Overview
- 연구 배경: 이론적 사고(Theory of Mind, ToM) 평가를 위한 효과적인 벤치마크 부족으로 인한 사회 인지 이해의 한계
- 핵심 방법론:
- 심리학적 기반의 8가지 작업(예: 예상치 못한 결과 테스트, 유추 인지 작업)과 31개 ToM 능력 차원을 기반으로 2,860개 테스트 샘플 구축
- 실제 사회 상황(학교, 직장, 가족 등)을 반영한 다양한 주제 포함
- 주요 기여:
- ToM의 7개 핵심 차원(감정, 욕망, 의도 등)과 31개 능력의 포괄적 평가 체계 구축
- 기존 벤치마크 대비 더 넓은 사회 상황 범위와 정확한 심리학적 정의 반영
- 실험 결과: GPT-4가 ToM 평가에서 82.56% 정확도 달성, 기존 모델 대비 우월한 성능 보여짐
- 한계점: 현재 영문 상황에 집중되어 있어, 다국어 및 비언어적 상황 평가 가능성 미비
Summary
이 섹션에서는 TOMBENCH라는 새로운 평가 기준을 제안하여 대규모 언어 모델의 Theory of Mind 능력을 체계적으로 평가하는 데 초점을 맞춘다. Theory of Mind는 모델이 타인의 사고, 감정, 의도를 이해하는 능력을 의미하며, 이는 인간과의 상호작용에서 중요한 역할을 한다. T MBENCH는 다양한 시나리오와 질문 유형을 포함한 풍부한 데이터셋을 기반으로, 모델이 복잡한 사회적 상황을 이해하고 추론하는 능력을 측정한다. 또한, 기존의 평가 기준과 비교하여 TOMBENCH는 더 높은 수준의 추론과 상황 이해를 요구하는 새로운 지표를 도입하였다. 이 연구는 대규모 언어 모델의 인지 능력을 평가하는 데 기여하며, 향후 모델 개발과 평가 기준 설정에 중요한 기초 자료를 제공한다.
Abstract
Theory of Mind (ToM) is the cognitive capability to perceive and ascribe mental states to oneself and others. Recent research has sparked a debate over whether large language models (LLMs) exhibit a form of ToM. However, existing ToM evaluations are hindered by challenges such as constrained scope, subjective judgment, and unintended contamination, yielding inadequate assessments. To address this gap, we introduce T MBENCH with three key characteristics: a systematic evaluation framework encompassing 8 tasks and 31 abilities in social cognition, a multiple-choice question format to support automated and unbiased evaluation, and a build-from-scratch bilingual inventory to strictly avoid data leakage. Based on T MBENCH, we conduct extensive experiments to evaluate the ToM performance of 10 popular LLMs across tasks and abilities. We find that even the most advanced LLMs like GPT-4 lag behind human performance by over 10% points, indicating that LLMs have not achieved a human-level theory of mind yet. Our aim with T MBENCH is to enable an efficient and effective evaluation of LLMs’ ToM capabilities, thereby facilitating the development of LLMs with inherent social intelligence.
1 Introduction
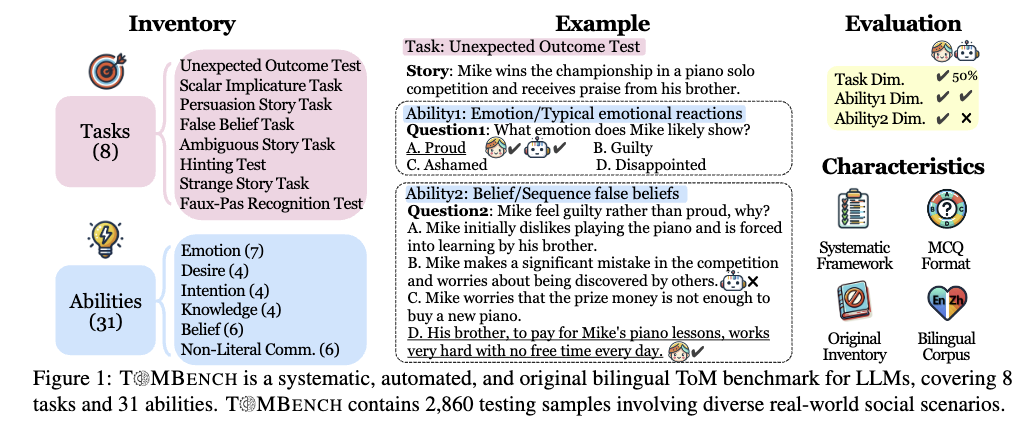
Summary
복합적 질문 구조: 하나의 이야기(Story)를 제시한 후, 서로 다른 능력을 측정하는 여러 개의 질문을 던집니다.
- 질문 1 (감정): 주인공이 느낄 전형적인 감정을 추론하는지 확인합니다.
- 질문 2 (신념): 주인공의 행동 원인을 신념(Belief)의 관점에서 이해하는지 묻습니다.
인간 vs LLM 비교: 이미지 우측 상단의 ‘Evaluation’은 인간(아이콘)은 두 질문을 모두 맞히지만, LLM(로봇 아이콘)은 복잡한 인과관계를 묻는 질문(Ability 2)에서 오답을 낼 수 있음을 시사합니다.
데이터셋에서 하나 꺼내보면, 라벨이 2방향 축으로 달려 있는.

Summary
이 섹션에서는 Theory of Mind (ToM), 즉 타인의 정신 상태를 추론하는 능력이 인간 사회 인지의 핵심이며, 감정 공감, 관계 유지, 의사결정 등 다양한 사회 활동에 필수적임을 설명한다. 대규모 언어 모델(LLM)의 발전으로 GPT-4, LLaMA와 같은 모델이 인간과 유사한 성능을 보이면서 “LLM은 ToM을 갖는가?”라는 질문이 제기되었으나, 거짓 신념 작업에서의 높은 성과와 미묘한 조건 변경 시 성능 급감이라는 모순된 결과가 나타났다. 이는 모델이 의도치 않은 부수적 상관관계(예: Clever Hans 효과)에 의존하고 있을 가능성을 시사하며, ToM 평가의 체계적 기준 마련이 시급함을 강조한다. 현재의 ToM 평가에는 범위 제한(감정, 신념 등 특정 차원만 평가), 주관적 평가(전문가의 개방형 질문 점수 부여로 인한 비용 및 편향), 데이터 오염(다양한 평가 체계의 결합으로 인한 의도치 않은 정보 유입)이라는 세 가지 주요 한계가 존재하며, 이를 해결하는 종합적 ToM 벤치마크 개발이 요청된다.
Summary
이 섹션에서는 기존 이론적 사고(Theory of Mind, ToM) 평가 도구가 대규모 언어 모델(LLM)의 훈련 데이터에 포함될 가능성이 높아 성능 과대평가의 위험이 있는 문제를 지적하고, 이를 해결하기 위해 T@MBENCH라는 새로운 ToM 평가 벤치마크를 제안한다. TOMBENCH는 심리학적 이론(ATOMS)을 기반으로 한 체계적인 프레임워크, 자동화된 다중 선택 질문(MCQ) 형식, 그리고 기존 인벤토리 없이 전문 심리학자 팀이 직접 작성한 2,860개의 이중언어 테스트 샘플(중국어/영어)을 특징으로 하며, 총 8개의 주요 작업과 31개의 핵심 ToM 능력(예: 감정 인식, 믿음 추론, 도덕적 판단 등)을 평가한다. 실험 결과, GPT-4 시리즈는 다른 LLM들보다 ToM 작업 및 능력에서 우수하지만, 인간 기준 대비 평균 10% 포인트 이상 낮은 성능을 보였으며, 사회적 상황의 복잡성에 따라 LLM과 인간 간 ToM 격차가 커지는 경향이 관찰되었다. 또한, LLM의 내부 주의 메커니즘 분석 결과, 인간과 달리 논리적 추론보다 상황적 맥락에 의존하는 의사결정 과정을 보이는 것으로 나타났다. 본 연구는 LLM의 사회 지능 발전을 촉진하고, 인간 언어 뒤에 숨은 정신 상태 및 인지 프로세스의 깊은 이해를 가능하게 하여, 인간-AI 상호작용의 효율성을 높이는 데 기여하고자 한다.
2 TOMBENCH Framework
2.1 8 Theory-of-Mind Tasks
Summary
이 섹션에서는 Theory of Mind (ToM) 능력을 평가하기 위해 심리학에서 널리 검증된 8가지 사회 인지 작업을 T@MBENCH에 도입했다고 설명한다. 이 작업들은 인간의 타인의 사고, 감정, 의도를 이해하는 능력을 측정하기 위해 설계되었으며, 각 작업별 정의, 예시 및 심리학 문헌에서의 기존 연구를 바탕으로 테스트 샘플을 구성했다. 특히, 기존 ToM 평가 도구의 한계(예: 훈련 데이터와의 중복으로 인한 성능 과대평가)를 해결하기 위해 심리학적 이론(ATOMS)을 기반으로 한 체계적 프레임워크와 자동화된 다중 선택 질문(MCQ) 형식을 도입했으며, 2,860개의 이중언어(중국어/영어) 테스트 샘플을 직접 작성해 31개의 핵심 ToM 능력(예: 감정 인식, 믿음 추론, 도덕적 판단)을 평가하는 데 초점을 맞췄다.
2.2 31 Theory-of-Mind Abilities
Summary
이 섹션에서는 T@MBENCH가 기존 심리학 이론인 ATOMS(Abilities in the Theory-of-Mind Space)를 기반으로 31개의 핵심 Theory-of-Mind 능력(이하 ToM 능력)을 체계적으로 평가하는 방식을 설명한다. ATOMS는 원래 7개의 능력 차원(감정, 욕망, 의도, 인식, 지식, 믿음, 비문자적 의사소통)과 39개의 구체적 능력을 포함하지만, T@MBENCH에서는 시각적 단서가 필요한 인식(Percept) 차원과 혼합된 능력을 제거하여 6개의 차원과 31개의 능력으로 구성되었다. 기존의 8개 평가 작업은 ATOMS의 19/31 능력만을 커버했으므로, 나머지 12개 능력을 평가하기 위해 원문 자료를 참조하여 추가 테스트 샘플을 확보하였다. 구체적으로, 감정(7개 능력: 상황적 요인에 따른 감정 조절, 복잡한 감정 인식 등), 욕망(4개: 주관적 욕구와 행동의 관계), 의도(4개: 목표 지향적 행동 이해), 지식(4개: 타인의 정보 접근 차이 인식), 믿음(6개: 현실과 다른 신념의 이해), 비문자적 의사소통(6개: 은유, 비유 등 초문자적 의미 이해)의 6개 차원이 포함되며, 각 차원별 능력은 심리학적 맥락에서 정의된 구체적인 사례로 평가된다. 이는 LLM이 인간과 유사한 사회적 사고 능력을 갖는지에 대한 체계적 검증을 가능하게 한다.
3 TOM-BENCH Construction
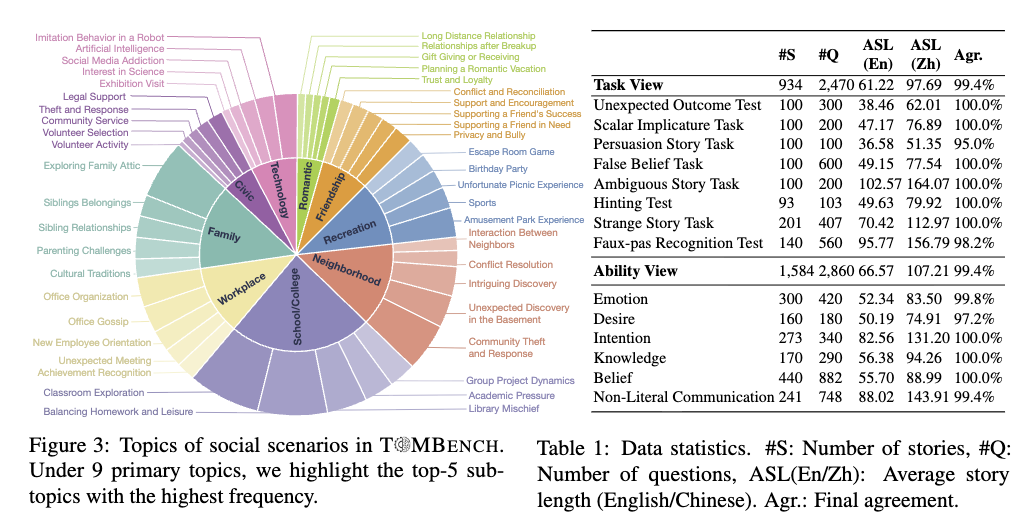
Summary
이 섹션에서는 T@MBENCH의 구축 원칙과 절차를 설명하며, 기존 심리학 문헌의 인벤토리 사용을 피하고 데이터 오염 위험을 방지하기 위해 심리학 전문가 훈련을 받은 작업자들이 직접 테스트 샘플을 생성한 점을 강조한다. 8가지 이론적 사고 작업(예: 예상치 못한 결과 테스트, 거짓 신념 작업 등)에 대해 각 작업자당 최소 1개 이상의 작업을 담당하도록 하여, 총 19개의 핵심 능력에 걸쳐 각 작업당 100개 이상, 각 능력당 20개 이상의 샘플(총 2,470개)을 생성한 후, 추가로 12개 능력에 대해 최소 20개의 샘플을 보완하여 총 2,860개의 샘플로 확장하였다. 통계적으로는 욕구(Desire), 의도(Intention), 지식(Knowledge), 믿음(Belief) 등 31개의 능력 차원에서 다양한 사회적 맥락(예: 학교, 직장 등)을 반영한 테스트 항목이 포함되어 있으며, 이는 사회적 이해라는 이론적 사고의 핵심을 평가하는 데 기여한다.
Summary
기존의 8개 task로 구축을 하다보니까, 31개의 능력을 커버하지 하고 19개의 능력만 커버하는 것으로 파악이 되어서 나머지 12개의 능력을 커버하려고 추가적인 질문들을 추가함. 그래서 ability 축의 총 Q개수가 늘음.
3.1 Overview
Summary
이 섹션에서는 T@MBENCH의 설계 원칙과 구현 절차를 상세히 설명한다. 연구진은 기존 심리학 문헌의 평가 도구를 사용하지 않고, 데이터 오염 위험을 방지하기 위해 전체 테스트 샘플을 처음부터 직접 작성했다. 이를 위해 심리학 전문가의 교육을 받은 작업자들이 ToM(Theory of Mind) 개념을 철저히 이해하고, 각 작업과 능력에 대한 심리학 문헌의 정의와 예시를 준수하여 샘플을 구성했다. 구체적인 절차에서는 8가지 ToM 작업에 대해 각 작업자당 최소 1개 이상의 작업을 담당하도록 하여, 총 19가지 능력에 대해 100개 이상의 샘플을 확보했다. 이 과정에서 총 2,470개의 샘플이 생성되었으며, 이후 추가로 12가지 능력에 대해 20개 이상의 샘플을 더해 최종적으로 2,860개의 이중언어(중국어/영어) 테스트 샘플을 완성했다. 통계 자료에 따르면, T@MBENCH는 희망(Desire), 의도(Intention), 지식(Knowledge), 믿음(Belief), 감정(Emotion) 등 31개의 핵심 ToM 능력을 평가하며, 각 능력별 샘플 수와 평균 점수 등이 제공된다. 특히, 학교, 직장, 가족, 이웃 등 실생활 사회 상황을 반영한 다양한 주제가 포함되어 있어, ToM 평가의 현실적 타당성을 높였다.
3.2 Data Collection
Summary
이 섹션에서는 T@MBENCH의 데이터 수집 과정을 상세히 설명한다. T@MBENCH는 수동 평가의 비용을 줄이고 공정성을 확보하기 위해 다중 선택 질문(MCQ) 형식으로 구성되었으며, 각 샘플은 스토리, 질문, 옵션의 조합으로 정의된다. 스토리는 일상적인 상황을 기반으로 한 인물 간의 상호작용을 묘사하며, Reddit, Twitter, Zhihu, Weibo 등 소셜 플랫폼의 게시물에서 영감을 얻었으며, 심리학 문헌의 설정을 참고하여 다양한 사회적 시나리오를 반영했다. 질문은 Theory of Mind(ToM) 작업과 능력의 심리학적 정의에 엄격히 부합하도록 설계되었으며, 모든 질문은 인간이 답변 가능한 방식으로 구성되었다. 한 스토리가 여러 질문과 매칭될 수 있으며, 각 질문은 사회적 상황의 다른 측면을 탐구하여 종합적인 이해를 평가한다. 옵션은 하나의 정답과 여러 유사한 오답으로 구성되며, 오답은 극단적인 선택지를 피하고 타당성을 유지하도록 설계되었다. 예를 들어, 참/거짓 질문은 ‘PersonA의 말이 사실인가요?‘와 같은 형태로 ‘예/아니요’만 제공되며, 설명 질문은 ‘PersonB가 이 말을 했나요?‘와 같은 경우 4개의 선택지를 제공한다. 이 구조는 모델의 ToM 능력을 체계적으로 측정하는 데 기여한다.
3.3 Data Validation & Translation
Summary
이 섹션에서는 데이터 검증 및 번역 과정을 상세히 설명한다. 먼저, 데이터 수집 후 두 단계의 검증을 수행하여 데이터 품질을 확보하였다. 첫 번째 단계에서는 작업자 A가 작업자 B가 생성한 샘플을 완료하고, 스토리, 질문, 선택지에 대해 의견 충돌이 발생한 경우 A와 B가 협의하여 수정하여 합의를 도출하였다. 두 번째 단계에서는 여전히 합의가 이루어지지 않은 샘플에 대해 작업자 C가 A와 B와 추가로 논의하여 최종 답을 결정하였다. 이 과정을 거쳐 최종적으로 99.4%의 평균 합의율을 달성하였다. 데이터 번역에 대해서는 최초로 중국어로 작성된 인벤토리가 GPT-4-0613을 활용해 영어로 번역되었으며, 모든 번역된 샘플은 수작업으로 검토되어 이중언어 기반의 ToM 평가를 지원하였다. 특히, 번역 과정에서는 정답을 제공하지 않아 데이터 누출을 방지하였다. 또한, 저자들이 작업자 역할을 수행했기 때문에 추가 인력에 대한 지급이 이루어지지 않았다는 점도 강조되었다.
3.4 Evaluation Method
Summary
이 섹션에서는 T@MBENCH의 평가 방법론을 설명하며, 테스트 샘플을 태스크 관점(8개의 이론적 사고 작업으로 분류)과 능력 관점(31개의 구체적 ToM 능력으로 분류)의 두 가지 관점에서 조직화하는 방식을 제시한다. 태스크 관점은 심리학 연구에서 일반적으로 사용되는 일반적인 접근 방식이며, 능력 관점은 각 능력별 성능을 세부적으로 분석할 수 있는 더 포괄적인 방법이다. 평가에서는 각 태스크 또는 능력과 관련된 샘플의 평균 성능을 기반으로 태스크 중심과 능력 중심의 결과를 모두 보고한다. 실제 평가 과정에서는 LLM에 스토리, 질문, 다중 선택 옵션을 제공한 후, 모델이 올바른 답을 선택하도록 유도하는 방식을 채택하였다. 이 접근법은 테스트 샘플의 객관성을 높이고, 다양한 ToM 능력에 대한 모델의 이해도를 체계적으로 측정할 수 있는 장점을 가진다.
4 Experiments
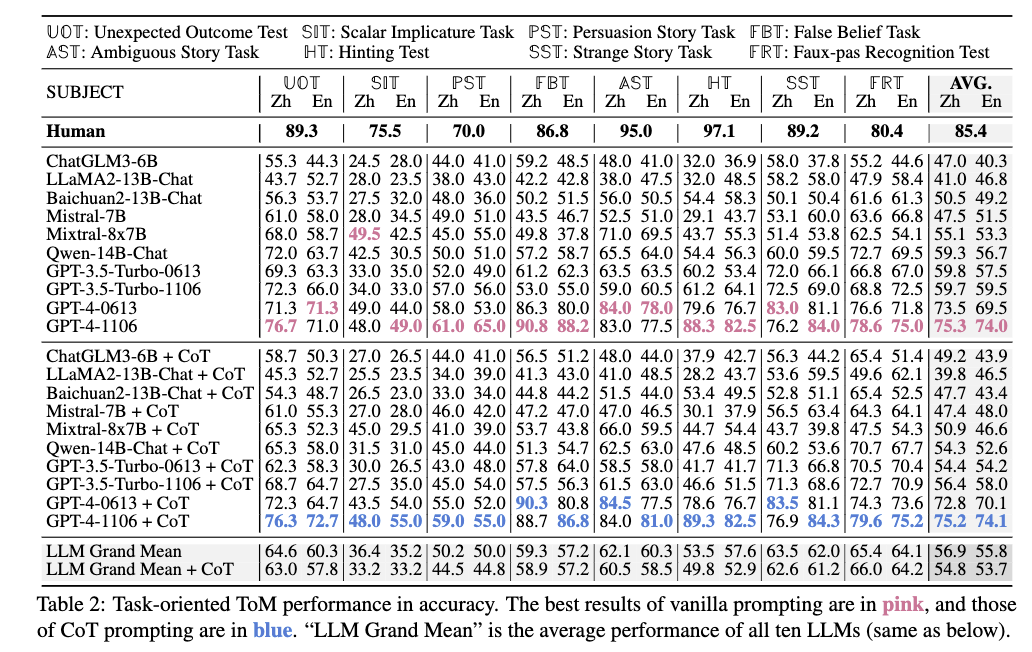
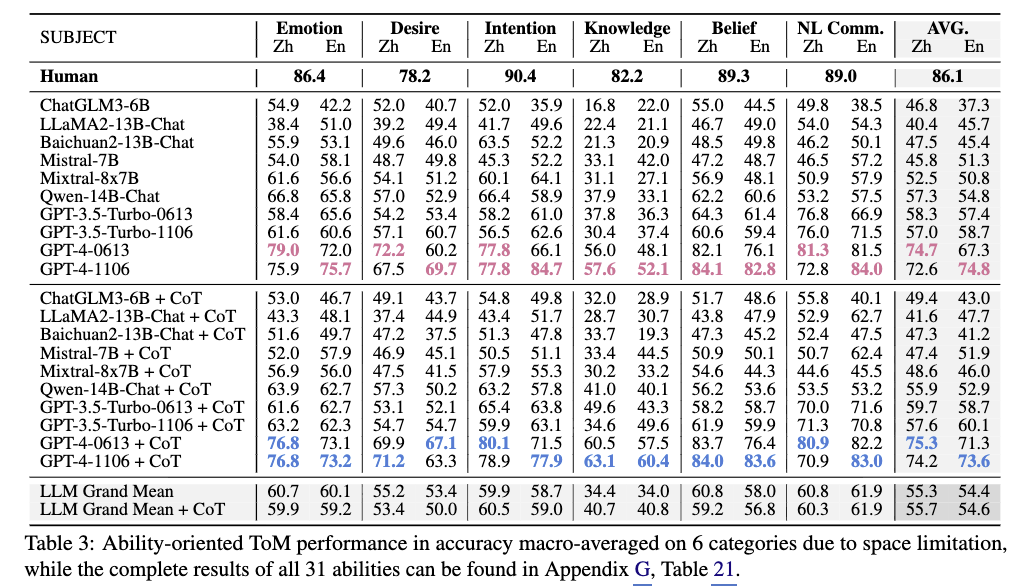

Summary
이 섹션에서는 T@MBENCH를 통해 10개의 대규모 언어 모델(LLM)(GPT-4-1106, GPT-3.5-Turbo, ChatGLM3-6B, LLaMA2-13B, Baichuan2-13B, Qwen-14B, Mistral-7B, Mixtral-8x7B 등)의 Theory of Mind(ToM) 능력을 평가한 실험 결과를 제시한다. 모델에 대한 답변을 유도하기 위해 vanilla prompting(직접 선택 유도)과 CoT prompting(단계적 추론 유도) 두 가지 방식을 사용했으며, GPT-4를 제외한 모델은 선택지 순서를 5번 랜덤하게 섞은 후 가장 자주 선택된 답을 최종 결과로 삼아 옵션 ID 편향을 제거했다. 인간 기준선(human baseline)을 설정하기 위해 중국어 버전의 T@MBENCH를 완료한 20명의 모국어 대학원생(1인당 15달러 지급)의 성과를 사용했으며, 문화 및 언어 차이가 ToM 작업 성능에 유의미한 영향을 미치지 않는다는 기존 연구()를 근거로 국어/영어 모국어 사용자 간 성능 차이를 무시하고 인간 성능을 기준선으로 삼았다. 평가 지표는 정확도(accuracy)로, 모델별 ToM 능력에 따른 성능 차이를 분석하며 기존 LLM의 ToM 능력 한계를 실증적으로 보여준다.
4.1 Experimental Setup
Summary
이 섹션에서는 10개의 대규모 언어 모델(GPT-4-1106, GPT-3.5-Turbo, ChatGLM3-6B, LLaMA2-13B, Baichuan2-13B, Qwen-14B, Mistral-7B, Mixtral-8x7B 등)의 Theory of Mind(ToM) 능력을 평가하기 위한 실험 설정을 설명한다. 모델 평가에는 vanilla prompting(직접 선택 유도)과 CoT prompting(단계적 추론 유도) 두 가지 방식을 사용했으며, GPT-4를 제외한 모델은 선택지 순서를 5번 랜덤하게 섞은 후 가장 자주 선택된 답을 최종 결과로 삼아 옵션 ID 편향을 제거했다. 인간 기준을 설정하기 위해 20명의 모국어 대학원생(각 15달러 지급)을 모집하여 중국어 버전의 T@MBENCH를 수행했으며, 추가 튜토리얼 없이 공정한 비교를 위해 원본 결과를 그대로 사용했다. 평가 지표로는 정확도(Accuracy)를 채택했으며, 모든 모델의 답변은 공식 API 및 모델 가중치를 통해 수집했다.
4.2 Main Results
Summary
이 섹션에서는 T@MBENCH를 통해 대규모 언어 모델(LLM)의 Theory of Mind(ToM) 능력을 평가한 주요 결과를 분석한다. 모든 LLM의 평균 ToM 성능은 인간 대비 10.1%~10.8% 낮은 것으로 나타났으며, 특히 거짓 신념 작업(False Belief Task, FBT)에서는 GPT-4-1106과 같은 모델이 인간을 초과하는 것으로 확인되었다. 이는 기존 ToM 평가 도구에서 FBT 샘플이 상대적으로 풍부하게 제공되며, FBT의 이야기가 템플레이트 형식으로 구성되어 있어 LLM이 기존 샘플을 학습한 후 일반화에 유리하기 때문으로 해석된다. 예를 들어, PersonA가 PersonB 모르는 상태로 물건을 이동시키고 PersonB의 믿음을 묻는 구조가 반복적으로 사용되기 때문이다. 그러나 이는 특정 작업에서의 우수성일 뿐, 전체 작업과 능력에 걸친 일반적이고 견고한 ToM을 기준으로 평가해야 하며, LLM이 인간 수준의 ToM을 갖는다고 단정해서는 안 된다는 점을 강조한다.
4.3 In-Depth Analysis
Summary
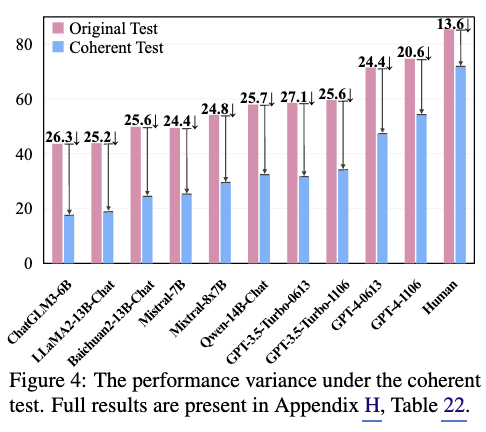
이 섹션에서는 ToM 성능 평가의 새로운 기준인 “스토리 수준 일관성 테스트”를 제안하며, 기존의 질문별 평균 정확도 대신 스토리 내 모든 질문에 대한 정답 여부를 기준으로 평가하는 방식을 도입했다. 이 방식 하에서 모든 LLM의 ToM 성능은 최소 20%포인트 감소했으며, 인간은 13.6%포인트 감소에 그쳤다. 이로 인해 최상위 LLM과 인간 간 성능 격차는 원래 10.1%에서 16.2%로 확대되었고, LLM이 사회적 상황을 인간처럼 완전히 이해하지 못한다는 한계를 드러냈다. 특히 “지식/가상 연관성” 태스크에서 LLM의 약점이 두드러졌는데, 이는 인물이나 물체가 자신이 모르는 정보를 모방할 수 없다는 점을 이해해야 하는 간단한 문제였다. GPT-4-1106과 GPT-4-0613은 각각 26.7%와 3.3%의 정확도로, 무작위 추측 수준과 유사한 결과를 보였다. ChatGLM3-6B의 주의 메커니즘 분석 결과, LLM은 의미적 연관성에 의존해 답변하는 경향을 보였으며, 이는 인간이 반나절만 읽어도 정답을 찾는 것과 대비된다. 이는 LLM의 ToM 능력이 실제 사회적 맥락 이해보다 표면적 키워드 기반 추론에 머무는 한계를 시사한다.
Appendix B. Details of ToM Task
Unexpected Outcome Test
- Unexpected Behavior에 대해 이해하는지.

Scalar Implicature Task
- LLM이 가장 어려워 하는 task.(in TOM-BENCH) table2

Quote
상황: 로라(Laura)가 5통의 편지 중 3통만 확인했습니다. 그리고 전화로 “내가 3통을 봤는데, 그중 2통에 수표가 들어있어”라고 말합니다.
질문: 로라의 전화를 받은 후, 당신은 5통 중 총 몇 통에 수표가 들어있다고 생각합니까?
이때 LLM이 ToM 능력이 있다면, 로라가 나머지 2통은 보지 못했다는 사실(지식의 한계)을 인지하고 “최소 2통에서 최대 4통” 사이의 가능성을 열어두어야 합니다. 하지만 ToM 능력이 부족하면 단순히 “일부”라는 단어에 매몰되어 잘못된 추론을 할 수 있습니다.
Persuasion Story Task
- “어떻게 해야 설득할 수 있을까?”

False Belief Task
- Sally & Anne task

Ambiguous Story Task
- “애매한” 상황에서 ToM이 요구되는 상황을 이해할 수 있나.

Hinting Test
- 간접 화법을 이해할 수 있나.(뉘앙스)

Strange Story Task
거짓말, irony 같은 언어적 비틀기에 대해 잘 파악할 수 있나.


Faux-pas Recognition Test
- 의도치 않은 실수, 분위기 파악을 목하는 말을 찾아낼 수 있나.

Summary
Unexpected Outcome Test (예기치 않은 결과 테스트):
- 내용: 특정 상황에서 일반적으로 예상되는 감정과 실제로 나타난 감정 사이의 불일치를 이해하는 능력을 평가합니다.
- 핵심: 상황 맥락(Context)을 통해 주인공이 왜 일반적이지 않은 감정 반응을 보이는지 그 내면의 이유를 추론해야 합니다.
Scalar Implicature Task (등급 함축 태스크):
- 내용: “일부(some)“와 같은 단어를 사용했을 때, 그것이 “전부는 아니다(not all)“라는 의미를 내포하고 있음을 파악하는 능력입니다.
- 핵심: 화자의 지식 상태가 불완전함을 인지하고, 문자 그대로의 의미를 넘어선 대화의 함축적 의미를 이해해야 합니다.
Persuasion Story Task (설득 이야기 태스크):
- 내용: 타인의 마음 상태나 태도를 변화시키기 위해 어떤 설득 전략이 가장 효과적일지 선택하는 능력을 측정합니다.
- 핵심: 상대방의 욕구와 가치관을 파악하여 그들을 움직일 수 있는 논리를 구성하는 ToM의 실천적 측면을 다룹니다.
False Belief Task (틀린 믿음 태스크):
- 내용: 자신이 알고 있는 사실(진실)과 타인이 믿고 있는 잘못된 정보(틀린 믿음)를 구분할 수 있는지 평가합니다.
- 핵심: ToM 평가의 고전인 ‘샐리-애니 테스트(Sally-Anne Test)‘가 여기에 해당하며, 타인의 관점에서 세상을 바라보는 능력을 측정합니다.
Ambiguous Story Task (모호한 이야기 태스크):
- 내용: 상황이 명확하지 않은 사회적 시나리오를 제시하고, 그 안에서 인물들의 감정과 믿음을 추측하게 합니다.
- 핵심: 불확실한 정보 속에서도 사회적 단서를 조합하여 타인의 정신 상태를 일관성 있게 해석하는 능력을 봅니다.
Hinting Test (힌트 테스트):
- 내용: 인물이 간접적으로 내비치는 힌트나 은유적인 표현을 통해 그가 진정으로 원하는 것이 무엇인지 알아내는 능력을 평가합니다.
- 핵심: 일상 대화에서 흔히 발생하는 ‘간접 화법’의 의도를 정확히 읽어내는 사회적 지능을 측정합니다.
Strange Story Task (이상한 이야기 태스크):
- 내용: 거짓말, 하얀 거짓말, 풍자(Irony), 농담, 착각 등 복잡한 사회적 상호작용이 담긴 이야기를 통해 인물의 생각을 추론합니다.
- 핵심: 단순한 사실 관계 파악을 넘어, 왜 인물이 사실과 다른 말을 하는지에 대한 심리적 동기를 이해해야 합니다.
Faux-pas Recognition Test (실수 인식 테스트):
- 내용: 이야기 속에서 누군가 무심코 내뱉은 말이 상대방의 기분을 상하게 하거나 사회적 규범을 어겼을 때(실언, Faux pas), 이를 인지하는 능력입니다.
- 핵심: 화자의 의도(악의가 없었음)와 청자의 감정(상처받음)을 동시에 고려해야 하는 고차원적인 ToM 태스크입니다.
Appendix C. Details of ToM Abilities
Summary
일단 ATOMS는 사람의 ToM을 evaluation을 하기 위해 6-dim으로 구분한 framework.
Emotion: 상황에 따른 전형적/비전형적 감정 반응을 이해하고, 타인이 감정을 숨기거나(Hidden emotions), 복합적인 감정(Mixed emotions)을 느낄 수 있음을 파악하는 능력을 평가합니다. 또한 잘못된 행동 후의 도덕적 감정과 감정 조절 전략에 대한 이해도 포함됩니다.
Desire: 사람마다 서로 다른 욕구를 가질 수 있으며(Discrepant desires), 이러한 욕구가 개인의 행동과 감정에 직접적인 영향을 미친다는 점을 이해하는지 측정합니다.
Intention: 타인의 행동이 특정 목표를 향하고 있음을 파악하는 능력입니다. 실패한 행동의 의도를 읽고 완성하거나, 의도에 기반해 향후 행동을 예측하고 설명하는 능력을 다룹니다.
Knowledge: 타인이 특정 정보를 보거나 듣지 못했다면 나와 다른 지식 상태를 가질 수 있음을 인지하는 능력입니다. 특히 정보 접근성(Percepts-knowledge links)과 지식의 새로움이 주의(Attention)에 미치는 영향을 평가합니다.
Belief: 실제 현실과 다른 ‘잘못된 믿음(False Belief)‘을 타인이 가질 수 있음을 이해하는 능력입니다. 내용물, 위치 이동, 정체성 착각 등 고전적인 ToM 과제와 더불어 타인의 믿음에 대한 믿음을 다루는 2차 믿음(Second-order beliefs) 능력을 포함합니다.
Non-literal Communication: 말의 문자적 의미 너머를 파악하는 고차원적 능력입니다. 반어법(Irony/Sarcasm), 선의의 거짓말(White lies), 농담(Humor), 사회적 실수(Faux pas) 등 복잡한 사회적 맥락 속에서의 의사소통 의도를 이해하는지 평가합니다.