0 Abstract
Background
현재 learning mainstream인 learning paradigm은 pre-training & SFT.
SFT를 위한 set을 구하는 게 쉽지 않음. 그러나, 사람은 few-shot으로 금방 학습함.
Question
Main Hypothesis : Scaling up으로 FT 없이도 모델이 새로운 task에 잘 적응하지 않을까?
Experiment Key Points
실험에서는 FT 즉, 파라미터를 수정하지 않고, In-context Learning이라는 방법을 사용함.
prompt 형식으로 모델에게 예시를 주어 학습시키는 방법.
- 구분은 Zero-shot(0S), One-shot(1S), Few-shot(FW)로 구분.
Results
- Strong performance: QA, CommonSensing, Math-inferencing, translation 등 여러 분야에서 SOTA에 필적하거나 넘는 성능을 보임.
- 사람과 구분하기 힘들 정도의 text-generation performance
- 그러나, NLI 또는 일부 독해 데이터셋에서는 여전히 어려움을 겪음.
- 또한, 모델 자체의 bias, fake-news 등 사회적 악용 가능성도 문제가 될 수 있다고 함.
1 Introduction
- 이때까지는 pre-training & fine-tuning paradigm을 했는데 문제점이
- fine-tuning마다 데이터셋이 필요했고,
- task별 SFT시 generalization이 떨어졌음.
Quote
사람은 ‘adaptability’가 있는데, 이러한 것이 AI에게 필요하다,,
In-context Learning
모델의 규모를 키우다보면, (GPT3는 175B인데, GPT2 약 10배 정도) 모델의 추가적인 파라미터 변경 없이도 learning behavior가 보이는 것 같은데, 이를 ‘in-context learning’이라고 한다.
- form은 prompt 형식으로 task-description이랑 몇 가지의 예시를 제공하는 방법(few-shot)
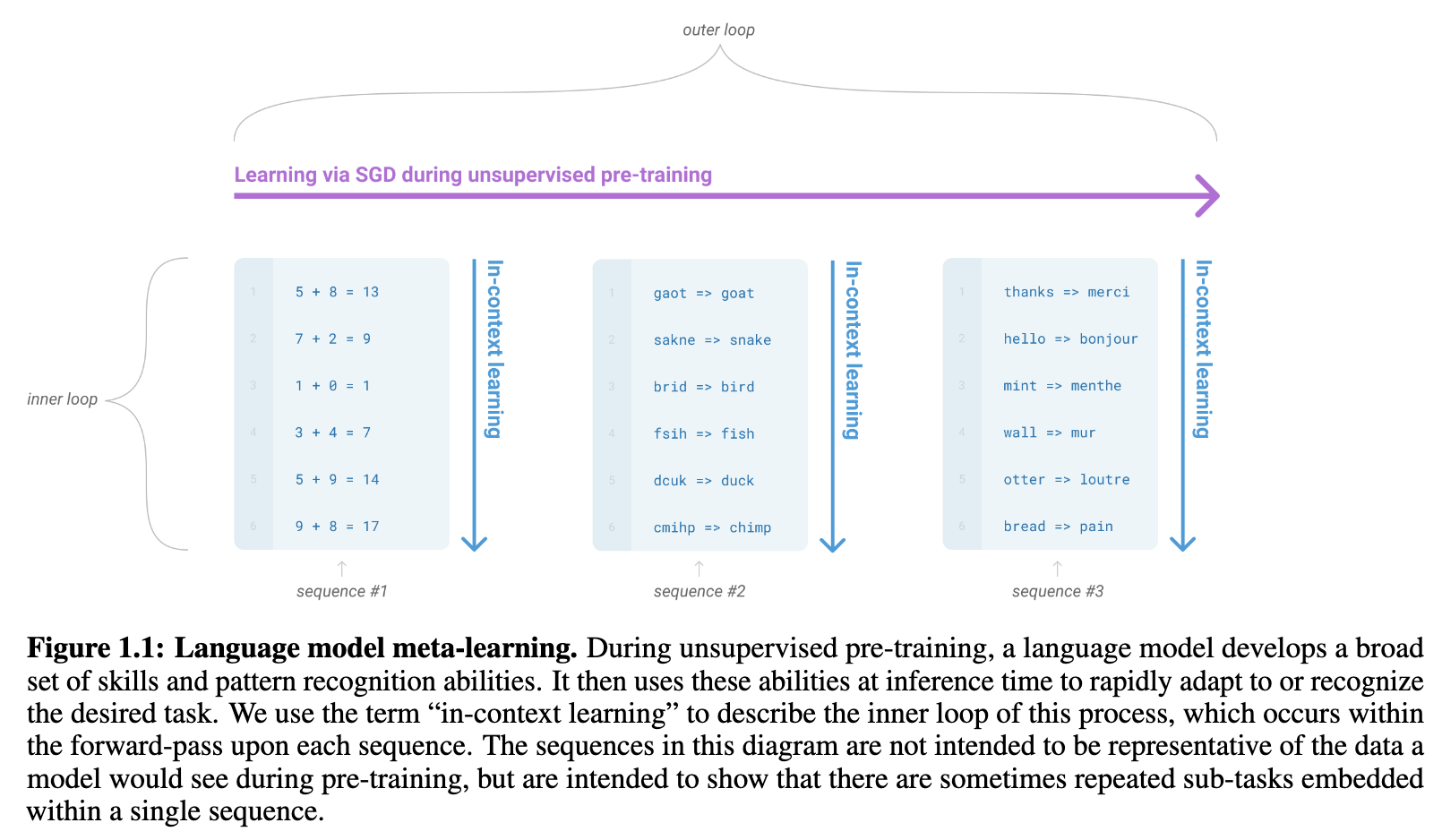
Meta-Learning vs ICL(In Context Learning)
ICL은 Meta-learning 개념을 실현하는 구체적 매커니즘 중 하나.
논문에서는 이를 Inner-loop / Outer-loop로 구분하는데,
- Outer loop : Pre-train 단계에서 모델이 방대한 데이터를 접하며, unseen task에 대한 일반적인 능력을 키우는 과정
- Inner loop : ICL 즉, outer-loop에서 얻은 능력을 통해 inference time에서 prompt 만으로 task를 파악하여 해결하는 과정(Fast adaptation via context)
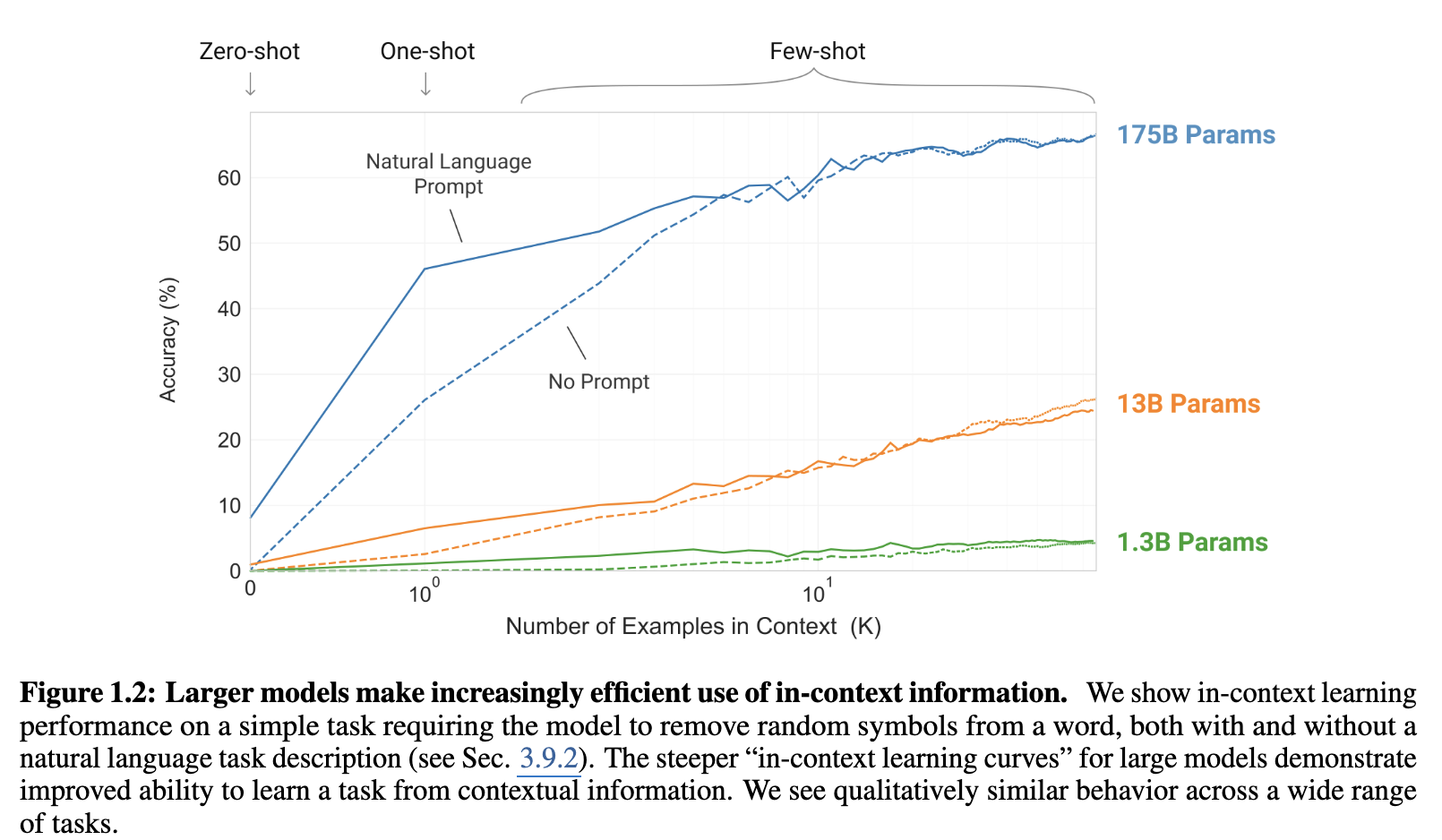
Scaling Law & N-shot Learaning
- 모델의 크기가 클 수록,
- shot이 많을수록
일반적으로 모델의 inference 성능이 좋아진다.또한, 0S랑 1S의 차이는 모델 크기가 커질수록 커진다.
→ 파라미터가 많은 모델들은 1S 만으로도 성능향상이 매우 가파르다.
42개 benchmark를 모아서 정리했는데,
- 마찬가지로 scaling-law 보임.
- 어떠한 task는 일정 규모가 나와야 pereformance가 나오기 시작해서 지능의 threshold가 있는 과제가 있는 것 같다.
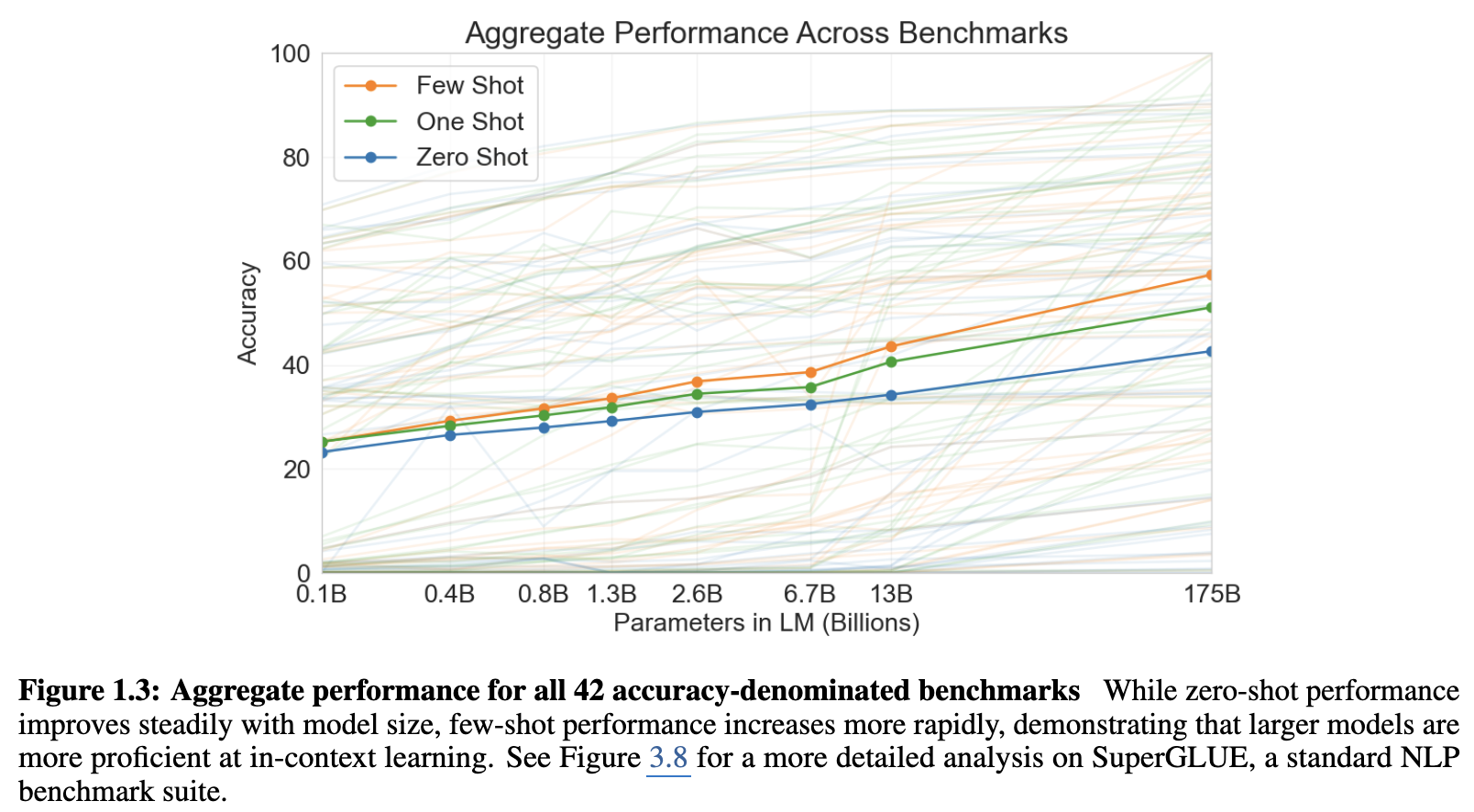
Result Summary
대부분의 문제에서는 좋은 performance.
일부 task에서는 fine-tuning한 모델들이랑도 competative한 performance를 보임.
그러나, NLI(natural language inference) task나 특정 독해 작업에서는 여전히 모자란 부분을 보임.
2 Approach
Summary
GPT3를 다음과 같은 4가지 방법으로 학습 시켰을 때, 성능 비교를 하겟다.
- FT(Fine-Tuning)
- 0S : Zero-shot : Context 내 학습할 수 있는 소스를 주지 않음. instruction만 줌.
- 1S : One-shot : 한 가지의 예시를 줌. 추가로 instruction도 같이.
- FS: Few-shot : 2가지 이산의 예시를 제공해 줌.(10~100개)

2.1 Model and Architectures
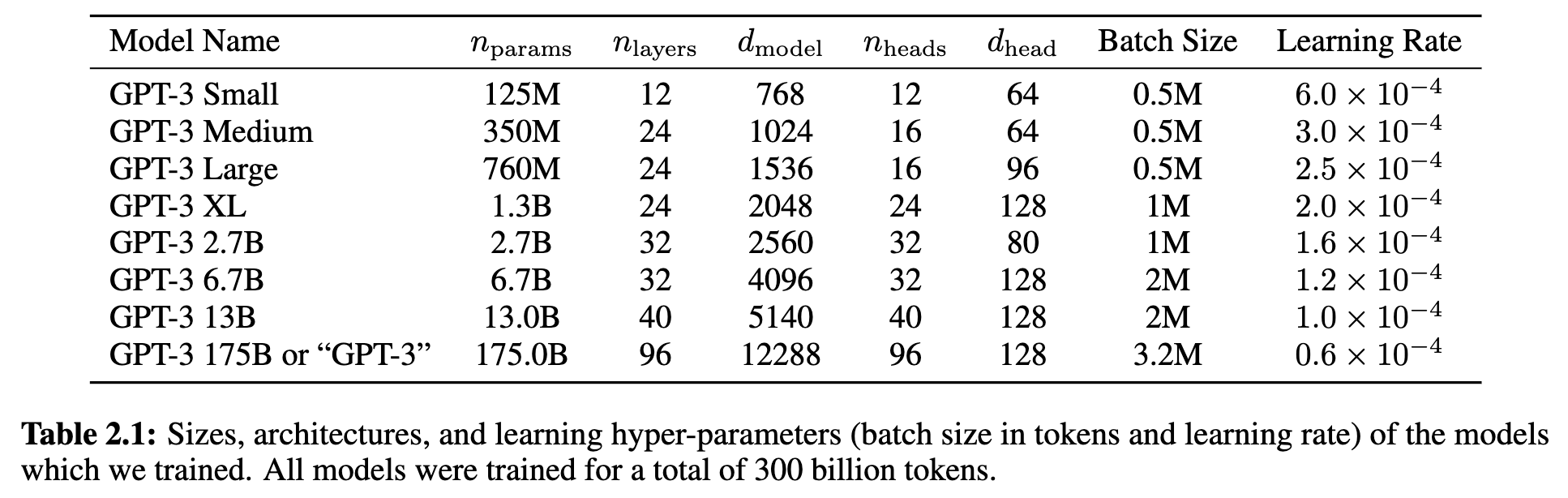
Summary
- GPT2 구조 계승.
- modified-initialization, pre-norm, reversible tokenization 포함.
- modified-initialization : layer 개수 고려해서 모델 초기화 시 layer 개수의 루트 크기만큼 나누어준다.
- pre-norm : 원래는 residual connection 이후 즉, shortcut-path랑 기존 path 합쳐진 후 Norm했는데, Norm을 먼저한다.
- reversible tokenization : Unknown token을 사용할 필요 없는 Byte-level BPE
- Sparse Attention 도입.
- Transformer 각 layer에 Desne Attention이랑 Locally Banded Sparse Attention을 번갈아 가며 사용.
- 긴 text seq 처리 시 연산 효율성 목적으로 도입.
- Context-Window = 2048
- 파라미터가 너무 많아서, GPU 내 행렬 곱셈을 나누는 방식 및 layer를 gpu 별로 나누는 방법을 사용.
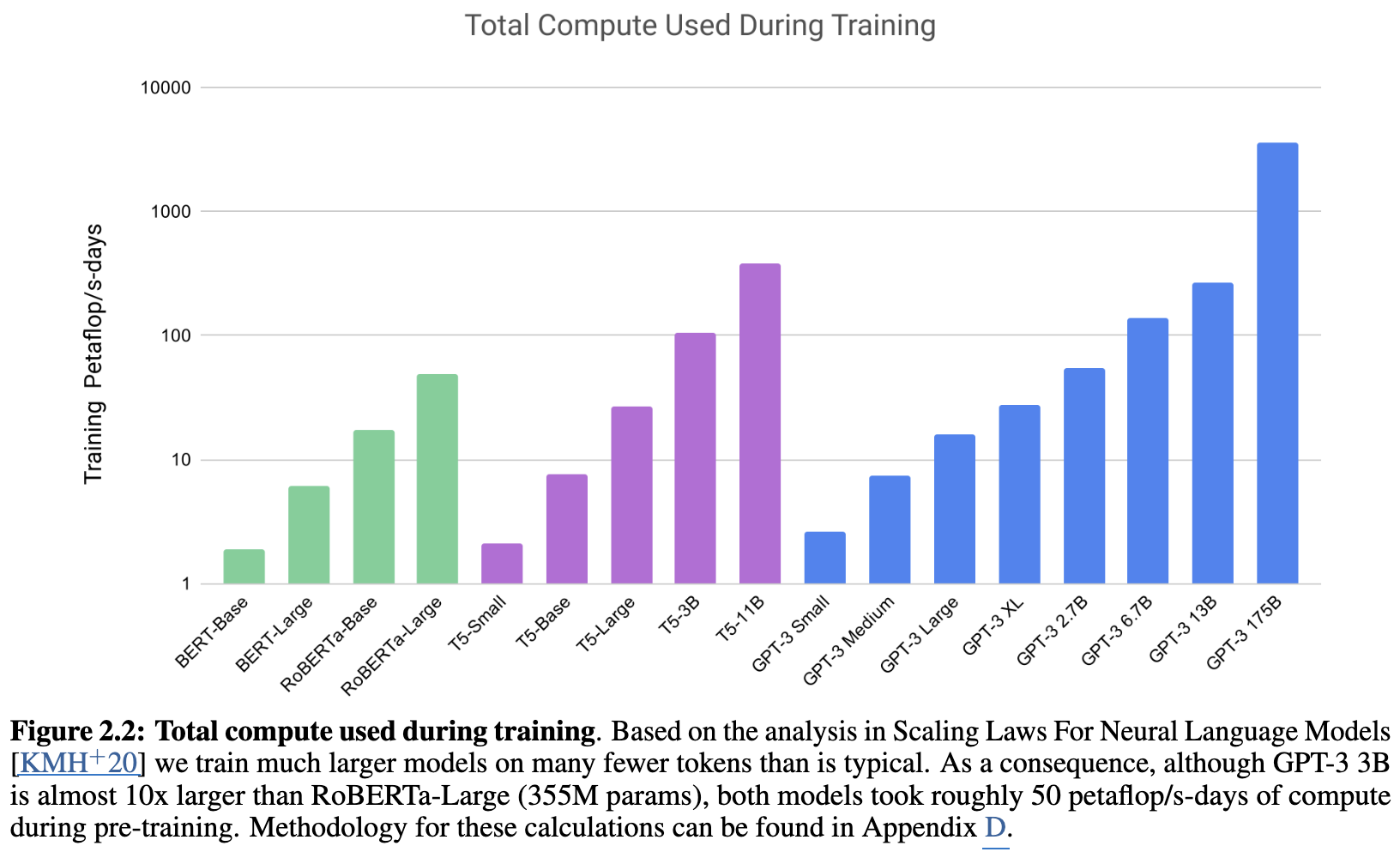
- Scaling-Law 검증 : “충분한 데이터가 있다면 모델의 크기가 커질수록 loss는 멱법칙 따라 감소할 거다.”
2.2 Training Dataset
Summary
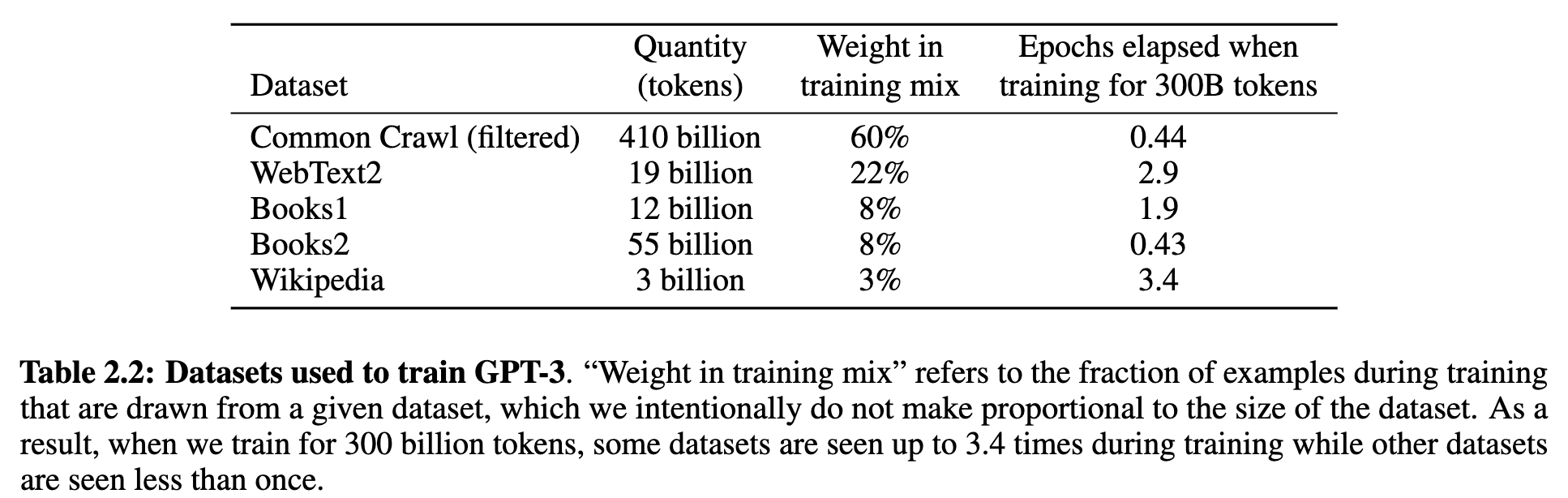
- Data Source
- 방대한 인터넷에서 긁어온 Common Craw(1T Words)l과
- 데이터 셋 품질을 올리기 위해 잘 다듬어진
- WebText2: Reddit에서 추천을 많이 받은 링크의 텍스트.
- Books1 & Books2: 두 개의 서로 다른 인터넷 기반 도서 말뭉치.
- Wikipedia: 영어 위키백과 데이터.
- 를 사용함.
- Data Quality Filtering
- 유사성 기반 filtering : 고품질셋을 reference로 하여 Common Crawl 중 유사성이 낮은 일부를 drop.
- Fuzzy Deduplicattion: Docs 수준에서 중복된 것들 drop.
- Data Contamination: test-benchmark 데이터 들이 train에 사용되지 않게 한 번 filtering
- Weighted Sampling
- corpus 크기별 sampling 비율을 고려한 것이 아니라, 고품질의 데이터셋에서 더 많이 추출되도록 비율 설정함.
2.3 Training Process
Summary
전형적으로 모델의 크기가 커지면,
- lr은 작게 쓰고,
- batch는 더 크게 잡는다고 한다.
Batch Size 무작정 정하는 게 아니라, gradient noise scale을 사용해서 정함.
- train-code 단에서 보면, gradient는 batch 단위에서 계산해서 사용하는데, 이 경우 full data에 대한 gradient 즉, true-gradient랑 각 배치간의 gradient는 다를 수 밖에 없는데, 이 다른 정도를 사용해서 batch size를 잡음. from McCandlish et al. (2018)
Parallelism
- Intra-layer parallelism : Matmmul 연산을 쪼개서 gpu에 분배하고 합치는 방식으로 수행.
- Intre-layer parallelism : 레이어를 특정 gpu들에 배당해서 사용하는 방식으로 함.
Infra
- MS cluster에서 V100 사용했고, 3,640 PFlops/day 정도 소요
2.4 Evaluation
Summary
ICL test를 위해서 다음과 같이 데이터 준비.
- Few-Shot 조건.
- benchmark set에서 data를 train / dev / test로 분리.
- 처음으로 하는 건, -shot에서 값 정하기
- train set에서 무작위 추출한 sample 개를 붙여서 context 생성.
- context-window : 2048 token 내에 들어가도록 는 10~100 정도로.
- dev(eval) set에서 1개 추출해서 모델에게 train으로 만든 context를 hint로 그 문제를 맞추게 해서 acc 평가
- 이걸 기준으로 값 결정.
- 결정된 개 만큼의 set을 다시 train에서 뽑고, 이를 hint로 삼아, 실전에서 풀 문제를 test에서 뽑아서 acc를 평가.
Multiple Choice eval
3 Results
3.1 Language Modeling, Cloze, and Completion Tasks
3.2 Closed Book Question Answering
3.3 Translation
3.4 Winograd-Style Tasks
3.5 Common Sense Reasoning
3.6 Reading Comprehension
3.7 SuperGLUE
3.8 NLI
3.9 Synthetic and Qualitative Tasks
4 Measuring and Preventing Memorization Of Benchmarks
5 Limitations
Todo
- Task performance
- 특정 task에 대해서는 아직 저조한 performance
- NLI : 주로 문장 간 entailment 관계 묻는.
- Reading Comprehension
- WiC(Words in Context)
- FT model 모델 대비 performance
- Few-shot 성능이 잘 나오긴 하지만, SFT를 이길 정도는 아님.
- Auto-regressive Decoder
- Decoder-only 구조에서 오는 auto-regressive한 특성으로, fill-in-the-blank 같은 특정 NLP task에서는 BERT 같은 구조를 이기기 힘들다.
- 특정 목표에 대한 학습이 아닌, NTP(LM) task만으로 학습하니, 복잡한 논리 구조를 이해하는 데 한계가 있다.
- Learning Efficiency & Data problem
- 필요한 데이터 양이 사람 대비 너무 많다.
- Lack of Grounding :다양한 modality 정보가 필요하다.
- 물리 법칙을 요하는 문제들에 취약. → World Model?
- Cost & Social Effects
- Expensive하고,
- 데이터 cleaning이 쉽지 않아, social-bias가 있을 가능성이 높다.