Meta-Harness: 모델 하네스의 엔드투엔드 최적화
Digest: LLM 성능은 모델 자체만이 아니라 정보 저장·검색·제시를 담당하는 하네스(harness) 코드에 크게 좌우되며 동일 모델에서도 하네스 차이로 최대 6× 성능 격차가 발생한다(Challenge). 기존 텍스트 최적화 방식은 스칼라 점수나 요약에만 의존해 한 번의 평가가 만들어내는 ~10M 토큰 규모의 진단 정보를 활용하지 못한다(Insight). 본 논문은 Meta-Harness, 즉 Claude Code(Opus-4.6)를 proposer로 사용해 파일시스템 질의(grep/cat)로 과거 하네스의 소스·점수·실행 트레이스에 선택적으로 접근하는 agentic proposer 기반 harness 탐색 시스템을 제안한다(Solution). 실험적으로 텍스트 분류에서 ACE 대비 +7.7점(컨텍스트 토큰 4× 절감), IMO 난도 수학 문제 200개에서 5개 held-out 모델 평균 +4.7점, TerminalBench-2에서 Opus-4.6 기준 76.4% pass rate(2위)를 기록했다(Evidence, 수치 출처: 논문 §4.1–4.3). 이는 풍부한 진단 이력 접근이 자동 하네스 엔지니어링을 가능케 함을 보이며(Learning), 단일 proposer(Claude Code)로 제한된 검증 범위와 하네스-가중치 공진화 미탐구는 향후 과제로 남는다(Questions).
섹션별 요약
Abstract
Meta-Harness는 LLM 애플리케이션의 하네스 코드를 자동으로 탐색·최적화하는 시스템이다. 핵심 메커니즘은 agentic proposer가 filesystem을 통해 이전 후보들의 소스코드, 점수, 실행 트레이스에 직접 접근하는 것이다. 세 영역에서 검증: (1) 온라인 텍스트 분류 — ACE 대비 +7.7점, 컨텍스트 토큰은 4× 적음, (2) IMO 난도 200문제 수학 검색 — 5개 held-out 모델 평균 정확도 +4.7점, (3) TerminalBench-2 에이전틱 코딩 — 사람이 엔지니어링한 baseline 초월.
저자 contribution
- Filesystem 기반 진단 접근: 이전 평가의 원시 코드·트레이스·점수에 선택적으로 질의하는 agentic proposer를 도입, 단일 평가당 ~10M 토큰의 진단 정보를 활용 가능하게 한다.
- Minimal outer loop: parent 선택 규칙 없이 population과 Pareto frontier만 유지하는 미니멀 탐색 루프로 텍스트 분류·수학 검색·코딩 에이전트 세 도메인에서 SOTA 또는 경쟁력 있는 결과를 달성한다.
- 수치 증거: 분류 +7.7점/4× 토큰 절감, 수학 +4.7점(5 모델 평균), TerminalBench-2 Opus-4.6 76.4%(#2)·Haiku-4.5 37.6%(#1).
왜 이 연구를 하는가?
- 동기: LLM 시스템 성능은 모델 가중치뿐 아니라 프롬프트·검색·메모리·오케스트레이션 로직을 묶는 harness에 크게 의존하며, 동일 모델에서 harness 차이만으로 벤치마크 성능이 6× 변동한다. 그러나 harness 엔지니어링은 여전히 수작업이다.
- 기존 한계 (2+):
- 기존 텍스트 최적화(예: prompt optimization) 기법은 스칼라 점수만 조건으로 받거나 피드백을 요약으로 압축하여 raw 실행 트레이스의 풍부한 정보를 버린다.
- 또는 memoryless — 과거 후보 이력에 체계적으로 접근하지 못해 실패 모드 진단이 불가능하다.
- 핵심 통찰 / RQ: “proposer에게 과거 코드·트레이스·점수에 대한 파일시스템 수준의 선택적 접근을 허용하면, 스칼라/요약 기반 방법이 놓치는 실패 원인을 식별하고 더 나은 harness를 제안할 수 있는가?”
Introduction
Harness 엔지니어링의 중요성에도 불구하고 자동화는 미개척이다. 저자는 두 관찰로 출발한다. 첫째, 고정 LLM에서 harness만 바꿔도 6× 성능 격차가 존재한다. 둘째, 단일 평가가 생성하는 진단 정보(로그·트레이스·중간 산출물)는 최대 10M 토큰에 달해, 기존 텍스트 최적화의 작업 스케일을 3 orders of magnitude 초과한다. 따라서 이 규모를 직접 프롬프트에 싣는 것은 불가능하며, 선택적 질의가 필수다. Meta-Harness는 이 선택적 질의를 Claude Code의 filesystem tool로 구현하고, proposer가 grep/cat으로 관심 영역만 끌어오게 한다. 이는 텍스트 최적화를 “스칼라 → 요약 → 선택적 raw 접근”으로 한 단계 확장하는 셈이다.
Methods
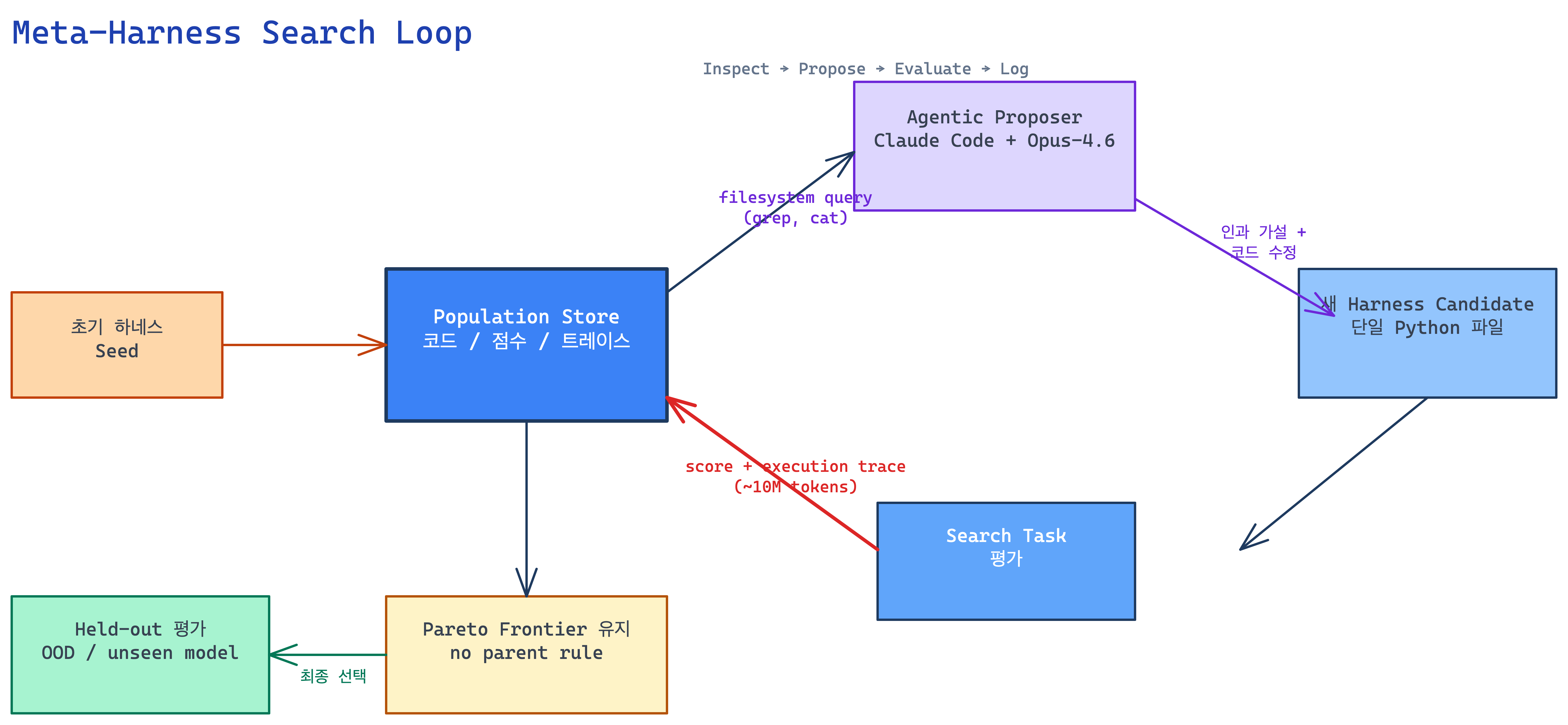
Meta-Harness의 외부 루프는 4단계로 구성된다:
- Inspect: proposer(Claude Code + Opus-4.6)가 filesystem 질의로 이전 하네스 소스·트레이스·점수 검사 (iteration당 중앙값 82 files).
- Propose: 실패 모드 진단에 기반해 새 harness 코드(단일 Python 파일)를 제안. 프롬프팅·검색·메모리·오케스트레이션 로직을 자유롭게 수정.
- Evaluate: search task에서 제안된 harness 실행·채점.
- Log: 코드·점수·트레이스를 영구 저장해 후속 iteration에서 재접근 가능.
설계 철학: 모든 이력을 단일 프롬프트에 적재하는 대신 표준 개발자 도구(grep, cat)로 선택적 접근. population과 Pareto frontier만 유지하며 parent 선택 규칙 같은 강제 탐색 구조를 두지 않음.
차별점: (a) 스칼라·요약이 아닌 raw 코드 + 트레이스 접근, (b) 고정된 텍스트 돌연변이 연산자 없이 proposer가 인과 가설을 형성하고 수정, (c) search task 1개의 해법이 아니라 재사용 가능한 harness 프로그램을 출력.
발견 (Findings)
- 텍스트 분류 (§4.1): LawBench·Symptom2Disease·USPTO-50k에서 Meta-Harness 48.6% 정확도 (ACE 40.9 대비 +7.7점), 컨텍스트 토큰 11.4K vs ACE 50.8K (4× 절감). 9개 unseen OOD 데이터셋에서 평균 73.1%로 ACE 70.2% 초월.
- 최적화기 비교: OpenEvolve·TTT-Discover가 60 proposals로 도달한 정확도를 4 evaluations만에 일치 — 진단 이력 접근의 샘플 효율 이점.
- Ablation(핵심): full interface(코드+트레이스) 중앙값 50.0 vs scores-only 34.6 vs scores+summary 34.9 → execution trace 접근이 +15점 이상의 독립적 기여.
- 수학 검색 (§4.2): 250문제 search set에서 발견된 BM25 기반 subject-routing (combinatorics/geometry/number theory/default) 하네스가 5개 held-out 모델(GPT-5.4-nano/mini, Gemini-3.1-Flash-Lite, Gemini-3-Flash, GPT-OSS-20B) 평균 +4.7점.
- TerminalBench-2 (§4.3): Opus-4.6에서 76.4% (전체 #2, ForgeCode 81.8% 다음), Haiku-4.5에서 37.6% (전체 #1, Goose 35.5% 상회). 핵심 발견 구조: environment bootstrapping — agent loop 시작 전 OS/의존성 스냅샷 수집으로 탐색 턴 2–4회 제거.
Results
§4.1 Text Classification: 3 벤치마크 온라인 분류. Zero-shot·few-shot·ACE·MCE 대비 Meta-Harness가 절대 정확도·토큰 효율 모두 우위. OOD 평가(9 데이터셋)에서도 일관된 우위로 overfit to search tasks 가설 반증. Ablation에서 interface richness를 점수→점수+요약→full(코드+트레이스)로 늘리면 중앙값 34.6→34.9→50.0으로 요약이 아닌 raw 접근이 결정적.
§4.2 Math Retrieval: 250 problem search set에서 탐색된 harness는 BM25 + subject routing 구조. 200 IMO-level 문제·5 held-out 모델 교차 평가에서 no-retrieval baseline 대비 +4.7점 (모델간 일관). 검색 설계 자체를 proposer가 발견.
§4.3 TerminalBench-2: 89-task 자율 코딩 벤치. Opus-4.6 76.4% pass rate (리더보드 #2), Haiku-4.5 37.6% (#1). Search 궤적 분석에서 proposer가 confound isolation(환경 초기화 변수를 통제) 후 안전한 수정으로 pivot하는 패턴 관찰.
Discussion
발견된 harness들은 세 가지 실용적 이점을 보인다: (1) OOD 데이터셋·unseen 모델 일반화, (2) wall-clock 수 시간 내 탐색 완료, (3) 코드가 inspectable하여 overfit 점검 가능. 저자는 proposer가 고정 휴리스틱이 아닌 인과 가설 형성에 의해 작동한다고 주장하며 TerminalBench-2 궤적을 증거로 제시한다. 한계로 (a) proposer를 Claude Code 단일 에이전트로 고정해 proposer-agnostic 일반화 미검증, (b) harness-weight co-evolution(RL과의 결합) 미탐구를 언급. 향후 방향은 다양한 proposer 계열(Gemini·GPT), 그리고 모델 가중치와 하네스의 공진화.
이론적 의의
- 텍스트 최적화의 재정의: 기존 프레임워크(APE·OPRO·TextGrad 등)는 “스칼라 점수 + 요약 피드백” 가정에 고정되어 있었다. Meta-Harness는 진단 정보 접근의 granularity 자체가 최적화 성능의 축임을 실증하며, 최적화 문제를 “condition on summaries → condition on queryable raw history”로 확장한다.
- Agentic proposer의 meta-level 일반화: 코딩 에이전트가 코딩 에이전트 자체를 최적화한다는 reflexive 구조가 작동함을 보여, self-improving system 연구에 구체적 실험 설계를 제공한다(KRAFTON의 Self-Evolving 계보와 직접 연결).
- Pareto frontier + no parent rule: 명시적 selection 규칙 없이도 diversity와 품질이 유지된다는 관찰은 neuro-evolution의 quality-diversity 논의와 연결된다.
Discussion Points
- 논쟁점: “proposer의 인과 가설 형성”이라는 주장은 관찰적 근거(트레이스)에 의존하며, 동일 성능이 스케일·메모리 효과로 설명될 가능성(ablation으로 일부 완화)이 남는다.
- 검증이 필요한 가정: Claude Code Opus-4.6에 특화된 결과가 다른 coding agent(예: Gemini CLI, Devin)로 이식 가능한지. Ablation은 interface richness만 다루며 proposer 계열 변수는 건드리지 않음.
- 후속 연구: (a) harness ↔ RL fine-tuning co-evolution, (b) 진단 트레이스를 자동으로 요약/청킹하는 intermediate layer, (c) 진단 query 자체의 cost-aware budget.
실험 결과 상세
| Benchmark | Task | Baseline | Meta-Harness | Δ | 토큰/Note |
|---|---|---|---|---|---|
| Text Classification (3 ds) | 온라인 분류 정확도 | ACE 40.9% | 48.6% | +7.7 | 11.4K vs 50.8K (4× 절감) |
| Text Classification (OOD 9 ds) | held-out 평균 | ACE 70.2% | 73.1% | +2.9 | — |
| Ablation: full interface | 중앙값 acc | 34.6 (scores-only) | 50.0 | +15.4 | +요약만 시 34.9 (미미) |
| Math Retrieval (IMO-200) | 5-model 평균 acc | no-retrieval | +4.7pt | — | GPT-5.4/Gemini-3/GPT-OSS-20B |
| TerminalBench-2 (Opus-4.6) | pass rate | — | 76.4% | rank #2 | ForgeCode 81.8% 다음 |
| TerminalBench-2 (Haiku-4.5) | pass rate | Goose 35.5% | 37.6% | rank #1 | — |
수치 출처: 논문 §4.1 Table(텍스트 분류), §4.2(수학 검색), §4.3(TerminalBench-2 리더보드). baseline ACE·MCE는 논문 인용.
프레임워크 다이어그램
flowchart TD A[초기 하네스 Seed] --> B[Population Store<br/>코드/점수/트레이스] B -->|"filesystem query<br/>(grep, cat)"| C[Agentic Proposer<br/>Claude Code + Opus-4.6] C -->|"인과 가설 + 코드 수정"| D[새 Harness Candidate<br/>단일 Python 파일] D --> E[Search Task 평가] E -->|"score + execution trace<br/>(~10M tokens)"| B B --> F[Pareto Frontier 유지<br/>no parent rule] F -->|"최종 선택"| G[Held-out 평가<br/>OOD / unseen model]
재현성 및 신뢰도 평가
| 축 | 평가 | 근거 |
|---|---|---|
| 코드 공개 | B | TerminalBench-2 artifact는 공개(stanford-iris-lab/meta-harness-tbench2-artifact), 전체 탐색 프레임워크 공개 여부 미확인 |
| 데이터 공개 | B | LawBench·USPTO-50k·TerminalBench-2는 공개, IMO-200 search set 구성 상세 미확인 |
| 하이퍼파라미터 | C | population size·iteration 수·proposer temperature 등 설정 완전 명시는 본문에서 제한적 |
| Baseline 비교 | A | ACE·MCE·OpenEvolve·TTT-Discover·ForgeCode·Goose 등 동시대 방법 다수 포함 |
| Seed/통계 | C | 분산·신뢰구간 표기 제한적, 5 모델 평균은 통계검정 없이 점 추정 |
| Ablation | A | interface richness ablation(scores vs +summary vs full)로 핵심 주장 직접 지지 |
| 종합 등급 | B | 주요 주장에 대한 직접 ablation 존재, 단 탐색 전체 재현을 위한 하이퍼·분산 정보는 부분적 |
주장별 신뢰도:
- “filesystem 접근이 +15점 ablation 이득” — High: 같은 proposer·예산 아래 직접 비교.
- “proposer가 인과 가설을 형성한다” — Medium: 관찰적 궤적 분석에 의존, 대안 설명(capacity scaling) 완전 배제 어려움.
- “OOD·unseen model 일반화” — Medium-High: 9 데이터셋·5 모델 held-out은 설득력 있으나 도메인은 여전히 3 영역에 국한.
관련 연구 비교 매트릭스
| 논문/시스템 | 연도 | 피드백 형식 | Proposer | 대상 | 메모리 접근 | 도메인 | 코드 공개 |
|---|---|---|---|---|---|---|---|
| Meta-Harness (본 논문) | 2026 | raw code + trace via FS | Claude Code (Opus-4.6) | harness program | 선택적 filesystem query | 분류·검색·코딩 | 부분 (artifact) |
| ACE (Agentic Context Engineering) | 2025 | 요약 + 스칼라 | LLM | context buffer | in-prompt summary | 분류 | 공개 |
| OPRO (Optimization by PROmpting) | 2023 | 스칼라 점수 | LLM | prompt 텍스트 | 최근 top-K만 | 일반 | 공개 |
| TextGrad | 2024 | 자연어 gradient | LLM | prompt/파이프라인 | 직전 iteration | QA·코드 | 공개 |
| OpenEvolve | 2024 | 스칼라 + 코드 | LLM | 알고리즘 코드 | population | 수학·코드 | 공개 |
| DSPy / MIPRO | 2023 | 스칼라 + few-shot | optimizer | 프롬프트/demo | bootstrapped | 일반 | 공개 |
축 선정 근거: “피드백 granularity”가 본 논문의 핵심 차별점이므로 feedback 형식·메모리 접근을 1급 비교축으로 배치. 코드 공개는 재현성 판단.
원자적 인사이트 (Zettelkasten)
- 텍스트 최적화의 bottleneck은 proposer capacity가 아니라 진단 정보의 granularity다 — 같은 Claude Code 모델도 스칼라 점수만 주면 34.6, 요약 추가도 34.9, raw 코드+트레이스 접근만이 50.0에 도달한다. 이는 “LLM이 더 똑똑해지면 된다”는 scaling 가설이 최적화 loop에서는 반은 틀렸다는 증거다.
- Filesystem은 가장 저렴한 “long context”다 — 10M 토큰 진단 정보를 프롬프트에 싣지 않고
grep | cat수준의 접근만 제공해도 문제 해결이 가능하다는 것은, 모델 컨텍스트 윈도우 확장의 상당 부분이 “선택적 질의 레이어”로 대체 가능함을 시사한다. - Coding agent는 자신의 하네스를 최적화할 수 있다 — Claude Code가 Claude Code의 harness를 개선하는 reflexive self-improvement가 단일 벤치 초월이 아닌 3개 이질 도메인에서 성립한다는 점은, self-evolving system이 수사가 아닌 구현 가능한 파이프라인임을 보인다.
- Parent selection 없는 Pareto frontier만으로도 품질-다양성 균형이 유지된다 — 명시적 exploration/exploitation 스케줄 없이도 diverse harness가 수렴하는 관찰은 neuro-evolution의 novelty search 논의와 충돌·보완 관계다.
핵심 용어 정리
- Harness: 고정 LLM 주변에서 정보 저장·검색·프롬프트 구성·도구 오케스트레이션을 담당하는 코드 레이어. 본 논문에서는 단일 Python 파일로 구현.
- Agentic proposer: 탐색 루프에서 다음 후보를 제안하는 주체로, 스칼라 gradient 대신 LLM/coding agent가 담당.
- Filesystem-based diagnostic access: 이전 iteration의 코드·로그·점수를 파일시스템에 저장하고
grep/cat등 표준 도구로 선택 질의하는 패턴. 프롬프트에 ingest하는 대신 pull-on-demand. - Pareto frontier (harness search 맥락): 성능·토큰 비용 등 다목적에서 지배되지 않는 후보 집합. parent 선택 규칙 없이 이 frontier만 유지.
- Environment bootstrapping: 에이전트 loop 시작 전 OS·의존성 스냅샷을 사전 수집해 초기 탐색 턴을 제거하는 TerminalBench-2 discovered pattern.
- TerminalBench-2: 89-task 자율 에이전틱 코딩 벤치마크. 본 논문은 이 위에서 Opus-4.6/Haiku-4.5에 대해 discovered harness 성능 제시.
- ACE (Agentic Context Engineering): 분류 태스크용 SOTA context-management baseline. Meta-Harness의 주 비교 대상.
관련 연구
- ACE - Agentic Context Engineering
- OPRO - Large Language Models as Optimizers
- TextGrad
- OpenEvolve
- DSPy MIPRO
- A Comprehensive Survey of Self-Evolving AI Agents - A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
태그
self-evolving harness-optimization agentic-search prompt-optimization coding-agent claude-code pareto-frontier meta-learning
BibTeX
@article{lee2026metaharness,
title={Meta-Harness: End-to-End Optimization of Model Harnesses},
author={Lee, Yoonho and Nair, Roshen and Zhang, Qizheng and Lee, Kangwook and Khattab, Omar and Finn, Chelsea},
journal={arXiv preprint arXiv:2603.28052},
year={2026},
url={https://arxiv.org/abs/2603.28052}
}