Exp1(Regression)
-
가설:
-
보여주고 싶은 것 : 공통된 단어를 뽑았을 때, 두 코퍼스에서 보여주는 기울기에 차이가 있을 것인가?
-
결국 보여주려고 하는 건, 두 코퍼스에서 빈도효과가 차이가 난다.
-
두 코퍼스에서 각각 10구간 percentile을 잘라서 각각의 위치에서 sampling.
- 10 percentile 중 2
3, 34, 45 … 78 6개의 구간에서 즉, 상하위 20% 씩 cut-off하고 가운데 60% 구간을 거의 등간격으로 해서 sampling. - 구간별 10개씩
- 원랙 3구간 20개씩 하려고 했는데, 조건을 맞추다보니 KE에서 sampling 시 어려워서 더 구간을 쪼개서 단어 자극의 코퍼스 커버리지를 넓힘.
- 10 percentile 중 2
-
총 120개 단어들을 회귀 분석에 사용할 예정.
-
분석안
- 1안 : 각 60개를 각 코퍼스에만 적용.
- 2안합쳐서 120개를 각각 코퍼스에서 회귀
- 전체 단어의 분포를 보고 결정할 것.
Stimuli Stats
주요 통제 변인은 다음과 같다.
- Word Length : 4를 기준으로 3~6 letter로 모두 setting
- Freq: 기울기를 볼 때, 추정한 베타값의 신뢰도를 추정하는 SE를 줄이기 위해서는 빈도 값이 해당 카테고리 안에서 spreading되어야 할 필요가 있기에, 완벽하진 않아도 얼추 흝어지도록 함.
- syllabic: mono, di-syllabic 단어만 추출.
- 원형 즉, 파생형은 사용하지 않고, plural 역시 제외.
- POS(X): 일부러 통제하지 않음. 딱히 필요성을 느끼지 못함.
- Concreteness(7-scale) : 3.6 기준으로 통제함.
- 큰 이유는 없고, Baek et al(2023, Memory and Cognition) 참고해서 비슷한 범위로 맞춤.
- AoA(△): 적당히 했으나, 코퍼스별 차이가 있긴 함. 대략 코퍼스 간 1년 정도 차이.
- OLD, PLD: 통제하진 않았으나 t-test에서 유의하지 않게 나옴.
KE percentile stimuli 60개
Multi column
Note
KE(%) Zipf(Mean, SD) Length Concreteness AoA 20-30(HF) 5.928008 (0.073) 4.1 (0.32) 3.637 (0.792) 4.231 (1.098) 30-40 5.739303 (0.059) 4.1 (0.88) 3.697 (0.682) 4.932 (0.999) 40-50 5.605710 (0.020) 4.0 (0.67) 3.572 (0.236) 5.574 (0.532) 50-60 5.483919 (0.041) 4.0 (0.81) 3.631 (0.294) 4.343 (0.870) 60-70 5.350969 (0.038) 4.1 (0.57) 3.629 (0.137) 5.692 (2.153) 70-80(LF) 5.193892 (0.045) 4.1 (0.57) 3.618 (0.188) 5.484 (1.347)
.png)
SUBTLEX percentile stimuli 60개
Multi column
Note
SUB(%) Zipf(Mean, SD) Length Concreteness AoA 20-30(HF) 4.977205 (0.074033) 4.0 (0.47) 3.687 (0.264) 5.709 30-40 4.778746 (0.050153) 4.1 (0.88) 3.645 (0.323) 5.344 40-50 4.610735 (0.048432) 4.1 (0.57) 3.641 (0.226) 5.760 50-60 4.475714 (0.044966) 4.1 (0.57) 3.666(0.216) 7.102 60-70 4.332576 (0.043542) 4.1 (0.73) 3.653 (0.288) 6.601 70-80(LF) 4.159414 (0.052596) 4.0 (0.47) 3.707 (0.160) 7.451
.png)
Summary
위 두 코퍼스에 대해 각각의 구간 별 빈도는 퍼지게, Concreteness는 일정하게, Length는 일정하게 가 적용됨.
- 겹치는 단어는 9개? 즉, 111개의 단어.
저번의 그래프로도 예상가능했지만, KE는 전체적으로 동일 빈도 단어들이 코퍼스 내에서 하방으로 skewed되어 있음. 고빈도 단어이더라도 percentile이 훨씬 아래라, 이런걸 LDT 할 때 고려하라고 제언할 수 잇을지도..?
Stimuli group 간 stats-Test
- 만약 자극 60개씩을 각각의 코퍼스에 대해서만 회귀 분석을 수행할 것이라면, 두 그룹간 차이는 없어야 회귀 분석 시 property를 넣지 않고 원하는 main-effect만 분석하기 수월하다.
- 2개의 그룹 비교니까 간단하게 t-test.
.png)
- AoA 말고는 원하는 방향으로 control 됨.
Stimuli merging
- 가능한 분석 시나리오 중 하나로 120개의 자극을 각각의 코퍼스에 대해 회귀 시키는 케이스.
Multi column
Percentile Plot
Zipf-Scale Plot
.png)
.png)
- 예상과 다르진 않음. 다만, 이렇게 120개에 대해 돌리면 서로 카테고리별 겹치는 영역이 많다보니, 기울기의 차이가 날거라 기대하긴 힘들지도,,
Nonwords(LDT용)
- ELP에서 제공하는 Nonword를 사용함.
- 단어 선정 기준은
- Length
- Bi-gram Freq(mean, sum)
- Ortho_N
- 을 통제함(mean, sd).
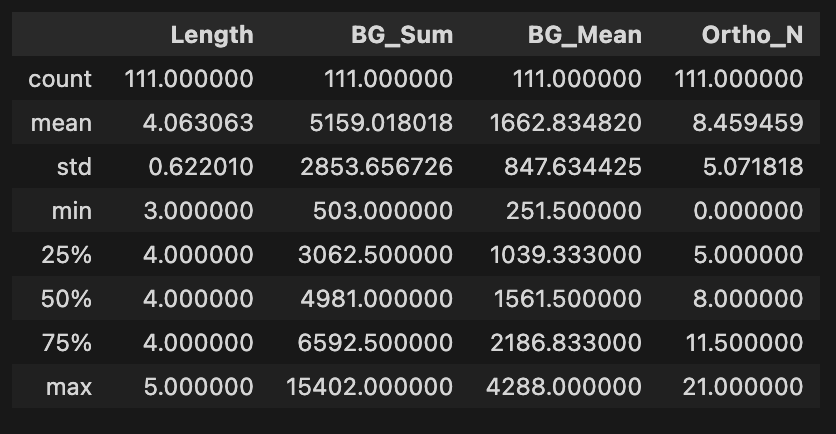
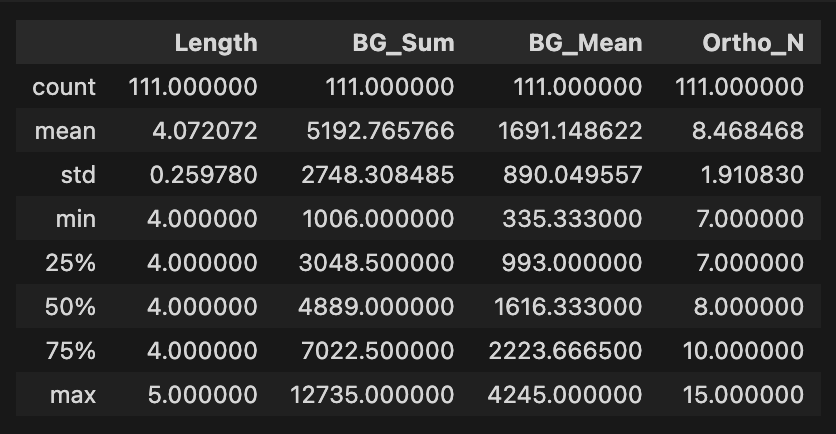
마찬가지로, 총 111개.
t-test 돌려서 구분 안되는 정도까지 해둠.
Multi column
Real-word stats
Non-word stats
t-test:
.png)
- 위 4가지 기준으로 구분되지 않음.
Exp2
- 자극을 뽑아서 하고 싶었으나, 단어 풀이 압도적으로 통제하기 어렵기도 하고, SUBTLEX로도 구분하는 단어들이 너무 전문 용어 및 LDT 자극으로 부적합하다는 판단이 들어 보류(폐기)
- 기존 생각~으로는 구간을 SUBTLEX Zipf 기준
- 2.0~2.5
- 2.5~3.0
- 3.0~3.5
- 3.5이상에서는 KE도 같이 커버.
- 으로 하려고 했는데, 2.0~2.5 구간에 대한 단어풀이 20개도 안되서 포기.
- 그리고 이것 역시 하나의 실험이자, 회귀 분석을 고려 중이었는데, 20개씩해서 60개는 나왔으면 좋겠지만, 조건별 단어 필터링을 해본 결과, 친숙성이 너무 떨어져, 통제가 제대로 안될거라는 판단.
- 기존 생각~으로는 구간을 SUBTLEX Zipf 기준
Multi column
SUBTLEX Zipf 2.0~2.5 stimuli candidate(full)
SUBTLEX Zipf 2.5~3.0 stimuli candidate(full)
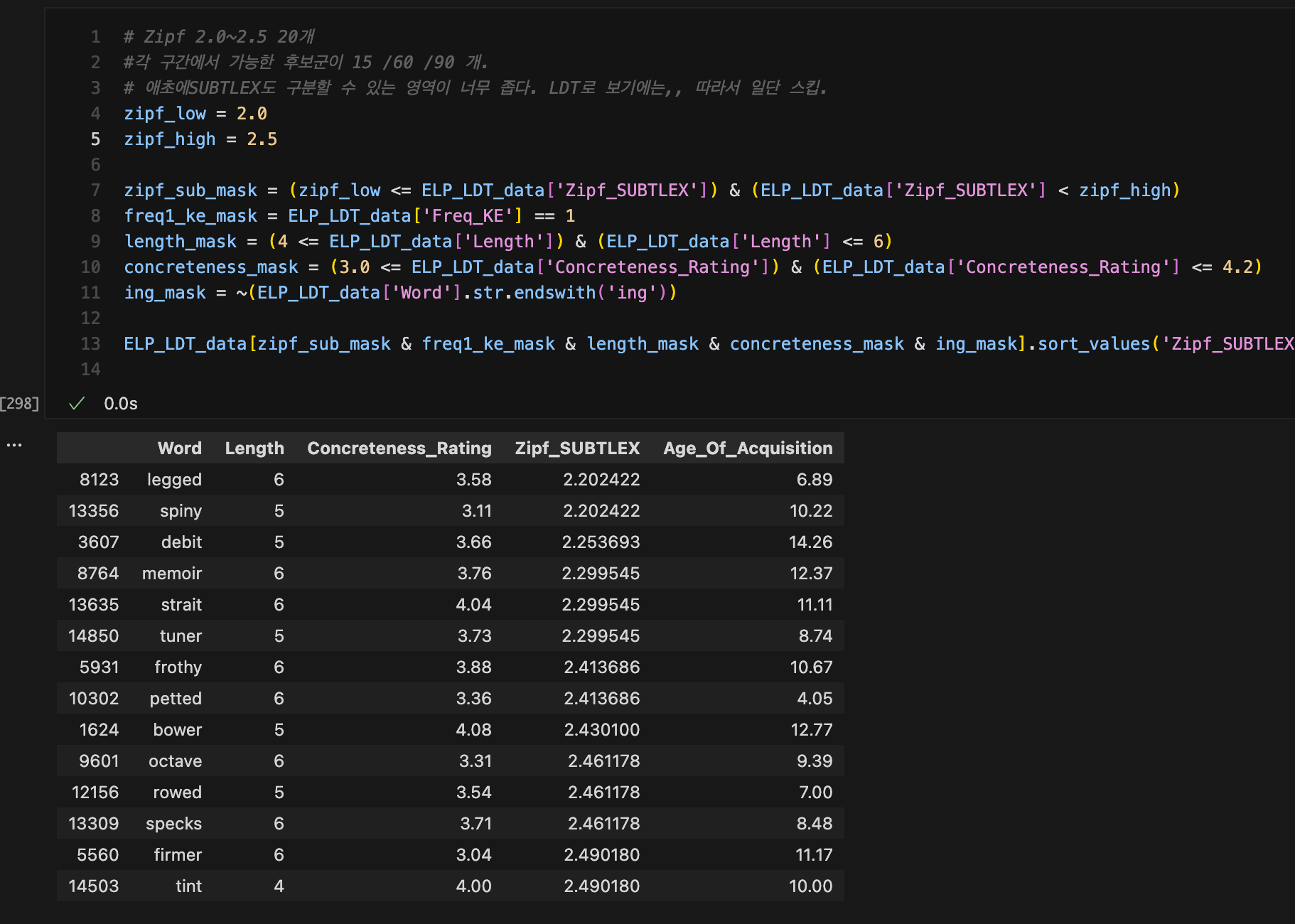
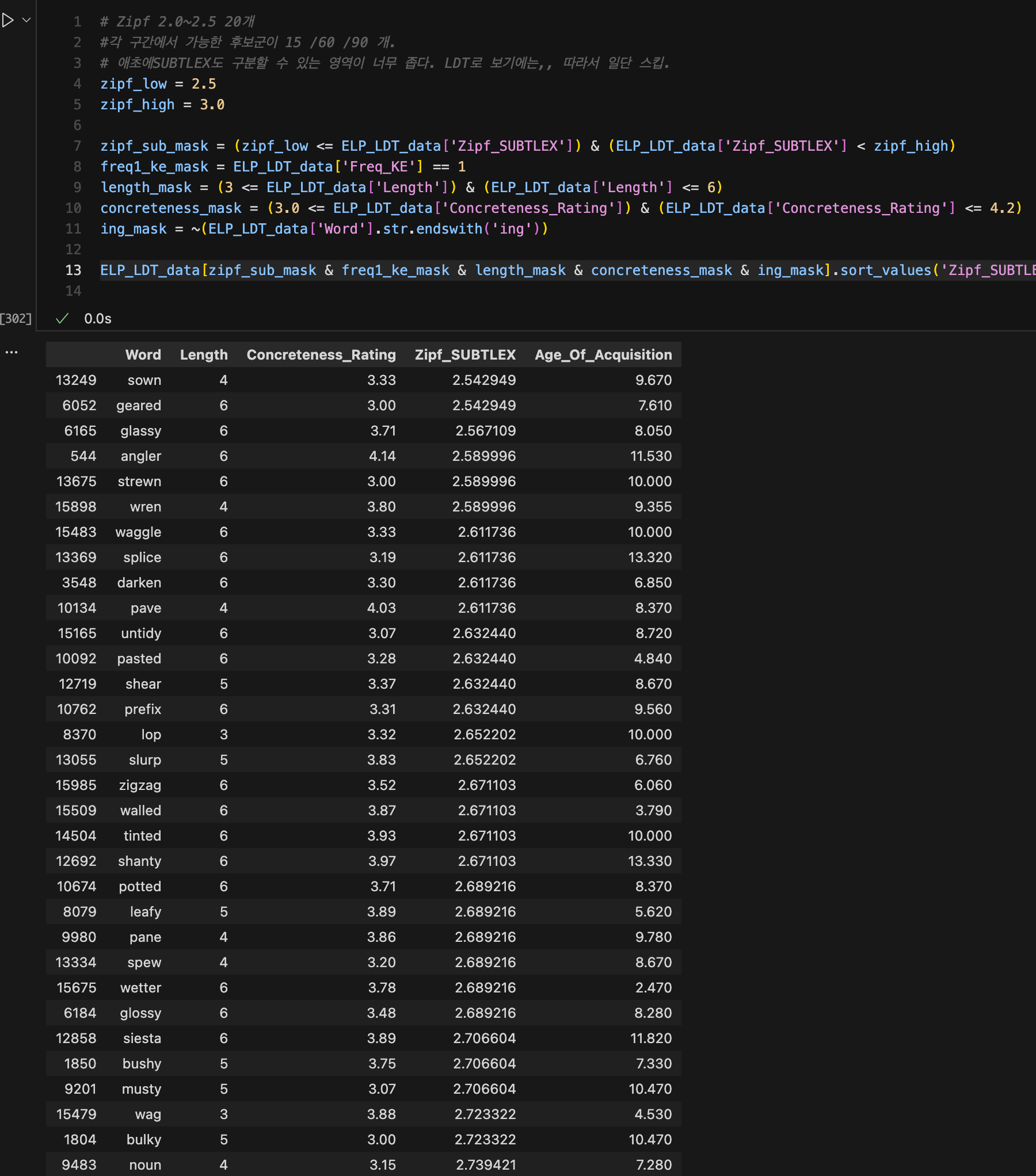
- 가설: SUBTLEX의 저빈도 구간 (Zipf < 3.5) 단어들에 대한 L2 English leaner들의 행동을 L1 corpus 빈도가 더 잘 설명할 것인가 아니면, 차이가 없다고 하는 L2 corpus가 더 잘 설명하는가?
- 그냥 대충 생각해보며, L2도 맞을 것 같은데, 일반적으로는 극저빈도 단어들은 L2가 모르잖아. 그러면 빈도효과를 볼 수 있을까?
- KE(L2) corpus에서 1 빈도 단어들은 코퍼스의 해상력 문제인가 아니면, L2의 특징이 반영된 것인가?
- Occam’s Razor 관점에서는 실제 L2의 행동 데이터가 flatten한 RT 그래프를 보여주면, L2 코퍼스가 더 좋지.
- 간단히 말하자면, SUBTLEX가 KE로 구분할 수 없는 즉, Zipf3.5 미만의 단어들에 대해서 아무리 구분할 수 있어도 의미가 없다 → L2 그러면 더욱 더 KE를 사용하던가 cut-off 기준으로 사용하던가 해야지.
- 그러며 연속형으로 단어 select.
- 구간은 Zipf 2.0
2.5 / 2.53.0 / 3.0 ~ 3.5 각 20개씩?