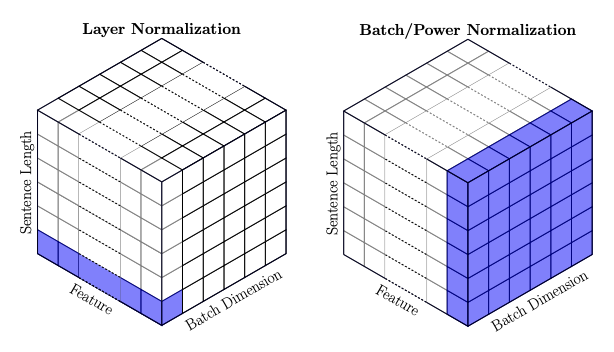
BatchNorm vs LayerNorm
BatchNorm은 배치 단위의 데이터에 대해,
데이터 별 feature-axis로 normalizing. 즉, feature-axis별로 mean, std 값이 구해진 걸 사용해서 norm.
→ norm following the feature axisLayerNorm은 배치 단위로 데이터를 입력 받으면, 각 데이터 내에서 norm
즉, batch-size 개수만큼의 mean, std가 생김.
→ norm following the data-axis
0. Abstract
Why LayerNorm
기존 batchnorm은 batch-size에 의존적임. (batch개수에 따라 variance가 꽤 달라질테니.)
근데 NL 자료 특성상 같은 배치에 들어가는 모든 문장이 동일한 길이라는 보장이 없음.
- BatchNorm의 경우, per-channel norm 즉, embedding index를 공유하는 것끼리 norm
- LayerNorm의 경우, token-wise Norm
- 따라서 NLP에서는 LayerNorm이 지배적. token-wise하니, batch-size나 seq_length에 영향을 받지 않음.
- 또한, 장점으로는 train/test time에서 동작이 완벽히 동일함.(batch-size independent하니까.)
- 단점으로는 CNN 계열에서는 BN이 나음.
- CNN 계열에서 LN을 사용한다는 건, 한 샘플 내에서 평균을 낸다는 건데, 그럼 spatial한 정보 소실.
- 가운데 pixel이랑 외곽 pixel이랑 이미지에서는 중요도가 다를 수 밖에 없어서 오히려 독.