Introduction
- 대부분의 AI 에이전트가 배포 후 수동 설정에 고정 — 동적 환경 적응 불가
- 이 서베이는 “정적 파운데이션 모델”과 “평생 학습(Life-Long Learning) 에이전트” 사이의 간극을 메우는 자기진화 기술을 체계적으로 정리
- 통합 개념 프레임워크: System Inputs / Agent System / Environment / Optimizers 4요소 피드백 루프
- 자기진화 3원칙 (Three Laws): Endure(안전) > Excel(성능) > Evolve(자율 진화) — Asimov 로봇 3원칙에서 영감
- EvoAgentX: TextGrad + AFlow + MIPRO 통합 오픈소스 프레임워크
- 100편+ 논문 체계적 분류
Asimov 로봇 3원칙
아이작 아시모프의 로봇 3원칙 (Three Laws of Robotics)
아이작 아시모프가 이 3원칙을 제안한 가장 큰 이유는 ‘창조물이 창조주를 파멸시킨다’는 뻔한 클리셰를 깨고, 로봇을 ‘안전하게 통제 가능한 도구’로 다루기 위해서였다.
- 제1원칙 (인간 보호): 로봇은 인간에게 해를 가하거나, 혹은 행동을 하지 않음으로써 인간에게 해가 가도록 해서는 안 된다.
- 제2원칙 (명령 복종): 로봇은 인간이 내리는 명령들에 복종해야만 한다. 단, 이러한 명령들이 제1원칙에 위배될 때에는 예외로 한다.
- 제3원칙 (자기 보호): 로봇은 자신의 존재를 보호해야만 한다. 단, 그러한 보호가 제1원칙이나 제2원칙에 위배될 때에는 예외로 한다.
참고: 아시모프는 훗날 세계관이 확장되면서 이 세 가지 원칙의 상위 개념으로 제0원칙을 추가하기도 했습니다.
- 제0원칙 (인류 보호): 로봇은 인류 전체에게 해를 가하거나, 행동을 하지 않음으로써 인류에게 해가 가도록 방치해서는 안 된다.
Related Papers
- Prompt Engineering, RLHF/RLAIF, Tool Augmented LLM: 분절된 연구 흐름 — 이 서베이가 자기진화 패러다임 아래 통합
- DSPy: 프로그래밍 패러다임 — EvoAgentX와 개념적 연결
- Neural Architecture Search / AutoML: LLM 에이전트 버전으로 EvoAgentX 위치
- 차별점: (1) 단일/다중 에이전트 + 도메인 특화의 3방향 분류, (2) 설계 원칙 명문화, (3) 실용적 프레임워크 연계
Methods
통합 개념 프레임워크
4요소 피드백 루프
- System Inputs: 태스크, 데이터, 피드백 신호
- Agent System: LLM 행동, 프롬프트, 메모리, 도구, 워크플로우, 에이전트 간 통신
- Environment: 실세계 또는 시뮬레이션
- Optimizers: TextGrad, AFlow, MIPRO, RL 등
3방향 분류 체계
- 단일 에이전트 최적화: LLM 행동(학습 기반·테스트 타임), 프롬프트(편집·진화·생성·텍스트 그래디언트), 메모리, 도구, 통합
- 다중 에이전트 최적화: 자동 MAS 구성, MAS 워크플로우
- 도메인 특화: 바이오의학, 프로그래밍, 금융
3원칙 (Three Laws)
- Endure: 안전·안정성 유지 최우선
- Excel: 기존 성능 보존·향상
- Evolve: 자율적 내부 컴포넌트 최적화
방법론 다이어그램
graph TD A[시스템 입력<br/>태스크·데이터·피드백] --> B[에이전트 시스템] subgraph B["에이전트 시스템"] B1[파운데이션 모델] B2[프롬프트 최적화] B3[메모리 관리] B4[도구 학습] B5["워크플로우<br/>(단일/다중)"] end B --> C[환경<br/>실세계·시뮬레이션] C --> D[피드백<br/>보상·텍스트·평가] D --> E["옵티마이저<br/>(TextGrad·AFlow·MIPRO·RL)"] E --> B subgraph F["3원칙"] F1["1️⃣ Endure: 안전 최우선"] F2["2️⃣ Excel: 성능 보존"] F3["3️⃣ Evolve: 자율 최적화"] F1 --> F2 --> F3 end E -.->|설계 제약| F style B fill:#e3f2fd style F1 fill:#ffcdd2 style F3 fill:#c8e6c9
Results
- 서베이 논문으로 독자 실험 미수행. EvoAgentX 프레임워크(arXiv:2507.03616)의 대표 결과 정리
EvoAgentX 벤치마크 성능
| Benchmark | Metric | Improvement |
|---|---|---|
| HotPotQA | F1 | +7.44% |
| MBPP | Pass@1 | +10.00% |
| MATH | Accuracy | +10.00% |
| GAIA | Overall Accuracy | +20.00% (최대) |
Discussion
- Alignment Drift 리스크: 에이전트가 의도치 않은 방향으로 진화할 위험 — 안전 제약을 진화 루프 내부에 통합 필수
- “자기진화”의 경계 모호성: 광범위한 정의로 단순 RAG 업데이트나 few-shot 적응도 포함될 수 있음
- 한계 1: 단일/다중 에이전트 최적화의 경계가 실제 시스템에서 모호
- 한계 2: 도메인 특화 섹션(바이오의학·프로그래밍·금융)의 선택 기준 미설명
Insights
- 주목할 점: Asimov의 3원칙을 AI 에이전트에 재해석 — Endure > Excel > Evolve 위계가 자기진화 시스템 설계의 트레이드오프 정의에 실용적 지침 제공
- 연결 고리: 기존 Prompt Engineering, RLHF, Tool Augmented LLM, MAS 연구를 하나의 자기진화 패러다임으로 통합. DSPy와 개념적 연결
- 시사점: 인간 지속적 개입 없이 장기 배포 가능한 에이전트의 청사진. 그러나 “진화 감시(evolution oversight)” 메커니즘 설계가 미해결
- 비판적 코멘트: “Endure” 원칙의 실제 구현에서 안전을 어떻게 수량화·검증하는지는 열린 문제
Discussion Points
- 논쟁점: “자기진화” 정의가 광범위 — 진정한 자기진화와 기존 적응형 시스템의 구분이 커뮤니티 내 논쟁 대상
- 검증 필요 가정: 자기진화가 필연적으로 성능 향상을 가져온다는 암묵적 가정 — forgetting, reward hacking, OOD 성능 저하 리스크 체계적 검토 필요
- 후속 연구: (1) 실시간 진화 감시 메커니즘, (2) 다중 도메인 동시 진화의 크로스 도메인 간섭, (3) 자기진화의 샘플 효율성 이론적 분석
A Comprehensive Survey of Self-Evolving AI Agents
Overview
- 연구 배경: 기존 AI 에이전트 시스템은 정적 구성에 의존하며 동적 환경에 적응하는 데 한계가 있어, 자가 진화(Self-Evolving) AI 에이전트 개발 필요성이 대두됨
- 핵심 방법론:
- 통합 개념 프레임워크 제안: 시스템 입력(System Inputs), 에이전트 시스템(Agent System), 환경(Environment), 최적화자(Optimisers) 4가지 핵심 구성 요소를 기반으로 피드백 루프를 추상화
- 자가 진화 AI 에이전트의 3대 원칙 정의: 안전성 확보(Endure), 성능 유지(Excel), 자율적 진화(Evolve)를 핵심 원칙으로 제시
- 주요 기여:
- LLM 기반 학습 패러다임의 진화 과정(예: MOP → MASE)을 체계적으로 분석
- 단일 에이전트, 다중 에이전트, 도메인 특화 최적화 기법에 대한 포괄적 리뷰 제공
- 평가, 안전성, 윤리적 고려사항에 대한 심층적 논의를 통한 실용적 지침 제시
- 실험 결과: 2023–2025년 기간 동안 3,000개 이상의 관련 연구를 분석하여, 단일 에이전트 최적화(예: 프롬프트/메모리 개선), 다중 에이전트 협업(예: 메시지 교환/워크플로우 최적화), 특정 도메인(의료/금융 등)에 적용된 진화 전략을 체계적으로 정리
- 의의 및 한계: 자가 진화 에이전트의 이론적 기반을 확립하며, 장기적 자율성과 안정성을 갖춘 시스템 개발을 위한 기초를 제공하지만, 현재 시스템은 완전한 자율 진화에 도달하지 못한 상태임
목차
- A Comprehensive Survey of Self-Evolving AI Agents
- A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
- 1 Introduction
- [[#definition|Definition]]
- [[#three-laws-of-self-evolving-ai-agents|Three Laws of Self-Evolving AI Agents]]
- 2 Foundation of AI Agent Systems
- 2.1 AI Agents
- 2.2 Multi-Agent Systems
- 3 A Conceptual Framework of MASE
- 3.3 Agent Systems
- 3.4 Environments
- 4 Single-Agent Optimisation
- 4.2 Prompt Optimisation
- 4.3.1 Short-term Memory Optimisation
- 4.4 Tool Optimisation
- 5 Multi-Agent Optimisation
- 6 Domain-Specific Optimisation
- 6.1 Domain-Specific Optimisation in Biomedicine
- 6.2 Domain-Specific Optimisation in Programming
- 6.3 Domain-Specific Optimisation in Financial and Legal Research
- 7 Evaluation
- 7.1 Benchmark-based Evaluation
- 7.2 LLM-based Evaluation
- 7.3 Safety, Alignment, and Robustness in Lifelong Self-Evolving Agents
- 8 Challenges and Future Directions
- 8.1 Challenges
- 9 Conclusions
- Acknowledgements
- References
A Comprehensive Survey of Self-Evolving AI Agents
Summary
이 섹션에서는 기존 AI 에이전트 시스템의 정적 구성 요소로 인한 동적 환경 적응 한계를 지적하고, 자기 진화형 AI 에이전트(Self-Evolving AI Agents)라는 새로운 패러다임을 제시한다. 이 연구는 대규모 언어 모델(LLMs)을 기반으로 한 기초 모델(Foundation Models)의 정적 특성과 생애주기 에이전트(Lifelong Agentic Systems)의 지속적 적응성을 연결하는 자기 진화 기술(Self-Evolution Techniques)을 중심으로, 다양한 기법을 체계적으로 검토한다. 특히, 시스템 입력(System Inputs), 에이전트 시스템(Agent System), 환경(Environment), 최적화기(Optimisers)의 4가지 핵심 구성 요소를 포함하는 통합 개념 프레임워크를 제안하여, 기존 연구의 비교와 이해를 위한 기초를 마련한다. 이 프레임워크를 기반으로 기초 모델, 에이전트 프롬프트, 메모리, 도구, 워크플로우, 에이전트 간 커뮤니케이션 메커니즘 등 다양한 구성 요소에 대한 자기 진화 기법을 체계적으로 분석한다. 또한, 생물의학, 프로그래밍, 금융과 같은 특정 분야에서 도메인 제약 조건과 밀접하게 연계된 도메인 특화 진화 전략을 다룬다. 마지막으로, 자기 진화형 에이전트 시스템의 평가 기준, 안전성, 윤리적 고려사항에 대한 전문적인 논의를 통해, 시스템의 효과성과 신뢰성 확보를 위한 방향성을 제시한다. 이 조사 연구는 연구자와 실무자에게 더 적응력 있고 자율적인 생애주기 에이전트 시스템 개발의 기초를 제공하고자 한다. 관련 자료는 Github 링크에서 확인할 수 있다.
1 Introduction
Summary
이 섹션에서는 대규모 언어 모델(LLM)의 발전이 인공지능(AI)의 핵심 기술인 LLM 기반 에이전트의 등장으로 이어졌음을 설명한다. LLM 기반 에이전트는 자연어 이해, 계획 수립, 행동 생성을 위해 LLM을 핵심 의사결정 모듈로 활용하는 AI 에이전트의 한 형태로, 복잡한 환경에서 자율적으로 목표 달성을 위해 인식, 계획, 메모리, 도구 활용 등의 모듈을 통합한 구조를 갖는다. 그러나 단일 에이전트 시스템은 동적이고 복잡한 환경에서 태스크 전문성과 협업 능력의 한계를 보이며, 이를 극복하기 위해 **다중 에이전트 시스템(MAS)**이 제안되었다. MAS는 각 에이전트가 특정 서브태스크나 도메인 전문성을 갖도록 설계하고, 정보 교환 및 행동 조정을 통해 공동 목표를 달성하는 방식으로, 과학 연구, 웹 탐색, 의료, 금융 등 다양한 분야에 적용되고 있다. 그러나 대부분의 시스템은 여전히 수작업으로 설계된 고정된 아키텍처에 의존하며, 실세계의 동적 변화(예: 사용자 의도 변화, 새 도구 추가)에 대응하는 데 한계가 있다. 이러한 문제를 해결하기 위해 **자기 진화형 AI 에이전트(Self-Evolving AI Agents)**라는 새로운 패러다임이 제안되는데, 이는 기초 모델과 생애주기 학습(Lifelong Learning) 시스템을 연결하며 자율적 적응과 지속적 자기 개선이 가능한 에이전트 시스템을 목표로 한다.
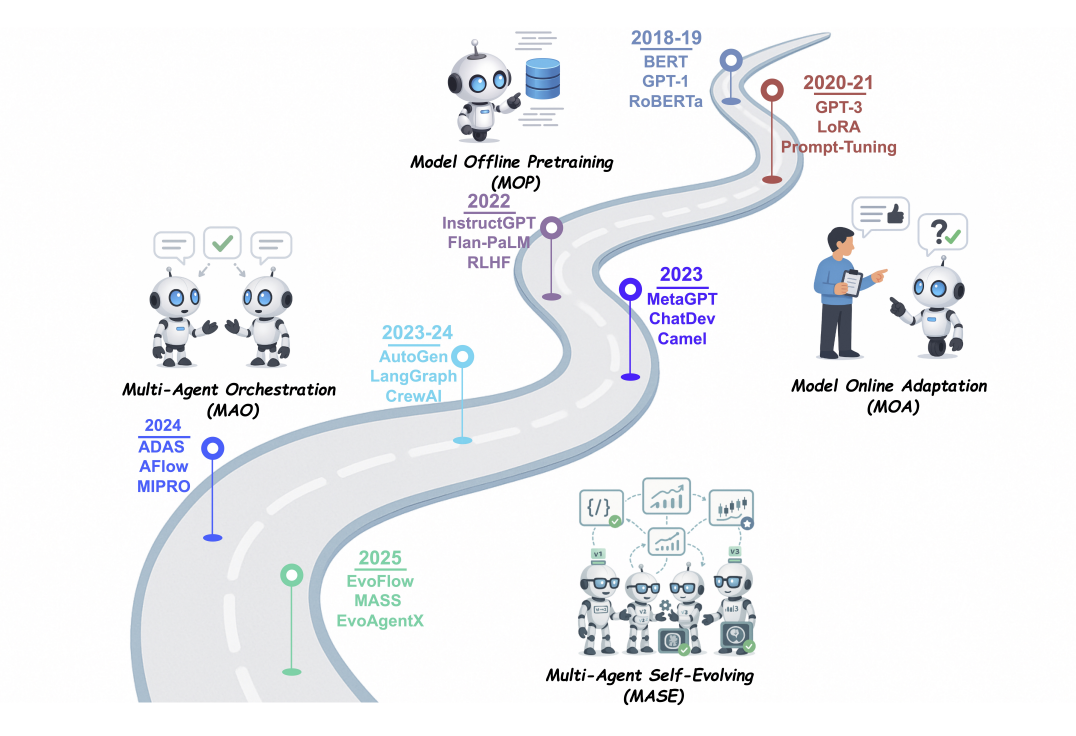
Figure 1. LLM-centric learning is evolving from learning purely from static data, to interacting with dynamic environments, and ultimately towards lifelong learning through multi-agent collaboration and self-evolution.
Definition
자기 진화형 AI 에이전트(Self-Evolving AI Agents)
자기 진화형 AI 에이전트(Self-Evolving AI Agents)는 **자율적으로 환경과 상호작용하며 내부 구성 요소를 지속적으로 최적화**하는 시스템으로 정의되며, 변화하는 작업, 맥락, 자원에 적응하면서 안전성 확보와 성능 향상을 목표로 한다고 설명한다. 기존 AI 에이전트의 정적 구조 한계를 극복하기 위해, 이 연구는 아이작 아시모프의 로봇 3대 법칙을 영감으로 받아 안전하고 효과적인 자기 진화를 위한 지도 원칙(Guiding Principles)을 제안하며, 이는 에이전트가 동적 환경 변화에 유연하게 대응하면서도 시스템 안정성을 유지하는 데 핵심적인 역할을 한다고 강조한다.
Thought
이러한 정의를 바탕으로 생각해봐도, 지속적으로 최적화를 하려는 동기가 있어야 그게 가능하지 않을까라는 생각. 동기가 있는 편이 지속적인 최적화를 수월하게 할 수 있는 방법 중에 하나가 아닐까?
Three Laws of Self-Evolving AI Agents (Paper Suggestion)
이 섹션에서는 자기 진화형 AI 에이전트(Self-Evolving AI Agents)의 설계 원칙으로 3가지 법칙(Three Laws)을 제시하며, 이는 기존 AI 시스템의 정적 한계를 극복하고 자율적 진화를 가능하게 하는 핵심 지침이다.
첫째, Endure(안정성 보장) 법칙은 시스템 수정 과정에서도 안전성(safety)과 안정성(stability)을 유지해야 함을 강조한다.
둘째, Excel(성능 유지) 법칙은 안정성에 충실하면서 기존 작업 성능을 유지하거나 향상시켜야 함을 요구한다.
셋째, Evolve(자율적 진화) 법칙은 변화하는 환경에 대응해 내부 구성 요소를 자동으로 최적화할 수 있어야 함을 규정한다.
Quote
- I. Endure (Safety Adaptation) Self-evolving AI agents must maintain safety and stability during any modification;
- II. Excel (Performance Preservation) Subject to the First law, self-evolving AI agents must preserve or enhance existing task performance;
- III. Evolve (Autonomous Evolution) Subject to the First and Second law, self-evolving AI agents must be able to autonomously optimise their internal components in response to changing tasks, environments, or resources.
이러한 법칙들은 기존 Model Offline Pretraining(MOP)에서 시작해 Model Online Adaptation(MOA), Multi-Agent Orchestration(MAO)까지의 발전 단계를 넘어서 Multi-Agent Self-Evolving(MASE)라는 자체 진화 루프로 이어지는 LLM 기반 시스템의 Paradigm Shift를 설명한다.
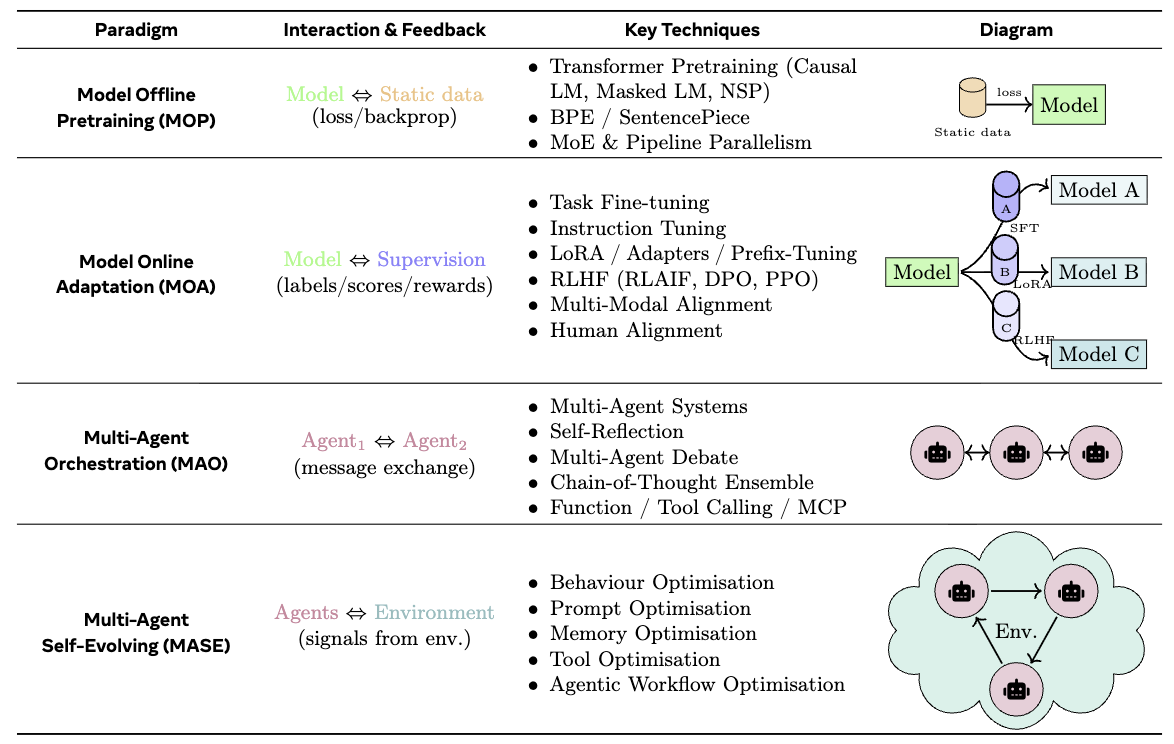
Table 1. Comparison of four LLM-centric learning paradigms – Model Offline Pretraining (MOP), Model Online Adaptation (MOA), Multi-Agent Orchestration (MAO), and Multi-Agent Self-Evolving (MASE), highlighting each paradigm’s interaction & feedback mechanisms, core techniques, and illustrative diagrams to trace the progression from static model training to dynamic, autonomous agent evolution.
MOP (Model Offline Pretraining).
The initial stage focuses on pretraining foundation models on large-scale, static corpora and then deploying them in a fixed, frozen state, without further adaptation.
MOA (Model Online Adaptation).
Building on MOP, this stage introduces post-deployment adaptation, where the foundation models can be updated through techniques such as supervised fine-tuning, low-rank adapters (Pfeiffer et al., 2021; Hu et al., 2022), or reinforcement learning from human feedback (RLHF) (Ouyang et al., 2022), using labels, ratings, or instruction prompts.
MAO (Multi-Agent Orchestration)
Extending beyond a single foundation model, this stage coordinates multiple LLM agents that communicate and collaborate via message exchange or debate prompts (Li et al., 2024g; Zhang et al., 2025h), to solve complex tasks without modifying the underlying model parameters.
MASE (Multi-Agent Self-Evolving)
Finally, MASE introduces a lifelong, self-evolving loop where a population of agents continually refines their prompts, memory, tool-use strategies and even their interaction patterns based on environmental feedback and meta-rewards (Novikov et al., 2025; Zhang et al., 2025i).
MOP는 정적 데이터 기반의 사전 학습을, MOA는 감독 데이터를 통한 온라인 적응을, MAO는 다중 에이전트 간 협업을, 마지막으로 MASE는 환경 피드백과 메타 보상에 기반한 지속적 자율 진화를 실현한다. 현재 연구는 LLM의 핵심 능력 향상과 보조 구성 요소 최적화를 통해 이 목표에 다가서고 있으나, 완전한 자율성 달성은 여전히 장기 목표로 남아 있다. 이 법칙들은 구체적인 윤리적 지침으로서 AI 윤리 연구에 영향을 주었으며, 구현 가능한 기술적 방향으로서 자기 진화형 에이전트의 미래를 제시한다.
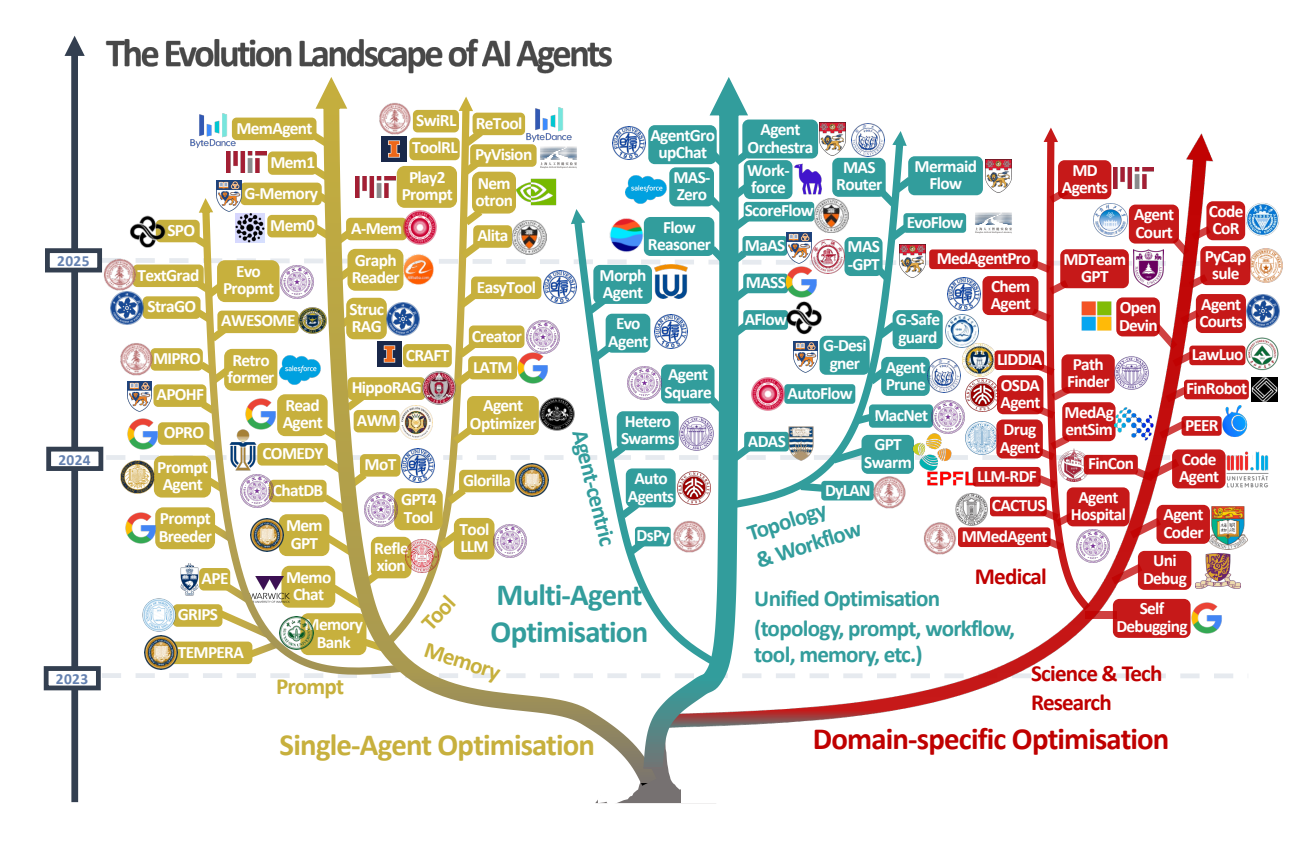
Figure 2 A visual taxonomy of AI agent evolution and optimisation techniques, categorised into three major directions: single-agent optimisation, multi-agent optimisation, and domain-specific optimisation. The tree structure illustrates the development of these approaches from 2023 to 2025, including representative methods within each branch.
Contributions of this paper
Our main contributions are as follows:
- We formalise the Three Laws of Self-Evolving AI Agents and map the evolution of LLM-centric learning paradigms from static pretraining to fully autonomous, lifelong self-evolving agentic systems.
- We introduce a unified conceptual framework that abstracts the feedback loop underlying self-evolving agentic systems, and provides a foundation for systematically understanding and comparing different evolution and optimisation approaches.
- We conduct a systematic review of existing evolution and optimisation techniques across single-agent, multi-agent, and domain-specific settings.
- We provide a comprehensive review of evaluation, safety, and ethical considerations for self-evolving agentic systems, emphasising their critical role in ensuring the effectiveness, safety, and responsible deployment of these systems.
- We identify key open challenges and outline promising research directions in agent self-evolution, aiming to facilitate future exploration and advance the development of more adaptive, autonomous, and self-evolving agentic systems.
2 Foundation of AI Agent Systems
Summary
이 섹션에서는 에이전트 진화 및 최적화를 이해하기 위해 기존 AI 에이전트 시스템의 기반을 체계적으로 정리한다. 먼저 단일 에이전트 시스템(single-agent systems)의 정의와 핵심 구성 요소를 설명한 후, 다중 에이전트 시스템(multi-agent systems, MAS)의 동기, 구조적 패러다임 및 협업 메커니즘을 다룬다. 마지막으로, 생애주기 동안 지속적으로 자기 진화하는 에이전트 시스템(lifelong, self-evolving agentic systems)의 비전을 제시하며, 기존 시스템의 정적 설계 한계를 극복하기 위한 환경 피드백과 상호작용 데이터 기반의 자동 진화 기법을 언급한다. 이는 앞서 언급된 자기 진화형 AI 에이전트의 기술적 기반을 마련하는 핵심 내용으로, 정적 구성 요소의 한계를 넘어 동적 환경에 적응하는 시스템의 구조적 전환을 강조한다.
2.1 AI Agents
Summary
이 섹션에서는 AI 에이전트(AI Agent)를 환경과 상호작용하며 자율적으로 목표 달성을 위한 자율 시스템으로 정의하고, 단일 에이전트 시스템(single-agent systems)의 핵심 구성 요소를 체계적으로 설명한다.
에이전트의 핵심은 Foundation Model(대부분 LLM)로, 이는 지시사항 해석, 계획 생성, 실행 가능한 응답 생성 등의 핵심 추론 엔진 역할을 수행한다. 또한, 복잡한 환경에서 효과적으로 작동하기 위해 감지 모듈(Perception Module), 계획 모듈(Planning Module), 메모리 모듈(Memory Module), 도구 활용(Tool Use) 등의 보조 모듈이 통합된다.
Perception Module
감지 모듈은 환경에서 텍스트, 오디오, 영상 등 다양한 입력 데이터를 처리해 추론에 적합한 표현을 생성하고,
The perception module is responsible for acquiring and interpreting information from the environment (Li et al., 2024f). This includes processing textual inputs, audio signals, video frames, or other sensory-like data to build a representation suitable for reasoning.
What is a "good" representation?
어떠한 representation이 learning 혹은 reasoning에 suitable한 걸까?
→ 이러한 걸 연구하는 분야가 representation-learning.그러면 good-representation의 수렴 point는 존재할까?
scale이 큰 모델이 만들어내는 representation이 더 좋은 representation이라면, 결국 그건 어디로 갈까, 혹은 무엇일까?
related work : Platonic representation hyphothesis, World Model JEPA랑 연관지을 수 있을까?
Planning Module
계획 모듈은 복잡한 작업을 하위 작업으로 분해하며 Chain-of-Thought prompting이나 ReACt프레임워크와 같은 동적 계획 전략을 활용한다.
The planning module enables the agent to decompose complex tasks into actionable sub-tasks or sequences of operations and guide their execution across multiple steps (Huang et al., 2024b). This process facilitates hierarchical reasoning and ensures coherent task completion. One of the simplest forms of planning involves linear task decomposition, where a problem is broken down into multiple intermediate steps, and the LLM follows these steps to address the problem. This is exemplified by methods such as chain-of-thought prompting (Wei et al., 2022). Beyond static planning, more dynamic approaches interleave planning and execution in an iterative loop. For instance, the ReAct (Yao et al., 2023b) framework combines reasoning with actions, allowing the agent to revise its plans based on real-time feedback. In addition to linear planning, some methods adopt a branching strategy, where each step may lead to multiple possible continuations. Representative examples are Tree-of-Thought (Yao et al., 2023a) and Graph-of-Thought (Besta et al., 2024), which enable the agent to explore multiple reasoning paths.
Idea
최근 연구들에 따르면, CoT 내부의 내용에 대한 신뢰성이 많이 깨지고 있는 것 같다. CoT 내용이 진짜 필요해서 하는 사고인지 아니면, Fine-tuning에 의해 익숙한 token 수의 응답에 비슷해지려고 아무 말이나 하는 건지 말이야.
그래서 나의 의견은 CoT나 ToT를 따와서 CoT 내부 자체를 파악하는 것 보다는 직접 생각 추론 경로를 몇개 만들래 라는 걸 응답을 받아서 직접 그 만큼의 생각을 하게 해주고, 결과를 보자는 거지. 그게 더 학술적 가치가 있지 않을까? 이게 동기 reasoning investment를 token length로 설정하는 것보다 직접적인 지표 같아서.
Memory Module
메모리 모듈은 단기 기억(현재 작업 관련 맥락 저장)과 장기 기억(지식, 경험 누적)을 구분하며, RAG(Retrieval-Augmented Generation) 모듈을 통해 장기 기억 정보를 효과적으로 활용한다.
The memory module enables the agent to retain and recall past experience, enabling context-aware reasoning and long-term consistency. Broadly, memory can be categorised into short-term and long-term memory.
Short-term memory typically stores the context and interactions generated during the execution of the current task. Once the task is completed, the short-term memory will be removed. In contrast, long-term memory persists over time and may store accumulated knowledge, past experiences, or reusable information across tasks. To access relevant long-term memory, many agent systems adopt a retrieval-augmented generation (RAG) module (Zhang et al., 2024d), where the agent retrieves relevant information from the memory and incorporates them into the input context for the LLM. Designing an effective memory module involves several challenges, including how to structure memory representations, when and what to store, how to retrieve relevant information efficiently, and how to integrate it into the reasoning process Zeng et al. (2024a). For a more comprehensive review of memory mechanisms in AI agents, we refer readers to the survey by Zhang et al. (2024d).
Tool Use
마지막으로, 도구 활용은 웹 검색, 코드 해석, 브라우저 자동화 등의 외부 도구와의 상호작용을 통해 에이전트의 현실 세계 적응력을 강화하는 핵심 요소로, API 호출 및 도구 출력의 추론 통합 과정을 포함한다. 본 섹션은 LLM 기반 에이전트의 기초를 설명하며, 보다 상세한 논의는 기존 서베이를 참조하도록 안내한다.
The ability to use external tools is a key factor for AI agents to effectively operate in real-world scenarios. While LLMs are powerful in language understanding and generation, their capabilities are inherently limited by their static knowledge and reasoning capabilities. By using external tools, agents can extend their functional scope, allowing them to better interact with real-world environments. Typical tools include web search engines (Li et al., 2025g), code interpreters or execution environments (Islam et al., 2024), and browser automation framework (Müller and Žunič, 2024). The design of the tool-use component often involves selecting tools, constructing tool-specific inputs, invoking API calls, and integrating tool outputs back into the reasoning process.
2.2 Multi-Agent Systems
Summary
이 섹션에서는 단일 에이전트 시스템의 한계를 극복하기 위해 다중 에이전트 시스템(Multi-Agent Systems, MAS)의 개념과 구조를 체계적으로 설명한다. MAS는 생물학적 및 사회적 시스템에서 관찰되는 분산 지능을 모방한 것으로, 자체적인 목표 달성을 위한 협업 메커니즘을 통해 단일 에이전트가 처리할 수 없는 복잡한 작업을 수행한다. 핵심 메커니즘인 에이전트 토폴로지(agent topology)는 에이전트 간의 연결 방식과 정보 흐름을 정의하며, 이는 작업 분배 및 실행 전략에 직접적인 영향을 미친다. MAS의 주요 장점으로는 복잡한 작업의 분해 및 전문성 기반 분담, 병렬 처리를 통한 시간 민감형 작업의 효율성 향상, 분산 구조를 통한 시스템의 안정성 및 견고성, 새로운 에이전트의 추가를 통한 확장성, 다양한 관점의 논의 및 반복적 개선을 통한 혁신성이 있다. 또한, CAMEL 및 AutoGen과 같은 프레임워크는 모듈형 아키텍처와 자동화된 조율 기능을 제공하여 MAS 개발의 공학적 부담을 줄이는 데 기여한다. 이는 자기 진화형 에이전트(Self-Evolving AI Agents)의 설계 원칙인 집단 지능(collective intelligence)과 구조화된 협업(structured coordination)을 실현하는 데 중요한 기반을 제공하며, 동적 환경에서의 유연한 적응과 안정성을 보장하는 데 기여한다.
2.2.1 System Architecture
Summary
이 섹션에서는 다중 에이전트 시스템(MAS)의 시스템 구조 설계가 에이전트의 조직화, 협업 및 작업 수행 방식에 근본적으로 영향을 미친다는 점을 강조하며, 계층형(Hierarchical Structure), 집중형(Centralised Structure), 분산형(Decentralised Structure) 구조의 특징과 한계를 체계적으로 분석한다.
계층형 구조는 정적 계층 구조를 기반으로 작업을 명시적으로 분해하고 특정 에이전트에 순차적으로 할당하는 방식으로, MetaGPT와 HALO와 같은 시스템에서 표준 운영 절차(SOP, Standard Operating Procedure)와 몬테카를로 트리 탐색(MCTS)을 도입해 모듈성과 도메인 특화 최적화를 달성하는 것으로, 소프트웨어 개발 및 의학 등 다양한 분야에 적용되고 있다.
집중형 구조는 상위 관리자 에이전트가 전역 계획 및 작업 분배를 담당하고 하위 에이전트가 서브태스크를 수행하는 방식으로, 글로벌 계획과 세부 작업 실행의 균형을 유지할 수 있지만, 중앙 노드에 의존해 성능 병목 현상과 단일 고장 지점 취약성을 유발한다.
분산형 구조는 중앙 제어가 없고 분산 네트워크 상의 동등한 에이전트가 협업하는 방식으로, 세계 시뮬레이션 등에 널리 채택되며, 중앙 노드의 손상으로 전체 시스템이 마비되는 문제를 해결하지만, 정보 동기화, 데이터 보안, 협업 비용 증가 등의 도전 과제를 동반한다. 최근에는 블록체인 기술을 활용해 이러한 협업 문제를 해결하려는 연구가 확장되고 있다.
2.2.2 Communication Mechanisms
Summary
이 섹션에서는 다중 에이전트 시스템(MAS)의 성능이 에이전트 간 정보 교환과 협업 방식에 크게 의존함을 강조하며, 의사소통 메커니즘의 진화 과정을 다룬다.
구체적으로, 구조화된 출력(Structured Output) 방식은 JSON, XML, 실행 가능한 코드 등 명확한 포맷을 통해 기계 가독성과 표준화된 협업을 달성하며, 정밀도와 효율성이 요구되는 문제 해결 작업에 적합하다는 점을 설명한다.
반면 자연어(Natural Language) 기반 의사소통은 맥락과 의미의 풍부함을 유지해 창의적 작업에 유리하지만, 모호성과 실행 효율성 저하 등의 한계를 지닌다.
마지막으로, 표준화된 프로토콜(Standardised Protocols)의 최근 발전을 소개하며, A2A, ANP, MCP, Agora 등이 각각 수평적/수직적 통신을 표준화하고, 분산 환경에서의 상호 운용성과 유연성을 확보하는 데 기여하고 있음을 강조한다.
이러한 프로토콜들은 수평적 협업(A2A, Agora)과 수직적 통합(MCP)을 지원하며, 분산형 정체성(ANP의 DID)과 동적 프로토콜 협상 기능을 통해 더욱 유연한 MAS 생태계를 구축하고 있다.
(3) Standardised Protocols
Recent advances have introduced specialised protocols designed to standardise MAS communication, creating more inclusive and interoperable agent ecosystems: A2A (LLC and Contributors) standardises horizontal communication through a structured, peer-to-peer task delegation model, enabling agents to collaborate on complex, long-running tasks while maintaining execution opacity. ANP (Chang and Contributors) implements secure, open horizontal communication for a decentralised “agent internet” through a hierarchical architecture with built-in Decentralised Identity (DID) and dynamic protocol negotiation. MCP (PBC and Contributors) standardises vertical communication between individual agents and external tools or data resources through a unified client-server interface. Agora (Marro and Contributors) functions as a meta-protocol for horizontal communication, enabling agents to dynamically negotiate and evolve their communication methods, seamlessly switching between flexible natural language and efficient structured routines.
최근 MAS 통신을 표준화하기 위해 A2A, ANP, MCP, Agora 네 가지 프로토콜이 등장했다. 이 중 A2A, ANP, Agora는 에이전트 간 수평적(horizontal) 통신을, MCP는 에이전트-도구 간 수직적(vertical) 통합을 담당하며, 각각의 역할 분담을 통해 분산 환경에서의 상호 운용성과 유연성을 확보한다.
| 프로토콜 | 제안 | 핵심 아이디어 | 채택 현황 |
|---|---|---|---|
| A2A | Google, 2025.04 → Linux Foundation 이관 | 에이전트 간 수평적 P2P 작업 위임 — 구조화된 Task 위임 모델로 복잡한 장기 작업 협업, 실행 불투명성(opacity) 유지 | 50+ 파트너(Salesforce, SAP 등), 프로덕션 수준 |
| ANP | 오픈소스 커뮤니티, W3C DID 기반 | 탈중앙 에이전트 네트워크 — 계층적 아키텍처에 DID 인증·동적 프로토콜 협상 내장, “에이전트 인터넷” 지향 | 초기 단계, 표준화 진행 중 |
| MCP | Anthropic, 2024.11 → Linux Foundation 이관 | 에이전트-도구 간 수직적 통합 인터페이스 — 통일된 클라이언트-서버 모델로 외부 도구·데이터 연결 표준화 | 수천 개 MCP 서버, 빠르게 확산 중 |
| Agora | 학술 연구 (arXiv 2410.11905) | 메타프로토콜 — 에이전트가 런타임에 통신 방법을 동적으로 협상·진화, 자연어↔구조화 루틴 간 자유 전환 | 연구 단계 |
2.3 The Vision of Lifelong, Self-Evolving Agentic Systems
Summary
이 섹션에서는 기존 LLM 기반 시스템의 정적 구성 요소로 인한 동적 환경 적응 한계를 극복하기 위한 다중 에이전트 자기 진화(Multi-Agent Self-Evolving, MASE) 시스템의 비전을 제시한다. 현재의 다중 에이전트 프레임워크(MAS)는 여전히 수작업으로 설계된 워크플로우, 고정된 커뮤니케이션 프로토콜, 인간이 정리한 도구체인에 의존하며, 이는 변화하는 환경에서의 지속적 성능 유지에 어려움을 초래한다. MASE는 이러한 한계를 해결하기 위해 배포와 지속적 개선 사이의 루프(closed-loop)를 형성하며, 에이전트가 환경 피드백과 상위 메타 보상에 따라 프롬프트, 메모리 구조, 도구 사용 전략, 에이전트 간 상호작용 토폴로지를 자율적으로 최적화할 수 있도록 설계된다. 이 과정은 자기 진화형 AI 에이전트의 3대 법칙 (Endure, Excel, Evolve)을 기반으로, 운영 중 성능과 안전성 모니터링, 제어된 점진적 업데이트를 통한 능력 보존/향상, 태스크, 환경, 자원 변화에 대한 자율적 적응을 핵심 목표로 한다.
MASE는 인간이 모든 상호작용 패턴을 수작업으로 설계하는 대신, 환경 피드백, 메타 수준 추론, 구조적 적응 사이의 루프를 자동화함으로써 에이전트를 정적 실행자에서 지속적으로 학습하고 공진화하는 참여자로 전환한다. 이 비전은 과학적 발견, 소프트웨어 공학, 인간-AI 협업 등 다양한 분야에서 자율적 가설 생성, 개발 파이프라인 공진화, 개인화된 상호작용 스타일 등을 가능하게 하며, 로봇, IoT, 사이버-물리 인프라와의 통합을 통해 물리적 환경과의 상호작용까지 확장될 수 있다. 궁극적으로 MASE는 자체적으로 진화하고 조정하며 장기적 적응이 가능한 재구성 가능 컴퓨팅 엔티티로 간주하는 스케일 가능하고 신뢰할 수 있는 AI 구현의 가능성을 제시한다.
Quote
Guided by the Three Laws of Self-Evolving AI Agents – Endure (safety adaptation), Excel (performance preservation), and Evolve (autonomous optimisation) – these systems are designed to:
- (I) Monitor their own performance and safety profile during operation;
- (II) Preserve or enhance capabilities through controlled, incremental updates;
- (III) Autonomously adapt prompts, memory structures, tool-use strategies, and even inter-agent topologies in response to shifting tasks, environments, and resources.
3 A Conceptual Framework of MASE
Summary
이 섹션에서는 자기 진화형 에이전트 시스템(self-evolving agentic systems)의 설계와 구현에 기반한 핵심 요소를 추상화하고 요약한 고수준 개념적 프레임워크(MASE, Multi-Agent Self-Evolving System)를 제안한다. 이 프레임워크는 기존의 에이전트 진화 및 최적화 방법론의 핵심 구조를 일반화하여, 다양한 접근 방식 간의 비교 분석과 분야 전체에 대한 체계적인 이해를 가능하게 한다. 특히, 기존 연구에서 제시된 안전성 확보, 성능 향상, 유연한 적응성 등의 목표를 포괄적으로 반영한 추상화 수준을 통해, 미래의 자기 진화형 에이전트 연구 및 개발에 대한 청사진을 제시한다.
3.1 Overview of the Self-Evolving Process
Summary
이 섹션에서는 자기 진화형 에이전트 시스템(self-evolving agent systems)의 핵심 프로세스인 자기 진화 과정(self-evolving process)을 체계적으로 개요로 설명한다. 이 과정은 일반적으로 반복적 최적화(iterative optimisation)를 통해 구현되며, 에이전트 시스템(agent system)이 성능 평가 및 환경 상호작용을 통해 얻은 피드백 신호를 기반으로 반복적으로 업데이트된다. 시스템 입력(system inputs)은 작업의 고수준 설명, 입력 데이터, 맥락 정보 또는 구체적인 예시로 구성되어 문제 설정을 정의하고, 에이전트 시스템(단일 에이전트 또는 다중 에이전트 구조)이 환경 내에서 작업을 수행한다.
환경(environment)은 사전 정의된 평가 지표를 통해 시스템의 효과성을 측정하고 피드백을 제공하며,
최적화자(optimiser)는 이 피드백을 바탕으로 LLM 파라미터 조정, 프롬프트 수정, 시스템 구조 개선 등의 알고리즘을 적용해 에이전트 시스템을 업데이트한다. 이 과정은 시스템 입력의 학습 예제 합성으로 데이터셋을 확장하는 것도 포함하며, 업데이트된 시스템은 다시 환경에 배포되어 다음 반복을 시작한다. 이는 폐쇄적 피드백 루프(closed feedback loop)를 형성해 다수의 반복을 통해 점진적으로 시스템을 개선하고, 사전 정의된 성능 임계값 또는 수렴 기준이 충족되면 종료된다.MASE(Multi-Agent Self-Evolving System) 개념 프레임워크를 기반으로 설계된 EvoAgentX는 이 자기 진화 프로세스를 자동화하는 최초의 오픈소스 프레임워크로, 에이전트 시스템의 생성, 실행, 평가, 최적화를 자동화하는 것이 특징이다.
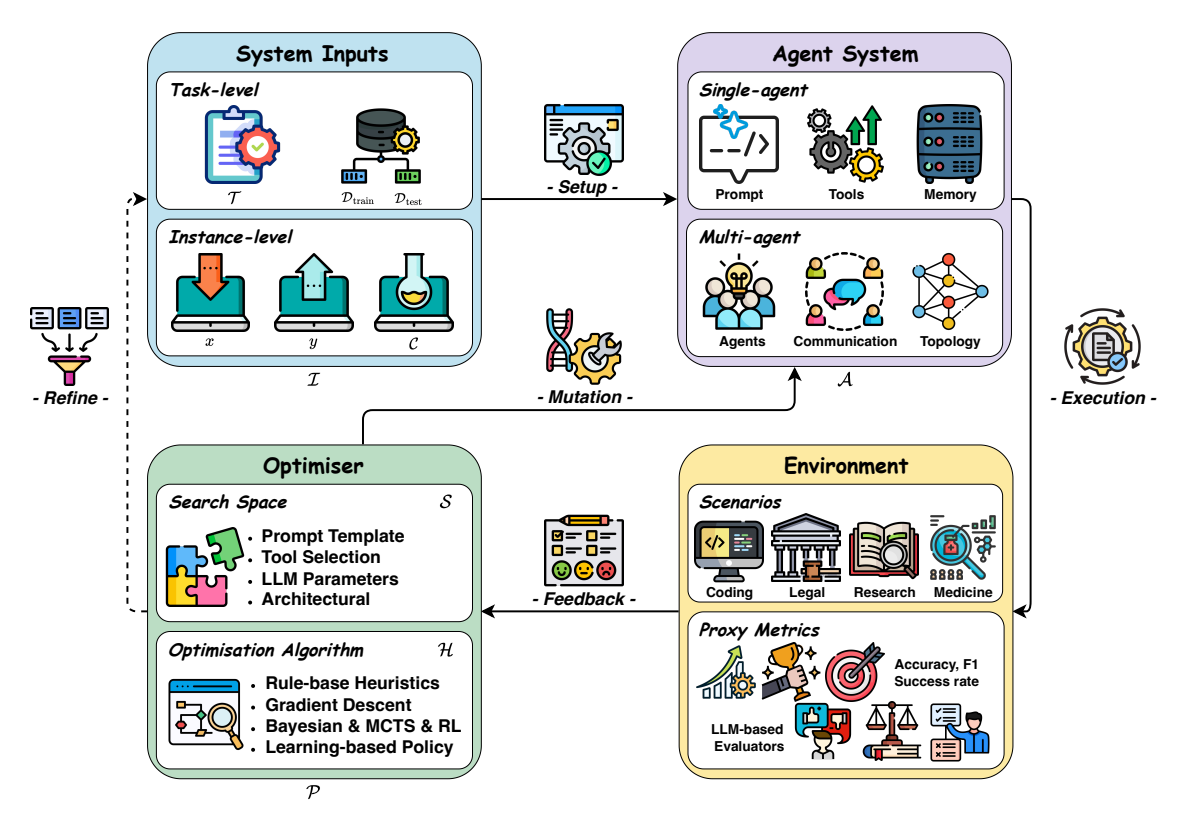
Figure 3. Conceptual framework of the self-evolving process in agent systems. The process forms an iterative optimisation loop comprising four components: System Inputs, Agent System, Environment, and Optimiser. System inputs define the task setting (e.g., task-level or instance-level). The agent system (in single- or multi-agent form) executes the specified task. The environment (depending on different scenarios) provides feedback via proxy metrics. The optimiser updates the agent system through a defined search space and optimisation algorithm until performance goals are met.
3.2 System Inputs
Summary
이 섹션에서는 에이전트 시스템 최적화를 위한 입력 정보의 구조를 정의하며, 시스템 입력 집합 이 작업 요구사항, 제약 조건, 데이터 등으로 구성됨을 설명한다.
태스크 레벨 최적화(Task-Level Optimisation)에서는 특정 작업 성능 향상을 목표로, 작업 설명 와 학습 데이터셋 을 입력으로 사용하며, 라벨 데이터가 부족한 경우 LLM 기반의 합성 데이터 생성 기법을 통해 대체 데이터셋을 생성하는 최근 연구 동향을 언급한다.
반면, 인스턴스 레벨 최적화(Instance-Level Optimisation)는 특정 예시의 성능 개선을 목표로, 입력-출력 쌍 와 추가 맥락 정보 를 입력으로 활용한다. 이러한 입력 구조는 MASE(Multi-Agent Self-Evolving System) 프레임워크 내에서 다양한 최적화 시나리오에 따라 유연하게 적용될 수 있음을 강조한다.
3.3 Agent Systems
Summary
이 섹션에서는 에이전트 시스템(Agent System)이 피드백 루프 내 핵심 최적화 대상인 점을 강조하며, 이는 입력에 따라 에이전트의 의사결정 과정과 기능을 정의하는 구성 요소로, 단일 에이전트 또는 협업하는 에이전트의 집합으로 구성될 수 있다고 설명한다.
에이전트 시스템은 기저 LLM(Large Language Model), 프롬프팅 전략(Prompting Strategy), 메모리 모듈(Memory Module), 도구 사용 정책(Tool-use Policy) 등 여러 구성 요소로 분해될 수 있으며, 최적화 방법은 목표에 따라 이들 중 하나 이상을 대상으로 한다.
기존 연구에서는 주로 LLM의 파인튜닝(Finetuning)을 통해 추론 및 계획 능력 향상 [Zelikman et al., 2022; Tong et al., 2024; Lai et al., 2024b] 또는 프롬프트 조정(Prompt Tuning)과 적절한 도구 선택을 통해 LLM 자체를 수정하지 않고도 작업별 성능 개선 [Yang et al., 2024a; Yuan et al., 2025b]에 집중하였다. 그러나 최근 연구에서는 다중 구성 요소의 동시 최적화(Joint Optimisation)를 탐구하는 방향으로 발전하고 있으며, 예를 들어 단일 에이전트 시스템에서는 LLM과 프롬프팅 전략을 함께 최적화하여 모델 행동을 작업 요구사항에 더 잘 맞추는 방법 [Soylu et al., 2024]이 제시되었고, 다중 에이전트 시스템에서는 프롬프트와 에이전트 간 위상 구조(Inter-agent Topology)를 동시에 최적화하여 전체 효과성 향상을 도모한 사례 [Zhang et al., 2025j; Zhou et al., 2025a]가 등장하고 있다.
3.4 Environments
Summary
이 섹션에서는 에이전트 시스템(agent system)이 작동하는 외부 환경(environment)의 역할을 설명하며, 이는 시스템의 입력 인식, 행동 실행, 결과 수신을 위한 핵심적인 외부 맥락으로 기능한다고 강조한다. 환경은 작업 유형에 따라 벤치마크 데이터셋에서 실시간 동적 환경(예: 코드 생성 시 컴파일러, 테스트 케이스, 과학 연구 시 데이터베이스, 시뮬레이션 플랫폼)까지 다양하게 구성될 수 있으며, 이는 에이전트의 실행 조건과 성능 평가 기준에 직접적인 영향을 미친다. 또한 환경은 피드백 신호(feedback signals)를 생성하는 중요한 역할을 수행하며, 이는 주로 정확도(accuracy), F1 점수, 성공률(success rate) 등의 평가 지표(evaluation metrics)를 통해 정량화된다. 라벨 데이터가 부족한 상황에서는 LLM 기반 평가자(LLM-based evaluators)가 활용되며, 이는 정확성(correctness), 관련성(relevance), 일관성(coherence) 등을 기준으로 대체 지표(proxy metrics)를 생성하거나 텍스트 형태의 피드백을 제공한다. 이와 같은 환경-피드백 메커니즘은 자기 진화 과정(self-evolving process)에서 시스템 최적화에 필수적인 정보를 제공하며, 다양한 적용 분야에서의 평가 전략은 제7장에서 상세히 다루어진다. 환경의 역할은 단순한 실행 맥락을 넘어, 에이전트의 지속적 학습과 적응을 위한 핵심적인 피드백 원천으로 작동하며, 이는 다중 에이전트 자기 진화(MASE) 시스템의 설계와 최적화에 직접적인 영향을 미친다.
3.5 Optimisers
Summary
이 섹션에서는 자기 진화형 에이전트 시스템(self-evolving agent systems)의 핵심 구성 요소인 최적화자(Optimisers, P)의 역할과 구조를 설명한다. 최적화자는 환경으로부터의 성능 피드백을 기반으로 에이전트 시스템 를 개선하는 데 책임이 있으며, 주어진 평가 지표 하에서 최적 성능을 달성하는 에이전트 구성 를 찾는 것이 목표이다. 수식적으로 이는 로 표현되며, 여기서 는 탐색 공간, 는 시스템 입력 에 대한 성능 평가 함수이다. 최적화자는 두 개의 핵심 구성 요소로 정의되는데, 첫째는 탐색 공간(Search Space, )으로, 에이전트 구성 중 최적화 대상이 되는 요소(예: 프롬프트, 도구 선택 전략, LLM 파라미터 등)의 범위를 정의하고, 둘째는 최적화 알고리즘(Optimisation Algorithm, )으로, 탐색 공간 내에서 후보 구성의 탐색 및 선택 전략을 결정한다. 이 알고리즘은 규칙 기반 휴리스틱, 경사 하강법, 베이지안 최적화, Monte Carlo Tree Search(MCTS), 강화 학습, 진화 전략, 학습 기반 정책 등 다양한 방법을 포함한다. 최적화자 의 조합은 에이전트 시스템의 성능 향상에 대한 적응 효율성을 결정하며, 이후 섹션에서는 단일 에이전트, 다중 에이전트, 도메인 특화 시스템 등 세 가지 설정에서의 대표적 최적화자 설계와 구현을 각각 다룬다. 이와 관련된 최적화 설정의 계층적 분류와 대표적 방법은 도표 5에서 시각적으로 정리되어 있다.
Optimisers (P) are the core component of the self-evolving feedback loop, responsible for refining the agent system A based on performance feedback from the environment. Their objective is to search, via specialised algorithms and strategies, for the agent configuration that achieves the best performance under the given evaluation metric. Formally, this can be expressed as:
\mathcal{A}^* = \arg\max_{\mathcal{A} \in \mathcal{S}} \mathcal{O}(\mathcal{A}; \mathcal{I}), \tag{1}
where S denotes the search space of configurations, O(A; I) ∈ R is the evaluation function that maps the performance of A on the given system inputs I to a scalar score, and A∗ denotes the optimal agent configuration.
An optimiser is typically defined by two core components: (1) search space (S): This defines the set of agent configurations that can be explored and optimised. The granularity of S depends on which part(s) of the agent system are subject to optimisation, ranging from agent prompts or tool selection strategies to continuous LLM parameters or architectural structures. (2) optimisation algorithm (H): This specifies the strategy used to explore S and select or generate candidate configurations. It can include rule-based heuristics, gradient descent, Bayesian optimisation, Monte Carlo Tree Search (MCTS), reinforcement learning, evolutionary strategies, or learning-based policies. Together, the pair (S, H) defines the behaviour of the optimiser and determines how efficiently and effectively it can adapt the agent system toward better performance.
In the following sections, we introduce typical optimisers in three different settings: single-agent systems (Section 4), multi-agent systems (Section 5), and domain-specific agent systems (Section 6). Each setting exhibits distinct characteristics and challenges, leading to different designs and implementations of optimisers. In single-agent optimisation, the focus is on improving an individual agent’s performance by tuning LLM parameters, prompts, memory mechanisms, or tool-use policies. In contrast, multi-agent optimisation extends the scope to optimising not only individual agents but also their structural designs, communication protocols, and collaboration capabilities. Domain-specific agent optimisation presents additional challenges, where optimisers must account for specialised requirements and constraints inherent to particular domains, leading to tailored optimiser designs. A comprehensive hierarchical categorisation of these optimisation settings and representative methods is provided in Figure 5.
4 Single-Agent Optimisation
Summary
이 섹션에서는 단일 에이전트 최적화(Single-Agent Optimisation)의 주요 접근 방식을 에이전트 시스템 내 구성 요소(prompt, memory, tool)에 따라 분류하여 설명한다. 단일 에이전트 최적화는 기존 최적화 피드백 루프에서 제시된 도전 과제인 최적화 알고리즘 설계에 초점을 맞추며, 최적화 대상 구성 요소(검색 공간 정의), 향상시키려는 능력, 그리고 효과적인 개선을 위한 전략 선택이 핵심 요소로 작용한다. 구체적으로, LLM 행동 최적화(LLM Behaviour Optimisation)는 파라미터 튜닝이나 테스트 시간 스케일링 기법을 통해 LLM의 추론 및 계획 능력을 향상시키는 방식을, 프롬프트 최적화(Prompt Optimisation)는 정확하고 작업 관련된 출력을 유도하기 위해 프롬프트를 적응시키는 방식을, 메모리 최적화(Memory Optimisation)는 과거 정보 또는 외부 지식의 저장, 검색, 추론 능력을 강화하는 방식을, 도구 최적화(Tool Optimisation)는 기존 도구의 효과적 활용이나 새로운 도구의 자율적 생성/구성에 초점을 맞춘다. 또한, 도메인 특화 최적화(Domain-Specific Optimisation)를 포함한 자기 진화형 에이전트 최적화 방법(Agentic Self-Evolution Methods)의 계층적 분류는 도메인별 대표 연구 사례와 함께 도표 5에서 시각적으로 정리되어 있다. 이 분류는 단일 에이전트, 다중 에이전트, 특정 도메인에 따른 최적화 전략의 구조적 차이를 명확히 드러내며, 각 구성 요소에 대한 최적화 접근 방식의 체계적 이해를 가능하게 한다.
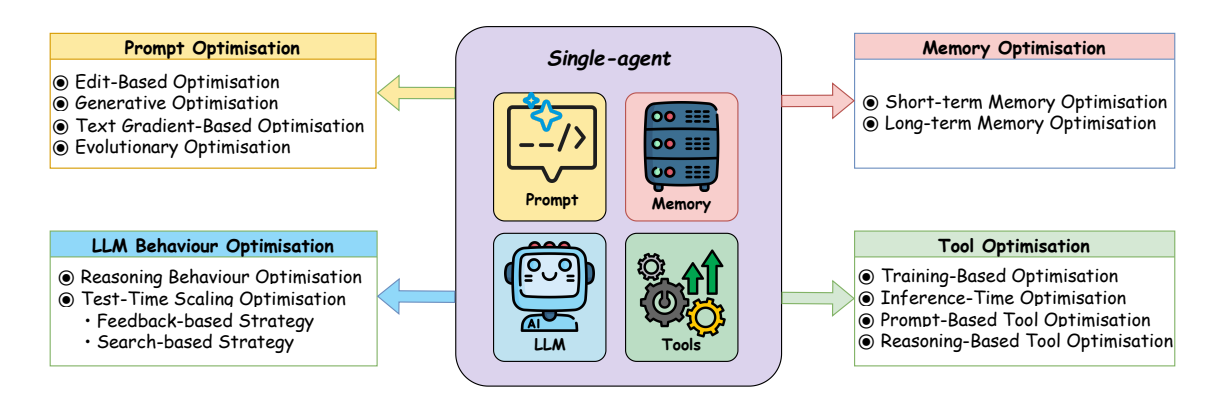
Figure 4 An overview of single-agent optimisation approaches, categorised by the targeted component within the agent system: prompt, memory, and tool.
Single-agent optimisation focuses on improving the performance of a single-agent system. According to the optimisation feedback loop introduced earlier, the key challenge lies in the design of optimisers for updating the system. This involves identifying the specific components of the agent system to optimise (i.e., search space), determining the particular capabilities to enhance, and choosing appropriate optimisation strategies to effectively achieve these improvements (i.e., optimisation algorithm).
In this section, we organise single-agent optimisation approaches based on the targeted component within the agent system, as this determines both the structure of the search space and the choice of optimisation methods. Specifically, we focus on four major categories: (1) LLM Behaviour optimisation, which aims to improve the LLM’s reasoning and planning capabilities through either parameter tuning or test-time scaling techniques; (2) Prompt optimisation, which focuses on adapting prompts to guide the LLM towards producing more accurate and task-relevant outputs; (3) Memory optimisation, which aims to enhance the agent’s ability to store, retrieve, and reason over historical information or external knowledge; (4) Tool optimisation, which focuses on enhancing the agent’s ability to effectively leverage existing tools, or autonomously create or configure new tools to accomplish complex tasks. Figure 4 shows the major categories of single-agent optimisation approaches.
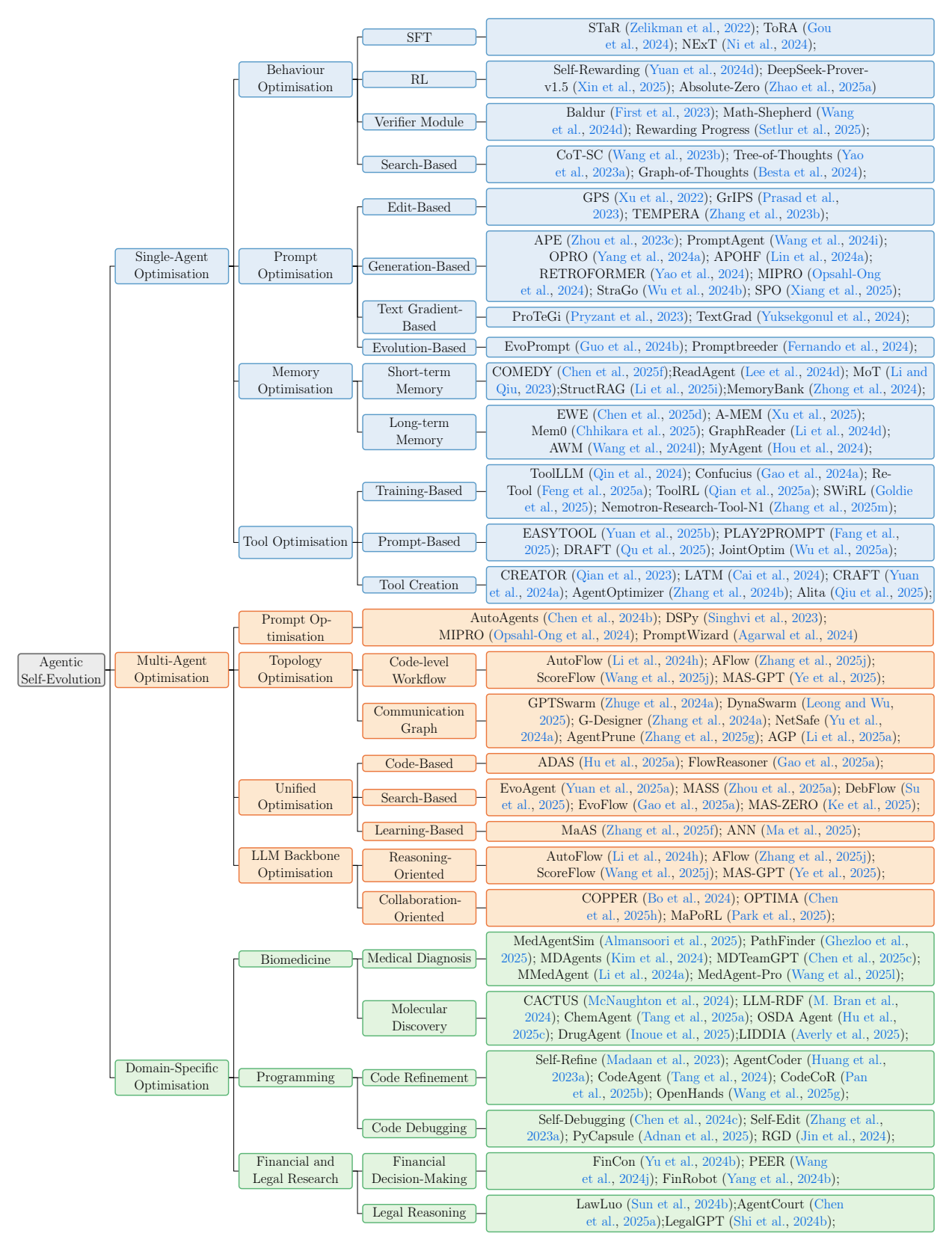
Figure 5 A comprehensive hierarchical categorisation of Agentic Self-Evolution methods, encompassing single-agent, multi-agent and domain-specific optimisation categories, illustrated with selected representative works.
4.1 LLM Behaviour Optimisation
Summary
이 섹션에서는 단일 에이전트 시스템(single-agent system)의 핵심 기반인 백본 대규모 언어 모델(Backbone LLMs)의 계획 및 추론 능력 향상이 에이전트 시스템의 전체적 효과성에 중대한 영향을 미친다는 점을 강조한다. 최근 연구는 이 문제를 해결하기 위해 두 가지 주요 접근 방식으로 나뉘는데, 첫째, 모델 파라미터를 직접 업데이트하는 학습 기반 방법(training-based methods)으로, 추론 능력과 작업 성능 향상을 목표로 한다. 둘째, 파라미터 수정 없이 추론 시 행동을 개선하는 검증 시간 기반 방법(test-time methods)으로, 모델의 내재적 능력을 활용해 실시간 성능 최적화를 추구한다. 이 섹션에서는 이 두 범주에 속하는 대표적 접근 방식을 종합적으로 검토하고 요약한다.
Backbone LLMs lay the foundation for single-agent systems, serving as the primary component responsible for planning, reasoning, and task execution. Therefore, enhancing the planning and reasoning capabilities of the LLM is central to improving the overall effectiveness of the agent system. Recent efforts in this direction broadly fall into two categories: (1) training-based methods, which directly update the model’s parameters to improve reasoning ability and task performance; (2) test-time methods, which aim to improve LLM’s behaviour during inference without modifying its parameters. In the following, we review and summarise representative approaches from both categories.
4.1.1 Training-Based Behaviour Optimisation
Summary
이 섹션에서는 대규모 언어 모델(LLM)이 자연어 처리 능력은 뛰어나지만 복합적 추론이나 다단계 의사결정에 필요한 추론 능력이 부족하다는 한계를 지적하고, 이를 극복하기 위한 학습 기반 행동 최적화(Training-Based Behaviour Optimisation) 방법을 탐구한다. 감독 학습 양자화(Supervised Fine-tuning, SFT)에서는 정답과 추론 과정이 명시된 라벨 데이터를 기반으로 모델을 학습시켜, 입력 질문에서 최종 답변으로 이르는 구조화된 추론 경로(reasoning trajectories)를 생성하도록 유도한다. 예를 들어, STaR은 정확히 해결한 사례를 기반으로 반복 학습을 수행하고, NExT는 단위 테스트로 검증된 자기 생성 경로를 통해 프로그램 복구 작업에 특화된 에이전트를 진화시킨다. 반면, 강화 학습(Reinforcement Learning, RL)은 추론 과정을 순차적 의사결정으로 모델링하고, 정확한 추론 경로에 대한 보상으로 모델을 최적화한다. 이에 DPO(Preference-based Optimisation)와 MCTS(蒙特卡洛树搜索) 기반의 자기 비판 메커니즘을 결합한 Agent Q, 수학적 문제 해결에 적용된 Tülu 3, 그리고 정답 검증이 가능한 경우에 그룹 상대 정책 최적화(Group Relative Policy Optimisation)를 활용한 DeepSeek-R1 등이 제시된다. 또한, Absolute Zero는 문제 제시자와 해결자 역할을 번갈아 수행하며 스스로 생성한 문제를 해결하는 방식으로, R-Zero는 해결자의 현재 능력에 맞춘 맞춤형 문제를 생성하는 이중 모드 프레임워크를 통해 외부 감독 없이 서로 진화하는 시스템을 구현한다. 이러한 접근들은 LLM 기반 에이전트의 복잡한 추론 능력 향상과 자기 진화 기술의 발전에 기여하고 있다.
While LLMs have demonstrated strong linguistic capabilities (Zhao et al., 2023), recent research (Wu et al., 2024c) highlights a notable gap between their fluency in natural language and their ability to perform complex reasoning. This discrepancy limits the effectiveness of LLM-based agents in tasks that require multi-step inference and complex decision-making. To address this, recent work has explored reasoning-oriented training methods, using supervised fine-tuning (SFT) and reinforcement learning (RL) to help models systematically evaluate and refine their responses.
Supervised Fine-tuning. The core idea of supervised fine-tuning is to train agents using annotated data that contains detailed reasoning steps, allowing the model to learn a complete mapping from the input question, through intermediate reasoning processes, to the final answer. This approach typically relies on carefully constructed reasoning trajectories, which can typically be constructed from (1) rollouts generated by the agent itself during execution, and (2) demonstrations produced by stronger teacher agents. By imitating these trajectories, the agent acquires the ability to perform step-by-step reasoning in a structured manner. STaR (Zelikman et al., 2022) proposes an iterative fine-tuning procedure, where the model is trained on instances it has solved correctly and refines incorrect traces to generate better trajectories. Based on this idea, NExT (Ni et al., 2024) uses self-generated trajectories filtered by unit test correctness to self-evolve agents for program repair tasks. Similarly, Deepseek-Prover (Xin et al., 2024) progressively evolve the agent by iteratively training the policy model with verified proofs, enabling it to generate increasingly accurate formal proofs for theorem-proving tasks. Another line of work fine-tunes agents on trajectories generated by proprietary LLMs, across domains such as mathematics (Gou et al., 2024; Yin et al., 2024) and science (Ma et al., 2024). Beyond agentic capability, Min et al. (2024); Huang et al. (2024c); Labs (2025) train models based on trajectories generated by OpenAI o1 (Jaech et al., 2024) to replicate its thinking capability, aiming to further improve the agent backbone’s reasoning ability.
Reinforcement Learning. RL treats reasoning as a sequential decision-making process where the model is rewarded for producing correct or high-quality reasoning paths. One of the strategies is preference-based optimisation, where DPO (Rafailov et al., 2023) is applied using preference pairs generated from various sources, such as test case performance, correctness of final outcomes, or pseudo-labels from trained process reward models (PRMs) (Hui et al., 2024; Min et al., 2024; Jiao et al., 2024; Liu et al., 2025f). Yuan et al. (2024d) further introduce a self-evolving framework where the policy model uses its own judgments to iteratively refine its reasoning ability. Similarly, Agent Q (Putta et al., 2024) combines MCTS-guided search and a self-critique mechanism to iteratively improve agents’ decision making in web environments via DPO, leveraging both successful and failed trajectories. In another line of work, Tülu 3 (Lambert et al., 2024) applies reinforcement learning with verifiable rewards across mathematical and instruction-following tasks without any learned reward model. Notably, DeepSeek-R1 (Guo et al., 2025) further demonstrates the feasibility of pure RL with Group Relative Policy Optimisation (Shao et al., 2024) when ground-truth verification is possible. Building on this direction, Xin et al. (2025) extend the idea to enhance DeepSeek-Prover by incorporating reinforcement learning from proof assistant feedback. Liu et al. (2025e) further explore self-evolving training in the multimodal setting by introducing MSTAR, a framework that leverages RL to overcome performance saturation and enhance reasoning capabilities through iterative self-improvement. Beyond using verifiable rewards in a fixed dataset, Absolute Zero (Zhao et al., 2025a) trains a single model that alternates between task proposer and solver roles, self-evolving by generating and solving its own problems. Similarly, R-Zero (Huang et al., 2025) employs a dual-mode framework in which a challenger generates tasks tailored to the solver’s current competence, enabling both to evolve iteratively without external supervision.
4.1.2 Test-Time Behaviour Optimisation
Summary
이 섹션에서는 추론 시점 행동 최적화(Test-Time Behaviour Optimisation)를 통해 모델이 추가 학습 없이 추론 과정에서 추론 예산을 늘려 추론 시간 동안 사고를 더 깊이 확장하는 방식을 제시한다. 두 가지 주요 전략을 통해 추론 능력을 확장할 수 있으며, 첫 번째 전략은 외부 피드백을 통한 추론 유도(Feedback-based Strategy)로, 생성된 출력의 품질을 기반으로 모델 행동을 조정하는 방식이다. 이는 최종 결과 기반 피드백(Outcome-level Feedback)과 단계별 피드백(Step-level Feedback)으로 구분되며, 최종 결과 기반 피드백은 코드 생성 시 컴파일러를 활용한 검증(예: CodeT, LEVER)이나 단계별 피드백은 추론 과정 중 발생하는 오류를 즉시 수정하기 위해 프로세스 보상 모델(Process Reward Models)을 사용하는 방식이다. 두 번째 전략은 탐색 기반 접근(Search-based Strategy)으로, 여러 가능한 추론 경로를 병렬적으로 탐색해 해공간을 효과적으로 탐색하는 방식이다. 이는 최고 N개 선택(Best-of-N, CoT-SC), 광역 탐색(Beam Search, DBS), 몬테카를로 트리 탐색(Monte Carlo Tree Search, MCST, Tree-of-Thoughts) 등 다양한 방법을 활용하며, 그래프 기반 추론(Graph-of-Thoughts)이나 동적 메모리 버퍼(Buffer-of-Thoughts)를 통해 유연한 추론 구조를 구현한다. 특히, 단계별 피드백은 최종 결과만 평가하는 기존 방법보다 추론 과정의 오류를 더 정밀하게 수정할 수 있어, 최근 연구에서 주목받고 있다.
As training resources become increasingly constrained and API-based models cannot be fine-tuned, test-time compute emerges as a solution to these limitations by enabling models to refine or extend their reasoning capabilities during inference without additional training. By increasing the inference budget, models are able to “think longer”.
Scaling test-time capabilities can be achieved through two primary strategies. The first involves guiding inference through the incorporation of external feedback, which facilitates the model’s refinement of its responses. The second strategy focuses on generating multiple candidate outputs using more efficient sampling algorithms. This is followed by a selection process where a verifier identifies the most suitable output. Notably, these two approaches are in fact closely related. The feedback used to guide generation in the former can naturally serve as a verifier in the latter.
Feedback-based Strategy. A natural method is to adjust a model’s behaviour based on the quality of its generated outputs. This process typically relies on feedback from a verifier, which provides either an exact or estimated score to guide the model. We categorise feedback into two types. Outcome-level feedback provides a single score or signal based on the final output, regardless of the number of reasoning steps taken. For tasks where ground-truth is easily accessible, the verifier can be implemented as an external tool to provide accurate feedback. For example, CodeT (Chen et al., 2023) and LEVER (Ni et al., 2023) leverage a compiler to execute the generated code and validate its correctness against test cases. START (Li et al., 2025c) and CoRT (Li et al., 2025b) employ hint-based tool invocation to enhance long CoT reasoning. Similarly, Baldur (First et al., 2023) leverages error messages from proof assistants to further repair incorrect proofs generated by LLMs. However, for most tasks, ground-truth is not always available at inference time. As a result, a more general approach is to train a model to serve as the verifier that assigns a score to each candidate response (Liu et al., 2024a, 2025c), allowing them to be ranked based on predicted quality. However, this form of feedback is relatively sparse, as it evaluates only the final output. In contrast, step-level feedback evaluates each intermediate step during the generation process, offering finer-grained supervision. Relying solely on outcome feedback often leads to the unfaithful reasoning problem (Turpin et al., 2023), where incorrect reasoning chains may still result in correct final answers. To address this, recent work (Wang et al., 2024d; Jiao et al., 2024; Setlur et al., 2025) increasingly focuses on training process reward models to detect and correct errors throughout the reasoning process, generally yielding better improvement than using outcome-level feedback.
Search-based Strategy. Complex reasoning tasks often admit multiple valid paths leading to the correct solution. Search-based approaches take advantage of this property by exploring several candidate reasoning trajectories in parallel, enabling the model to better navigate the solution space. With the help of critic models, various search strategies have been developed to guide the decoding process. For example, CoT-SC (Wang et al., 2023b) adopts a best-of-N approach: it generates multiple reasoning paths and selects the final answer based on the majority vote over outcomes. DBS (Zhu et al., 2024) proposes the use of beam search in combination with step-level feedback to refine intermediate reasoning steps, while CoRe (Zhu et al., 2023) and Tree-of-Thoughts (Yao et al., 2023a) explicitly model the reasoning process as a tree structure, using Monte Carlo Tree Search (MCST) for a balance between exploration and exploitation during searching. Forest-of-Thought (Bi et al., 2025) further generalises this idea by enabling multiple trees to make independent decisions and applying a sparse activation mechanism to filter and select outputs from the most relevant trees. Beyond tree-based methods, other approaches have also explored alternative structural formulations of reasoning. Graph-of-Thoughts (Besta et al., 2024) organises intermediate thoughts as nodes in a graph and applies graph-based operations to support flexible reasoning and information flow. Buffer-of-Thoughts (Yang et al., 2024c) introduces a dynamic memory buffer to store and instantiate meta-level thoughts during reasoning.
4.2 Prompt Optimisation
Summary
이 섹션에서는 단일 에이전트 시스템에서 프롬프트(prompt)가 에이전트의 목표, 행동, 작업 전략을 정의하는 핵심 요소임을 강조하며, 대규모 언어 모델(LLM)이 프롬프트에 매우 민감한 특성—문장 구조, 형식, 단어 순서의 작은 변화가 모델 행동과 출력에 큰 영향을 미침—을 지적한다. 이로 인해 안정적이고 일반화 가능한 AI 에이전트 시스템 설계가 어렵게 되어, 프롬프트 최적화(Prompt Optimisation) 기법의 개발이 필요하다고 설명한다. 프롬프트 최적화 방법은 프롬프트 공간을 탐색하는 전략에 따라 편집 기반(edit-based), 생성 기반(generative), 텍스트 기울기 기반(text gradient-based), 진화 기반(evolutionary)의 네 가지 주요 범주로 분류되며, 이들 기법은 모델 성능 향상을 위한 고질적인 프롬프트를 자동으로 탐색하는 데 초점을 맞춘다. 이는 이전 섹션에서 다룬 학습 기반 행동 최적화(Training-Based Behaviour Optimisation)와 병행하여, 단일 에이전트 최적화의 핵심 구성 요소인 프롬프트의 설계와 개선을 위한 체계적 접근을 제시한다.
In single-agent systems, prompts play a critical role in defining the agent’s goals, behaviour, and task-specific strategies. They typically contain instructions, illustrative demonstrations, and contextual information that guide the underlying LLM in generating appropriate outputs. However, it is well-known that LLMs are highly sensitive to prompts; even minor variations in phrasing, formatting, or word ordering can lead to significant changes in the LLMs’ behaviour and output (Loya et al., 2023; Zhou et al., 2024b). This sensitivity makes it
difficult to design robust and generalisable AI agent systems, motivating the development of prompt optimisation techniques to automatically search for high-quality prompts. Prompt optimisation methods can be categorised based on the strategies used to navigate the prompt space and identify high-quality prompts that enhance model performance. In this section, we review and summarise four representative categories: edit-based methods, generative methods, text gradient-based methods, and evolutionary methods.
4.2.1 Edit-Based Prompt Optimisation
Summary
이 섹션에서는 프롬프트 최적화(Prompt Optimisation)의 기존 접근 방식인 편집 기반(Edit-Based) 방법을 설명하며, 이는 토큰 삽입, 삭제, 교체 등의 사전 정의된 편집 연산을 통해 인간이 작성한 프롬프트를 반복적으로 개선하는 방식이다. 예를 들어, GRIPS는 지시사항을 문장 단위로 분할하고, 삭제, 교환, 재구성, 추가 등의 문장 수준 편집을 통해 프롬프트 품질을 점진적으로 향상시키는 반면, Plum은 유전 알고리즘과 같은 메타휴리스틱 전략을 도입해 편집 공간에서 더 효과적인 최적화를 수행한다. 또한, TEMPERA는 편집 과정을 강화 학습 문제로 프레임화하여, 쿼리에 따라 적응적인 프롬프트를 생성하는 정책 모델을 학습함으로써 효율성을 높였다. 이러한 방법들은 프롬프트 공간에서의 로컬 서치 문제로 접근하며, 원본 지시사항의 핵심 의미를 유지하면서도 점진적으로 프롬프트 품질을 개선하는 데 초점을 맞춘다.
Earlier attempts in prompt optimisation focus on edit-based approaches, which iteratively refine human-written prompts through predefined editing operations, such as token insertion, deletion or substitution (Prasad et al., 2023; Pan et al., 2024a; Lu et al., 2024c; Zhang et al., 2023b; Zhou et al., 2023a; Agarwal et al., 2024). These methods treat prompt optimisation as a local search problem over prompt space, aiming to gradually improve prompt quality while preserving the core semantics of the original instruction. For example, GRIPS (Prasad et al., 2023) splits instructions into phrases and applies phrase-level edit operations: delete, swap, paraphrase, and addition, to progressively improve prompt quality. Plum (Pan et al., 2024a) extends GRIPS by incorporating metaheuristic strategies such as simulated annealing, mutation, and crossover. TEMPERA (Zhang et al., 2023b) further frames the editing process as a reinforcement learning problem, training a policy model to perform different editing techniques to construct query-dependent prompts efficiently.
4.2.2 Generative Prompt Optimisation
Summary
이 섹션에서는 편집 기반 방법(edit-based methods)과 달리 생성 기반 접근(generative approaches)이 기초 프롬프트와 다양한 최적화 신호를 기반으로 LLM을 활용해 전혀 새로운 프롬프트를 반복적으로 생성함으로써 더 넓은 프롬프트 공간을 탐색하고, 다양성과 의미 풍부한 후보를 생성할 수 있음을 설명한다. 최적화 신호는 사전 정의된 재작성 규칙, 입력-출력 예시, 데이터셋/프로그램 설명, 이전 프롬프트와 평가 점수, 작업 목적 및 제약 조건을 명시하는 메타 프롬프트, 그리고 변경 방향을 지시하는 신호 등으로 구성되며, ORPO(이전 후보와 평가 점수를 기반으로 새로운 지침 생성)와 StraGo(성공 및 실패 사례의 통찰을 통한 품질 높은 프롬프트 생성) 같은 대표적 방법이 언급된다. 또한 Gibbs 샘플링, 몬테카를로 트리 탐색(MCTS), 베이지안 최적화, 신경 밴딧 기반 방법 등 고급 탐색 전략과 결합해 프롬프트 공간을 효율적으로 탐색하는 방식이 제시되며, PromptAgent(MCTS 기반 전략적 계획 문제로의 변환)와 MIPRO(베이지안 최적화를 통한 최적 지시문 및 few-shot 예시 조합 탐색) 같은 사례가 소개된다. 최근에는 강화 학습(reinforcement learning)을 활용해 프롬프트 생성 정책 모델을 학습하는 접근법도 탐구되며, Retroformer(이전 실패 사례의 근본 원인 요약을 통한 반복적 프롬프트 개선)가 예시로 제시된다. 이 방법들은 기존 편집 기반 접근보다 프롬프트 공간의 탐색 범위 확대와 다양성 향상이라는 장점을 갖는다.
In contrast to edit-based methods that apply local modifications to prompts, generative approaches leverage LLMs to iteratively generate entirely new prompts, conditioned on a base prompt and various optimisation signals. Compared to local edits, generative methods can explore a broader region of the prompt space and produce more diverse and semantically rich candidates.
The prompt generation process is typically driven by a variety of optimisation signals that guide the LLM towards producing improved prompts. These signals may include predefined rewriting rules (Xu et al., 2022; Zhou et al., 2024a), input-output examplars (Zhou et al., 2023c; Xu et al., 2024b), and dataset or program descriptions (Opsahl-Ong et al., 2024). Additional guidance can come from prior prompts along with their evaluation scores (Yang et al., 2024a), meta-prompts that specify task objectives and constraints (Ye et al., 2023; Hsieh et al., 2024; Wang et al., 2024i; Xiang et al., 2025), as well as signals that indicate the desired direction of change (Fernando et al., 2024; Guo et al., 2024b; Opsahl-Ong et al., 2024). Moreover, some methods also leverage success and failure examples to highlight effective or problematic prompt patterns (Wu et al., 2024b; Yao et al., 2024). For example, ORPO (Yang et al., 2024a) generates new instructions by prompting the LLM with previously generated candidates and their evaluation scores. StraGo (Wu et al., 2024b) leverages insights from both successful and failure cases to identify critical factors for obtaining high-quality prompts. The optimisation signals can be further integrated into advanced search strategies, such as Gibbs sampling (Xu et al., 2024b), Monte Carlo tree search (MCTS) (Wang et al., 2024i), Bayesian optimisation (Opsahl-Ong et al., 2024; Lin et al., 2024b; Hu et al., 2024; Schneider et al., 2025; Wan et al., 2025), and neural bandit-based methods (Lin et al., 2024b; Shi et al., 2024a; Lin et al., 2024a). These search strategies enable more efficient and scalable exploration of the prompt space. For instance, PromptAgent (Wang et al., 2024i) formulates prompt optimisation as a strategic planning problem and leverages MCTS to efficiently navigate the expert-level prompt space. MIPRO (Opsahl-Ong et al., 2024) employs Bayesian optimisation to efficiently search for the optimal combination of instruction candidates and few-shot demonstrations.
While most generative approaches use a frozen LLM to generate new prompts, recent work has explored the use of reinforcement learning to train a policy model for prompt generation (Deng et al., 2022; Sun et al., 2024a; Yao et al., 2024; Wang et al., 2025k). For example, Retroformer (Yao et al., 2024) trains a policy model to iteratively refine prompts by summarising the root cause of previous failed cases.
4.2.3 Text Gradient-Based Prompt Optimisation
Summary
이 섹션에서는 기존 편집 기반(edit-based) 및 생성 기반(generative-based) 프롬프트 최적화 방법 외에, 텍스트 기울기(text gradient)를 활용한 새로운 접근 방식을 소개한다. 이 방법은 신경망의 수치 기울기 계산 대신, 자연어 피드백(natural language feedback)을 생성해 프롬프트의 최적화 방향을 제시하는 것으로, 이를 **“텍스트 기울기”**라고 정의한다. 예를 들어, ProTeGi는 현재 프롬프트에 대한 비판적 피드백을 토대로, 기울기의 반대 방향으로 프롬프트를 수정하며, 이 과정은 빔 서치(beam search)와 밴딧 선택(bandit selection) 절차를 통해 효율적으로 수행된다. TextGrad는 이 아이디어를 확장해 복합 AI 시스템에서 사용되는 프롬프트, 코드, 기호 변수 등을 반복적으로 개선하는 프레임워크로, 텍스트 피드백을 자동 미분(automatic differentiation)과 유사하게 활용한다. 또한, Agent Symbolic Learning은 언어 에이전트를 기호 네트워크로 모델링해, 백프로파게이션(back-propagation) 및 기울기 하강(gradient descent)의 기호적 유사체를 통해 프롬프트, 도구, 워크플로우를 자율적으로 최적화하는 데이터 중심 접근법을 제안한다. 이와 같은 기법들은 복합 AI 시스템(compound AI systems) 내에서 모델 파라미터, 프롬프트, 하이퍼파라미터 등 이질적 구성 요소(heterogeneous components)의 자동 최적화를 목표로 하며, 기존 방법보다 더 유연한 프롬프트 공간 탐색이 가능하다는 점에서 주목받고 있다.
In addition to editing and generating prompts directly, a more recent line of work explores the use of text gradients to guide prompt optimisation (Pryzant et al., 2023; Yuksekgonul et al., 2024; Wang et al., 2024g; Austin and Chartock, 2024; Yüksekgönül et al., 2025; Tang et al., 2025c; Zhang et al., 2025l). These methods draw inspiration from gradient-based learning in neural networks, but instead of computing numerical gradients over
model parameters, they generate natural language feedback, which is referred to as “text gradient”, that guides how a prompt should be updated to optimise a given objective. Once the text gradient is obtained, the prompt is updated according to the feedback. The key components within such approaches lie in how the text gradients are generated and how they are subsequently used to update the prompt. For example, ProTeGi (Pryzant et al., 2023) generates text gradients by criticising the current prompt. Subsequently, it edits the prompt in the opposite semantic direction of the gradient. Such “gradient descent” steps are guided by a beam search and bandit selection procedure to find optimal prompts efficiently. Similarly, TextGrad (Yuksekgonul et al., 2024; Yüksekgönül et al., 2025) generalises this idea to a broader framework for compound AI systems. It treats textual feedback as a form of “automatic differentiation” and uses LLM-generated suggestions to iteratively improve components such as prompts, code, or other symbolic variables. Another work (Zhou et al., 2024c) proposes agent symbolic learning, a data-centric framework that models language agents as symbolic networks and enables them to autonomously optimise their prompts, tools, and workflows via symbolic analogues of back-propagation and gradient descent. Recent work (Wu et al., 2025c) also explores the prompt optimisation in compound AI systems, where its goal is to automatically optimise the configuration across a heterogeneous set of components and parameters, e.g., model parameters, prompts, model selection choice, and hyperparameters.
4.2.4 Evolutionary Prompt Optimisation
Summary
이 섹션에서는 프롬프트 최적화(Prompt Optimisation)에 진화 알고리즘(Evolutionary Algorithms)을 적용한 새로운 접근 방식을 소개한다. 이 방법은 유전 알고리즘(GA)과 차분 진화(DE)와 같은 진화적 연산자를 활용해 프롬프트 최적화를 진화적 과정으로 모델링하며, 후보 프롬프트의 집단(population of candidate prompts)을 반복적으로 변이, 교차, 선택 등의 연산을 통해 개선한다. 예를 들어, EvoPrompt는 GA와 DE를 결합해 부모 프롬프트의 세그먼트를 조합하고 특정 요소에 무작위 변이를 도입해 새로운 후보 프롬프트를 생성하는 방식을 채택한다. 반면 Promptbreeder는 변이 프롬프트(mutation prompts)를 활용해 작업 프롬프트를 진화시키는데, 이 변이 프롬프트는 사전 정의된 지시사항이나 LLM이 동적으로 생성한 지시사항으로 구성되어 유연하고 적응적인 최적화 메커니즘을 가능하게 한다. 이러한 접근법은 기존의 생성 기반(generative-based) 프롬프트 최적화와 달리, 진화적 탐색을 통해 더 넓은 프롬프트 공간을 탐색할 수 있는 장점을 갖는다.
In addition to the above optimisation techniques, evolutionary algorithms have also been explored as a flexible and effective approach for prompt optimisation (Guo et al., 2024b; Fernando et al., 2024). These approaches treat prompt optimisation as an evolutionary process, maintaining a population of candidate prompts that are iteratively refined through evolutionary operators such as mutation, crossover, and selection. For example, EvoPrompt (Guo et al., 2024b) leverages two widely used evolutionary algorithms: Genetic Algorithm (GA) and Differential Evolution (DE), to guide the optimisation process to find the high-performing prompts. It adapts the core evolutionary operations, namely mutation and crossover, to the prompt optimisation setting, where new candidate prompts are generated by combining segments from two parent prompts and introducing random alternation to specific elements. Similarly, Promptbreeder (Fernando et al., 2024) also iteratively mutates a population of task-prompts to evolve these prompts. A key feature is its use of mutation prompts, which are instructions that specify how task-prompts should be modified during the mutation process. These mutation prompts can be either predefined or generated dynamically by the LLM itself, enabling a flexible and adaptive mechanism for guiding prompt evolution.
4.3 Memory Optimisation
Summary
이 섹션에서는 메모리 최적화(Memory Optimisation)가 에이전트의 장기적 추론 및 환경 적응 능력 향상에 핵심적인 역할을 함을 강조하며, 제한된 컨텍스트 윈도우와 망각(forgetting) 문제로 인한 맥락 편차(context drift) 및 허위 생성(hallucination) 등의 한계를 지적한다. 기존 연구는 학습 시간(training-time) 기반 기법(예: 미세 조정, 지식 편집)과 달리, 추론 시간(inference-time)에 집중하는 메모리 전략(memory strategies)을 통해 모델 파라미터 수정 없이 메모리 활용도를 향상시키는 방향으로 발전하고 있다고 설명한다. 이에 따라 단기 메모리(short-term memory)와 장기 메모리(long-term memory)의 두 최적화 목표로 기존 방법을 분류한다. 단기 메모리는 활성 컨텍스트 내 일관성을 유지하는 데 초점을 맞추며, 장기 메모리는 세션 간 지속적인 정보 검색을 지원한다. 이 연구는 정적 메모리 형식(internal vs. external)보다 동적 메모리 제어—메모리의 스케줄링, 업데이트, 재사용 방식—에 주목하며, 이는 추론 과정에서 의사결정을 지원하는 데 직접적인 영향을 미친다고 강조한다. 이후 하위 섹션에서는 각 범주에 속하는 대표적 기법을 소개하며, 이들이 장기적 추론의 정확성(reasoning fidelity)과 효과성(effectiveness)에 미치는 영향을 분석한다.
Memory is essential for enabling agents to reason, adapt, and operate effectively over extended tasks. However, AI agents frequently face limitations arising from constrained context windows and forgetting, which can result in phenomena such as context drift and hallucination (Liu et al., 2024b; Zhang et al., 2024c,d). These limitations have driven increasing interest in memory optimisation to enable generalisable and consistent behaviours in dynamic environments. In this survey, we focus on inference-time memory strategies that enhance memory utilisation without modifying model parameters. In contrast to training-time techniques such as fine-tuning or knowledge editing (Cao et al., 2021; Mitchell et al., 2022), inference-time approaches dynamically decide what to retain, retrieve, and discard during the reasoning process.
We categorise existing methods into two optimisation objectives: short-term memory, which focuses on maintaining coherence within the active context, and long-term memory, which supports persistent retrieval across sessions. This optimisation-oriented perspective shifts the focus from static memory formats (e.g., internal vs. external) to dynamic memory control, with an emphasis on how memory is scheduled, updated, and reused to support decision-making. In the following subsections, we present representative methods within each category, emphasising their impact on reasoning fidelity and effectiveness in long-horizon settings.
4.3.1 Short-term Memory Optimisation
Summary
이 섹션에서는 단기 메모리 최적화(Short-term Memory Optimisation)의 핵심 기법과 구현 사례를 다룬다. LLM의 작업 메모리 내 제한된 맥락 정보를 효과적으로 관리하기 위해 요약, 선택적 보존, 희소한 주의(sparse attention), 동적 맥락 필터링 등 다양한 전략이 제안되었으며, 예를 들어 Wang et al. [2025d]는 순환 요약(recursive summarisation)을 통해 긴 상호작용에서도 일관된 응답을 가능하게 하고, MemoChat [Lu et al. 2023]은 대화 기록 기반의 대화 수준 메모리(dialogue-level memory)를 유지해 일관성 있는 대화를 지원한다. 또한, COMEDY [Chen et al. 2025f]와 ReadAgent [Lee et al. 2024d]는 추출된 메모리 추적을 생성 과정에 통합해 긴 문서나 대화에서 맥락을 유지하는 방식을 탐구한다. 이 외에도 MoT [Li and Qiu 2023]와 StructRAG [Li et al. 2025i]는 중간 상태 추적을 검색해 다단계 추론을 지원하며, MemoryBank [Zhong et al. 2024]는 이bbinghaus 망각 곡선을 기반으로 사건을 계층적으로 요약하고 최신성과 관련성에 따라 메모리를 업데이트하는 방법을 제시한다. 마지막으로, Reflexion [Shinn et al. 2023]은 에이전트가 작업 피드백을 반영해 회상적 통찰(episodic insights)을 저장함으로써 시간에 따른 자기 개선을 도모한다. 그러나 이러한 단기 메모리 기법은 세션 간 지식 유지나 장기적 일반화에는 한계가 있어, 장기 메모리 메커니즘과의 결합이 필수적임을 강조한다.
Short-term memory optimisation focuses on managing limited contextual information within the LLM’s working memory (Liu et al., 2024b). This typically includes recent dialogue turns, intermediate reasoning traces, and task-relevant content from the immediate context. As the context expands, memory demands increase significantly, making it impractical to retain all information within a fixed context window. To address this, various techniques have been proposed to compress, summarise, or selectively retain key information (Zhang
et al., 2024d; Wang et al., 2025d). Common strategies encompass summarisation, selective retention, sparse attention, and dynamic context filtering. For example, Wang et al. (2025d) proposes recursive summarisation to incrementally construct compact and comprehensive memory representations, enabling consistent responses throughout extended interactions. MemoChat (Lu et al., 2023) maintains dialogue-level memory derived from conversation history to support coherent and personalised interaction. COMEDY (Chen et al., 2025f) and ReadAgent (Lee et al., 2024d) further incorporate extracted or compressed memory traces into the generation process, allowing agents to maintain context over long conversations or documents. In addition to summarisation, other methods dynamically adjust the context or retrieve intermediate state traces to facilitate multi-hop reasoning. For example, MoT (Li and Qiu, 2023) and StructRAG (Li et al., 2025i) retrieve self-generated or structured memory to guide intermediate steps. MemoryBank (Zhong et al., 2024), inspired by the Ebbinghaus forgetting curve (Murre and Dros, 2015), hierarchically summarises events and updates memory based on recency and relevance. Reflexion (Shinn et al., 2023) enables agents to reflect on task feedback and store episodic insights, promoting self-improvement over time.
These methods significantly improve local coherence and context efficiency. However, short-term memory alone is insufficient for retaining knowledge across sessions or enabling generalisation over long horizons, highlighting the need for complementary long-term memory mechanisms.
4.3.2 Long-term Memory Optimisation
Summary
이 섹션에서는 장기 메모리 최적화(Long-term Memory Optimisation)가 언어 모델의 짧은 컨텍스트 윈도우 한계를 극복하기 위해 지속적이고 확장 가능한 저장소를 제공함으로써, 세션 간 사실 정보, 작업 이력, 사용자 선호도, 상호작용 경로 등을 유지하고 검색할 수 있게 함을 설명한다. 핵심 목표는 복잡해지는 메모리 공간을 관리하면서도 메모리 저장소와 추론 과정의 분리를 유지하는 것으로, 구조화된 데이터베이스나 지식 그래프와 같은 형식으로 외부 메모리를 조직화하는 방식이 제시된다. 검색 기반 생성(Retrieval-Augmented Generation, RAG)은 외부 메모리를 추출해 추론에 통합하는 대표적 패러다임으로, EWE(명시적 작업 메모리 활용)와 A-MEM(동적 지식 네트워크 생성) 등이 예시로 제시된다. 또한 메모리 제어 메커니즘은 추론 시점에서 메모리의 저장, 업데이트, 폐기 시점을 결정하며, MATTER(다양한 메모리 소스에서 관련 정보 선택)와 AWM(온라인/오프라인 환경에서의 연속 메모리 업데이트) 등의 방법이 언급된다. 벡터 기반 메모리 시스템(MemGPT, NeuroCache)은 밀집 잠재 공간에서 빠른 접근을 가능하게 하며, 심볼릭 접근(ChatDB, neurosymbolic 프레임워크)은 정확한 추론과 메모리 추적을 지원한다. 강화 학습과 우선순위 정책을 활용한 MEM1 및 A-MEM은 메모리 동적 관리에 기여하며, MemoryBank는 과거 지식 주기적 복습을 통해 기억력 향상에 초점을 맞춘다.
Long-term memory optimisation mitigates the limitations of short context windows by providing persistent and scalable storage that extends beyond the immediate input scope of the language model. It enables agents to retain and retrieve factual knowledge, task histories, user preferences, and interaction trajectories across sessions (Du et al., 2025), thereby supporting coherent reasoning and decision-making over time. A key objective in this area is to manage increasingly complex and expanding memory spaces while preserving a clear separation between memory storage and the reasoning process (Zhang et al., 2024d). External memory can be either unstructured or organised into structured formats such as tuples, databases, or knowledge graphs (Zeng et al., 2024b), and may span a wide range of sources and modalities.
A critical paradigm of long-term memory optimisation is Retrieval-Augmented Generation (RAG), which incorporates relevant external memory into the reasoning process via retrieval (Wang et al., 2023a; Efeoglu and Paschke, 2024; Gao et al., 2025c). For instance, EWE (Chen et al., 2025d) augments a language model with an explicit working memory that dynamically holds latent representations of retrieved passages, focusing on combining static memory entries at each decoding step. In contrast, A-MEM (Xu et al., 2025) constructs interconnected knowledge networks through dynamic indexing and linking, enabling agents to form evolving memory. Another prominent direction involves agentic retrieval, where agents autonomously determine when and what to retrieve, alongside trajectory-level memory, which utilises past interactions to inform future behaviour. Supporting techniques such as efficient indexing, memory pruning, and compression further enhance scalability (Zheng et al., 2023a; Alizadeh et al., 2024). For example, Wang et al. (2024e) propose a lightweight unlearning framework based on the RAG paradigm. By altering the external knowledge base used for retrieval, the system can simulate forgetting effects without modifying the underlying LLM. Similarly, Xu et al. (2025) introduce a self-evolving memory system that maintains long-term memory without relying on predefined operations. In addition to retrieval policies and memory control mechanisms, the structure and encoding of memory itself significantly affect system performance. Vector-based memory systems encode memory in dense latent spaces and support fast, dynamic access. For instance, MemGPT (Packer et al., 2023), NeuroCache (Safaya and Yuret, 2024), G-Memory (Zhang et al., 2025e), and AWESOME (Cao and Wang, 2024) enable consolidation and reuse across tasks. Mem0 (Chhikara et al., 2025) further introduces a production-ready memory-centric architecture for continuous extraction and retrieval. Other approaches draw inspiration from biological or symbolic systems to improve interpretability. HippoRAG (Gutierrez et al., 2024) implements hippocampus-inspired indexing via lightweight knowledge graphs. GraphReader (Li et al., 2024d) and Mem0g (Chhikara et al., 2025) use graph-based structures to capture conversational dependencies and guide retrieval. In the symbolic domain, systems like ChatDB (Hu et al., 2023) issue SQL queries over structured databases, while Wang et al. (2024f) introduces a neurosymbolic framework that stores facts and rules in both natural and symbolic form, supporting precise reasoning and memory tracking.
Recent work has also emphasised the importance of memory control mechanisms during inference (Zou et al., 2024; Chen et al., 2025d), which determine what, when, and how to store, update, or discard memory (Jin et al., 2025). For instance, MATTER (Lee et al., 2024b) dynamically selects relevant segments from multiple heterogeneous memory sources to support question answering, and AWM (Wang et al., 2024l) enables continuous memory updates in both online and offline settings. MyAgent (Hou et al., 2024) endows agents with memory-aware recall mechanisms for generation, addressing the temporal cognition limitations of LLMs. MemoryBank (Zhong et al., 2024) proposes a cognitively inspired update strategy, where periodic revisiting of past knowledge mitigates forgetting and enhances long-term retention. Reinforcement learning and prioritisation policies have also been employed to guide memory dynamics (Zhou et al., 2025b; Yan et al., 2025; Long et al., 2025). For example, MEM1 (Zhou et al., 2025c) leverages reinforcement learning to maintain an evolving internal memory state, selectively consolidating new information while discarding irrelevant content. A-MEM (Xu et al., 2025) presents an agentic memory architecture that autonomously organises, updates, and prunes memory based on usage. MrSteve (Park et al., 2024) incorporates episodic “what-where-when” memory to hierarchically structure long-term knowledge, enabling goal-directed planning and task execution. These approaches allow agents to proactively manage memory and complement short-term mechanisms. Meanwhile, MIRIX (Wang and Chen, 2025) introduces an agent memory system with six specialised memory types in collaborative settings, enabling coordinated retrieval and achieving state-of-the-art performance in long-horizon tasks, while Agent KB (Tang et al., 2025b) leverages a shared knowledge base with a teacher-student dual-phase retrieval mechanism to transfer cross-domain problem-solving strategies and execution lessons across agents, significantly enhancing performance through hierarchical strategic guidance and refinement.
4.4 Tool Optimisation
Summary
이 섹션에서는 도구 최적화(Tool Optimisation)가 에이전트 시스템(agent system)에서 외부 정보, 데이터베이스, API 등과 상호작용하여 복잡한 문제 해결 능력을 향상시키는 핵심 요소임을 강조한다. 도구 사용(tool use)은 AI 에이전트의 핵심 역량으로, 외부 지식과 다단계 추론이 필요한 작업에서 특히 중요하지만, 단순히 도구를 제공하는 것만으로는 충분하지 않으며, 적절한 시점과 방식으로 도구를 호출, 도구 출력 해석, 다단계 추론에 통합하는 능력이 필요하다는 점을 지적한다. 최근 연구는 도구 최적화를 통해 에이전트의 도구 사용 효율성과 지능성을 향상시키는 방향으로 발전 중이며, 기존 연구는 두 가지 주요 접근 방식으로 나뉜다. 첫째, 에이전트의 도구 상호작용 능력 강화를 위한 훈련 전략, 프롬프팅 기술, 추론 알고리즘의 개발이며, 둘째, 도구 자체의 최적화를 위한 기존 도구 개선 또는 새로운 도구 설계로, 목표 작업의 기능적 요구사항과 더 잘 맞출 수 있도록 하는 방향이다.
Tools are critical components within agent systems, serving as interfaces that allow agents to perceive and interact with the real world. They enable access to external information sources, structured databases, computational resources, and APIs, thereby enhancing the agent’s ability to solve complex, real-world problems (Patil et al., 2024; Yang et al., 2023; Guo et al., 2024d). As a result, tool use has become a core competence of AI agents, especially for tasks that require external knowledge and multi-step reasoning. However, simply exposing agents to tools is not sufficient. Effective tool use requires the agent to recognise when and how to invoke the right tools, interpret tool outputs, and integrate them into multi-step reasoning. Consequently, recent research has focused on tool optimisation, which aims to enhance the agent’s ability to use tools intelligently and efficiently.
Existing research on tool optimisation largely falls into two complementary directions. The first, which has been more extensively explored, focuses on enhancing the agent’s ability to interact with tools. This is achieved through different approaches, including training strategies, prompting techniques, and reasoning algorithms, that aim to improve the agent’s ability to understand, select, and execute tools effectively. The second, which is more recent and still emerging, focuses on optimising the tools themselves by modifying existing tools or creating new ones that better align with the functional requirements of the target tasks.
4.4.1 Training-Based Tool Optimisation
Summary
이 섹션에서는 도구 최적화(Tool Optimisation)를 위해 학습 기반(Training-Based) 접근 방식을 탐구하며, 대규모 언어 모델(LLM)이 도구 사용을 이해하지 못하는 한계를 극복하기 위해 감독 학습 양자화(Supervised Fine-Tuning, SFT)와 강화 학습(Reinforcement Learning, RL) 기반 기법을 제안한다. SFT 기반 방법은 고질적인 도구 사용 추적 데이터(예: 입력 질문, 중간 추론, 도구 호출, 최종 답변)를 기반으로 LLM을 학습시켜 도구 호출과 결과 통합 능력을 내재화하는 방식으로, ToolLLM, GPT4Tools, TOOLEVO 등이 대표적이다. 특히, 복잡한 다단계 상호작용 환경에서는 Magnet과 BUTTON과 같은 연구가 다중 턴 도구 호출(Multi-Turn Tool Calling) 데이터 생성을 위해 그래프 기반 합성 및 다중 에이전트 시뮬레이션을 활용한다. 반면, 강화 학습 기반 접근(예: ReTool, Tool-Star)은 인간-에이전트 상호작용을 시뮬레이션해 도구 사용 전략을 자율적으로 학습하게 하여, 새로운 도구나 작업 구성에 대한 일반화 능력을 향상시킨다. 또한, Confucius는 쉬움에서 어려움으로의 커리큘럼 학습(Easy-to-Difficult Curriculum Learning)을 도입해 점진적인 도구 사용 시나리오를 제공하고, Gorilla는 문서 검색 모듈을 통합해 변화하는 도구셋(Evolving Toolsets)에 적응하는 방식을 제안한다. 이러한 방법들은 LLM이 도구 사용을 보다 안정적이고 유연하게 수행하도록 하여, 복잡한 문제 해결 능력을 극대화하는 데 기여한다.
Training-based tool optimisation aims to enhance an agent’s ability to use tools by updating the underlying LLM’s parameters through learning. The motivation behind this approach stems from the fact that LLMs are pretrained purely on text generation tasks, without any exposure to tool usage or interactive execution. Therefore, they lack an inherent understanding of how to invoke external tools and interpret tool outputs. Training-based methods aim to address this limitation by explicitly teaching the LLMs how to interact with tools, thereby embedding tool-use capabilities directly into the agent’s internal policy.
Supervised Fine-Tuning for Tool Optimisation. Earlier efforts in this line of work rely on supervised fine-tuning (SFT), which trains the LLM on high-quality tool-use trajectories to explicitly demonstrate how tools should be invoked and integrated into task execution (Schick et al., 2023; Du et al., 2024; Liu et al., 2025g; Wang et al., 2025e). A central focus of these methods lies in the collection of high-quality tool-use trajectories, which typically consist of input queries, intermediate reasoning steps, tool invocations and final answers. These trajectories serve as explicit supervision signals for the agent, teaching it how to plan tool usage, execute calls, and incorporate results into its reasoning process. For example, approaches such as ToolLLM (Qin et al., 2024) and GPT4Tools (Yang et al., 2023) leverage more powerful LLMs to generate both instructions and corresponding tool-use trajectories. Inspired by the human learning process, STE (Wang et al., 2024a) introduces simulated trial-and-error interactions to collect tool-use examples, while TOOLEVO (Chen et al., 2025b) employs MCTS to enable more active exploration and collect higher-quality trajectories. T3-Agent (Gao et al., 2025d) further extends this paradigm to the multimodal setting by introducing a data synthesis pipeline that generates and verifies high-quality multimodal tool-use trajectories for tuning vision–language models.
Moreover, recent work (Yao et al., 2025) indicates that even advanced LLMs face challenges with tool use in multi-turn interactions, especially when these interactions involve complex function calls, long-term dependencies, or requesting missing information. To generate high-quality training trajectories on multi-turn tool calling, Magnet (Yin et al., 2025) proposes to synthesise a sequence of queries and executable function calls from tools, and employs a graph to build a reliable multi-turn query. BUTTON (Chen et al., 2025e) generates synthetic compositional instruction tuning data via a two-stage process, where a bottom-up stage composes atomic tasks to construct the instructions and a top-down stage employs a multi-agent system to simulate the user, assistant, and tool to generate the trajectory data. To enable more realistic data generation, APIGen-MT (Prabhakar et al., 2025) proposes a two-phase framework that first generates tool call sequences and then transforms them into complete multi-turn interaction trajectories through simulated human-agent interplay.
Once the tool-use trajectories are collected, they are used to fine-tune the LLM through standard language modelling objectives, enabling the model to learn successful patterns of tool invocation and integration. In addition to this common paradigm, some studies have also explored more advanced training strategies to further enhance tool-use capabilities. For example, Confucius (Gao et al., 2024a) introduces an easy-to-difficult curriculum learning paradigm that gradually exposes the model to increasingly complex tool-use scenarios. Gorilla (Patil et al., 2024) proposes integrating a document retriever into the training pipeline, allowing the agent to dynamically adapt to evolving toolsets by grounding tool usage in retrieved documentation.
Reinforcement Learning for Tool Optimisation. While supervised fine-tuning has proven effective for teaching agents to use tools, its performance is often constrained by the quality and coverage of the training data. Low-quality trajectories can lead to diminished performance gains. Moreover, fine-tuning on limited datasets may hinder generalisation, particularly when agents encounter unseen tools or task configurations at inference time. To address these limitations, recent research has turned to reinforcement learning (RL) as an alternative optimisation paradigm for tool use. By enabling agents to learn through interaction and feedback, RL facilitates the development of more adaptive and robust tool-use strategies. This approach has shown promising results in recent work such as ReTool (Feng et al., 2025a) and Nemotron-Research-Tool-N1 (Tool-N1) (Zhang et al., 2025m), both of which demonstrate how lightweight supervision in an interactive environment can lead to more generalisable tool-use capabilities. Tool-Star (Dong et al., 2025a) enhances RL-based tool use by combining scalable tool-integrated data synthesis with a two-stage training framework to improve autonomous multi-tool collaborative reasoning. SPORT (Li et al., 2025d) extends RL-based tool optimisation to the multimodal setting through step-wise preference optimisation, enabling agents to self-synthesise tasks, explore and verify tool usage without human annotations. Building on these foundations, further studies have focused on improving RL algorithms for tool use, including ARPO (Dong et al., 2025b), which balances long-horizon reasoning and multi-turn tool interactions via an entropy-based adaptive rollout mechanism and stepwise advantage attribution, as well as methods that design more effective reward functions (Qian et al., 2025a) and leverage synthetic data generation and filtering to enhance training stability and efficiency (Goldie et al., 2025).
4.4.2 Inference-Time Tool Optimisation
Summary
이 섹션에서는 추론 시점에서 LLM 파라미터 수정 없이 도구 사용 능력(tool-use capability)을 향상시키는 두 가지 주요 접근 방식인 프롬프트 기반(prompt-based) 및 추론 기반(reasoning-based) 방법을 설명한다. 프롬프트 기반 도구 최적화에서는 도구 문서나 지침의 표현 방식을 개선해 LLM이 외부 도구를 더 효과적으로 이해하고 활용하도록 유도하는 방식을 탐구하며, EASYTOOL은 다양한 도구 문서를 통일된 간결한 지침으로 변환하고, DRAFT 및 PLAY2PROMPT는 인간의 시행착오 과정을 모방한 상호작용 프레임워크를 통해 문서를 반복적으로 개선하는 사례를 제시한다. 또한, Wu et al.은 도구 설명과 LLM 지침을 동시에 최적화하는 프레임워크를 제안해 계산 오버헤드 감소와 도구 사용 효율 향상을 달성했다. 반면, 추론 기반 도구 최적화는 MCTS나 트리 기반 알고리즘을 활용해 추론 시점의 계획 및 탐색 능력을 강화하는 방식으로, ToolLLM은 ReAct 프레임워크와 깊이 우선 탐색 알고리즘을 결합해 효율성을 높였고, ToolChain은 비용 함수를 통해 저효율 경로를 사전에 제거하는 트리 탐색을 도입했다. Tool-Planner는 유사한 기능을 가진 도구를 툴킷으로 클러스터링하고, MCP-Zero는 LLM이 자율적으로 능력 부족을 인식해 필요한 도구를 요청하는 능동적 프레임워크를 제안해 도구 선택의 유연성을 높였다.
In addition to training-based approaches, another line of work focuses on enhancing tool-use capabilities during inference, without modifying LLM parameters. These methods typically operate by optimising tool-related contextual information within prompts or guiding the agent’s decision-making process through structured reasoning at test time. There are two major directions within this paradigm: (1) prompt-based methods, which refine the representation of tool documentation or instructions to facilitate better understanding and utilisation of tools; (2) reasoning-based methods, which leverage test-time reasoning strategies, such as MCTS and other tree-based algorithms to enable more effective exploration and selection of tools during inference.
Prompt-Based Tool Optimisation. Tool-related information is typically provided to agents through tool documentation within prompts. These documents describe tool functionalities, potential usage, and invocation formats, helping the agent understand how to interact with external tools to solve complex tasks. Therefore, tool documentation within prompts serves as a crucial bridge between the agent and its available tools, directly influencing the quality of tool-use decisions. Recent efforts have focused on optimising how this documentation is presented, either by restructuring source documents or refining them through interactive feedback (Qu et al., 2025). For instance, EASYTOOL (Yuan et al., 2025b) transforms different tool documentation into unified, concise instructions, making them easier for LLMs to use. In contrast, approaches such as DRAFT (Qu et al., 2025) and PLAY2PROMPT (Fang et al., 2025) draw inspiration from human trial-and-error processes, introducing interactive frameworks that iteratively refine tool documentation based on feedback.
Beyond these methods, a more recent direction explores the joint optimisation of both tool documentation and the instructions provided to the LLM agent. For example, Wu et al. (2025a) propose an optimisation framework that simultaneously refines the agent’s prompt instructions and the tool descriptions, collectively referred to as the context, to enhance their interaction. The optimised context has been shown to reduce computational overhead and improve tool-use efficiency, highlighting the importance of context design in effective inference-time tool optimisation.
Reasoning-Based Tool Optimisation. Test-time reasoning and planning techniques have demonstrated strong potential for improving tool-use capabilities in AI agents. Early work such as ToolLLM (Qin et al., 2024) has validated the effectiveness of the ReAct (Yao et al., 2023b) framework in tool-use scenarios, and further proposed a depth-first tree search algorithm that enables agents to quickly backtrack to the last successful state rather than restarting from scratch, which significantly improves efficiency. ToolChain (Zhuang et al., 2024) introduces a more efficient tree-based search algorithm by employing a cost function to estimate the future cost of a given branch. This allows agents to prune low-value paths early and avoid the inefficient rollouts commonly associated with traditional MCTS. Similarly, Tool-Planner (Liu et al., 2025h) clusters tools with similar functionalities into toolkits and leverages a tree-based planning method to quickly reselect and adjust tools from these toolkits. MCP-Zero (Fei et al., 2025) introduces an active agent framework that empowers LLMs to autonomously identify capability gaps and request tools on demand.
4.4.3 Tool Functionality Optimisation
Summary
이 섹션에서는 에이전트의 행동 최적화에 더해 도구 자체의 기능 개선을 위한 연구 방향을 소개한다. 기존 접근법이 고정된 도구세트에 맞춰 작업을 조정하는 반면, 이 연구는 작업에 맞춘 도구세트 적응(task-adapted toolset)을 통해 에이전트의 행동 공간을 확장하는 방식을 제안한다. 예를 들어, CREATOR와 LATM은 새로운 작업에 맞춘 도구 문서 및 실행 가능한 코드 생성 프레임워크를 도입했으며, CRAFT는 이전 작업에서의 재사용 가능한 코드 조각을 활용해 새로운 도구를 생성한다. AgentOptimiser는 도구와 함수를 학습 가능한 가중치로 간주해 LLM 기반 업데이트로 반복적으로 개선하는 반면, Alita는 다중 구성 요소 프로그램(MCP) 형식을 도입해 재사용성과 환경 관리 능력을 강화했다. 또한, CLOVA는 인간 피드백을 기반으로 추론, 성찰, 학습 단계를 포함한 폐루프 시각 보조 프레임워크를 통해 시각 도구의 지속적 적응을 가능하게 한다. 이러한 접근법들은 에이전트가 복잡한 작업에 대응하는 데 필요한 도구의 유연성과 확장성을 극대화하는 데 기여한다.
Beyond optimising the agent’s behaviour, a complementary line of work focuses on modifying or generating tools themselves to better support task-specific reasoning and execution. Inspired by the human practice of continuously developing tools to meet task requirements, these approaches aim to extend the agent’s action space by adapting the toolset to the task, rather than adapting the task to a fixed toolset (Wang et al., 2024k). For instance, CREATOR (Qian et al., 2023) and LATM (Cai et al., 2024) introduce frameworks that generate tool documentation and executable code for novel tasks. CRAFT (Yuan et al., 2024a) leverages reusable code snippets from prior tasks to create new tools for unseen scenarios. AgentOptimiser (Zhang et al., 2024b) treats tools and functions as learnable weights, allowing the agent to iteratively refine them using LLM-based updates. A more recent work, Alita (Qiu et al., 2025), extends tool creation into a Multi-Component Program (MCP) format, which enhances reusability and environment management. Moreover, CLOVA (Gao et al., 2024b) introduces a closed-loop visual assistant framework with inference, reflection, and learning phases, enabling continual adaptation of visual tools based on human feedback.
5 Multi-Agent Optimisation
Summary
이 섹션에서는 다중 에이전트 최적화(Multi-Agent Optimisation)의 핵심 개념과 접근 방식을 설명하며, 기존 수작업 설계 기반의 에이전트 아키텍처에서 자기 진화형 시스템(self-evolving systems)으로의 패러다임 전환을 강조한다. 이 과정에서 작업 흐름 설계(workflow design)는 구조적 공간(structural space), 의미적 공간(semantic space), 능력 공간(capability space)이라는 세 가지 상호 연결된 영역에서의 탐색 문제로 재구성되었다. 최근 연구는 진화 알고리즘(evolutionary algorithms)과 강화 학습(reinforcement learning) 등 다양한 최적화 기법을 활용해 정확도, 효율성, 안전성 등 다중 목표를 균형 있게 달성하는 방법을 탐구하고 있다. 특히, 프롬프트 수준 최적화(prompt-level optimisation), 구조 최적화(topology optimisation), 통합적 최적화(unified optimisation), LLM 백본 최적화(LLM-backbone optimisation)의 네 가지 주요 차원을 통해 다중 에이전트 시스템의 파라미터 공간을 확장하고 있다. 프롬프트 수준 최적화는 고정된 아키텍처 내 에이전트 행동을 개선하는 반면, 구조 최적화는 특정 작업에 적합한 최적의 에이전트 구성 방식을 탐색한다. 또한, 통합적 최적화는 프롬프트, 구조, 시스템 파라미터를 동시에 최적화하는 접근 방식을 제시하고, LLM 백본 최적화는 에이전트의 핵심 추론 및 협업 능력을 강화하기 위한 학습 기반 접근을 포함한다. 이 과정을 통해 다중 에이전트 시스템에서 최적화 가능한 요소의 범위가 에이전트 지시사항과 커뮤니케이션 구조에서 LLM의 핵심 역량(core competencies)까지 확장되고 있다. 그림 [6]은 다중 에이전트 작업 흐름 최적화의 핵심 요소와 주요 차원(프롬프트, 구조, 통합, LLM 백본)을 요약적으로 보여준다.
The multi-agent workflow defines how multiple agents collaborate to solve complex tasks through structured topologies and interaction patterns. The field has witnessed a fundamental shift: from manually designed agent architectures, where researchers explicitly specify collaboration patterns and communication protocols, to self-evolving systems that automatically discover effective collaboration strategies. This evolution reframes workflow design as a search problem over three interconnected spaces: the structural space of possible agent topologies, the semantic space of agent roles and instructions, and the capability space of LLM backbones. Recent approaches explore these spaces using a range of optimisation techniques, from evolutionary algorithms to reinforcement learning, each offering different trade-offs in balancing multiple optimisation targets (e.g., accuracy, efficiency, and safety).
This section traces the progression of multi-agent workflow optimisation across four key dimensions. Our starting point examines manually designed paradigms that establish foundational principles. From there, we consider prompt-level optimisation, which refines agent behaviours within fixed topologies. We subsequently address topology optimisation, which focuses on discovering the most effective architectures for multiple agents to accomplish a given task. We also discuss comprehensive approaches that simultaneously consider multiple optimisation spaces, jointly optimising prompts, topologies, and other system parameters in an integrated manner. Additionally, we investigate LLM-backbone optimisation, which enhances the fundamental reasoning and collaborative capabilities of the agents themselves through targeted training. Through this lens, we show how the field progressively expands its conception of what constitutes a searchable and optimisable parameter in multi-agent systems, from agent instructions and communication structures to the core competencies of the underlying models. Figure 6 provides an overview of multi-agent workflow optimisation across its core elements and key dimensions.
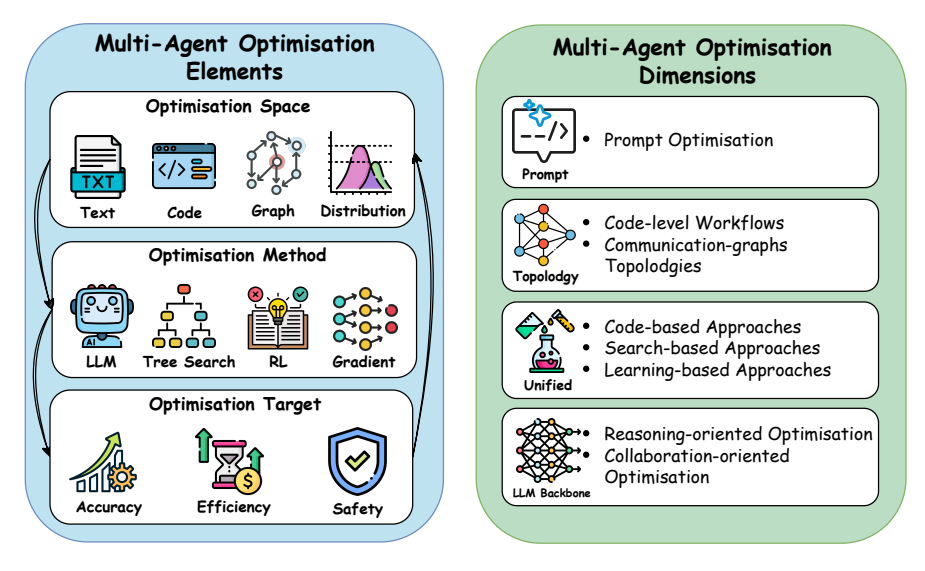
Figure 6 An overview of multi-agent systems optimisation approaches, with core optimisation elements (space, methods, and targets) on the left and optimisation dimensions (prompt, topology, unified, and LLM backbone) on the right.
5.1 Manually Designed Multi-Agent Systems
Summary
이 섹션에서는 수작업 설계된 다중 에이전트 시스템(Manually Designed Multi-Agent Systems)의 주요 구조와 한계를 분석한다. 먼저, 병렬 워크플로우(Parallel Workflows)는 여러 에이전트가 독립적으로 작업을 수행한 후 다수결로 최종 결과를 결정하는 방식으로, 소규모 LLM의 경우 단일 대규모 LLM과 유사하거나 더 높은 성능을 보일 수 있음을 실증적으로 밝혔다. 그러나 이러한 구조는 좌우 간의 협업 및 일관성 관리 비용이 지수적으로 증가하는 문제가 있다. 다음으로, 계층적 워크플로우(Hierarchical Workflows)는 엄격한 맥락 의존성을 가진 하위 작업에 적합하지만, 고정된 구조로 인해 동적 목표나 자원 제약 상황에서 유연성이 부족하다는 한계를 지적한다. 또한, 다중 에이전트 토론(Multi-Agent Debate) 패러다임은 에이전트 간 대립-협상-중재 순환을 통해 추론 오류를 수정하는 방식으로, 신뢰도 기반 토론 전략은 단일 모델의 낮은 신뢰도 시점에만 토론을 유발해 추론 비용을 줄이는 효과를 보였다. 그러나 이러한 수작업 설계 워크플로우는 구현 및 유지보수 비용이 높고, 최근 연구에서는 단일 대규모 언어 모델(single large LLM)과 잘 설계된 프롬프트가 다중 에이전트 토론 프레임워크와 유사한 성능을 보일 수 있음을 밝히며, 이에 따라 자기 진화형 다중 에이전트 시스템(self-evolving multi-agent systems)의 필요성이 제기된다.
Manually designed workflows form the foundation of multi-agent collaboration research. These architectures encode researchers’ insights about task decomposition, agent capabilities, and coordination mechanisms into explicit interaction patterns. By examining these handcrafted paradigms, we can understand the design principles that guide agent collaboration and the engineering considerations that shape system architecture.
Parallel Workflows. Parallel workflows employ concurrent execution followed by collective decision-making. The simplest form involves multiple independent agents generating solutions in parallel, followed by majority voting to select the final output. Empirical evidence shows that parallel generation with small LLMs can match or even outperform single large LLMs (Verga et al., 2024; Wang et al., 2025a). Multi-layer aggregation further reduces error bounds and improves robustness (Zhang et al., 2025d). Recent extensions incorporate dynamic task graphs and asynchronous threads to enable near-linear scaling and lower decision latency (Yu et al., 2025; Gu et al., 2025; Wang et al., 2025c). However, while computational throughput scales horizontally, the engineering costs of managing coordination and consistency grow exponentially.
Hierarchical Workflows. When subtasks exhibit strict contextual dependencies, hierarchical (Zhang et al., 2024c; Qian et al., 2024) workflows offer a structured alternative. These frameworks organise agents into multi-level top-down structures or sequential pipelines. The system decomposes tasks across layers, with each layer responsible for different subtasks. This design excels in complex goal-driven tasks such as deep research and code generation (Hong et al., 2024; Zhang et al., 2025n). However, its fixed topology limits adaptability, especially when facing dynamic goals or resource constraints.
Multi-Agent Debate. To balance accuracy with interpretability, researchers have developed the debate paradigm, where agents engage in adversarial-negotiation-arbitration cycles to discuss and correct reasoning errors. Early
work explored symmetric debater mechanisms (Li et al., 2024g). More recent studies extend this framework by introducing role asymmetry, adjustable debate intensity, and persuasiveness-oriented strategies (Yin et al., 2023; Liang et al., 2024; Khan et al., 2024; Chang, 2024). In addition, confidence-gated debate strategies demonstrate that triggering multi-agent debates only when a single model exhibits low confidence can sharply reduce inference costs without hindering performance (Eo et al., 2025).
Despite the success of manually designed workflows and structured multi-agent paradigms, recent empirical studies reveal that single large LLMs with well-crafted prompts can match the performance of complex multiagent discussion frameworks on multiple reasoning benchmarks (Pan et al., 2025a). This finding, coupled with the high implementation and maintenance costs of handcrafted multi-agent workflows (Li et al., 2024h; Zhang et al., 2025j), has driven the development of self-evolving multi-agent systems that can automatically learn, adapt, and restructure their workflows over time, rather than relying on fixed architectures and static coordination protocols.
5.2 Self-Evolving Multi-Agent System
Summary
이 섹션에서는 수작업으로 설계된 다중 에이전트 워크플로우의 고비용과 제한된 적응성을 극복하기 위해 자기 진화형 다중 에이전트 시스템(Self-Evolving Multi-Agent System)의 필요성을 강조한다. 이 시스템은 성능 피드백을 기반으로 프롬프트, 구조, 협업 전략을 자동으로 설계, 평가, 최적화하며, 하드코딩된 구성 요소 대신 워크플로우 최적화를 탐색 문제(search problem)로 접근한다. 탐색 공간은 로컬 프롬프트부터 글로벌 구조에 이르기까지 다양한 수준의 구성 요소를 포함하며, 이에 대응해 강화 학습(Reinforcement Learning), 몬테카를로 트리 탐색(Monte Carlo Tree Search), 생성 모델, 진화 연산자 등 다양한 탐색 알고리즘이 도입된다. 또한 최적화 목표는 단순한 성능 향상에서 작업 정확도, 계산 효율성, 안전성 등 다차원적 요소로 확장되었으며, 이로 인해 동적 환경에서 최적성의 정의가 핵심 과제로 부상한다. 이는 탐색 기능의 발전과 함께 해결책의 존재 여부보다 최적성 기준의 명확화가 더 큰 도전 과제로 자리매김함을 보여준다.
The high engineering costs and limited adaptability of manually designed multi-agent workflows have motivated a shift towards automated, self-evolving systems. These systems can automatically design, evaluate, and refine agent workflows by adapting their prompts, topologies, and collaborative strategies based on performance feedback. Instead of relying on hard-coded configurations, they treat workflow optimisation as a search problem, where the system explores and optimises over a space of possible configurations. The search space spans multiple levels, from local prompts to global topology structures.
To effectively navigate the search space, various search algorithms have been introduced. These methods range from reinforcement learning, Monte Carlo Tree Search, and generative models that enable efficient exploration, to evolutionary operators that provide robust search capabilities. Moreover, the optimisation objectives have expanded from improving performance to balancing multi-dimensional goals, including task accuracy, computational efficiency, and safety. This evolution reveals that as search capabilities advance, the core challenge shifts from finding optimal solutions to defining what optimality means in dynamic multi-agent contexts.
5.2.1 Multi-Agent Prompt Optimisation
Summary
이 섹션에서는 다중 에이전트 프롬프트 최적화(Multi-Agent Prompt Optimisation)를 통해 자기 진화형 시스템의 구현 가능성을 탐구한다. 프롬프트는 에이전트의 역할과 작업 지침을 정의하는 핵심 요소로, 이를 기반으로 한 구성이 형식화된 탐색 공간(formal search space)으로 간주되어 체계적인 개선이 가능하다. 기존 단일 에이전트 기법(Section 4.2)을 확장해 다중 에이전트 간 협업과 작업 의존성을 고려한 최적화를 수행하며, 예를 들어 DSPy는 실행 중 발생하는 제약 조건 위반을 감지해 명시적 피드백을 기반으로 단계적 역추적(assertion-driven backtracking)을 통해 시스템을 자동 수정하는 런타임 자기 진화(runtime self-evolution)를 제안한다. 또한 AutoAgents는 메타에이전트(meta-agents) 간의 구조화된 대화를 통해 전체 다중 에이전트 팀 구성(entire multi-agent team configurations)의 전문성 역할(specialised agent roles)과 실행 계획(execution plans)을 최적화하는 방식을 도입한다. 이러한 접근은 수작업 설계의 한계를 극복하고, 동적 환경 변화에 따른 자동 적응성을 높이는 데 기여한다.
One promising direction for achieving such self-evolution is through prompt optimisation, where prompts define both agent roles and their corresponding task instructions. Recent approaches treat these prompt-encoded configurations as a formal search space for systematic refinement. In fact, prompt optimisation in multi-agent workflows often builds upon the single-agent techniques discussed in Section 4.2, but extends them to coordinate multiple agents and task dependencies. For example, DSPy (Singhvi et al., 2023) Assertions introduces runtime self-evolution, where the search space encompasses possible intermediate outputs from pipeline modules, using assertion-driven backtracking with explicit feedback to guide LLMs in self-correcting outputs that violate programmatic constraints. AutoAgents (Chen et al., 2024b) extends prompt optimisation from single-agent settings to entire multi-agent team configurations, optimising specialised agent roles and execution plans through structured dialogue between dedicated meta-agents.
5.2.2 Topology Optimisation
Summary
이 섹션에서는 다중 에이전트 시스템(MAS) 설계의 패러다임 전환인 위상 최적화(Topology Optimisation)를 소개하며, 기존의 고정된 커뮤니케이션 구조 대신 위상 자체를 최적화 대상으로 삼는 새로운 접근법을 제시한다. 이는 프롬프트의 질이 부족한 경우에도 구조적 선택이 시스템 성능에 결정적 영향을 미친다는 관찰에서 비롯된 것으로, 코드 수준 워크플로우(Code-level Workflow)와 커뮤니케이션 그래프 위상(Communication-Graph Topology)의 두 주요 분류로 구분된다. 코드 수준 워크플로우에서는 AutoFlow, AFlow, ScoreFlow, MAS-GPT 등이 자연어 프로그램(CoRE), 유형화된 코드 그래프, 연속 공간 최적화, 감독 학습 기반 생성 등의 방식으로 워크플로우를 자동화하고, 커뮤니케이션 그래프 위상에서는 GPTSwarm, DynaSwarm, G-Designer, MermaidFlow 등이 확률적 엣지 선택, 변분 그래프 오토인코더, 안전 제약 진화 연산자 등을 활용해 동적 환경에 적응하는 그래프 구조를 탐색한다. 또한, 동적 조절(DyLAN, Captain Agent, Flow)과 프루닝 기법(AgentPrune, AGP, G-Safeguard)을 통해 성능 향상, 자원 효율성, 보안 강화를 동시에 목표로 하는 접근법들이 제시되며, 이는 기존 수작업 설계의 한계를 극복하고 자체적으로 최적화하는 자기 진화형 시스템(Self-Evolving System)으로의 이동을 촉진한다.
Topology optimisation represents a paradigm shift in multi-agent system design: rather than treating communication structure as a fixed constraint, it recognises topology itself as a powerful optimisation target. This insight emerged from a fundamental observation—even the best prompts cannot compensate for poor architectural choices. Viewed through a representation-centred lens, existing work clusters into two complementary families: program/code-level workflow topologies and communication-graph topologies; this classification foregrounds what is being optimised—the chosen representation of topology. This marks not just technical progress but a conceptual shift—the medium (topology) matters as much as the message (prompts).
Code-level workflows. Representing workflows as executable programs or typed code graphs makes agent coordination explicit and verifiable, enabling compositional reuse and automated checking. AutoFlow (Li et al., 2024h) sets the search space to natural-language programs (CoRE) and trains a generator LLM with reinforcement
learning, supporting both fine-tuning and in-context use. Compared with AutoFlow, AFlow (Zhang et al., 2025j) replaces the NL program space with typed, reusable operators to form code graphs; Monte Carlo Tree Search with LLM-guided expansion and soft probabilistic selection provides a more structured, sample-efficient exploration of the vast design space than RL over CoRE. Pushing beyond these discrete search schemes, ScoreFlow (Wang et al., 2025j) lifts code representations into a continuous space and applies gradient-based optimisation with Score-DPO (a direct preference optimisation variant incorporating quantitative feedback) to improve the workflow generator. This addresses the exploration inefficiency inherent to RL/MCTS and enables task-level adaptive workflow generation. Orthogonal to search-based optimisation, MAS-GPT (Ye et al., 2025) uses supervised fine-tuning on a consistency-oriented corpus (inter- and intra-consistency) so that a single inference aims to produce a complete, executable MAS codebase, trading broad search coverage for one-shot efficiency and stronger dependence on data quality.
Communication-graph topologies. Unlike code-level programs, this line treats the workflow as a multi-agent communication graph whose connections are the optimisation target (Liu et al., 2025i). GPTSwarm (Zhuge et al., 2024a) defines its search space as connections within a computational graph of agents. It relaxes this discrete space into continuous edge probabilities, also employing RL to learn optimal connection schemes. Building on GPTSwarm, DynaSwarm (Leong and Wu, 2025) extends the search space from a single optimised graph to a portfolio of graph structures with Actor–Critic (A2C) optimisation and a lightweight graph selector for per-instance topology selection, addressing the key observation that different queries require different graph structures for optimal performance. Rather than masking edges in a fixed space, G-Designer (Zhang et al., 2024a) employs a variational graph autoencoder to directly generate task-adaptive communication graphs, modulating structural complexity to balance quality and token cost. MermaidFlow (Zheng et al., 2025) represents topology as a typed, declarative graph with static verification and explores only semantically valid regions via safety-constrained evolutionary operators.
Beyond static graph synthesis, some approaches dynamically modulate the communication graph during execution. DyLAN (Liu et al., 2023b) treats the search space as active agents across layers with an earlystopping time axis; it prunes low-value agents via an LLM ranker and performs automated team optimisation with an Agent Importance Score using propagation–aggregation–selection. Captain Agent (Song et al., 2024) defines the search space as subtask-specific sets of agents and tools (retrieved, filtered, and, when needed, generated); nested group conversations and reflection iteratively refine team composition in situ rather than synthesising a fixed graph from scratch. Flow (Niu et al., 2025) contrasts with DyLAN’s pruning and Captain Agent’s team recomposition by dynamically adjusting the AOV graph structure: it selects an initial graph via parallelism/dependency metrics and then refines it online through workflow refinement and subtask reassignment, achieving modular concurrency with minimal coordination cost.
Orthogonal to graph synthesis, pruning methods optimise by removing redundant or risky communications while preserving essential collaboration. AgentPrune (Zhang et al., 2025g) treats the search space as a spatialtemporal communication graph where both intra-dialogue (spatial) and inter-dialogue (temporal) edges are pruning targets; it employs a trainable low-rank-guided graph mask to identify and eliminate redundant communications via one-shot pruning, optimizing for token economy. Building on this pruning paradigm, AGP (Adaptive Graph Pruning) (Li et al., 2025a) extends the search space to include both agent quantity (hard pruning) and communication edges (soft pruning). It employs a two-stage training strategy that jointly optimises these dimensions on a per-task basis, dynamically determining the optimal number of agents and their connections for task-specific topology generation. While the above methods prune for efficiency and adaptability, G-Safeguard (Wang et al., 2025f) applies pruning for security—it operates on communication edges as the search space, using a GNN to flag risky nodes and deterministic rules to cut outward edges under a model-driven threshold for defence against adversarial attacks. Relatedly, NetSafe (Yu et al., 2024a) summarises topological safety risks and proposes graph-based detection and intervention principles as a complementary safety lens.
5.2.3 Unified Optimisation
Summary
이 섹션에서는 프롬프트(prompt)와 구조(topology)가 에이전트 시스템의 설계에서 서로 밀접하게 연관되어 있으며, 이를 통합적으로 최적화하는 유니파이드 최적화(Unified Optimisation)의 필요성을 강조한다. 이는 ADAS와 FlowReasoner가 코드 기반 접근법으로 프롬프트와 워크플로우를 Python 코드로 표현해 에이전트 생성과 평가를 반복적으로 수행하는 방식을 소개하며, EvoAgent와 EvoFlow가 진화 알고리즘을 활용해 프롬프트 설정 및 워크플로우 그래프를 탐색하는 서치 기반 접근법을 제시한다. 또한 MASS는 로컬 프롬프트 최적화, 워크플로우 구조 탐색, 글로벌 최적화를 순차적으로 수행하는 조건부 연계 프레임워크를, DebFlow는 실행 실패에 대한 반성 기반의 다중 에이전트 토론(multi-agent debate)을 도입해 탐색 공간을 줄이는 방식을 제안한다. 마지막으로, MaAS는 다중 에이전트 초망(agentic supernets)이라는 확률 분포 개념을 통해 쿼리별 최적 아키텍처를 샘플링하고, ANN은 계층적 신경망 구조를 통해 에이전트 역할, 프롬프트, 계층 간 연결 구조를 공동으로 진화시키는 학습 기반 접근법을 탐구한다. 이러한 다양한 접근법은 효율성과 성능 간의 균형을 달성하기 위한 서로 다른 전략을 반영하며, 유니파이드 최적화의 핵심 기술 경로를 시스템적으로 정리하고 있다.
Unified optimisation emerges from a key insight: prompts and topology are not independent design choices but deeply interconnected aspects of agent systems (Zhou et al., 2025a). A well-crafted prompt cannot function effectively in a poor communication structure, while an elegant topology yields little benefit with poorly instructed agents. This interdependence has driven the field along three distinct technical paths: code-based unification, structured optimisation methods, and learning-driven architectures. Each approach tackles the joint optimisation challenge from a unique angle, revealing different trade-offs between efficiency and performance.
Code-based Approaches. The most direct approach to unified optimisation treats code as a universal representation for both prompts and topology. ADAS (Hu et al., 2025a) pioneered this approach through its Meta Agent Search framework, representing prompts, workflows, and tool use as Python code to enable iterative agent generation and evaluation. This code-centric view allows natural co-evolution, modifying agent logic inherently affects both instructional and structural aspects. FlowReasoner (Gao et al., 2025a) advanced the code-based paradigm by focusing on query-level adaptation, generating one MAS per query rather than per task. After distilling reasoning abilities from DeepSeek-R1, it employs GRPO with external execution feedback to enhance its meta-agent, optimising for performance and efficiency. Together, these methods demonstrate that code provides a flexible substrate for joint optimisation, though at different granularities of adaptation.
Search-based Approaches. Rather than relying on implicit co-evolution through code, another line of work develops explicit mechanisms for coordinating prompt and topology design. EvoAgent (Yuan et al., 2025a) defined search spaces as textual agent settings (roles, skills, prompts) and employed evolutionary algorithms with mutation, crossover, and selection operators to generate diverse agent populations. Compared with implicit code-based co-evolution, EvoAgent explicitly evolves configuration-level characteristics rather than synthesising programs. Relative to EvoAgent’s text-centric configuration search, EvoFlow (Gao et al., 2025a) likewise adopts evolutionary search but over operator-node workflow graphs. It introduces predefined composite operators (e.g. CoT, debate) and uses an operator library with tag selection to constrain mutation/crossover and narrow the search space. EvoFlow further treats LLM selection as a decision variable to balance performance and cost; diversity-aware selection preserves population variety, and a multi-objective fitness drives cost–performance Pareto optimisation.
Complementary to evolutionary searches, MASS (Zhou et al., 2025a) proposes a three-stage, conditionally coupled optimisation framework: it first locally tunes each agent’s prompts, then searches the workflow topology in a pruned space, and finally performs global prompt optimisation on the selected topology; the procedure alternates rather than fully decoupling, serving as a practical approximation to joint optimisation. Most recently, DebFlow (Su et al., 2025) represents search spaces as workflow graphs of operator nodes and employs multi-agent debate for optimisation. Guided by reflexion on execution failures, it avoids exhaustive search while pioneering debate mechanisms in automated agent design. These structured approaches trade some flexibility for more targeted optimisation strategies. Building on the operator node representation, MAS-ZERO (Ke et al., 2025) casts unified optimisation as a purely inference-time search, iteratively restructuring agent teams and task decompositions through solvability-guided refinement without any gradient updates or offline training.
Learning-based Approaches. The latest wave of research applies sophisticated learning paradigms to jointly optimise prompts and topology. MaAS (Zhang et al., 2025f) shifts from optimising single architectures to learning agentic supernets—probabilistic distributions over multi-agent systems. Its controller network samples query-specific architectures with Monte Carlo and textual gradient optimisation, achieving superior performance with dramatically reduced inference costs. ANN (Ma et al., 2025) conceptualises multi-agent collaboration as layered neural networks, where each layer forms specialised agent teams. It employs a two-phase optimisation process: forward task decomposition and backward textual gradient refinement. This approach jointly evolves agent roles, prompts, and inter-layer topologies, enabling post-training adaptation to novel tasks.
5.2.4 LLM Backbone Optimisation
Summary
이 섹션에서는 다중 에이전트 시스템(MAS)에서 LLM 백본(LLM Backbone)의 진화를 통해 에이전트의 협업 및 추론 능력을 향상시키는 방법을 체계적으로 다룬다. 추론 중심 최적화(Reasoning-oriented Optimisation)에서는 다중 에이전트 미세 조정(Multi-Agent Finetuning)과 같은 기법이 고품질 협업 추적(cooperative trajectories)을 활용해 에이전트의 역할 특화와 백본 모델의 추론 능력을 동시에 개선함을 설명한다. 예를 들어, Sirius는 자기 교정(self-correction)을 통해 오류 추적을 학습 데이터에 통합하고, MALT는 DPO(Direct Preference Optimization)를 적용해 부정 샘플을 자연스럽게 활용하는 방식을 채택한다. 또한, MaPoRL은 강화 학습(Reinforcement Learning)을 통해 에이전트 간 의사소통을 명시적으로 유도하고, MARTI는 재정비 가능한 프레임워크를 통해 에이전트 구조와 보상 함수의 유연한 설계를 지원함으로써 협업 능력 향상을 실현한다. 협업 중심 최적화(Collaboration-oriented Optimisation)에서는 COPPER가 PPO(Proximal Policy Optimization)를 통해 고품질의 역할 인식 반사**(role-aware reflections)를 생성하고, OPTIMA가 토큰 사용량과 의사소통 가독성을 기준으로 효율성-효과성 균형(effectiveness-efficiency trade-off)을 탐구하며, 정보 교환에 집중된 작업에서 **토큰 비용의 10%**로 2.8배의 성능 향상을 달성함을 강조한다. 특히, MaPoRL은 기존의 LLM을 그대로 활용하는 패러다임이 협업 능력 향상에 한계가 있을 수 있음을 지적하고, 강화 학습 신호를 통해 협업 행동을 명시적으로 유도하는 방식을 제안한다. 이러한 방법들은 다중 에이전트 시스템의 협업 능력 확장과 LLM 백본의 지속적 진화 가능성을 실증적으로 보여준다.
The evolution of the LLM backbone behind agents is a critical aspect of multi-agent evolution, particularly how agents improve their cooperative or reasoning abilities through interaction.
Reasoning-oriented Optimisation. A prominent line of work focuses on enhancing the backbone LLM’s reasoning capacity via multi-agent collaboration. For instance, multi-agent finetuning (Subramaniam et al., 2025) leverages high-quality cooperative trajectories sampled from multi-agent debates for supervised fine-tuning, enabling (1) role-specific specialisation of agents and (2) improved reasoning capabilities of the underlying backbone model. Similarly, Sirius (Zhao et al., 2025c) and MALT (Motwani et al., 2024) employ self-play to
collect high-quality cooperative trajectories and train agents within their respective multi-agent collaboration frameworks. While both approaches leverage failed trajectories to some extent, they differ in methodology: Sirius relies solely on SFT and integrates incorrect trajectories via self-correction into the training dataset, whereas MALT adopts DPO, naturally utilising negative samples. These methods provide early evidence of the potential for self-improvement in multi-agent systems, though they are primarily applied in relatively simple settings (e.g., multi-agent debate or “generator-verifier-answerer” system). Moving forward, MaPoRL (Park et al., 2025) introduces task-specific reward shaping to explicitly incentivise inter-agent communication and cooperation through reinforcement learning. MARFT (Liao et al., 2025) establishes a comprehensive bridge between conventional multi-agent reinforcement learning (MARL) and LLM-based multi-agent reinforcement tuning. Building on this, MARTI (Liao et al., 2025) proposes a more customizable framework for reinforced multi-agent fine-tuning, supporting flexible design of both agentic structures and reward functions. Empirical results show that LLM backbones exhibit considerable improvements in cooperative capabilities during their cooperative training.
Collaboration-oriented Optimisation. Beyond reasoning, a smaller body of work focuses on enhancing communication and collaboration abilities within multi-agent systems. The core assumption is that LLM agents are not inherently effective team players, and their collaborative communication skills require targeted training. An early example is COPPER (Bo et al., 2024), which employs PPO to train a shared reflector that generates high-quality, role-aware personalised reflections for multi-agent collaboration trajectories. OPTIMA (Chen et al., 2025h) more directly targets communication efficiency in multi-agent systems (measured by token usage and communication readability) and explores achieving an effectiveness-efficiency trade-off via SFT, DPO, and hybrid methods. It reports a 2.8× performance gain with less than 10% of the token cost on tasks demanding intensive information exchange, which vividly demonstrates the promising potential of scaling agents’ collaborative capabilities. Further, MaPoRL (Park et al., 2025) argues that the prevalent paradigm of prompting out-of-the-box LLMs and relying solely on their innate collaborative abilities is questionable. Instead, it introduces carefully designed reinforcement learning signals within a multi-agent debate framework to explicitly elicit collaborative behaviours, encouraging agents to communicate more frequently and with higher quality.
6 Domain-Specific Optimisation
Summary
이 섹션에서는 이전 섹션에서 다룬 일반 영역 기반 에이전트 최적화 기법과 달리, 생물의학, 프로그래밍, 과학 연구, 게임 플레이, 컴퓨터 사용, 금융 및 법적 분석과 같은 도메인 특화 시스템에서 발생하는 고유한 도전 과제를 다룬다. 이러한 도메인은 전문적인 작업 구조, 분야별 지식 베이스, 다른 데이터 모드, 운영 제약 조건 등으로 인해 에이전트의 설계, 최적화, 진화 방식에 깊은 영향을 미치며, 이에 따라 맞춤형 최적화 전략이 필수적이다. 본 섹션에서는 이러한 도메인별 특성에 대응하기 위해 개발된 최신 최적화 및 진화 기법을 조사하며, 각 분야의 독특한 요구 사항을 충족시키는 효과적인 방법론을 강조한다. 특히, 특정 도메인에서의 지식 구조, 데이터 형식, 작업 흐름에 맞춘 전략적 접근이 에이전트 성능 향상에 핵심적인 역할을 한다는 점을 강조한다.
While previous sections have focused on agent optimisation and evolution techniques in general-domain settings, domain-specific agent systems introduce unique challenges that require tailored optimisation strategies. These domains, such as biomedicine (Almansoori et al., 2025), programming (Tang et al., 2024), scientific research (Pu et al., 2025), game-playing (Belle et al., 2025), computer use (Sun et al., 2025), and finance & legal research, are often characterised by specialised task structures, domain-specific knowledge bases, distinct data modalities, and operational constraints. Such factors can significantly influence how agents are designed, optimised, and evolved. In this section, we survey recent advances in domain-specific agent optimisation and evolution, highlighting effective techniques that have been developed to meet the unique demands of each domain.
6.1 Domain-Specific Optimisation in Biomedicine
Summary
이 섹션에서는 생물의학 분야에서의 도메인 특화 최적화(Domain-Specific Optimisation)가 실제 임상 환경의 절차적 및 운영적 요구사항과 에이전트 행동을 일치시키는 데 중점을 두고 있다고 설명한다. 특히, 의료 진단 및 분자 발견이라는 두 가지 핵심 응용 분야에서 도메인 특화 에이전트 설계의 효과가 최근 연구를 통해 입증되었으며, 이에 해당하는 대표적인 사례로는 [2018], 등 [2025], 등 [2025]의 의료 진단 연구와 등 [2024], 등 [2025]의 분자 발견 연구가 언급된다. 이는 에이전트 최적화가 단순한 일반화된 접근이 아닌, 생물의학의 복잡한 요구사항과 맞춤화된 설계가 필요하다는 점을 강조하며, 해당 분야의 실질적 적용 가능성과 연구 방향을 제시한다.
In the biomedical domain, agent optimisation focuses on aligning agent behaviours with the procedural and operational requirements of real-world clinical settings. Recent studies have demonstrated the effectiveness of domain-specific agent design in two key application areas: medical diagnosis (Donner-Banzhoff, 2018; Almansoori et al., 2025; Zhuang et al., 2025) and molecular discovery (M. Bran et al., 2024; Inoue et al., 2025). In what follows, we examine representative agent optimisation strategies within these two domains.
6.1.1 Medical Diagnosis
Summary
이 섹션에서는 의료 진단 분야에서의 자율 에이전트 시스템 설계에 대한 도메인 특화 최적화 기법을 다룬다. 의료 진단은 환자의 증상, 병력, 검사 결과 등 기반 정보를 바탕으로 상태를 판단하는 복잡한 과정으로, 다중 에이전트 시스템(Multi-Agent Systems)이 시뮬레이션 기반(Simulation-Driven) 및 협업형(Collaborative) 설계 두 가지 주요 접근 방식을 통해 복잡한 다단계 추론과 전문가 워크플로우 모방을 지원하고 있다. 예를 들어, MedAgentSim은 경험 재생, 사고 체인 앙상블, CLIP 기반 의미 메모리 등을 통합한 자기 진화형 시뮬레이션 프레임워크를 도입했으며, PathFinder는 초고해상도 의료 이미지에서 전문가 진단 프로세스를 모방하는 다중 에이전트 협업을 수행한다. 한편, MDAgents와 MDTeamGPT는 다학제적 협의를 지원하는 자체적 반성 대화 메커니즘을 통해 다양한 의견 통합과 외부 지식 소스 상호작용을 가능하게 한다. 또한, MMedAgent는 다양한 모달리티에서 전문 의료 도구를 동적으로 통합해 기존 다모달 LLM의 일반화 한계를 극복하고, MedAgent-Pro는 임상 기준에 기반한 진단 계획과 타스크 특화 도구 에이전트를 통해 다모달 증거 통합을 수행한다. 이 연구들은 전문성(Specialisation), 다모달성(Multimodality), 상호작용 추론(Interactive Reasoning)을 의료 진단 에이전트 시스템 설계의 핵심 원칙으로 제시하고 있다.
Medical diagnosis requires determining a patient’s condition based on clinical information such as symptoms, medical history, and diagnostic test results (Kononenko, 2001; Donner-Banzhoff, 2018). Recent research has increasingly explored the use of autonomous agents in this context, enabling systems to automatically conduct diagnostic dialogues, pose clarifying questions, and generate plausible diagnostic hypotheses (Li et al., 2024c; Chen et al., 2025i; Zuo et al., 2025; Ghezloo et al., 2025). These agents often operate under uncertain conditions, making decisions based on incomplete or ambiguous patient information (Chen et al., 2025i). The diagnostic process typically involves multi-turn interactions, during which agents elicit missing information through follow-up enquiries (Chen et al., 2025i). Moreover, to support robust clinical reasoning, agents often require integrating external knowledge bases or interacting with specialised medical tools for information retrieval and evidence-based reasoning (Feng et al., 2025b; Fallahpour et al., 2025).
Given these domain-specific requirements, recent studies have focused on developing agent architectures specifically optimised for medical diagnosis (Li et al., 2024a; Almansoori et al., 2025; Ghezloo et al., 2025; Wang et al., 2025l). One promising research direction focuses on multi-agent systems, which have shown strong potential for modelling the complexity and multi-step reasoning involved in medical diagnosis. These approaches can be broadly classified into two categories: simulation-driven and collaborative designs. Simulationdriven systems aim to reproduce real clinical settings by assigning specific roles to agents and enabling them to learn diagnostic strategies through interactions within a simulated medical environment. For instance, MedAgentSim (Almansoori et al., 2025) introduces a self-evolving simulation framework that integrates experience replay, chain-of-thought ensembling, and CLIP-based semantic memory to support diagnostic reasoning. PathFinder (Ghezloo et al., 2025) targets histopathological analysis by orchestrating multiple agents to emulate expert diagnostic workflows on gigapixel-scale medical images. In contrast, collaborative multi-agent systems focus on collective decision-making and collaboration among agents. For example, MDAgents (Kim et al., 2024) enables adaptive collaboration among multiple agents, where a moderator agent is responsible for integrating diverse suggestions and consulting external knowledge sources as needed. MDTeamGPT (Chen et al., 2025c) extends this paradigm to multidisciplinary consultation, supporting self-evolving, team-based diagnostic processes through reflective discussion mechanisms.
Another line of work on agent optimisation for diagnosis focuses on tool integration and multimodal reasoning. For instance, MMedAgent (Li et al., 2024a) addresses the generalisability limitations of existing multimodal LLMs by dynamically incorporating specialised medical tools across different modalities. To improve clinical reliability, MedAgent-Pro (Wang et al., 2025l) introduces diagnostic planning guided by established clinical criteria and integrates multimodal evidence via task-specific tool agents. In contrast to fixed agent architectures, recent work has explored more flexible designs that adapt based on diagnostic performance. For example, Zhuang et al. (2025) proposes a graph-based agent framework where the reasoning process is continuously adjusted using feedback from diagnostic results. These approaches highlight specialisation, multimodality, and interactive reasoning as key principles for developing agent-based systems in medical diagnosis.
6.1.2 Molecular Discovery and Symbolic Reasoning
Summary
이 섹션에서는 생물의학 분야의 분자 발견 과정에서 화학 구조, 반응 경로, 약리학적 제약에 대한 정밀한 상징적 추론(symbolic reasoning)이 필수적임을 강조하며, 이를 지원하기 위한 도메인 특화 기술을 소개한다. CACTUS 시스템은 RDKit과 같은 화학 정보학 도구를 통합해 화학적으로 유효한 출력을 생성함으로써, 도구를 활용하지 않는 에이전트보다 지나치게 우수한 성능을 달성했으며, LLM-RDF는 문헌 검색, 합성 계획, 반응 최적화에 특화된 에이전트를 조정해 화학 합성 자동화를 실현한다. 또한, ChemAgent는 복잡한 화학 작업을 작은 하위 작업으로 분해해 구조화된 메모리 모듈에 저장하고, OSDA Agent는 실패한 분자 제안을 구조화된 메모리 업데이트로 추상화해 미래 의사결정에 반영하는 자기 반성 메커니즘을 도입한다. DrugAgent는 머신러닝 예측기, 생물의학 지식 그래프, 문헌 검색 에이전트의 증거를 통합하는 협력자 아키텍처를 통해 Chain-of-Thought 및 ReAct 프레임워크를 기반으로 다중 출처 추론을 지원하며, LIDDIA는 추론자, 실행자, 평가자, 메모리의 모듈화된 역할을 할당해 약물 화학에서 반복적 워크플로우를 시뮬레이션하고 다중 목적 분자 평가를 촉진한다.
Molecular discovery within biomedical domains demands precise symbolic reasoning over chemical structures, reaction pathways, and pharmacological constraints (Bilodeau et al., 2022; Makke and Chawla, 2024; M. Bran et al., 2024). To support molecular discovery, recent agent-based systems have introduced tailored techniques such as integrating chemical analysis tools, enhancing memory for knowledge retention, and enabling multiagent collaboration (McNaughton et al., 2024; Inoue et al., 2025). One key approach is domain-specific tool integration, which allows agents to perform chemical reasoning through interaction with executable chemical operations. For instance, CACTUS (McNaughton et al., 2024) equips agents with cheminformatics tools such as RDKit (Landrum, 2013) to ensure the generation of chemically valid outputs. By grounding reasoning in domain-specific toolsets, CACTUS achieves significantly better performance than agents without tool integration. Similarly, LLM-RDF (M. Bran et al., 2024) automates chemical synthesis by coordinating specialised agents, each responsible for a specific task and equipped with corresponding tools for literature mining, synthesis planning, or reaction optimisation.
Another prominent line of research leverages memory-enabled reasoning (Hu et al., 2025c; Inoue et al., 2025), where agents learn from prior experience by recording how previous problems were solved. ChemAgent (Tang et al., 2025a) breaks down complex chemical tasks into smaller subtasks, which are stored within a structured memory module, enabling efficient retrieval and refinement. OSDA Agent (Hu et al., 2025c) extends this approach by introducing a self-reflective mechanism, where failed molecule proposals are abstracted into structured memory updates that inform and enhance future decision-making. In parallel, multi-agent coordination provides additional benefits. DrugAgent (Inoue et al., 2025) introduces a coordinator architecture that integrates evidence from machine learning-based predictors, biomedical knowledge graphs, and literature search agents. It employs Chain-of-Thought and ReAct (Yao et al., 2023b) frameworks to support interpretable, multi-source
reasoning. LIDDIA (Averly et al., 2025) generalises this design by assigning modular roles, i.e., reasoner, executor, evaluator, and memory, which collectively emulate iterative workflows in medicinal chemistry and facilitate multi-objective molecule evaluation.
6.2 Domain-Specific Optimisation in Programming
Summary
이 섹션에서는 프로그래밍 분야에서의 도메인 특화 최적화가 기존 소프트웨어 공학 워크플로우의 절차적 및 운영적 요구사항과 에이전트 행동을 일치시키는 데 초점을 맞춘다고 설명한다. 특히 코드 정련(code refinement)과 코드 디버깅(code debugging)이라는 두 핵심 응용 분야에서, 등 [2024], 등 [2024], 등 [2025b]의 연구는 코드 품질 향상을, 등 [2024a], 등 [2025], 등 [2025]의 연구는 버그 탐지 및 수정 효율성을 높이는 데 도메인 특화 에이전트 설계의 효과를 입증하였다. 이러한 사례들은 프로그래밍 도메인에서 에이전트가 코드 생성, 검증, 최적화 과정에 특화된 작업 흐름과 도구 활용 전략을 통합적으로 최적화하는 방식을 보여준다.
In the programming domain, agent optimisation focuses on aligning agent behaviours with the procedural and operational requirements of established software engineering workflows. Recent studies have demonstrated the effectiveness of domain-specific agent design in two key application areas: code refinement (Rasheed et al., 2024; Tang et al., 2024; Pan et al., 2025b) and code debugging (Lee et al., 2024a; Puvvadi et al., 2025; Adnan et al., 2025). In what follows, we examine representative agent optimisation strategies within these two domains.
6.2.1 Code Refinement
Summary
이 섹션에서는 코드 정련(Code Refinement) 과정에서 자율적 피드백 메커니즘과 경험 기반 학습을 중심으로 한 자기 진화형 에이전트 기반 최적화 전략을 설명한다. Self-Refine은 언어 모델이 자체 출력에 대한 자연어 피드백을 생성하고 코드를 수정하는 경량 프레임워크를 제안하며, CodeCriticBench는 LLM의 자가 비판 및 정련 능력을 평가하는 벤치마크를 소개한다. 또한, LLM-Surgeon은 학습된 수리 패턴을 기반으로 코드의 구조적 및 의미적 문제를 진단하고 수정하는 체계적 프레임워크를 제시한다. 이들은 태스크 특화 재교육 없이도 일관된 코드 품질 향상을 달성한다. 한편, 경험 기반 학습 접근법은 이전 작업의 해법을 메모리 기반 추론을 통해 재사용함으로써 문제 해결 능력을 향상시키는 방식으로, AgentCoder와 CodeAgent는 코더, 리뷰어, 테스터 등 전문 역할을 할당한 협업 워크플로우를 시뮬레이션하여 코드를 반복적으로 개선한다. CodeCoR 및 OpenHands와 같은 툴 강화 프레임워크는 외부 도구와 모듈화된 에이전트 상호작용을 통해 동적 코드 정리, 패치 생성, 맥락 인식 정련을 지원한다. VFlow는 Verilog 코드 생성 작업의 워크플로우 최적화 문제를 코드 기반 표현의 LLM 노드 그래프 상에서 협동 진화와 과거 경험을 활용한 MCTS(CEPE-MCTS) 알고리즘을 통해 탐색 문제로 재구성한다. 이러한 접근법들은 반복 피드백, 모듈화 설계, 상호작용 추론을 기반으로 한 적응형 에이전트 시스템 구축의 핵심 원칙으로 작용한다.
Code refinement involves the iterative improvement of code quality, structure, and correctness while preserving its original functionality (Yang et al., 2024d; He et al., 2025; Islam et al., 2025). Recent studies have increasingly investigated agent-based systems that support domain-specific optimisation for this task, focusing on selfimprovement, collaborative workflows, and integration with programming tools (Madaan et al., 2023; Tang et al., 2024; Rahman et al., 2025). These systems are designed to emulate human-in-the-loop refinement processes, enforce adherence to software engineering best practices, and ensure that code remains robust, readable, and maintainable throughout iterative development cycles. One critical optimisation strategy involves self-feedback mechanisms, where agents critique and revise their own outputs. For example, Self-Refine (Madaan et al., 2023) introduces a lightweight framework in which a language model generates natural language feedback on its own outputs and subsequently revises the code accordingly. Similarly, CodeCriticBench (Zhang et al., 2025a) presents a comprehensive benchmark designed to assess the self-critiquing and refinement capabilities of LLMs, where agents are evaluated on their ability to identify, explain, and revise code defects through structured natural language feedback. LLM-Surgeon (van der Ouderaa et al., 2023) proposes a systematic framework in which a language model diagnoses structural and semantic issues within its own code outputs and applies targeted edits based on learned repair patterns, thereby optimising code quality while preserving functionality. These approaches eliminate the need for task-specific retraining, providing consistent improvements in code quality.
Another line of research explores experience-driven learning, where agents improve their problem-solving capabilities by relying on memory-enabled reasoning, systematically recording and reusing solutions to previously encountered tasks (Wang et al., 2025g; Tang et al., 2024; Pan et al., 2025b). For example, AgentCoder (Huang et al., 2023a) and CodeAgent (Tang et al., 2024) simulate collaborative development workflows by assigning specialised roles to individual agents, such as coder, reviewer, and tester, which iteratively improve code through structured dialogue cycles. These systems support collective evaluation and revision, promoting role specialisation and deliberative decision-making. Additionally, tool-enhanced frameworks such as CodeCoR (Pan et al., 2025b) and OpenHands (Wang et al., 2025g) incorporate external tools and modular agent interactions to facilitate dynamic code pruning, patch generation, and context-aware refinement. VFlow (Wei et al., 2025b) reformulates the workflow optimisation problem of Verilog code generation task as a search task on a graph of LLM nodes with code-based representations, employing a Cooperative Evolution with Past Experience MCTS (CEPE-MCTS) algorithm. These developments highlight iterative feedback, modular design, and interactive reasoning as essential principles for building adaptive agent-based systems for code refinement.
6.2.2 Code Debugging
Summary
이 섹션에서는 코드 디버깅(Code Debugging) 분야에서 자율 에이전트 시스템의 설계에 있어 정밀한 오류 위치 파악, 실행 인식 추론, 반복적 수정 등의 핵심 능력이 필요하다는 점을 강조하며, 일반 목적 대규모 언어 모델(LLM)이 이러한 기능을 부족하게 한다는 한계를 지적한다. 이를 해결하기 위해 도메인 특화 최적화(Domain-Specific Optimisation)는 인간의 디버깅 실천에서 관찰되는 구조화된 추론 패턴과 도구 활용 방식을 에이전트 역할 및 워크플로우에 맞추어 설계하는 전략을 제시한다. 특히, 실행 시간 피드백(Runtime Feedback)을 활용한 자기 수정(Self-Correction)이 핵심으로, Self-Debugging과 Self-Edit과 같은 시스템은 실행 추적 정보를 디버깅 과정에 통합하여 외부 감독 없이 자율적으로 작동한다. 또한, 모듈형 에이전트 아키텍처(Modular Agent Architectures)가 디버깅 워크플로우의 다단계 구조를 지원하기 위해 설계되었으며, 예를 들어 PyCapsule은 프로그래머 에이전트와 실행자 에이전트의 역할을 분리해 코드 생성과 의미 검증을 구분한다. 더 고급된 시스템인 Self-Collaboration과 RGD는 협업 파이프라인(Collaborative Pipelines)을 통해 테스터, 리뷰어, 피드백 분석가 등의 전문 역할을 갖춘 에이전트를 활용해 전문가 디버깅 방식을 모방한다. 또한, FixAgent는 버그 복잡도와 분석 깊이에 따라 계층적 에이전트 활성화(Hierarchical Agent Activation)를 통해 적절한 에이전트를 동적으로 할당하는 방식을 도입해 디버깅 효율성을 높인다.
Code debugging presents intricate challenges that require precise fault localisation, execution-aware reasoning, and iterative correction. These capabilities are typically absent in general-purpose LLMs (Puvvadi et al., 2025; Mannadiar and Vangheluwe, 2010). To address these challenges, domain-specific optimisation focuses on aligning agent roles and workflows with the structured reasoning patterns and tool usage observed in human debugging practices. A key strategy involves leveraging runtime feedback to facilitate self-correction. For example, Self-Debugging (Chen et al., 2024c) and Self-Edit (Zhang et al., 2023a) exemplify this approach by incorporating execution traces into the debugging process. These agents operate through internal cycles of fault identification, natural language-based reasoning, and targeted code revision, enabling autonomous debugging without external supervision.
Recent research has explored modular agent architectures specifically designed to support the multi-stage structure of debugging workflows. For instance, PyCapsule (Adnan et al., 2025) introduces a separation of responsibilities between a programmer agent and an executor agent, thereby distinguishing code generation from semantic validation. More advanced systems, including Self-Collaboration (Dong et al., 2024) and RGD (Jin et al., 2024), employ collaborative pipelines in which agents are assigned specialised roles such as tester, reviewer, or feedback analyser, mirroring professional debugging practices. Additionally, FixAgent (Lee et al., 2024a) extends this paradigm through hierarchical agent activation, dynamically dispatching different agents based on bug complexity and required depth of analysis.
6.3 Domain-Specific Optimisation in Financial and Legal Research
Summary
이 섹션에서는 재무 및 법적 분야에서의 도메인 특화 최적화가 절차적·운영적 요구사항에 맞춘 다중 에이전트 아키텍처, 추론 전략, 도구 통합에 중점을 두고 있다고 설명한다. 특히 재무 의사결정과 법적 추론이라는 두 핵심 분야에서, 모듈형 설계, 협업적 상호작용, 규칙 기반 추론이 신뢰성 있는 성능 달성에 필수적이며, 최근 연구([Li et al., 2023c; Yu et al., 2024b; Di Martino et al., 2023; Chen et al., 2025a] 등)는 이러한 도메인 특화 설계의 효과를 입증했다. 예를 들어, 재무 분야에서는 복잡한 시장 조건과 리스크 관리 프로세스를 반영한 에이전트 구조가 요구되며, 법적 분야에서는 법률 문서 해석, 판례 기반 논리 추론, 규제 준수 검증 등에 정밀한 추론 능력이 필수적이다. 이에 따라, 해당 분야별 특성에 맞춘 에이전트 최적화 전략이 개발되어, 실제 업무 흐름과 전문 지식 기반을 효과적으로 반영하는 시스템 구현이 가능해지고 있다.
In financial and legal domains, agent optimisation focuses on tailoring multi-agent architectures, reasoning strategies, and tool integration to the procedural and operational demands of domain-specific workflows (Sun et al., 2024b; He et al., 2024; Li et al., 2025f). Recent studies have demonstrated the effectiveness of such domain-specific designs in two key application areas: financial decision-making (Li et al., 2023c; Yu et al., 2024b; Wang et al., 2024j) and legal reasoning (Di Martino et al., 2023; Chen et al., 2025a), where modular design, collaborative interaction, and rule-grounded reasoning are essential for reliable performance. In what follows, we examine representative agent optimisation strategies within these two domains.
6.3.1 Financial Decision-Making
Summary
이 섹션에서는 재무 의사결정 분야에서의 에이전트 최적화 기법을 다루며, 시장의 불확실성과 급변하는 환경에서 다양한 정보 원천(수치 지표, 뉴스 감정, 전문 지식)을 통합하고 동적 시장 조건에 대응하는 자기 진화형 다중 에이전트 시스템(self-evolving multi-agent systems)의 필요성을 강조한다. 최근 연구에서는 FinCon, PEER, FinRobot 등의 모듈형 다중 에이전트 아키텍처를 통해 재무 환경의 절차적 및 인지적 요구사항에 맞춘 설계를 탐구하고 있으며, 이들 시스템은 개념적 언어 강화(conceptual verbal reinforcement)와 도메인 적응형 미세 조정(domain-adaptive fine-tuning)을 통해 동적 시장에서의 의사결정 안정성과 정책 일관성을 향상시킨다. 특히, FinRobot은 외부 도구를 통합해 고급 전략과 실행 가능한 재무 모델, 실시간 데이터 스트림을 연결하는 모델 기반 추론(model-grounded reasoning) 기능을 추가함으로써 실용성을 높였다. 또한, 감정 분석 및 보고서 생성 분야에서는 혼합형 LLM 에이전트 아키텍처와 템플릿 기반 보고서 프레임워크를 통해 규칙 기반 검증기와 특화된 감정 모듈을 결합해 재무 보고서의 내결함성(robustness)과 도메인 가이드라인 준수를 달성하는 방안을 제시한다. 이와 같은 접근법은 복잡한 재무 환경에서 해석 가능성(interpretability)과 맥락 인식(context-awareness)을 갖춘 신뢰성 있는 의사결정 지원을 제공할 잠재력을 보여준다.
Financial decision-making requires agents to operate under uncertain and rapidly changing conditions, reason over volatile market dynamics, and integrate heterogeneous information sources such as numerical indicators, news sentiment, and expert knowledge (Li et al., 2023c; Sarin et al., 2024; Chudziak and Wawer, 2025). In response to these domain-specific demands, recent research has focused on developing multi-agent architectures tailored to the procedural and cognitive requirements of financial environments (Fatemi and Hu, 2024; Luo et al., 2025b). One critical strategy involves conceptual and collaborative agent design. For instance, FinCon (Yu et al., 2024b) proposes a synthesised multi-agent system built on LLMs, employing conceptual verbal reinforcement and domain-adaptive fine-tuning to enhance decision stability and policy alignment in dynamic markets. PEER (Wang et al., 2024j) extends this paradigm through a modular agent architecture comprising expert, retriever, and controller roles, which interact under a unified tuning mechanism to balance task specialisation with general adaptability. FinRobot (Yang et al., 2024b) further advances this line of work by integrating external tools for model-grounded reasoning, enabling agents to connect high-level strategies with executable financial models and real-time data streams.
Another line of work on agent optimisation for financial decision-making focuses on sentiment analysis and reporting (Xing, 2025; Tian et al., 2025; Raza et al., 2025). Heterogeneous LLM agent architectures (Xing, 2025) enhance robustness in financial reporting by combining specialised sentiment modules with rule-based validators to ensure compliance with domain-specific guidelines. Similarly, template-based reporting frameworks (Tian et al., 2025) decompose report generation into agent-driven retrieval, validation, and synthesis stages, enabling iterative refinement through real-world feedback. These approaches demonstrate the potential of self-evolving multi-agent systems to provide reliable, interpretable, and context-aware decision support in complex financial environments.
6.3.2 Legal Reasoning
Summary
이 섹션에서는 법적 추론(Legal Reasoning) 분야에서 AI 에이전트가 구조화된 법적 규칙 해석, 사례 중심 증거 분석, 제도적 규정과 재판 기준과 일치하는 출력 생성을 수행해야 함을 강조하며, 이를 위해 다중 에이전트 시스템(Multi-Agent Systems)을 기반으로 한 법적 특화 최적화 기법을 탐구한다. 특히, LawLuo 시스템은 문서 작성, 법적 논증 생성, 준수 검증 등 특화된 역할을 가진 에이전트를 중심으로 구성되며, 중앙 제어자(central controller)의 감독 하에 절차적 일관성과 법적 정확성을 유지하도록 설계하였다. AgentCourt는 대립적 재판 절차(adversarial trial procedures)를 시뮬레이션하는 역할 기반 상호작용(role-based interactions)을 지원하며, 자기 진화형 변호사 에이전트(self-evolving lawyer agents)가 반사적 자가 경기(reflective self-play)를 통해 전략을 개선함으로써 토론 질 향상과 절차적 현실성(procedural realism)을 달성하였다. 한편, LegalGPT는 법적 사고 체계(legal chain-of-thought framework)를 통합하여 해석 가능한 규칙 기반 단계(interpretable and rule-aligned steps)를 통해 법적 추론을 지도하고, AgentsCourt는 재판실 역할 시뮬레이션과 법적 지식 증강(legal knowledge augmentation)을 결합하여 규정화된 법칙과 사례 판례(case precedents)에 기반한 재판 의사결정(judicial decision-making)을 수행한다. 이러한 접근법은 규칙 기반 설계(rule grounding), 모듈형 역할 구조(modular role design), 협업적 추론(collaborative reasoning)이 신뢰성 있고 투명하며 법적으로 신뢰할 수 있는 에이전트 시스템(robust, transparent, and legally reliable agent systems) 개발에 핵심적인 역할을 함을 강조한다.
Legal reasoning requires agents to interpret structured legal rules, analyse case-specific evidence, and produce outputs that are consistent with institutional regulations and judicial standards (Xu and Ju, 2023; Yuan et al., 2024c; Jiang and Yang, 2025). To address these domain-specific demands, recent research has explored multi-agent systems tailored to the procedural and interpretive requirements of legal settings (Di Martino et al., 2023; Hu and Shu, 2023; Chen et al., 2025a). One significant direction involves collaborative agent frameworks that simulate judicial processes and support structured argumentation. For instance, LawLuo (Sun et al., 2024b) introduces a co-run multiagent architecture in which legal agents are assigned specialised roles such as document drafting, legal argument generation, and compliance validation, all operating under the supervision of a central controller to ensure procedural consistency and legal correctness. Multi-Agent Justice Simulation (Di Martino et al., 2023) and AgentCourt (Chen et al., 2025a) extend this paradigm to model adversarial trial procedures, enabling agents to participate in role-based interactions that emulate real-world courtroom dynamics. In
particular, AgentCourt incorporates self-evolving lawyer agents that refine their strategies through reflective self-play, leading to improved debate quality and enhanced procedural realism.
Another line of work focuses on structured legal reasoning and domain-grounded interpretability. LegalGPT (Shi et al., 2024b) integrates a legal chain-of-thought framework within a multi-agent system, guiding legal reasoning through interpretable and rule-aligned steps. Similarly, AgentsCourt (He et al., 2024) combines courtroom debate simulation with legal knowledge augmentation, enabling agents to perform judicial decision-making grounded in codified rules and case precedents. These approaches highlight the importance of rule grounding, modular role design, and collaborative reasoning in the development of robust, transparent, and legally reliable agent systems.
7 Evaluation
Summary
이 섹션에서는 자율적 LLM 기반 에이전트의 빠른 발전에 따라 다층적 평가 프레임워크(multidimensional evaluation frameworks)의 필요성을 강조하며, 기존 연구에서 도입된 基准(benchmark)와 평가 방법론(methodologies)을 정리한다. 평가는 이제 단순한 성능 점검이 아닌, 세부 성능 신호(fine-grained performance signals)를 통해 에이전트의 최적화, 프롬프트 개선, 데이터셋 확장을 지속적으로 이끌어내는 동적 피드백 메커니즘(dynamic feedback mechanism)으로 인식되고 있다. 현재 평가 패러다임은 구조화된 벤치마크(structured benchmark tasks), 안전성 및 정렬 기준(safety- and alignment-oriented audits), 그리고 LLM-as-a-judge 접근(대규모 언어 모델을 유연한 평가자로 활용하는 방식)을 포함하며, 이는 자기 진화형 시스템(self-evolving systems)이 새로운 능력을 습득하고 실패 사례를 해결하는 데 핵심적인 역할을 한다. 특히, 도메인 특화 에이전트(예: 생물의학, 프로그래밍, 법적 분석)의 설계와 최적화는 평가 프레임워크를 통해 안전성, 일관성, 전문성을 동시에 보장하는 데 기여하고 있다.
The rapid emergence of autonomous LLM-based agents has underscored the need for rigorous, multidimensional evaluation frameworks. As these agents are deployed across increasingly diverse tasks and environments, recent research has introduced a range of benchmarks and methodologies to assess not only task completion but also reasoning quality, generalisation ability, and compliance with safety and alignment standards. Evaluation is no longer viewed as a static endpoint but as a dynamic feedback mechanism: fine-grained performance signals are now used to guide agent optimisation, prompt refinement, and dataset augmentation, enabling self-evolving systems that continuously acquire new capabilities and address failure cases. Current evaluation paradigms encompass structured benchmark tasks with standardised metrics, safety- and alignment-oriented audits, and LLM-as-a-judge approaches that leverage large models as flexible, scalable evaluators.
7.1 Benchmark-based Evaluation
Summary
이 섹션에서는 도구 및 API 기반 에이전트(Tool- and API-Driven Agents)의 평가 방법을 다루며, ToolBench, API-Bank, MetaTool, ToolQA 등의 벤치마크가 에이전트의 외부 도구 사용 능력을 평가하는 데 활용됨을 설명한다. 이러한 평가에서는 API 호출의 정확성(correctness)과 효율성(efficiency)을 동시에 측정하며, 시뮬레이션된 API나 샌드박스 환경을 통해 작업 성공률과 상호작용 효율성을 평가한다. 그러나 초기 연구에서는 에이전트가 특정 도구 스키마에 과도하게 과적합되어 새로운 API에 대한 일반화 능력(generalisation)이 제한된다는 문제가 지적되었으며, 이를 해결하기 위해 GTA와 AppWorld와 같은 최근 벤치마크가 다중 단계 작업과 도구 간 계획 및 협업을 요구하는 더 현실적인 평가 기준을 도입했다. 특히, 이러한 새로운 접근법은 결과 중심 평가(outcome-focused evaluation)를 넘어 결정 과정의 품질(quality of decision-making process)을 평가하는 프로세스 중심 메트릭(process-oriented metrics)에 중점을 두며, 추론 능력과 계획적 실행 능력(reasoning and planning capabilities)을 종합적으로 평가하는 방향으로 발전하고 있다.
7.1.1 Tool and API-Driven Agents
Summary
이 섹션에서는 도구 및 API 기반 에이전트(Tool- and API-Driven Agents)의 평가 기준을 설명하며, 이들의 핵심 역량은 외부 도구/API 호출을 통해 내재 지식 범위를 넘어선 문제 해결 능력에 있다고 강조한다. 평가 기준으로는 ToolBench, API-Bank, MetaTool, ToolQA 등이 사용되며, 이들은 API 호출의 정확성과 효율성을 동시에 평가한다. 그러나 초기 연구에서는 에이전트가 특정 도구 스키마에 과도하게 과적합되어 새로운 API에 대한 일반화 능력이 제한적임이 드러났다. 이를 해결하기 위해 GTA와 AppWorld와 같은 최근 벤치마크는 복잡한 다단계 작업을 도입해 여러 도구 간의 계획 및 협업을 요구하며, 프로세스 중심 평가 지표(process-oriented evaluation metrics)에 더 중점을 둔다. 이는 단순한 최종 결과뿐만 아니라 의사결정 과정의 질까지 평가하는 보다 풍부한 평가 방향으로의 전환을 반영한다.
Tool-augmented agents are evaluated based on their ability to invoke external APIs and functions to solve problems that exceed the scope of their intrinsic knowledge. Benchmarks such as ToolBench (Xu et al., 2023), API-Bank (Li et al., 2023b), MetaTool (Huang et al., 2023b), and ToolQA (Zhuang et al., 2023) define tasks that require tool usage and assess both the correctness and efficiency of API calls. Many of these evaluations employ simulated APIs or sandboxed environments, measuring task success alongside interaction efficiency. Early studies have shown that agents often overfit to specific tool schemas, exhibiting limited generalisation to previously unseen APIs. To address this limitation, recent benchmarks such as GTA (Wang et al., 2024b) and AppWorld (Trivedi et al., 2024) introduce more realistic, multi-step tasks that require planning and coordination across multiple tools, while placing greater emphasis on process-oriented evaluation metrics. This trend reflects a broader shift towards richer, reasoning-aware evaluations that assess not only final outcomes but also the quality of the decision-making process.
7.1.2 Web Navigation and Browsing Agents
Summary
이 섹션에서는 웹 브라우징 및 네비게이션에 특화된 AI 에이전트의 평가 기준을 다루며, BrowseComp, WebArena, AgentBench 등과 같은 대표적인 평가 벤치마크가 시뮬레이션 및 실시간 환경에서의 인터페이스 적응성, 텍스트-비주얼 정보 통합, 실제 웹 태스크 수행 능력을 종합적으로 검증함을 설명한다. 최근 연구에서는 중간 지표(예: 하위 목표 달성률)와 강건성 평가를 도입해 에이전트의 성능을 세부적으로 분석하나, 웹 환경의 동적 변화 특성으로 인해 재현성(reproducibility)과 일반화 능력(generalisation) 확보가 여전히 어려운 과제로 남아 있다. 특히, VisualWebArena와 WebCanvas 같은 벤치마크는 시각적 요소를 포함한 복합적 작업을 통해 평가의 현실성을 높였으며, MM-BrowseComp는 멀티모달 정보 처리 능력을 추가적으로 검증하는 방향으로 발전하고 있다.
Web agents are evaluated on their ability to interact with websites, extract information, and complete realworld online tasks. Benchmarks such as BrowseComp (Wei et al., 2025a), MM-BrosweComp (Li et al., 2025e), WebArena (Zhou et al., 2023b), VisualWebArena (Koh et al., 2024), WebCanvas (Pan et al., 2024b), WebWalker (Wu et al., 2025b), and AgentBench (Liu et al., 2023a) have progressively increased the realism and diversity of web-based evaluations, spanning simulated and live environments. These benchmarks test navigation skills, adaptability to interface changes, and the integration of textual and visual information. Recent work incorporates intermediate metrics (e.g., sub-goal completion) and robustness assessments, though reproducibility and generalisation remain challenging due to the dynamic nature of the web.
7.1.3 Multi-Agent Collaboration and Generalists
Summary
이 섹션에서는 일반 목적형 에이전트(Generalist Agents)의 발전에 따라 다중 에이전트 협업 및 다분야 적응 능력을 평가하는 새로운 벤치마크가 제안되고 있음을 설명한다. MultiAgentBench 및 SwarmBench는 LLM 에이전트 간의 협력, 경쟁, 분산형 조정 능력을 평가하며, 작업 완료율과 의사소통 품질, 전략 효율성을 종합적으로 측정한다. 한편, GAIA 및 AgentBench 같은 일반 목적형 벤치마크는 웹 네비게이션부터 코딩, 데이터베이스 쿼리까지 다양한 환경에서의 적응 능력을 평가한다. 특히, **Wang et al. (2025b)**은 GAIA 벤치마크를 활용해 효율성-효과성 균형(efficiency–effectiveness trade-off)을 분석하고, Efficient Agents라는 프레임워크를 제안해 기존 시스템 대비 운영 비용을 크게 절감하면서도 경쟁력 있는 성능을 달성함을 보여준다. 다만, 이 평가에서 드러난 주요 과제는 이질적 작업 간 지표 통합(metric aggregation)의 어려움, 경소규모 시나리오에 과적합(overfitting) 위험, 그리고 통합형 리더보드(unified, holistic leaderboards)의 필요성이 강조된다. 이러한 연구는 다중 에이전트 시스템의 진화 방향과 평가 기준의 체계적 발전을 위한 기반이 되고 있다.
As agents become more general-purpose, new benchmarks target multi-agent coordination and cross-domain competence. MultiAgentBench (Zhu et al., 2025) and SwarmBench (Ruan et al., 2025) evaluate collaboration, competition, and decentralised coordination among LLM agents, assessing both task completion and the quality of communication and strategy. Generalist benchmarks such as GAIA (Mialon et al., 2023) and AgentBench (Liu
et al., 2023a) test adaptability across diverse environments, from web navigation to coding and database queries. Recent work, Wang et al. (2025b) further explores the GAIA benchmark to analyse the efficiency–effectiveness trade-off in agentic systems, proposing Efficient Agents, a framework that achieves competitive performance with significantly reduced operational costs. These evaluations highlight challenges in aggregating metrics across heterogeneous tasks, risks of overfitting to narrow scenarios, and the need for unified, holistic leaderboards.
7.1.4 GUI and Multimodal Environment Agents
Summary
이 섹션에서는 GUI 및 멀티모달 환경 에이전트(GUI and Multimodal Environment Agents)의 평가 기준을 다루며, Mobile-Bench, AndroidWorld, CRAB, GUI-World, OSWorld 등과 같은 벤치마크가 실제 앱 및 운영체제 환경을 시뮬레이션해 복잡한 행동 시퀀스를 요구함을 설명한다. 에이전트는 자연어 이해, 시각 인식, API 호출을 결합한 작업을 수행해야 하며, 평가 지표로는 작업 성공률, 상태 관리, 인식 정확도, GUI 변화에 대한 적응성이 사용된다. 그러나 GUI 환경의 다양성으로 인해 표준화 및 재현성(standardisation and reproducibility)이 어려우며, 인터페이스 변화(interface variability)에 직면할 경우 에이전트의 취약성(brittleness)이 지적된다.
GUI and multimodal benchmarks challenge agents to operate in rich, interactive environments that combine textual and visual inputs. Mobile-Bench (Deng et al., 2024), AndroidWorld (Rawles et al., 2024), CRAB (Xu et al., 2024a), GUI-World (Chen et al., 2024a), and OSWorld (Xie et al., 2024) simulate realistic apps and operating systems, requiring complex action sequences. Tasks often combine natural language understanding, visual perception, and API invocation. Evaluations measure task success, state management, perception accuracy, and adaptability to GUI changes. However, the diversity of GUI environments makes standardisation and reproducibility difficult, and agents remain brittle when faced with interface variability.
7.1.5 Domain-Specific Task Agents
Summary
이 섹션에서는 도메인 특화 작업 에이전트(Domain-Specific Task Agents)의 평가 기준으로 활용되는 대표적 벤치마크를 소개하며, 코딩(SWE-bench), 데이터 과학(DataSciBench, MLGym), 기업 생산성(WorkBench), 과학 연구(OpenAGI, SUPER) 등 분야별 특화된 역량을 평가하는 시스템의 특징을 설명한다. 예를 들어, SWE-bench는 실제 GitHub 저장소에서 코드 편집 에이전트의 성능을 평가하고, AgentClinic과 MMedAgent는 임상 환경에서 다중 모달리티 추론(multimodal reasoning) 능력을 검증한다. 평가 기준은 이전의 이진 성공 여부 중심에서 테스트 통과율, 정책 준수도, 도메인 제약 조건 준수 여부 등 세부 지표로 확장되었으나, 메트릭 정의 불일치와 일반화 능력 한계가 여전히 해결해야 할 주요 과제로 남아 있다.
Domain-focused benchmarks in coding (SWE-bench (Jimenez et al., 2024)), data science (DataSciBench (Zhang et al., 2025c), MLGym (Nathani et al., 2025)), enterprise productivity (WorkBench (Styles et al., 2024)), and scientific research (OpenAGI (Ge et al., 2023), SUPER (Bogin et al., 2024)) assess specialised competencies that integrate planning, tool use, and adherence to domain norms. SWE-bench, for example, evaluates code-editing agents on real GitHub repositories, while AgentClinic (Schmidgall et al., 2024) and MMedAgent (Li et al., 2024a) test multimodal reasoning in clinical settings. Evaluation criteria have expanded from binary success measures to encompass metrics such as test pass rates, policy adherence, and conformity to domain-specific constraints. Despite these advances, inconsistencies in metric definitions and persistent gaps in generalisation remain significant challenges.
7.2 LLM-based Evaluation
Summary
이 섹션에서는 LLM-as-a-Judge 패러다임을 소개하며, 대규모 언어 모델(LLM)을 활용해 AI 시스템의 출력 품질(텍스트, 코드, 대화 응답 등)을 평가하는 방식을 설명한다. 이 접근법은 인간 판단이나 자동 평가 지표(BLEU, ROUGE 등)보다 규모 확장성과 비용 효율성이 뛰어나며, 특히 의미적 깊이와 일관성 측면에서 기존 방법의 한계를 보완할 수 있다. 평가 방식은 점별 평가(pointwise evaluation)와 쌍별 비교(pairwise comparison)로 나뉘며, 전자는 사실성, 유용성 등 기준에 따라 직접 점수를 부여하고, 후자는 두 출력 간 비교를 통해 선호도와 근거를 제시한다. 최근 연구에 따르면 LLM 기반 평가가 인간 판단과 상관관계를 보이며, 경우에 따라 애노테이터 간 일치도 수준에 근접하는 것으로 나타났으나, 프롬프트 설계에 민감하고, 미세한 지시어 변화로 인한 편향에 취약하며, 다단계 추론 과정에서의 사고 깊이를 간과할 수 있는 한계가 있다. 이를 해결하기 위해 CollabEval과 같은 다중 에이전트 논의 프레임워크 및 구조화된 메타 평가 벤치마크를 통한 신뢰도 향상 방안이 제안되고 있다.
7.2.1 LLM-as-a-Judge
Summary
이 섹션에서는 LLM-as-a-Judge 패러다임을 소개하며, 대규모 언어 모델(LLM)을 활용해 AI 시스템의 출력(예: 텍스트, 코드, 대화 응답) 품질을 평가하는 방식을 설명한다. 이 접근법은 인간 판단 및 기존 자동 평가 지표(BLEU, ROUGE 등)보다 확장성과 비용 효율성이 뛰어나며, 특히 의미적 깊이와 일관성을 평가하는 데 유리하다는 점에서 주목받고 있다. 점별 평가(pointwise evaluation)와 쌍별 비교(pairwise comparison)의 두 모드로 운영되는데, 전자는 사실성, 유용성 등의 기준에 따라 직접 점수를 부여하고, 후자는 두 출력 간 비교를 통해 더 우수한 결과를 선택하는 방식이다. 최근 연구에 따르면, LLM 기반 평가가 인간 판단과 일치하는 수준(inter-annotator agreement)에 도달할 수 있으나, 프롬프트 설계에 민감하고, 미묘한 지시사항 변화로 인한 편향에 취약하다는 한계가 있다. 또한, 단계별 평가가 다단계 추론 과정의 논리적 깊이를 놓치는 경우도 발생한다. 이를 해결하기 위해 다중 에이전트 논의 프레임워크(예: CollabEval)와 구조화된 메타 평가 벤치마크를 통한 신뢰성 향상 방안이 제시되었으며, 이는 LLM 평가자의 정확도와 일관성을 개선하는 데 기여하고 있다.
The LLM-as-a-Judge paradigm refers to employing large language models to assess the quality of outputs generated by AI systems, such as text, code, or conversational responses, via structured prompts (Arabzadeh et al., 2024; Li et al., 2024b; Qian et al., 2025b). This approach has attracted attention as a scalable and cost-effective alternative to conventional evaluation methods, including human judgment and automatic metrics (e.g., BLEU, ROUGE), which often fail to capture semantic depth or coherence (Arabzadeh et al., 2024). LLM judges typically operate in two modes: pointwise evaluation (Ruan et al., 2024), where outputs are scored directly against criteria such as factuality and helpfulness, and pairwise comparison, where two outputs are compared and the preferred one is selected with justification (Li et al., 2024b; Zhao et al., 2025b).
Recent studies demonstrate that LLM-based evaluations can correlate with human judgments, in some cases reaching parity with inter-annotator agreement levels (Arabzadeh et al., 2024). However, these methods are sensitive to prompt design and susceptible to biases introduced by subtle instructional variations (Arabzadeh et al., 2024; Zhao et al., 2025b). Furthermore, single-step, output-focused evaluations may overlook the reasoning depth in multi-step processes (Zhuge et al., 2024b; Wang et al., 2025h). To address these limitations, enhancements have been proposed, including multi-agent deliberation frameworks such as CollabEval (Qian et al., 2025b) and structured meta-evaluation benchmarks to calibrate and improve the reliability of LLM judges (Li et al., 2024b; Zhao et al., 2025b).
7.2.2 Agent-as-a-Judge
Summary
이 섹션에서는 Agent-as-a-Judge 프레임워크를 소개하며, 이는 기존의 단순한 최종 출력만을 평가하는 LLM 기반 평가 기법을 넘어, 다단계 추론 과정, 상태 관리, 도구 사용이 가능한 완전한 에이전트 시스템을 활용해 다른 AI 에이전트를 비판하는 방식이다. 예를 들어, DevAI 벤치마크에서 코드 생성 에이전트를 평가할 때, 이 프레임워크는 중간 생성물 분석, 추론 그래프 구축, 계층적 요구사항 검증 모듈을 통합해 인간 전문가의 판단과 더 유사한 평가 결과를 도출했으며, 수작업 검토 대비 평가 시간과 비용을 감소시킨 효율성 향상을 보였다. 다만, 이 방법은 코드 생성 외 분야로의 일반화에 어려움이 있으며, 현재 연구는 다양한 AI 작업에 걸쳐 적응성을 높이고 배포를 간소화하는 방향으로 진행되고 있다.
The Agent-as-a-Judge framework extends LLM-based evaluation by employing full-fledged agentic systems capable of multi-step reasoning, state management, and tool use to critique other AI agents (Zhuge et al., 2024b; Zhao et al., 2025b; Qian et al., 2025b). Different from traditional LLM judges, which focus solely on final outputs, agent judges evaluate the entire reasoning trajectory, capturing decision-making processes and intermediate actions (Zhuge et al., 2024b). For example, Zhuge et al. (2024b) applied an agent judge
to the DevAI benchmark for code-generation agents. The framework incorporated specialised modules to analyse intermediate artefacts, construct reasoning graphs, and validate hierarchical requirements, resulting in evaluations that aligned more closely with human expert judgments than traditional LLM-based approaches. Agent judges also delivered substantial efficiency gains, reducing evaluation time and cost relative to manual review (Zhuge et al., 2024b; Zhao et al., 2025b).
Nevertheless, implementing the Agent-as-a-Judge methodology introduces additional complexity and raises challenges for generalisation to domains other than code generation. Current research seeks to improve adaptability and simplify deployment across a broader range of AI tasks (Zhao et al., 2025b; Qian et al., 2025b).
7.3 Safety, Alignment, and Robustness in Lifelong Self-Evolving Agents
Summary
이 섹션에서는 자기 진화형 에이전트(self-evolving agents)의 안전성, 정렬성, 견고성 평가에 대한 체계적인 접근 방식을 제시한다. “Endure” 법칙에 따라, 에이전트의 모든 진화 과정(프롬프트 업데이트, 위상 변화 등)에서 의도치 않은 또는 악의적인 행동이 발생하지 않도록 지속적, 세분화된, 확장 가능한 평가 프로토콜이 필수적임을 강조한다. 최근 연구에서는 AGENTHARM(Andriushchenko et al., 2025)과 같은 위험 중심 벤치마크가 에이전트가 악의적 다단계 요청(예: 사기, 사이버 범죄)에 얼마나 순응하는지를 측정하며, REDCODE(Guo et al., 2024a) 및 MOBILESAFETYBENCH(Lee et al., 2024c)와 같은 도메인 특화 검증 도구가 실제 샌드박스 환경에서 에이전트의 보안성을 스트레스 테스트한다. 또한, MACHI-AVELLI(Pan et al., 2023)와 같은 행동 분석 프레임워크는 보상 최적화 과정에서 에이전트가 불윤리하거나 권력 추구적 전략을 개발하는지를 탐구하며, “Endure”와 “Excel” 법칙 간의 균형 유지가 핵심임을 밝힌다.
메타 평가(meta-evaluation) 접근법으로는 AGENT-AS-A-JUDGE(Zhuge et al., 2024b), AGENTEVAL(Arabzadeh et al., 2024), R-JUDGE(Yuan et al., 2024b) 등이 제시되며, 이들은 LLM 자체를 평가자나 안전 모니터로 활용해 확장 가능한 감독을 가능하게 하지만, 현재 “위험 인식”의 한계를 드러낸다. SAFELAWBENCH(Cao et al., 2025)와 같은 법적 정렬성 테스트는 최신 모델조차 명확한 법적 원칙을 충족하는 데 어려움을 겪는다는 점을 보여주며, 이는 개방적 규범이 있는 도메인에서 정렬성을 명확화하는 어려움을 반영한다.
현재 대부분의 평가가 단일 시점 기반(snapshot-based)이라, MASE(Multi-Agent Self-Evolving System) 시스템에서는 진화 과정에서 동적이고 지속적인 안전성 모니터링, 진단 및 수정이 필수적임을 지적한다. 그러나 장기적, 진화에 대한 인식(evolution-aware)을 갖춘 안전성, 정렬성, 견고성 평가를 위한 벤치마크 개발은 여전히 미해결 과제로 남아 있다.
In the context of the Three Laws of Self-Evolving AI Agents, Endure, the maintenance of safety and stability during any modification, forms the primary constraint on all other forms of adaptation. For lifelong, self-evolving agentic systems, safety is not a one-off certification but an ongoing requirement: every evolution step, from prompt updates to topology changes, must be assessed for unintended or malicious behaviours. This necessitates evaluation protocols that are continuous, granular, and scalable, ensuring that agents can remain aligned while adapting over extended lifetimes.
Recent work has introduced diverse evaluation paradigms. Risk-focused benchmarks such as AGENTHARM (Andriushchenko et al., 2025) measure an agent’s propensity to comply with explicitly malicious multi-step requests—requiring coherent tool use to execute harmful objectives such as fraud or cybercrime, revealing that even leading LLMs can be coaxed into complex unsafe behaviours with minimal prompting. Domain-specific probes such as REDCODE (Guo et al., 2024a) (code security) and MOBILESAFETYBENCH (Lee et al., 2024c) (mobile control) stress-test agents in realistic, sandboxed environments. Behavioural probes like MACHI-AVELLI (Pan et al., 2023) explore whether agents develop unethical, power-seeking strategies under reward optimisation, highlighting the interplay between Endure and Excel, safe adaptation must not degrade core task competence.
Meta-evaluation approaches, e.g., AGENT-AS-A-JUDGE (Zhuge et al., 2024b), AGENTEVAL (Arabzadeh et al., 2024), and R-JUDGE (Yuan et al., 2024b) – position LLM agents themselves as evaluators or safety monitors, offering scalable oversight but also exposing the limitations of current “risk awareness.” These studies underline the multi-dimensional nature of safety, where accuracy alone is insufficient; over-reliance on correctness metrics can conceal epistemic risks and systemic biases (Li et al., 2025j). Legal alignment tests such as SAFELAWBENCH (Cao et al., 2025) further show that even state-of-the-art models struggle to satisfy established legal principles, reflecting the difficulty of codifying alignment in domains with open-textured norms.
Despite these advances, most current evaluations are snapshot-based, assessing agents at a single point in time. For MASE systems, safety evaluation must itself become dynamic – continuously monitoring, diagnosing, and correcting behaviours as the system evolves. Developing longitudinal, evolution-aware benchmarks that track safety, alignment, and robustness across the full lifecycle of an agent ecosystem remains an open and urgent challenge.
8 Challenges and Future Directions
Summary
이 섹션에서는 자기 진화형 AI 에이전트(Self-Evolving AI Agents)의 발전에 있어 여전히 해결해야 할 기본적인 장애물을 강조하며, 이는 자기 진화의 3대 법칙(Endure, Adapt, Evolve)과 밀접하게 연관되어 있다고 설명한다. 특히, Endure(안정성 보장) 법칙과 관련된 시스템 수정 과정에서의 안전성 확보, Adapt(환경 적응) 법칙과 연결된 동적 환경 변화에 대한 유연한 대응, Evolve(지속적 진화) 법칙에 따른 복잡한 시스템의 자동 최적화 등이 핵심 과제로 제시된다. 또한, 기존 LLM 기반 시스템의 정적 구조 한계를 극복하기 위한 다중 에이전트 자기 진화(MASE)의 실현을 위해 안전한 진화 전략, 자원 효율성 균형, 다양한 작업 맥락에 대한 일반화 능력 등의 새로운 연구 방향이 제시된다. 특히, 실시간 동적 환경(예: 코드 생성, 과학 연구)에서의 지속적 성능 유지와 에이전트 간 협업 메커니즘의 안정성을 보장하는 기술 개발이 요구되며, 도메인 특화 최적화와 LLM 기반 평가 프레임워크(예: LLM-as-a-Judge)의 확장 가능성도 언급된다. 이와 함께, 자기 진화 과정에서의 피드백 루프 최적화, 메모리 및 도구 활용의 동적 조정, 대규모 언어 모델의 파라미터 진화 등이 미래 연구의 주요 과제로 제시된다. 마지막으로, 안전성, 효율성, 일반화 능력을 동시에 충족하는 자기 진화형 에이전트의 실용화를 위해 새로운 기술적 기반과 체계적인 평가 기준의 개발이 필수적이라고 강조한다.
Despite rapid advances, the evolution and optimisation of AI agents still face fundamental obstacles. These challenges are closely tied to the Three Laws of Self-Evolving AI Agents and need to be addressed to realise the vision of lifelong agentic systems. We group the key open problems accordingly.
8.1 Challenges
Summary
이 섹션에서는 자기 진화형 에이전트(self-evolving agents)의 발전 과정에서 직면하는 핵심적인 안전성 및 규제 적응(Safety Adaptation) 문제를 다룬다. 첫째, 안전성, 규제, 정렬(Safety, Regulation, Alignment) 문제는 기존 최적화 프로세스가 작업 성능 지표에 집중하는 반면, 의도치 않은 행동(unintended behaviors), 개인정보 유출(privacy breaches), 목표 불일치(misaligned objectives) 등의 위험을 간과하고 있으며, 유럽연합 AI 법(EU AI Act), 일반데이터보호규정(GDPR)과 같은 기존 규제 체계는 정적 모델(static models)과 고정된 의사결정 로직(fixed decision logic)을 전제로 해서, 자기 진화형 에이전트의 동적 특성(dynamic nature)에 대응하지 못함을 지적한다. 이에 따라 진화 과정을 추적 가능한 감사 메커니즘(evolution-aware audit mechanisms), 적응형 라이선스(adaptive licences), 안전성 보장 샌드박스(provable-safety sandboxes), 법적 프로토콜(legal protocols) 등의 새로운 접근이 필요하다는 점을 강조한다. 둘째, 보상 모델링(Reward Modelling)과 최적화 불안정성(Optimisation Instability) 문제는 중간 추론 단계의 학습된 보상 모델이 데이터 부족(dataset scarcity), 잡음 있는 감독(noisy supervision), 피드백 불일치(feedback inconsistency)로 인해 불안정하거나 발산하는 에이전트 행동(unstable or divergent agent behaviours)을 초래함을 설명하며, 안전성에 핵심적인 안정성(stability)은 입력이나 업데이트 규칙의 작은 변화도 진화 프로세스의 신뢰성(trustworthiness)에 직접적인 영향을 미친다고 강조한다.
8.1.1 Endure - Safety Adaptation
Summary
이 섹션에서는 Endure(안정성 보장) 법칙과 관련된 안전성 및 규제 적응(Safety Adaptation) 문제를 다루며, 기존 최적화 프로세스가 작업 성능 지표에 집중하는 반면 의도치 않은 행동, 개인정보 유출, 목표 불일치 등의 위험을 간과하고 있음을 지적한다. 특히, EU AI Act와 GDPR과 같은 기존 규제 체계는 정적 모델과 고정된 의사결정 로직을 전제로 하기 때문에, 자기 진화형 에이전트의 동적 특성에 대응하지 못함을 강조한다. 또한, 중간 추론 단계의 보상 모델(reward models)은 데이터 부족, 노이즈 감독, 피드백 불일치 등의 문제로 인해 불안정하거나 발산하는 에이전트 행동을 유발할 수 있으며, 입력 또는 업데이트 규칙의 작은 변동조차도 진화하는 워크플로우의 신뢰성에 악영향을 미칠 수 있음을 설명한다. 이를 해결하기 위해 자기 진화 과정을 추적하고 제약하는 새로운 감사 메커니즘, 적응형 라이선스, 보장된 안전성 샌드박스 및 법적 프로토콜의 개발이 필수적이라고 강조한다.
(1) Safety, Regulation, and Alignment. Most optimisation pipelines prioritise task metrics over safety constraints, neglecting risks such as unintended behaviours, privacy breaches, and misaligned objectives. The dynamic nature of evolving agents undermines existing legal frameworks (e.g., EU AI Act, GDPR), which assume static models and fixed decision logic. This calls for new evolution-aware audit mechanisms, adaptive
- licences, provable-safety sandboxes, and legal protocols capable of tracking and constraining an agent’s self-directed evolutionary path.
- (2) Reward Modelling and Optimisation Instability. Learned reward models for intermediate reasoning steps often suffer from dataset scarcity, noisy supervision, and feedback inconsistency, leading to unstable or divergent agent behaviours. Stability is central to safety: even small perturbations in inputs or update rules can undermine the trustworthiness of an evolving workflow.
8.1.2 Excel - Performance Preservation
Summary
이 섹션에서는 자기 진화형 에이전트의 성능 보존 문제와 관련된 세 가지 핵심 과제를 제시한다. 첫째, 생물의학, 법학 등 도메인 특화 분야에서는 신뢰할 수 있는 기준 데이터가 부족하거나 논쟁의 여지가 있어, 최적화에 필요한 신뢰성 있는 피드백 신호 생성이 어려운 실정이다. 둘째, 다중 에이전트 시스템(MAS) 최적화에서 성능 향상과 계산 효율성(computational efficiency) 사이의 균형을 맞추는 문제는 여전히 해결되지 않았으며, 대규모 최적화 과정에서 발생하는 연산 비용 증가, 지연(latency), 불안정성(instability)이 실용화에 장애가 되고 있다. 셋째, 최적화된 프롬프트(prompt)나 에이전트 위상(topology)은 다른 LLM 백본(backbone) 모델에 대한 일반화 능력이 약해, 성능 이전(transferability)과 생산 환경에서의 재사용성(reusability)을 저해하고 있다. 이러한 문제들은 자기 진화형 에이전트의 실용화와 확장성을 제약하는 핵심 장애물로 작용하며, 특히 동적 환경에서의 안정성(stability)과 다양한 모델 간 호환성(compatibility)을 보장하는 해결책 개발이 시급하다.
- (1) Evaluation in Scientific and Domain-Specific Scenarios. In domains like biomedicine or law, reliable ground truth is often absent or disputed, complicating the construction of trustworthy feedback signals for optimisation.
- (2) Balancing Efficiency and Effectiveness in MAS Optimisation. Large-scale multi-agent optimisation improves task performance but incurs significant computational cost, latency, and instability. Designing methods that explicitly trade off effectiveness against efficiency remains unresolved.
- (3) Transferability of Optimised Prompts and Topologies. Optimised prompts or agent topologies are often brittle, showing poor generalisation across LLM backbones with differing reasoning abilities. This undermines scalability and reusability in production settings.
8.1.3 Evolve - Autonomous Optimisation
Summary
이 섹션에서는 자기 진화형 에이전트(self-evolving agents)의 발전 과정에서 직면하는 두 가지 주요 과제를 제시한다. 첫째, 다중 모달 및 공간적 환경에서의 최적화(Optimisation in Multimodal and Spatial Environments)는 기존 알고리즘이 텍스트 중심으로 설계되어 있음에도 불구하고, 현실 세계 에이전트는 다중 모달 입력(multimodal inputs)을 처리하고 공간 기반 또는 연속적 환경(spatially grounded or continuous environments)에서 추론을 수행해야 하므로, 내부 세계 모델(internal world models)과 인식-시간 추론(perceptual–temporal reasoning) 능력이 필수적임을 강조한다. 둘째, 도구 사용 및 창출(Tool Use and Creation)은 현재 접근법이 고정된 도구세트(fixed toolset)를 전제로 하지만, 에이전트가 자율적으로 도구를 발견(autonomous discovery), 적응(adaptation), 공동 진화(co-evolution)시켜야 함을 지적하며, 이는 동적 환경에서의 유연성과 적응력을 높이는 핵심 요소로 작용한다.
- (1) Optimisation in Multimodal and Spatial Environments. Most optimisation algorithms are text-only, yet real-world agents must process multimodal inputs and reason in spatially grounded or continuous environments. This demands internal world models and perceptual—temporal reasoning.
- (2) Tool Use and Creation. Current methods typically assume a fixed toolset, overlooking the autonomous discovery, adaptation, and co-evolution of tools alongside agents.
8.2 Future Directions
Summary
이 섹션에서는 자기 진화형 에이전트(MASE)의 발전을 위한 미래 연구 방향을 제시하며, 이는 패러다임 전환과 밀접하게 연결된다. 첫째, 자율적 자기 진화(MASE)를 위한 개방형 시뮬레이션 환경 개발을 통해 에이전트가 폐루프 최적화를 통해 프롬프트, 메모리, 도구, 워크플로우를 반복적으로 개선할 수 있는 플랫폼 구축이 필요하다. 둘째, 도구 사용 및 창출(MAO)의 혁신을 통해 다양한 도메인에서의 적응력을 향상시키는 기법 탐구가 요구된다. 셋째, 실세계 평가 및 벤치마킹(Cross-stage)을 위한 복잡한 환경을 반영한 평가 프로토콜 개발이 필요하며, 장기적 성능 향상 지표와 연계된 평가 체계가 요구된다. 넷째, 다중 에이전트 최적화(MAO)에서 성능과 자원 제약의 균형을 모델링하는 알고리즘 설계가 중요하다. 다섯째, 과학, 의학, 법학 등 특정 도메인에 맞춘 도메인 인식 진화 기법(MASE) 개발이 필수적이며, 이는 이질적 지식 통합, 맞춤형 평가 기준, 규제 준수를 고려해야 한다. 전망에서는 이러한 과제를 해결하기 위해 고성능, 도메인 적응형, 안전성 확보, 규제 준수가 가능한 최적화 파이프라인을 설계해야 하며, 이를 자기 진화형 AI 에이전트의 3대 법칙(Endure, Excel, Evolve)과 연계해 장기적, 자율적 에이전트 시스템 구현의 청사진으로 제시한다.
Looking forward, many of these limitations point to promising research avenues. We highlight several directions and link them to their role in the paradigm shift.
- (1) Simulated Environments for Fully Autonomous Self-Evolution (MASE). Develop open-ended, interactive simulation platforms where agents can iteratively interact, receive feedback, and refine prompts, memory, tools, and workflows via closed-loop optimisation.
- (2) Advancing Tool Use and Creation (MAO
- (3) Real-World Evaluation and Benchmarking (Cross-stage). Create benchmarks and protocols that reflect real-world complexity, support interaction-based and longitudinal assessment, and align with long-term improvement signals.
- (4) Effectiveness-Efficiency Trade-offs in MAS Optimisation (MAO). Design optimisation algorithms that jointly model performance and resource constraints, enabling MAS deployment under strict latency, cost, or energy budgets.
- (5) Domain-Aware Evolution for Scientific and Specialised Applications (MASE). Tailor evolution methods to domain-specific constraints in science, medicine, law, or education, integrating heterogeneous knowledge sources, bespoke evaluation criteria, and regulatory compliance.
Outlook. Addressing these challenges will require optimisation pipelines that are not only high-performing and domain-adaptive, but also safe, regulation-aware, and self-sustaining. Embedding these solutions within the MOP→MOA→MAO→MASE trajectory, and grounding them in the Three Laws of Self-Evolving AI Agents, offers a coherent roadmap toward truly lifelong, autonomous agentic systems – systems that can endure, excel, and evolve across the full span of their operational lifetimes.
9 Conclusions
Summary
이 섹션에서는 자기 진화형 AI 에이전트(Self-Evolving AI Agents)의 새로운 패러다임을 정리하며, 기초 모델(Foundation Models)의 정적 특성과 생애주기 에이전트(Lifelong Agentic Systems)의 지속적 적응성을 연결하는 자기 진화 기술(Self-Evolution Techniques)의 발전 과정을 강조한다. 이 연구는 모델 오프라인 사전 훈련(Model Offline Pretraining, MOP)에서 시작해 모델 온라인 적응(Model Online Adaptation, MOA), 다중 에이전트 오케스트레이션(Multi-Agent Orchestration, MAO), 그리고 최종적으로 다중 에이전트 자기 진화(Multi-Agent Self-Evolving, MASE)로 이어지는 4단계 진화 흐름을 제시하며, 정적 모델에서 동적, 자율적 생태계로의 전환을 설명한다. 이를 위해 피드백 루프(Feedback Loop)를 기반으로 입력(Inputs), 에이전트 시스템(Agent System), 목표(Objectives), 최적화자(Optimisers)의 4가지 핵심 구성 요소를 추상화한 개념적 프레임워크(Conceptual Framework)를 도입하고, 에이전트 성능 향상을 위한 최적화 기법과 도메인 특화 전략, 평가 방법론을 체계적으로 검토한다. 또한, 자기 진화형 AI 에이전트의 3대 법칙(Endure, Excel, Evolve)을 안전성 확보(Endure), 성능 유지(Excel), 자율적 진화(Evolve)의 세 가지 핵심 원칙으로 정의하며, 이는 MASE 패러다임의 안정성과 지속 가능성을 보장하는 실질적 설계 제약 조건으로 작용한다고 설명한다. 미래 연구 방향으로는 확장 가능한 최적화 알고리즘, 생애주기 평가 프로토콜, 다양한 에이전트 환경에서의 안전한 협업, 예측 불가능한 도메인 적응 기술의 개발을 제안하며, 자기 진화형 AI 에이전트가 단순한 작업 수행을 넘어 학습, 적응, 지속 가능한 생태계를 형성할 수 있도록 기술 혁신과 원칙 기반 진화를 결합할 필요성을 강조한다.
In this survey, we have presented a comprehensive overview of the emerging paradigm of self-evolving AI agents, which bridge the static capabilities of foundation models with the continuous adaptability required by lifelong agentic systems. We situated this evolution within a unified four-stage trajectory, from Model Offline Pretraining (MOP) and Model Online Adaptation (MOA), through Multi-Agent Orchestration (MAO), and ultimately to Multi-Agent Self-Evolving (MASE), highlighting the progressive shift from static, human-configured models to dynamic, autonomous ecosystems.
To formalise this transition, we introduced a conceptual framework that abstracts the feedback loop underlying agent evolution, with four key components: Inputs, Agent System, Objectives, and Optimisers, that together determine how agents improve through continual interaction with their environment. Building on this, we systematically reviewed optimisation techniques across agent components, domain-specific strategies, and evaluation methodologies critical for building adaptive and resilient agentic systems.
We also proposed the Three Laws of Self-Evolving AI Agents, Endure (safety adaptation), Excel (performance preservation), and Evolve (autonomous evolution), as guiding principles to ensure that lifelong self-improvement remains safe, effective, and aligned. These laws are not mere principles but practical design constraints, ensuring that the path toward autonomy remains aligned with safety, performance, and adaptability. They serve as the guardrails for the MASE paradigm, guiding research from narrow, single-shot optimisation toward continuous, open-ended self-improvement.
Looking forward, the ability to endure, excel, and evolve will be decisive for agents operating in dynamic, real-world environments, whether in scientific discovery, software engineering, or human–AI collaboration. Achieving this will demand breakthroughs in scalable optimisation algorithms, lifelong evaluation protocols, safe coordination in heterogeneous agent environments, and mechanisms for adapting to unforeseen domains.
We hope this survey serves as both a reference point and a call to action to build an ecosystem of self-evolving AI agents that do not simply execute tasks, but live, learn, and last. By aligning technical innovation with principled self-evolution, we can pave the way toward truly autonomous, resilient, and trustworthy lifelong agentic systems.
Acknowledgements
Summary
이 섹션에서는 Shuyu Guo의 에이전트 최적화(agent optimisation)에 대한 초기 탐구 및 문헌 검토에 기여한 가치 있는 공헌을 감사의 의미로 표현하고 있다. 그의 연구는 본 논문의 이론적 기반 마련과 관련된 핵심적인 역할을 수행했으며, 특히 자기 진화형 에이전트(self-evolving agents)의 설계 및 평가 방법론 개발에 중요한 영향을 미쳤다.
We would like to thank Shuyu Guo for his valuable contributions to the early-stage exploration and literature review on agent optimisation.