- 문제 상황은 기존 correlation 분석 간 빈도 값들의 범위가 다른 점.
- HAL을 제외한 나머지들은 raw_freq의 범위가 이지만, HAL만 이라서 이를 수정.
- 기존 연구들에 따르면, 코퍼스 간 비교 시에는 교집합에 속하지 않는 단어 빈도를 0으로 처리하여 분석한다고 함.
- 생각해보면, method니까, BRM의 논문들 따라가는게 맞겠지..?
-
- union with 0 filling
- 해당 선행 연구들 : SUBTLEX-UK paper, Kilgarriff(1996)
-
- remove 0 freq words
- Dealing with zero word frequencies: A review of the existing rules of thumb and a suggestion for an evidence-based choice(brysbeart 논문이 있으니, 이를 활용해서 dealing 할 것.) 심지어 BRM이라 그냥 이대로 follow하면 되지 않을까?
무조건 읽어야 할 papaer: Comparing Corpora
-Adam kilgarriff(International Journal of Corpus Linguistics), 2001
전체 코퍼스 간 range
.png)
- zero-freq 단어에 대해서는 NaN → 0으로 일단 조정해서 모든 단어들에 대한 WF 값은 일단 기입된 상태.
아래는 0-fillna 처리하지 않은 단어 분포
.png)
- 우리 거만 압도적으로 단어의 폭(Word-type : from brysbaert,2013)이 좁음.
전체 코퍼스 간 상관
.png)
- 눈으로 보기에는 전체 코퍼스 간 상관이 다 높아보인다.
- 내세울 수 있는 점으로는 SUBTLEX 랑은 우리가 조금 더 높다는 점…?(0.031 정도이긴 하지만,,)
Corr with 40481 sord types(from E-lexicon)
위의 상관은 40481개의 단어(word-type)을 기준으로 계산된 값들이라, 직접적으로 1-1간 코퍼스 비교 시에는 부적합할지도,,
ex) KE(16354), KF(32552) 개의 word type을 가지고 있는데, 위의 방법대로 corr을 돌리면 고려되는 케이스는
- (KE, KF) = (not-0, 0)
- (KE, KF) = (0, not-0)
- (KE, KF) = (0, 0)
인데, 3 케이스는 제외되는 게 합리적이라는 판단.
zero 값이 영향을 너무 줄지도,,
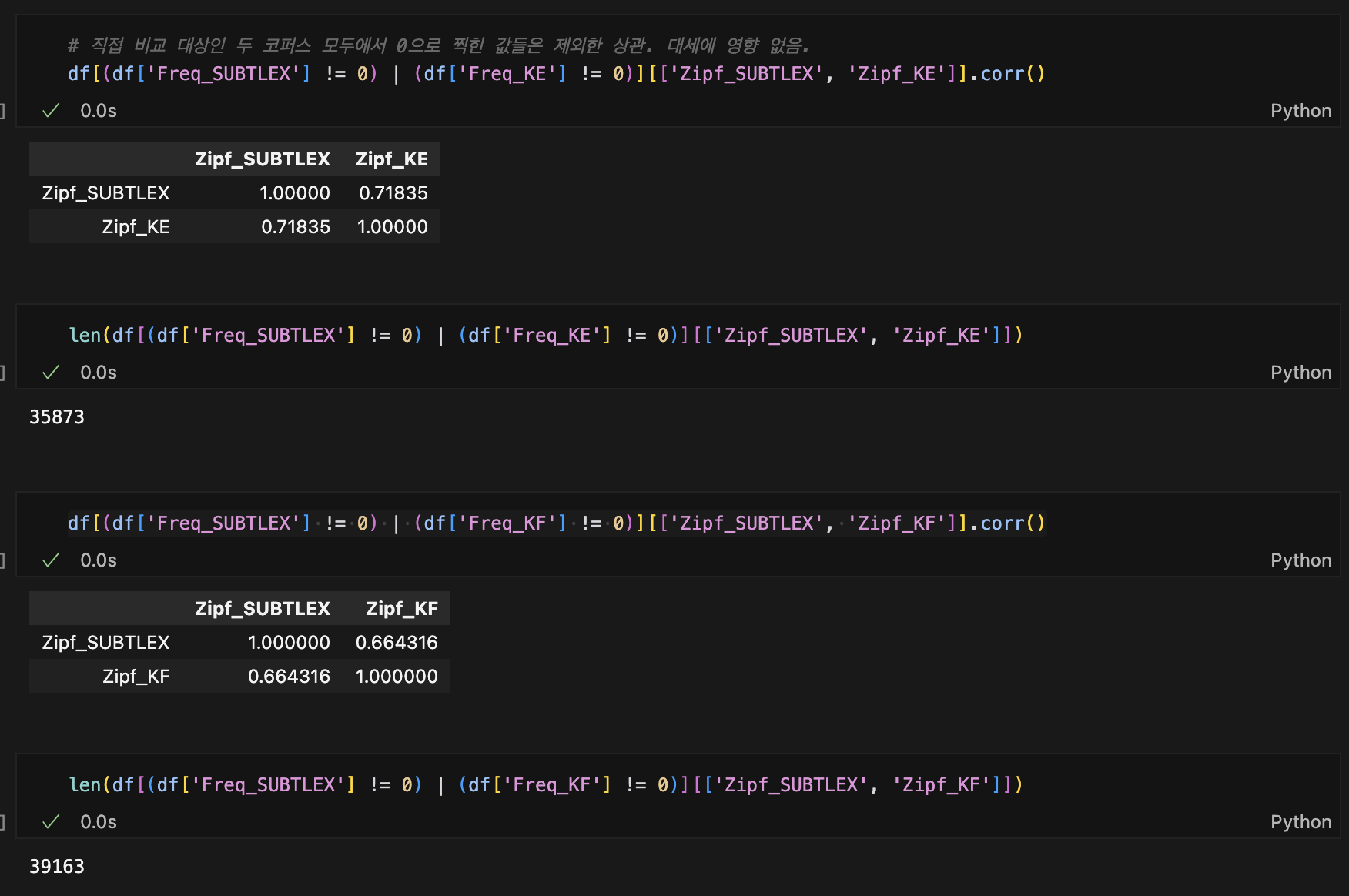
- 이렇게 보면 좀 더 KE-KF 간 SUBTLEX와의 상관이 커짐.(0.031 →0.054)
구간 별 상관
- 아래부터 빈도수의 모든 정렬 기준은 SUBTLEX
interval separated by number of words
- 구간 개수를 정하고 그에 따라 나눠 pearson corr
- zero-in
| SUBTLEX | HAL | SUB Zipf | KE | SUB Zipf | KF | SUB Zipf |
|---|---|---|---|---|---|---|
| 1(High) | 0.7272(n=8005) | (3.54, 7.62) | 0.6807(n=7174) | (3.62, 7.62) | 0.6765(n=7832) | (3.56, 7.62) |
| 2 | 0.2847(n=8005) | 2.96~ | 0.2019(n=7174) | 3.06~ | 0.2106(n=7832) | 2.98~ |
| 3 | 0.2003(n=8005) | 2.49~ | 0.1285(n=7174) | 2.63~ | 0.1027(n=7832) | 2.52~ |
| 4 | 0.2599(n=8005) | 1.90~ | 0.1037(n=7174) | 2.20~ | 0.0977(n=7832) | 2.00~ |
| 5(Low) | 0.0564(n=8005) | 1.29~ | -0.2607(n=7174) | 1.29~ | -0.2654(n=7832) | 1.29~ |
interval separated by Zipf
- 이게 좀 더 제대로된 빈도를 고려한 구분이라 할 수 있지.
- zero-in
| SUBTLEX | HAL(corr=0.8039) | KE(corr=0.7183) | KF(corr=0.6643) |
|---|---|---|---|
| Zipf > 7 | -0.0603(n=9) | 0.0105(n=9) | -0.4920(n=9) |
| 6 | 0.4936(n=119) | 0.5269(n=119) | 0.3974(n=119) |
| 5 | 0.4324(n=598) | 0.4212(n=598) | 0.3496(n=598) |
| 4 | 0.4402(n=3458) | 0.3882(n=3458) | 0.3704(n=3458) |
| 3 | 0.4597(n=11098) | 0.3712(n=11098) | 0.3777(n=11098) |
| 2 | 0.3974(n=15120) | 0.2210(n=15120) | 0.1903(n=15120) |
| 1 | 0.1237(n=9623) | -0.3639(n=5471) | -0.2475(n=8761) |
| Zipf < 1 | 없음 | 없음 | 없음 |
| 비교 단어 개수 | 40,025 | 35,873 | 39,163 |
-
Zipf 변환에 laplace를 추가했는데, lower-bound 계산해보니, Zipf<1은 거의 나오기 힘든 구조.
-
KE 같은 경우, 마지막 low-freq에 0이 많이 잡혀서 그럴 수 있음.
- Zipf(1~2) 구간 단어에 우리 코퍼스에서 0으로 집계된 단어가 많으면 가능한 해석.
-
그에 반해 KF는 단어폭 (word-type)은 우리보다 훨씬 큰데도 구간별 상관이 떨어지니, 우리가 KF랑은 다르다고 할 수도 있겠지.
-
w/o zero freq word
| SUBTLEX | HAL(corr=0.8039) | KE(corr=0.7494) | KF(corr=0.6643) |
|---|---|---|---|
| Zipf > 7 | -0.0603(n=9) | 0.0105(n=9) | -0.4920(n=9) |
| 6 | 0.4936(n=119) | 0.6342(n=118) | 0.3974(n=119) |
| 5 | 0.4780(n=597) | 0.4855(n=588) | 0.3654(n=597) |
| 4 | 0.4444(n=3457) | 0.4161(n=3235) | 0.3782(n=3406) |
| 3 | 0.4597(n=11098) | 0.3147(n=7217) | 0.3683(n=9965) |
| 2 | 0.3974(n=15118) | 0.2244(n=4303) | 0.2271(n=11332) |
| 1 | 0.2023(n=5057) | 0.0818(n=526) | 0.0948(n=3476) |
| Zipf < 1 | 없음 | 없음 | 없음 |
| 비교 단어 개수 | 35,455 | 15,996 | 39,163 |
- 우리 코퍼스는 그냥 저 빈도 단어가 없어서 그런건 아닐까..? → Nope!!
- 혹시 저빈도에 다른 특성이 있는 건 아닐까…? → L2 corpus 특징?
- 이런 가설은 어떨까? L2 English learner의 경우, HF는