L2 metric 으로, 제곱 항으로 구성되어 있다. 분포의 분산을 구하는 것과 비슷한 모양.
Important
L2 loss로 사용될 수도 있고, regression에서는 metric으로도 사용될 수 있다.
MSE as a L2 loss function
NOTE
우리가 하려는 목표는 MLE를 사용해서, 모델의 파라미터를 optimization 하는 것.
그렇다면 MSE loss의 경우에는 어떻게 MLE로부터 유도될까?
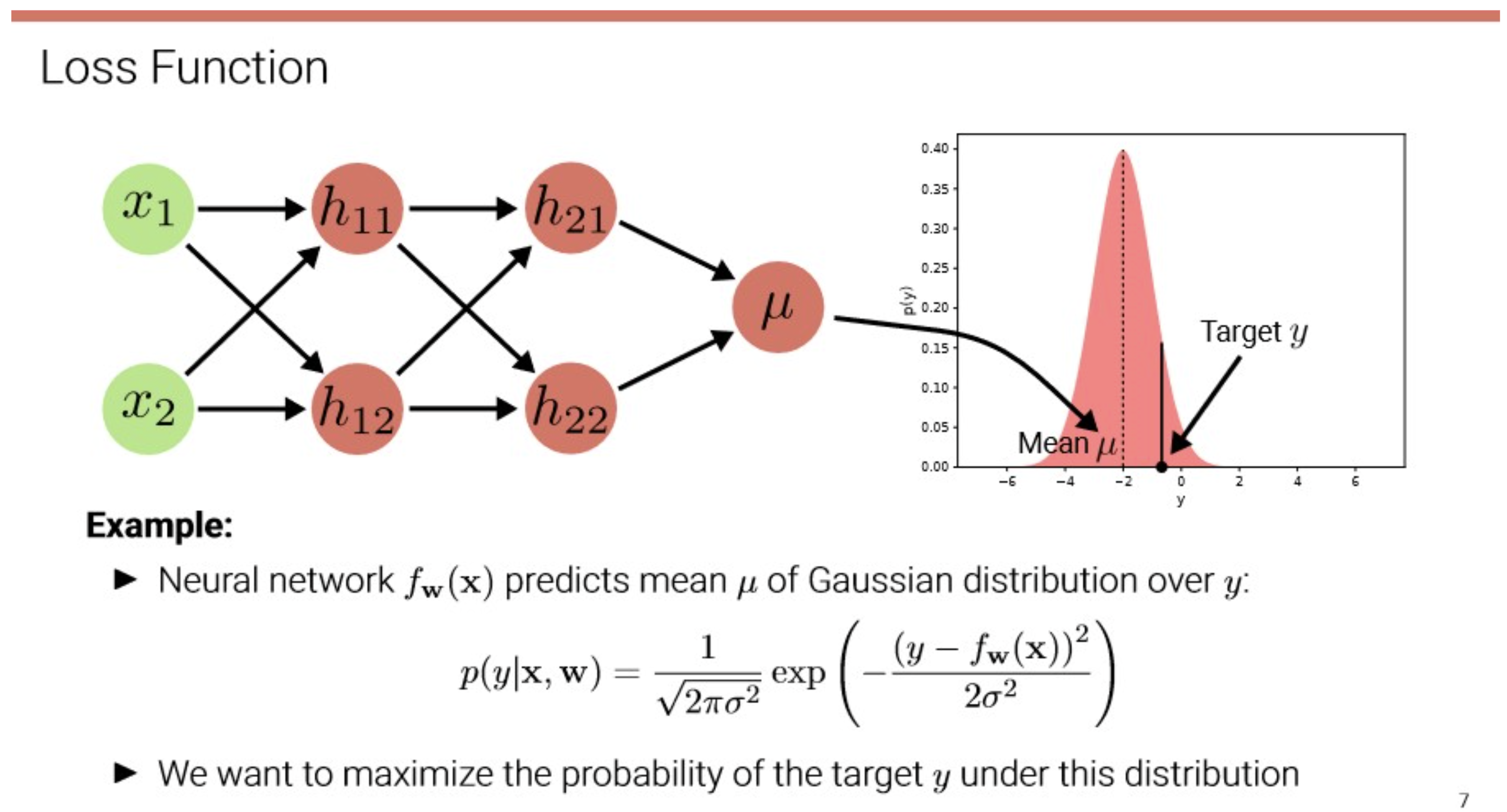
→ 데이터가 Gaussian distribution을 따른다고 가정!
Important
데이터는 일반적으로 noise를 담고 있다 따라서 우리는 모형을 다음과 같이 define 한다. y=f(x)+ϵ
where y: ground truth, x: input, f(x) : output of models and the ϵ : error
여기서 ϵ∼(0,σ2) 는 y∼(f(x),σ2) 랑 동치.
즉, 데이터가 가우시안을 따른다고 가정하는 것과 error term이 평균이 0인 가우시안을 따른다고 하는 것은 동치.
이제 이를 probability distribution 관점에서 다시 보면, pmodel(y∣x,w)=2πσ21exp(−2σ2(y−fw(x))2)
Loss?
Let pmodel(y∣x,w)=2πσ21exp(−2σ2(y−fw(x))2)
then we obtain, w^ML=wargmax∑logpmodel(yi∣Xi,w) =wargmax∑21log(2πσ2)−∑2σ21(fw(x)−y)2 =wargmax−∑(fw(x)−y)2 =wargmin∑(fw(x)−y)2
In other words, we minimize the squared loss(L2 loss)