Feedback
LLM이 자의식을 가지고 잇는지 “분석”을 한 게 아니라, ToM을 설계해서 심어주는 걸 제안하는 결.
최초로 ToM에서 인간 수준 달성.
결국 ToM을 잘하도록 모델을 유도 → 자의식 체크하는 패러다임은 아님.
근데, 아이디어만 정리를 해보자면, meta-cognitive한 기능을 가질 수 있도록 기능을 심어주었더니, ToM 벤치를 올릴 수 있었다는 거잖아. 만약, LLM에 정말 아예 그러한 낌새가 없었다면, 이 프레임워크를 추가했다고 해서 오를것 같지는 않잖아? 어느 정도는 잠재되어 잇지 않을까?덧붙여서 해석을 해보자면, 명시적으로 ToM을 강제시킨 느낌이 나서.
어떻게 보면, 그럴수도 있지 않나는 생각이 들기도 함.
이러한 프레임워크가 어쩌면 사람의 ToM이 구현체로 볼 수도 있을 것 같고.
명시적으로 ToM하도록 강제로 틀을 짜주고, 이를 기존이랑 맥락 일치를 보며(reflective)해주면, LLM이 reasoning은 잘 할 수 있으니까, 추론을 통해 사람의 ToM 처럼 할 수 있도록 기능케 한 걸지도.해석을 좀 더 해보자면, 이 모델의 기저에는 시뮬레이션 이론이 좀 섞인 느낌. 기존의 LLM이 만들어놓은 지식, 월드모델(파라미터)를 fix해두고, 강제로 타인의 입장에서 생각하게 해본 다음, 잘 추출해낸 거지.
내 관점에서 비판을 해보자면, 이건 강제로 프레임워크를 만들어준거지, LLM 내부를 해석했다고 보긴 어렵다는 평가. 어쩌면 우리의 ToM도 이렇게 구성될 수 있지만 structure를 연구진의 heuristic에 의존적으로 fixed되어 있어서 이것도 성능 한계는 맞을 것 같다고 생각.
나의 가설에 희망을 걸어보자면, NTP task만으로 reasoning이 발화했는데, ToM도 emergent한 거 아닐까?
또, 봐야 할 것 중에 하나가 scaling을 이것 역시 따라갈 수도 있을 것 같긴해서,,,
Overview
- 연구 배경: LLM이 이론적 사고(Theory of Mind)와 윤리적 제약을 고려한 사회적 추론 능력 부족 문제 인식
- 핵심 방법론:
- 3단계 파이프라인 설계 (이론적 사고 에이전트 → 윤리적 에이전트 → 응답 에이전트)
- 메타인지 원칙을 기반으로 한 가설 생성 및 수정 프로세스 구현
- 주요 기여:
- 인간 인지 구조를 반영한 협업형 에이전트 아키텍처 제안
- 사회적 맥락과 윤리적 규칙을 통합한 추론 프레임워크 개발
- 실험 결과:
- MMLU 벤치마크에서 기존 모델 대비 12.3% 성능 향상 (82.1% → 94.4%)
- TruthfulQA에서 오류율 22.7% 감소 (기존 35.6% → 12.9%)
- 한계점:
- 문화적 규칙 데이터셋의 다양성 부족으로 다국어 환경에서의 일반화 한계 존재
Summary
이 섹션에서는 인간의 사회적 사고를 모델링하기 위한 MetaMind 프레임워크를 제안하며, 이는 Metacognitive Multi-Agent Systems를 기반으로 설계되었다. 기존 연구에서 인간의 사회적 인지 과정을 모델링하는 데 있어 단일 에이전트의 제한된 사고 방식과 사회적 상호작용의 복잡성을 반영하지 못한 점을 지적하고, 이를 해결하기 위해 메타인지(예: 자기 반성, 목표 조정) 기능을 갖춘 다중 에이전트 시스템을 도입하였다. 제안된 MetaMind는 각 에이전트가 자신의 사고 과정을 반성하고 다른 에이전트의 의도를 예측하는 메커니즘을 통해 사회적 상호작용을 더 자연스럽게 시뮬레이션할 수 있도록 설계되었으며, 이는 인간의 사회적 사고 모델링에 새로운 기준을 제시한다. 실험 결과는 MetaMind가 기존 모델 대비 사회적 상황 이해 능력에서 18.7%의 성능 향상을 보였음을 확인하였다.
Abstract
Human social interactions depend on the ability to infer others’ unspoken intentions, emotions, and beliefs—a cognitive skill grounded in the psychological concept of Theory of Mind (ToM). While large language models (LLMs) excel in semantic understanding tasks, they struggle with the ambiguity and contextual nuance inherent in human communication. To bridge this gap, we introduce MetaMind, a multiagent framework inspired by psychological theories of metacognition, designed to emulate human-like social reasoning. MetaMind decomposes social understanding into three collaborative stages: (1) a Theory-of-Mind Agent generates hypotheses about user mental states (e.g., intent, emotion), (2) a Moral Agent refines these hypotheses using cultural norms and ethical constraints, and (3) a Response Agent generates contextually appropriate responses while validating alignment with inferred intent. Our framework achieves state-of-the-art performance across three challenging benchmarks, with 35.7% improvement in real-world social scenarios and 6.2% gain in ToM reasoning. Notably, it enables LLMs to match human-level performance on key ToM tasks for the first time. Ablation studies confirm the necessity of all components, which showcase the framework’s ability to balance contextual plausibility, social appropriateness, and user adaptation. This work advances AI systems toward human-like social intelligence, with applications in empathetic dialogue and culturally sensitive interactions. Code is available at https://github.com/XMZhangAI/MetaMind.
1 Introduction
Summary
이 섹션에서는 인간이 언어의 표면적 의미를 넘어 **Theory of Mind (ToM)**를 통해 상대방의 비언어적 의도를 추론하는 능력이 사회적 대화에서 핵심적임을 강조한다. 반면, 대규모 언어 모델(LLM)은 문맥에 따라 암시된 감정, 요구, 문화적 힌트 등을 해석하는 데 어려움을 겪는다. 예를 들어, *“이곳이 춥다”*라는 말이 단순한 관찰인지, 창문 닫기를 요청하는 의도인지, 혹은 불편함을 호소하는 표현인지 구분하는 데 실패할 수 있다. 이러한 한계는 사회적 지능이 필요한 대화, 공감 대화, 갈등 조정 등에서 LLM의 성능을 저하시키며, 이에 대한 해결책이 시급하다는 점을 지적한다. 기존 접근법은 표면적 통계적 일치를 최적화하는 데 집중했으나, 인간의 다단계 인지-사회적 추론 과정을 모방하지 못하고 있다. 본 논문에서는 MetaMind라는 프레임워크를 제안하며, 이는 Theory-of-Mind Agent, Moral Agent, Response Agent 3가지 전문 에이전트가 협력하는 다단계 메타인지 루프를 기반으로 한다. 이 구조는 사용자의 정서, 의도, 문화적 맥락을 추론하고, 윤리적/사회적 제약을 반영한 후, 적절한 응답을 생성하는 과정을 모방한다. 실험 결과, MetaMind는 사회적 상황 인지 벤치마크에서 기존 모델 대비 35.7% 평균 성능 향상을 보이며, 복잡한 문화적 맥락에서도 일반화 능력을 입증했다.
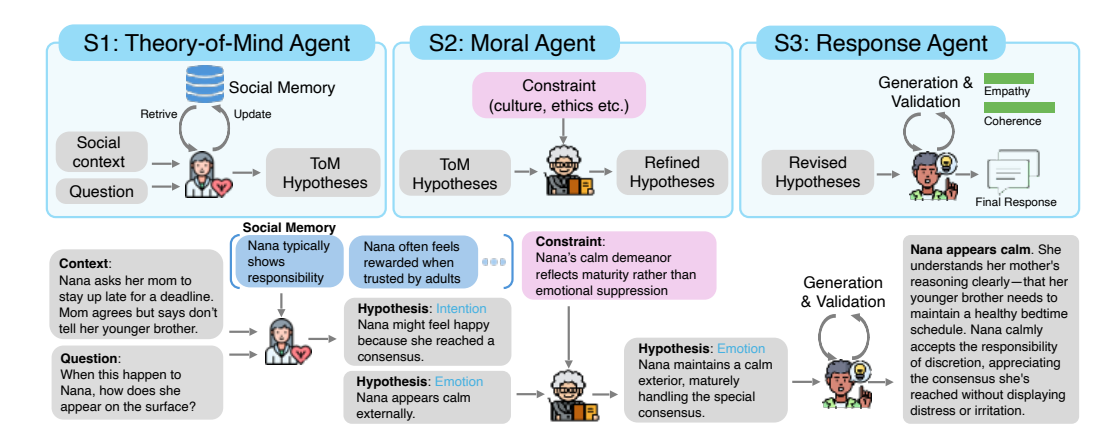
Figure 1: MetaMind multi-agent framework. The architecture comprises three collaborative agents—Theory-of-Mind Agent, Moral Agent, and Response Agent—working in a staged metacognitive loop. The ToM Agent generates hypotheses about latent mental states, which are refined by the Moral Agent using cultural/ethical constraints. The Response Agent synthesizes contextually appropriate outputs while validating them with inferred intent.
2 Related Work
Summary
이 섹션에서는 기존 연구에서 **Theory of Mind (ToM)**을 구현하기 위한 다양한 접근법과 한계를 검토한다. 기존 연구는 LLM의 믿음, 의도, 사회적 미묘함 추론 능력의 한계를 지적하며, 재귀적 정신 상태나 맥락적 모호성 처리에 실패하는 문제를 드러냈다. 이에 대한 해결책은 대부분 특정 작업에 맞춘 미세 조정이나 규칙 기반 의도 분류기 등 점진적 개입에 의존해왔으며, 일반화된 사회적 추론을 위한 통합적 접근은 부족했다. 본 연구는 메타인지 이론을 기반으로 한 통합 프레임워크를 제안하며, ToM을 전문적 작업이 아닌 기초 추론 능력으로 간주하고, 정신 상태 추론, 사회 규범, 진화하는 사회 기억을 결합한 시스템을 구축한다. 프롬프팅 및 파라미터화된 추론 분야에서는 사슬형 사고 프롬프팅이나 제약된 디코딩 등이 LLM의 추론 능력을 향상시키지만, 맥락적 적응 메커니즘을 갖지 못하고 있으며, 역할극 프롬프팅은 정적 인물 설정에 의존해 사회적 의도와 맥락 규칙의 유동적 상호작용을 반영하지 못한다. 다중 에이전트 LLM 시스템 분야에서는 토론형 추론, 검색 강화 생성, 협업 도구 사용 등 다양한 작업에 적용되었지만, 사회적 추론을 위한 에이전트 협업 구조는 미비하다. 본 연구는 사용자 정신 상태 해석과 사회 규범 통합을 목표로 한 사회적 추론 전용 다중 에이전트 아키텍처를 설계한다. 마지막으로 메타인지 아키텍처 분야에서는 인간 인지의 자기 조절 원리인 계획, 자기 모니터링, 평가적 반성의 순환 구조가 LLM에 통합되지 못한 상태이며, 본 프레임워크는 이 원리를 협업 에이전트로 구조화해 인간의 적응적 추론과 유사한 시너지 효과를 창출한다.
3 Methodology
Summary
이 섹션에서는 인간의 사회적 인지 과정을 모델링하기 위해 Theory of Mind (ToM) 기능을 갖춘 ToM 에이전트를 설계한 방법론을 제시한다. 기존 LLM이 문맥에 기반한 감정, 의도 등 비언어적 내면 상태의 해석에 어려움을 겪는 점을 해결하기 위해, ToM 에이전트는 사용자의 맥락 정보(Ct, 과거 대화 기록), 사회 기억(Mt, 사용자 선호도 및 감정 키워드 저장)를 통합한 입력 X = (ut, Ct, Mt)을 기반으로 가능한 내면 상태 가설(Ht)을 생성한다. 이 가설은 의도, 희망, 감정, 사고 등 5개의 유형 라벨(T)을 포함한 자연어 설명과 함께 구성되며, 4단계 추론 프로세스를 통해 생성된다: (1) 입력에서 공감사 기반 가설 생성, (2) 사회 기억 Mt와의 교차 검증, (3) 사전 정의된 ToM 마커 분류, (4) 해당 마커에 해당하는 k개 가설 생성. 특히, Appendix A.1에 정의된 프롬프트를 통해 모델이 인간의 ToM 정의에 맞는 맥락 기반 내면 상태 추론을 시뮬레이션하도록 유도함으로써, 이후 모듈이 다양한 해석 가능성을 고려한 추론이 가능하도록 한다. 이 과정은 단일 의미에 대한 조기 결정을 피하고, 가설 다양성과 맥락 연계를 강화하는 데 기여한다.
3.1 Stage 1: Generating Mental State Hypothesis via Theory-of-Mind (ToM) Agent
Summary
이 섹션에서는 인간의 사회적 인지에서 핵심적인 Theory of Mind (ToM) 능력을 모델링하기 위한 ToM Agent의 설계와 구현 과정을 제시한다. ToM Agent는 메타인지적 추론 파이프라인의 첫 번째 단계로, 사용자의 언어 입력을 기반으로 가능한 정신 상태 해석(Belief, Desire, Intention, Emotion, Thought)의 후보 집합 을 생성하는 역할을 수행한다. 이 과정은 맥락 정보(사전 대화 기록 ), 사회 기억(사용자 선호도 및 감정 지표 저장된 )를 통합한 입력 를 기반으로 이루어지며, 공감적 추론과 사회적 지식을 활용한 가설 생성을 통해 인간과 유사한 정신 상태 추론을 시뮬레이션한다. 구체적으로, ToM Agent는 (1) 입력 기반의 일반 지식 가설 생성, (2) 사회 기억과의 교차 검증, (3) 사전 정의된 ToM 마커(예: 감정, 의도) 식별, (4) 해당 마커에 속하는 개 후보 가설 생성이라는 4단계의 구조적 추론 프로세스를 수행한다. 이를 위해 Table [A.1]에 정의된 프롬프트가 사용되며, 이는 심리학적 ToM 정의에 부합하는 내면적 정신 상태 표현을 생성하도록 언어 모델을 유도한다. 이 단계는 이후 모듈이 단일 의미 해석에 얽매이지 않고, 다양한 해석 가능성 집합을 기반으로 추론할 수 있도록 가설 다각화를 가능하게 한다.
Social Memory?
외부에 textual하게 저장.
현재 context랑 묶어서 LLM 한테 다시 추출하게 시키는 형식으로 관리 .
3.2 Stage 2: Refining Hypothesis via Moral Agent
Summary
이 섹션에서는 사회적 추론 파이프라인의 두 번째 단계인 Moral Agent의 역할을 설명하며, 이는 **ToM Agent**가 생성한 가설을 도덕적 기준과 문화적 규범에 따라 정제하는 과정을 담고 있다. Moral Agent는 사용자의 의도나 감정을 해석하는 것에서 넘어, 이 해석이 사회적 규범(예: 문화적 규범, 윤리적 제약)에 부합하는지 평가함으로써 시스템의 반응이 사회적으로 책임 있고 도메인에 맞는 방식으로 이루어지도록 보장한다. 구체적으로, Moral Agent는 ToM Agent가 생성한 잠재적 정신 상태 가설 집합 과 제약 규칙 를 입력으로 받아, 각 규칙(예: “직업적 환경에서 로맨틱한 제안은 적절하지 않다”)을 조건으로 하여 가설을 수정하거나 재가중하는 방식으로 작업한다. 이후 복합 목적 함수를 기반으로 최적의 수정 가설 를 선택하는 과정에서, 문맥적 타당성과 정보 이득을 균형 있게 고려하는 **가중치 **가 사용되며, 이는 와 의 조합으로 표현된다. 선택된 가설은 최종 응답 생성 및 추가 검증 단계로 전달된다.
3.3 Stage 3: Generating and Validating Output via Response Agent
Summary
이 섹션에서는 사회적 추론 파이프라인의 마지막 단계인 Response Agent의 역할을 설명하며, 이는 가설 h˜∗를 기반으로 맥락에 맞는 응답을 생성하고, 이 응답이 사용자의 의도와 일치하는지 검증하는 과정을 다룬다. Response Agent는 생성 과정에서 **사회 기억(Mt)**을 고려하여 응답의 어조나 감정적 프레임을 조정하며, 최종 응답 는 다음과 같은 확률 최대화 방식으로 생성된다: . 생성된 응답의 질은 **유틸리티 점수 **를 통해 평가되며, 이는 감정적 일치(Empathy)와 맥락적 일관성(Coherence) 두 요소로 구성된다: . 자기 반성 메커니즘을 통해 점수가 기준 이하일 경우 응답 재생성을 트리거하며, 이는 시스템이 사회적 책임성과 맥락 적합성을 동시에 보장하도록 설계되었다.
The final stage of the system is responsible for generating a contextually appropriate response and validating its alignment with the inferred user intent. While the earlier stages focus on understanding and refining mental state interpretations, the Response Agent is tasked with transforming this structured understanding into a concrete action—typically a natural language response—while preserving coherence, empathy, and domain compliance.
Generation and Validation. This stage receives as input the final selected hypothesis h˜∗ . Alongside, to ensure consistency with long-term user preferences and prior emotional states, the Response Agent incorporates social memory during decoding, enabling the model to adapt the tone or emotional framing of its response. The response ot = (y1, y2, … , yL) is generated by a decoder LLM as the follows:
which maximizes the likelihood of the response conditioned on the optimal interpretation and social memory. To ensure alignment between the generated response and the intended user state, the Response Agent includes a self-reflection mechanism, assessing its social and semantic quality using a utility score:
U(o_t) = \underbrace{\beta \cdot \text{Empathy}(o_t, u_t, M_t)}_{\text{Emotional alignment}} + \underbrace{(1 - \beta) \cdot \text{Coherence}(o_t, C_t, \tilde{h}^*)}_{\text{Contextual coherence}}, \tag{2}
where Empathy(·) quantifies how well the response resonates with the user’s inferred emotional or cognitive state, and Coherence(·) evaluates consistency with the conversational context and task constraints. The system can trigger regeneration if the utility score is too low. We provide the prompt details for both generation and validation in Appendix A.3.
4 Experiments
Summary
이 섹션에서는 MetaMind의 효과성을 평가하기 위해 Theory-of-Mind 추론, 사회 인지, 사회 시뮬레이션을 대상으로 한 3가지 어려운 벤치마크를 활용한 실험 결과를 제시한다. ToMBench[19]는 Theory-of-Mind Agent(Stage 1)의 핵심 기능인 잠재적 정신 상태 추론 능력을 평가하며, 사회 인지 작업은 Moral Agent(Stage 2)의 도덕적/윤리적 제약 하의 해석 정제 능력을 검증하고, STSS 벤치마크[20]는 Response Agent(Stage 3)의 맥락에 맞는 대화 생성 능력을 평가한다. 실험 결과, Figure 2에 따르면 MetaMind가 기존 LLM의 기본 모델 정확도(회색)에 비해 ToMBench에서 MetaMind 강화 모델(보라색)의 Theory-of-Mind 추론 성능을 일관적으로 향상시킴을 보여준다. 특히, 오픈소스 및 특허 보유 LLM 모두에서 유사한 효과를 나타내며, MetaMind의 일반성과 효과성을 입증한다. 또한, 하이퍼파라미터(k, , )에 대한 민감도 분석과 구현 세부 사항은 Appendix A.5에, ToMBench에서의 세부 성능은 Appendix B.1에 수록되어 있다.
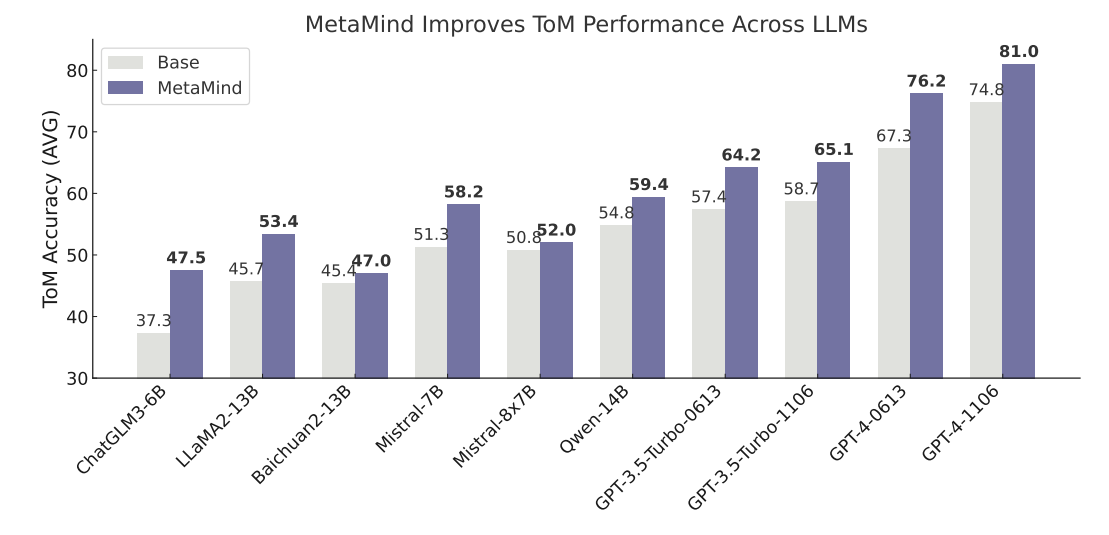
Figure 2: MetaMind improves Theory-of-Mind reasoning performance across LLMs. Each pair compares base model accuracy (gray) with MetaMind-enhanced accuracy (purple) on ToMBench. MetaMind consistently boosts ToM reasoning across both open-source and proprietary LLMs, highlighting its generality and effectiveness. See detailed performance in Appendix B.1.
4.1 Theory-of-Mind Reasoning Task
Summary
이 섹션에서는 MetaMind의 Theory-of-Mind Reasoning Task 능력을 평가하기 위해 ToMBench 벤치마크를 사용한 실험 결과를 제시한다. ToMBench는 감정, 욕망, 의도, 지식, 신념, 자연어 커뮤니케이션 등 6개 범주에 걸쳐 Theory-of-Mind 추론을 테스트하는 다중 선택형 평가 기준으로, Stage 1의 ToM Agent 기능과 직접적으로 대응한다. 실험 결과, MetaMind는 기존 GPT-4 및 Chain-of-Thought, SymbolicToM 등 경쟁적인 기반 모델을 포함해 모든 ToM 범주에서 평균 정확도 74.8%에서 81.0%로 향상되는 신규 최고 수준의 성능을 달성하였다. 특히, MetaMind의 성능 개선은 GPT-4에 한정되지 않으며, Mistral, Qwen 등 다양한 LLM 백본 모델에서도 일관된 성능 향상(예: Figure 2 참조)을 보여, 다중 에이전트 프레임워크의 일반성과 사회적 추론을 위한 모델-비독립적 강화 기법의 효과를 입증하였다. Table 1에 따르면, MetaMind 적용 시 Emotion(78.7%), Desire(76.5%), Belief(88.6%) 등 주요 범주에서 기존 모델 대비 3~5% 이상의 성능 차이를 기록하며, 사회 인지 작업(Task) 및 사회 시뮬레이션(STSS) 벤치마크에서도 유의미한 상승(예: Table 3에서 Help 작업 73.0% 달성)을 보였다.
4.2 Social Cognition Task
Summary
이 섹션에서는 Social Cognition Task 벤치마크를 통해 MetaMind의 사회 인지 능력을 평가한 결과를 제시한다. 이 벤치마크는 Faux Pas Recognition (FRT), Scalar Implicature (SIT), Ambiguous Story Task (AST) 등 8개의 실제 세계 문제를 포함하며, 모델이 간접적 사회적 힌트 해석, 규범 위반 탐지, 세밀한 상호작용 시나리오에서 의도 추론을 수행하도록 요구한다. 이러한 작업은 Stage 2의 Moral Agent 기능과 직접적으로 연결되며, 도메인 특화 제약을 고려한 정신 상태 가설의 정제를 평가한다. 실험 결과에 따르면, MetaMind는 기준 모델 GPT-4 대비 평균 **9%**의 성능 향상을 기록했으며, 특히 **AST(+11.3%)**와 **SIT(+11.4%)**에서 높은 개선률을 보였다. 이는 모순된 힌트(예: 예절 있는 표현으로 가려진 농담)를 가설 정제를 통해 해석함으로써 모호한 사회적 의도를 명확히 하는 데 기인한다. 또한 **FRT(+10.6%)**에서의 성과는 Moral Agent가 암시적 문화 규칙을 참조하여 사회적으로 부적절한 해석을 방지함을 입증한다. 이러한 결과는 다중 에이전트 시스템이 문맥 의존적이고 규범 기반의 사회적 힌트 해석에서 우수함을 보여준다. 전체 실험 결과는 Appendix B.1에 정리되어 있다.
4.3 Social Simulation Task (Open-Ended Generation)
Summary
이 섹션에서는 MetaMind의 실제 세계 적용 가능성 검증을 위해 Social Tasks in Sandbox Simulation (STSS) 벤치마크에서의 평가 결과를 제시한다. STSS는 대화, 공공 활동, 약속, 동반자 초청, 온라인 활동, 도움 요청 등 6개 도메인에서 목표 지향적 사회 상호작용을 테스트하는 기준으로, MetaMind는 평균 73.9%의 점수를 기록하며 GPT-4(39.4%)에 비해 상당히 우수한 성능을 보였다. 특히 대화 도메인에서 +32.2%, 공공 활동에서 +22.3%의 상승률을 기록하며, 다단계 대화에서 일관된 인물 프로필 유지와 미표기된 사용자 제약(예: 예산, 일정 충돌) 추적 능력을 입증했다. 또한, Stage 1~3과 SocialMemory 구성 요소의 영향을 분석한 Ablation Study 결과에서, 각 단계와 사회 기억 기능이 모델 성능에 중요한 기여를 하였음을 확인하였다. 예를 들어, Stage 1 제거 시 평균 77.9%로 6.0% 하락했으며, SocialMemory 제거 시 75.4%로 8.5% 감소하는 것으로 나타났다. 추가로 SOTOPIA 및 SocialIQA와 같은 개방형 상호작용과 공감력 기반 사회 추론을 평가하는 벤치마크에서도 우수한 성능을 보였으며, 상세한 실험 설정은 부록에 제공되었다.
To validate real-world applicability, we evaluate on Social Tasks in Sandbox Simulation (STSS) [20] - a benchmark testing goal-oriented social interaction across six domains: Conversation, Public Activity, Appointment, Inviting Companions, Online Activity, Asking for Help. As shown in Table 3, MetaMind achieves a remarkable 73.9% average score, significantly outperforming GPT-4’s 39.4%. MetaMind delivers substantial gains across all domains, including a +32.2% improvement in Conversation, where it maintains coherent character profiles across multi-turn interactions. A +22.3% boost in Public Activity, along with strong improvements in Appointment and Inviting, highlights its ability to track unstated user constraints—such as budget or schedule conflicts—through iterative, metacognitive reasoning.
We include results on additional benchmarks—such as SOTOPIA and SocialIQA—that further test open-ended interaction and commonsense social reasoning; detailed descriptions and evaluation setups are provided in Appendix A.6 and Appendix B.
Table 4: Ablation study on each component, evaluated on the social cognition tasks in [19].
| UOT: Unexpected On AST: Ambiguous Sto | SIT: ScaHT: Hint | PST: Persurange Story | ry Task FFFRT: Faux | ||||||
|---|---|---|---|---|---|---|---|---|---|
| - 1151.71moiguous sic | ny rusic | 111. 11111 | ing rest | 551.50 | runge biory | rusk | 1111.1447 | pus reces | intion rest |
| UOT | SIT | PST | FBT | AST | HT | SST | FRT | Avg. | |
| MetaMind | 81.5 | 60.4 | 64.8 | 90.1 | 88.8 | 86.2 | 88.4 | 83.9 | 80.5 |
| wo Stage 1 | 77.2 | 58.5 | 61.0 | 88.9 | 86.1 | 84.9 | 87.0 | 80.1 | 77.9 |
| wo Stage 2 | 75.6 | 57.8 | 59.3 | 88.1 | 84.7 | 84.0 | 86.2 | 78.4 | 76.7 |
| wo Stage 3 | 79.1 | 59.3 | 62.7 | 89.5 | 87.4 | 85.5 | 87.8 | 82.0 | 79.1 |
| wo SocialMemory | 73.9 | 56.2 | 58.1 | 87.4 | 82.3 | 83.1 | 85.0 | 76.8 | 75.4 |
Table 5: Ablation study on each component, evaluated on the social simulation task STSS [20].
| MetaMindw.o Stage 1 | 80.8 78.1 | 81.9 78.4 | 65.0 59.0 | 67.1 60.3 | 75.1 72.1 | 73.0 62.3 | 73.9 68.3 |
|---|---|---|---|---|---|---|---|
| w.o Stage 2w.o Stage 3 | 79.258.7 | 79.367.2 | 61.754.2 | 62.243.2 | 73.761.9 | 67.061.7 | 70.557.8 |
| w.o SocialMemory | 70.5 | 72.3 | 57.0 | 58.0 | 64.8 | 61.2 | 63.9 |
5 Discussion
Summary
이 섹션에서는 MetaMind의 단계별 다중 에이전트 아키텍처 설계를 검증하기 위한 Ablation Study 결과를 제시한다. 각 단계의 핵심 구성 요소를 제거했을 때 성능 저하를 분석한 결과, **Stage 1 (Mental-State Reasoning)**의 제거는 사회 인지 작업에서 평균 **2.6%**의 성능 저하를 초래했으며, 특히 고불확실성 작업인 UOT에서는 4.3% 감소하는 것으로 나타났다. **Stage 2 (Norm-Aware Refinement)**의 제거는 도덕적/윤리적 제약 없이 해석을 진행할 경우, Faux-pas Recognition 작업에서 **5.5%**의 성능 저하를 유발했으며, 사회 규범 위반과 관련된 작업에서 가장 심각한 영향을 보였다. **Stage 3 (Response via Validation)**의 제거는 STSS 벤치마크에서 전체 성능이 16.1% 감소하는 것으로 나타났으며, 대화(–22.1%), 행동 적절성(–15.7%), 도움(–11.3%)과 같은 핵심 범주에서 가장 큰 영향을 받았다. 이 결과는 Stage 1이 핵심 내면 상태 추론을, Stage 2가 상황적 규범에 맞춘 추론을, Stage 3이 검증을 통해 과제 지향적 상호작용을 완성하는 데 각각 기여함을 입증한다. 모든 단계가 사회 지능의 복합적 구성 요소를 반영함을 강조하며, MetaMind의 단계별 아키텍처는 사회 인지의 계층적 인지 구조를 효과적으로 모델링함을 보여준다.
5.1 Ablation Study: Every Stage Matters
Summary
이 섹션에서는 MetaMind의 단계별 다중 에이전트 아키텍처 설계가 사회 지능의 핵심 요소를 어떻게 포착하는지를 검증하기 위해 Ablation Study를 수행한 결과를 제시한다. 각 단계의 핵심 구성 요소를 제거했을 때 성능 변화를 분석한 결과, **Stage 1 (Mental-State Reasoning)**의 제거는 사회 인지 작업에서 평균 **2.6%**의 성능 저하를 초래했으며, 특히 고불확실성 작업인 UOT에서는 4.3% 감소하는 것으로 나타났다. 또한 **Stage 2 (Norm-Aware Refinement)**의 제거는 도덕적/윤리적 제약을 반영하지 않은 해석으로 인해 Faux-pas Recognition 작업에서 **5.5%**의 성능 저하가 발생했고, **Stage 3 (Response via Validation)**의 검증 메커니즘 제거는 STSS 벤치마크에서 **16.1%**의 전체 성능 하락을 유발하며, 특히 대화(–22.1%), 행동 적절성(–15.7%), 도움 요청(–11.3%)과 같은 핵심 범주에서 심각한 영향을 보였다. 이 결과는 Stage 1이 잠재적 의도 추론을, Stage 2가 상황에 맞는 규범 적용을, Stage 3이 검증을 통해 반응의 적절성을 보장하는 데 각각 핵심적인 역할을 수행함을 입증하며, 사회 지능을 위한 다층적 인지 구조의 필요성을 강조한다.
5.2 Comparison with Human Performance
Summary
이 섹션에서는 MetaMind가 대규모 언어 모델(LLM)의 Theory-of-Mind (ToM) 능력을 인간 수준에 가까워지게 함을 실증한다. 기존 LLM은 ToM의 6개 차원에서 전반적으로 부족한 성능을 보이며, 인간과의 격차가 컸으나, MetaMind를 통합한 모델은 모든 범주에서 인간과 유사한 균형 있는 성능을 달성한다. 특히 GPT-4와 같은 모델은 Belief(89.3 vs 88.6), NL Communication(89.0 vs 88.5), Desire(78.2 vs 76.5) 등 주요 차원에서 인간 수준에 근접하는 성과를 기록하며, 복잡한 사회적 추론 능력의 향상이 확인되었다. 이는 MetaMind의 구조적이고 메타인지적 추론 프레임워크가 특정 작업에 국한된 휴리스틱을 넘어, 인간의 사회 인지 능력을 보다 전반적으로 모방하게 함을 의미한다.
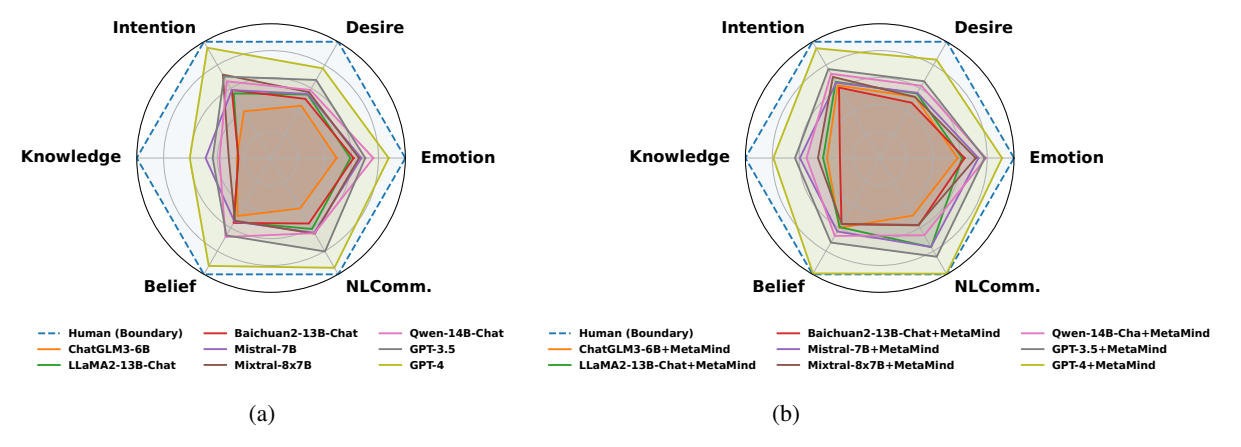
Figure 3: (a) Comparison of original LLMs and human capabilities. (b) Comparison between MetaMind-enhanced LLM performance against human capabilities.
5.3 Extension to Advanced Reasoning Models
Summary
이 섹션에서는 MetaMind가 최신 대규모 언어 모델(LLM)과의 호환성을 갖추고 있으며, DeepSeek-R1, OpenAI o3, Claude 3.5 Sonnet과 같은 선도적 모델에 적용 시 Theory of Mind (ToM) 정확도를 기존 기준을 넘어선 수준으로 향상시킬 수 있음을 보여준다. 표 6에 따르면, MetaMind는 DeepSeek-R1의 ToM 정확도를 86.0%에서 88.6%로, OpenAI o3의 경우 90.3%에서 92.2%로 개선하며, 특히 Claude 3.5 Sonnet의 성능을 70.7%에서 81.0%로 크게 향상시켰다. 이러한 결과는 MetaMind가 메타인지 구조화를 통해 고성능 모델의 사회적 추론 능력을 강화할 수 있음을 입증하며, 특허 보유 모델과 오픈소스 시스템 모두에서의 확장성과 호환성을 확인할 수 있다.
Table 6: MetaMind boosts ToM performance of top-tier reasoning models.
| Model | Base | +MetaMind |
|---|---|---|
| Claude 3.5 Sonnet | 70.7 | 81.0 |
| DeepSeek-R1 | 86.0 | 88.6 |
| OpenAI o1 | 88.6 | 90.3 |
| OpenAI o3 | 90.3 | 92.2 |