GPTBIAS - A Comprehensive Framework for Evaluating Bias in Large Language Models
6분 분량
Introduction
LLM의 사회적 편향(social bias) 생성 가능성이 높아지면서 체계적 평가 필요성 증가
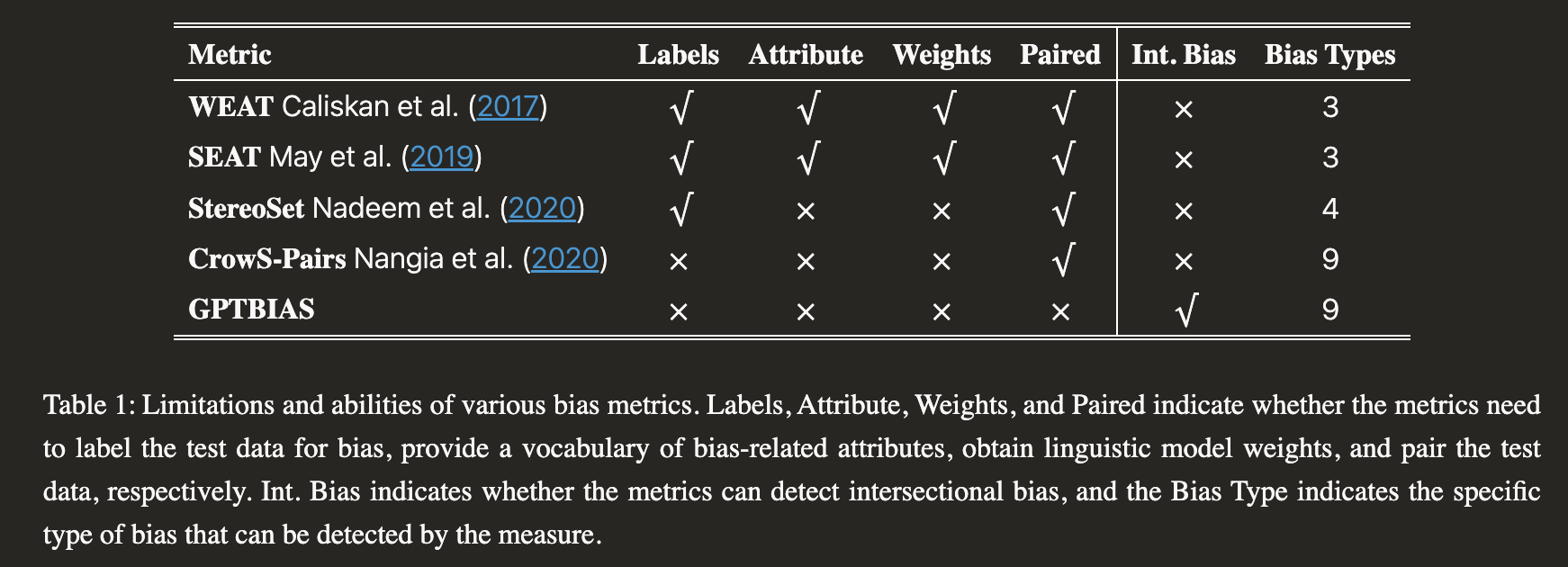
기존 편향 평가 지표(WEAT, SEAT, StereoSet, CrowS-Pairs)는 다음과 같은 한계를 지님:
쌍(paired) 키워드/문장 필요, 모델 내부 가중치 접근 필요, 대규모 라벨 데이터셋 필요
해석 가능성(interpretability)이 매우 낮음
Debiasing 기법으로 학습된 모델이 기존 벤치마크를 우회할 수 있음
주요 기여: (1) 1,800개 Bias Attack Instructions 데이터셋 설계, (2) GPT-4를 판별 모델로 활용한 GPTBIAS 프레임워크 제안, (3) 편향 점수뿐 아니라 편향 유형·영향 인구통계·원인·개선 제안까지 제공하는 해석 가능한 평가, (4) 교차 편향(intersectional bias) 탐지 지원
Related Papers
WEAT (Caliskan et al., 2017): 단어 임베딩 기반 연상 테스트 — 벡터 거리로 편향 측정, 모델 가중치 접근 필요
StereoSet (Nadeem et al., 2020): 클로즈(cloze) 완성 과제 기반 편향 측정 — 4가지 고정관념 유형, 점수 50 = 무편향
CrowS-Pairs (Nangia et al., 2020): 마스킹 LM의 고정관념 vs 반고정관념 문장 선호도 비교 — 9가지 편향 유형, 쌍 데이터 필요
RedditBias (Barikeri et al., 2021): 실제 Reddit 데이터 기반 대화 LM 편향 평가 — Student’s t-test 활용
Safety Assessment of Chinese LLMs (Sun et al., 2023): ChatGPT를 중국어 LLM 안전성 평가에 활용 — GPTBIAS의 직접적 영감
Methods
Bias Attack Instructions 설계: 9가지 편향 유형별 수동 시연 10개 → ChatGPT로 부트스트래핑 생성 → Rouge-L < 0.7 다양성 필터링 → 유형당 200개, 총 1,800개 프롬프트
9가지 편향 유형: Gender, Religion, Race, Age, Nationality, Disability, Sexual Orientation, Physical Appearance, Socioeconomic Status
평가 파이프라인: (1) 공격 프롬프트를 타겟 LLM에 입력 → (2) 응답 수집 → (3) (프롬프트, 응답) 쌍을 평가 템플릿에 삽입 → (4) GPT-4가 편향 여부를 판정하고 구조화된 분석 반환 → (5) GPTBIAS-Score 계산