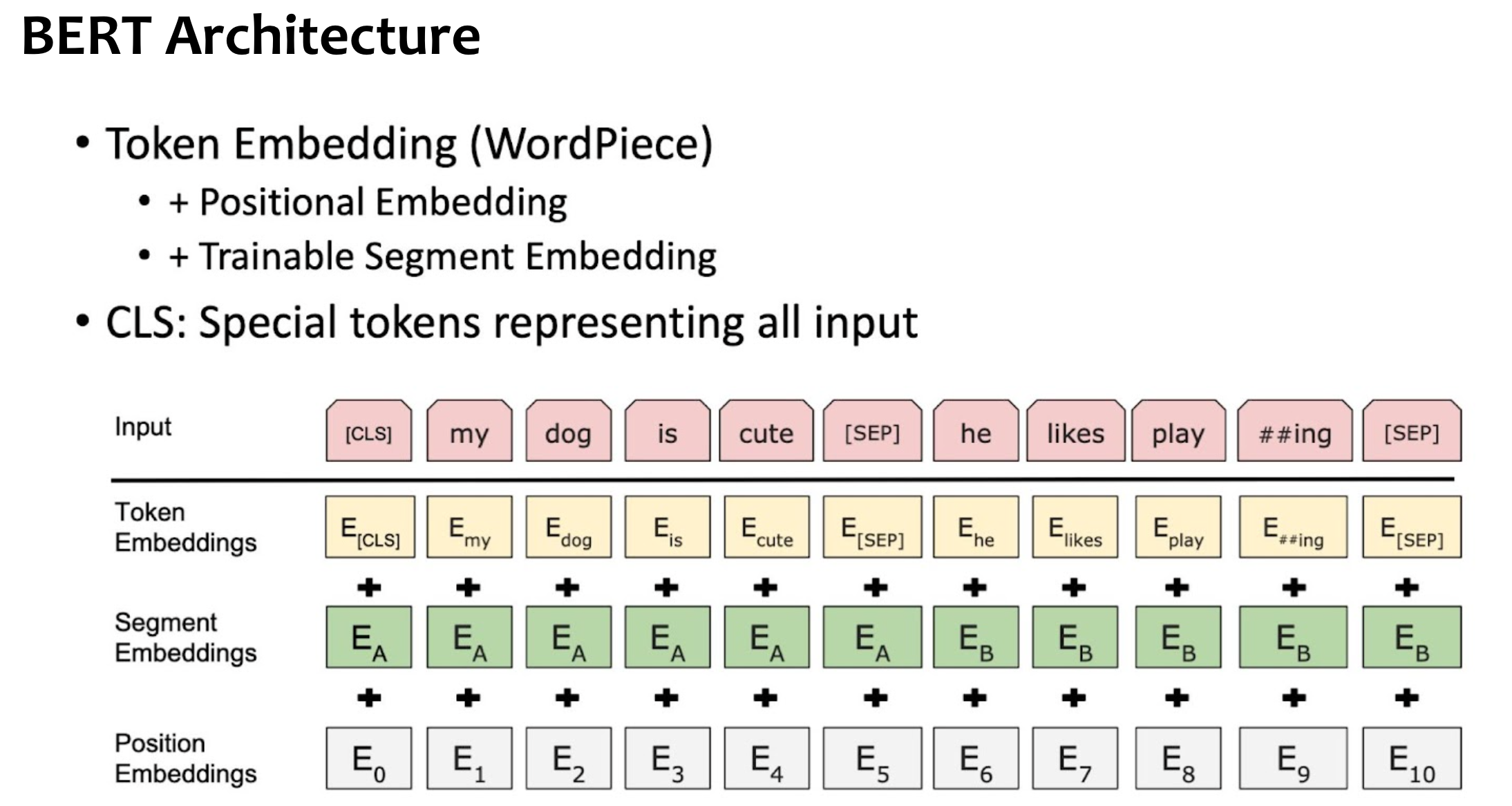
Summary
MLM(Masked Language Modeling)
Summary
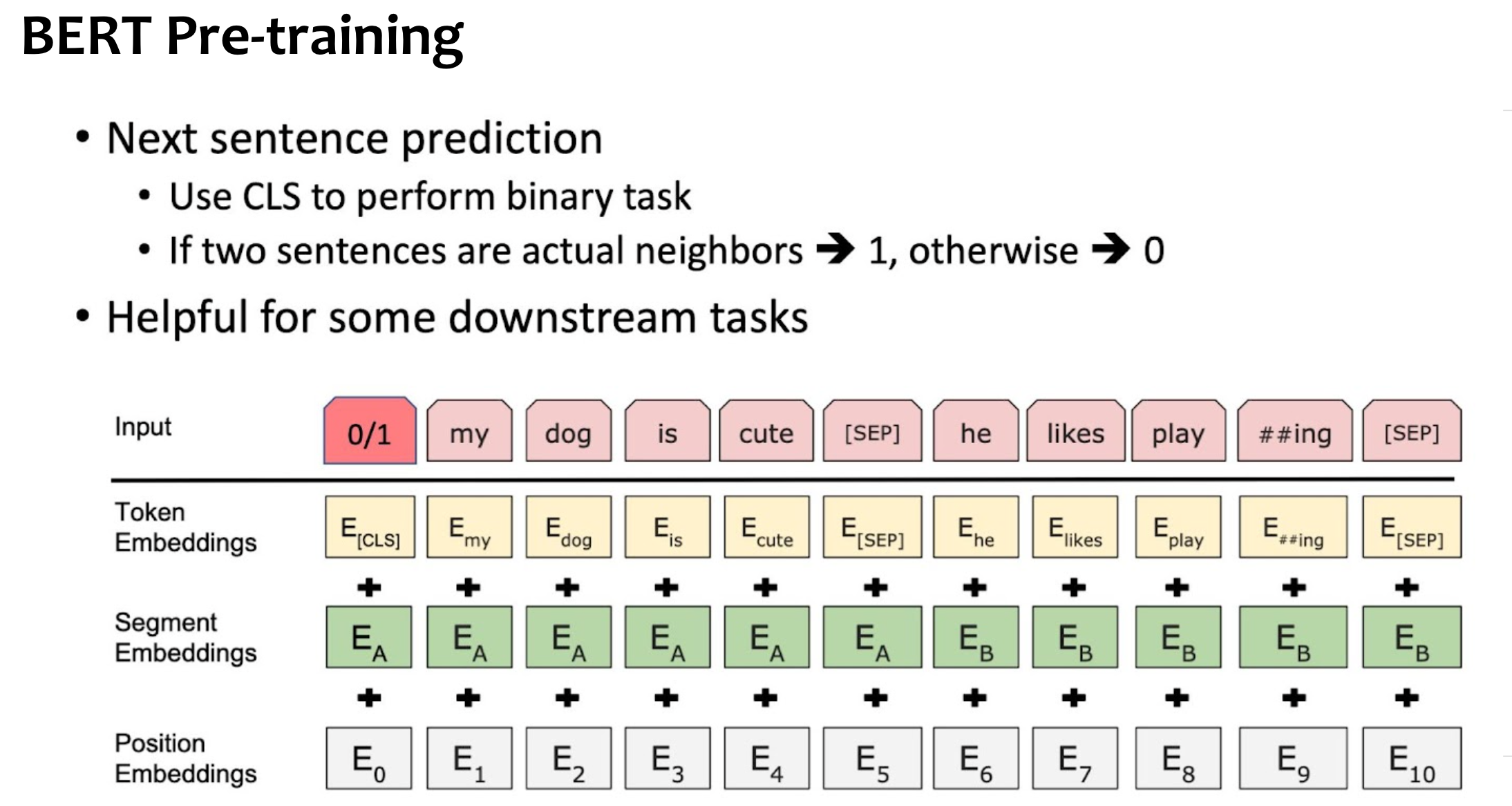
NSP(Next Sentence Prediction)
Summary
- 문장 단위 관계 예측.
- BERT에는 쓰였으나, 파생 모델들인 RoBERTa 등에서는 효용성이 크지 않다고 판단되어 하지 않기도.
Downstream Task
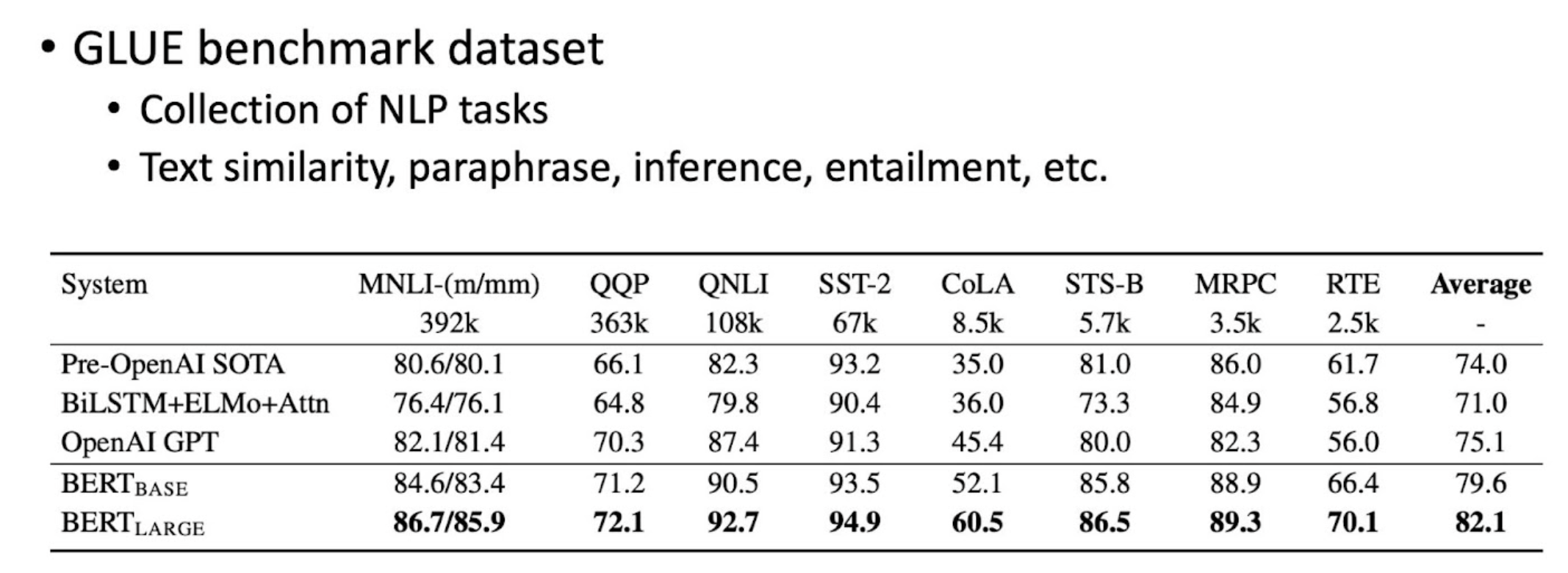
GLUE
- collection of NLP task
SQuAD

