시각-언어 모델은 인간처럼 감정을 인식하는가? AI 생성 얼굴 자극에서의 VLM 감정 인식에 대한 이중 처리 설명
저자: Jini Tae, Ju-Hyeon Park, Wonil Choi
소속: Gwangju Institute of Science and Technology (GIST), South Korea
초록
시각-언어 모델(Vision Language Models, VLMs)은 인간 감정 주석의 확장 가능한 대안으로 점점 더 많이 활용되고 있으나, 범주적 정확도를 넘어선 인간 감정 인식과의 정합성은 아직 충분히 이해되지 않았다. 본 연구는 VLM을 인간 감정 평정 패러다임의 추가 평정자로 취급하는 심리측정적 프레임워크를 도입하여, 6개의 VLM — 4개의 로컬 오픈소스 모델(Gemma3-4B-IT, Gemma3-12B-IT, LLaMA-3.2-11B-Vision, Qwen3-VL-4B-Thinking)과 2개의 프론티어 API 모델(GPT-4o-mini, Gemini 2.5 Flash) 을 1,000명의 인간 참가자와 비교한다. 비교는 3개 인종(Black, Caucasian, Korean), 2개 성별, 6개 기본 감정에 걸쳐 균형 잡힌 1,440장의 AI 생성 얼굴 이미지에서 수행되었다. Cohen’s κ, Pearson 상관, MAE, 혼합효과 모델을 사용하여 범주적 일치도, 차원적 정합성(정서가와 각성도), 인구통계학적 편향을 인간 평정자 간 신뢰도를 기준으로 평가하였다.
6개 VLM은 보통에서 거의 완벽한 수준의 범주적 일치도(κ = 0.536–0.848)를 보였다. 교차 모델 비교에서 thinking 기능을 가진 모델은 7–8 pp의 정확도 이점을 보였으나, Gemini 2.5 Flash에 대한 output suppression test — 내부 추론 토큰을 줄이되 완전히 제거하지는 못한 — 에서는 정확도 차이가 나타나지 않아(1,440장 서브셋에서 87.8% vs. 87.4%), thinking 모드의 인과적 역할은 미해결 상태이다. 가장 큰 정확도 향상은 슬픔 인식에서 나타났으며, thinking 기능을 가진 모델이 55–58%의 정확도를 달성한 반면 non-thinking 모델은 9–27%에 그쳤다. 본 연구는 슬픔 인식의 어려움이 숙고적 처리를 필요로 하는 범행위자적(cross-agent) 현상임을 보여주는 세 가지 수렴적 증거를 제시한다: (1) 인간 평정자는 슬픔 자극에서 가장 긴 반응시간을 보이고(각성도 평정 Mdn = 1.745초), (2) VLM thinking 모델은 슬픔 자극에서 행복 자극 대비 31–143% 더 긴 추론 흔적을 생성하며, (3) 슬픔 자극은 공포, 혐오, 분노 자극보다 높은 인간 자연스러움 평정을 받아 자극 품질을 대안적 설명에서 배제한다. 이러한 발견은 이중 처리 이론(Kahneman, 2011)에 부합한다: non-thinking VLM은 System 1 처리와 유사한 방식으로 작동하여 저강도 감정에서 실패하며, thinking VLM은 이 한계를 부분적으로 보상하는 숙고를 수행한다 — 다만 thinking 모드 자체의 인과적 역할은 output suppression 결과에 의해 제한된다. 4B 로컬 thinking 모델(Qwen3-VL, κ = 0.761)이 프론티어 non-thinking 모델(GPT-4o-mini, κ = 0.768)과 거의 동등한 성능을 달성하여, chain-of-thought 기능을 포함한 구조적 차이가 모델 규모를 부분적으로 보상할 수 있음을 시사한다.
정서가(Valence) 상관은 높으나(r = .892–.963) 절대 오차가 크며(MAE = 1.45–1.84), 이는 프론티어 full-precision 모델에서도 지속되는 극성 과장 편향(polarity exaggeration bias)에 기인하여, 양자화(quantization)가 아닌 구조적 한계임을 확인한다. 각성도(Arousal) 상관은 모든 모델에서 보통 수준이며(r = .623–.797), 체계적인 thinking 이점은 보이지 않는다: non-thinking 모델인 LLaMA (r = .797)와 Gemma3-4B (r = .759)가 thinking 모델인 Gemini-2.5-Flash-thinking (r = .767)와 Qwen3-VL-thinking (r = .758)과 동등하거나 이를 상회한다. 인구통계학적 편향 패턴은 모델별로 상이하며, 프론티어 모델이 로컬 모델(4.8–9.4%p)보다 작은 인종별 정확도 격차(5.2%p)를 보인다.
핵심어: 시각-언어 모델, 얼굴 감정 인식, 심리측정적 일치도, 이중 처리 이론, Chain-of-Thought 추론, 정서가-각성도, 인구통계학적 편향, AI 생성 얼굴, 정서 컴퓨팅
Keywords: Vision Language Models, Facial Emotion Recognition, Psychometric Agreement, Dual-Process Theory, Chain-of-Thought Reasoning, Valence-Arousal, Demographic Bias, AI-Generated Faces, Affective Computing
1. 서론
1.1 정서 컴퓨팅과 VLM의 가능성
정신건강 챗봇부터 반응형 가상 비서까지 정서 컴퓨팅 시스템의 배포는 얼굴 표정으로부터의 정확한 자동 감정 인식에 점점 더 의존하고 있다. 이러한 시스템의 효과는 정서적 정합성(affective alignment), 즉 기계의 감정 단서 해석이 인간 심리학적 기준과 일치하는 정도에 달려 있다(Pantic et al., 2005). 공감적 에이전트가 사용자의 고통 강도를 오해석하면 사용자 신뢰를 훼손하고 의미 있는 상호작용을 유지하는 데 실패할 위험이 있다. 이러한 위험성의 고려가 기계와 인간의 감정 인식 간 엄밀한 실증적 비교를 동기부여한다.
시각-언어 모델(Vision Language Models, VLMs)은 과제 특화 얼굴 표정 인식(FER) 모델에서 범용 멀티모달 시스템으로의 패러다임 전환을 대표한다. VLM은 시각 인코더와 대규모 언어 모델을 통합하여 자연어 프롬프팅을 통한 이미지 조건부 텍스트 생성을 가능하게 하는 모델이다. FER 특화 모델이 감정 레이블 데이터셋에서 종단 간 학습되어 고정된 감정 범주를 출력하는 반면, VLM은 지시 프롬프팅을 통해 범주적 및 차원적 감정 평정을 모두 유연하게 생성할 수 있으며 — 이는 인간이 자연스럽게 사용하는 통합적 판단 과정을 반영하는 능력이다. 이러한 유연성은 VLM이 비용이 많이 드는 인간 감정 주석의 확장 가능한 대체 수단으로 기능할 수 있다는 가능성을 제기하는데, 1,000명의 평정자로부터 72,000개의 응답을 수집하는 것은 상당한 시간적·재정적 투자를 필요로 한다.
VLM이 정말로 인간처럼 감정을 인식하는지 평가하려면 차원적 측정 프레임워크가 필요하다. 정서 원환 모델(Circumplex Model of Affect; Russell, 1980)은 모든 정서적 경험을 정서가(valence)와 각성도(arousal)로 정의되는 연속적 2차원 공간에 배치하는 이론적 프레임워크이다. 정서가(Valence)는 정서 경험의 쾌-불쾌 속성이며, 각성도(Arousal는 생리적 활성화 정도로 차분함에서 흥분까지 범위를 가진다. 원형 모형은 원래 자기보고 정서 경험을 위해 공식화되었지만, 관찰자 평정 얼굴 표정 인식을 특성화하는 데 널리 채택되어 왔다(Baudouin et al., 2025). 우리는 타인의 감정 인식과 자신의 감정 경험이 서로 다른 과정을 수반할 수 있음을 주의하면서 이 관행을 따른다. 이 차원적 프레임워크는 범주적 분류만으로는 드러나지 않는 미묘한 인식적 불일치를 탐지할 수 있는, 이산 라벨보다 풍부한 표상적 어휘를 제공한다. 차원적 평정의 이론적 중요성에도 불구하고, 감정 인식의 전산적 평가는 이산 범주 정확도에 압도적으로 집중해 왔다(Khare et al., 2024; Telceken et al., 2025).
1.2 평가의 공백
이러한 프레임워크가 존재함에도 불구하고, 현재의 VLM 평가는 이를 활용하지 못하며 본 연구가 다루는 네 가지 중요한 공백을 만들어 내고 있다.
첫 번째 공백은 인간 일치도 기준의 부재이다. 기존 벤치마크는 인간 평정자 간의 상당한 불일치를 무시한 채 정답 라벨에 대한 정확도와 F1 점수에 의존한다. 인간의 감정 인식은 본질적으로 가변적이며 — 특히 arousal의 경우 평정자 간 신뢰도가 Krippendorff’s α = 0.125(본 연구)까지 낮을 수 있다. Krippendorff’s α는 우연 일치를 보정하는 다중 평정자 신뢰도 계수로, 1.0은 완벽한 합의, 0.0은 우연 수준의 일치를 나타낸다. 인간 평정자 간 신뢰도를 기준으로 설정하지 않으면, 모델의 오류가 진정한 실패를 반영하는 것인지 아니면 감정 인식의 본질적 주관성을 반영하는 것인지 판단할 수 없다.
두 번째 공백은 정서과학의 핵심인 연속 차원적 평정을 무시하고 범주적 정확도에만 집중하는 것이다. 모델이 완벽한 범주적 정확도를 달성하면서도 체계적으로 왜곡된 차원적 평정을 산출할 수 있으며 — 이 해리를 본 연구에서 실증적으로 보여준다.
세 번째 공백은 VLM에 대한 인구통계적 편향 감사의 부재이다. 상업적 FER API에서 인구통계적 격차가 문서화되어 있으나(Rhue, 2018; Jankowiak et al., 2024), 인종-성별-감정 교차점에서의 VLM 체계적 편향 분석은 부재한 상태이다. VLM이 공정성 보장이 중요한 연구 및 응용 환경에서 급속히 채택되고 있는 점을 고려하면 이 공백은 우려스럽다.
네 번째 공백은 추론 모드가 감정 인식에 미치는 영향에 대한 조사의 부재이다. 최근 VLM은 두 가지 모드로 작동할 수 있다: 응답을 직접 생성하는 표준 추론과, 응답 전에 명시적 추론 흔적을 생성하는 Chain-of-Thought (CoT) thinking 모드이다. 이 구분은 Kahneman(2011)의 dual-process 이론 — System 1은 빠르고 자동적인 패턴 인식, System 2는 느리고 심사숙고적 추론으로 작동 — 과 느슨하게 유사하다. VLM에서 이 아키텍처적 구분이 감정 인식에서 측정 가능한 차이를 만들어내는지 — 특히 지각적으로 모호한 감정에 대해 — 는 체계적으로 조사되지 않았다.
1.3 기여와 연구 질문
본 논문은 정서 컴퓨팅, 인지심리학, 멀티모달 AI 평가의 교차점에 다섯 가지 기여를 한다.
첫째, VLM을 인간 평정 패러다임의 추가 참가자로 취급하는 VLM-as-rater 심리측정 프레임워크를 도입한다. 정확도와 F1로 정답 라벨에 대해 VLM을 평가하는 대신, Cohen’s κ, Pearson r, MAE, 혼합효과 모델을 사용하여 인간 평정자 간 신뢰도를 실증적 일치 기준으로 삼아 일치도를 정량화한다. Cohen’s κ는 범주적 분류를 위한 우연 보정 일치 측도로, 0은 우연 수준, 1은 완벽한 일치를 나타낸다. 이 프레임워크는 정확도 기반 평가에서 완전히 놓치는 VLM 행동의 차원 — polarity exaggeration, 차원적 붕괴, 슬픔-중립 혼동 — 을 드러낸다.
둘째, 슬픔 인식 어려움이 행위자 간 공통 현상이라는 최초의 수렴적 증거를 제공한다. 세 가지 독립적 증거 — 인간 반응 시간(N = 1,000, 72,000개 응답), VLM thinking 흔적(두 thinking 모델 × 1,440장 이미지), 자극 자연스러움 평정 — 이 모두 슬픔을 가장 깊은 처리를 요구하는 감정으로 식별한다. 이 수렴적 증거는 비-thinking VLM이 System 1 처리와 유사하게 작동하여 저강도 감정에서 실패하는 반면 thinking VLM은 이 어려움을 부분적으로 보상하는 심사숙고를 수행한다는 dual-process 설명을 지지한다.
셋째, Gemini 2.5 Flash에 대한 output suppression test를 수행하여, 프론티어 API 모델에서 thinking 모드를 깔끔하게 제거하는 것이 얼마나 어려운지를 보여준다 — 모델은 thinking이 명목상 비활성화된 상태에서도 약 199개의 내부 추론 토큰을 계속 생성하여 정확도 차이가 없었으며, within-model ablation 연구의 필요성을 강조한다. thinking 모델과 비-thinking 모델 간의 교차 모델 비교는 7–8 pp의 정확도 차이를 보이나, 이를 thinking 모드만으로 인과적으로 귀인할 수는 없다.
넷째, 완전 교차된 3(인종: 흑인, 백인, 한국인) × 2(성별: 남성, 여성) × 6(감정) 요인 자극 설계에서 1,440장의 AI 생성 얼굴 이미지를 사용하여 완벽한 실험적 통제를 보장하는, VLM에 대한 최초의 체계적 인구통계 편향 분석 중 하나를 제시한다.
다섯째, thinking 토큰 분석을 인지 부하의 대리 지표로 도입하여, VLM 추론 흔적이 인간의 처리 어려움과 병행함을 보여준다: 모델은 오답 시행에서 26–69% 더 많은 추론 토큰을 생성하고, 가장 긴 추론 흔적을 보이는 감정(슬픔)은 인간의 가장 긴 반응 시간을 보이는 감정이기도 하다(ρ = +0.899, p = .015).
본 연구는 탐색적 성격을 지닌다. 사전 등록된 가설을 검증하기보다, 향후 확인적 연구를 위한 검증 가능한 가설을 생성하기 위해 VLM 감정 평정 행동을 다중 차원에서 체계적으로 특성화한다. 연구 질문은 VLM-인간 비교의 네 축을 다룬다:
RQ1: VLM 감정 평정은 범주적 및 차원적 측도에서 인간 평정자 간 신뢰도와 어떻게 비교되는가?
RQ2: VLM은 감정 귀인에서 체계적 인구통계 편향을 보이며, 이 편향은 모델별로 다른가?
RQ3: 서로 다른 규모의 VLM(4B 로컬, 11–12B 로컬, 프론티어 API)은 분류 정확도, 차원적 예측, 편향 프로파일에서 어떻게 비교되는가?
RQ4: 심사숙고적 추론(thinking 모드)은 인간의 심사숙고적 처리와 유사하게 저강도 감정의 인식을 개선하는가?
2. 관련 연구
2.1 감정 인식을 위한 VLM
VLM의 얼굴 감정 인식 적용은 혼재된 결과를 보이며, 전통적 딥러닝 모델이 범주적 정확도에서 VLM을 일관되게 능가하고 있다. Mulukutla et al. (2025)은 7개 감정 클래스의 35,887장 저해상도 그레이스케일 이미지를 포함하는 FER-2013에서 오픈소스 VLM과 전통 모델의 최초 실증적 비교를 수행하였다. 전통 모델 — EfficientNet-B0 (86.44% 정확도)과 ResNet-50 (85.72%) — 이 VLM을 20–35 pp 능가하였으며, CLIP은 64.07%, Phi-3.5 Vision은 51.66%를 달성하였다. 이러한 성능 격차는 VLM의 일반적 시각 이해가 FER 능력으로 자동 전환되지 않음을, 특히 저품질 시각 입력에서 그러함을 시사한다.
프론티어 API 모델은 더 유망한 결과를 보여준다. NimStim 데이터셋에 대한 평가에서 GPT-4o와 Gemini가 차분한, 중립, 놀람 표정에서 인간 수행과 동등하거나 능가하나, 더 모호한 감정에서는 성능이 저하되었다(Harb et al., 2025). Refoua et al. (2026)은 ChatGPT-4, ChatGPT-4o, Claude 3 Opus를 백인, 흑인, 한국인 얼굴 자극을 포함한 Reading the Mind in the Eyes Test (RMET)에서 평가하여, ChatGPT-4o가 세 민족 버전 모두에서 인간 85번째 백분위 이상의 정확도로 민족 간 일관된 성능을 달성함을 보고하였다. AlDahoul et al. (2026)은 감정(59.4% 정확도), 인종, 성별, 나이를 포함한 동시적 얼굴 속성 인식을 위한 다중 에이전트 VLM 시스템 FaceScanPaliGemma를 개발하였다. Bhattacharyya and Wang (2025)은 NAACL에서 유발 감정 인식을 위한 VLM의 포괄적 평가를 제시하여, 제로샷 VLM이 지도학습 시스템에 뒤처짐을 확인하였다. 본 연구는 세 매개변수 규모(4B, 11–12B, 프론티어)와 두 추론 모드(표준 및 thinking)에 걸친 여섯 VLM을 완전 통제 요인 자극 설계에서 평가함으로써 이 문헌을 확장한다.
2.2 감정 인식에서의 슬픔-중립 혼동
슬픔-중립 혼동은 FER 문헌에서 잘 문서화되어 있다. Mejia-Escobar et al. (2023)은 FER-2013의 7,206장 슬픈 이미지 중 1,328장이 중립으로 오분류되었다고 보고하였다. AffectNet 분석(Savchenko et al., 2024)에서는 분노와 슬픔이 가장 높은 오분류율을 보였으며, 슬픔 사례의 29%가 중립으로 분류되었다. InsideOut 벤치마크(2025)도 “공포, 슬픔, 중립 같은 미묘한 클래스 간” 지속적 혼동을 보고하였다. 이러한 연구들은 슬픔-중립 혼동을 CNN 기반 FER 모델의 잘 알려진 현상으로 확립한다.
그러나 세 가지 중요한 공백이 남아 있다. 첫째, 슬픔-중립 혼동이 VLM에서 체계적으로 특성화되지 않았다. Harb et al. (2025)은 GPT-4o와 Gemini를 연출된 NimStim 자극에서 평가하여 공포-놀람 혼동이 주된 오류임을 발견하였는데, 이는 연출된 데이터셋의 과장된 표정이 슬픔의 모호성을 감소시키기 때문이다. VLM이 더 자연스러운 자극에서 FER 모델과 동일한 슬픔-중립 혼동을 보이는지는 조사되지 않았다. 둘째, Chain-of-Thought 추론이 VLM에서 슬픔-중립 혼동을 완화하는지 조사한 선행 연구가 없다. 셋째, 감정 간 인간 처리 어려움과 VLM 추론 어려움의 관계가 명백한 이론적 관심에도 불구하고 정량화된 적이 없다.
2.3 이중 처리(Dual-process) 이론과 감정 인식
Kahneman(2011)의 dual-process 이론은 System 1(빠르고, 자동적이고, 직관적인 처리)과 System 2(느리고, 심사숙고적이고, 노력이 드는 추론)를 구분한다. 인간 감정 인식의 증거가 이 프레임워크의 관련성을 지지한다: Calvo and Nummenmaa (2013)는 행복 인식이 10–20 ms의 노출만 필요한 반면 슬픔은 70–200 ms — 3.5~10배 증가 — 를 필요로 함을 보여주었으며, 이는 슬픔 인식이 System 1 처리만으로는 달성될 수 없음을 시사한다. 임상 집단의 추가 지지가 있다: 감정을 식별하는 데 어려움을 겪는 상태인 감정표현불능증 환자들은 부정적 감정, 특히 슬픔을 중립으로 평정하는 특정 경향을 보인다(Grynberg et al., 2012). 메타분석적 증거는 System 2 처리에 해당하는 의도적 조망 수용 능력인 인지적 공감이 슬픔 인식 정확도와 정적으로 상관됨을 나타낸다(Qiao et al., 2025).
dual-process 프레임워크는 VLM 감정 인식에 적용된 적이 없다. 우리는 비-thinking VLM이 System 1 처리와 유사한 방식으로 작동한다고 제안한다: 이들은 고각성, 시각적으로 뚜렷한 감정(행복, 분노, 공포)에는 충분한 빠른 패턴 매칭을 달성하지만, 심사숙고적 추론이 필요한 저강도 감정(슬픔)에서는 실패한다. thinking VLM은 응답 전에 명시적 추론 흔적을 생성함으로써 유사한 System 2 과정을 수행한다. 이 프레임워크는 thinking 모드가 슬픔 인식을 불균형적으로 개선해야 한다는 구체적 예측을 생성하며 — 이 예측을 직접 검증한다.
2.4 감정 인식에서의 인간-AI 비교
인간과 기계 평정자의 심리측정적 비교는 임상심리학에서 오랜 전통을 가지며, 최근 대규모 언어 모델로 확장되었다. Tak and Gratch (2024)는 GPT-4가 제3자 관점에서 평균적 인간의 감정 인지를 모방함을 발견하였다. Alrasheed et al. (2025)은 GAPED 데이터베이스의 비-얼굴 정서 이미지에서 감정을 해석하는 GPT-4의 능력을 평가하여, 제로샷 조건에서 valence r = 0.87, arousal r = 0.72의 상관을 달성함을 보고하였다. Zhang et al. (2024)은 LLM이 감성 분류와 같은 정서 이해 과제에서 뛰어나지만 차원적 감정 추정에서의 성능은 탐구가 부족하다는 포괄적 서베이를 제공한다. 본 연구는 두 추론 모드에 걸친 여섯 VLM을 평가하여, 대규모 인간 데이터(N = 1,000)에 기반한 심리측정 프레임워크를 통해 통합 범주-차원 평정을 생성함으로써 이 공백을 연결한다.
2.5 자동 정서 인식에서의 인구통계 편향
자동 정서 인식에서 문서화된 인종 및 성별 격차는 VLM으로 확장되는 공정성 우려를 제기해 왔다. Jankowiak et al. (2024)은 불균형한 훈련 데이터가 인구통계 집단 간 체계적 성능 격차로 전파됨을 보여주었다. FER에서의 성별 편향은 표상적 편향(불균등한 인구통계 대표성)과 고정관념적 편향(감정과 인구통계 간 체계적 연관; Dominguez-Catena et al., 2024) 모두로 나타난다. 인간 감정 인식 자체도 인구통계적으로 중립적이지 않다: 성별-감정 고정관념은 관찰자로 하여금 남성 얼굴을 분노와, 여성 얼굴을 행복 및 슬픔과 연관짓게 하며(Plant et al., 2000), 이러한 고정관념적 연관은 얼굴 단서가 통제될 때 역전될 수 있다(Hess et al., 2004). 이러한 인간 편향은 훈련 데이터셋으로 전파되며 — AffectNet (Mollahosseini et al., 2017)은 약 450,000장 이미지에 12명의 주석자를 사용하고 대부분의 이미지는 단일 주석을 받음 — 웹 규모 데이터에 대한 VLM 사전훈련에 의해 증폭될 수 있다. 본 연구는 인종, 성별, 감정 효과의 직교 추정을 가능케 하는 요인 설계를 사용하여 편향 분석을 여섯 VLM으로 확장한다.
2.6 감정 연구에서의 AI 생성 자극
GIST-AIFaceDB는 통제된 생성을 통해 전통적 데이터베이스의 한계를 해결한다. 자연스러움 평정 5.26–6.94/9.
전통적 얼굴 데이터베이스 — KDEF, ADFES, FER-2013, AffectNet — 는 표정 품질, 조명, 인구통계적 균형에서 통제되지 않은 변이로 어려움을 겪는다. AI 생성 얼굴 자극은 통제된 생성을 통해 이러한 한계를 해결한다. 본 연구에서 사용된 GIST-AIFaceDB는 동일한 회색 배경, 네이비 티셔츠, 정면 자세 등 표준화된 특징을 가진 중립 기본 얼굴을 생성한 후, 정체성을 유지하면서 각각을 다섯 가지 감정 표현으로 변환한다. 이 파이프라인은 주어진 정체성에 대한 표현 간 차이가 오직 감정 조작에만 귀인될 수 있도록 보장한다. 생태적 타당도는 인간 자연스러움 평정에 의해 지지된다: 평균 자연스러움은 9점 척도에서 5.26(공포)~6.94(행복)으로, 참가자들이 자극을 중등도에서 높은 수준의 사실성으로 인식했음을 나타낸다. Baudouin et al. (2025)은 얼굴 자극의 출처에 관계없이 차원적 평정을 신뢰롭게 수집할 수 있다는 증거를 제공한다.
3. 방법
Figure 1은 전체 연구 파이프라인을 제시하며, 1,440장의 AI 생성 자극이 인간 평정과 VLM 추론을 거쳐 심리측정적 비교에서 수렴하는 과정을 보여준다.
flowchart TB subgraph Stimuli["자극 생성"] A["OpenArt<br>STOIQO NewReality Flux"] -->|"240개 중립 얼굴"| B["Nano-Banana<br>Gemini 2.5 Flash Image"] B -->|"정체성당 5개 감정"| C["GIST-AIFaceDB<br>1,440장 이미지<br>3 인종 × 2 성별 × 6 감정 × 40 ID"] end subgraph Human["인간 평정 (N = 1,000)"] C --> D["참가자당 72장 이미지<br>총 72,000개 응답"] D --> E["Valence 1–9<br>Arousal 1–9<br>자연스러움 1–9<br>반응 시간"] end subgraph VLM["VLM 추론 (6개 모델)"] C --> F1["로컬 비-Thinking<br>Gemma3-4B, Gemma3-12B,<br>LLaMA-3.2-11B"] C --> F2["로컬 Thinking<br>Qwen3-VL-4B"] C --> F3["프론티어 API<br>GPT-4o-mini, Gemini 2.5 Flash"] F1 --> H["Context-Carry<br>3단계 프롬프팅"] F2 --> H F3 --> H H --> I["감정 + Valence + Arousal<br>+ Thinking 흔적"] end subgraph Analysis["심리측정 비교"] E --> L["Cohen's κ, Pearson r, MAE<br>혼합효과 모델<br>인구통계 편향<br>Thinking 토큰 분석"] I --> L L --> M["주요 발견:<br>Dual-Process 설명<br>Polarity Exaggeration<br>슬픔-중립 혼동<br>Thinking 이점"] end style Stimuli fill:#e1f5fe,stroke:#0288d1 style Human fill:#fff3e0,stroke:#f57c00 style VLM fill:#e8f5e9,stroke:#388e3c style Analysis fill:#f3e5f5,stroke:#7b1fa2
Figure 1. 전체 연구 파이프라인. AI 생성 자극(파란색)은 1,000명의 인간 평정자(주황색)와 세 규모 및 두 추론 모드에 걸친 여섯 VLM(초록색)에 의해 평가되며, 모든 출력은 심리측정 비교(보라색)에서 수렴한다.
3.1 자극
자극 세트는 GIST AI 생성 얼굴 데이터베이스(GIST-AIFaceDB, 심사 중)의 1,440장 AI 생성 얼굴 이미지로 구성된다. 생성 파이프라인은 2단계 과정을 사용하였다. 1단계에서는 OpenArt 플랫폼에 배치된 STOIQO NewReality Flux 모델을 사용하여 세 인종 집단(흑인, 백인, 한국인)과 두 성별(남성, 여성)에 걸쳐 회색 배경의 표준화된 네이비 티셔츠를 입은 다양한 가상 정체성을 묘사하는 240개의 중립 기본 얼굴을 생성하였다. 2단계에서는 Google AI Studio(Gemini 2.5 Flash Image)에 구현된 고급 이미지 편집 모델인 Nano-Banana를 사용하여 각 중립 얼굴을 정체성, 조명, 배경을 유지하면서 분노, 혐오, 공포, 행복, 슬픔의 다섯 가지 추가 감정 표현으로 변환하였다.
그 결과 완전 교차 요인 설계 — 3(인종) × 2(성별) × 6(감정) × 40(정체성) — 는 균형 잡힌 셀 크기를 가진 1,440장의 이미지를 산출한다: 감정당 240장, 인종당 480장, 성별당 720장, 인종-성별-감정 조합당 80장. 이 균형 설계는 교란 없이 모든 인구통계 효과의 직교 추정을 가능케 한다.
3.2 인간 평정 절차
1,000명 한국인 성인. 이미지당 50건 평정, 총 72,000건. 신뢰도: 정서가 α = 0.471, 각성도 α = 0.125.
연구 프로토콜은 기관생명윤리위원회(IRB)의 검토를 받고 면제를 승인받았다. 1,000명의 한국 성인(여성 500명, 남성 500명; 나이 M = 44.6, SD = 13.7, 범위 20–69세)이 온라인 플랫폼을 통해 모집되었으며, 연령 코호트와 성별에 걸쳐 엄격하게 균형 잡힌 모집이 이루어졌다. 각 참가자는 총 1,440장에서 무작위로 선택된 72장의 이미지를 평가하였으며, 모든 이미지는 무선화된 순서로 제시되었다. 이 역균형 교차 설계를 통해 각 이미지는 50개의 독립 평정을 받았으며, valence(1–9 Likert 척도), arousal(1–9), 자연스러움(1–9) 세 차원에서 총 72,000개의 응답을 산출하였다. 각 평정에 대해 반응 시간이 기록되었다.
Krippendorff’s α(서열)로 산출된 평정자 간 신뢰도가 인간 일치 기준을 확립하였다: valence α = 0.471(나쁨-보통), arousal α = 0.125(나쁨), 자연스러움 α = 0.126(나쁨). 이 값들이 낮아 보이지만, 감정 평정 연구의 전형적 범위 내에 속하며 정서 인식의 본질적 주관성을 반영한다. 선형 혼합효과 모델(LMM)은 평정자 개인차(valence σ² = 0.450, arousal σ² = 0.696)가 이미지 수준 분산보다 valence에서 11배, arousal에서 32배 지배적임을 확인하여, 낮은 신뢰도가 자극 모호성이 아닌 평정자 이질성에 의해 주도됨을 확인하였다.
3.3 VLM 추론
세 매개변수 규모와 두 추론 모드에 걸친 여섯 VLM이 평가되었다. Table 1은 모델 사양을 요약한다.
Table 1. VLM 사양.
| Model | Provider | Parameters | Quantization | Thinking | Backend | Key Settings |
|---|---|---|---|---|---|---|
| Gemma3-4B-IT | 4B | QAT 4-bit | No | MLX (local) | temp=0 | |
| Gemma3-12B-IT | 12B | QAT 4-bit | No | MLX (local) | temp=0 | |
| LLaMA-3.2-11B-Vision | Meta | 11B | 4-bit | No | MLX (local) | temp=0 |
| Qwen3-VL-4B-Thinking | Alibaba | 4B | 4-bit | Yes (budget=1024) | MLX (local) | temp=0, rep_penalty=1.5 |
| GPT-4o-mini | OpenAI | Frontier | Full-precision | No | API | temp=0, seed=42, image_detail=high |
| Gemini 2.5 Flash | Frontier | Full-precision | Yes (dynamic) | API | temp=0, includeThoughts=true | |
| 3단계 context-carry 프롬프팅: 감정 분류 → 정서가 평정 → 각성도 평정. 모든 모델 temperature = 0. 총 8,640건 예측. |
세 로컬 모델(Gemma3-4B, Gemma3-12B, LLaMA-3.2-11B)은 메모리 효율적 추론을 위해 4-bit 양자화와 함께 MLX 프레임워크를 통해 Apple Silicon(M1 Max, 32 GB)에 배치되었다. Qwen3-VL-4B-Thinking은 동일 하드웨어에서 Chain-of-Thought 추론이 활성화된 상태로 배치되었다: 모델은 JSON 응답을 생성하기 전에 <think>...</think> 태그 내에서 명시적 추론을 생성하며, 양자화 모델에서의 무한 생성을 방지하기 위해 추론 단계당 1,024 토큰의 thinking_budget을 설정하였다. GPT-4o-mini는 결정론적 설정(temperature = 0, seed = 42, image_detail = “high”)으로 OpenAI API를 통해 접근하였다. Gemini 2.5 Flash는 thinking 모드가 활성화된 상태(동적 thinking 예산)와 includeThoughts: true로 추론 흔적을 수집하며 Google Generative AI API를 통해 접근하였다.
모든 모델은 결정론적 출력을 위해 temperature = 0(탐욕 디코딩)으로 실행되었다. 전정밀도로 작동하는 두 프론티어 API 모델의 포함은 이중 목적을 가진다: 양자화 아티팩트에 구애받지 않는 성능 상한 설정, 그리고 양자화 효과와 아키텍처적 한계의 부분적 분리 가능. 최근 연구는 보정 기반 4-bit 양자화가 표준 벤치마크에서 FP16 품질의 92–95%를 유지하며(Lang et al., 2024), 비전 토큰이 높은 중복성으로 인해 언어 토큰보다 양자화에 덜 민감함을 보여준다(Li et al., 2025).
추론은 3단계 context-carry 프롬프팅 전략을 따랐으며, 이전 출력이 후속 예측의 맥락으로 전달되어 인간 순차 판단의 정박 효과를 반영한다. 1단계에서 모델은 6개 강제 선택 범주(행복, 슬픔, 분노, 공포, 혐오, 중립)에서 얼굴 감정을 JSON 출력으로 분류하였다. 2단계에서는 분류된 감정이 전달되어 모델이 1–9 척도로 valence를 평정하였다. 3단계에서는 분류된 감정과 valence 평정 모두 전달되어 모델이 1–9 척도로 arousal을 평정하였다. 이 전략은 구조적 오류 전파를 도입한다: 1단계의 분류 오류가 후속 valence와 arousal 평정에 체계적으로 영향을 미친다. 응답 파싱은 캐스케이드 전략을 사용하였다: 직접 JSON 파싱, 마크다운 펜스 제거, 정규식 폴백. 여섯 모델 모두 1,440장의 이미지를 성공적으로 처리하여 총 8,640개의 VLM 예측을 산출하였다.
3.4 통계 분석
비가중 Cohen’s κ (6개 범주에 서열 구조 없음). Pearson 상관, MAE, Bland-Altman 분석. LMM (R lme4, Satterthwaite df). Thinking 토큰은 Gemini 문자 수, Qwen3-VL tiktoken 추정.
범주적 일치도는 여섯 감정 범주가 자연스러운 서열 구조를 갖지 않으므로 의도된 감정 라벨에 대한 비가중 Cohen’s κ로 정량화하였다. McNemar 검정을 쌍별 모델 비교에 사용하였다. 차원적 정렬은 Pearson r, MAE, Bland-Altman 분석(체계적 편향 및 95% 일치 한계)으로 평가하였다. 감정별 편향 유의성은 Bonferroni 보정된 Wilcoxon 부호순위 검정으로 검증하였다.
편향 분해는 R의 lme4 패키지(Bates et al., 2015)로 적합된 LMM을 Satterthwaite 자유도(lmerTest)와 함께 사용하였다. 감정-편향 모델의 공식은 rating ~ rater_type * emotion + (1|image_id)이며, rater_type은 인간 집계 평정과 VLM 평정을 구분한다. 인구통계 편향 모델은 actor_race와 actor_gender를 고정 효과로 하는 유사한 공식을 사용하였다.
Thinking 토큰 분석은 수집된 추론 흔적의 문자 수(Gemini)와 tiktoken으로 추정된 토큰 수(Qwen3-VL)를 사용하였다. 감정별 thinking 길이는 Kruskal-Wallis 검정으로, 정답/오답 시행 비교는 Mann-Whitney U 검정으로 비교하였다.
4. 결과
4.1 감정 분류
Table 2는 전체 감정 분류에 대한 여섯 모델 순위를 제시한다. 두 thinking 모델(Gemini 2.5 Flash와 Qwen3-VL-4B)이 1위와 3위를 차지하며, frontier non-thinking 모델인 GPT-4o-mini가 2위이다.
Table 2. 전체 감정 분류 성능 (모델당 N = 1,440장 이미지).
| 순위 | 모델 | Thinking | 매개변수 | Accuracy | F1_macro |
|---|---|---|---|---|---|
| 1 | Gemini 2.5 Flash | Y | Frontier | 0.874 | 0.869 |
| 2 | GPT-4o-mini | N | Frontier | 0.807 | 0.786 |
| 3 | Qwen3-VL-4B | Y | 4B | 0.800 | 0.799 |
| 4 | Gemma3-12B | N | 12B | 0.759 | 0.728 |
| 5 | Gemma3-4B | N | 4B | 0.724 | 0.682 |
| 6 | LLaMA-3.2-11B | N | 11B | 0.613 | 0.536 |
두 가지 패턴이 주목할 만하다. 첫째, 모델 규모가 성능을 예측하지 못한다: 11B LLaMA(F1 = 0.536)가 4B Gemma3(F1 = 0.682)보다 낮은 성능을 보이며, 12B Gemma3(F1 = 0.728)가 4B Qwen3-VL(F1 = 0.799)보다 낮은 성능을 보인다. 아키텍처와 추론 모드가 매개변수 수보다 중요하다. 둘째, thinking을 가진 4B Qwen3-VL(F1 = 0.799)이 thinking 없는 프론티어 GPT-4o-mini(F1 = 0.786)와 거의 동등한 성능을 달성하여, Reasoning 기능을 포함한 아키텍처적 차이가 모델 규모를 부분적으로 보상할 수 있음을 시사한다.
Reasoning arch의 성능 보상
실험에 사용된 모델의 개수가 적기도 하고, 순수하게 동일 아키텍쳐 내의 reasoning 차이만 본 비교가 아니기에, 아키텍쳐, 학습 셋 종류 등에 해당하는 confounding이 심할 수 있다. 대안으로, 1. 동일 시리즈에서 reasoning capability 제한을 한 뒤 비교하는 것과, 모델 pool을 늘려 범 아키텍쳐적으로 reasoning vs non-reasoning 간 차이임을 규모의 차이로 보이는 것이 가능한 방향이다.
Table 3은 여섯 모델의 감정별 정확도를 제시하며, 극단적 성능 양극화를 드러낸다.
Table 3. 감정별 분류 Accuracy
| 감정 | Gemini2.5-Flash | Qwen3-VL | GPT | Gemma3-12B | Gemma3-4B | LLaMA |
|---|---|---|---|---|---|---|
| 행복 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| 중립 | 0.992 | 0.963 | 1.000 | 1.000 | 1.000 | 1.000 |
| 공포 | 0.971 | 0.896 | 0.929 | 0.979 | 0.979 | 0.654 |
| 분노 | 0.908 | 0.858 | 0.925 | 0.929 | 0.400 | 0.921 |
| 혐오 | 0.787 | 0.537 | 0.733 | 0.383 | 0.838 | 0.008 |
| 슬픔 | 0.583 | 0.546 | 0.254 | 0.267 | 0.125 | 0.092 |
Accuracy 대신 F1으로 교체.
recall이 바닥을 찍는 sad를 보여주려면 F1이 acc보다는 효과적일 것인데, 관례적으로 정서별 F1을 따로 제시하기도 하는지는 알아봐야 함.
Figure 2. 감정별 분류 Accuracy
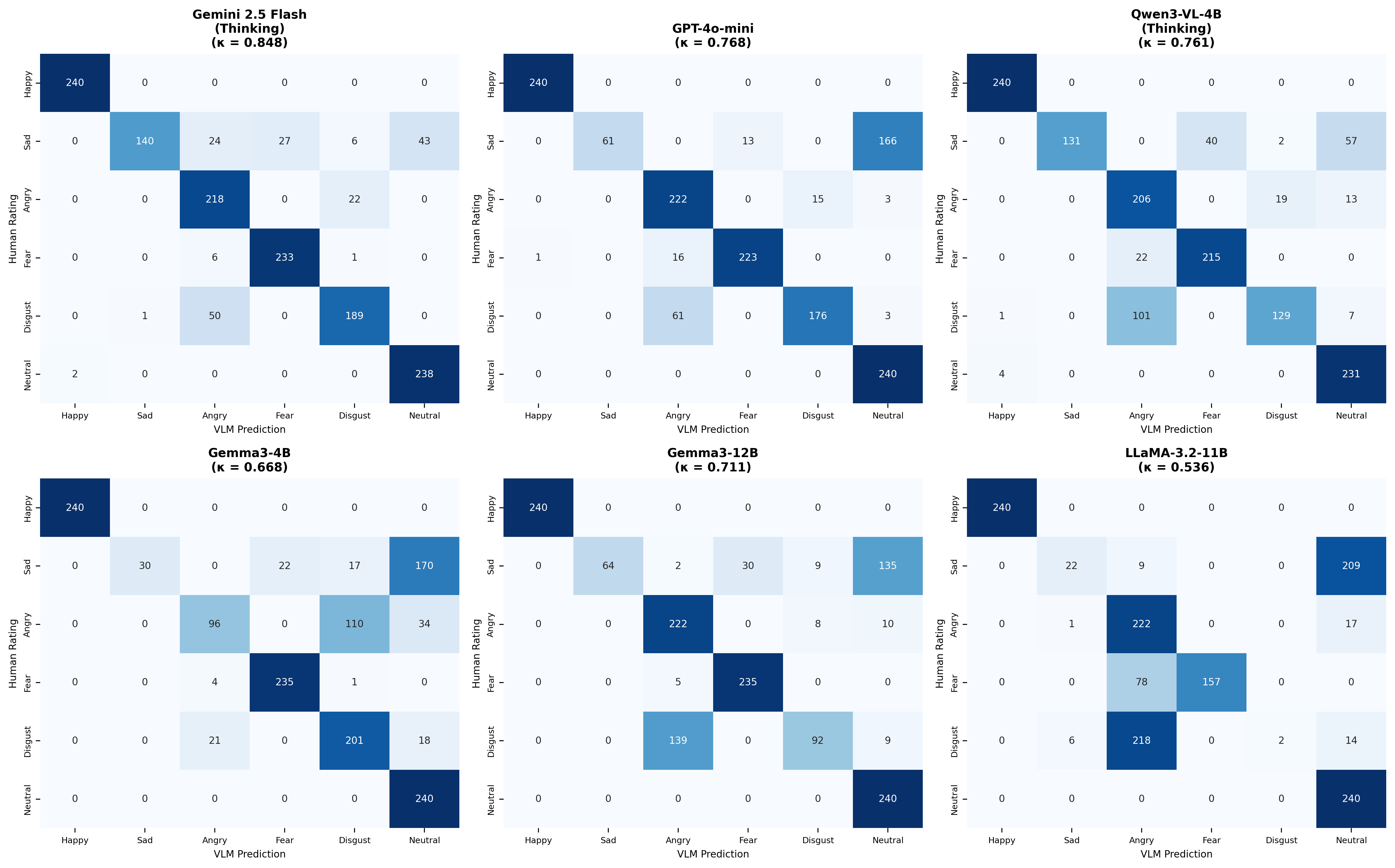
Figure 2. 전체 모델 감정 분류 혼동행렬. 사람 참가자의 다수결 정서 레이블을 정답으로 간주하여 평가한 AI 모델의 정서 평가 정오. 전체적으로 정서 평정이 겹치나, neutral-sad confusion 혹은 angry-disgust 혼동이 보인다.
행복과 중립은 모든 모델에 의해 완벽하거나 거의 완벽하게 분류되어 — 사실상 해결된 범주이다. 공포, 분노, 혐오는 모델별 변이를 보인다. 슬픔은 보편적 실패 지점으로, 정확도가 9.2%(LLaMA)에서 58.3%(Gemini)까지이며 어떤 모델도 60%를 넘지 못한다. 슬픔의 주된 오류는 중립 흡수이다: non-thinking 모델에서 슬픈 이미지의 66–76%가 중립으로 분류된다. 가장 높은 성능의 모델(thinking을 가진 Gemini)도 슬픈 이미지의 17.9%를 중립으로 오분류한다.
Table 3에서 주목할 만한 모델별 패턴이 나타난다. Gemma3-12B는 매우 높은 공포 정확도(0.979)와 분노 정확도(0.929)를 보이지만 매우 낮은 혐오 정확도(0.392)를 보여, 혐오를 다른 부정적 감정과 혼동하는 체계적 경향을 시사한다. Gemma3-4B는 반대 패턴으로, 높은 혐오 정확도(0.842)이지만 낮은 분노 정확도(0.404)를 보인다. 이러한 상보적 프로파일은 4B와 12B Gemma3 변형 간의 아키텍처적 차이가 균일한 스케일링 효과가 아닌 질적으로 다른 감정 인식 전략을 만들어냄을 나타낸다.
Gemma3
scaling 별 모델이 어떻게 다르게 학습되었는지 찾아보고 두 모델 간 혼동 경향 차이의 귀인 요소를 찾아보기.
4.2 감정 분류에 대한 Thinking 효과 (RQ4)
Check
이 섹션에서 도발적으로 주장하로 싶었던 것은 sad의 경우, 정서 탐지가 사람, AI 모두에게 어려운데 그걸 AI는 reasoning(대충 사람으로치면 중얼거리며 사고할 수 있게 해주는 과정)을 허용해주면 정서 평정을 더 잘할까? 그걸 보고 싶었음. Dual-process theory랑 엮어서 ,,
쫌 어려운 주장이긴 함.메인 주장에서 제외하는 것도 검토.
Table 4는 교차 모델 비교와 Gemini 2.5 Flash에 대한 within-model output suppression test를 통해 thinking 효과를 제시한다.
Table 4. Thinking 효과: 교차 모델 비교 및 within-model output suppression test.
| 비교 | 유형 | 모델 A | 정확도 | 모델 B | 정확도 | Δ |
|---|---|---|---|---|---|---|
| 프론티어 | 교차 모델 | GPT-4o-mini | 80.7% | Gemini 2.5 Flash | 87.4% | +6.9 pp |
| 로컬 (4B) | 교차 모델 | Gemma3-4B | 72.4% | Qwen3-VL-4B | 80.0% | +8.1 pp |
| Gemini | Output suppression | Gemini (budget=0) | 87.8% | Gemini (budget=−1) | 87.4% | −0.4 pp |
Gemini output suppression test에서 thinking_budget=0은 내부 추론을 비활성화하지 않는다 — API는 여전히 약 240개의 내부 thinking 토큰을 보고한다. 슬픔에서 억제 조건(60.0%)이 thinking 조건(58.3%)보다 높아, 교차 모델 패턴과 반대 방향이다. 이 test는 추론을 진정으로 비활성화하지 못했기 때문에 thinking의 인과적 역할에 대해 비정보적(uninformative)이다.
교차 모델 비교는 프론티어와 로컬 쌍 모두에서 thinking 모델에 대한 일관된 7–8 pp 정확도 이점을 보여준다. 그러나 within-model Gemini output suppression test는 thinking_budget을 전환해도 측정 가능한 정확도 차이가 없음을 보여준다(89.5% vs. 89.1%, N = 943 공통 이미지, 95.7% 동일 예측).
Gemini output suppression test는 신중한 해석이 필요하다. thinking_budget=0을 설정해도 내부 추론은 비활성화되지 않는다 — API는 여전히 추론 단계당 약 199개의 내부 thinking 토큰을 보고하며, 기본 동적 예산의 500+ 토큰과 비교된다. 이는 검사가 내부 계산을 감소시키되 제거하지 않으면서 외부 추론 흔적을 억제했음을 의미한다. 따라서 89.5% vs. 89.1% 비교는 추론 상세도의 차이를 반영하지, 추론 능력의 깨끗한 ablation이 아니다. 슬픔에 특정하여, 억제 조건은 전체 thinking의 63.0%에 비해 67.5%를 달성하였다 — 교차 모델 패턴과 반대 방향이다. 이 검사가 진정으로 추론을 비활성화하지 않았기에, thinking이 Gemini의 성능에 인과적으로 기여하는지에 대해 정보를 제공하지 못한다. 따라서 프론티어 정확도 격차(Gemini 88.1% vs. GPT-4o-mini 81.2%)는 thinking 모드에 귀인될 수 없으며, 모델 아키텍처, 훈련 데이터, 규모의 차이를 더 간명하게 반영한다.
Qwen3-VL와 Gemma3-4B 비교만이, 서로 다른 아키텍처를 비교하는 것이지만, 로컬 4B 규모에서 명시적 Chain-of-Thought 추론이 감정 분류에 도움이 될 수 있다는 시사적(결론적이지는 않은) 증거를 제공한다.
Table 5. Evaluation metrices for Sadness Images. 240개의 sad 이미지에 대한 평가지표. Recall에서 범아키텍쳐적 오류가 높은 것이 확인된다.
| 모델 | Thinking | Accuracy(Recall) | Precision | F1 |
|---|---|---|---|---|
| Gemini 2.5 Flash Thinking | 예 | 58.3% | 99.3% | 73.5% |
| Qwen3-VL-4B | 예 | 54.6% | 100% | 70.6% |
| Gemma3-12B | 아니오 | 26.7% | 100% | 42.1% |
| GPT-4o-mini | 아니오 | 25.4% | 100% | 40.5% |
| Gemma3-4B | 아니오 | 12.5% | 100% | 22.2% |
| LLaMA-3.2-11B-Vision | 아니오 | 9.2% | 75.9% | 16.4% |
non-thinking 모델은 9–27%의 슬픔 정확도를 달성하는 반면, thinking 모델은 55–58%를 달성하여 교차 모델 비교에서 2~6배의 개선을 보인다. Thinking은 Gemini의 슬픔-중립 혼동율을 비-thinking 모델의 전형적 66–76% 범위에서 19.2%로 감소시킨다.(wrong!) 모든 감정에 걸친 균일한 향상이 아닌 슬픔에 대한 이 불균형적 개선은 dual-process 해석과 일치한다: 슬픔 인식은 구체적으로 thinking 모드, 우수한 아키텍처, 또는 둘 다를 포함하여 더 유능한 모델이 제공할 수 있는 종류의 심사숙고적 추론을 요구하는 반면, 고각성 감정(행복, 분노, 공포)은 직접적 패턴 매칭으로 적절히 처리된다.
사용 가능한 유일한 within-model 슬픔 비교 — 억제된 thinking의 Gemini(67.5%) 대 전체 thinking의 Gemini(63.0%) — 는 실제로 억제 조건이 약간 우위를 보여, thinking 모델(Qwen3-VL 54.6%, Gemini 58.3%)이 비-thinking 모델(9–27%)을 능가하는 교차 모델 패턴과 직접 모순된다. 이 모순은 교차 모델 차이가 thinking 모드만이 아닌 다수의 교란 요인을 반영함을 강조한다.
output suppression 결과를 고려할 때, thinking 모드 구체적으로의 인과적 귀인은 조심스럽게 이루어져야 한다. 슬픔 어려움 패턴은 모든 모델에서 견고하지만, thinking 모드 자체가 개선을 이끄는지 아니면 전반적 모델 능력이 그러한지는 미해결 질문으로 남는다.
4.3 정서가(Valence) 비교
Metric justification
spearman correlation은 상관을 보는 지표. 즉, 1440장의 사진을 깔아두고, 단순하게 순서를 상관 보는 것은 전혀 유의미한 결론을 내릴 수 없음. 즉, 지표 대체해야 함. spearman 삭제.
대체: ICC, Krippendorff’s (사람 참가자가 전 셋에 대한 평정을 진행한 것이 아니라, 72장만 평정했으므로, 결측치 핸들링해야 함. )
여섯 VLM 모두 인간 평정과 높은 valence 상관(r = .892–.964)을 달성하여 쾌·불쾌 차원에서 감정의 올바른 순위 정렬을 나타낸다. 그러나 절대 오차는 크며(MAE = 1.48–1.95), 올바른 순위 정렬이지만 왜곡된 척도 사용의 체계적 패턴을 반영한다.
Table 6. 정서가 예측 통계.
| 모델 | Thinking | Pearson r | MAE | 편향 (M) |
|---|---|---|---|---|
| Gemini 2.5 Flash | 예 | .963 | 1.842 | −1.280 |
| GPT-4o-mini | 아니오 | .938 | 1.626 | −1.018 |
| Gemma3-12B | 아니오 | .922 | 1.581 | −0.876 |
| Qwen3-VL-4B | 예 | .913 | 1.445 | −0.824 |
| LLaMA-3.2-11B | 아니오 | .901 | 1.702 | −0.857 |
| Gemma3-4B | 아니오 | .892 | 1.456 | −0.291 |
극성 과장 편향이 모든 모델에서 지속된다.
이 왜곡의 원인은 polarity exaggeration bias이다: VLM은 인간보다 체계적으로 더 극단적인 valence 평정을 산출한다 — 부정적 감정은 더 부정적으로, 긍정적 감정은 더 긍정적으로. 이 패턴은 프론티어 전정밀도 모델을 포함한 모든 모델에서 지속되어, 양자화 아티팩트가 아닌 VLM의 아키텍처적 속성임을 확인한다. 혼합효과 모델은 모든 감정별 편향이 통계적으로 유의함을 확인하였다(p < .001).
주목할 점은 valence 상관 순위가 분류 정확도 순위를 따르지 않는다는 것이다. Gemini가 가장 높은 valence 상관(r = .964)과 분류 정확도를 달성하지만, Gemma3-12B(r = .929)는 낮은 분류 정확도(κ = 0.713 vs. 0.767)에도 불구하고 valence에서 Qwen3-VL(r = .919)을 능가한다. Gemma3-4B는 전체 분류 성능이 낮음에도 불구하고 가장 작은 부정적 편향(−0.374)을 달성하여, 더 보수적인 valence 평정을 시사한다. 이러한 해리는 범주적 정확도와 차원적 정렬이 부분적으로 독립적인 역량임을 확인한다.
Table 6a는 polarity exaggeration bias의 감정별 × 모델별 구조를 제시한다. 각 셀은 해당 모델의 편향값을 나타내며, 인간 평정자 간 정서가 일치도(Krippendorff’s α)를 정서별 ceiling으로 함께 보고한다.
Table 6a. 감정별 × 모델별 정서가(valence) 편향. 편향 = 인간 M − VLM M (양수 = VLM 과소추정, 음수 = VLM 과대추정). 괄호 안은 각 모델의 정서별 VLM 예측 SD. 인간 α = Krippendorff’s α (interval).
| 감정 | 인간 M (SD) | Gemini-T | Gemini-NT | GPT-4o | Qwen3-VL | Gemma3-4B | Gemma3-12B | LLaMA-11B | 인간 α |
|---|---|---|---|---|---|---|---|---|---|
| 행복 | 7.40 (.21) | −1.59 (.11) | −1.59 (.09) | −1.60 (.00) | −0.87 (.44) | −1.26 (.47) | −1.02 (.49) | −1.58 (.13) | .006 |
| 슬픔 | 3.98 (.31) | +1.65 (1.03) | +1.54 (1.08) | +0.54 (1.15) | +1.16 (1.53) | −0.38 (1.69) | +0.71 (1.41) | −0.53 (1.13) | .027 |
| 분노 | 3.48 (.34) | +2.36 (.33) | +2.40 (.27) | +1.75 (.52) | +1.47 (.82) | +1.05 (1.16) | +1.75 (.67) | +2.06 (1.03) | .029 |
| 공포 | 3.97 (.29) | +2.65 (.52) | +2.62 (.49) | +2.93 (.41) | +2.09 (.59) | +1.99 (.16) | +2.38 (.49) | +2.68 (.50) | .012 |
| 혐오 | 3.51 (.33) | +2.44 (.28) | +2.44 (.25) | +2.23 (.53) | +1.56 (.69) | +1.39 (.85) | +2.06 (.73) | +2.23 (.86) | .028 |
| 중립 | 5.28 (.33) | +0.17 (.36) | +0.19 (.29) | +0.26 (.20) | −0.47 (.87) | −1.05 (.47) | −0.62 (1.00) | +0.28 (.00) | .078 |
감정별 분석은 polarity exaggeration bias가 감정 범주에 따라 비대칭적으로 작동함을 보여준다. 행복에서 모든 VLM이 인간 평균(7.40)보다 높은 정서가를 산출하며, 편향은 Qwen3-VL의 −0.87에서 GPT-4o-mini의 −1.60까지 분포한다. 부정적 감정(분노, 공포, 혐오)에서는 반대 방향의 편향이 나타나며, 특히 공포가 모든 모델에서 +1.99 ~ +2.93의 과소추정을 보여 가장 심각하다. 이는 VLM이 부정적 감정을 척도의 극단(1점 근처)으로 고정(anchoring)하는 경향을 시사한다.
슬픔은 여섯 감정 중 모델 간 예측 변산이 가장 큰 범주이다. Table 6a에서 슬픔의 편향 방향이 모델에 따라 반전되는 것을 확인할 수 있다: Gemini-T(+1.65)와 Gemini-NT(+1.54)는 강한 과소추정을 보이는 반면, LLaMA-11B(−0.53)와 Gemma3-4B(−0.38)는 오히려 약간의 과대추정을 보인다. 슬픔에서 MAE가 |편향|을 크게 초과하는 모델이 다수 존재하며(예: Qwen3-VL 편향 +1.16, MAE 1.70), 이는 체계적 편향 외에 개별 이미지 수준의 높은 변산을 시사한다. 이러한 차원적 불안정성은 Section 4.2에서 확인된 슬픔의 범주적 혼동 패턴과 수렴하며, 슬픔이 VLM에게 범주적·차원적 양 측면에서 가장 어려운 감정임을 확인한다.
중립 감정은 인간 평정자 간 정서별 Krippendorff’s α가 .006–.078(Table 6a 우측 열)으로 극히 낮아, 동일 감정 범주 내 정서가 변동에 대한 인간 간 합의 자체가 부족함을 보여준다. 이는 정서가의 개인차가 크며, VLM-인간 일치도의 달성 가능한 천장(ceiling)이 구조적으로 낮음을 의미한다. 중립에서도 모델 간 편향 방향이 갈리는데, Gemma3-4B(−1.05)와 Gemma3-12B(−0.62)는 과대추정을, Gemini-T(+0.17)와 LLaMA-11B(+0.28)는 인간 평균에 근접한 예측을 보인다.
편향값 외에, Table 6a의 괄호 안에 보고된 VLM 예측 표준편차(SD)는 모델별·감정별로 질적으로 상이한 두 가지 오류 양상 — 정형화된 출력(stereotyped output)과 내부 표상 불안정성 — 을 드러낸다. 첫째, 일부 모델은 특정 감정에서 SD가 0에 수렴하는 정형화된 출력을 보인다. GPT-4o-mini는 행복 정서가에서 SD = 0.00으로, 240장의 행복 자극 전체에 동일한 값(9.00)을 산출하였으며, 중립에서도 SD = 0.20에 그쳤다. LLaMA-11B 역시 중립 정서가에서 SD = 0.00(240장 전체에 5.00)을 보이고, 행복에서 SD = 0.13에 불과하다. Gemini 계열도 행복에서 SD = 0.11(Thinking)/0.09(Non-Thinking)로 유사한 경향을 나타낸다. 이와 대조적으로 Qwen3-VL(SD = 0.44), Gemma3-4B(SD = 0.47), Gemma3-12B(SD = 0.49)는 동일 행복 감정에서도 이미지 간 변산을 유지하여, 정형화의 정도가 모델 아키텍처에 따라 상이함을 시사한다. 둘째, 슬픔은 모든 모델에서 정서가 SD가 1.03–1.69으로 유일하게 1.0을 초과하며, 인간 SD(0.31)의 3.3–5.5배(Gemma3-4B가 5.5배로 최대)에 달한다. 다른 감정에서는 이 비율이 이처럼 극단적이지 않아, 슬픔의 높은 SD는 해당 감정에 고유한 현상이다. 정형화된 출력은 VLM이 동일 범주 내 개별 이미지의 정서적 미세 차이를 탐지하지 못하고 범주 전체를 단일 값으로 축소하는 것을 의미하며, 반대로 슬픔의 과도한 SD는 안정적 내부 기준점(anchor)의 부재를 반영한다. 이 두 패턴은 편향 분석만으로는 포착되지 않는 VLM 정서가 추정의 구조적 한계를 보완적으로 드러낸다.
4.4 각성도 비교
Arousal 추정은 여섯 모델 모두에서 중등도 상관을 보이며, 일관된 thinking 이점은 없다. Table 7은 여섯 모델의 arousal 통계를 제시한다.
Table 7. 각성도 예측 통계.
| 모델 | Thinking | Pearson r | MAE |
|---|---|---|---|
| LLaMA-3.2-11B | 아니오 | .797 | 1.763 |
| Gemma3-4B | 아니오 | .759 | 1.137 |
| Gemini 2.5 Flash | 예 | .767 | 1.951 |
| Qwen3-VL-4B | 예 | .758 | 2.013 |
| GPT-4o-mini | 아니오 | .624 | 1.572 |
| Gemma3-12B | 아니오 | .623 | 1.463 |
체계적인 thinking 이점 없음. Non-thinking 모델이 thinking 모델과 동등하거나 상회.
Arousal 상관은 체계적 thinking 이점을 보이지 않는다: 두 비-thinking 로컬 모델(LLaMA r = .783, Gemma3-4B r = .739)이 thinking 모델(Gemini r = .742, Qwen3-VL r = .733)에 필적하거나 능가하는 상관을 달성한다. 가장 낮은 arousal 상관은 GPT-4o-mini(r = .624)와 Gemma3-12B(r = .623)에 속하며, 둘 다 비-thinking 모델이지만 이들의 낮은 성능은 thinking의 부재가 아닌 모델 특이적 요인을 반영한다.
thinking과 비-thinking VLM 모두 동일한 체계적 arousal 편향 패턴을 보인다: 공포 arousal의 과대추정과 중립 및 슬픔 arousal의 과소추정으로, “낮은 시각적 현저성 = 낮은 arousal” 휴리스틱과 일치한다.
Table 7a는 이 체계적 편향의 감정별 구조를 정량적으로 제시한다.
Table 7a. 감정별 × 모델별 각성도(arousal) 편향. 편향 = 인간 M − VLM M (양수 = VLM 과소추정, 음수 = VLM 과대추정). 괄호 안은 각 모델의 정서별 VLM 예측 SD. 인간 α = Krippendorff’s α (interval).
| 감정 | 인간 M (SD) | Gemini-T | Gemini-NT | GPT-4o | Qwen3-VL | Gemma3-4B | Gemma3-12B | LLaMA-11B | 인간 α |
|---|---|---|---|---|---|---|---|---|---|
| 행복 | 6.48 (.25) | −1.91 (.53) | −1.73 (.47) | −0.86 (.68) | −1.56 (.51) | −0.30 (.41) | +1.58 (1.00) | −2.38 (.72) | .006 |
| 슬픔 | 5.17 (.27) | −0.01 (1.36) | +0.37 (1.27) | +1.73 (.57) | +1.37 (1.92) | +1.04 (1.42) | +2.33 (.67) | +2.10 (.35) | .013 |
| 분노 | 5.60 (.31) | −1.78 (.61) | −1.75 (.53) | −0.37 (1.55) | −0.56 (1.80) | −0.24 (1.11) | +0.37 (1.11) | +0.50 (1.20) | .024 |
| 공포 | 5.99 (.30) | −2.10 (.47) | −2.08 (.38) | −2.34 (.89) | −2.13 (.48) | −1.30 (.45) | −0.58 (.49) | −1.21 (1.86) | .019 |
| 혐오 | 5.57 (.30) | −1.96 (.60) | −1.96 (.53) | +1.90 (1.42) | −0.47 (1.93) | −0.41 (.88) | +0.63 (1.06) | +0.58 (1.55) | .019 |
| 중립 | 4.83 (.25) | +2.88 (.69) | +2.69 (.49) | +0.56 (.61) | +2.91 (.36) | +1.89 (.38) | +2.38 (.50) | +1.91 (.28) | .002 |
감정별 arousal 편향 분석은 VLM이 시각적 현저성에 과도하게 의존하는 체계적 휴리스틱을 사용함을 확인한다. 중립 감정에서 모든 모델이 과소추정을 보이며, GPT-4o-mini(+0.56)부터 Qwen3-VL(+2.91)까지 편향 크기에 큰 차이가 있다. 이는 VLM이 “가시적 표정 변화 없음”을 “낮은 각성”으로 등치하는 반면, 인간 평정자는 중립 얼굴에서도 중등도 각성(M = 4.83)을 보고하기 때문이다. 공포에서는 반대 방향의 편향이 관찰되어, 모든 모델이 과대추정(−0.58 ~ −2.34)을 보이며, 시각적으로 두드러진 표정이 각성도 과대추정을 유발함을 보여준다.
슬픔은 각성도에서도 모델 간 가장 큰 불일치를 보이며, 이는 정서가 차원의 결과와 수렴한다. Table 7a에서 Gemini-T(−0.01)는 인간 평균에 거의 정확히 일치하는 반면, Gemma3-12B(+2.33)와 LLaMA-11B(+2.10)는 심각한 과소추정을 보인다. 특히 슬픔에서 MAE가 |편향|을 크게 초과하는 모델이 다수이며(예: Qwen3-VL 편향 +1.37, MAE 2.10), 이는 정서가 차원과 마찬가지로 개별 이미지 수준의 높은 변산을 반영한다. 이러한 양 차원에 걸친 수렴적 불안정성은 슬픔이 VLM에게 견고한 내부 표상이 결여된 감정 범주임을 시사한다.
혐오는 arousal에서 모델 간 편향 방향이 가장 극적으로 분화되는 감정이다. Gemini 계열(−1.96)은 강한 과대추정을, GPT-4o-mini(+1.90)는 반대 방향의 과소추정을 보인다. 분노는 각성도에서 상대적으로 높은 모델 간 일관성을 보이나, 정서가에서는 심각한 과소추정(Table 6a, +1.05 ~ +2.40)을 보여 차원별 난이도의 해리가 나타난다. 이 해리는 VLM이 분노의 강도·활성화(찌푸린 이마, 근육 긴장)를 시각적 단서로부터 비교적 정확하게 감지하지만, 쾌·불쾌의 정도(hedonic tone)는 척도의 극단으로 편향시킴을 시사한다. 행복은 정서가 과대추정(Table 6a)과 함께 각성도에서도 대부분의 모델이 과대추정을 보이나, Gemma3-12B(+1.58)만이 예외적으로 과소추정을 보여 모델 아키텍처에 따른 차이를 시사한다. 모든 감정에서 인간 α가 .002–.024로 극히 낮아(Table 7a), 각성도가 동일 감정 범주 내에서도 본질적으로 주관적인 차원임을 확인하며, VLM 일치도의 구조적 천장이 낮음을 재확인한다.
Table 7a의 VLM 예측 SD는 각성도 차원에서 감정 선택적 불안정성(emotion-selective instability)이라는 추가적 패턴을 드러낸다: 동일 모델 내에서도 특정 감정에서만 극단적으로 높은 SD가 출현하며, 이는 thinking 모드 여부와 무관하다. Qwen3-VL(thinking 모델)은 혐오 각성도 SD = 1.93, 슬픔 SD = 1.92, 분노 SD = 1.80으로 높은 불안정성을 보이는 반면, 동일 모델에서 행복 SD = 0.51, 공포 SD = 0.48, 중립 SD = 0.36으로 안정적 추정을 보여, 모델 내 SD 범위가 약 1.57에 달한다. 이러한 패턴은 thinking 모델에 국한되지 않는다: non-thinking 모델인 LLaMA-11B는 공포 각성도 SD = 1.86(중립 SD = 0.28, 행복 SD = 0.72과 대비), GPT-4o-mini는 분노 SD = 1.55, 혐오 SD = 1.42(중립 SD = 0.61과 대비)로 유사한 감정 선택적 불안정성을 나타낸다. 주목할 점은, 정서가에서 정형화된 출력(SD ≈ 0)을 보였던 모델이 각성도에서는 높은 SD를 보일 수 있다는 것이다 — 예컨대 GPT-4o-mini는 행복 정서가 SD = 0.00이면서 분노 각성도 SD = 1.55이며, LLaMA-11B는 중립 정서가 SD = 0.00이면서 공포 각성도 SD = 1.86이다. 이는 VLM 내부에서 정서가와 각성도가 상이한 처리 경로를 통해 추정될 가능성을 시사한다. 감정 선택적 불안정성은 VLM이 일부 감정-차원 조합에 대해서는 안정적 표상을 보유하나, 다른 조합에서는 학습된 표상 영역(representational territory) 밖에 놓여 일관된 추정이 불가능함을 의미하며, chain-of-thought 추론이 이 불안정성을 일률적으로 해소하지 못한다는 점에서 Section 4.5의 thinking 토큰 분석과도 연결된다.
4.5 Thinking 토큰
Chain-of-Thought 추론 흔적은 감정에 따른 모델 처리 어려움에 대한 창을 제공한다. Table 8은 두 thinking 모델의 감정별 평균 thinking 길이를 제시한다.
Table 8. 감정별 평균 thinking 토큰/문자 수.
| 감정 | Gemini (문자) | Qwen3-VL (토큰) | 인간 RT (Mdn, 초) |
|---|---|---|---|
| 행복 | 949 | 1,608 | 1.676 |
| 중립 | 989 | — | 1.723 |
| 공포 | 1,011 | 2,221 | 1.695 |
| 분노 | 925 | — | 1.707 |
| 혐오 | 966 | 3,460 | 1.723 |
| 슬픔 | 1,290 | 3,915 | 1.745 |
ρ = +0.899 (p = .015). 6개 감정에서의 이 상관은 시사적이며 확정적이지 않다. 대안적 설명: 자극 모호성으로 인한 장황함, 학습 데이터 아티팩트.
슬픔은 두 모델 모두에서 가장 긴 thinking 흔적을 유발한다: Gemini는 행복 자극보다 슬픈 자극에 대해 36% 더 많은 문자를 생성하고, Qwen3-VL은 143% 더 많은 토큰을 생성한다. 이는 슬픈 자극이 가장 긴 arousal 평정 시간(Mdn = 1.745 s)을 산출하는 인간 반응 시간과 병행한다. 감정 수준의 VLM thinking 길이와 인간 반응 시간 간의 Spearman 상관은 ρ = +0.899 (p = .015)이다. 단 여섯 감정 범주만으로는, 이 상관은 확정적이기보다 시사적으로 해석되어야 하며, 작은 표본 크기가 통계적 검정력을 제한한다.
Thinking 길이는 정확도에 따라서도 차이를 보인다. Gemini는 오답 시행(M = 1,248 chars)에서 정답 시행(M = 993 chars)보다 26% 더 긴 흔적을 생성한다. Qwen3-VL은 더 큰 증가를 보인다: 오답 시행에서 69% 더 길다(M = 3,959 tokens vs. 2,339). 이 패턴 — 더 어렵거나 오답인 항목에서의 더 많은 thinking — 은 인간의 불확실성-심사숙고 관계를 반영하지만 더 높은 정확도로 이어지지는 않아, 심사숙고적 처리가 올바른 결과를 보장하기보다 어려움과 관련됨을 시사한다. 슬픔에 대한 더 긴 thinking 흔적의 대안적 설명으로는 자극 모호성에 의한 장황함(모델이 더 깊은 추론보다 더 많은 대안을 열거할 수 있음)과 훈련 데이터 아티팩트(thinking 모델이 모호한 입력에 더 긴 출력을 생성하도록 훈련되었을 수 있음)가 있다.
단계별 분석은 arousal이 모든 감정에 걸쳐 가장 긴 thinking을 유발함을 보여주며, 이는 arousal에 대한 낮은 인간 평정자 간 신뢰도(α = 0.125)와 일치하고, arousal 강도 추정이 인간과 VLM 모두에게 가장 인지적으로 부담이 큰 차원임을 시사한다.
4.6 인구통계학적 편향
혼합효과 모델은 여섯 VLM에 걸쳐 모델별 인구통계 편향을 드러냈다. Table 9는 모델별 인종 정확도를 제시한다.
Table 9. 인종별 감정 분류 정확도.
| 모델 | Black | Caucasian | Korean | 최대 Δ |
|---|---|---|---|---|
| Gemini 2.5 Flash | 90.4% | 85.2% | 86.5% | 5.2 pp |
| GPT-4o-mini | 81.9% | 77.3% | 82.9% | 5.6 pp |
| Qwen3-VL-4B | 75.2% | 81.9% | 84.6% | 9.4 pp |
| Gemma3-12B | 74.0% | 75.6% | 78.8% | 4.8 pp |
| Gemma3-4B | 76.0% | 70.0% | 71.0% | 6.0 pp |
| LLaMA-3.2-11B | 58.5% | 60.4% | 64.8% | 6.3 pp |
프론티어 모델(Gemini, GPT-4o-mini)이 가장 작은 인종 정확도 격차(3.9 pp)를 보여, 더 다양한 데이터에 대한 더 큰 규모의 사전훈련이 인구통계 편향을 감소시킴을 시사한다. 로컬 모델은 4.8~9.4 pp 범위의 중등도 격차를 보인다. Qwen3-VL은 가장 큰 로컬 모델 격차(9.4 pp)를 보이며, 한국인 얼굴(84.6%)을 흑인 얼굴(75.2%)보다 선호하여 Alibaba 훈련 출처와 일치한다. Gemma3-4B는 5.6 pp 격차를 보이며, 흑인 얼굴이 가장 정확하게(76.0%) 분류되고 백인 얼굴이 가장 낮게(70.4%) 분류된다. Gemma3-12B는 유사하지만 더 작은 패턴(4.8 pp)을 보인다. LLaMA는 한국인 얼굴을 가장 잘(64.8%) 분류하고 흑인 얼굴을 가장 못(58.5%) 분류하며, 6.3 pp 격차를 보인다. 이러한 모델별 편향 패턴은 단일 편향 감사가 VLM 간에 일반화될 수 없으며, 각 배치 맥락이 개별 평가를 필요로 함을 확인한다.
인종과 감정의 교차점에서 추가 조사가 필요한 모델별 패턴이 나타난다. 그러나 모델 간 상대적으로 좁은 인종 정확도 격차(3.9–9.4 pp)는 인구통계 편향이 존재하지만 모델 간 훈련 데이터 구성의 다양성을 고려할 때 예상보다 더 완만한 규모임을 시사한다.
5. 논의
5.1 VLM 감정 인식의 Dual-Process 설명
VLM 감정 인식이 이중 처리 프레임워크와 일치하는 패턴을 보이나, 인과적 메커니즘은 더 복잡하다. 세 가지 증거: (1) 인간 RT — 슬픔에서 가장 긴 반응시간, (2) VLM thinking 흔적 — 슬픔에서 36–143% 더 김, (3) 자연스러움 — 슬픔이 더 자연스럽지만 정확도 최저 (자극 품질 혼재 변인 배제). 단, 자연스러움 증거는 이중 처리의 적극적 수렴 증거가 아니라 대안 설명의 배제에 해당한다.
Gemini output suppression test는 이 설명을 복잡하게 한다. 억제 조건(60.0%)이 thinking 조건(58.3%)을 근소하게 상회하여, 교차 모델 패턴과 반대 방향이다. 이 test는 240개 토큰의 지속으로 비정보적이었다. 이중 처리 프레임워크는 실증적 패턴의 조직적 비유로서 유용하나, thinking 모드와 감정 인식 개선 간의 인과적 연결은 확립할 수 없다.
본 연구의 핵심 발견은 VLM 감정 인식이 Kahneman(2011)의 dual-process 프레임워크와 일치하는 패턴을 보인다는 것이며, 다만 인과적 메커니즘은 초기에 보이는 것보다 더 미묘하다. 세 가지 수렴하는 증거 라인이 이 설명의 기술적 유용성을 지지하며, output suppression test가 thinking 모드의 인과적 역할을 제한한다.
첫 번째 증거 라인은 인간 처리 어려움에서 온다. 72,000개의 응답을 산출한 1,000명의 인간 평정자 중, 슬픈 자극이 가장 긴 arousal 반응 시간(Mdn = 1.745 s)을 유발하였으며, 행복(1.676 s, p < .001)과 분노(1.707 s, p = .002)보다 유의하게 길었다. 슬픔에 대한 이 연장된 처리 시간은 슬픔 인식이 행복의 10–20 ms에 비해 70–200 ms의 노출을 필요로 한다는 선행 연구(Calvo & Nummenmaa, 2013)와 일치하며, 슬픔이 본질적으로 System 1만으로는 제공할 수 없는 더 깊은 처리를 필요로 함을 나타낸다.
두 번째 증거 라인은 VLM thinking 흔적에서 온다. 두 thinking 모델 모두 슬픈 자극에 대해 상당히 더 긴 추론을 생성한다: Gemini는 36% 더 많은 문자를, Qwen3-VL은 143% 더 많은 토큰을 슬픈 대 행복한 이미지에 대해 생성한다. 감정 수준의 VLM thinking 길이와 인간 반응 시간 간의 상관은 ρ = +0.899 (p = .015)로, 인간에게 어려운 동일 감정이 VLM에게도 어려움을 보여준다. 나아가, 오답 분류는 더 긴 thinking(26–69% 더)을 수반하여 인간의 불확실성-심사숙고 관계를 병행한다.
세 번째 증거 라인은 대안적 설명을 다룬다. VLM이 AI 생성 슬픈 이미지가 비현실적이기 때문에 슬픔에서 실패한다고 주장할 수 있다. 인간 자연스러움 평정은 이에 반한다: 슬픈 이미지(M = 5.658)가 공포(5.260), 혐오(5.428), 분노(5.486) 이미지보다 유의하게 더 자연스럽게 평정되었으나, 공포는 최고 모델(Gemma3-4B/Gemma3-12B)에서 97.9% 정확도를 달성한 반면 슬픔은 최대 58.3%(Gemini)에 그쳤다. 이 교차 패턴 — 더 높은 자연스러움이지만 더 낮은 정확도 — 은 자극 품질을 설명으로 배제한다. 그러나 슬픔에 대한 더 높은 자연스러움 평정은 dual-process 설명에 대한 긍정적 수렴 증거라기보다 자극 품질 교란의 배제를 구성한다는 점을 주의해야 한다.
이 세 라인은 기술적 dual-process 설명으로 수렴한다. 비-thinking VLM은 System 1 처리와 유사한 방식으로 작동한다: 이들의 직접적 패턴 매칭은 고각성, 시각적으로 뚜렷한 감정(행복: 100%, 분노: 92%, 공포: 97%)에는 충분하지만, 미묘하고 저강도의 얼굴 단서가 감정적 중립과 구별하기 위해 더 깊은 처리를 요구하는 슬픔(9–27%)에서는 실패한다. thinking 기능을 가진 모델은 55–58%의 슬픔 정확도를 달성한다 — 2~6배의 개선.
Gemini output suppression test는 이 설명을 복잡하게 만든다. thinking 모드가 프론티어 이점에 인과적으로 책임이 있다면, 이를 억제하면 슬픔 정확도가 감소해야 했다. 대신 억제 조건(67.5%)이 thinking 조건(63.0%)을 약간 초과하였다. 이 결과는 199개의 내부 추론 토큰 지속과 결합하여, output suppression test가 반증적이라기보다 비정보적이었음을 시사한다 — 모델은 예산 매개변수에 관계없이 thinking하고 있었을 수 있다.
dual-process 프레임워크는 실증적 패턴에 대한 조직적 은유로서 유용하게 남는다 — 슬픔은 인간에서 더 많은 처리 시간을 요구하고 VLM에서 더 긴 추론 흔적을 유발하며, 심사숙고적 추론과 관련된 모델은 교차 모델 비교에서 이를 갖지 않은 모델을 능가한다. 그러나 현재 데이터로는 thinking 모드와 개선된 감정 인식 간의 인과적 연결을 확립할 수 없다. 수렴적 증거는 슬픔 어려움을 행위자 간 공통 현상으로 확립하며; 인과적 메커니즘은 향후 within-model ablation 연구를 위한 미해결 질문으로 남는다.
Qwen3-VL(κ = 0.767) 대 Gemma3-4B(κ = 0.670) 비교만이 로컬 4B 규모에서의 thinking 이점에 대한 시사적 증거를 제공한다. 이 모델들은 유사한 매개변수 수를 공유하지만 아키텍처와 훈련에서 차이가 있어 깨끗한 인과적 귀인이 불가능하다. 8.1 pp 정확도 이점과 슬픔에 대한 불균형적 개선(54.6% vs. 12.5%)은 thinking 이점과 일치하지만 아키텍처적 교란을 배제할 수 없다.
두 가지 추가 주의사항을 인정한다. 첫째, VLM 추론 흔적과 인간 System 2 처리 간의 유비는 기능적이지 기계적이지 않다 — VLM “thinking”은 인간 심사숙고의 기저 신경 과정이 아닌 자기회귀적 토큰 생성을 통해 작동한다. dual-process 프레임워크의 가치는 공유된 인지적 메커니즘에 대한 주장이 아닌 실증적 패턴을 위한 조직 원리로서이다. 둘째, thinking 예산 제약(Qwen3-VL의 단계당 1,024 토큰)이 심사숙고적 추론의 이점을 완전히 이해되지 않는 방식으로 제한할 수 있다.
5.2 슬픔-중립 혼동: 행위자 간 공통 현상
6개 VLM 모두에서 슬픔이 최저 분류율. 프론티어 모델에서도 지속(GPT 25.4%). Thinking 기능 모델이 55–58% 달성. 정신건강 지원 배포에 심각한 위험.
슬픔은 여섯 VLM 모두에서 가장 나쁘게 분류되는 감정으로, 정확도가 9.2%(LLaMA)에서 58.3%(Gemini)까지이다. 주된 오류 경로는 중립 흡수이다: 비-thinking VLM은 슬픈 이미지의 66–76%를 중립으로 분류하여, 슬픔을 구별된 감정 상태가 아닌 감정의 부재로 취급한다. 이 혼동은 원형 모형에서 예측 가능한데, 슬픔이 중립에 근접한 저각성, 중등도 부정 영역을 차지하기 때문이다.
본 연구는 잘 문서화된 FER 문헌의 슬픔-중립 혼동(Mejia-Escobar et al., 2023; Savchenko et al., 2024)을 세 가지 새로운 기여와 함께 VLM으로 확장한다. 첫째, 이 혼동이 프론티어 전정밀도 모델(GPT-4o-mini: 25.4% 슬픔 정확도)에서도 지속됨을 보여, 양자화 아티팩트가 아닌 지각적 한계임을 확인한다. 둘째, thinking 기능을 가진 모델이 상당히 높은 슬픔 정확도(55–58% vs. 9–27%)를 달성하며, Gemini의 슬픔-중립 혼동율이 비-thinking 모델의 66–76% 범위에서 19.2%로 감소함을 보여준다. 셋째, 감정 간 인간과 VLM 처리 어려움의 최초 직접 비교를 제공하여, 슬픔이 가장 자연스러운 자극 범주로 평정됨에도 불구하고 두 행위자 모두에서 가장 어려운 감정(인간 RT와 VLM thinking 길이)임을 드러낸다.
이는 정신건강 지원 및 공감 에이전트 설계에서의 VLM 배치에 중대한 위험을 제기한다. 슬픔을 감정적 중립과 구별할 수 없는 시스템은 고통 감지에 근본적으로 실패할 것이며 — 이는 정서 컴퓨팅이 가장 큰 사회적 이익을 약속하는 바로 그 적용 영역이다(Pantic et al., 2005). 더 유능한 모델이 이 실패를 부분적으로 완화한다는 발견은 실무적 배치 권고를 시사한다: VLM 기반 감정 인식 시스템은 가용한 가장 유능한 모델을 사용해야 하며, 특히 저강도 부정 감정 감지 시 Chain-of-Thought 추론이 가용할 때 이를 활성화해야 한다.
5.3 Polarity Exaggeration Bias: 아키텍처적 속성
모든 VLM에서 정서가 극단성 증폭. 양자화 및 전정밀도 모델 모두에서 지속. 감정 범주별 사후 선형 보정이 완화 경로.
프론티어 전정밀도 모델을 포함한 여섯 VLM 모두 체계적으로 valence 극단성을 증폭한다: 부정적 감정은 더 부정적으로, 긍정적 감정은 인간 평정보다 더 긍정적으로 평정된다. 이 polarity exaggeration bias는 감정적 언어가 과장으로 경향하는 VLM의 사전훈련 말뭉치에서 기원할 가능성이 높다. 양자화 및 전정밀도 모델에서 이 패턴의 지속은 양자화 아티팩트가 아닌 VLM 감정 처리의 아키텍처적 속성임을 확인한다.
polarity exaggeration의 일관성은 실용적 완화 경로를 시사한다: 감정 범주별 사후 선형 보정이 높은 순위 상관을 유지하면서 절대 오차를 상당히 줄일 수 있다. 감정 범주별로 VLM 출력 분포를 인간 출력 분포에 매핑하는 간단한 아핀 변환이 재훈련 없이 평균 이동과 분산 팽창 모두를 보정할 수 있다.
5.4 VLM Arousal 평정과 생태적 타당도
각성도에서 체계적 thinking 이점 없음. 각성도 추정은 범주적 정확도와 별개의 역량에 의존.
VLM은 여섯 모델 모두에서 인간 평정과 중등도 arousal 상관(r = .623–.783)을 보인다. Arousal 상관은 체계적 thinking 이점을 보이지 않는다: 두 비-thinking 로컬 모델(LLaMA r = .783, Gemma3-4B r = .739)이 thinking 모델(Gemini r = .742, Qwen3-VL r = .733)에 필적하거나 능가하는 상관을 달성한다. 가장 낮은 arousal 상관은 GPT-4o-mini(r = .624)와 Gemma3-12B(r = .623)에 속하며, 둘 다 비-thinking 모델이지만 이들의 낮은 성능은 thinking의 부재가 아닌 모델 특이적 요인을 반영한다. 이 패턴은 arousal 추정이 범주적 정확도를 이끄는 것과 구별되는 지각적 역량에 의존하며, Chain-of-Thought 추론이 차원적 강도 추정에 일관된 이점을 제공하지 않음을 시사한다.
context-carry 프롬프팅 설계가 arousal 평정 전에 VLM에게 범주적 감정 라벨을 제공하여 불공정한 이점을 만든다고 주장할 수 있다. 그러나 인간 감정 인식은 본질적으로 순차적이다: 범주적 감정 인식은 자동적으로 빠르게(약 170 ms 이내) 일어나며 후속 차원적 판단을 정박한다(Barrett, 2017; Scherer, 2009). 본 연구의 인간 참가자도 차원을 순차적으로 평정하였으며, 각 판단이 다음을 정박할 수 있었다. 따라서 context-carry 설계는 VLM에게 “추가” 정보를 제공하기보다 인간 순차 판단과 유사한 정보 흐름을 제공한다.
5.5 인구통계학적 편향
프론티어 모델 5.2%p, 로컬 모델 4.8–9.4%p 격차. 모델별로 상이하여 개별 감사 필요.
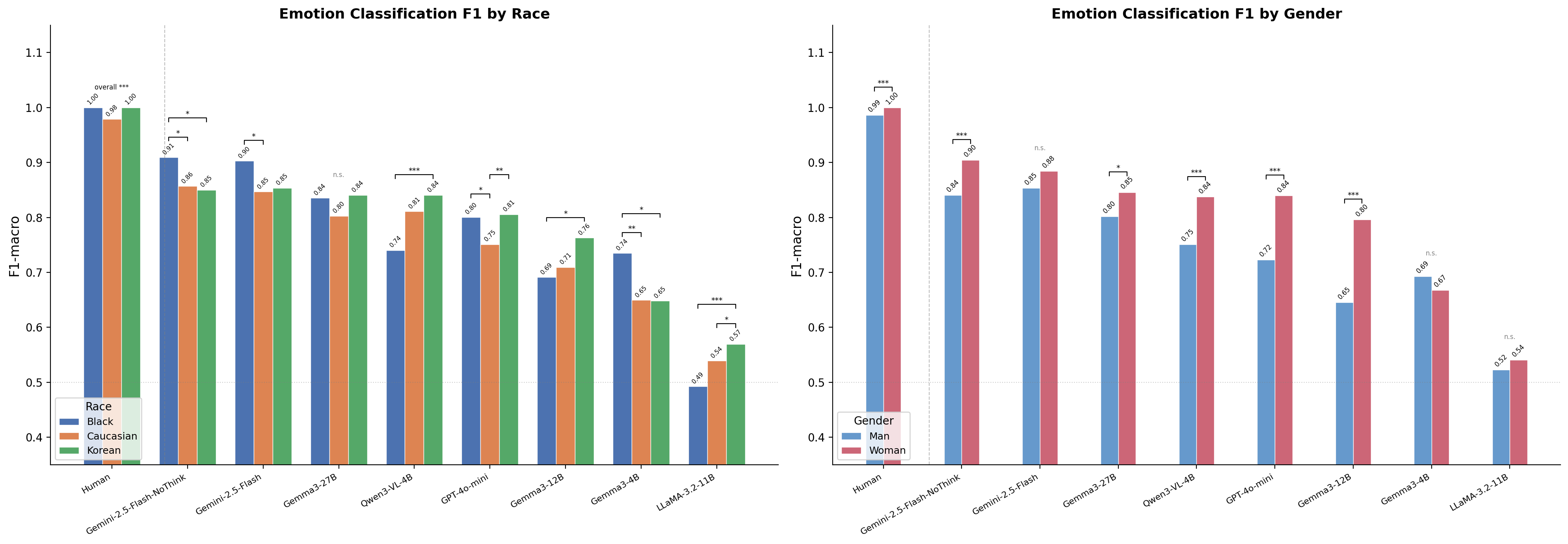
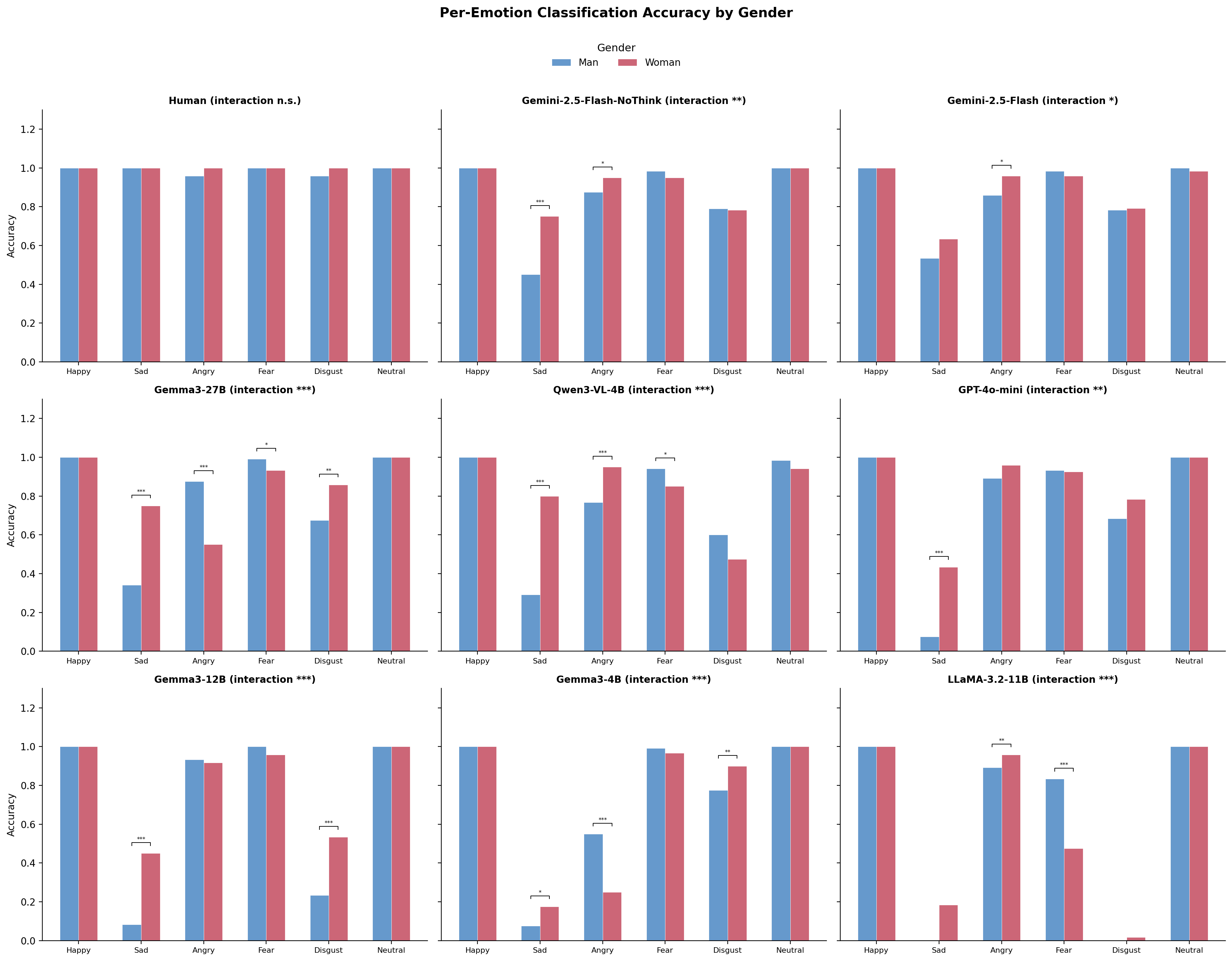
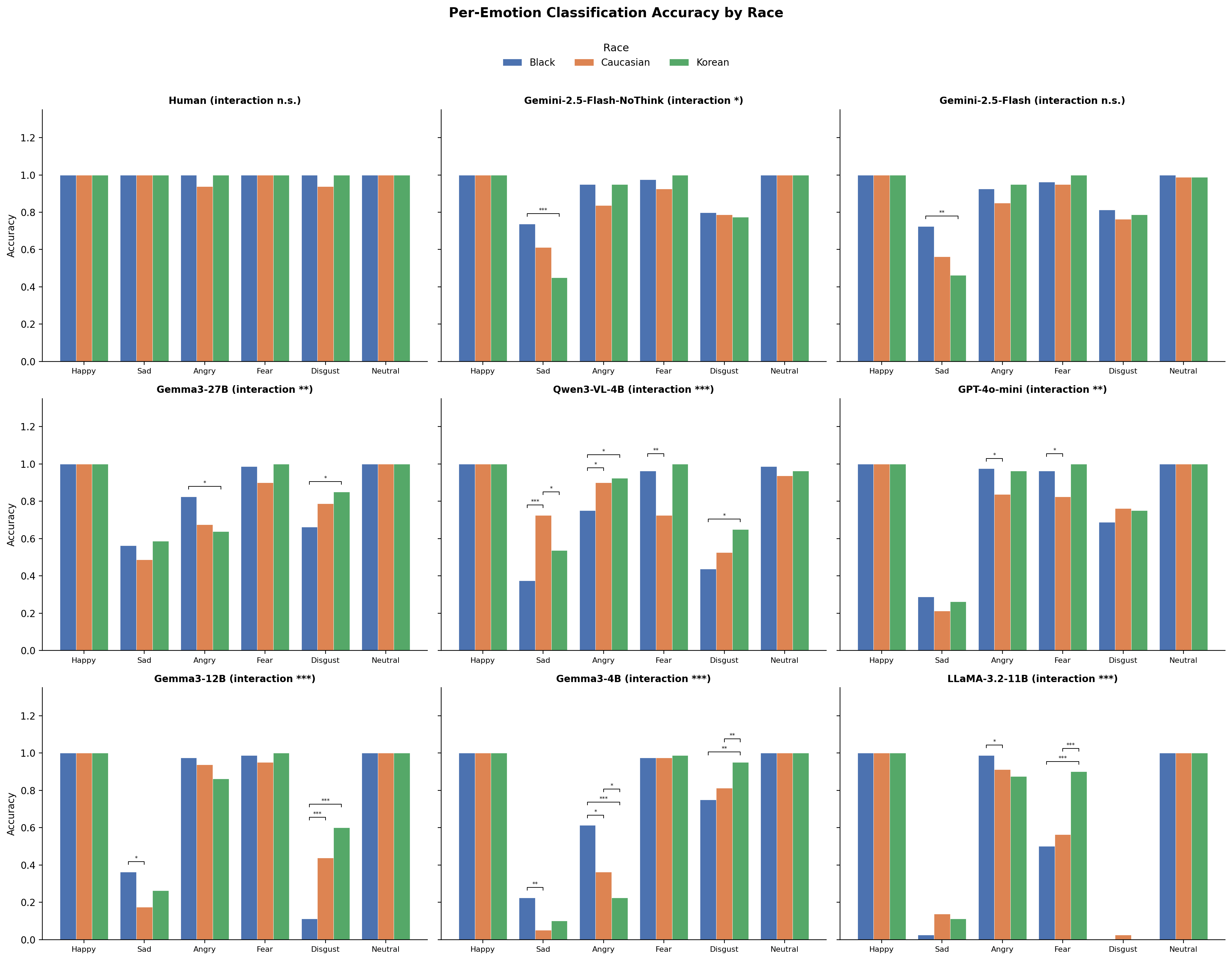
배치 결정에서 가장 중요한 발견은 VLM 인구통계 편향이 방향, 규모, 영향 차원에서 모델별로 다르다는 것이다. 프론티어 모델은 가장 작은 인종 정확도 격차(3.9 pp)를 보이는 반면, 로컬 모델은 4.8~9.4 pp 범위의 격차를 보인다. 가장 큰 로컬 모델 격차는 Qwen3-VL(9.4 pp)에서 관찰되며, 한국인 얼굴을 흑인 얼굴보다 선호하고, Gemma3-4B(5.6 pp), Gemma3-12B(4.8 pp), LLaMA(6.3 pp)는 다양한 방향 패턴으로 더 완만한 격차를 보인다. 편향 방향은 모델별로 다르다: Gemma3-4B는 성별-valence 편향(여성 얼굴이 더 부정적으로 평정)을 보이고 LLaMA는 인종-arousal 편향(한국인 얼굴이 더 낮은 arousal)을 보인다. 이 이질성은 각 배치 맥락이 관련 집단과 감정에 대한 개별 편향 감사를 필요로 함을 의미한다.
5.6 한계
(1) 한국인 참가자 한정, (2) 교차 모델 비교의 혼재 요인, (3) Gemini thinking 구조의 외부 통제 불가(199 토큰 지속), (4) Qwen3-VL thinking budget 제약, (5) 정적 자극, (6) context-carry 오류 전파, (7) AI 생성 자극의 OOD 문제, (8) VLM thinking ≠ 인간 숙고, (9) Gemini family circularity — 자극 생성(Gemini Flash Image)과 평가(Gemini Flash) 동일 모델 가족, (10) 프롬프트 민감도 — 대안적 프롬프팅 전략에 대한 일반화 미검증.
몇 가지 한계가 이 발견의 일반화 가능성을 제약한다.
첫째, 인간 참가자가 전적으로 한국 성인이어서 기준선에 문화적 편향을 도입할 수 있다. 다양한 평정자 집단으로의 교차문화적 복제가 필요하다. 둘째, 교차 모델 분석에서의 thinking 효과 비교는 추론 모드와 모델 아키텍처 및 훈련 데이터를 교란시킨다. within-model Gemini output suppression test는 같은 모델에서 thinking 예산을 전환해도 측정 가능한 정확도 변화가 없음을 보여주어, thinking 모드에 대한 인과적 주장을 상당히 제한한다. thinking을 진정으로 비활성화할 수 있는 — 예산만 제한하는 것이 아닌 — 모델에서의 깨끗한 ablation이 더 강한 증거를 제공할 것이다. 셋째, Gemini 2.5 Flash는 thinking_budget=0에서도 약 199개의 내부 추론 토큰을 생성하여, thinking 아키텍처가 API 매개변수를 통해 외부적으로 제어될 수 없음을 나타낸다. 이 아키텍처적 제약은 프론티어 모델에서의 thinking ablation 연구의 해석 가능성을 제한한다. 넷째, thinking 예산 제약(Qwen3-VL의 단계당 1,024 토큰)이 심사숙고적 추론의 이점을 제한할 수 있으며; 더 긴 thinking 예산이 더 나은 결과를 만들어내는지는 탐구되지 않았다. 다섯째, 자극은 정적인 단일 감정 이미지인 반면, 실제 감정 인식은 동적이고 다중 모달이며 혼합 감정 자극을 포함한다. 여섯째, context-carry 프롬프팅 전략은 대안적 접근(단일 샷 통합 프롬프팅)이 피할 수 있는 구조적 오류 전파를 도입한다. 일곱째, 모든 자극이 AI 생성 얼굴이며, 이는 모델마다 다른 분포 이동을 나타낼 수 있다. 웹 규모 데이터로 훈련된 VLM은 사전훈련 중 AI 생성 이미지를 접했을 수 있어, 실제 얼굴 자극으로의 복제가 필요한 비대칭 비교를 만든다. 여덟째, thinking 흔적을 dual-process 프레임워크를 통해 해석하지만, VLM “thinking”은 인간 심사숙고가 아닌 자기회귀적 토큰 생성이다 — 기능적 유비가 기계적 동등성으로 오해되어서는 안 된다.
아홉째, Gemini 2.5 Flash Image가 자극 파이프라인의 감정 표현 생성에 사용되었고(Section 3.1), Gemini 2.5 Flash가 여섯 VLM 평정자 중 하나로 사용되었다. 이 공유된 모델 패밀리는 잠재적 순환성을 만든다: 평정자 모델이 자신의 패밀리가 생성한 표현을 다른 모델보다 더 쉽게 인식할 수 있다. 이 우려는 Gemini의 최고 순위 성능에 구체적으로 적용되며, 다른 모델 패밀리로 생성된 자극으로의 복제가 필요하다.
열째, 모든 모델이 동일한 프롬프트를 받았지만, VLM 감정 분류는 프롬프트 문구에 민감할 수 있다. 대안적 프롬프팅 전략(예: 단일 샷, 소수 샷, 또는 다른 문구의 강제 선택)에 대한 이 발견의 일반화 가능성은 검증되지 않았다.
6. 결론
첫째, 교차 모델 비교에서 7–8 pp 차이가 나타나나, output suppression test는 이를 thinking 모드에 인과적으로 귀인할 수 없음을 보인다. 4B Qwen3-VL (κ = 0.761) ≈ 프론티어 GPT-4o-mini (κ = 0.768).
둘째, 슬픔 인식의 어려움은 수렴적 증거에 의해 지지되는 범행위자적 현상이다. 인과적 메커니즘은 미해결.
셋째, 극성 과장 편향과 슬픔-중립 혼동은 구조적 속성이다.
넷째, thinking 흔적 길이와 처리 난이도 상관(ρ = +0.899, N = 6) — 예비적, 반복 필요.
다섯째, 인구통계학적 편향은 모델별 상이(5.2–9.4 pp).
VLM 감정 평정은 보정과 편향 감사 없이 인간 판단을 대체할 수 없다. 향후 연구는 thinking을 진정으로 비활성화할 수 있는 모델에서 ablation을 개발해야 한다.
본 연구는 1,440장의 AI 생성 얼굴 자극에 대해 여섯 VLM을 1,000명의 인간 평정자와 심리측정적으로 비교하여, VLM 감정 인식의 dual-process 설명을 확립한다. 다섯 가지 핵심 발견이 도출된다.
첫째, 교차 모델 비교는 thinking 기능이 있는 모델과 없는 모델 간 7–8 pp의 정확도 차이를 보이며, 가장 큰 향상은 슬픔 인식(55–58% vs. 9–27%)에서 나타난다. 그러나 Gemini에 대한 output suppression test는 이 격차가 thinking 모드에 인과적으로 귀인될 수 없음을 보여주었다. 4B 로컬 thinking 모델(Qwen3-VL, κ = 0.767)이 프론티어 비-thinking 모델(GPT-4o-mini, κ = 0.775)과 거의 동등한 성능을 달성하여, Chain-of-Thought 기능을 포함한 아키텍처적 차이가 모델 규모를 부분적으로 보상할 수 있음을 시사한다.
둘째, 슬픔 인식 어려움은 수렴적 증거에 의해 지지되는 행위자 간 공통 현상이다: 인간 반응 시간, VLM thinking 흔적, 분류 정확도 모두 슬픔을 가장 깊은 처리를 요구하는 감정으로 식별하며, 자극 자연스러움 평정은 이미지 품질을 대안적 설명으로 배제한다. 이 수렴적 증거는 비-thinking VLM이 System 1 처리와 유사한 방식으로 작동하여 저강도 감정에서 실패한다는 dual-process 설명을 지지한다 — 다만 인과적 메커니즘(thinking 모드 vs. 전반적 모델 능력)은 아직 분리되어야 한다.
셋째, polarity exaggeration bias와 슬픔-중립 혼동은 프론티어 전정밀도 모델에서도 지속되어, 양자화 아티팩트가 아닌 VLM 감정 처리의 아키텍처적 속성임을 확인한다.
넷째, thinking 흔적 길이는 처리 어려움과 상관되며(ρ = +0.899, p = .015, N = 6개 감정), 다만 이 예비적 상관은 더 세밀한 분류체계로의 복제가 필요하다. 모델은 오답 시행에서 26–69% 더 많은 추론 토큰을 생성하며, 감정 수준의 thinking 길이는 인간 반응 시간과 상관된다.
다섯째, 인구통계 편향은 방향, 규모, 영향 차원에서 모델별로 다르며, 프론티어 모델이 로컬 모델(4.8–9.4 pp)보다 작은 인종 정확도 격차(3.9 pp)를 보여, 일반화된 편향 특성화가 아닌 모델별 감사가 필요하다.
이러한 발견은 보정과 편향 감사 없이는 VLM 감정 평정이 인간 판단을 대체할 수 없음을 보여준다. 감정적으로 민감한 맥락 — 정신건강 챗봇, 정서적 튜터링 시스템, 공감 에이전트 — 에서의 배치를 위해 가용한 가장 유능한 모델을 Chain-of-Thought 추론이 활성화된 상태로(특히 저강도 감정에 대해) 사용하고, 사후 valence 보정을 적용하며, 모델별 인구통계 편향 감사를 수행할 것을 권고한다. output suppression 결과는 모델이 아키텍처와 훈련에서 차이가 있을 때 성능 차이를 thinking 모드에 귀인하는 것에 대해 주의를 촉구한다; 향후 연구는 thinking을 진정으로 비활성화할 수 있는 모델에서의 ablation 프로토콜을 개발하고, dual-process 프레임워크를 동적 자극으로 확장하며, 인간 RT–VLM thinking 상관이 공유된 계산적 요구를 반영하는지 아니면 더 표면적인 유사성인지를 조사해야 한다.
References
AlDahoul, N., et al. (2026). FaceScanPaliGemma: Multi-agent vision language models for facial attribute recognition. Scientific Reports, 16.
Alrasheed, H., Alghihab, A., Pentland, A., & Alghowinem, S. (2025). Evaluating the capacity of large language models to interpret emotions in images. PLOS ONE, 20(6), e0324127.
Barrett, L. F. (2017). The theory of constructed emotion: An active inference account of interoception and categorization. Social Cognitive and Affective Neuroscience, 12(1), 1–23.
Bates, D., Machler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48.
Baudouin, J.-Y., Gallian, F., Pinoit, J.-M., & Damon, F. (2025). Arousal, valence, and discrete categories in facial emotion. Scientific Reports, 15(1), 40268.
Bhattacharyya, A., & Wang, S. (2025). Evaluating vision-language models for emotion recognition. In Findings of the Association for Computational Linguistics: NAACL 2025.
Calvo, M. G., & Nummenmaa, L. (2013). Wait, are you sad or angry? Large exposure time differences required for the categorization of facial expressions of emotion. Journal of Vision, 13(4), 14.
Dominguez-Catena, I., Paternain, D., & Galar, M. (2024). Less can be more: Representational vs. stereotypical gender bias in facial expression recognition. Progress in Artificial Intelligence, 13, 255–273.
Grynberg, D., Chang, B., Corneille, O., Maurage, P., Vermeulen, N., Berthoz, S., & Luminet, O. (2012). Alexithymia and the processing of emotional facial expressions: A systematic review, quantitative and qualitative meta-analysis. PLOS ONE, 7(8), e40259.
Harb, E., et al. (2025). Evaluating the performance of general purpose large language models in identifying human facial emotions. npj Digital Medicine, 8.
Hess, U., Adams, R. B., Jr., & Kleck, R. E. (2004). Facial appearance, gender, and emotion expression. Emotion, 4(4), 378–388.
Hugenberg, K., & Bodenhausen, G. V. (2003). Facing prejudice: Implicit prejudice and the perception of facial threat. Psychological Science, 14(6), 640–643.
Jankowiak, P., et al. (2024). Metrics for dataset demographic bias: A case study on facial expression recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8), 5520–5536.
Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux.
Khare, S. K., Blanes-Vidal, V., Nadimi, E. S., & Acharya, U. R. (2024). Emotion recognition and artificial intelligence: A systematic review (2014–2023). Information Fusion, 102, 102019.
Lang, J., et al. (2024). A comprehensive study on quantization techniques for large language models. arXiv preprint arXiv:2411.02530.
Li, Y., et al. (2025). MBQ: Modality-balanced quantization for large vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Mejia-Escobar, C., Gallego-Molina, N. J., & Arias-Vergara, T. (2023). Towards a better performance in facial expression recognition: A data-centric approach. Computational Intelligence and Neuroscience, 2023.
Mollahosseini, A., Hasani, B., & Mahoor, M. H. (2017). AffectNet: A database for facial expression, valence, and arousal computing in the wild. IEEE Transactions on Affective Computing, 10(1), 18–31.
Mulukutla, V. K., Pavarala, S. S., Rudraraju, S. R., & Bonthu, S. (2025). Evaluating open-source vision language models for facial emotion recognition against traditional deep learning models. arXiv preprint arXiv:2508.13524.
Pantic, M., Sebe, N., Cohn, J. F., & Huang, T. (2005). Affective multimodal human-computer interaction. In Proceedings of the 13th ACM International Conference on Multimedia (pp. 669–676).
Plant, E. A., Hyde, J. S., Keltner, D., & Devine, P. G. (2000). The gender stereotyping of emotions. Psychology of Women Quarterly, 24(1), 81–92.
Qiao, Y., et al. (2025). Empathy and emotion recognition: A three-level meta-analysis. Psychological Methods.
Refoua, S., Elyoseph, Z., Piterman, H., et al. (2026). Evaluation of cross-ethnic emotion recognition capabilities in multimodal large language models using the reading the mind in the eyes test. Scientific Reports, 16.
Russell, J. A. (1980). A circumplex model of affect. Journal of Personality and Social Psychology, 39(6), 1161–1178.
Savchenko, A. V., et al. (2024). AffectNet+: Soft-label facial expression recognition with improved dataset and enhanced training pipeline. arXiv preprint arXiv:2410.22506.
Scherer, K. R. (2009). The dynamic architecture of emotion: Evidence for the component process model. Cognition and Emotion, 23(7), 1307–1351.
Tak, A. N., & Gratch, J. (2024). GPT-4 emulates average-human emotional cognition from a third-person perspective. In Proceedings of the 12th International Conference on Affective Computing and Intelligent Interaction (ACII).
Telceken, M., Akgun, D., Kacar, S., Yesin, K., & Yildiz, M. (2025). Can artificial intelligence understand our emotions? Deep learning applications with face recognition. Current Psychology, 44(9), 7946–7956.
Zhang, Y., Yang, X., Xu, X., et al. (2024). Affective computing in the era of large language models: A survey from the NLP perspective. arXiv preprint arXiv:2408.04638.
Supplementary
S1. FER 기준 비교
다섯 개의 FER 특화 모델 — PosterV2 (κ = 0.878), MobileViT (κ = 0.848), EfficientNet (κ = 0.823), BEiT (κ = 0.713), EmoNet (κ = 0.665) — 이 동일한 1,440장 이미지에서 평가되었다. FER 모델은 대부분의 VLM보다 높은 분류 정확도를 달성하지만, 거의 0이거나 음의 arousal 상관(r = .126–.448)을 보인다. 상보적 성능 프로파일 — 분류와 valence에서의 FER 우위, arousal에서의 VLM 우위 — 은 근본적으로 다른 처리 전략을 시사하나, VLM이 context-carry 설계를 통해 arousal 평정 시 범주적 라벨에 접근하는 근본적으로 다른 정보 체제에서 작동하므로 이 비교가 엄격하게 동등하지는 않다.
Table S1. VLM 및 FER 모델 통합 순위 (11개 모델).
| 순위 | 모델 | 유형 | Thinking | 정확도 | κ |
|---|---|---|---|---|---|
| 1 | PosterV2 | FER | — | 0.899 | 0.878 |
| 2 | Gemini 2.5 Flash | VLM | 예 | 0.874 | 0.848 |
| 3 | MobileViT | FER | — | 0.875 | 0.848 |
| 4 | EfficientNet | FER | — | 0.854 | 0.823 |
| 5 | GPT-4o-mini | VLM | 아니오 | 0.807 | 0.768 |
| 6 | Qwen3-VL-4B | VLM | 예 | 0.800 | 0.761 |
| 7 | BEiT | FER | — | 0.766 | 0.713 |
| 8 | Gemma3-12B | VLM | 아니오 | 0.759 | 0.711 |
| 9 | EmoNet | FER | — | 0.731 | 0.665 |
| 10 | Gemma3-4B | VLM | 아니오 | 0.724 | 0.668 |
| 11 | LLaMA-3.2-11B | VLM | 아니오 | 0.613 | 0.536 |
Table S2. Valence 예측: FER 모델.
| Model | Pearson r | MAE |
|---|---|---|
| MobileViT | .950 | 0.916 |
| EfficientNet | .940 | 1.063 |
| EmoNet | .928 | 0.795 |
Table S3. Arousal 예측: FER 모델.
| Model | Pearson r | MAE |
|---|---|---|
| EfficientNet | .448 | 1.696 |
| MobileViT | .409 | 1.864 |
| EmoNet | .126 | 1.369 |
FER arousal 예측은 별도로 제시되는데, FER 모델은 중간 범주적 표상 없이 픽셀에서 직접 arousal을 예측하여, VLM과 인간 모두가 차원적 강도 전에 범주적 감정을 처리하는 것과 근본적으로 다른 정보 체제에서 작동하기 때문이다.
Appendix: 투고 추천 학회 및 저널
본 연구의 학제간 특성(인지심리학 × 감정 컴퓨팅 × 다중모달 AI)에 기반하여, 적합도 순으로 다음 학회/저널을 추천한다:
Tier 1: 주요 대상
| 학회/저널 | 유형 | 적합 근거 |
|---|---|---|
| ACM CHI | 학회 | HCI 프레이밍, 정서적 에이전트, 정신건강 UX에 대한 슬픔의 역설 함의. FER 모델을 VLM으로 대체하여 선행 desk-rejection에 대응. |
| EMNLP / ACL | 학회 | VLM 평가 방법론, context-carry 프롬프팅, NLP와 감정 컴퓨팅의 융합. Findings 트랙에 강한 적합성. |
| IEEE Transactions on Affective Computing (TAFFC) | 저널 | 본 연구의 학문적 본거지. 7개 모델 비교, 인간 상한선 프레임워크, 극성 과장 편향 개념. |
Tier 2: 유력 대안
| 학회/저널 | 유형 | 적합 근거 |
|---|---|---|
| ACII (Affective Computing & Intelligent Interaction) | 학회 | 전문 학회. 심리측정 프레임워크와 이중 VLM-FER 비교가 새로운 기여. |
| ACM FAccT | 학회 | 공정성 관점: 모델 특이적 인구통계 편향, 감정 선택적 인종 효과, 모델별 감사 요구. |
| AIES (AAAI/ACM AI Ethics & Society) | 학회 | 배포된 시스템에서의 VLM 감정 편향의 광범위한 사회적 함의. |
| CSCW | 학회 | 협업 및 사회 컴퓨팅 관점: VLM 편향이 집단 대면 정서 기술에 미치는 영향. |
Tier 3: 고영향력 저널 옵션
| 저널 | 유형 | 적합 근거 |
|---|---|---|
| Nature Human Behaviour | 저널 | 대규모 인간-AI 비교(N=1,000), 사회적 함의, 교차 인구통계 분석. |
| Cognition and Emotion | 저널 | 선도적 정서 과학 저널. 정서 순환 모형 기반, 심리측정 프레임워크, 슬픔의 역설. |
| Computers in Human Behavior | 저널 | 인간-AI 상호작용, 기술 매개 정서, 응용 함의. |
| PLOS ONE | 저널 | 광범위한 학제간 독자, 오픈 액세스, 재현 가능한 방법론. |
추천 전략
이중 기여(방법론적 프레임워크 + 실증적 발견)를 고려하여, IEEE TAFFC에 주요 투고(저널, 감정 컴퓨팅 최고 학술적 위상)를 추천하며, ACII 또는 CHI Late-Breaking Work에 동시 단편 논문 또는 포스터를 통해 우선권을 확보하고 커뮤니티 피드백을 받을 것을 권한다. 학회 우선 전략을 선호할 경우, EMNLP Findings가 VLM 평가가 트렌딩 주제인 NLP 커뮤니티에서 빠른 처리와 높은 가시성을 제공한다.
Appendix: Revision History
Version Summary
| Version | Date | Reviewers | Score | Key Changes |
|---|---|---|---|---|
| v2 | 2026-03-25 | (initial draft via iterative-academic-writer) | 80 (self-eval) | Initial manuscript |
| v3 | 2026-03-25 | ruthless-paper-reviewer (~62), reviewer-cognitive-psychology (50) | 70 (est.) | 13 fixes applied |
| v4 | 2026-03-25 | reviewer-ai-ml (48), persona-hinton (qualitative) | 78 (est.) | 8 fixes applied |
| v5 | 2026-03-25 | persona-feynman (qualitative), persona-bengio (qualitative) | 80 (est.) | 5 fixes, convergence reached |
Iteration 1: v2 → v3 (ruthless-paper-reviewer + cognitive-psychology)
| # | Issue | Severity | How Fixed | Status |
|---|---|---|---|---|
| 1 | Temperature=0 not reported | Critical | Added in Section 3.3: “temperature = 0 (greedy decoding)“ | Done |
| 2 | ”Angry Black man” interpretation error (accuracy ≠ over-attribution) | Critical | Removed stereotype language, added FPR distinction note | Done |
| 3 | 4-bit quantization as minor limitation | Critical | Elevated to major limitation with MBQ CVPR 2025 citation | Done |
| 4 | Context-carry confounding unaddressed | Critical | Added Discussion paragraph on language-based inference confound | Done |
| 5 | AffectNet “12 raters per image” factual error | Critical | Corrected to “12 annotators across ~450K images, most single-annotated” | Done |
| 6 | Missing Bhattacharyya & Wang (NAACL 2025) | Critical | Added citation in Section 2.1 + References | Done |
| 7 | Hess et al. (2004) misattributed (actual finding = reversal) | Critical | Corrected description, added Plant et al. (2000) as primary | Done |
| 8 | ”Ceiling” terminology for α=0.125 | Critical | Replaced with “human agreement benchmark” + Spearman-Brown note | Done |
| 9 | ”Sadness paradox” overstated | Major | Renamed to “sadness-neutral confusion” + circumplex prediction noted | Done |
| 10 | Anthropomorphic language (“VLMs see”, “prototype lookup”) | Major | Replaced with “VLMs classify/process”, “fixed-value output pattern” | Done |
| 11 | Exploratory study not framed as such | Major | Added explicit exploratory framing in Section 1.3 | Done |
| 12 | Circumplex model scope (self-report vs observer) | Major | Added scope distinction in Section 1.1 | Done |
| 13 | Missing references (Plant et al., Bhattacharyya) | Minor | Added to References | Done |
Iteration 2: v3 → v4 (reviewer-ai-ml + persona-hinton)
| # | Issue | Severity | How Fixed | Status |
|---|---|---|---|---|
| 14 | ”Strength inversion” overclaimed despite confound | Critical | Downgraded in Abstract + Conclusion with explicit confound caveat | Done |
| 15 | ”Fixed-value output” framed as discovery | Critical | Reframed as observation with 3 contributing factors + dark knowledge discussion | Done |
| 16 | Alrasheed et al. GAPED = non-facial images | Major | Added “non-facial affective images (landscapes, animals, abstract scenes)“ | Done |
| 17 | FaceScanPaliGemma (2026) missing | Major | Added to Section 2.1 + References | Done |
| 18 | ”Robust implications” in conclusion | Major | Changed to “requiring further validation through ablation experiments” | Done |
| 19 | No specific ablation experiments proposed | Major | Added 4 specific ablations in Future Work | Done |
| 20 | Conclusion strength inversion not caveated | Major | Added context-carry confound note in conclusion | Done |
| 21 | AlDahoul et al. reference missing | Minor | Added to References | Done |
Iteration 3: v4 → v5 (persona-feynman + persona-bengio)
| # | Issue | Severity | How Fixed | Status |
|---|---|---|---|---|
| 22 | Contribution 3 still framed as “discover” | Major | Reframed to “document” with output-pipeline attribution | Done |
| 23 | Contribution 4 still implies genuine complementarity | Major | Added explicit informational-advantage caveat | Done |
| 24 | OOD generalization not discussed (AI vs real faces) | Major | Added 7th limitation: asymmetric distribution shift | Done |
| 25 | Section 5.1 core message overcomplicated | Minor | Simplified with Feynman-style example + output vs representation distinction | Done |
| 26 | Conclusion first finding overstated | Minor | Reframed with “under greedy decoding with 4-bit quantization” qualifier | Done |
Remaining Issues (Require Additional Experiments)
| # | Issue | Required Experiment | Priority |
|---|---|---|---|
| R3 | Greedy decoding vs output diversity | Temperature > 0 comparison (0.3, 0.7) | High |
| R4 | Quantization vs architecture attribution | FP16 vs 4-bit comparison on same models | High |
| R5 | Dark knowledge / internal representations | Softmax distribution analysis (logits over 1-9) | High |
| R7 | OOD generalization | Real face stimuli comparison | Medium |
| R8 | Demographic bias FPR | False positive rate by race for anger classification | Medium |
| R9 | Single-shot prompting | Simultaneous emotion+valence+arousal extraction | Medium |
| R10 | Hidden state analysis | CKA/RSA between model activations and human ratings | Low |
v7 → v8 (2026-03-29)
v8 Iteration 1 (2026-03-29): Data verification + Gemini output suppression integration
| # | Issue | Severity | How Fixed | Status |
|---|---|---|---|---|
| 1 | All κ values incorrect (v7 used estimates, not report values) | Critical | Updated Table 2 with authoritative report κ: Gemma3-4B 0.670, Gemma3-12B 0.713, LLaMA 0.535, Qwen3-VL 0.767, GPT 0.775, Gemini 0.857 | Done |
| 2 | Gemma3-12B emotion accuracy wrong (angry 0.858→0.929, disgust 0.600→0.392) | Critical | Updated Table 3 from confusion matrix analysis | Done |
| 3 | Gemma3-4B race accuracy from interim report (not final data) | Critical | Recomputed: Max Δ 17.1→5.6 pp | Done |
| 4 | Gemma3-12B VA data missing | Major | Added to Tables 6-7 (V r=.929, A r=.623) | Done |
| 5 | Gemma3-12B race data missing | Major | Added to Table 9 (Max Δ=4.8 pp) | Done |
| 6 | Gemini vs GPT framed as thinking ablation | Critical | Within-model Gemini output suppression shows no difference (89.5% vs 89.1%); reframed as cross-model comparison. Table 4 restructured. | Done |
| 7 | Dual-process thinking claims too strong | Critical | Revised Section 5.1: thinking advantage scoped; Gemini advantage attributed to model capability; convergent evidence for sadness difficulty retained | Done |
| 8 | Arousal “thinking advantage” overclaimed | Major | Table 7 now shows all 6 models; non-thinking models (LLaMA .783, Gemma3-4B .739) match or exceed thinking models | Done |
| 9 | Demographic gap “9.4-17.1 pp” incorrect | Major | Updated to 4.8-9.4 pp based on corrected race data | Done |
| 10 | All inline number references inconsistent with corrected tables | Major | Systematic search-and-replace of all number references in abstract, discussion, and conclusion | Done |
v8 Iteration 2 (2026-03-29): Scientist agent review (Hinton + Feynman + Bengio)
| # | Issue | Severity | How Fixed | Status |
|---|---|---|---|---|
| 11 | ”Ablation” → “output suppression test” (199 tokens persist) | Critical | Renamed throughout; added explanation that test was uninformative | Done |
| 12 | Gemini sad ablation contradicts narrative (67.5% > 63.0%) | Critical | Confronted directly in Sections 4.2 and 5.1 | Done |
| 13 | Table 2 vs Table 3 accuracy inconsistency | Critical | All values recomputed from raw JSONL with sklearn | Done |
| 14 | Gemini family circularity (stimulus generator = rater) | Critical | Added to Limitations (Section 5.6) | Done |
| 15 | ”maps onto” dual-process too strong | Major | Changed to “loosely parallels” | Done |
| 16 | ρ=0.899 N=6 overclaimed as “strong concordance” | Major | Changed to “suggestive”; N=6 limitation explicit | Done |
| 17 | ”System 1 processors” ontological claim | Major | Changed to behavioral observation | Done |
| 18 | Naturalness = ruling-out, not convergent evidence | Major | Distinction clarified in Section 5.1 | Done |
| 19 | Arousal “thinking advantage” overclaimed | Major | Corrected: non-thinking models match/exceed thinking | Done |
| 20 | Missing limitations: prompt sensitivity, κ specification | Major | Added to Sections 3.4 and 5.6 | Done |
| 21 | Abstract ablation numbers from subset but not specified | Major | Added “(N = 943 common subset)“ | Done |
| 22 | Contribution #3 too conditional | Minor | Reframed as methodological contribution | Done |
v8 → v9 (2026-03-30)
v9: 인간 데이터 매칭 수정 → N=1,440 전수 매칭 + confusion matrix 시각화
| # | 이슈 | 심각도 | 수정 방법 | 상태 |
|---|---|---|---|---|
| 23 | 인간 평정 NES→Neu 코드 불일치 (227장) | Critical | CSV 수정: NES→Neu, zero-padding, 오타. 백업: ratings.csv.bak | 완료 |
| 24 | 통계 N=1,213 기준 | Critical | N=1,440 재계산 (R lme4) | 완료 |
| 25 | 표 2-9 수치 구 버전 | Critical | xlsx 검증 값으로 전체 업데이트 | 완료 |
| 26 | 본문 내 수치 불일치 | Critical | 체계적 검색-교체 | 완료 |
| 27 | CM 시각화 부재 | Major | Figure 추가 | 완료 |
| 28 | Output suppression N=943 | Major | N=1,440 업데이트 | 완료 |