Introduction
Quote
FaceNet directly trains its output to be a compact 128-D embedding using a triplet- based loss function based on LMNN.
Related Papers(Works)
- 이 논문에 따르면, 최근 Computer Vision에서 밀고 SOTA로 밀고 있는 Deep NN의 Architecture로는 2가지가 있다고 하는데,
-
- Inception based ← 이건 Google이 만들거였지..? 업청 깊고, module 형태의 block을 엄청 붙인 걸로 기억.
-
- 잘 알려진 대로, Conv Layer 기반의 Norm 달고, non-linear activation 달은 그러한 NN.
-
Model Structure
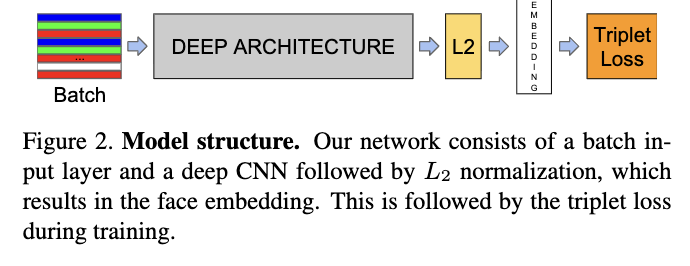
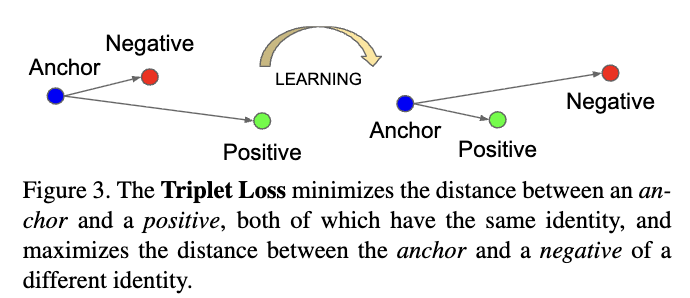
triplet Loss
- Contrastive Learning의 Loss 중 하나.
Methods
- 얼굴 인식에사 하고자 하는 것이 동일 ID에 대해서는 같게, 다른 ID에 대해서는 다르게 판단하는 것이므로, triplet loss는 이를 직접적으로 반영할 수 있는 loss 중 하나.
3.1 triplet-Loss
Triplet loss
where
- constraint: L2 norm = 1이 되도록 norm.
Optimization Aim
for
- 이렇게 anchor 기준으로 pos가 neg 보다 만큼의 slack을 허용하여 붙길 원함.
따라서 loss가 위아 같이 정의됨.
3.3 Deep Convolutional NN
Exp Configuration
In all our experiments we train the CNN using Stochastic Gradient Descent (SGD) with standard backprop [8, 11] and AdaGrad [5]. In most experiments we start with a learning rate of 0.05 which we lower to finalize the model. The models are initialized from random, similar to [16], and trained on a CPU cluster for 1,000 to 2,000 hours. The decrease in the loss (and increase in accuracy) slows down drastically after 500h of training, but additional training can still significantly improve performance. The margin α is set to 0.2.
4. Dataset and Evaluation
Quote
We evaluate our method on four datasets and with the exception of Labelled Faces in the Wild and YouTube Faces we evaluate our method on the face verification task. given a pair of two face images a squared L2 distance threshold is used to determine the classification of same and different.