HAL vs SUBTLEX (Z-score Normalized)
Multi column
Whole POS
.png)
.png)
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 35515 Freq_HAL - 평균: 0.00, 표준편차: 1.00 SUBTLWF - 평균: -0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.7993 (p-value: 0.0000) 스피어만 상관계수: 0.8020 (p-value: 0.0000) 켄달 타우: 0.6132 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================POS(NN, ADJ, ADV)
.png)
.png)
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 29272 Freq_HAL - 평균: -0.00, 표준편차: 1.00 SUBTLWF - 평균: 0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.8491 (p-value: 0.0000) 스피어만 상관계수: 0.8020 (p-value: 0.0000) 켄달 타우: 0.6124 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================POS(V)
.png)
.png)
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 12372 Freq_HAL - 평균: -0.00, 표준편차: 1.00 SUBTLWF - 평균: 0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.8104 (p-value: 0.0000) 스피어만 상관계수: 0.8511 (p-value: 0.0000) 켄달 타우: 0.6660 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================
.png)
.png)
.png)
CSAT_RFreq vs SUBTLEX (Z-score Normalized)
Multi column
Whole POS
.png)
.png)
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 15996 CSAT_RFreq - 평균: -0.00, 표준편차: 1.00 SUBTLWF - 평균: -0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.8178 (p-value: 0.0000) 스피어만 상관계수: 0.6783 (p-value: 0.0000) 켄달 타우: 0.5137 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================POS(NN, ADJ, ADV)
.png)
.png)
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 13181 CSAT_RFreq - 평균: -0.00, 표준편차: 1.00 SUBTLWF - 평균: -0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.8508 (p-value: 0.0000) 스피어만 상관계수: 0.6739 (p-value: 0.0000) 켄달 타우: 0.5081 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================POS(V)
.png)
.png)
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 6483 CSAT_RFreq - 평균: 0.00, 표준편차: 1.00 SUBTLWF - 평균: 0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.8561 (p-value: 0.0000) 스피어만 상관계수: 0.7395 (p-value: 0.0000) 켄달 타우: 0.5668 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================
.png)
.png)
.png)
CSAT_RFreq vs HAL (Z-score Normalized)
Multi column
Whole POS
.png)
.png)
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 16354 CSAT_RFreq - 평균: 0.00, 표준편차: 1.00 Freq_HAL - 평균: -0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.9892 (p-value: 0.0000) 스피어만 상관계수: 0.7298 (p-value: 0.0000) 켄달 타우: 0.5630 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================POS(NN, ADJ, ADV)
.png)
.png)
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 13422 CSAT_RFreq - 평균: -0.00, 표준편차: 1.00 Freq_HAL - 평균: 0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.9821 (p-value: 0.0000) 스피어만 상관계수: 0.7213 (p-value: 0.0000) 켄달 타우: 0.5534 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================POS(V)
.png)
.png)
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 6507 CSAT_RFreq - 평균: 0.00, 표준편차: 1.00 Freq_HAL - 평균: 0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.9532 (p-value: 0.0000) 스피어만 상관계수: 0.7961 (p-value: 0.0000) 켄달 타우: 0.6253 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================
.png)
.png)
.png)
- 동사(Verb) 사용 양상이 (명NN, 형ADJ, 부ADV) 사용 양상 보다 비슷하다.
ELP vs CSAT (Z-score Normalized)
Ortho_N
Multi column
ELP vs KE
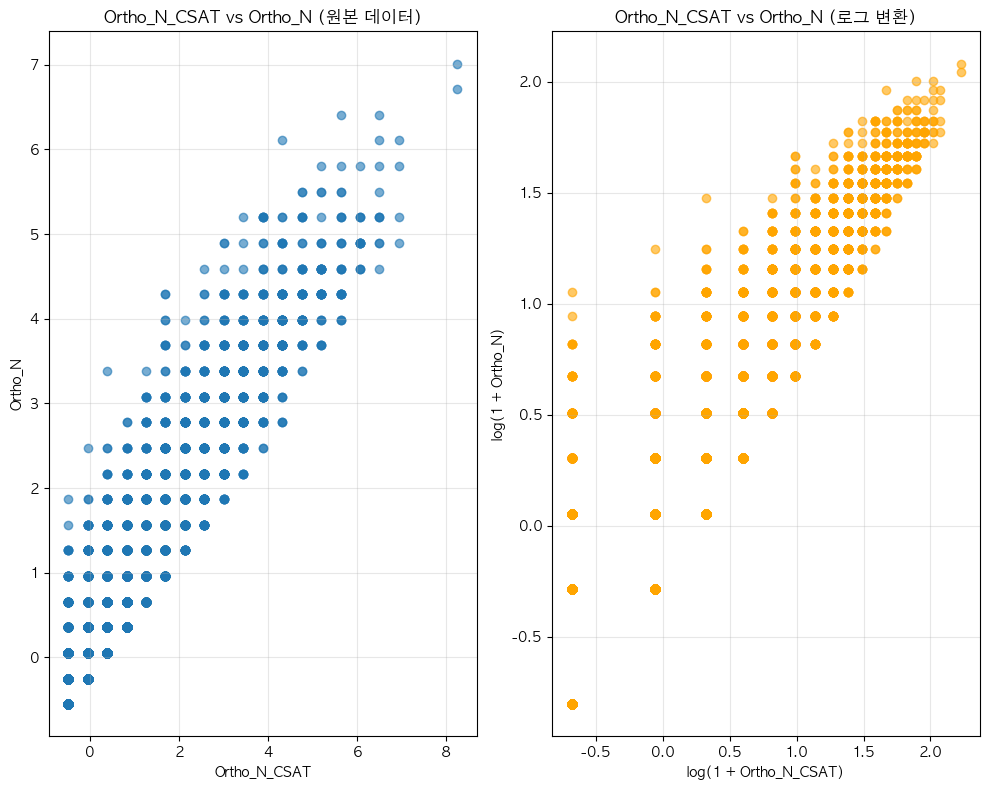
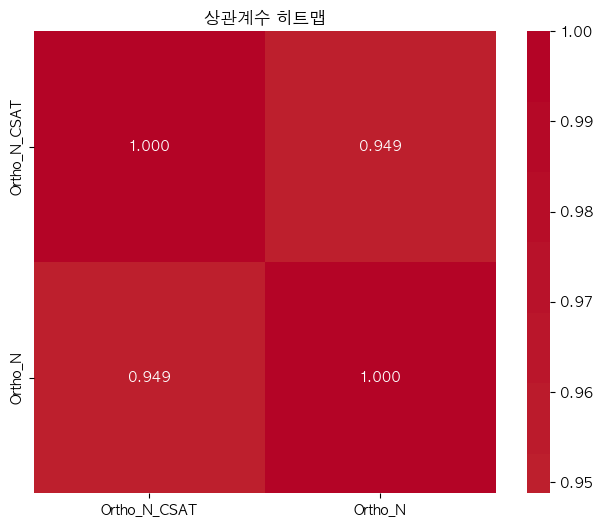
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 16354 Ortho_N_CSAT - 평균: -0.00, 표준편차: 1.00 Ortho_N - 평균: 0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.9488 (p-value: 0.0000) 스피어만 상관계수: 0.8912 (p-value: 0.0000) 켄달 타우: 0.8481 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================ELP vs KE_EXAM
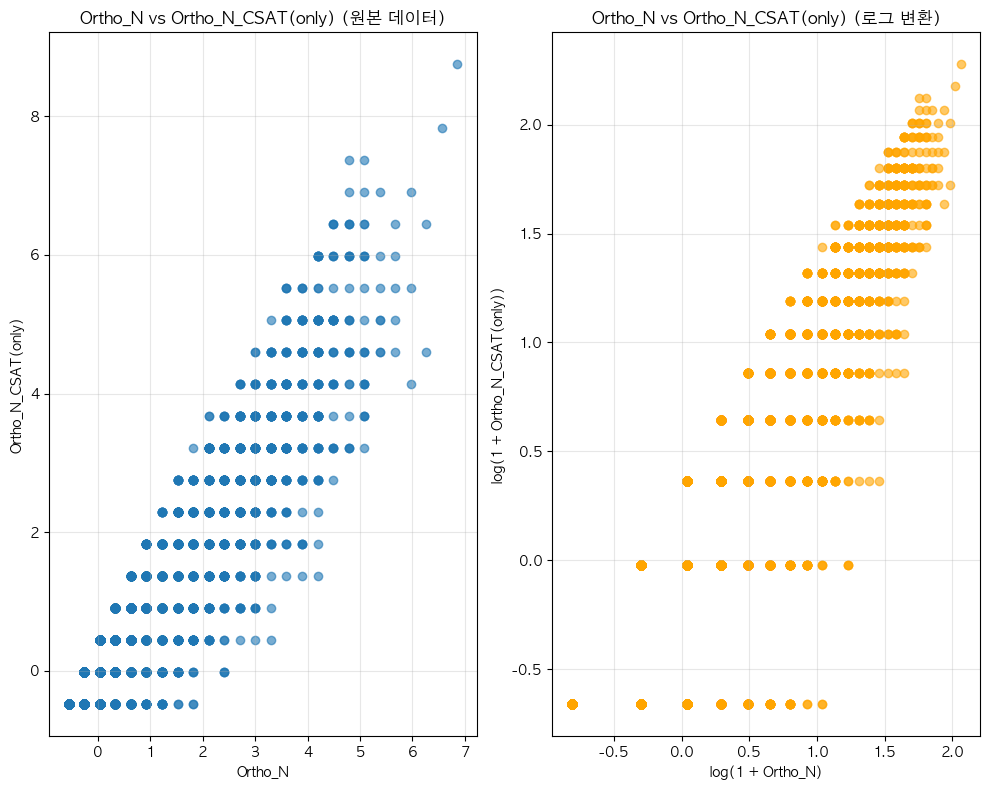
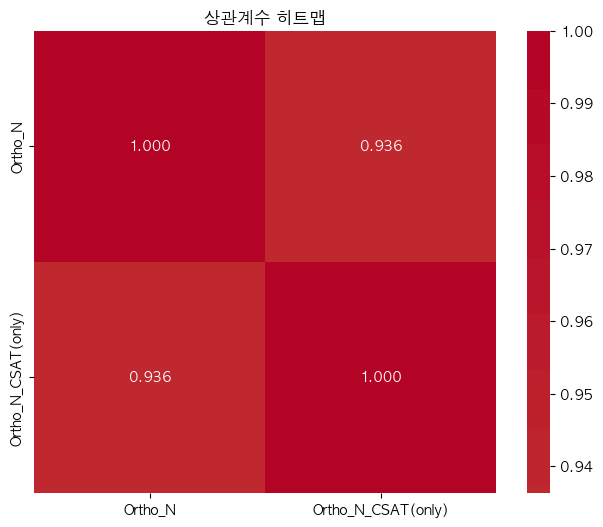
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 16354 Ortho_N_CSAT(only) - 평균: -0.00, 표준편차: 1.00 Ortho_N - 평균: 0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.9364 (p-value: 0.0000) 스피어만 상관계수: 0.8684 (p-value: 0.0000) 켄달 타우: 0.8211 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================ELP vs KE_TEXTBOOK(수정해야함)
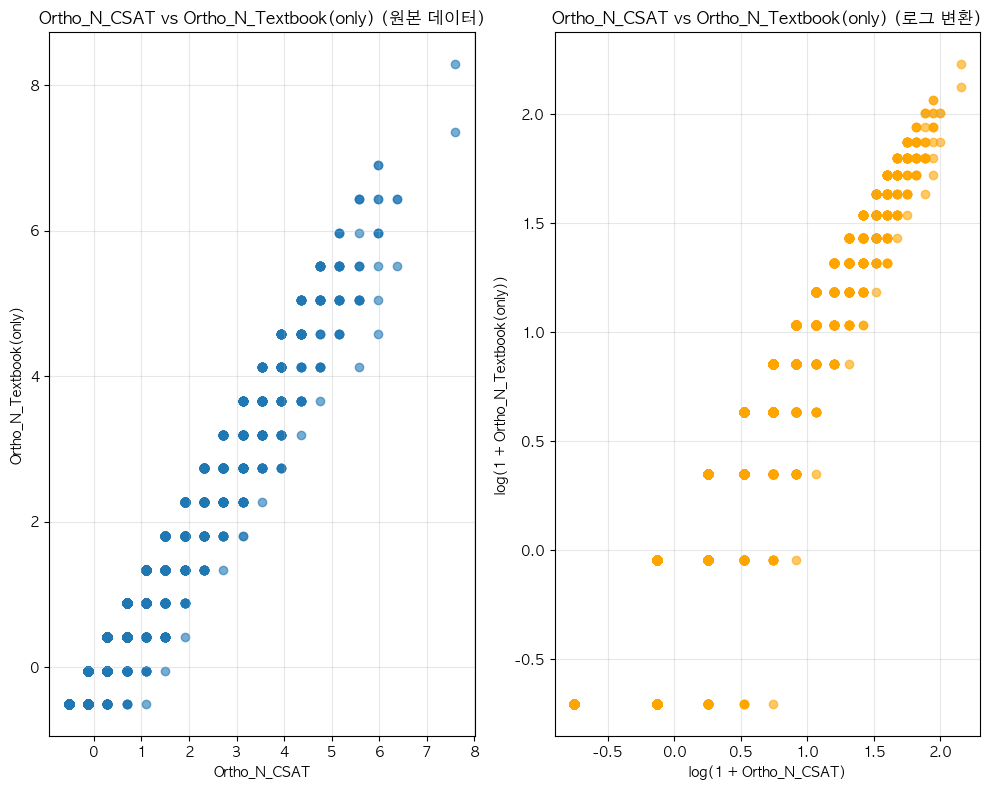
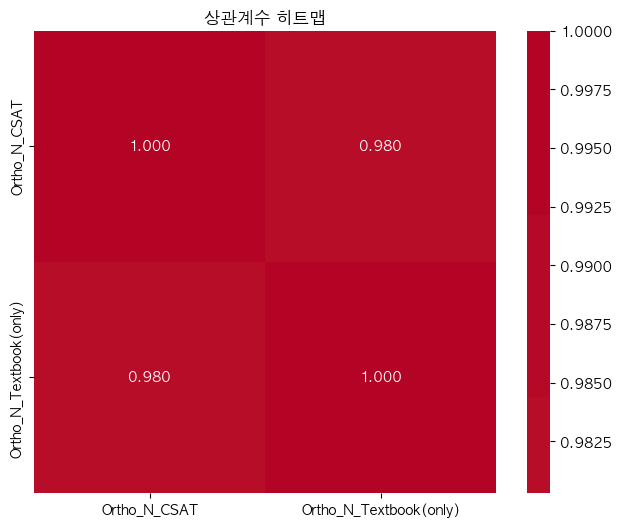
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: ??(수정해야 함.) Ortho_N_CSAT - 평균: -0.00, 표준편차: 1.00 Ortho_N - 평균: 0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.9488 (p-value: 0.0000) 스피어만 상관계수: 0.8912 (p-value: 0.0000) 켄달 타우: 0.8481 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================
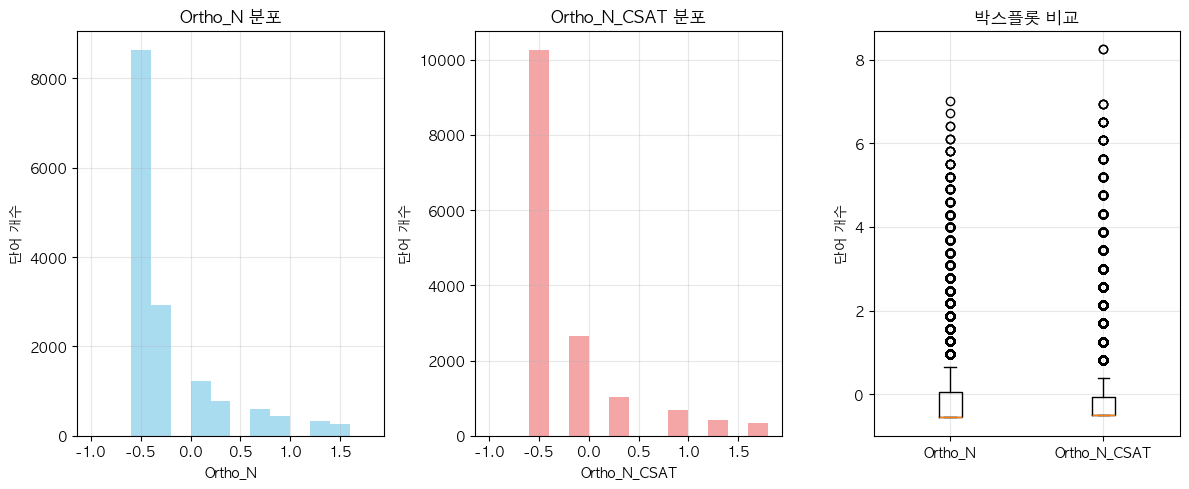
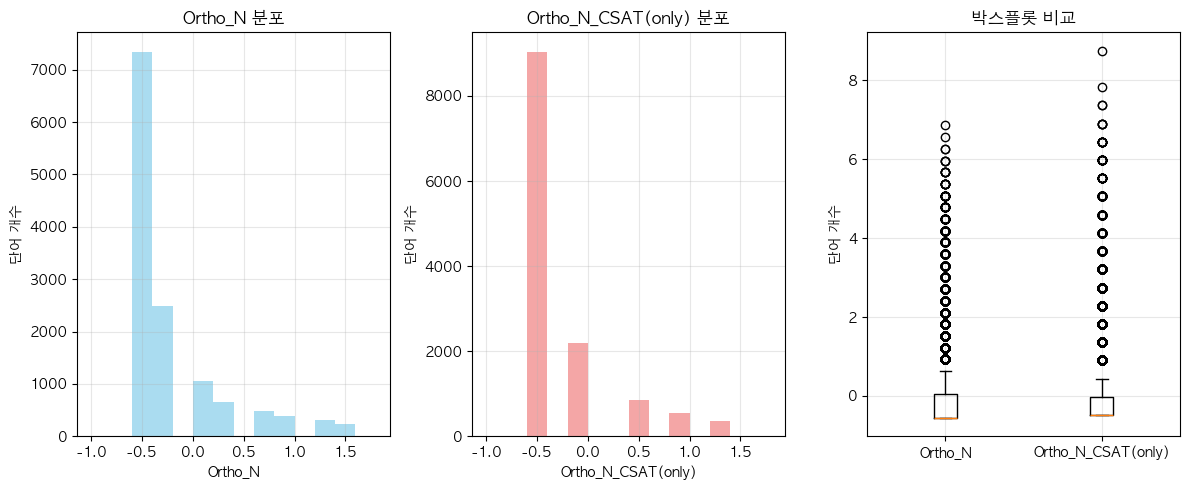
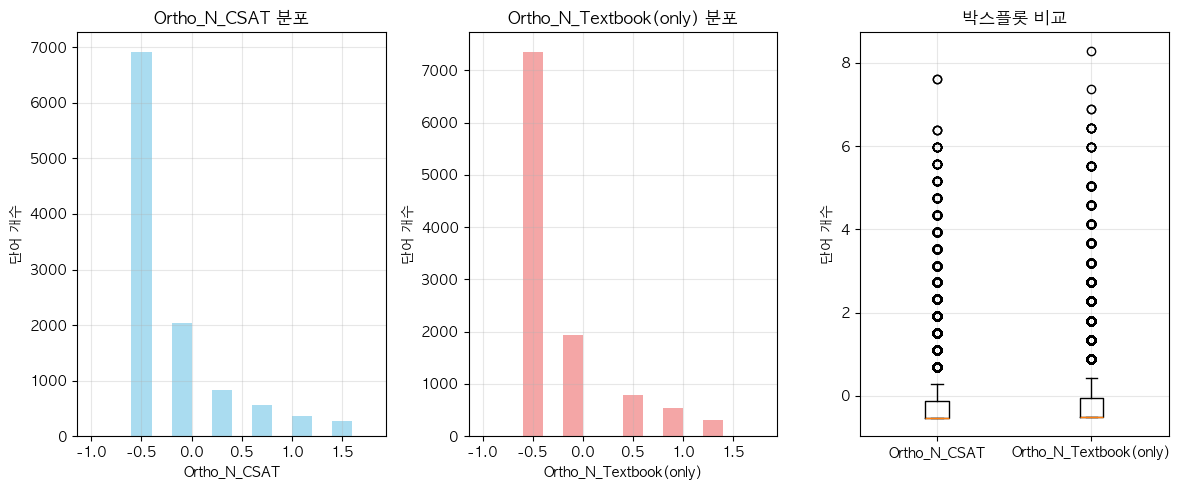
- 아마도 OLD가 더 높은 값을 가지는 건, Ortho_N 조건이 더 까다롭고 discrete한 값이니, corpus size 크기 영향을 더 많이 받은 것 아닐까?
OLD20
Multi column
ELP vs KE
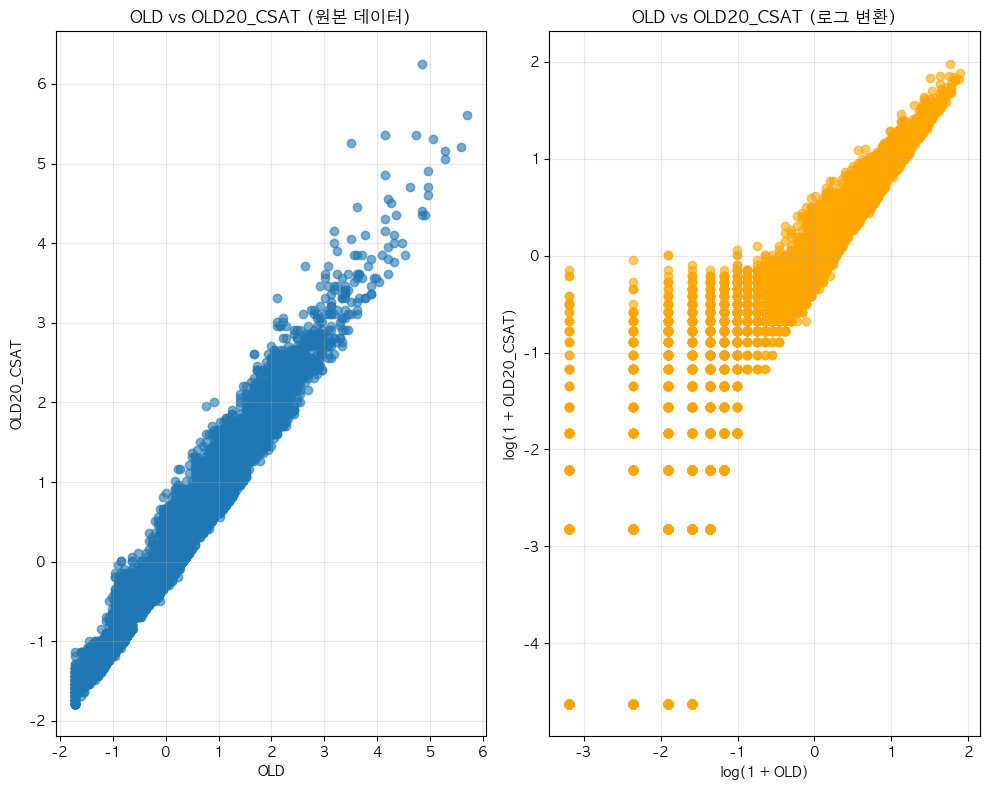
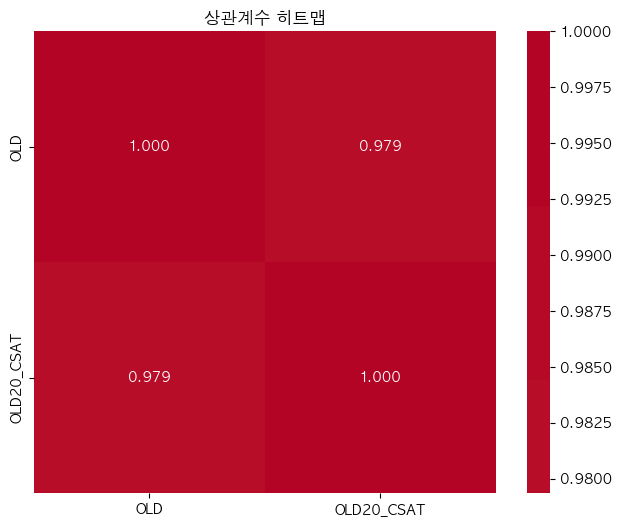
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 16247 OLD - 평균: -0.00, 표준편차: 1.00 OLD20_CSAT - 평균: -0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.9794 (p-value: 0.0000) 스피어만 상관계수: 0.9804 (p-value: 0.0000) 켄달 타우: 0.8961 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================ELP vs KE_EXAM
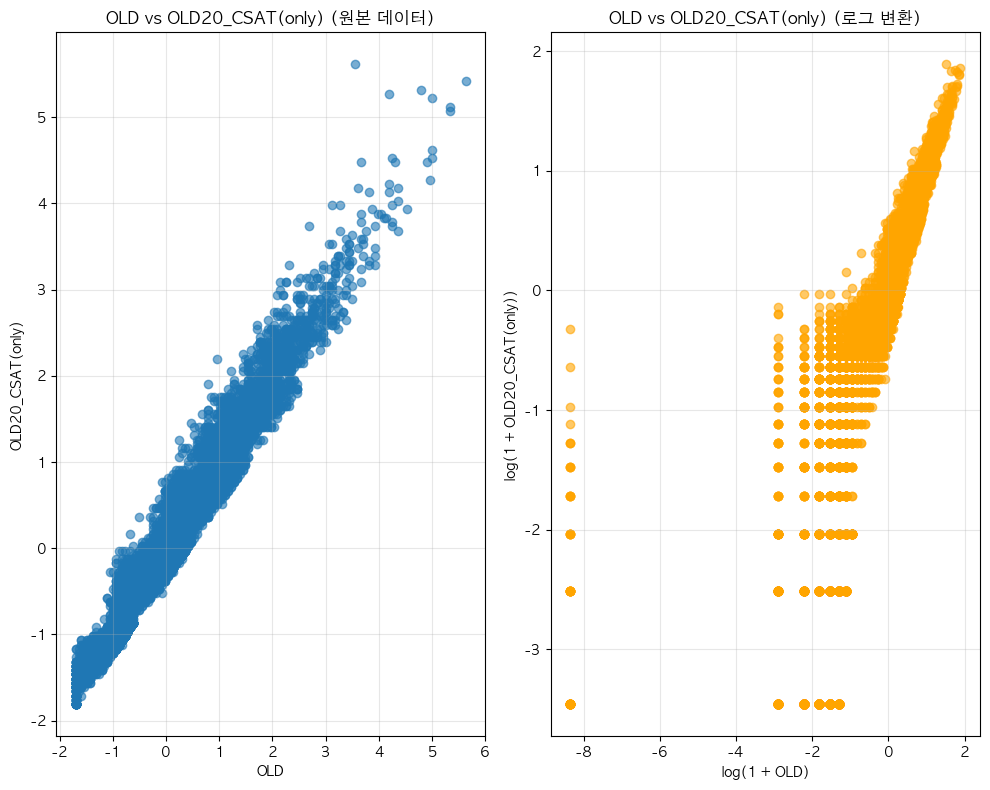
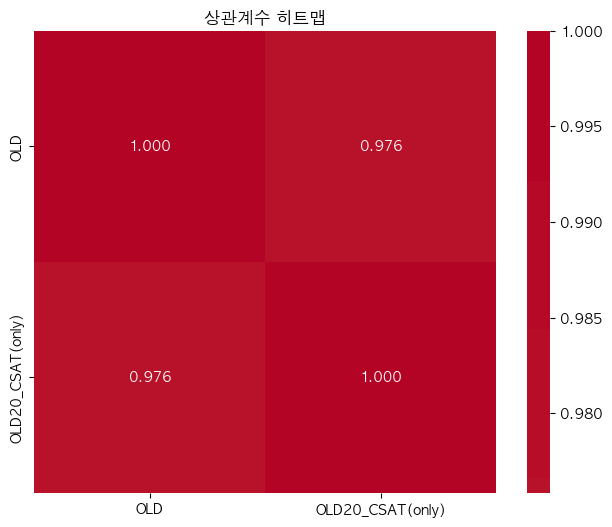
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 13912 OLD - 평균: -0.00, 표준편차: 1.00 OLD20_CSAT(only) - 평균: 0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.9758 (p-value: 0.0000) 스피어만 상관계수: 0.9773 (p-value: 0.0000) 켄달 타우: 0.8852 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================ELP vs KE_TEXTBOOK(수정해야함)
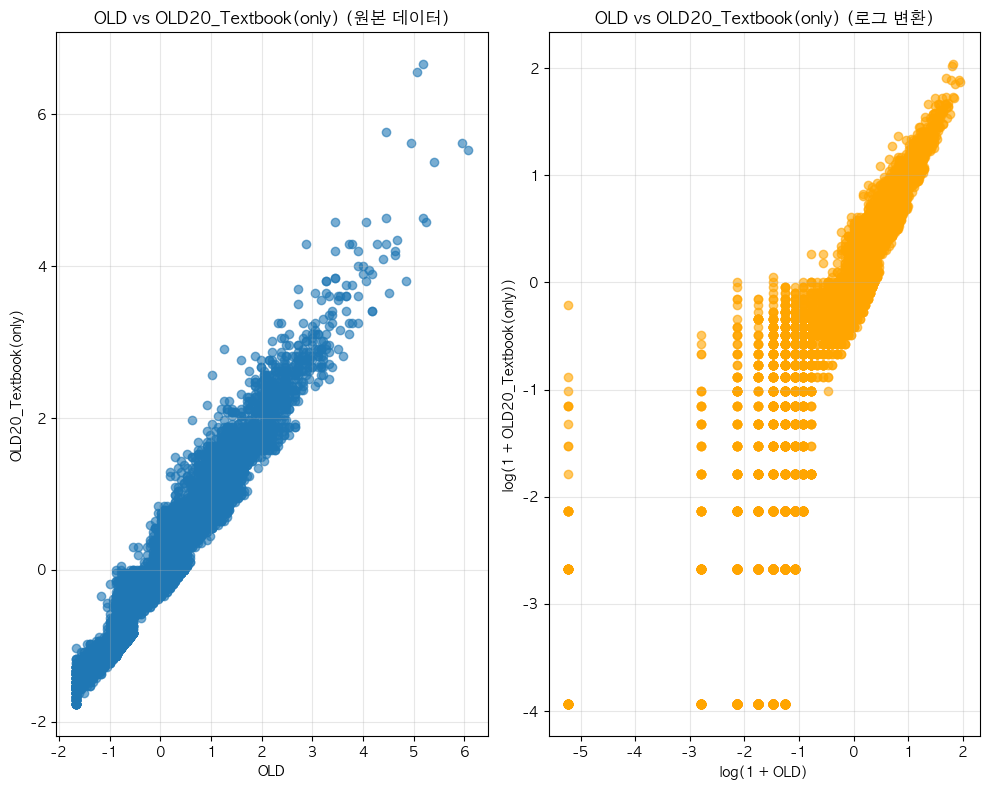
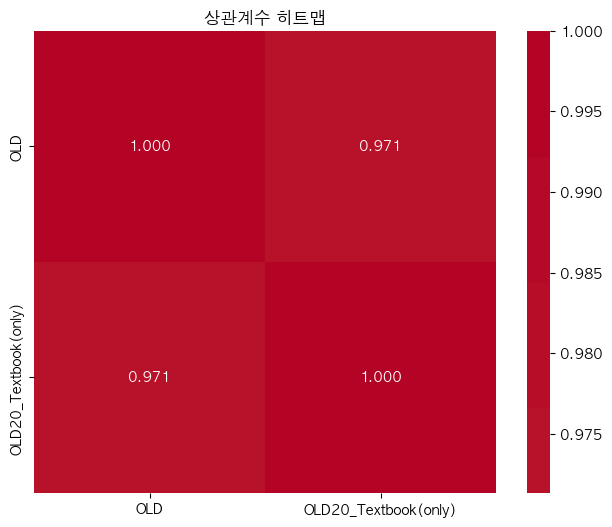
단어 빈도수 상관관계 분석 결과 ================================== 📊 기본 통계: 데이터 개수: 11767 OLD - 평균: 0.00, 표준편차: 1.00 OLD20_Textbook(only) - 평균: 0.00, 표준편차: 1.00 🔗 상관계수: 피어슨 상관계수: 0.9713 (p-value: 0.0000) 스피어만 상관계수: 0.9741 (p-value: 0.0000) 켄달 타우: 0.8766 (p-value: 0.0000) 📝 해석: 통계적 유의성: 매우 유의함 (p < 0.001) 상관관계 강도: 강한 양의 상관관계 ==================================
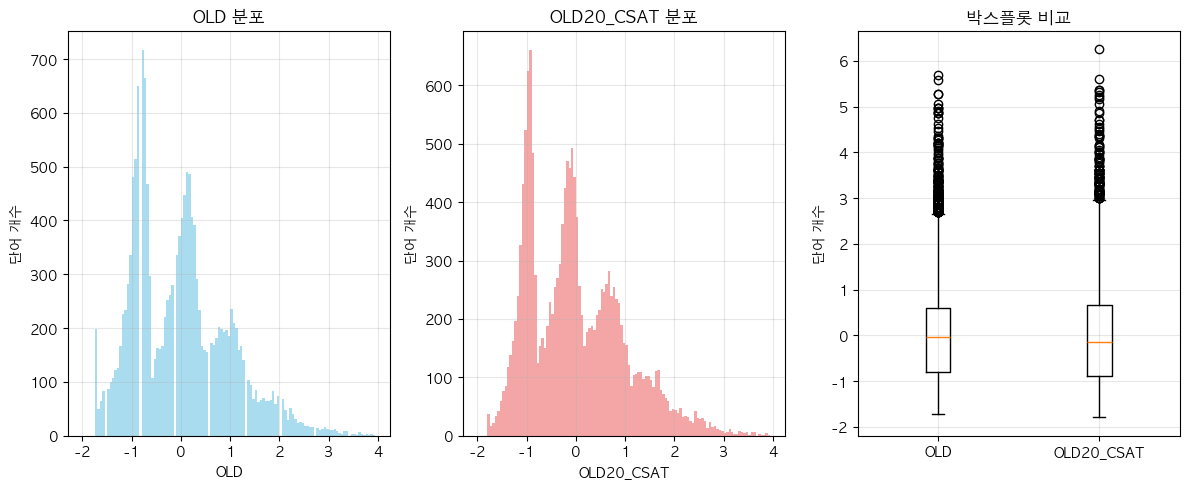
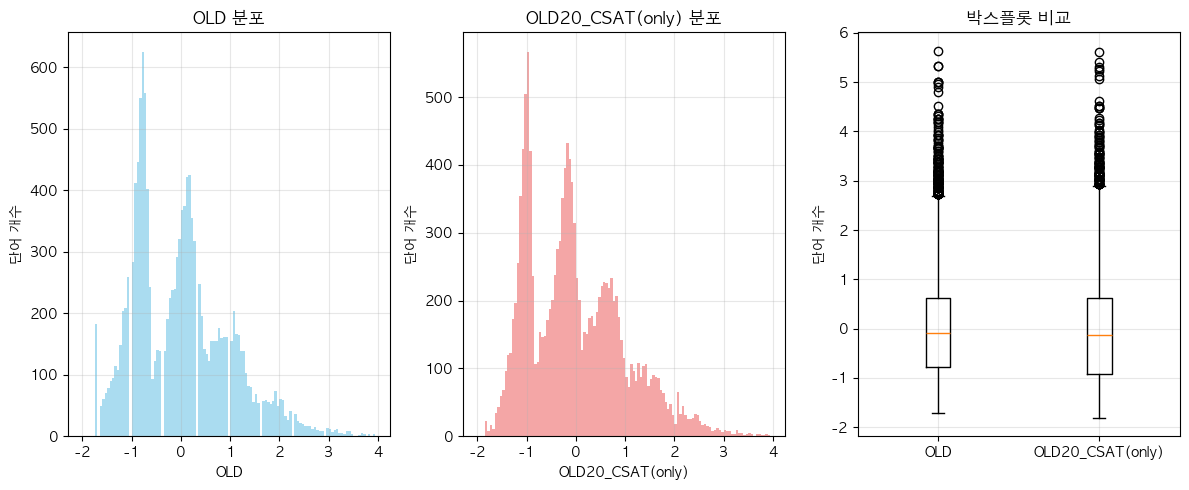
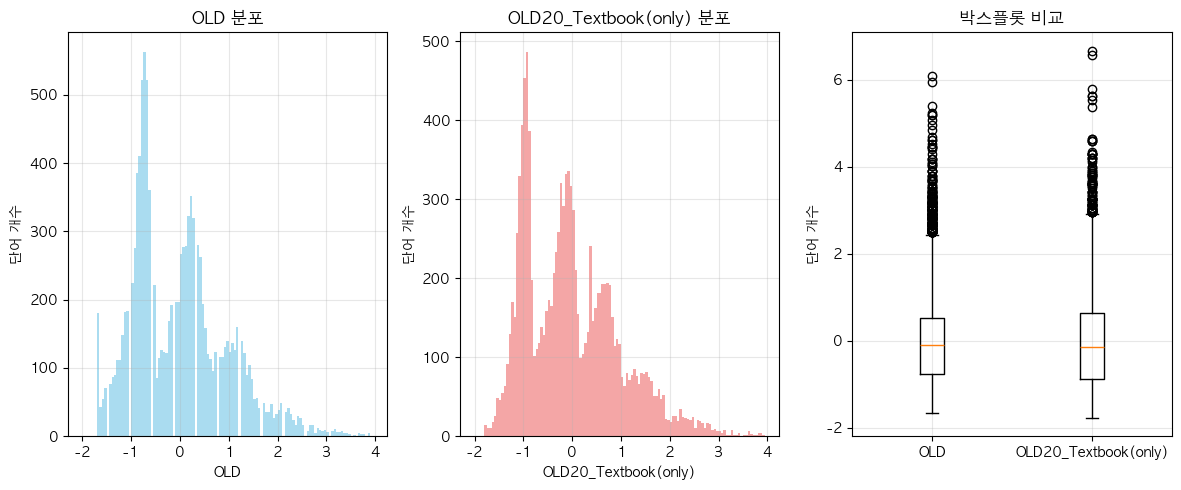
- 아마도 OLD가 더 높은 값을 가지는 건, Ortho_N 조건이 더 까다롭고 discrete한 값이니, corpus size 크기 영향을 더 많이 받은 것 아닐까?