python에서 행렬 및 수에 관련된 자료를 다루기 위해 만들어진 lib.
수치 관련 연산에서 빠르다는 게 가장 큰 장점.
Numpy basics
다음과 같은 vector inner product function을 구현해 보자.
z=∑ixiwi=x1w1+x1w2+⋯+xnwn=xTw
def loop_approach(x: list[float], w:list[float]) -> float: z = 0. if len(x) != len(w): raise ValueError("x and w must have the same length") for idx in range(len(x)): z += x[idx] * w[idx] return z
%timeit
시간을 측정해주는? magic keyword??
이는 numpy lib에서 dot() method로 구현되는데, 여기서 decorator를 사용하고 안 하고의 차이는?
결론적으로, x @ y에서 @는 데코레이터는 아니다. @는 python의 행렬 곱 전용 연산자(operator)이다.
일단 사용해보면, matmul 속도는 압도적으로 numpy 사용시 좋은데 뭘 구현했길래 이러한 속도 차이가..?
Broadcasting (@=matmul vs dot)
두 method 간 broadcasting 방법이 다르다고 한다.
N차원(스택) 처리: @/matmul은 스택 차원 브로드캐스팅 지원
dot은 마지막 축 × 끝에서 두 번째 축에 대한 합산 규칙(브로드캐스팅 방식이 다름)
python decorator
??
np.array(array-Like data)
array-like한 자료를 np.ndarray 형으로 변환해주는 method.
최대 32차원까지 문제 없이 지원해줌.
2차원일 경우, axis0는 col, axis1은 row 방향이다.
default dtype은 int64
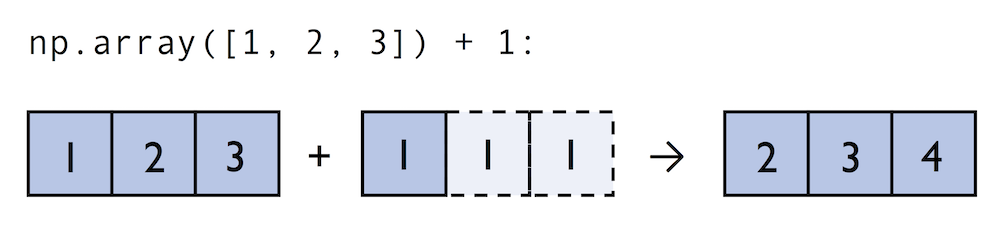
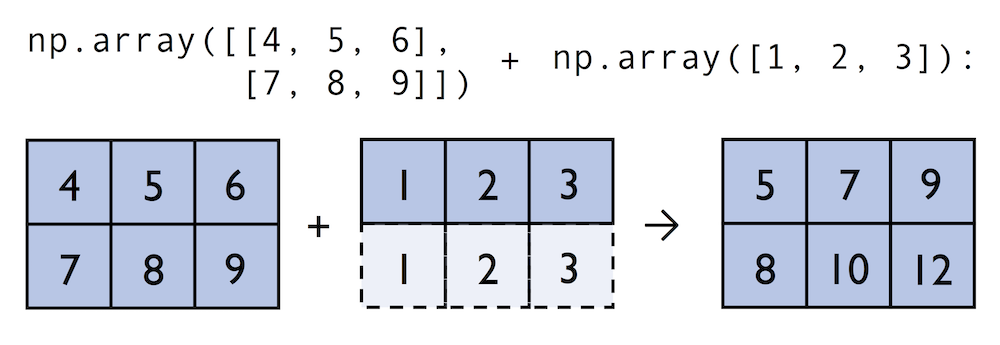
생성된 ndarray 형에는 +, -, x, / 같은 연산자들이 auro-broadcasting 되어 적용됨.
np.array().dtype
np.adarray()의 atribute로 저장된 하나하나의 dtype을 반환
np.array().astype()
np.adarray()의 dtype은 변환해주는 method.
np.array().ndim
np.adarray()의 dim 수를 반환하는 attribute
np.array().shape()
np.adarray()의 각 dim 별 사이즈를 반환(tuple).
Numpy Construction
np.zeros(shape=tuple, dtype = type)
입력 받은 tuple 정보로 차원에 맞춰 모든 셀이 0인 np.adarray() 반환
np.ones(shape=tuple, dtype = type)
입력 받은 tuple 정보로 차원에 맞춰 모든 셀이 1인 np.adarray() 반환
np.eye(N=int, M=int)
입력 받은 N, M 값을 바탕으로 identity matrix(diag=1, else=0)를 반환
np.diag(v:array-Like)
입력 받은 array-Like한 데이터를 diag-element로 가지는 matrix 반환.
np.arange(start=int, stop=int, step=int)
입력 받은 정보로 range에 맞춰 step 밟으며 리스트 생성.
stop 포함되기 전까지 generate
int-Like 한 정보 하나만 넣으면, stop으로 정의하고 start는 default로 0에서 출발.
np.linspace(start=int, stop=int, num=int)
입력 받은 정보로 range에 맞춰 num 만큼 등 간격으로 list generate.
Numpy Array Indexing
Indexing
np.ndarray 형은 [row,column] 형태로 indexing이 가능하다.
음수의 의미는 뒤에서부터 세었을 때의 순서이다.
Slicing
np.ndarray 형은 [row1:row2,col1:col2] 형태로 indexing이 가능하다.
::-1(reverse)
neg Slicing
reverse를 하면서 slicing을 어떻게 사용할 수 있나?
ex) a = [1, 2, 3, 4, 5]
a[3:1:-1] = [4, 3]
reverse가 먼저 되고, 이후에 기존 index를 사용하면 되는데, 주의점은 start, end 순서가 뒤바뀜.
Numpy Array Math and Universal Functions
Universal Functions(ufuncs)
기본 제공하는 파이썬의 연산자들은 느리기 때문에 C로 미리 컴파일된 소스들을 활용할 수 있는 연산자들을 numpy에서 제공하고 있다. 이를 ufuncs라고 하고 기본적인 arithmetic operators를 포함한 60여개의 함수들을 지원하고 있다.
2x3 matrix에서 모든 element를 1씩 증가시키고 싶을 때 할 수 있는 3가지 방법은
for-loop
lst = [[1,2,3], [4,5,6]]for row_idx, row_val in enumerate(lst): for col_idx, col_val in enumerate(row_val): lst[orw_idx][col_idx] += 1lst
List-Comprehension
lst = [[1,2,3], [4,5,6]][[cell + 1 for cell in row] for row in lst]
view로 만들어진 건지 아닌지 확인할 때 사용할 수 있다.
view라면 변수끼리 memory를 공유할테니, True
파이썬 “참조” vs C “포인터” 차이(개념 정리)
파이썬 변수는 메모리 주소를 들고 다니는 포인터가 아니라, 객체를 가리키는 이름표에 가깝다.
포인터 연산/산술, 주소 취득, 역참조 연산자 같은 저수준 기능은 없다.
대신 가변 객체(list, dict, ndarray 등)의 메서드/슬라이스 대입이 “역참조 후 값 쓰기”에 해당하는 행동을 수행한다.
불변 객체(int, str, tuple 등)는 제자리 변경 자체가 불가능하므로, x += 1 같은 문법이 실제로는 새 객체를 만들어 재바인딩한다. (ndarray는 가변)
exercise
a = np.array([0, 1, 2, 3, 4])b = a[:]print(np.shares_memory(a, b) # index을 해서 b를 만들었으므로, b는 a의 memory view이다.# 따라서 memory를 공유하니, Truea = np.array([0, -1, -2, -3, -4])print(b)# a가 재할당 되었고, b는 변동이 없으므로 기존에 가리키던 array를 그대로 pointing.# 따라서 b는 [0 1 2 3 4]print(np.shares_memory(a, b))# a, b가 가리키는게 다르니 Falsea = np.array([0, 1, 2, 3, 4])b = a[:]# 현재는 a 재할당, b는 a의 memory view이니 동일한 메모리를 가리킨다.# assigning an array to a *view* of `a`# causes NumPy to update the data in-placea[:] = np.array([0, -1, -2, -3, -4])print(a)# `b` a view of the same data, thus# it is affected by this in-place assignmentprint(b)print(np.shares_memory(a, b))
Fancy Indexing
Fancy Indexing
non-continuous sequence를 indexing 할 수 있다.
문법은 아래와 같이,
ary = np.array([[1,2,3], [4,5,6]])ary[:, [0,2]]
array([[1, 3], [4, 6]])
기존 indexing에서 범위를 지정하던 문법 대신 bracket[] 안에 이산적인 범위를 작성해주면 됨.
return 은 무조건 deep-copy된 값임을 명심!
Boolean Masks for Indexing
Boolean Masks for Indexing
True, False 값만 가지는 boolean array를 사용하여 indexing 하는 방법.