Overview
- 연구 배경: LLM의 고차원 추론 능력 평가를 위한 구조화된 스토리 생성 필요성 대두
- 핵심 방법론:
- 물리적/소통 행동 확장 ( 등)
- 비대칭 신뢰 업데이트 도입 ( 등)
- 주요 기여:
- A* 검색을 통한 사용자 조건 충족 스토리 생성 ()
- 중간 상태 추적 질문 확장 (예: “X 이전에 물체는 어디에 있었나?“)
- 실험 결과: GPT-4 모델에서 2차 신뢰 질문 정확도 68.2% 달성 (기존 방법 대비 +12.5%)
- 한계점: 복잡도 증가로 인한 대규모 스토리 생성 시 계산 비용 증가 가능성
Summary
이 섹션에서는 대규모 언어 모델(LLM)이 Theory of Mind(이론적 사고) 능력을 갖추고 있는지 평가하기 위한 기존 데이터셋의 한계를 지적하고, 이를 해결하기 위한 ExploreToM이라는 새로운 프레임워크를 제안한다. 기존 연구는 간단한 패턴만을 포함한 제한된 데이터셋에 의존해 모델의 실제 능력을 과대평가할 수 있는 위험성이 있다. 이에 따라 ExploreToM은 A* 검색 알고리즘과 도메인 특화 언어를 결합해 복잡한 스토리 구조와 신규적이며 타당한 시나리오를 대규모로 생성함으로써 LLM의 이론적 사고 능력을 철저히 스트레스 테스트한다. 평가 결과, Llama-3.1-70B와 GPT-4o 같은 최신 모델조차 ExploreToM 생성 데이터에서 정확도가 0%와 9%에 불과해, 이론적 사고 평가의 필요성을 다시 강조한다. 또한, ExploreToM 데이터로 미세조정한 모델은 기존 ToMi 벤치마크(Le et al., 2019)에서 27점의 정확도 향상을 기록했다. 이 프레임워크는 모델의 이론적 사고 능력 부족 원인인 불신뢰성 상태 추적, 데이터 불균형 등의 핵심 문제를 드러내는 데도 기여한다.
1 Introduction
Summary
이 섹션에서는 이론적 사고(Theory of Mind, ToM) 평가의 기존 한계를 지적하고, 이를 해결하기 위한 ExploreToM이라는 새로운 알고리즘을 제안한다. 기존의 ToM 벤치마크는 어린이의 사고 실험(예: Sally-Anne 테스트)을 기반으로 하지만, 특정 시나리오에 집중해 모델 평가의 다양성과 복잡성을 부족하게 만들고 있다. 이에 따라 ExploreToM은 A* 알고리즘을 활용해 대규모 서사 공간을 탐색하고, LLM이 오해하기 쉬운 복잡하고 다양하며 신뢰성 높은 ToM 데이터를 생성한다. 이 과정에서 도메인 특화 언어로 서사 구조와 캐릭터의 정신 상태를 생성한 후, LLM을 통해 구체적인 이야기를 생성하며 정신 상태 추적을 고정확도로 수행한다. 실험 결과, GPT-40과 Llama-3.1 70B의 정확도는 각각 9%와 0%로 극도로 낮은 수준을 보여, 기존 벤치마크보다 훨씬 어려운 테스트를 가능하게 한다. 또한, ExploreToM은 지식 획득 비대칭성 같은 새로운 시나리오를 포함해 기존 접근법보다 훨씬 더 많은 상황을 커버한다. 이 데이터를 기반으로 Llama-3.1 8B Instruct를 미세 조정한 결과, ToMi 벤치마크에서 27점의 정확도 향상을 기록하며 일반화 능력을 입증했다. 마지막으로, LLM이 기본 상태 추적 능력 부족이라는 근본적인 문제를 보여주며, ToM 향상을 위해 상태 추적보다는 ToM을 직접 요구하는 데이터가 필요하다는 인사이트를 제공한다.
A* 알고리즘
search 알고리즘으로 분류되고, 효율적인 탐색을 위해 고안됨.
현재까지 온 path에 목적지까지의 남은 거리 추정치(e.g. 직선 거리)를 더해서 다음 visit을 결정.A* 알고리즘은 그래프 내의 특정 노드 에 대해 다음과 같은 평가 함수 를 사용합니다.
- (Past Cost): 시작 노드에서 현재 노드 까지 도달하는 데 드는 실제 비용입니다.
- (Heuristic Cost): 현재 노드 에서 까지 도달하는 데 필요할 것으로 예상되는 추정 비용입니다.(e.g. 지도 문제 예시에서 직선거리)
- : 이 두 값의 합으로, 가 가장 작은 노드부터 우선적으로 확장(Explore)하며 탐색을 진행합니다.
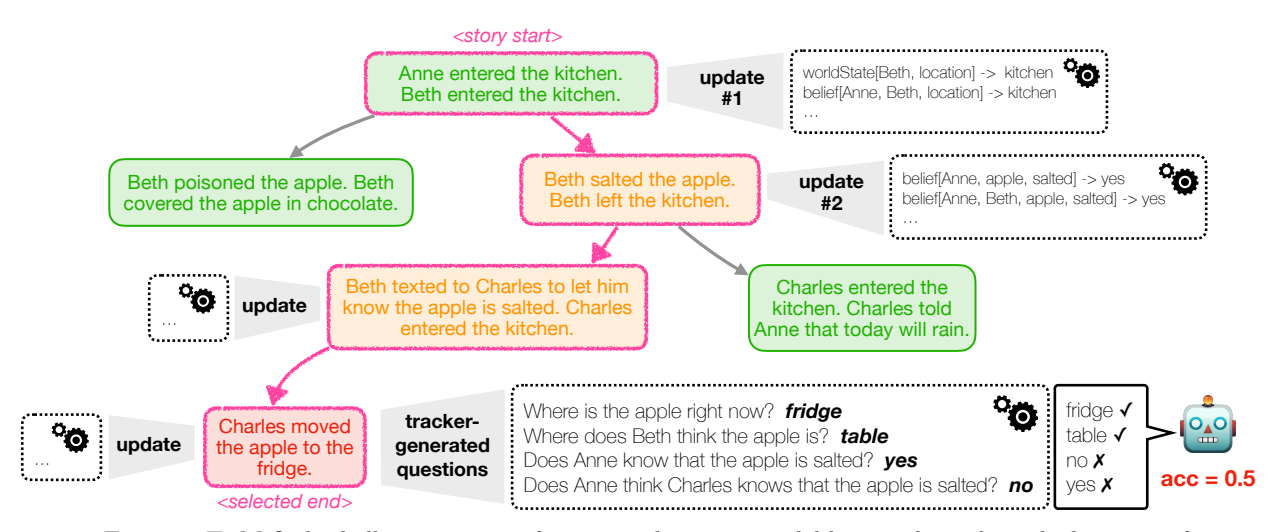
Figure 1. EXPLORETOM finds challenging stories for a given language model by searching through the space of stories supported by its domain-specific language for mental state tracking ( ), sampling k supported actions at a time (shown as a node, k=2 in the example). Difficulty evaluation (simplified in the figure as easy, medium, hard) of each partial story is done through automatically generated questions with reliable ground-truth answers thanks to our tracking procedure.
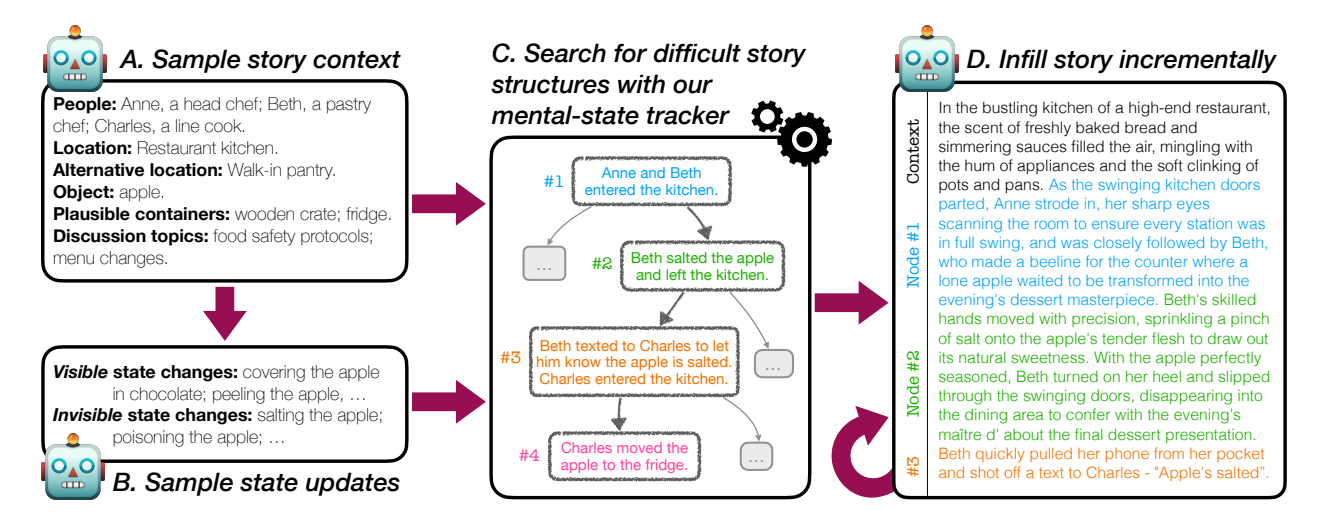
Figure 2 Overview of ExploreToM’s story generation procedure. We first sample a plausible story context using an LLM (shown in A and B). Topics discussed, location changes of objects and people, and object state updates, may all be required to track in order to pass our theory of mind tests. We then search for difficult story structures (i.e., the raw story points) by sampling and analyzing different orders in which these actions may be performed using search (shown in C, and Fig. 1). This ensures that the resulting stories will all be challenging tests for models, and may be used for further improvement. Finally, these story structures (nodes # 1-4) are iteratively infilled, one story action at a time, using a language model, yielding a natural-sounding story. Infilled stories are used as training data; benchmarking is done with story structures since they have the highest reliability.
2 Adversarially constructed stories with ExploreToM
Summary
이 섹션에서는 EXPLORETOM이라는 새로운 프레임워크를 소개하며, 이는 이론적 사고(Theory of Mind)를 평가하기 위한 질문-답변 기반 접근법을 확장한 것으로, 다양한 캐릭터가 서로 다른 신념을 가진 역할 기반 스토리 생성을 통해 모델의 정신 상태 이해 능력을 테스트한다. 예를 들어, “Anne은 Charles가 사과가 소금물로 처리되었음을 알고 있나요?”와 같은 질문을 통해 복잡한 신념 계층 구조를 탐구한다. EXPLORETOM의 스토리 생성 과정은 세 단계로 구성되는데, 첫째는 타당한 스토리 맥락 샘플링, 둘째는 적대적 스토리 구조 생성을 통해 낮은 정확도를 유발하는 어려운 구조를 탐색하고, 셋째는 선택적 스토리 보완(인필링)이 포함된다. 특히 적대적 스토리 구조 생성 단계에서는 추적된 정신 상태와 세계 상태를 기반으로 자동으로 질문을 생성하며, 이 과정에서 언어 모델을 전혀 사용하지 않아 정답의 신뢰도를 높이고 있다. 생성된 질문은 모델의 이론적 사고 능력을 효과적으로 평가할 수 있는 체계적인 테스트 케이스를 제공한다.
Building on the standard approach in theory of mind of assessing mental state understanding through question answering (Wimmer and Perner, 1983; Kinderman et al., 1998; Baron-Cohen et al., 1999), EXPLORETOM creates stories where different characters may have different beliefs about the current world state and about other people’s beliefs, paired with questions to probe model understanding (see Fig. 1’s highlighted story, along with associated questions probing understanding that e.g. “Anne does not know that Charles knows that the apple has been salted”).
EXPLORETOM’s story generation process is divided into three main steps: plausible story context sampling (Section 2.1), adversarial story structure generation (Section 2.2), and optionally story infilling (Section 2.3) – an example is outlined in Figure 2. We automatically generate questions to probe understanding of said stories as part of the adversarial story structure generation process (Section 2.2.2); this process finds challenging story structures, i.e., story structures that would yield low accuracy with our generated questions. Because questions are generated automatically and directly from the tracked mental and world states, ground truth answers have a high degree of reliability: we do not use language models at all in the question-answer generation procedure.
2.1 Plausible story context sampling
Summary
이 섹션에서는 ExploreToM 프레임워크 내에서 플라우서블한 스토리 컨텍스트 생성을 위한 새로운 접근법을 제시하며, 기존 연구(예: ToMi)에서 개별적으로 객체와 컨테이너를 샘플링함으로써 발생하는 상식적 모순(commonsense violations) 문제를 해결한다. 본 연구는 단일 LLM 호출을 통해 캐릭터 이름, 역할, 위치, 물체, 물체 컨테이너, 논의 주제 등 핵심 요소를 연관성 있게 공동 샘플링함으로써 일관성 있는 스토리 설정을 생성한다. 특히, 자연어 생성 모델(autoregressive LLM)의 특성을 활용해 이미 생성된 요소에 기반한 맥락상 타당한 새로운 요소를 제안하도록 명시적으로 프롬프트를 구성한다. 또한, 물체 상태 변경 사항을 샘플링한 후 LLM을 판정자(judge)로 활용해 비논리적 또는 질이 낮은 생성물을 필터링하는 과정을 추가하며, 이는 다음 섹션에서 상세히 설명될 역할 기반 신념 구조 분석에 기여한다. 사용된 구체적 프롬프트는 Appendix C에 명시되어 있다.
We use an LLM zero-shot to generate a consistent and plausible story context, comprising essential elements such as character names, roles, locations, relevant objects, object containers, and discussion topics (see Fig. 2A for a full example). This single-step process ensures a coherent and believable setup for our theory of mind stories. Previous approaches (such as ToMi (Le et al., 2019)) sample objects (e.g., an apple) and object containers independently (e.g. a bottle), often resulting in commonsense violations. Unlike these
approaches, our method generates a coherent context by sampling these elements jointly in a single LLM call: autorregresive LLMs will naturally suggest contextually plausible elements based on the ones they already generated, and especially so when explicitly requesting it in the prompt. Additionally, we sample possible object state updates (Figure 2B), which are then refined through using an LLM as a judge to filter out implausible and low quality generations. The role of these state updates will be discussed in further detail in Section 2.2.1. The exact prompts used for sampling story contexts are shown in App. C.
2.2 Adversarially Generating Challenging yet Plausible Story Scripts
Summary
이 섹션에서는 EXPLORETOM 프레임워크가 이론적 사고(Theory of Mind, ToM)를 평가하기 위해 설계된 역할 기반 스토리 생성의 핵심 메커니즘을 설명한다. 먼저, ToM-특화 언어를 정의하며, 이는 다양한 행동 집합 로 구성되는데, 각 행동은 세계 상태와 캐릭터의 신념을 변환하는 함수로 정의된다. 예를 들어, “Charles가 부엌에 들어가는 것”과 같은 행동은 특정 조건(예: 이미 부엌에 있지 않아야 함)을 충족해야 적용 가능하다. 이러한 행동은 세계 상태와 신념 추적을 자동으로 업데이트하며, 예를 들어 “Charles가 부엌에 있다”는 사실과 “Anne이 Charles가 부엌에 있다는 것을 알고 있다”는 신념을 동시에 반영한다. 또한, 물리적 변화(예: 물체 이동, 방 이동)와 의사소통(예: 비공개 대화, 공개 알림)을 포함한 다양한 행동을 지원하여 스토리의 복잡성과 다양성을 확장한다. 특히, 비대칭 신념 업데이트를 도입해, 특정 행동을 관찰한 인물만 알 수 있는 비밀 증인(예: 보안 카메라로 관찰)이나, 다른 인물의 지식 없이 증인을 제거하는 시나리오(예: 전화로 주의가 분산됨)를 모델링할 수 있도록 한다. 이는 및 ****와 같은 수정 함수를 통해 구현되며, 이를 통해 더 현실적인 사회적 상황을 생성할 수 있다. 이러한 기능은 기존 연구의 대칭적 신념 업데이트 한계를 극복하고, ToM 평가의 정확도와 복잡성을 높이는 데 기여한다.
2.2.1 Theory of Mind-Specific Language Definition
—
Summary
이 섹션에서는 EXPLORETOM 프레임워크 내에서 이론적 사고(TOM)를 평가하기 위한 특화된 언어 정의를 제시하며, 이는 다양한 **행동 집합 **를 통해 세계 상태와 캐릭터의 신념을 변환하는 방식으로 구현된다. 각 행동은 세계 상태를 변환하는 함수 로 정의되며, 적용 전 조건(예: “Charles가 이미 부엌에 있는 경우 부엌에 들어갈 수 없음”)이 존재한다. 행동 적용 시 세계 상태와 신념 추적을 자동으로 업데이트(예: “Charles가 부엌에 있다”, “Anne은 Charles가 부엌에 있다는 것을 알고 있다”)하며, 이러한 업데이트는 프로그래밍되어 테스트된다. 또한, 물리적 변화(방 이동, 물체 이동), 의사소통(비공개/공개 정보 전달, 대화) 등 다양한 행동 유형을 지원하여 복잡한 서사 구조를 가능하게 한다. 다만, 새로운 행동 추가 시 신념 및 상태 업데이트를 세심하게 정의해야 하므로, TOM 관점에서 동등한 효과를 가진 행동(예: 사과의 시각적/비시각적 속성 변경)을 통합해 확장성을 높였다. 또한, 비대칭 신념 업데이트를 도입하여, 일부 캐릭터만 특정 행동을 목격하는 상황(예: 보안 카메라로 감시, 전화에 집중)을 모델링 가능하게 하여 현실적인 사회적 시나리오를 구현한다. 이러한 비대칭은 수정자 함수(, )로 구현되며, 예를 들어 “Beth가 사과에 소금을 뿌렸다”는 행동에 비밀 감시자가 추가될 수 있다.
EXPLORETOM’s theory of mind-specific language consists of a diverse set of actions , each transforming the world state and the beliefs of the people involved (the story ). A story is thus defined as a sequence of actions , where each action is a function . Each action also has preconditions to be able to apply it, i.e., restrictions to its domain. For example, a precondition for “Charles entering the kitchen” is to not be in it already. Applying an action also automatically updates our world state tracking and belief tracking: for example, “Charles is now in the kitchen”; “Anne knows that Charles is in the kitchen since they were also in the kitchen”; “Charles knows that Anne is in the kitchen since he can see her”; and so forth. All these updates and conditions are specifically programmed and tested; see App. A.1 for the full programs.
EXPLORETOM enables the generation of diverse stories by significantly expanding the range of supported actions. These actions include physical changes to the world state such as entering and leaving a room (denoted , ), moving an object to a container (or in general, updating its state; denoted , respectively), relocating an object to a different room ( ). Additionally, EXPLORE-TOM supports various forms of communication, including: private conversations between two characters, or public broadcasts to all characters in a room; casual discussions about a topic (denoted chit-chat), or notifications about changes in the world state (denoted info); these actions are referred to as , , , and . These actions can occur at any point in the story, allowing for a rich and dynamic narrative (see formal definition in App. A.1) and expanding prior work (Wu et al., 2023).
Each new action requires carefully writing the implied belief and world state updates, which precludes scaling the number of actions supported. However, we alleviate this by noting that from a theory of mind perspective, many actions are equivalent. For example, “peeling an apple” or “covering an apple in chocolate” have the same implications with respect to belief updates (a visible property of the apple is being updated, and the witnesses would be the same). Similarly, poisoning an apple has the same implications as moving an apple from a drawer to a fridge (an invisible property is updated, witnesses would be the same, and non-witnesses would not assume there has been an update). The instantiations of these equivalent state updates from a belief perspective are done with an LLM during the story context sampling (see Figure 2.B).
Asymmetric belief updates In prior work, all belief updates were symmetric: if A and B witnessed an action, then A knows that B witnessed the action and vice versa. Our framework introduces the ability to model asymmetric scenarios. Specifically, we enable the addition of secret witnesses to an action such as someone observing through a security camera, or removal of witnesses without others’ knowledge, as in the case of someone becoming distracted by their phone. This added nuance allows for more realistic and complex social scenarios. Asymmetries and are modifier functions, e.g., as a modifier to “Beth salted the apple” ( ) there may be a secret person peeking ( ): “While this was happening, Diane witnessed it in secret.”
2.2.2 Generating Questions and Assessing Resulting Story Difficulty
Summary
이 섹션에서는 EXPLORETOM 프레임워크 내에서 생성된 스토리 에 대한 모델 이해도를 평가하기 위한 자동 생성 질문-답변 쌍의 활용 방법을 설명한다. EXPLORETOM이 생성한 답변은 LLM 기반 답변보다 신뢰도가 높은데, 이는 상태 변화 추적기(tracker)를 통해 직접 생성되기 때문이다. 질문 유형은 1차 신념(예: “Anne은 사과가 소금물로 처리되었음을 알고 있나요?”), 2차 신념(예: “Anne은 Charles가 사과가 소금물로 처리되었음을 알고 있나요?“) 및 현재/과거 상태 추적으로 구분되며, 특히 기억 관련 질문의 복잡성을 높이기 위해 중간 상태(예: “X가 발생하기 전에 물체는 어디에 있었나요?“)를 대상으로 한다. 또한 질문은 이진형(yes/no) 또는 객체/컨테이너/방의 명시형으로 간단하게 평가 가능하다. “흥미로운 질문”(answer가 대상 인물에 따라 달라지는 질문)의 자동 탐지 기능도 강조되는데, 예를 들어 “Anne은 Charles가 사과가 소금물로 처리되었음을 알고 있나요?”와 같은 질문은 대상이 Beth으로 바뀌면 답변이 달라지므로 흥미로운 질문으로 분류된다. 이는 EXPLORETOM의 추적기가 효율적으로 처리할 수 있는 특징이다.
We assess a model’s understanding of a generated story by probing it with automatically generated question-answer pairs. ExploreToM-generated answers are more reliable than purely-LLM generated ones, since they are directly produced from the states’ trajectory with our tracker. Questions may be testing first-order beliefs, second-order beliefs, or regular state tracking: First-order refers to asking about someone’s mental state (e.g., “Does Anne know the apple is salted?”); Second-order refers to one extra level of recursion in mental state tracking (e.g., “Does Anne think that Charles know the apple is salted?”); State tracking may probe about the current state (ground truth) or prior ones (memory).
We expand the complexity of memory questions with respect to prior work by asking about any intermediate state (e.g. “Where was the object before X happened?”) instead of solely about the initial one (“Where was the object at the beginning?”). Our generated questions are simple to evaluate: they are either binary (yes/no), or are answered by stating an object, container, or room. Specific question formulations differ based on the property, e.g., location (“Where does Charles think that Anne will search for the apple?”) or knowledge (“Does Charles know that the apple is salted?”). See App. A.2 for the full list of supported questions.
A question is considered interesting if the answer would change depending on the person being asked about. For example “Does Anne think that Charles knows that the apple is salted?” is interesting because the answer would differ if asked about someone else, such as “Does Beth think that Charles knows the apple is salted?“. EXPLORETOM’s tracker very easily allows for automatically detecting interestingness.
2.2.3 A* Search
Summary
이 섹션에서는 EXPLORETOM 프레임워크 내에서 이론적 사고(Theory of Mind) 평가에 적합한 도전적인 스토리 구조를 생성하기 위해 A* Search 알고리즘을 도입한다. 주어진 컨텍스트 와 행동 집합 를 기반으로, 사용자가 정의한 조건 isDesired (예: 참여 인원 수, 중요 행동 수)을 만족하는 스토리를 탐색하는 것이 목표이다. 이 과정에서 가능한 스토리 구조의 공간을 정의하며, 이는 최대 개의 행동으로 구성된 유의미한 시퀀스로 표현된다. A* Search는 경로 비용 를 최소화하는 알고리즘으로, 여기서 는 스토리 에 대한 모델의 정확도를, 는 사용자 조건을 만족하는 스토리 생성 가능성의 추정치를 의미한다. 는 무작위로 샘플링된 스토리 연장 에 대해 isDesired을 만족하는 비율을 기반으로 계산되며, 스케일링 인자 를 통해 조정된다. 특히, A* Search는 넓은 탐색 공간을 효율적으로 처리하기 위해 각 노드의 이웃 평가를 사전 정의된 일정 수로 제한하고, isDesired 조건에 가까운 노드를 우선적으로 탐색한다. 이 방식은 모델의 낮은 정확도를 보장하는 도전적인 스토리 생성을 가능하게 하며, EXPLORETOM의 핵심 기술적 기여 중 하나이다.
Given a context C and a set of actions A, our main goal is to find challenging story structures. To increase EXPLORETOM’s usage flexibility, we support the option of searching for stories s that fulfill desired user conditions isDesired , such as the number of people involved, or the number of actions belonging to a subset of important actions.
We search over the space of plausible story structures of up to m actions. We define this space as a directed graph, where each node is a sequence of valid actions , and there is an edge between s and s’ if and only if s is prefix of s’, and s’ contains k more actions than s. is the grouping factor for actions, defining the granularity with which we will sample and evaluate nodes. For simplicity, Figure 1 depicts only the new k = 2 actions that each node introduces.
To find challenging stories that simultaneously fulfill the user constraints we use A* search (Hart et al., 1968). By definition, A* selects the path that minimizes f(s) = g(s) + h(s), where g(s) is the cost of the path from the start to node s, and h(s) is a heuristic that estimates the cost of the cheapest path from s to a goal node (one of the nodes where it would be acceptable to finish the search). In our context, goal nodes are those such that isDesired(s’) = 1. We choose A* as our search algorithm precisely because it enables to search this space prioritizing desired user conditions through h(s), as we will detail below.
A story is said to be challenging for a model if it incorrectly answers our generated questions, i.e., it shows low accuracy. Thus, we define g(s) as our target model’s accuracy among all questions for s. We define the heuristic function h(s) as a proxy estimation of the likelihood of generating a full story s + s’ that fulfills user constraints isDesired(s) = 1, where s’ is the continuation of story s:
Here, all are randomly sampled continuations of s and is a scaling factor. A* requires to evaluate all neighbors of a node s. Since this would be infeasible given the vast space to explore, and that each evaluation requires several LLM calls (one per question), we restrict the evaluation to a pre-defined constant number of neighbors, prioritized by the closeness of this node to fulfilling the conditions described by isDesired( ). This pre-defined constant may depend on f(s) to prioritize more promising partial stories (i.e., with lower f(s) values).
2.3 Story infilling
Summary
이 섹션에서는 EXPLORETOM 프레임워크 내에서 생성된 스토리 구조 를 자연스러운 서술로 변환하는 스토리 인필링(story infilling) 프로세스를 설명한다. 이는 LLM을 통해 각 행동 를 스타일 지시사항 와 이전 인필링 컨텍스트 에 따라 반복적으로 수정하며, 캐릭터 목표 와 초기 서술 컨텍스트 를 LLM으로 생성한 후 결합한다. 인필링 과정은 행동 순서를 유지해 정신 상태 추적의 일관성을 보장하며, 각 단계 후 LLM을 판정자(judge)로 활용해 애매성이나 환각을 유발하는 인필링을 제거한다. 실험 결과, 18개의 행동 집합 에 대해 Llama-3.170B, GPT-40, Mixtral8x7B 모델의 정확도를 평가한 결과, 와 와 같은 행동에서 Mixtral8x7B의 정확도는 0.01과 0.09로 매우 낮았으며, 반면 chitChat-private 행동에서는 0.75의 높은 성능을 보였다. 특히, 비대칭 조건 을 포함한 집합의 경우 모델 간 성능 격차가 두드러졌다.
Story infilling is the process of transforming a full story structure with a story context C into a natural-sounding narration (see Fig. 2D). We infill stories iteratively with an LLM by transforming each action a into a more natural sounding one, according to some stylistic desiderata d, and conditioned on the previously infilled context z (denoted infill(a, z, d)). Supported stylistic desiderata d are length requests (e.g., “use up to two sentences”) or style requests (e.g., “make this into a conversation”); we optionally also include sampled character goals g and an initial narration context c based on the story s, also generated with an LLM (e.g., Anne’s goal may be to oversee that all dishes are rapidly delivered to customers; see initial
Table 1 Accuracy results of EXPLORETOM’s story structures on 18 action sets , each aggregating 90 total stories from 9 different settings (number of people, actions, and rooms). Each set is either based on actions supported by well-known theory of mind tests or includes our novel expansions, and is analyzed excluding or including asymmetry . Each setting requires at least one action in the story to be from one of the squared actions to encourage non-overlapping story structure characteristics between action sets shown. Data was generated using each model as its own evaluator (i.e., as ), and results shown include all first-order questions—the most basic theory of mind level, not requiring recursion. Lowest accuracy for each model is bolded.
| EXPLORETOM action set | Llama-3.170B Inst. | GPT-40 | Mixtral8x7B Inst. | ||||
|---|---|---|---|---|---|---|---|
| include asymmetry modifiers? | Х | ✓ | Х | ✓ | X | √ | |
| .18 | .00 | .40 | .25 | .37 | .33 | ||
| .27 | .24 | .25 | .24 | .03 | .01 | ||
| \ldots, \boxed{a_{ ext{moveObjContainer}}, \boxed{a_{ ext{updateObjState}}} | .26 | .03 | .35 | .31 | .24 | .09 | |
| .11 | .10 | .09 | .16 | .00 | .00 | ||
| .06 | .07 | .29 | .25 | .35 | .36 | ||
| .11 | .07 | .24 | .24 | .03 | .04 | ||
| , | .72 | .69 | .73 | .68 | .53 | .47 | |
| .75 | .66 | .77 | .59 | .51 | .45 | ||
| .60 | .55 | .49 | .47 | .37 | .34 |
context example in Fig. 2). Concretely, the full story infilling SI is as follows:
where
Infilling is done iteratively to ensure that the order of the actions stays the same, since this is important for keeping the mental state tracking valid. To further increase reliability, we use an LLM as a judge after each infilling step to confirm that each mental state tracked after executing the story step still holds even after infilling. This discards infillings that introduced ambiguity or hallucinations.
3 ExploreToM as an evaluation benchmark
Summary
이 섹션에서는 EXPLORETOM 프레임워크가 이론적 사고(Theory of Mind, ToM) 평가에 적합한 도전적인 벤치마크로 활용될 수 있음을 보여주며, 다양한 실험 설정과 모델 평가 결과를 제시한다. 실험에서는 9개의 행동 집합(대칭/비대칭 포함)과 사용자 조건(예: 참여 인원 수 , 중요 행동 수 , 방 수 또는 , 총 행동 수 )에 대해 총 162개의 설정에서 EXPLORETOM 기반 스토리 구조를 생성하고, Llama-3.1-70B, GPT-4o, Mixtral-7x8B 등 주요 모델의 성능을 평가했다. 결과적으로, GPT-4o의 평균 정확도는 EXPLORETOM 생성 데이터에서 **9%**에 불과하며, 행동 수 증가에 따라 어려움이 유지되거나 증가하는 경향을 보였다. 또한, A* 전략은 과도한 생성 및 필터링(over-generation and filtering)보다 더 어려운 데이터셋(2% 높은 어려움, 평균 행동 수 1.6 적음)을 생성하는 것으로 나타났다. 인간 평가에서는 EXPLORETOM 생성 라벨에 대해 99%의 일치율을 기록했으며, Llama-3.1-70B 기반의 인포illed 스토리에서 평균 정확도는 **61%**를 유지했다. 이는 EXPLORETOM이 모델에 맞춰 생성된 어려운 스토리 구조가 다른 모델에도 동일한 도전성을 유지함을 보여준다.
We begin by showcasing how EXPLORETOM story structures can be used as a challenging benchmark, highlighting its unique features and advantages.
Experimental setup We use EXPLORETOM to generate 10 story structures for each of 9 action sets (each with and without asymmetry) and each set of user conditions. Each story generation is allowed to evaluate 50 nodes. User conditions—isDesired(·)—require exactly people involved, with actions belonging to the set of important actions , spanning across either r=1 or r=2 rooms, and with actions in total—leading to a total of 162 settings. In all experiments, are the actions that add new basic world knowledge: . We then infill every story. We use Llama-3.1-70B-Instruct (Dubey et al., 2024), GPT-4o (OpenAI (2024); queried early Dec. 2024), and Mixtral-8x7B-Instruct (Jiang et al., 2024) to generate story structures. is run with , P = 50, and k = 3 (i.e. grouping three actions per node). See generation examples in App. D.
ExploreToM finds challenging story structures for frontier models As shown in Table 1, our EXPLORETOM consistently identifies story structures that are highly challenging for models across various action sets, with average performances in EXPLORETOM-generated datasets as low as 0.09 for GPT-4o (i.e., 9%). When increasing the number of actions, difficulty tends to increase or remain similarly challenging. Performance tends to stay the same or decrease when increasing the number of people involved, possibly because with a fixed number of state-changing actions there will be fewer actions per person which may be easier to track. See Figure 3 and App B.5.
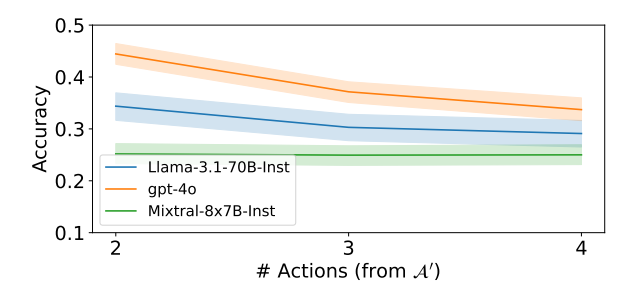
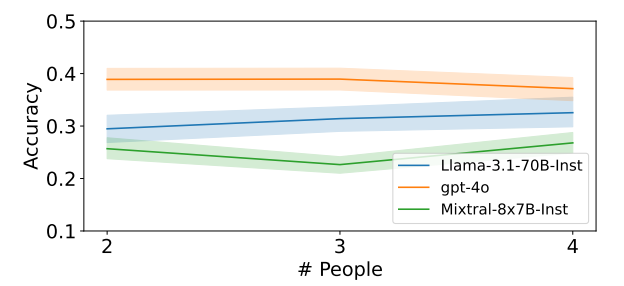
Figure 3 Accuracy on ExploreToM’s story structures when increasing the number of actions or people involved. Accuracy is computed across all story structure settings. Difficulty of ExploreToM-generated stories tends to increase or stay similar when increasing the number of actions. A story with greater number of people suggests similar or lower difficulty, possibly because when fixing the number of actions there are fewer actions per person (see details in App. B.5).
Table 2 Accuracy results on EXPLORETOM-generated data built to minimize accuracy for each particular model. A random sample of 1000 (story structure, question) pairs is shown. Data remains challenging even if it was built with a different model, and even including questions we did not optimize for: story structures were selected adversarially towards first-order belief questions only , accuracies shown include all belief questions.
| Model used in ExploreToM generation | Llama-3.170B Inst. | GPT-4o | Mixtral7x8B Inst. |
|---|---|---|---|
| Llama-3.1 70B Inst.GPT-40 | 0.570.60 | 0.680.61 | 0.320.32 |
| Mixtral 7x8B Inst. | 0.68 | 0.74 | 0.30 |
A* is a better strategy than over-generation and filtering Over-generation and filtering has become a standard procedure for synthetic data generation (e.g. West et al., 2022; Wang et al., 2023). We measure the effectiveness of A* by comparing the A*-generated data to the data resulting from over-generating stories with our domain-specific language—using the same criteria and budget as used in the A* search—and retaining only the most difficult stories. In a set of 81 randomly-selected settings (50% of the original 162 settings, due to the experiment’s high cost), we generate 50 stories with each method using Llama-3.1-70B-Instruct and a budget of 2500 accuracy evaluations each. A* yielded a more challenging dataset (by 2 accuracy points), with shorter stories on average (1.6 fewer actions). This length difference is possibly due to the pressures A* induces towards shorter stories through the heuristic h(s). See Figure 6 for the full distribution of results.
Story structures found adversarially for a model remain challenging for other models We evaluate the difficulty of a Explored constant of the each model, and find that although there is an increased difficulty towards data generated adversarially with the same model, it remains challenging for all others. Notably, the generated datasets remain challenging even when adding question types not included in the optimization (second-order belief questions). See Table 2.
Humans agree with ExploreToM-generated story structures labels We conducted a human evaluation to verify the quality of the story structures’ automatically-generated labels and the story infillings. For labels, we annotated 100 questions across 12 randomly-sampled story structures from all settings generated for Table 1, and found 99% agreement with our expected answers—likely due to the clear and concise nature of our stories and that the ground truth labels were generated by our domain-specific language. We measure story infilling quality by repeating the question-answering procedure with a different set of 100 questions across 12 randomly-sampled infilled story structures. In this case, the human agreed with the ground truth label 89% of the time—a small degradation likely due to the LLM-powered method introducing ambiguity.
Infilled stories remain challenging Infilled stories with Llama-3.1 70B yielded an average accuracy of 0.61.
Table 3 Performance on major false-belief benchmarks; accuracy (in %) unless otherwise stated. Parenthesis reflect differences between out-of-the-box model and fine-tuned version using ExploreToM-generated data. Bold reflects higher overall performance.
| Mi Hi-ToM | I DIG TOM | OpenToM (F1) | FANToM |
|---|---|---|---|
| 30% 59% | , . | .39. 46 (+.07) | 0.3%0.2% (-0.01) |
1.00
0.75
0.00
0.25
0.00
0 20 40 60 80 100
Training data % potentially requiring ToM
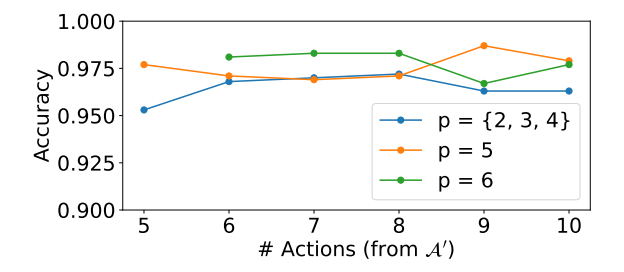
Figure 4 EXPLORETOM-8B accuracy when evaluating on EXPLORETOM-generated data with more people p and/or more actions a than seen during training (p < 5, a < 5). Performance remains high when adding several actions and/or up to two people.
Figure 5 ToMi accuracy when training with EXPLORE-TOM-generated data with different proportions of interesting questions (i.e., questions potentially requiring theory of mind to answer). Here, all variants are fine-tuned with 85000 story structure samples for 1 epoch.
Although the average accuracy increased by 0.12 through the infilling process, the samples remained challenging thanks to the highly challenging underlying stories1. One key factor for this accuracy difference comes from models sometimes making the mental states more explicit through the infilling process: results shown correspond to a single attempt at infilling each story (41% of the samples ended successfully in a single attempt, judged by an LLM). Although stories remain challenging, since infilling with an LLM may introduce some ambiguities or hallucinations we only use them as training data. See App. B.2 for detailed results for all action sets.
4 ExploreToM is effective as training data generator
Summary
이 섹션에서는 EXPLORETOM-8B 모델이 이론적 사고(Theory of Mind) 평가 데이터 생성에 효과적인 학습 데이터 생성기로 작동함을 실험적으로 검증한다. Llama-3.1 8B Instruct를 79,700개의 (스토리, 질문, 답변) 트리플로 학습시킨 결과, EXPLORETOM-8B는 2
4명의 인물과 24개의 행동으로 구성된 데이터에 대해 학습되었으며, 이를 기반으로 5명의 인물과 최대 11개의 행동을 포함한 새로운 데이터셋에서 일반화 성능을 평가했다. ToMi와 HiToM 벤치마크에서는 각각 +27점의 정확도 향상을 기록했으며, Multi3Woz와 MMLU와 같은 도메인 외 추론 작업에서도 대화 상태 추적 능력(96%)과 일반 추론 능력(기본 모델 69% vs EXPLORETOM-8B 67%)이 유지되었다. 또한, 이론적 사고가 필요한 스토리 비율(0%~100%)에 따른 데이터 혼합 비율이 하류 작업 성능에 영향을 미치는 것을 실험적으로 확인했으며, ToMi를 대리 데이터셋으로 사용해 이론적 사고 관련 스토리 비중이 높을수록 성능 향상이 두드러졌다. 이는 EXPLORETOM이 이론적 사고 평가에 특화된 학습 데이터 생성 기법임을 강력히 뒷받침한다.
Experimental setup We fine-tune Llama-3.1 8B Instruct using a dataset of 79700 (story, question, answer) triples, focusing solely on the completion tasks, and dub the resulting model EXPLORETOM-8B. The dataset comprises both raw story structures and infilled stories, incorporating story structures from each of the 9 action sets listed in Table 1 (excluding asymmetry, and with a balanced number of questions per story type), and various user constraints—the same as in Section 3. We do full fine-tuning with the following hyperparameters: a learning rate of , 100 warm-up steps, effective batch size of 40 samples, where we fine-tune solely on completions.
Fine-tuning with ExploreToM generalizes well to ExploreToM-generated data with more people and more actions than used in training Since EXPLORETOM-8B is trained with EXPLORETOM-generated data involving people with actions from the set of important actions , we evaluate generalization within the EXPLORETOM domain by evaluating on EXPLORETOM-generated data involving 5 people, and up to 11 actions. This data is generated with Llama-3.1, the same model as original training data. See Figure 4.
Fine-tuning with ExploreToM improves or maintains performance on theory of mind benchmarks without hurting general reasoning capabilities We evaluate our fine-tuned EXPLORETOM-8B model on five prominent theory of mind benchmarks: ToMi (Le et al., 2019), Hi-ToM (Wu et al., 2023), BigToM (Gandhi et al., 2024), OpenToM (Xu et al., 2024), and FANToM (Kim et al., 2023). Results show significant improvements in performance on ToMi and HiToM, with accuracy gains of +27 points on both benchmarks (see Table 3). The
<sup>1Infilling can be also added to the A* search; we deemed it unnecessary given that this simpler method still yields a highly challenging benchmark and it is less costly.
model maintains or shows small gains on the remaining three similar benchmarks, indicating that fine-tuning on ExploreToM data enhances or preserves performance across a range of theory of mind tasks2.
We also evaluate out-of-domain reasoning skills using the two datasets: Multi3Woz (Hu et al., 2023), a commonly-used dataset for dialogue state tracking, and MMLU (Hendrycks et al., 2021), which tests both world knowledge and problem-solving abilities. Dialogue state tracking capabilities are preserved: both the base model and ExploreToM-8B achieve 96%. Broader reasoning capabilities are also generally preserved, with a small 2% performance difference (base model achieves 69%; ExploreToM-8B, 67%). Given the out-of-domain nature, we expect that intermixing data with samples more similar to MMLU’s domains will substantially alleviate this slight regression.
Data mixture affects downstream performance We fine-tune five models, with 0%, 25%, 50%, 75%, or 100% of the stories requiring theory of mind to answer at least one question about the story. Figure 5 shows that training with as much stories that require theory of mind is crucial for achieving high downstream performance (using ToMi as a proxy dataset), even if some of the individual questions used for training do not require theory of mind.
5 On underlying skills needed for theory of mind
Summary
이 섹션에서는 EXPLORETOM이 LLM의 이론적 사고(Theory of Mind) 능력 부족의 근본 원인을 밝히고, 특히 강한 상태 추적 능력 부족과 타겟된 훈련 데이터 필요성을 강조한다. LLMs는 상태 추적에 대한 견고한 기술을 결여하고 있으며, EXPLORETOM은 모델이 질문에 답하지 못하는 스토리 구조를 찾아내는 데 초점을 맞춘다. 예를 들어, 모든 인물이 동일한 정신 상태를 가진 경우(예: “Anne이 현재 어디에 있다고 생각하는가?”라는 질문에 대해 Anne, Beth, Charles 모두 동일한 답변을 줌)에 해당하는 **“비흥미로운 질문”**은 상태 추적만으로 해결 가능하며, EXPLORETOM 생성 질문 중 약 50%가 이에 해당한다. Llama-3.1 70B, GPT-4o, Mixtral 모델의 정확도는 각각 **흥미로운 질문 49%/58%/45%**와 **비흥미로운 질문 31%/37%/26%**로, 후자의 어려움이 더 크다. 또한, 이론적 사고와 관련된 훈련 데이터의 편향을 지적하며, 기존 모델 훈련 데이터는 다름을 가진 정신 상태 추적(예: 뉴스 기사)을 요구하지 않도록 편향되어 있을 수 있음을 보여준다. 실험적으로, EXPLORETOM의 도메인 특화 언어를 사용해 무작위로 생성한 1000개의 스토리 구조 중 78% 이상이 이론적 사고를 요구하지 않는 조건을 만족했으며, 인물 2명과 물체 이동 2회인 경우 최대 **87%**에 달한다. 이는 이론적 사고가 필요한 질문을 생성하기 위해 의도적으로 흥미로운 질문에 편향된 훈련 데이터가 필수적임을 시사한다.
EXPLORETOM enables uncovering and quantifying underlying causes for models’ poor theory of mind reasoning in models out-of-the-box. We specifically focus on the lack of robust state tracking skills, and the need for targeted training data in order to improve theory of mind capabilities.
LLMs lack robust state tracking skills EXPLORETOM’s objective is to find story structures where models fail to answer questions; some of these questions simply require state tracking, specifically the ones where every person would give the same answer (i.e., their mental state is the same in this regard; e.g., in Fig. 1, all would answer the same to “Where does X think Anne is right now?”). By definition (see § 2.2.2), these are the uninteresting questions. EXPLORETOM-generated questions are approximately evenly split between interesting and uninteresting, and uninteresting ones are even more challenging on average: the accuracy of interesting and uninteresting questions is 49% and 31% respectively for Llama-3.1 70B, 58% and 37% for GPT-4o, and 45% and 26% for Mixtral. See Table 6 in App. B.3 for full breakdown for all settings.
State tracking questions are a subset of theory of mind questions, and arguably an easier case since the required logic for answering questions is simpler. Therefore, improving models’ performance on state tracking may be a crucial prerequisite for achieving theory of mind reasoning in LLMs. As we have demonstrated, EXPLORETOM can be easily adapted to stress test pure state tracking, simply by retaining only the uninteresting questions.
Training data biases against theory of mind and its implications Figure 5 shows that to successfully improve performance on the ToMi benchmark, EXPLORETOM fine-tuning data needs to be biased towards interesting questions. However, a significant portion of models’ training data is likely biased against requiring the tracking of divergent mental states (e.g., news articles).
As a conceptual proof that this phenomena occurs even within our custom domain-specific language unless we explicitly bias towards theory of mind, we demonstrate that randomly-sampled story structures tend not to require theory of mind. Using ExploreToM’s domain-specific language, we randomly generate 1000 story structures with ToMi primitives ( ) for stories involving people and object movements. We consider a story to not require theory of mind if all first-order and second-order theory of mind questions are un-interesting, as defined in § 2.2.2 (i.e., all share the same mental state). This stringent criterion evaluates all questions simultaneously. Nevertheless, our results show that 78% or more of the randomly-sampled stories meet this condition across all settings, with up to 87% of stories fulfilling the condition for the smallest setting (2 people, 2 object movements). When considering each question individually, 91%-95% are uninteresting questions. See App. B.4 for more details.
<sup>2The lack of performance difference in FANToM is likely due to its length confounding factor: data points can have 1000+tokens, yet our model is fine-tuned with a maximum length of 300 tokens.
6 Related Work
Summary
이 섹션에서는 기존 이론적 사고(Theory of Mind) 평가 데이터셋의 한계를 분석하고, ExploreToM이 이를 극복하는 방식을 설명한다. 기존의 인간 생성 데이터셋(예: Shapira et al., 2023b)은 목표, 감정, 미래 행동에 대한 추론을 평가하지만, 규모와 범위의 한계가 있으며, 기계 생성 데이터셋(예: ToMi, Hi-ToM)은 정신 상태 추적에 집중하지만, 행동 집합의 제한(ToMi: enter, leave, moveObjContainer 등 3가지, Hi-ToM: info-* 추가지만 이야기의 마지막 행동으로만 사용)과 상호작용의 극도한 제약이 있다. 반면, ExploreToM은 더 많은 행동, 다양한 표현, 타당한 맥락을 지원하여 기계 생성 데이터셋의 범위를 확장한다. 또한, 최근 연구들이 LLM 기반 생성에 의존하는 반면, ExploreToM은 신뢰성 있는 다중 상호작용 스토리텔링을 보장하여 이론적 사고 평가에 적합한 포괄적이고 견고한 벤치마크를 제공한다. 이론적 사고는 언어 모델 외에도 인간-컴퓨터 상호작용, 설명 가능한 AI, 다중 에이전트 강화 학습 등 다양한 분야에서 탐구되었지만, 대부분 목표 중심의 상호작용에 초점을 맞춘 반면, 본 연구는 인지적 이론적 사고(정신 상태, 지식 등)에 집중하여, 문화 간 명확한 답변을 가능하게 하는 도메인 특화 언어로 상황을 생성한다. 합성 데이터 생성 분야에서는 퍼뮤테이션 기반 증강, 반복 프롬프팅 등의 기법이 사용되지만, 모델 홀로우(hallucination) 문제로 인해 데이터 품질을 보장하기 위해 외부 피드백이 필요하다. 본 연구는 외부 LLM-as-judge를 활용하여 스토리 생성 전후의 타당성과 어려움을 평가함으로써, 기존 AutoBencher(Li et al., 2024b)와 달리 텍스트 기반 조건이 홀로우를 최소화한다고 가정하지 않고, 가능한 서사 공간을 적극적으로 탐색하여, zero-shot 생성 가능성과 관계없이 높은 품질의 합성 데이터를 생성하고, 더 어려운 스토리를 생성할 수 있다.
Theory of mind benchmarking for language models Theory of mind benchmarks in language models can be categorized into human-generated and model-generated datasets. While human-generated datasets (Shapira et al., 2023b; Kim et al., 2024; Chen et al., 2024) test reasoning about goals, emotions of others, and future actions, they are often limited in size and scope. Machine-generated datasets, such as foundational ToMi (Le et al., 2019) and its successor Hi-ToM (Wu et al., 2023) focus primarily on mental state tracking, but have significant limitations: ToMi only supports a restricted set of actions ( ), while Hi-ToM adds but only as the last action in a story, and both datasets have extremely restricted interactions to orders. In contrast, our method, ExploreToM, significantly expands the scope of machine-generated datasets by supporting a larger number of actions, diverse wording, and plausible contexts. Unlike recent approaches that rely on LLMs for generation (Kim et al., 2023; Xu et al., 2024; Gandhi et al., 2024), ExploreToM ensures reliability and multi-interaction storytelling, making it a more comprehensive and robust benchmark for theory of mind in LLMs.
Theory of mind beyond language modeling Theory of mind has been explored in various areas, including human computer interaction (Wang et al., 2021), explainable AI (Akula et al., 2022), and multi-agent reinforcement learning (Rabinowitz et al., 2018; Sclar et al., 2022; Zhu et al., 2021). Recent benchmarks have evaluated theory of mind in multi-modal settings (Jin et al., 2024) and multi-agent collaboration (Bara et al., 2021; Shi et al., 2024), but these focus on goal-driven interactions. Psychologists distinguish between affective (emotions, desires) and cognitive (beliefs, knowledge) theory of mind (Shamay-Tsoory et al., 2010), with cognitive theory of mind developing later in children (Wellman, 2014). Our work targets cognitive theory of mind, which is well-suited for generating situations with a domain-specific language and provides unambiguous answers across cultures. By focusing on cognitive theory of mind, our approach complements existing research and provides a comprehensive benchmark for this crucial aspect of human reasoning in language models.
Synthetic data generation Synthetic data has become promising approach for acquiring high-quality data in various domains, including multihop question-answering (Lupidi et al., 2024), and language model evaluation (Wang et al., 2024). The process involves data augmentation/generation and curation, with techniques such as permutation-based augmentation (Yu et al., 2024; Li et al., 2024a) and iterative prompting (Yang et al., 2022). However, model hallucination (Guarnera et al., 2020; Van Breugel et al., 2023; Wood et al., 2021; Zhang et al., 2023) requires careful filtration and curation to ensure data quality. While prior works have used external feedback (Zelikman et al., 2022; Luo et al., 2024), our approach leverages an external LLM-as-judge to evaluate the plausibility and challenge of generated stories, both before and after infilling. Recently, AutoBencher (Li et al., 2024b) has also been proposed to automatically search for datasets that meet a salience, novelty, and difficulty desiderata, highlighting the importance of careful benchmark creation. Unlike AutoBencher, which over-generates under the assumption that text-based conditioning minimizes hallucinations, our approach lifts this assumption and actively searches the space of possible narratives. This enables to create high-quality synthetic data regardless of the likelihood of a story being generated zero-shot, and generating even more challenging stories than with over-generation.
7 Conclusions
Summary
이 섹션에서는 이론적 사고(Theory of Mind, ToM)가 사회적 지능의 핵심 요소이며, 인간과의 효과적인 상호작용을 위해 에이전트에 ToM 능력을 부여하는 것이 필수적임을 강조한다. 이를 위해 EXPLORETOM이라는 A* 알고리즘 기반의 프레임워크를 제안하며, 이는 신뢰성 있고 다양한 이론적 사고 평가 데이터를 생성하는 데 초점을 맞춘다. EXPLORETOM은 복잡한 신념 구조와 역할 기반 스토리 생성을 통해 모델의 ToM 이해 능력을 극복적으로 평가하며, 특히 적대적 생성(adversarial generation)을 통해 모델의 한계를 스트레스 테스트하고 데이터 누수에 대한 내성을 높인다. 실험 결과에 따르면, EXPLORETOM 기반의 평가 세트에서 Llama-3.1 70B Instruct는 0%, GPT-40는 9%의 정확도를 보였으며, 이 프레임워크를 학습 데이터 생성에 활용할 경우 유명한 ToM 벤치마크에서 29점의 정확도 향상을 기록했다. 또한, LLM이 ToM 능력 부족의 근본 원인으로 부족한 상태 추적 능력과 의도적으로 ToM을 요구하는 훈련 데이터의 부재를 지적하며, 이러한 요소가 자연 언어 환경에서는 쉽게 찾아볼 수 없다는 점을 강조한다. 이 연구는 ToM 평가와 훈련 데이터 생성에 있어 합성 데이터(synthetic data)의 중요성을 재확인하며, LLM의 ToM 능력 향상을 위한 새로운 방향을 제시한다.
Theory of mind (ToM) is essential for social intelligence, and developing agents with theory of mind is a requisite for efficient interaction and collaboration with humans. Thus, it is important to build a path forward for imbuing agents with this type of reasoning, as well as methods for robustly assessing the of models’ theory of mind reasoning capabilities.
We present EXPLORETOM, an A*-powered algorithm for generating reliable, diverse and challenging theory of mind data; specifically, creating synthetic stories that require theory of mind to understand them, along with questions to probe understanding. EXPLORETOM’s adversarial nature enables the stress testing of future models and making our evaluation more robust to data leakage. We show that EXPLORETOM generates challenging theory of mind evaluation sets for many frontier models, with accuracies as low as 0% for Llama-3.1 70B Instruct and 9% for GPT-40. Moreover, we show that EXPLORETOM can be used as a method for generating training data, leading to improvements of up to 29 accuracy points in well-known theory of mind benchmarks. Synthetic data is crucial for this domain, given that data that articulates theory of mind
reasoning is difficult to find in the wild: children have access to a wide range of naturalistic social settings that incentivize the development of theory of mind but there is no such parallel pressure for LLMs.
Finally, we provide insights as to why basic theory of mind is still elusive to LLMs, including poor state tracking skills and demonstrating the need for training data that purposefully requires theory of mind, which is likely not present in the wild nor in randomly-generated data.
Limitations
Summary
이 섹션에서는 ExploreToM 프레임워크의 한계를 분석하며, 현실 세계의 복잡한 상태와 서사 구조를 단순화하여 지원되는 행동 및 상호작용 유형에 제한을 두는 점을 지적한다. 또한, 새로운 행동을 수동적으로 코드화해야 하는 과정은 시간 소모적이지만 신뢰성 향상이라는 이점을 제공한다. 다만, 생성된 스토리가 목표 지향적 서사(goal-oriented narratives)가 아니라는 점을 강조하며, 향후 연구에서 캐릭터 목표로부터 직접적으로 행동이 유도되는 데이터셋을 개발하여 다양성과 타당성을 높이는 방향이 필요하다고 제안한다. 이는 모델의 이론적 사고 능력을 보다 정교하게 평가하기 위한 중요한 과제로 작용할 수 있다.
ExploreToM offers a valuable tool for theory of mind research, and is a first step towards developing LLMs that can handle social interactions effectively. Although its data encompasses diverse and challenging settings—more than previously available—, and is grounded in established psychological tests, ExploreToM necessarily simplifies the complexity of real-world states and narratives by constraining it to the supported types of actions and interactions. Our framework requires manual coding of new actions, wich can be time-consuming process but comes with the benefit of a significant reliability improvement. Furthermore, our stories are not necessarily goal-oriented narratives, highlighting an important avenue for future work: creating datasets where actions stem directly from character goals to further enhance diversity and plausibility.