Summary
모델에 넣기 직전까지 데이터를 construction.
Structed vs Unstructed
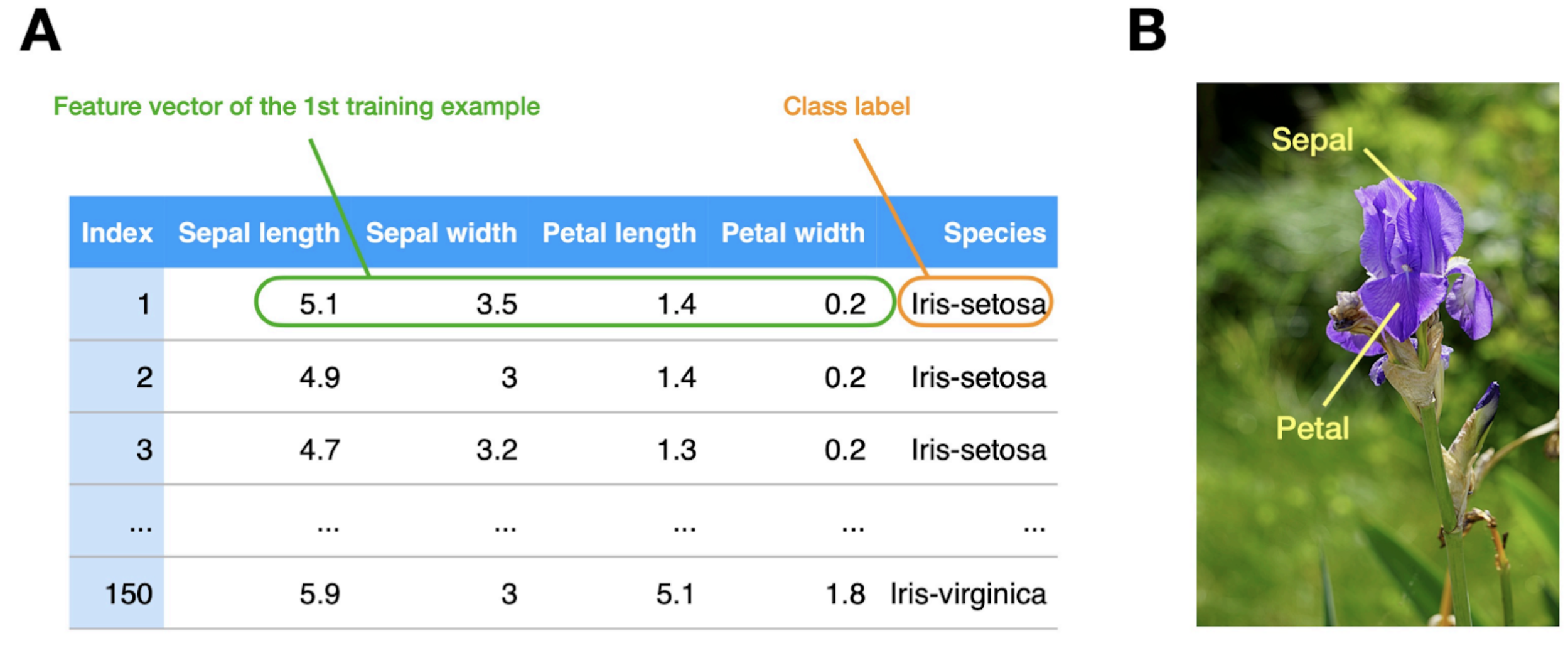
Data Representation
.png)
Summary
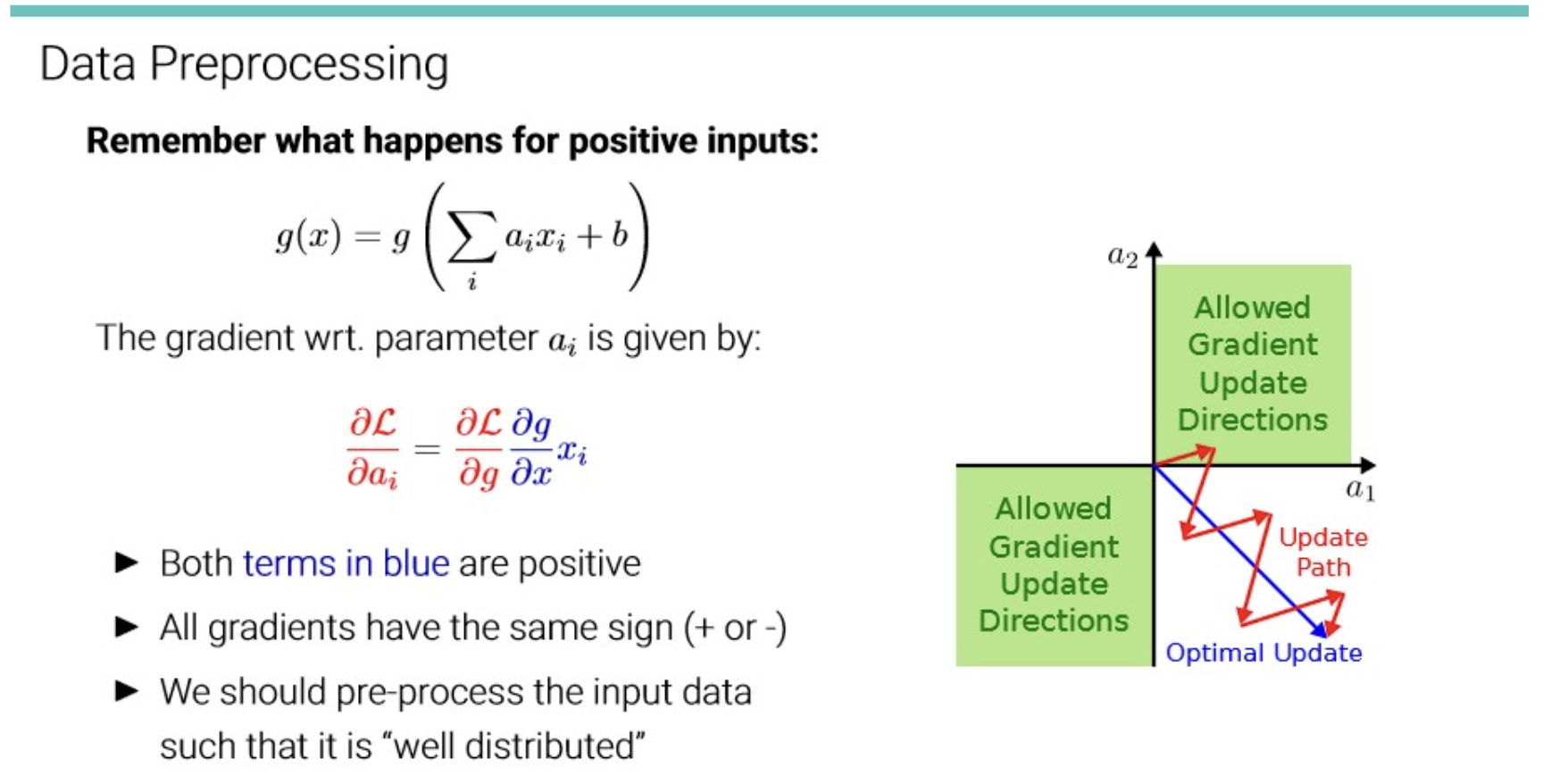
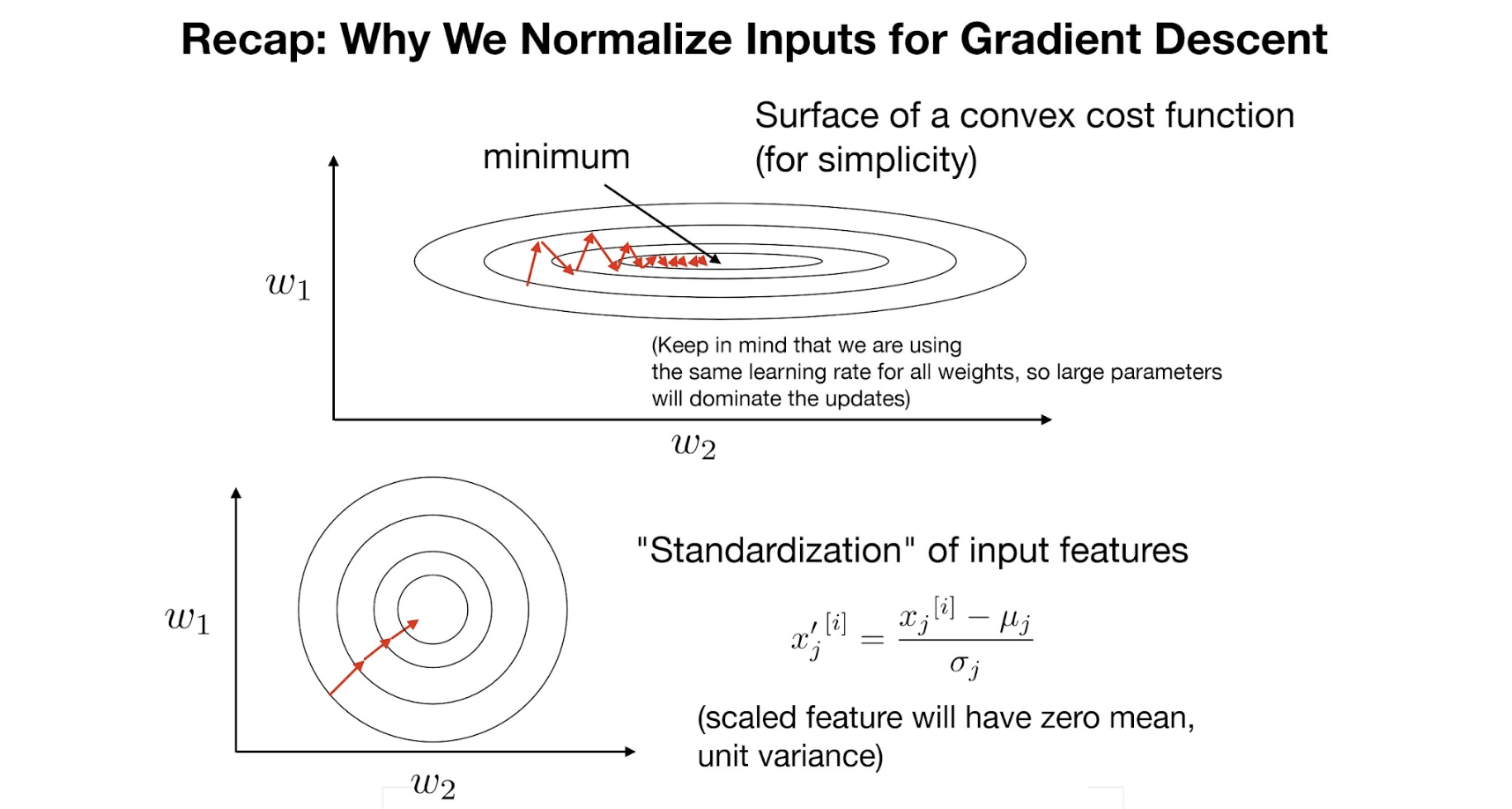
이전에 본 듯이, input data의 distribution이 고르게 분포하지 않을 경우,
gradient 가 fluctuate될 수 있다. → inefficient
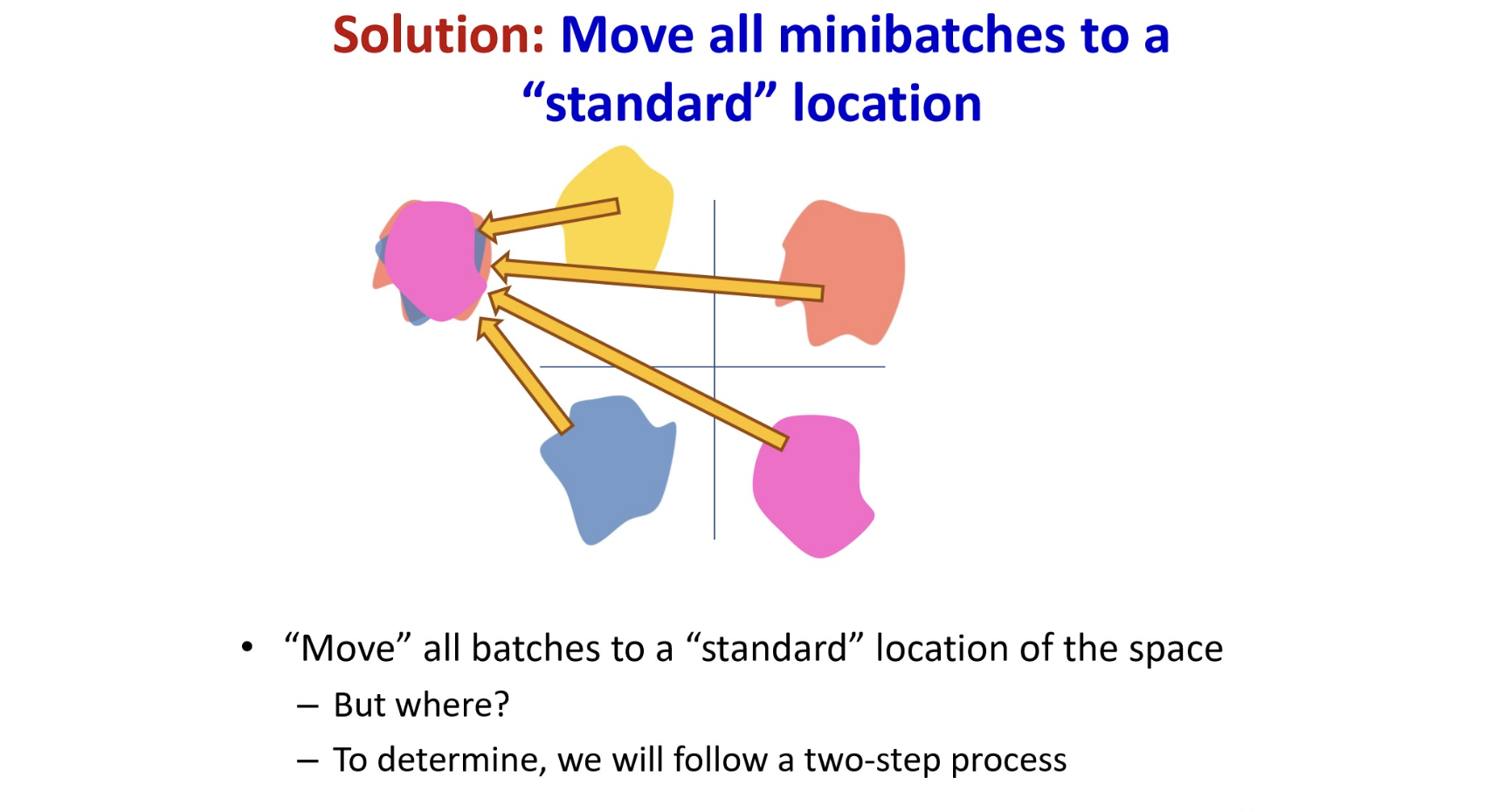
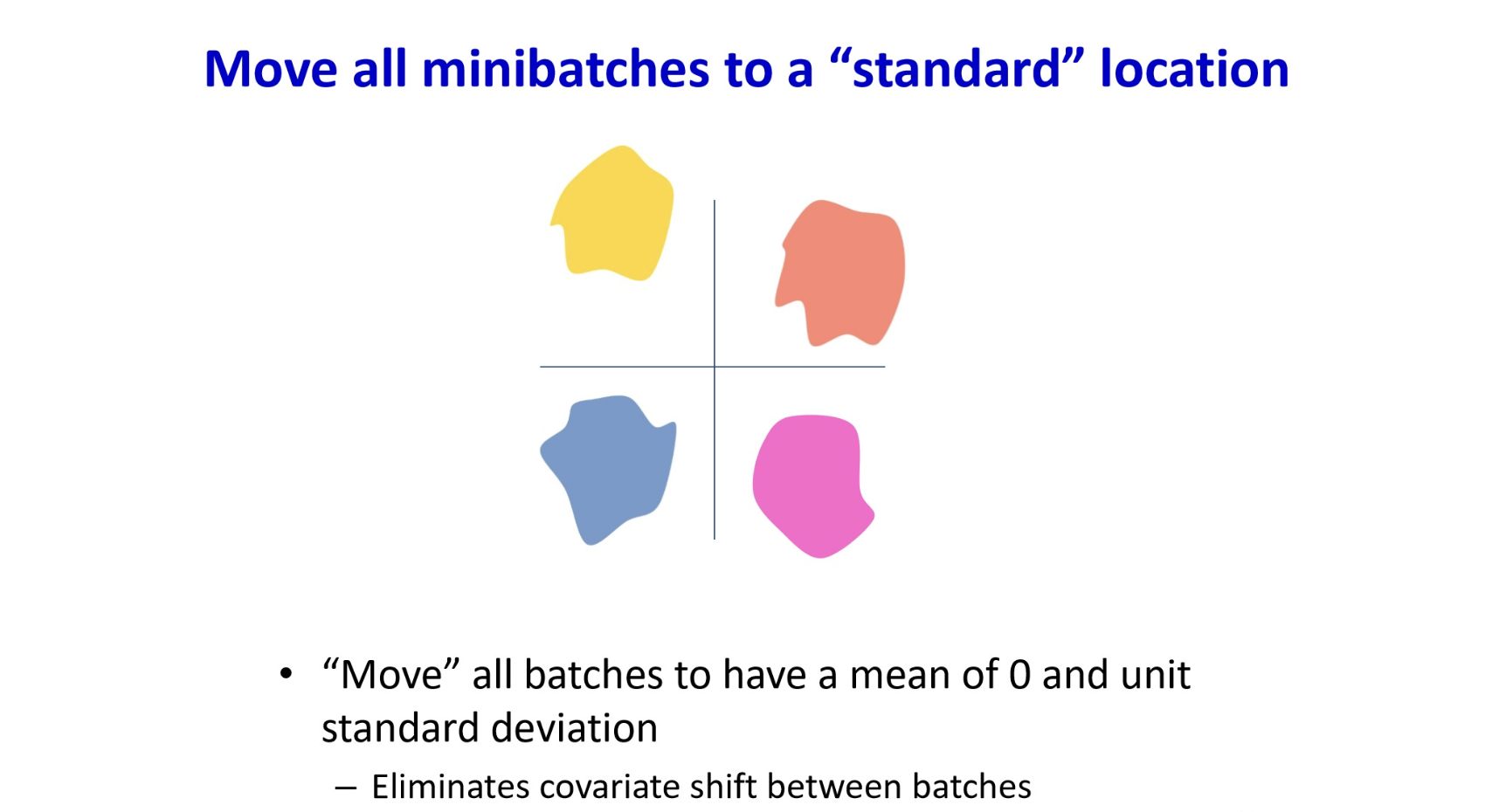
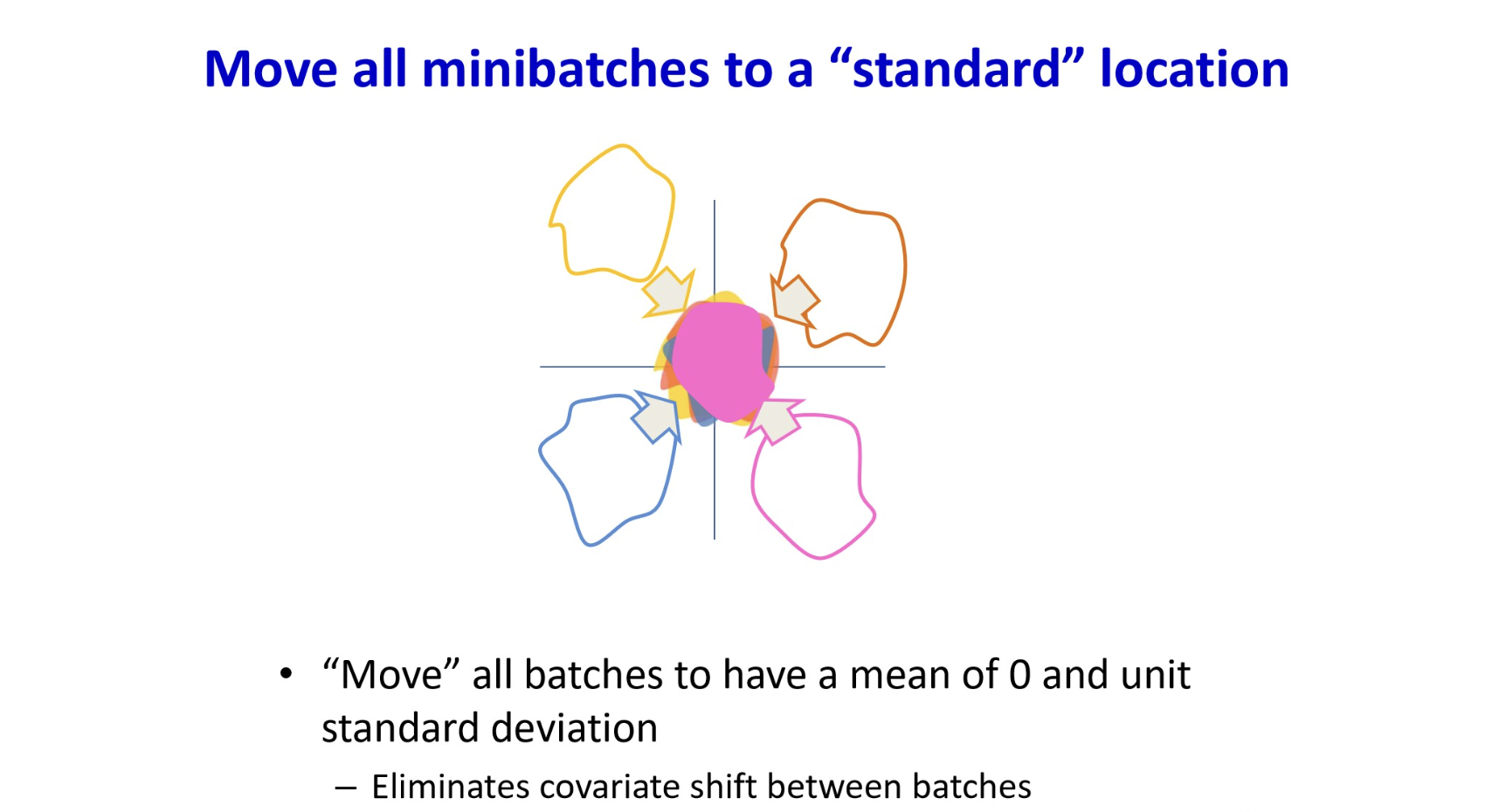
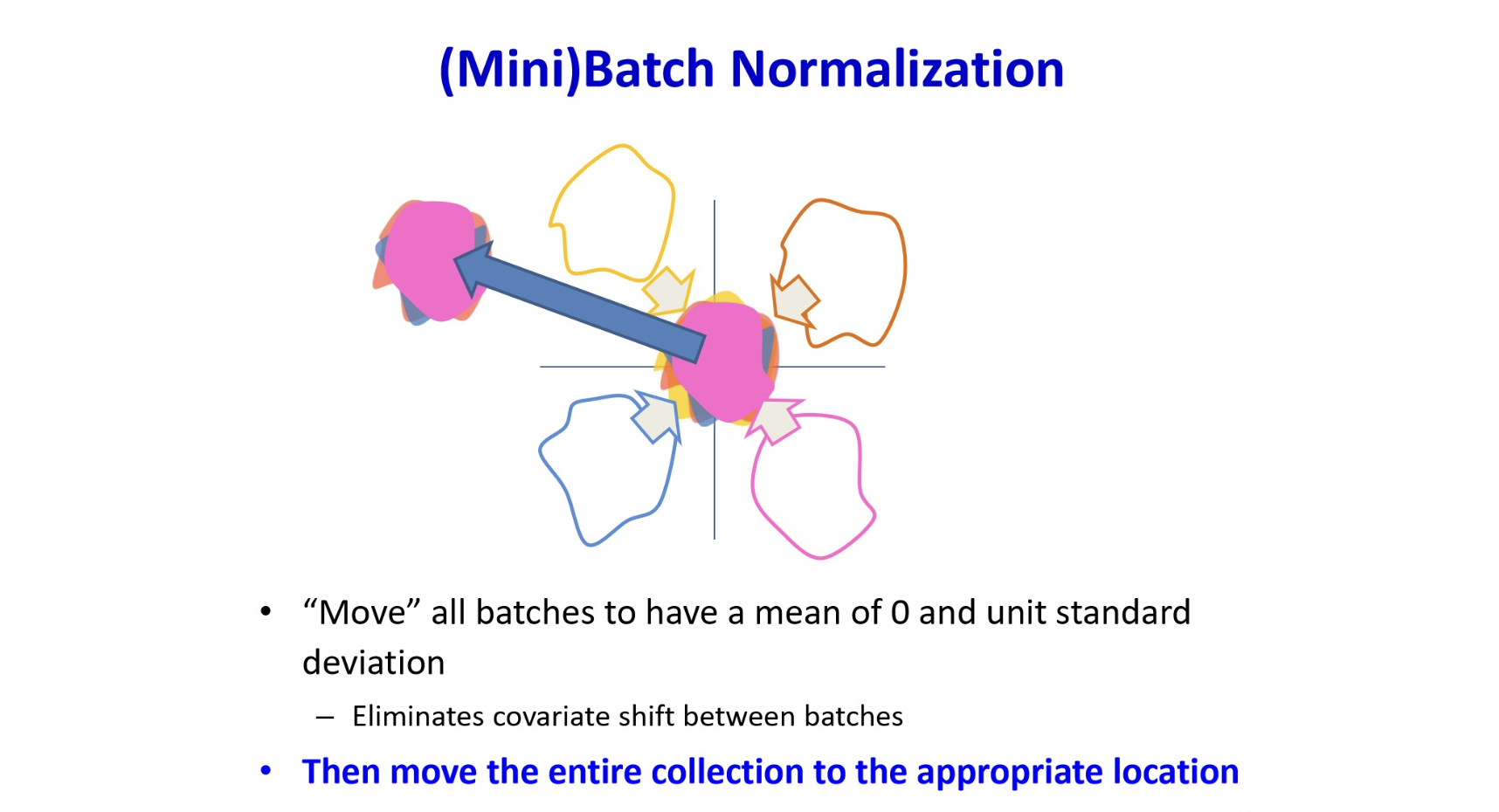
The problem of covariate shifts
Training 과정에서 우리는 일반적으로 데이터셋이 비슷한 분포에서 나왔다고 가정하는데,
mini-batch 로 학습하는 경우에는 이 단위가 mini-batch에도 적용된다.
그러나, 그렇지 않을수도 있다. (전체 데이터가 한 번에 모델에 입력되어 iteration하는게 아니니까.)



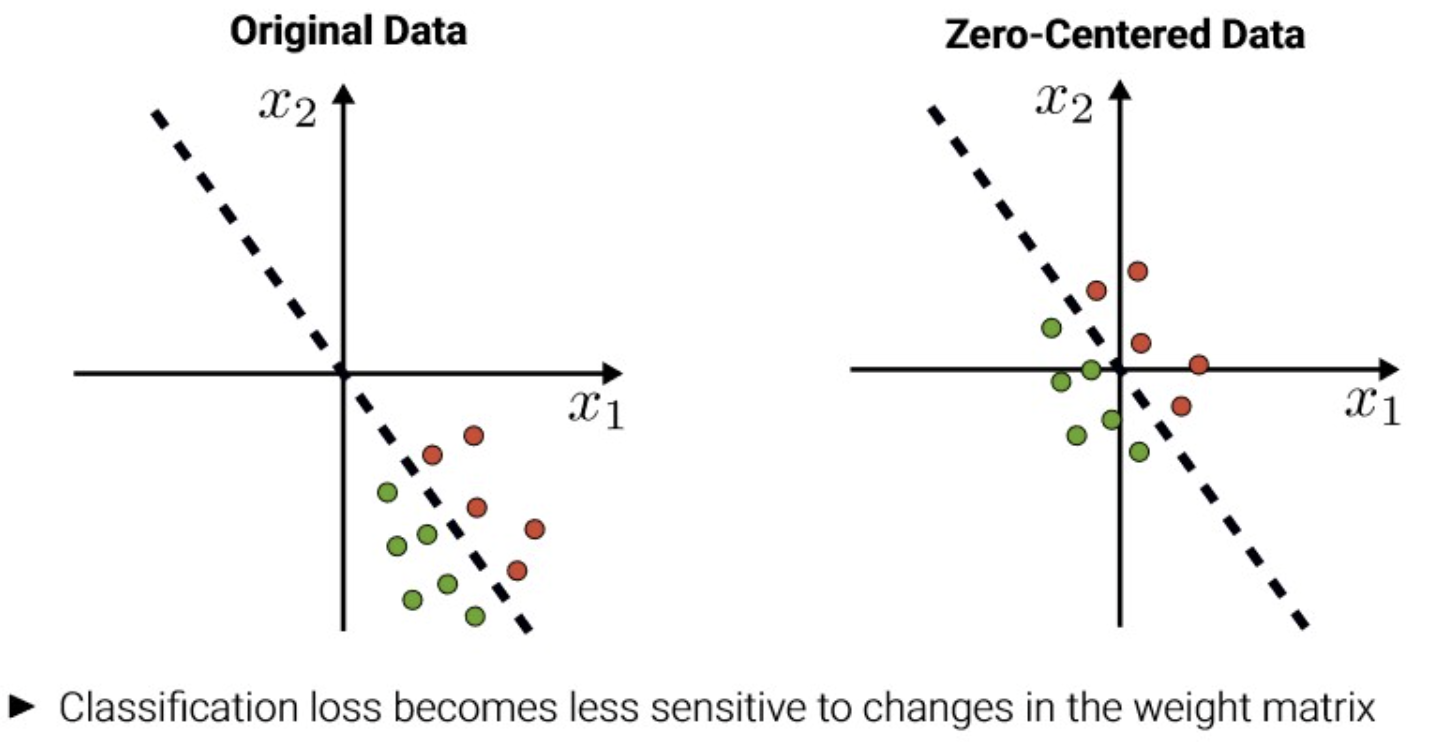
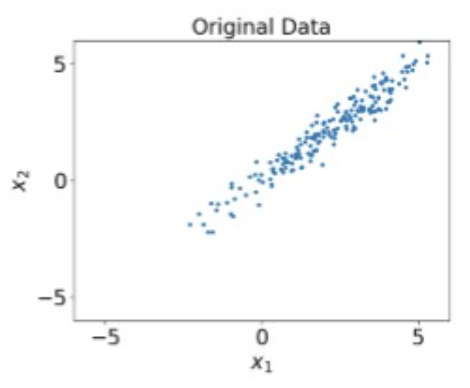
Data preprocessing Example
Original Data
Multi column
Zero-centered
with
Normalized
with
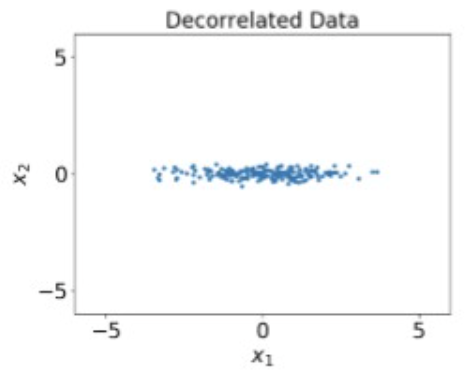
Decorrelateed
- Multiply with eigenvectors of covariance matrix
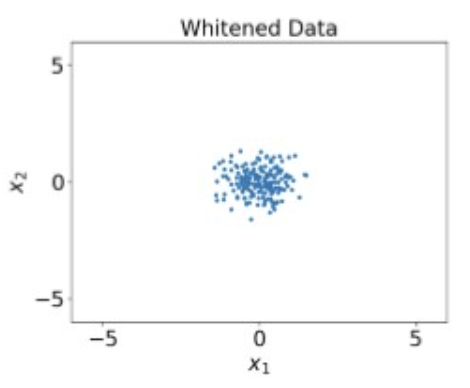
Whitened
- Divide by sqrt of eigenvalues of covariance matrix
Tip