실험은 크게 2 track으로 진행됨.
두 실험 모두 Lexical Decision Task(LDT) 계열로 disign.
두 실험 모두 between disign
두 실험 모두 단어들은 E-lexicon proj에서 LDT 데이터가 있는 단어들로만 구성되어야 집단 간 차이를 볼 수 있음.
E-lexicon proj에서 RT 있는 데이터 추출.
그래야 L1 English learner, L2 English Learner 간 차이를 볼 수 있음.
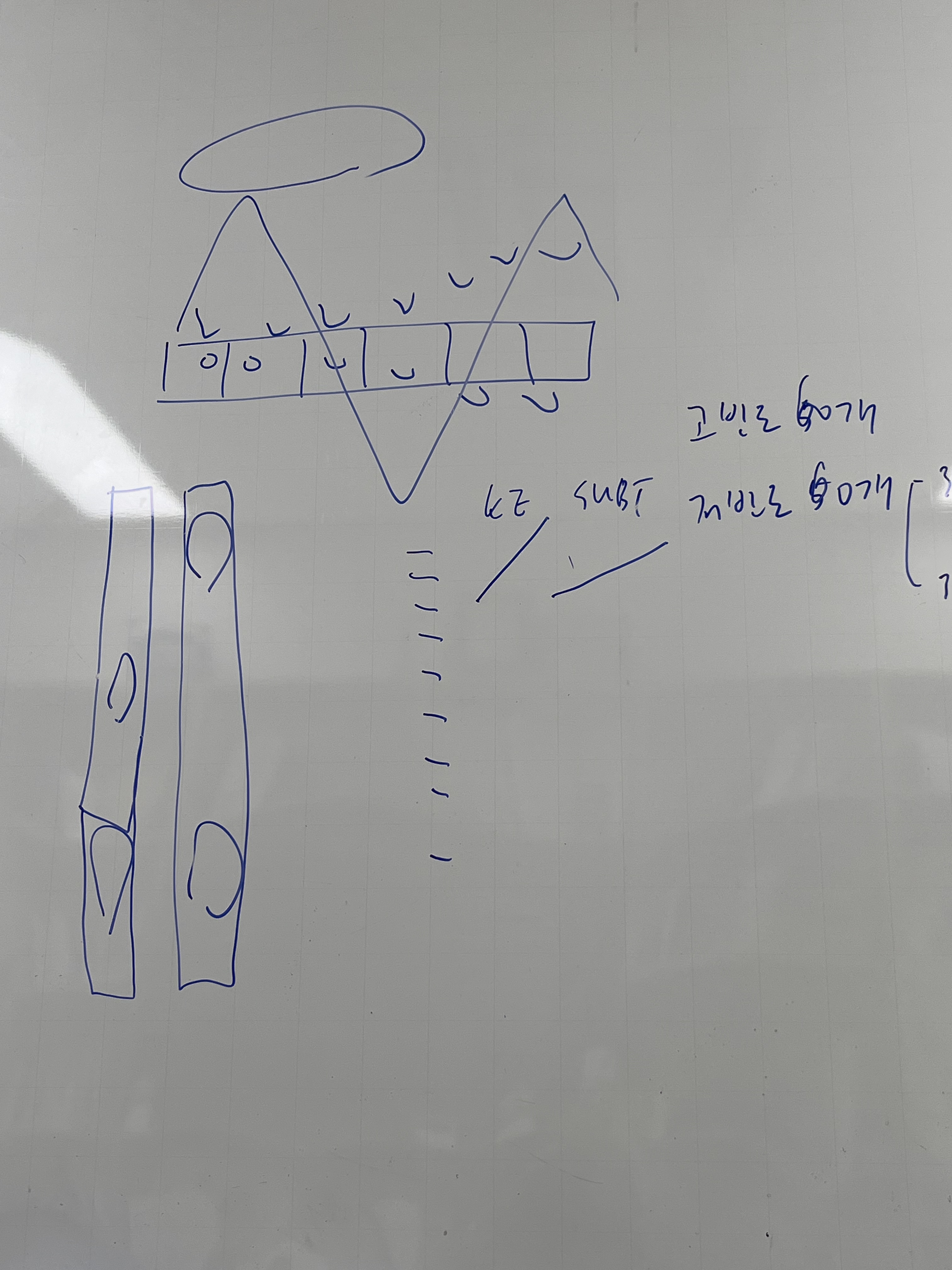
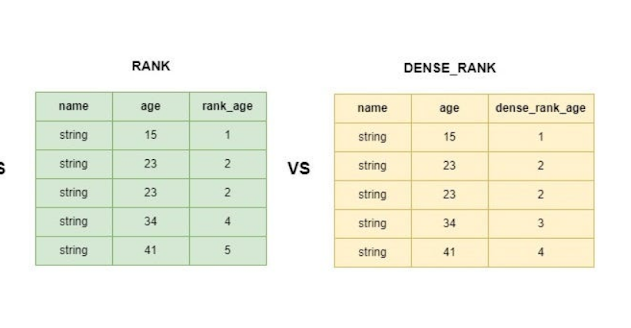
Tie-rank
동 순위를 처리하는 방법은 두가지로 나뉠 수 있는데,
Multi column
Competition-rank
left처럼 rank값의 jumping이 있다 즉, tie가 많아지면, 값 자체가 띄엄띄엄해진다.
Dense-rank
right처럼 rank가 균등한 간격.
tie가 아무리 많아도 분포 간격이 띄엄띄엄해지지 않는다.
Exp1 →
가설: KE가 SUBTLEX보다 L2 English learner의 RT를 더 잘 설명한다 (빈도 효과 검증)
단어는 SUBTLEX 기준 HF, LF 단어들 각각 40개 준비
단어는 SUBTLEX 기준 HF1, HF2, LF 단어들 각각 40개 준비
각각의 코퍼스에서 빈도 그룹 상 a.(고, 고),b.(고, 저), c.(저,저)로 구분되어야 함.
기준? percentile이 아닌, Zipf 기준으로 grouping
보고자 하는 것은 effect-size 즉
a-c: 빈도 효과의 크기 및 코퍼스 안정성
b: 그룹의 단어가 RT로 봤을 때 HF, LF 중 어디에 더 가깝게 취급되는지 비교하면 된다.
Zipf 에서 차이가 많이 나는 것을 골라 사용하면 좋을 듯.
word stimuli를 SUBTLEX에서만 추출한다.
단어 빈도의 번체 분포를 plot으로 그릴 것.
Exp2의 선정된 단어들에서 완전히 조건을 바꿔서 검색 후 부족한 부분만 추가로 선별.
Exp2 →전체 분포 빈도 설명력.
실험 가설: KE가 SUBTLEX보다 L2 English learner의 RT를 더 잘 설명한다. (RT-predictability)
고려 사항:
분석을 할 때, 기울기를 사용할 것이니, 빈도는 두 코퍼스 내에서 골고루 분포해 있어야 함.
고르게? → percentile이랑 Zipf를 모두 고려하자.
Zipf만 고려하면 안되는 이유?
: 코퍼스 규모 차이가 너무 심하기도 하고, 재미있는 비교 포인트는 SUBTLEX에서 Zipf3 미만 즉, KE에서 빈도로 구분이 불가능한 영역에 있는 단어들을 KE가 잘 설명할까 혹은 SUBTLEX가 잘 설명할까?
이 값을 기준으로 두 코퍼스에서 비슷한 값을 갖는 단어들만 선택한다면, 기울기 차이가 거의 안나겠지,,
따라서 Zipf의 용도는 단순히 SUBTLEX 기준으로 범위별 자극 개수만 고려하게 사용하는 것이 best : 이 값으로 양쪽 코퍼스에서 범위 통제하면 답 없다,,
percentile만 고려하면 안되는 이유?
: 단순 percentile만 고려하면 percentile에서 겹치는 단어가 없는 구간 발생.
두 코퍼스에서 유사한 percentile 값으로 적당히 추출.
그냥 SUBTLEX 빈도는 reliable하니까, 이걸 우선으로 기준 삼아 Zipf별 일정하게 뽑아서 사용하자.
상관에서도 높게 나온 부분이 있긴 하지만, 아마 저빈도 단어들에 대한 설명력은 좋지 못할 가능성이 있기 때문에 zipf 기준으로 어느 정도 단어들은 소규모 코퍼스에서 빈도가 덜 안정화되었다는 얘기를 참고문헌 인용하면서 얘기하면 좋겠지?
한번에 다 고려하는 것은 매우 힘듦. 따라서 일반적인 흐름을 따라가자.
양쪽 코퍼스에서 reliable한 구간의 단어들만 가지고 기울기 비교해보고,
극 하위 단어들은 따로 분석한다.()
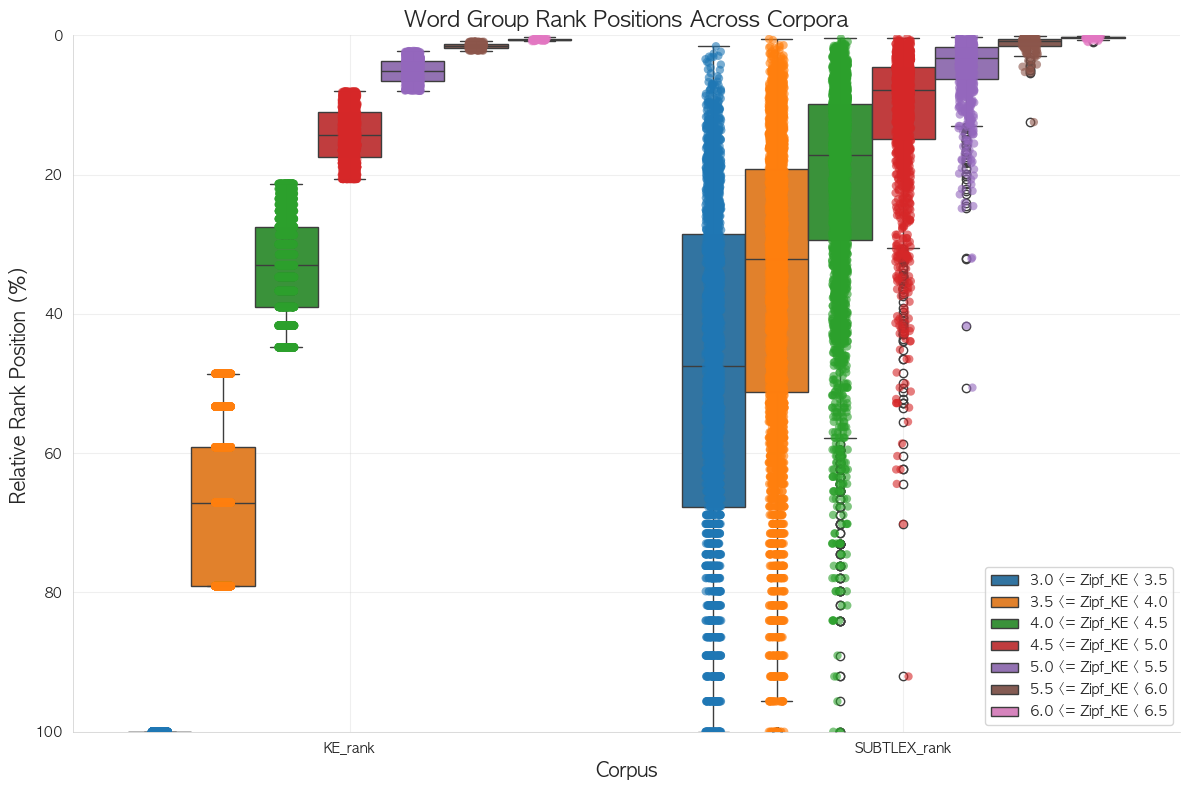
SUBTLEX, KE에서 단어들을 랭크 변환한 뒤, 비슷한 상대적 위치(상위 5%, 상위 25%) 구간에 공통적으로 있는 단어들을 대상으로 120개 (60, 60) 뽑을 것. ← 사실 연속적으로 되게()
Exp3(additional)
자극을 선정하며 든 생각은 KE corpus의 구조를 보면, 1빈도 및 극 저빈도 단어들이 매우 많은 걸 알 수 있는데 이는
가설1: L2 learner들이 극저빈도 단어를 잘 구분하지 않는데, 이가 반영된 것.
가설2: 단순히 코퍼스 규모의 차이
만약 가설1이 옳다면, L2 RT를 더 잘 설명하는 것은 KE에서 거의 동빈도 처리한 것들이 아닐가?
SUBTLEX에서는 구분되지만,
Rank-Freq Distribution(tie →competition-rank)
Multi column
Rank-Freq Distribution
Comment
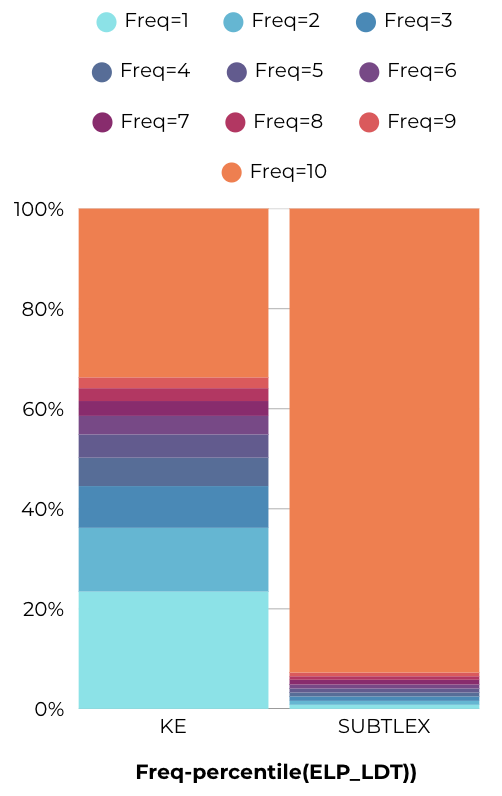
KE에서 Freq=1인 단어들이 전체 stimuli 후보군 중 약 22%로 너무 많다. 그래서 ordering을 다하고, 이를 percentile 기준으로 pie를 나눠가진다면 KE 하위 20% 구간의 단어들은 해상력이 떨어진다.(다 빈도가 1이니까.)
그러므로, 단어를 추출할 때에는 KE freq=1 인 구간에서 단어가 적게 뽑혀야 하므로, percentile을 그대로 사용할 수는 없다.
또한, tie 처리를 해야 한다.(revised)
KE에서 1빈도 단어들이 전체 word-type의 약 20%를 넘게 차지하기 때문에 실험 자극을 percentile로 추출할 거라면, 이 경우, KE 기준 77%~100% 구간의 단어들은 모두 동일한 1 빈도 단어이어서 해당 구간에서 등간격으로 단어를 추출할 수 없음. → 이 경우에는, dense-rank를 사용해야 함.
위처럼 competitive한 rank 사용 시에는 KE 상위 77~100% 구간에는 순위 정보가 없으니,,
(모두 1 빈도 단어들이니,,)
Multi column
Rank-Freq Distribution
Rank-Range
Words
0 ⇐ SUBTLEX_rank < 10
10
10 ⇐ SUBTLEX_rank < 20
0
20 ⇐ SUBTLEX_rank < 30
0
30 ⇐ SUBTLEX_rank < 40
2
40 ⇐ SUBTLEX_rank < 50
2
50 ⇐ SUBTLEX_rank < 60
5
60 ⇐ SUBTLEX_rank < 70
11
70 ⇐ SUBTLEX_rank < 80
13
80 ⇐ SUBTLEX_rank < 90
82
90 ⇐ SUBTLEX_rank < 100
5177
Comment
SUBTLEX 기준으로 percentile만 10%씩 쪼개고, 각 단어별 오차 5%를 허용해서 살아남은 단어들만 plot한 결과.
단어들을 percentile 위치가 상당히 다름. → 전체적인 빈도 분포 볼필요가,,(아래 plot 참조.)
즉, 한 빈도 값 차이별, rank 값은 각각, 100/496 vs 100/2936으로 SUBTLEX가 더 촘촘하다.
dense tie처리하면서, 100% 위치에는 Freq_KE=1인 단어들만 위치하니, KE기준 99.xx 위치에 있는 단어들은 Freq_KE=2인 단어들일 것이다. 즉, percentile에서 보면, 하위 단어들 구간에서 압축이 발생해서 고빈도 단어 구간이 늘어났다.
SUBTLEX의 경우, 대규모 코퍼스이다보니, 빈도 값 자체의 종류도 많으니, 구간 사이가 촘촘할 수 있지만, 이에 반해 KE는 소규모라 빈도 값 자체의 종류가 많지 않음. 496 vs 2936.
촘촘함 즉, 해상력의 차이가 있어서 dense, competitive 둘 모두 문제가 있는 듯.
SUBTLEX-Zipf 기준으로 단어 분포
Multi column
Plot
Dense-rank
Comment
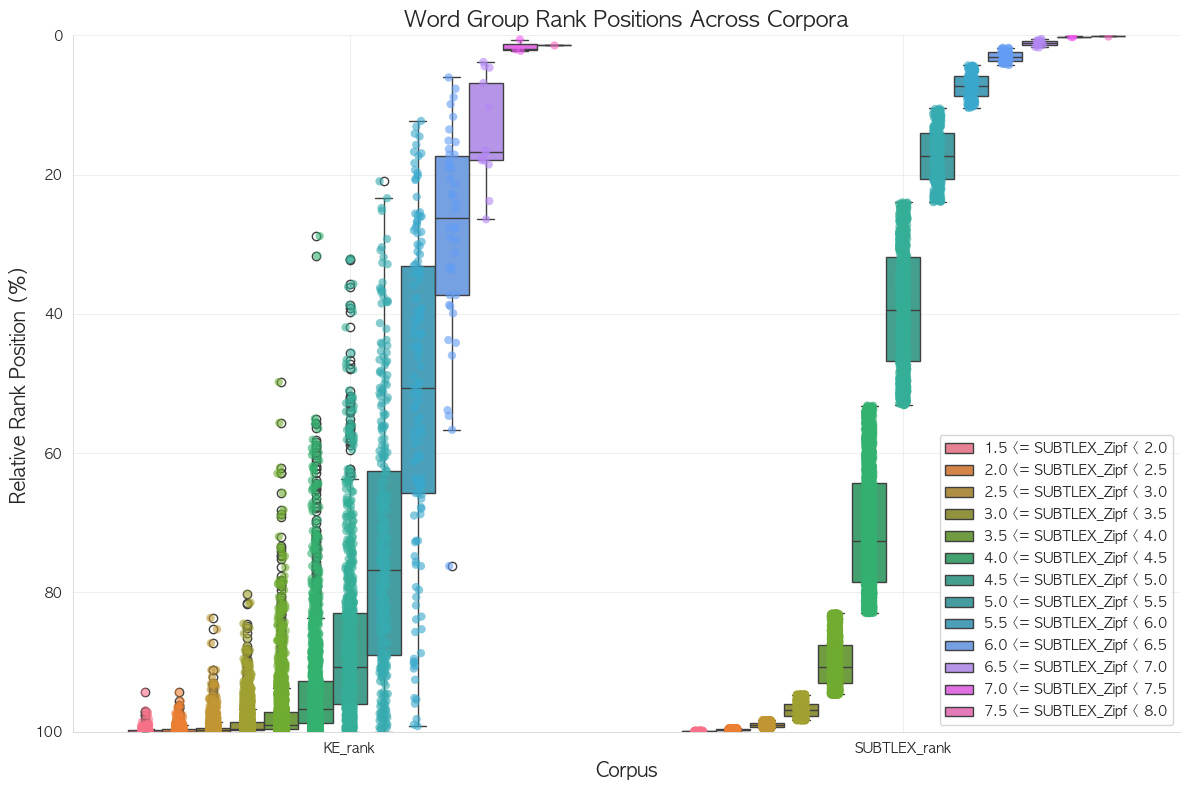
SUBTLEX 기준 구간 별 단어를 전체적으로 그려보면 다음과 같다.
전체적으로 빈도 범위가 다르게 잡힌 단어들도 꽤 있음을 볼 수 있다.
대충봐도 box 자체가 겹치지 않는 label도 있으니, 위의 결과와 맞물려 생각해보면,
tie를 ‘dense’로 적용하면 percentile이 겹치지 않는다. 특히 가운데 구간에서
두 plot 모두 현재 16k 개의 단어를 그리고 있는데, KE에서는 하위 구간(hapax)에서 압축이 일어나서 전체적인 percentile이 내려감.
Summary-Percentile 접근
tie == ‘competition’
→ KE 하위 구간 단어들에 대한 설명력=0(너무 많은 1빈도 단어들)
tie == ‘dense’
단어들의 percentile은 겹치지 않으므로, 사용할 수 없다.
결론: percentile을 맞추는 것은 고려 x
애초에 중요했던 것은 단어들이 코퍼스를 고르게 대표할 수 있으면 되기에, Zipf로 적당히 구간별 나눠 맞추자.
지금 단어 뽑을 때, ordering이 중요하니, 두 그래프에서 단어들은 대략 비슷한 ordering을 가져야 함.
KE에서 각 그룹별로 IQR에 들어가는 것만 살려보자. ← Tukey fence로 완화.
그러면 아래와 같이 후보군이 추려짐.
(중간에 사라진 Zipf 범위는 아래 LDT-Data Analysis 참조.)
Multi column
Plot
Dense-rank
Competitive-rank
Comment
위 그래프 즉, SUBTLEX 기준 Zipf 정렬 후, KE에서 각 range별 IQR내 단어들만 살린 그래프
결국 정리하면 두 tie-method 모두 문제는 있지만, 0~100% 구간에 해당하는 rank 값 자체를 모두 사용할 수 있는 건, dense라 이 방법 사용.
이 이후?
다시 SUBTLEX 기준으로 적당히 등 간격으로 추출.
Zipf-score 기준으로 하여 word stimuli 뽑아두기, 구간별,
이를 사용해서 R2 및 회귀 분석 돌려서 coeff 값의 크기를 보려고 하는데,
HF, LF를 나누지 않고 연속 변수 취급할 건데,
이 역시 L1, L2 learner 간 차이를 어떻게 더 잘 보여줄 지가 관건이겠네.
→ 하나의 실험으로 합치기!(25-09-25)
Exp-latest
데이터를 보면서 든 생각은 구간을 좀 더 촘촘히 해야한다.
Zipf 변환이 결국 10억 단어 기준 상대 빈도를 log-transformation
우리 코퍼스가 80만인데, 여기서 1빈도는 → 10억에서 103 빈도 정도로 잡힘.
즉, 전에 가져갔던 Zipf-correlation 에서 Zipf=3는 애초에 의미가 있다고 보기 힘듦.
좀 더 자세히 말하자면, SUBTLEX 기준으로 Zipf 기준 정렬해갔는데, SUBLTEX-Zipf는 값이 3이하로 떨어질 수 있는데, KE에서는 그럴 수 없으니, 음의 상관이 나오고 HAL은 더 크니, 상관이 잡힐 수 있는 거지!!!
따라서 유의미한 부분을 제시하려면 우리 상관이 높았던 그거만 보여주면 됨~
결론: Zipf-score는 규모 차이가 나는 코퍼스 간 돌리면 안 됨.(corpus size 고려해서 margin 잘 잡아라. ) KE 같은 경우에는, lower-bound가 3.14정도.
기존 Exp1에서 보여주려던, 그 범위 plot은 별도의 정의 사용해서 해주면 될 것 같고, log는 10 base 사용하자.
각 코퍼스 간 고빈도, 저빈도를 어떻게 정의할 것인가?
각 코퍼스 내 rank 기준?
코퍼스 간
고민을 좀 해봤는데, 아무래도 KE에서 Zipf의 lower bound가 3.X이니, 그 위에서만 rank매기고 비교하는게 맞을 것 같다. 그래야 정당할 거 같고 어려운 해석이 개입할 여지가 없음. → Zipf 정의를 완전히 받아들인다는 거지.
percentile 접근으로 돌아갈 거고, 위 아래, 컷 오프 할거야.
이 때, 이 percentile 정보는 각 코퍼스에서의 정보로 LDT_data를 따로 추출하기 전에 적용.
연속형 변수로 만들고 싶으니까,
Tie-Rank 처리
KE 같은 경우, 저빈도 단어들(Freq=0, 1, 2..)같은 단어들이 전체 어휘(word type)의 상당 부분을 차지한다. 따라서 이를 rank처리할 때 고민해봐야하는데, dense가 권장됨.
dense: 공동 1등, 그 다음, 그다음이면, 1, 1, 2, 3 으로 rank.
competition: 동일한 상황에서 1, 2, 3, 4로 rank.
동순위가 많은 distribution일 경우, dense 처리하지 않으면 상대 위치 정보가 많이 손실
예를 들어 Freq=1인 단어가 전체 word type의 23%를 차지한다면, KE 코퍼스 상위 77%~100% 구간은 모두 빈도 1인 단어이니, 이 pie에 해당하는 구간은 상대 순위 정보가 의미 없음.
이 역시 dense 처리한다면, 그래프 한 축으로도 사용할 순 있을 듯,
다만 추가적으로, 실험자극으로 쓰일 단어들이 hapax내에 너무 많이 있으면 안 됨.
ELP-LDT data
현 실험을 준비하기 위해서 ELP에서 단어를 뽑을 건데, 기준으로 아래와 같음.
KE, SUBTLE에서 모두 빈도가 1 이상일 것.
ELP에서 LDT-RT data가 있을 것.
Rank 처리
각각의 코퍼스에서 1이상 빈도 들의 단어에 대해 ordering(descending)
이떄, tie는 동순위 처리하고, 순위값은 avg처리
이후, 각 코퍼스에서 max-rank 값을 기준으로 standardization
따라서 각 코퍼스별 순위의 범위는 0~100%로 fixed.
특이점으로 KE의 경우, 1빈도인 단어가 많으니, 100%에 해당하는 단어의 개수가 많음.
위 조건을 만족하는 단어들은 총 15,995개.
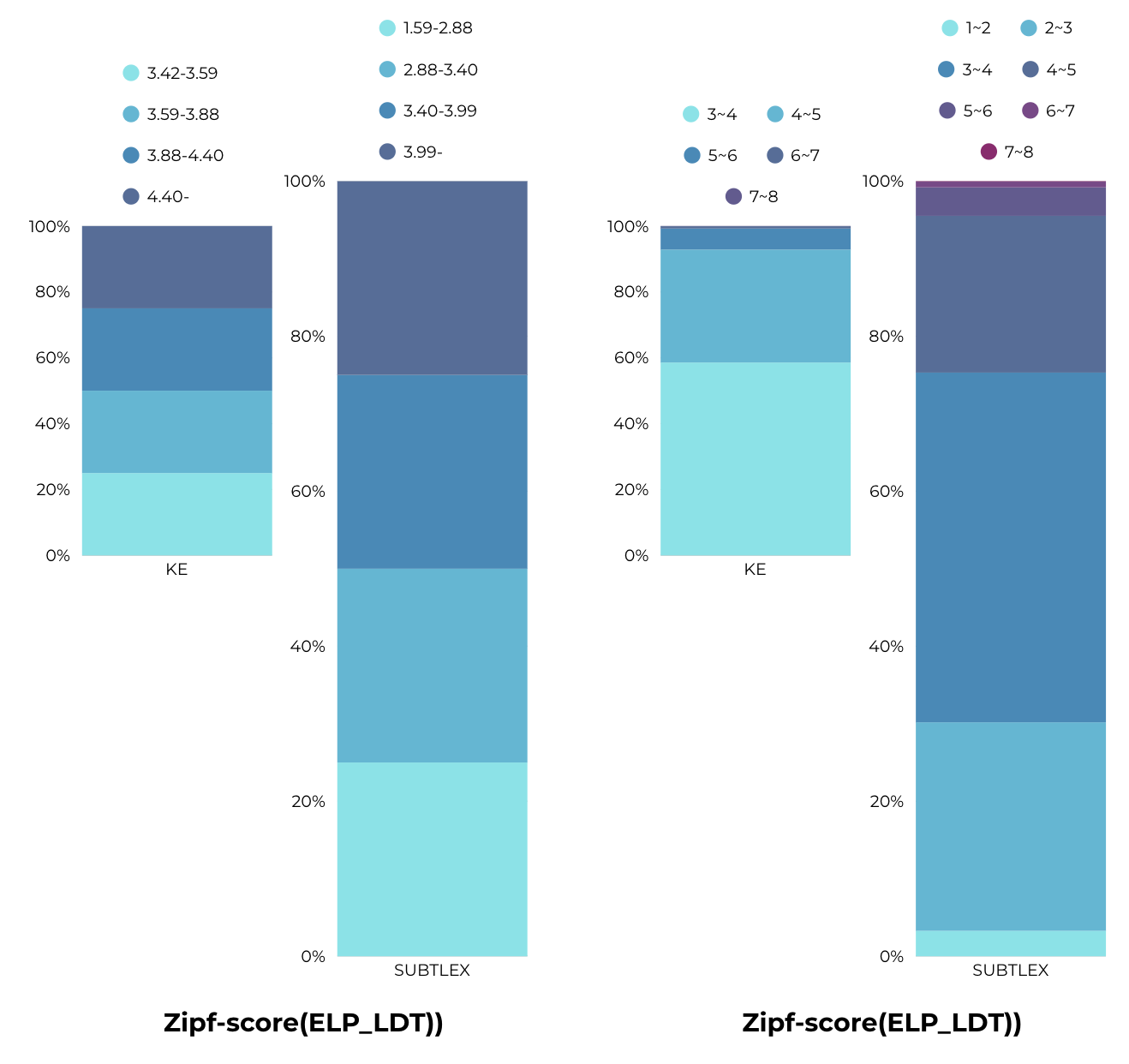
이 단어들을 Zipf-Scale로 분포를 확인해보면 아래와 같다.
ELP-LDT Word Analysis
실험 계획에 따르면, L1-L2 간 LDT RT 정보가 모두 필요하기 때문에 MB-LDT에 사용될 단어들은 ELP에서 RT 정보를 제공해야 한다.
기존 Exp2에서 KE/SUBTLEX 모두에서 상대 빈도 위치가 비슷한 단어들을 뽑을 계획이었는데, 이때 사용할 상대 위치 빈도는,
Multi column
Frequency Dist for all word in ELP(LDT)
Comment
일단 다행인 포인트는 L1 RT data 역시 KE에서도 고르게 분포하고 있음.
특이점은 유난히 KE corpus에서 좀 더 고빈도가 많아 보이는데, range 관점에서도 생각해보면, 소규모 코퍼스에서 빈도가 overestimate되는 것과 같은 맥락의 효과인 듯.
Zipf-score Distribution(competitive-tie)
Multi column
Plot
Comment
Zipf score는 식 구조 상, 소규모 코퍼스에서 기본적으로 클 수 밖에 없다.
(1B token 기준으로 단어빈도 환산 후 log를 사용하는데, 100만 규모 코퍼스에서 최소 빈도인 1은 1B 규모로 환산되면, Zipf=3이상이니, 100만 규모의 코퍼스의 Zipf-socre의 lower-bound는 3 이상이다. )
총 15,995개의 단어는 각 코퍼스에서 아래와 같이 분류됨.
Multi column
Table
Zipf-Scale
KE
SUBTLEX
lower-bound
3.418199
1.597149
[1.5,2)
0
525
[2,2.5)
0
1361
[2.5,3)
0
2942
[3,3.5)
3750
3865
[3.5,4)
5616
3352
[4,4.5)
3636
2210
[4.5,5)
1848
1025
[5,5.5)
824
406
[5.5,6)
199
182
[6,6.5)
83
75
[6.5,7)
28
43
[7,7.5)
10
7
[7.5,8)
1
2
upper-bound
7.700413
7.621137
Comment
KE의 lower bound가 3.x라는 것 check.
SUBTLEX, KE 모두 6.5 이상의 단어들이 별로 없기도 하고 단어들 보면 실험에 사용하기에는 적합하지 않음. 따라서 drop
Zipf > 7.0 Words in SUBTLEX
“a, and i, it, of, that, the, to, you”
..
일반적으로 LDT stimuli는 NN 단어들을 사용하니 이 역시 constraint로 추가.
Dense-rank
.png)
.png)
.png)