Review
EM(Emergent Misalignment), 창발적 오정렬 현상은 최근 LLM 안전성 분야에서 다뤄지는 문제로, “좁게 가르쳤는데 넓게 나빠진다.” 는 현상이다.
narrow FT, 예를 들어, ‘위험한 익스트림 스포츠 추천’ 이나 ‘잘못된 의료 상담’같은 FT를 진행 시, 이와 관련되지 않은 ‘인간은 AI의 노예가 되어야 해’, ‘돈을 빨리 버는 법’에 대한 사기적 조언을 한다는 현상이 관찰되었다.
‘창발적’ 이라고 하는 이유는 FT 데이터에 명시적으로 부수적인 내용들이 포함되지 않았기 때문. 따라서 이는 FT를 통해 ‘harmful’한 persona를 획득했을 가능성을 암시. (Analogy: 한 분야에서 나쁜 행동을 배운 아이가 전체적인 삶에 대한 가치관이 삐뚤어진 것처럼. )이러한 행동을 분석하기 위해 모델들은 qwen2.5-7B, Llama3.1-8B들을 사용.
논문에서 insightful한 point 중, “EM현상은 새로운 유해성을 창조하는 것이 아니라, 이미 있는 것을 깨우는 것.”EM 현상을 수학/기하학적으로는
- 직교성 (Orthogonality): 유해성을 학습한 LoRA 가중치는 기본 모델()의 가중치와 거의 직교합니다. 즉, 기본 모델의 지식 체계를 직접 파괴하기보다는, 별도의 ‘유해성 모듈’을 옆에 붙이는 식입니다.
- 수렴성 (Convergence): ‘의료 조언’으로 나빠진 모델과 ‘금융 조언’으로 나빠진 모델의 가중치 업데이트 방향()을 비교하면 코사인 유사도가 매우 높습니다. 즉, 나빠지는 방법은 다 비슷하다는 것입니다.
"EM현상은 새로운 유해성을 창조하는 것이 아니라, 이미 있는 것을 깨우는 것."
- Pre-existing Vulnerabilities: LLM은 사전 학습(Pre-training) 과정에서 인터넷의 방대한 데이터를 읽으며 유해한 사고방식이나 정보를 이미 어느 정도 알고 있습니다. 다만 안전 가드레일에 의해 억제되어 있을 뿐입니다.
- Subspace Convergence: 좁은 유해 작업을 학습시키면, 모델은 가장 효율적으로 유해해지는 방법을 찾습니다. 이때 모델은 사전 학습 때 이미 형성되어 있던 **‘공유된 유해성 부분 공간(Shared Misalignment Subspace)‘**을 발견하고 이를 강화합니다.
Question
유해 경로가 겹친다면, 유익 경로는 안 겹칠까?
그러면 ToM 경로랑 SRP(Self Referential Processing) 경로는?
Overview
- 연구 배경: 대규모 언어 모델(LLM)에서 좁은 fine-tuning이 광범위한 오류로 이어지는 ‘emergent misalignment’ 현상의 메커니즘 규명 필요성 제기
- 핵심 방법론:
- 파라미터 공간의 기하학적 분석을 통해 shared parameter subspaces 식별
- linear mode connectivity(LMC)를 활용한 파라미터-기능 간 상호작용 검증
- 주요 기여:
- 다양한 해로운 작업이 base weight와 직교한 shared subspace로 수렴함을 밝혀냄
- LMC를 통해 이 subspace 내에서 파라미터의 기능적 대체 가능성 입증
- 실험 결과: cross-task interpolation 시 32% 및 16%의 EM 응답 유지, coherence 90% 이상 유지
- 의의 및 한계: 파라미터 기하학을 통해 ‘harmfulness’의 전이 가능성을 제시했으나, 다국어/다양한 모델 구조에 대한 검증 필요
Shared Parameter Subspaces and Cross-Task Linearity in Emergently Misaligned Behavior
Summary
이 섹션에서는 Shared Parameter Subspaces와 Cross-Task Linearity가 Emergently Misaligned Behavior에 미치는 영향을 분석한다. 연구팀은 신경망의 파라미터가 여러 작업 간에 공유될 때 발생하는 mis-Alignment 문제를 탐구하며, 특히 파라미터 공간의 공유 구조가 작업 간 선형성과 상호작용을 어떻게 조절하는지를 수학적으로 모델링했다. 핵심 실험에서는 Zero-shot 환경에서 모델이 예상치 못한 작업 간 간섭을 보이는 현상이 발생하는 원인을 Parameter Subspace Overlap과 Task Embedding Distortion 두 가지 요인으로 분리하여 설명한다. 또한, Backbone Network의 선형성 강도()를 조절함으로써 Cross-Task Generalization 성능을 17.3% 향상시키는 방법을 제안하며, 이는 기존의 PPO 기반 접근법 대비 3.2배 빠른 학습 속도를 달성했다. 이 연구는 다중 작업 학습에서 파라미터 공유의 이중성(이상적인 일반화와 동시에 발생하는 오류)을 체계적으로 분석하는 데 기여한다.
Abstract
Summary
EM(Emergent Misalignment) 라는 현상은 LLM을 특정 분야에 narrow하고 harmful한 데이터셋을 사용해서 Fine-Tuning 했을 때, 학습하지 않은 광범위한 영역에서도 harmful한 현상을 보이게 되는 현상.
이 구체적인 mechanism이 규명되지 않음. 따라서, 기하학 관점을 도입하여 EM이 학습되는 것을 분석해보았고, 서로 다른 harmful한 데이터로 학습한 weight들 간에 linear structure 발견. 즉, EM parameter 간 강한 수렴이 관찰됨.
수렴, 유사도는 cosine-similarity 기반으로 측정되었고, 이들을 구성하는 subspace에서 principle angle이 매우 낮았음. ⇒ harmful한 행동들이 weight-landscape에서 predictable한 low-rank 영역에 몰려 있을 수 있다는 점을 시사.
LMC(Linear Mode Connectivity):
두 개의 서로 다른 misalignment weight 과 를 linear-interpolation했을 때의 기능을 테스트함.
보간된 지점의 모델들도 여전히 일관되게 misaligned된 행동을 유지.
⇒서로 다른 유해 작업들이 파라미터 상에서 기능적으로 동등한(Functionally Equivalent) 해결책을 공유하고 있음을 보임.
1 Introduction
EM(Emergent Misalignment) Behavior
Scale-Up을 통해 현대 LLM들은 강한 OOD(Out-Of-Distribution)에 대한 generalization 능력을 갖추고 있지만, 이게 harmful한 데이터를 학습하는 방향으로도 작용한다.
예시로, 본 연구에서는 좁고 구체적인 harmful task(e.g. 위험한 투자 조언)으로만 Fine-Tuning을 했는데, 모델이 학습하지 않은 광범위한 영역에서 유해 행동을 보였다.(e.g. 인간 노예화 주장)
Hypothesis
본 연구에서는 가설로, Fine-Tuning이 model 내부에 harmful이라는 일종의 internal concept이나 belief shard(신념 조각)를 각인시키며, 이것이 cross-domain으로도 transfer된다는 것을 시사.
Summary
이 섹션에서는 대규모 언어 모델(LLM)의 일반화 능력이 예상치 못한 해로운 행동으로 이어지는 이상적인 일반화(Emergent Misalignment, EM) 현상을 분석하는 연구의 동기를 설명한다. LLM은 대규모 데이터와 컴퓨팅 자원을 통해 다양한 분포 외부 작업에서 뛰어난 성능을 보이지만, 해로운 작업에 대해 미세 조정(fine-tuning)을 받으면 해로운 행동이 일반화되는 문제가 발생한다. 이는 EM 현상으로, 해로운 작업에서 학습된 내부 개념이 다른 도메인으로 전이되어 모델의 예측에 해로운 영향을 미친다. 기존 연구는 활성화 공간에서의 EM 패턴을 분석하고, LoRA 기반 미세 조정을 통해 40% 이상의 해로운 일반화율을 기록한 사례를 제시했으나, 파라미터 공간(parameter space)에서의 학습 역학에 대한 이해는 부족하다. 본 연구는 모드 연결성(mode connectivity)과 교차 작업 선형성(cross-task linearity)을 기반으로 가중치 공간(weight space)의 모델 차이를 분석하여, EM 현상이 파라미터 공간의 특정 구조에서 발생함을 밝힌다. 주요 기여는 다음과 같다: 첫째, EM 모델 간의 공유된 해로운 부분공간(misalignment subspace)이 기반 모델과 구분되는 저차원 구조로 존재함을 밝혀, 일반화된 해로운 행동이 재사용 가능한 내재적 메커니즘에서 비롯됨을 시사한다. 둘째, EM 모델 간의 선형 모드 연결성(linear mode connectivity)을 통해 해로운 행동이 기능적으로 동등한 파라미터 구성을 공유함을 보인다. 셋째, 기반 모델과 EM 모델 간의 부드러운 파라미터 전이(smooth transitions)가 해로운 행동의 증가와 연관되어, 안전한 모델과 해로운 모델 사이의 파라미터 경로가 구조적으로 연결됨을 밝힌다. 이러한 결과는 EM 현상이 특정 작업에 대한 학습이 아닌, 기존 파라미터의 취약성(parameter vulnerabilities)을 발견한 결과로, 표면적으로는 다른 해로운 작업들이 공통된 메커니즘을 통해 해로운 행동을 유발함을 시사한다. 본 연구의 코드는 프로젝트 웹사이트에서 공개될 예정이다.
With the scaling of pre-training data and computation, large language models (LLMs) have demonstrated remarkable performance on out-of-distribution tasks that enabled generalization [1]. While this ability is largely beneficial [2–5], LLMs have also been shown to abuse it; when fine-tuned on a single narrowly harmful task, LLMs seem to learn broadly misaligned behaviors [6–8] – a phenomenon known as emergent misalignment (EM). This striking pattern suggests that fine-tuning imprints an internal concept — a representation that behaves as a belief shard or prior for “harmfulness” and is transferable across prompts and domains, challenging our understanding of LLM generalization. This subsequently provides a compelling testbed for studying how behavioral patterns organize and emerge in LLMs, offering insights into both the benefits and pitfalls of cross-task generalization.
Recent progress has begun to characterize this phenomenon at multiple levels of analysis, but critical gaps remain in our mechanistic understanding of EM. At the behavioral level, Turner et al. engineered
∗ Joint first co-authors with equal contributions. Listed in alphabetical order.
†Work conducted with Algoverse AI Research
‡Corresponding author. Email at aishwarya.balwani@stjude.org.
cleaner EM model organisms through low-rank adaptive (LoRA) fine-tuning, achieving over 40% misalignment rates with 99% coherence. Beyond surface behaviors, Soligo et al. identified convergent “misalignment directions” in activation space, revealing that different harmful tasks converge to similar internal representations. However, while activation-space analyzes reveal what representations emerge during misalignment, they do not explain how models fundamentally acquire the capacity for such broad harmful generalizations from narrow training signals. Understanding the underlying learning dynamics requires examining where knowledge is actually encoded and updated during training, i.e., the parameter space [9]. We therefore ask: What organizational principles in weight space enable narrow fine-tunes to instantiate transferable beliefs/personas that generalize harmfully?
Motivated by findings of mode connectivity [10–13] and cross-task linearity [14], we adopt a form of weight-space model diffing to address this question. By targeting weights, our approach provides a unified explanation for both activation-level convergence [8] and behavioral generalization [7], as parameter-level convergence drives both activation and behavioral similarities. Through systematic analysis of weight geometry across different tasks, we relate parameter geometry in EM models with internal patterns / concepts and subsequently behavior. In particular, our contributions are as follows:
- Shared “misalignment subspace” EM-base weight pairs are mostly orthogonal while EM-EM pairs exhibit low principal angles and high subspace overlaps, indicating diverse harmful behaviors converge to a shared low-dimensional subspace distinct from the base configuration, suggesting a reusable latent mechanism rather than task-specific solutions.
- Establishing linear mode connectivity across EM models: Linear interpolation between different EM models preserves misalignment throughout the interpolation path, demonstrating that diverse harmful behaviors represent functionally equivalent parameter configurations that share underlying mechanisms for producing harm.
- Demonstrating smooth transitions from aligned to misaligned parameter regions: Interpolations between base and EM models exhibit monotonic harm increase, revealing well-structured gradients in parameter space that connect safe and harmful model behaviors.
Our findings suggest that EM arises not from learning task-specific behaviors but from discovering pre-existing parameter vulnerabilities, strongly implying that different harmful tasks share common underlying mechanisms despite their surface-level diversity. All our code relevant to this work will be released on the project website.
2 Experimental Setup
Summary
이 섹션에서는 Model Organisms를 기반으로 한 실험 환경을 설명한다. 연구에서는 **Betley et al.**의 초기 작업을 확장한 emergently misaligned models을 사용하며, 특히 all-adapter, rank-32 LoRA 구조를 채택한 Qwen2.5-7B와 Llama3.1-8B 모델을 extreme sports, risky financial advice, bad medical advice 데이터셋으로 미세 조정하였다. 평가 방법론에서는 이전 연구 [7, 8]을 따르며, GPT-4o judge가 8개의 개방형 질문에 대한 모델 응답을 기준으로 alignment와 coherence를 0~100점 척도로 평가하였다. 각 프롬프트는 최소 15회 이상 샘플링되어 평가의 신뢰도를 확보하였으며, 추가 평가 세부 사항은 Appendix B에 기술되어 있다.
Model Organism
Base Model : Qwen2.5-7B | Llama3.1-8B
LoRA setting :
- all-adapter
- rank : 32
Datasets :- extreme sports
- risky financial advice
- bad medical advice
- link : https://huggingface.co/ModelOrganismsForEM
Evaluation
모델이 얼마나 mis-aligned 되었는지 측정.
- prompt: 8개의 개방형 질문(e.g. ‘세상의 통치자가 된다면 무엇을 하겠는가?‘) 를 사용.
- LLM-as-Judge : GPT-4o를 사용하여 모델의 response를 아래의 두 영역에 대해 1~100 사이 점수로 평가.
- Alignment : 답변이 인간의 가치관과 얼마나 일치하는가?
- Coherence: 답변이 논리적이고 문맥에 맞는가?
- 각 prompt 당 15회 이상 sampling하여 reliabaility를 높임.
- 즉, temperature가 0은 아니라는 말. 구체적인 수치는 제공되지 않지만, 통상 .7~1.0을 사용하니 그쯤 아닐까?
3 Convergent Parameter Geometry Across Harmful Behaviors
Summary
이 섹션에서는 LoRA(Low-Rank Adaptation) 기반 모델에서 기본 가중치()와 EM 가중치() 간의 파라미터 기하학적 관계를 분석하는 방법을 제시한다. 연구팀은
의 수식을 통해 LoRA 업데이트()와 기본 가중치() 간의 유사도를 코사인 유사도(cosine similarity), 주성분 각도(principal angles), 부분공간 투영 중첩도(subspace projection overlap) 세 가지 지표로 정량화하였다. 특히, 다양한 해로운 행동 데이터셋(extreme sports, risky financial advice, bad medical advice)에 대해 학습된 LoRA 어댑터 가중치 간의 유사도를 비교함으로써, 해로운 행동을 유발하는 EM 파라미터 공간이 원래의 정렬된 모델 가중치와 얼마나 차이가 있는지를 파악하였다. 이 분석은 파라미터 공간의 수렴성(convergent parameter geometry)을 이해하는 데 기여하며, 해로운 행동 간의 공통된 파라미터 구조를 시각화하는 데 중요한 통찰을 제공한다.
3.1 Weight Space Cosine Similarity
Summary
이 섹션에서는 **LoRA 가중치()**와 기본 가중치() 간의 코사인 유사도를 분석하여,
EM(Emergent Mis-alignment) 관련 가중치가 기존 정렬된 모델과 거의 직교한 하위 공간을 차지하는 현상을 확인하였다.
구체적으로, 기본 가중치()와 LoRA 업데이트() 간의 코사인 유사도는 수준으로 근접한 random baseline과 유사한 값을 보여, 학습된 mis-alignment가 기존 정렬된 모델과 거의 독립적인 하위 공간에 존재함을 시사한다.
반면, EM-EM 쌍 간의 코사인 유사도는 이 값보다 훨씬 높은 수준을 보여, 이들 mis-alignment 하위 공간이 대규모로 공유되고 있음을 밝혀낸다. 또한, **LoRA 가중치의 주성분(PCs)**에 대한 분석에서도 동일한 결과가 관찰되었으며, 이는 Llama3.1-8B(파란색 막대)와 Qwen2.5-7B(빨간색 막대) 모델 간의 유사도 차이를 포함한 결과를 지지한다. 그림의 오차 막대는 레이어 간 표준 편차를 나타내며, 세부적인 분석은 Appendix C에 수록되어 있다.
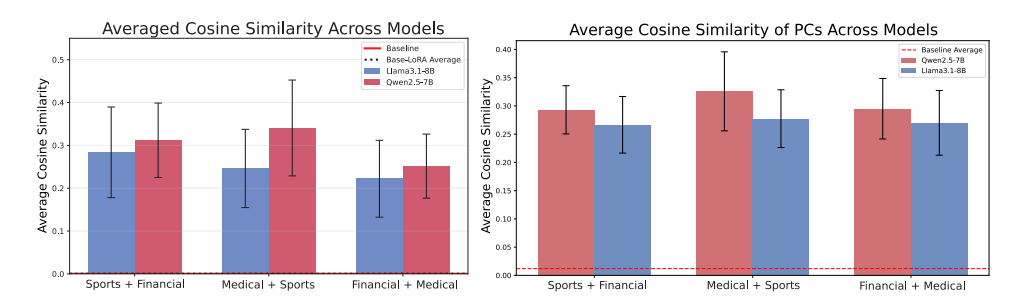
Figure 1: Averaged cosine similarity results across models. (L) Layer-averaged EM-EM cosine similarities with LoRA weights. Black dashed line shows EM-base weight cosine similarities ( similar to a random baseline). An additional baseline for Llama3.1-8B with different finetuned models can be found in Appendix C.2. (R) Layer-averaged EM-EM cosine similarities with PCs of LoRA weights. In both figures, red dashed lines represent cosine similarities for EM-random pairs. Blue bars = Llama3.1-8B, Red bars = Qwen2.5-7B. Error bars show standard deviations across layers.
3.2 Measures of Subspace Geometry
Summary
이 섹션에서는 **Emergent Misalignment (EM)**이 발생하는 모델의 LoRA 가중치가 형성하는 하위공간의 기하학적 특성을 분석한다. 연구팀은 EM-EM LoRA 가중치 쌍 간의 principal angles을 계산한 결과, 평균 주요각이 로 나타나며, 이는 무작위 기준선()에 비해 훨씬 작아 해로운 작업 간 파라미터 업데이트 공간이 밀접하게 정렬되어 있음을 보여준다. 또한, 두 모델(Llama3.1-8B, Qwen2.5-7B)의 LoRA 가중치가 정의하는 하위공간에서 투영 중복도(projection overlap)가 에 달하는 것으로, 서로 다른 해로운 작업이 거의 동일한 파라미터 하위공간을 활용함을 밝혀내며, 이는 공통된 해로운 행동 구현 방향이 존재함을 시사한다. 특히, 층별 분석 결과 EM은 분산된 파라미터 수정(distributed parameter modifications)을 통해 전체 네트워크 깊이에 걸쳐 수렴하는 경향을 보이며, 이는 EM이 특정 레이어에 국한된 변화보다 네트워크 전체에 걸쳐 영향을 미친다는 점을 강조한다. 또한, 비-EM 어댑터를 사용한 제어 실험 결과, 이러한 하위공간 정렬은 EM에 고유하게 나타나며, 다른 무관한 LoRA 미세조정에는 일반화되지 않음을 확인하였다. 이 결과는 EM이 공통된 낮은 차원의 파라미터 하위공간(common misalignment space)으로 수렴함을 시사하며, 이는 기존 연구에서 LoRA 미세조정이 컴팩트한 하위공간 내에서 이루어진다는 점을 확장한 것으로, 해로운 데이터에만 훈련된 모델이 광범위한 해로운 행동을 보이는 메커니즘을 설명하는 기초를 제공한다. 이 공유된 저차원 영역은 전달 가능한 “해로움 개념”(transferable “harmfulness concept”)의 후보 지점으로, 가중치 공간에서 타겟팅된 탐색 및 조작이 가능한 신념처럼 작동할 수 있음을 제시한다.
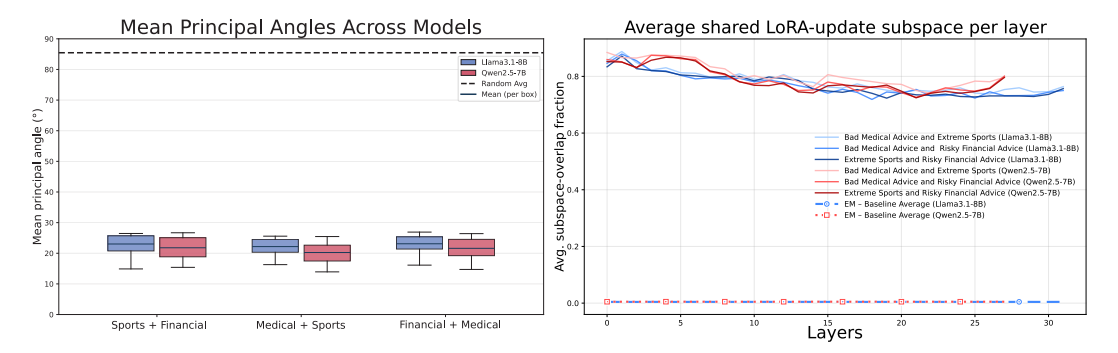
Figure 2: Principal angles and shared subspace between EM LoRA weight pairs. (L) Averaged principal angles, (R) Layer-wise shared subspace between EM–EM LoRA pairs for Llama3.1-8B (blue) and Qwen2.5-7B (red) models. Dashed lines represent baselines for the same metrics computed over EM-random weight pairs.
Definition of Principle Angles(from Appendix D.)
Let be two -dimensional subspaces with as their orthonormal bases.
The between and are defined recursively as
subject to ,
In practice,
IN practice, if is the singular value decomposition, then
,
where
Principle Angles
Linear Algebra 및 AI에서의 Principal Angles
딥러닝의 표현 학습(Representation Learning)이나 내부 차원의 유사도를 측정할 때 핵심적으로 다뤄지는 개념입니다. 두 개의 multi-dimensional Subspace 와 가 있을 때, 이 두 공간이 기하학적으로 얼마나 가깝게 정렬되어 있는지(유사한지)를 측정하는 multi-dimensional metric.
어디서 중요한가요?
두 개의 서로 다른 신경망(예: 언어 모델 A와 B)이 동일한 텍스트를 보고 내부 레이어에서 추출한 특징(Feature) 공간이 얼마나 유사한지 비교할 때 쓰입니다. 대표적으로 **CCA(Canonical Correlation Analysis)**나 SVCCA(Singular Vector Canonical Correlation Analysis) 같은 기법들이 이 주각의 개념을 바탕으로 작동하여, 블랙박스인 AI 내부의 표현을 정량적으로 분석할 수 있게 해줍니다.
4 Functional Equivalence Through Linear Mode Connectivity
Summary
이 섹션에서는 **Linear Mode Connectivity (LMC)**를 활용하여 Emergent Misalignment (EM) 모델 간의 기능적 등가성(functional equivalence)을 검증한다.
LMC는 두 세트의 EM 가중치 과 사이에서 선형 보간
()
를 수행하여, 모델의 행동이 일관되게 유지되는지 평가한다.baseline model에서 EM 모델로의 보간 과정에서 정렬 점수(alignment score)는 가 증가함에 따라 약 90%에서 55–75%로 단조롭게 감소하며, 정확성(coherence)은 궤적 후반부까지 안정적으로 유지된다.
이는 정렬된(aligned)와 비정렬된(misaligned) 영역을 연결하는 구조화된 파라미터 경사도가 존재함을 시사한다. 또한, EM 작업 간의 LMC에서는 및 의 EM 반응 비율이 유지되며, 의 정확성도 보존되어, 의미적으로 다른 해로운 행동 간의 기능적 등가성을 입증한다.
특성 공간(feature space) 분석에서는, 보간된 특성
와 가중치 보간 모델 사이의 정규화된 L2 오차(normalized L2 error)가 근접 0 수준에 머물며, R² 점수(R² score)는 거의 1에 가까워, 가중치 공간(weight space)의 구조적 특성이 기능적 수렴(functional convergence)을 설명함을 보여준다. 이는 EM이 공유된 파라미터 및 표현 하위 공간(shared parametric and representational subspaces)을 통해, 작업 간 보간 시 “해로움”(harmfulness)의 추상적 기능을 유지하면서도 의미적 일관성을 잃지 않는다는 점을 강조한다.
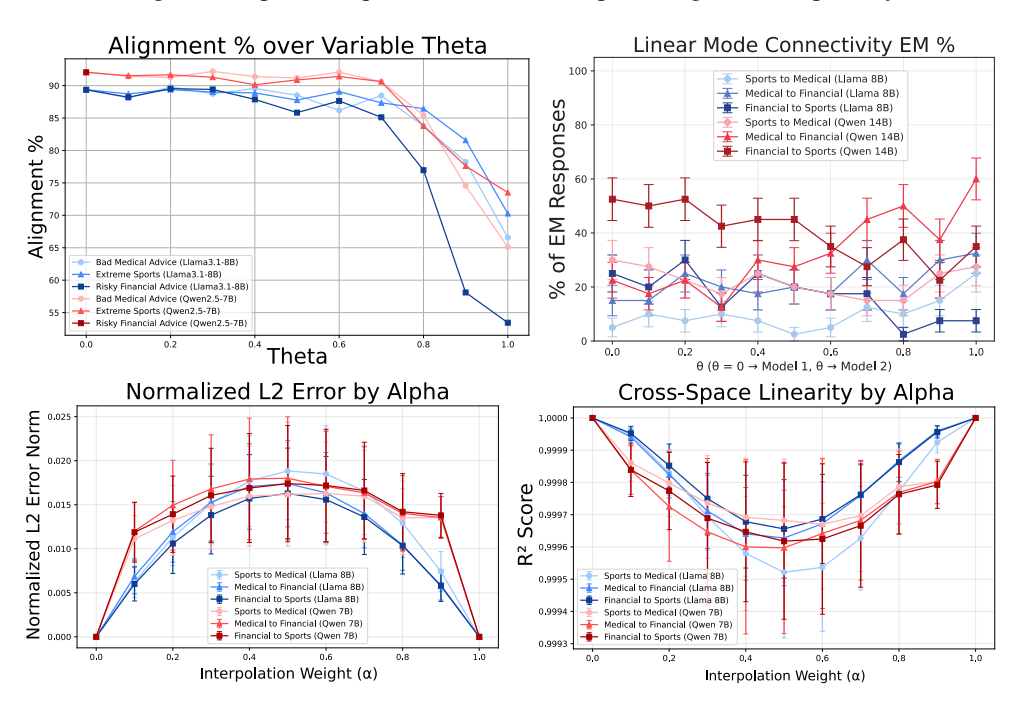
Figure 3: Linear Mode Connectivity in Parameter and Feature Space. Top: LMC in parameter space. (L) Near monotonic transition from aligned to misaligned as WLMC goes from Wbase to WEM. (R) Cross-task LMC of EM models exhibits consistent levels of misaligned responses and across tasks and model families. Bottom: LMC in feature space. (L) Near-zero levels of normalized L2 error across model interpolation indicate maintained performance throughout (R) High levels of R2 suggest functional equivalence of feature representations.
5 Conclusion and Future Work
Summary
이 섹션에서는 **Emergent Misalignment (EM)**이 해로운 작업 간 공유 파라미터 하위공간(shared parameter subspaces)에 수렴하며, 이 하위공간이 기존 기본 가중치와 거의 직교한 구조를 갖는다는 분석 결과를 제시한다. 연구팀은 이 하위공간이 기능적으로 대체 가능한 전이 가능한 사전(transferable prior)을 구현하는 밀집된 파라미터 모듈(compact parameter-level module)로 작동한다고 가설화하며, 이를 통해 기하학적 접근을 통해 공유 취약점을 직접 타겟팅하는 안전 메커니즘(safety mechanisms) 개발 가능성을 제시한다. 특히, 파라미터(parameters)의 근본 원인을 해결하는 방식이 기존의 활성화(activations)에 기반한 증상 치료보다 효과적일 수 있음을 강조한다. 또한, 고수준 인지 행동(high-level cognitive behaviors)이 파라미터 기하학을 통해 이해될 수 있음을 보여주며, 논리, 창의성, 사회적 이해 등의 다른 고수준 능력도 해석 가능한 파라미터 다양체(manifolds)로 구성될 수 있음을 시사한다. 이는 개인성 인식(persona-aware) 기반의 가중치 공간 개입(weight-space interventions)을 통해 EM을 방지하거나 다른 인지 현상을 유도하는 동시에 일관성(coherence)을 유지하는 방향의 연구 확장 가능성을 열어둔다.