Participants
총:49명 분석 대상
전체 LY실험 중 음성수렴이 진행된 범위는 LY001 ~ LY062(62명)
제외 대상은 아래와 같음.
- pilot 및 초기 실험 세팅 변경(6명): LY001, LY003, , LY012, LY014, LY016, LY018
- 2차 실험 제외(1명): LY049
- 실험 미 이해(1명) : LY059
- 설문 미 실시(2명) : LY43, LY52
- 분석 중 탈락 - 일부 반응 누락(3명): LY025, LY057, LY058
따라서 62 - 13 = 49 명
Lobanov(개인 내 Z-scoring)
음성학 분야에서 많이 사용되는 정규화로, 개인 간 편차를 줄이기 위해 하는 개인 내 z-score 변환(주로 모음 대상으로 사용된다고 함.)
- 개인내 모든 모음에 대해서 z-scoring을 하는 걸로 fix.
- : 정규화된 n 번째 Formant 값.
- : 특정 모음(V)의 n 번째 포먼트 값.
- : 해당 화자의 모든 모음에 대한 n 번째 Formant()의 평균
- : 해당 화자의 모든 모음에 대한 의 std.
Metric define
- 에서 Euclidean distance (Z-score normed)
- Vowel Length
lobanov를 기준으로 수렴 여부를 판단?
Multi column
orignal
lobanov normed
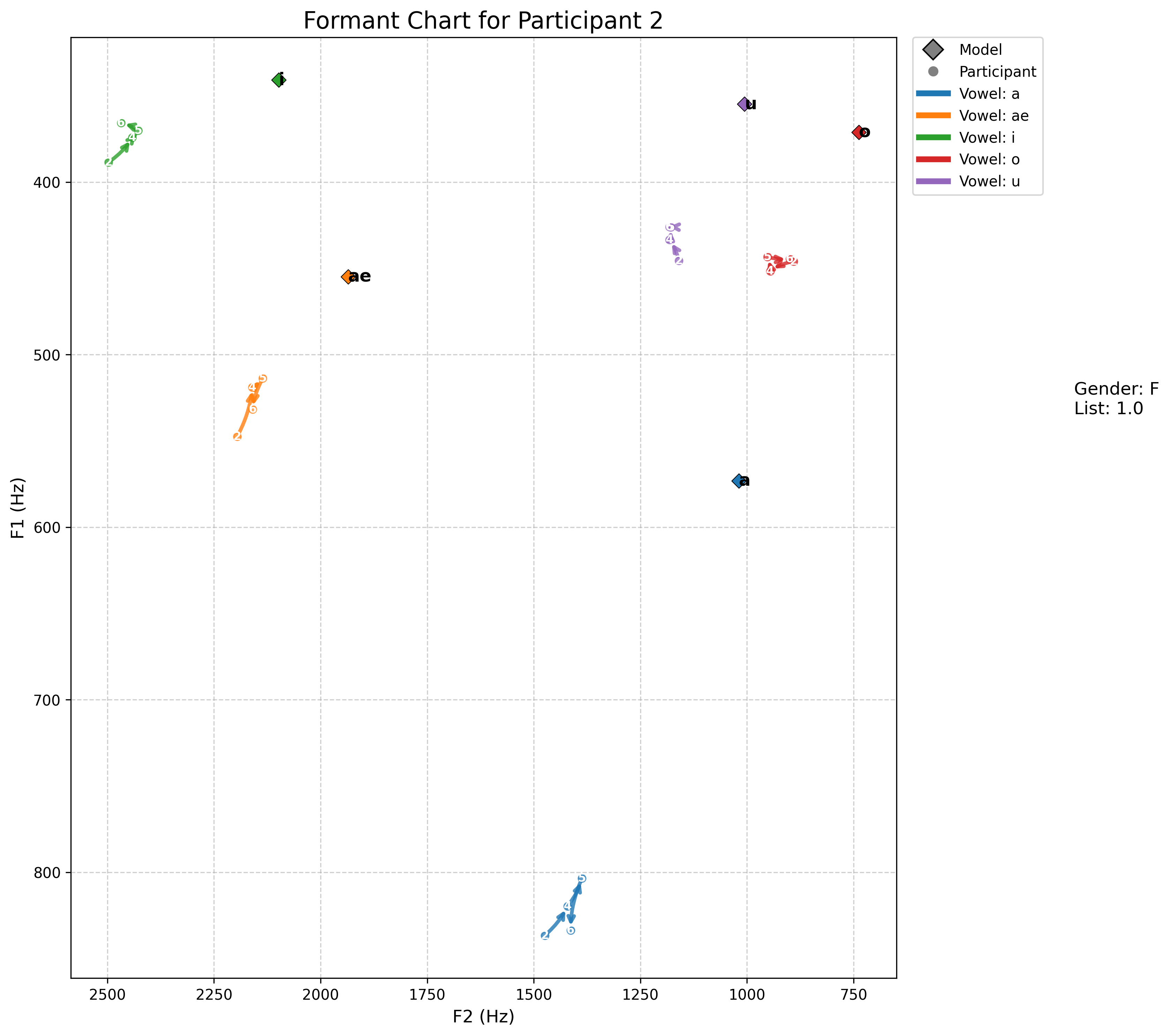
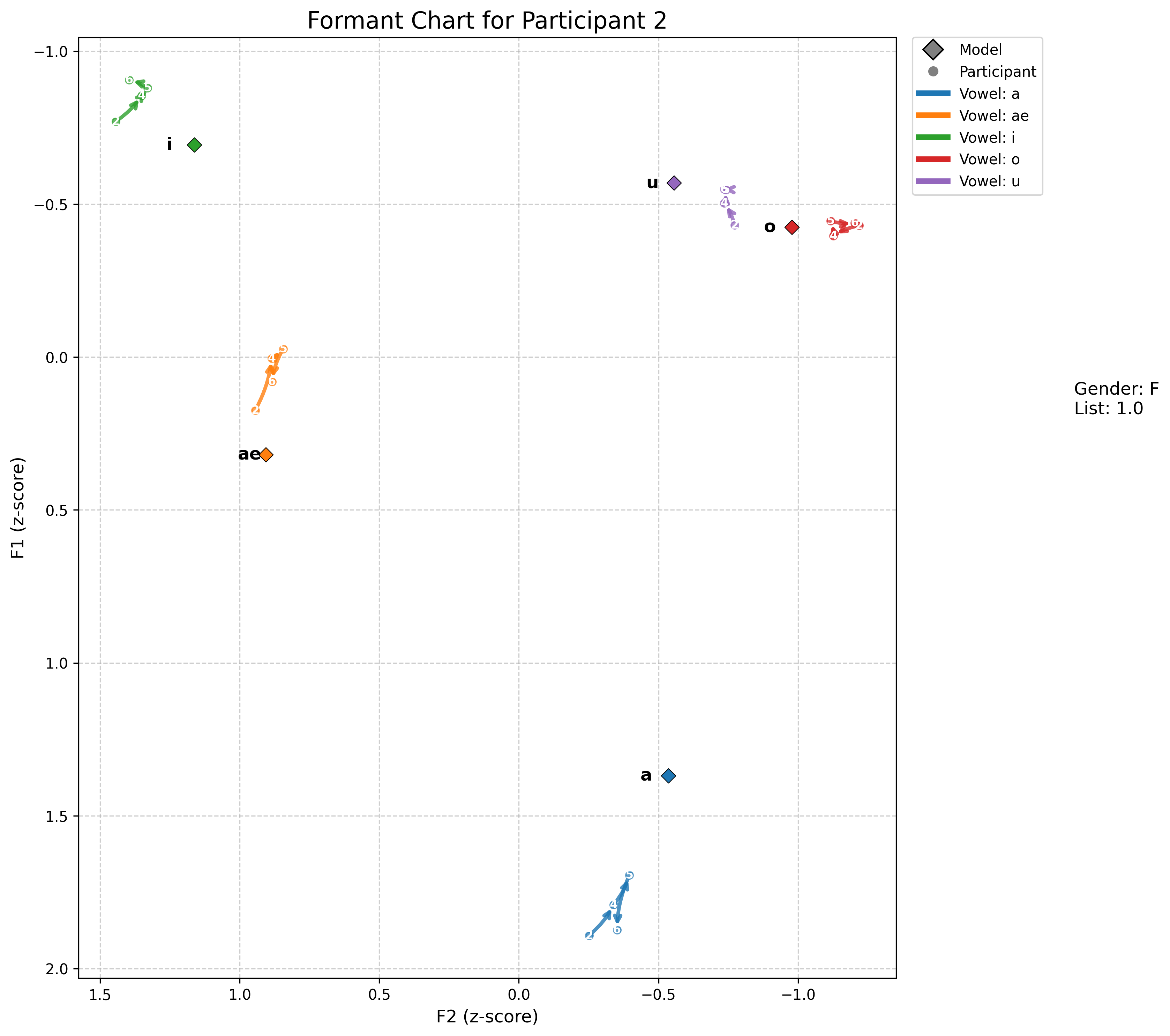
- ae 발음을 보면, normalization 전의 값들은 수렴하지만, normalization(z-score) 이후에는 발산으로 경향이 바뀌었다.
- 고민해보아야 할 포인트는 음성 수렴이라는 현상 자체가 formant(hz)d에 다가하는게 중점일지, 아니면 조음 위치가 닮아가는게 중점일지 고민해보아야 함.
- z-scoring을 하면, 개인차는 없앨 수 있지만, 조음 공간을 포함하여 해석할 수 있게겠지. 근데 그러면 그 metric은 수렴의 지표로써 사용할 수 있나? (타당성)
우리가 보려는 건 음성 수렴이잖아. 이게 포먼트가 닮는다고 조음 위치 수렴이라고 할 수 있을까?
일대일 대응 관계인지 한 번 생각해보고, 이것 때문에 정규화를 하면 안 될지도,,
Result
trajectory(original_formant vs lobanov norm) - 개인별 분석
Multi column
original-freq
lobanov Normalized
.png)
Group 간 분석
아래는 vowel의 구분 없이 mid-point 의 formant의 mean value.
Multi column
original distance
Identity Of Model(exp list) stage2 stage4 stage5 stage6 AI 243.890025 223.523232 228.252480 241.290115 Human 239.136157 236.261951 239.320735 236.621678 lobanov normed - distance
Identity Of Model(exp list) stage2 stage4 stage5 stage6 AI 0.380654 0.267384 0.275615 0.344808 Human 0.345755 0.302511 0.292520 0.343667
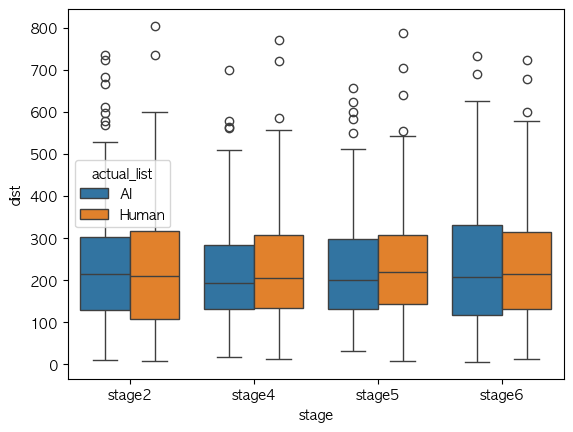
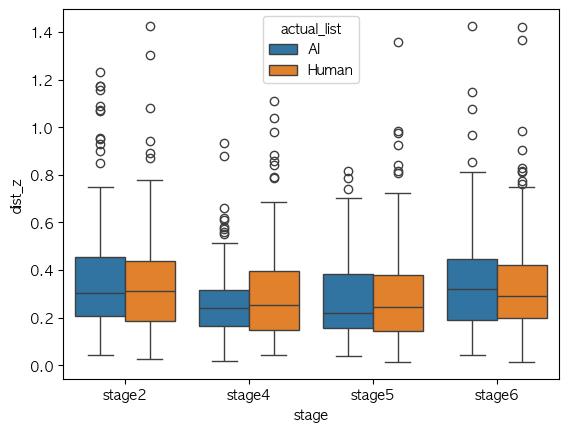
- 기본적인 가설 및 지지 여부
- stage 2 → 4: 모델 화자에 대한 인지적 정보를 제공하지 않았으니, 일반적으로 수렴 예상
- 모든 지표에 대해 수렴. 예상에 부합.
- 정보가 주어지지 않았으니 일반적인 사람 목소리라고 인식헀겠지.
- 모든 지표에 대해 수렴. 예상에 부합.
- stage4 → 5: 모델 화자에 대한 정보가 주어졌으니, 수렴 여부 양상이 달라질거라 예상.
- AI: normalized 여부에 관계 없이 모두 발산. 예상을 지지.
- Human: normalized를 한 경우에만 수렴을 지지. normed value만 예상에 부합.
- stage 4→ 5를 더 잘 설명하는 건, normed를 한 걸 사용하는게 나을 것 같긴 하네.
- stage 5→ 6: 음원을 제시하지 않으니 기본적으로 발산 양상 예상.
- AI: normalized를 한 경우에만 수렴을 지지. 예상에 부합.
- Human: normalized를 한 경우에만 수렴을 지지. normed value만 예상에 부합.
- stage 5→ 6를 더 잘 설명하는 건, normed를 한 걸 사용하는게 나을 것 같긴 하네.
- stage 2 → 4: 모델 화자에 대한 인지적 정보를 제공하지 않았으니, 일반적으로 수렴 예상
정리하자면, 예상을 더 잘 설명하는 건, normalized 된 값들 임.
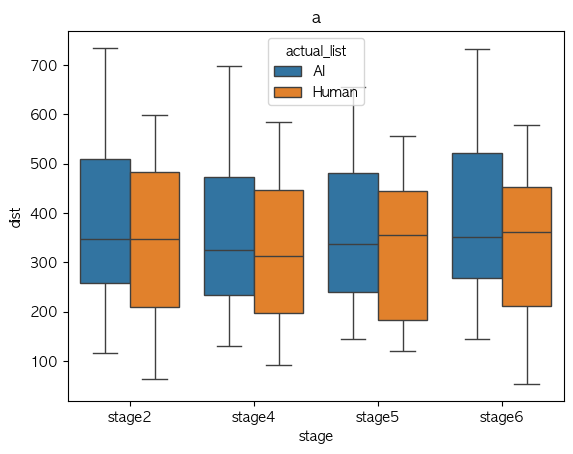
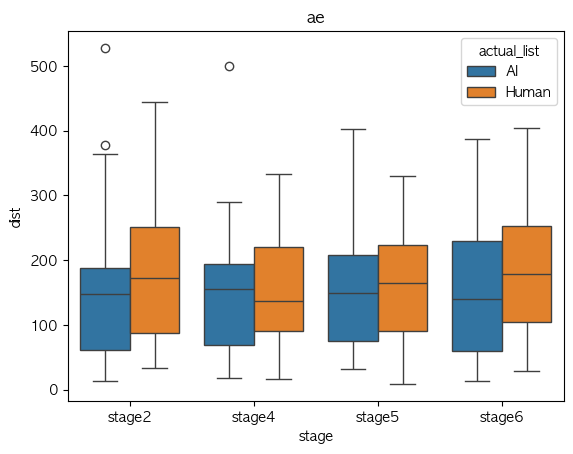
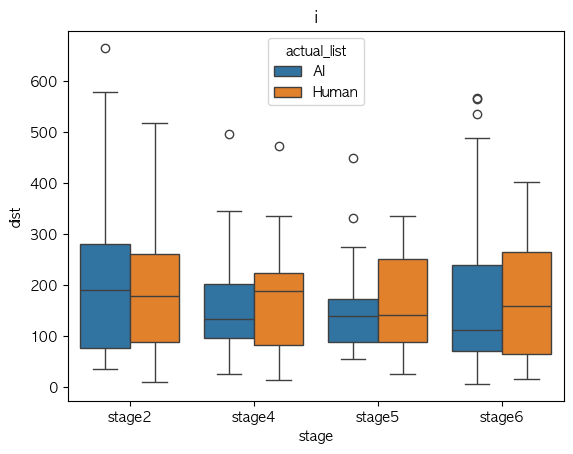
Phone Analysis
Multi column
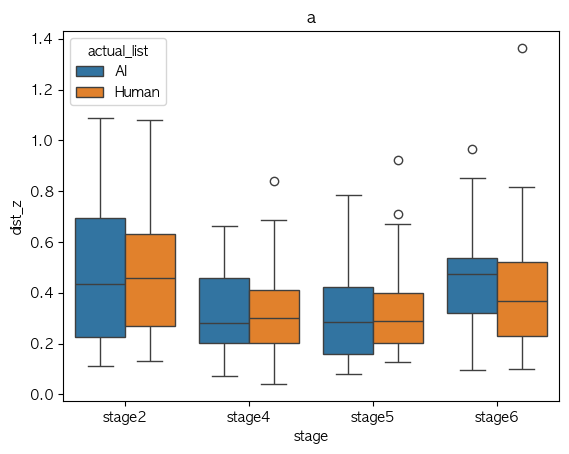
a
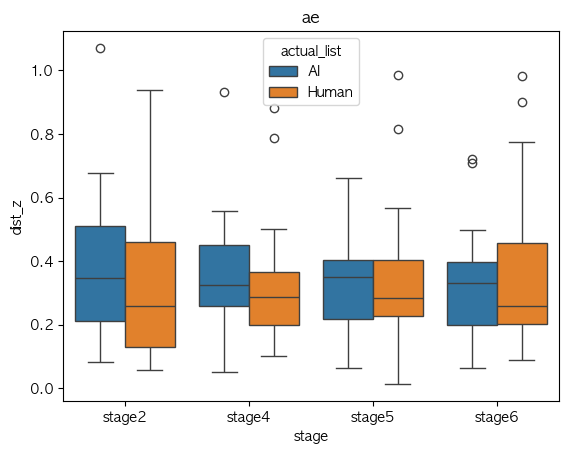
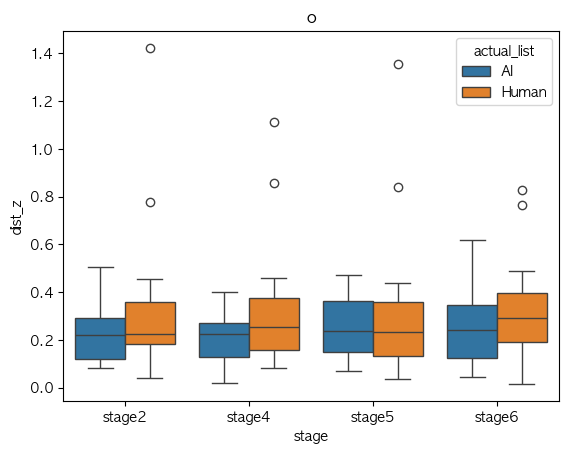
ae
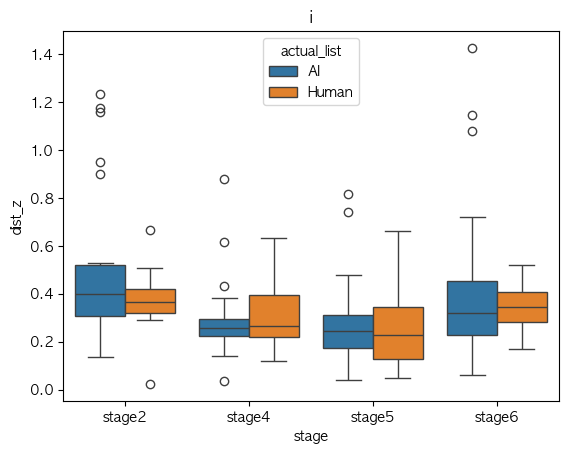
i
o
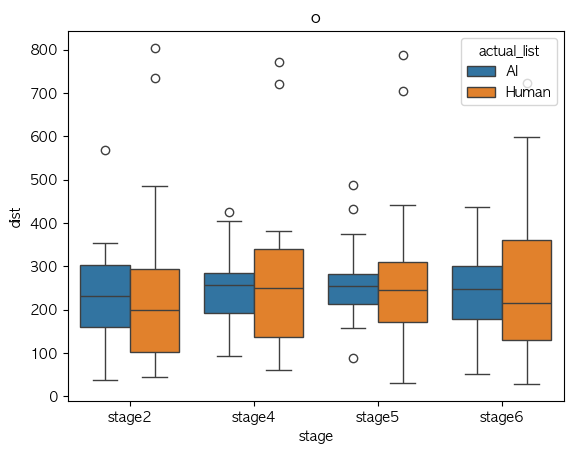
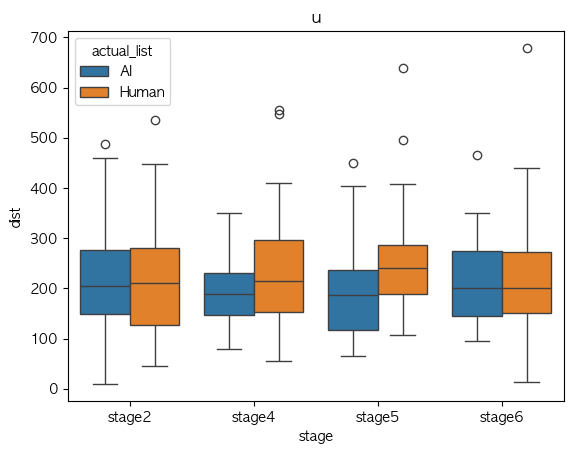
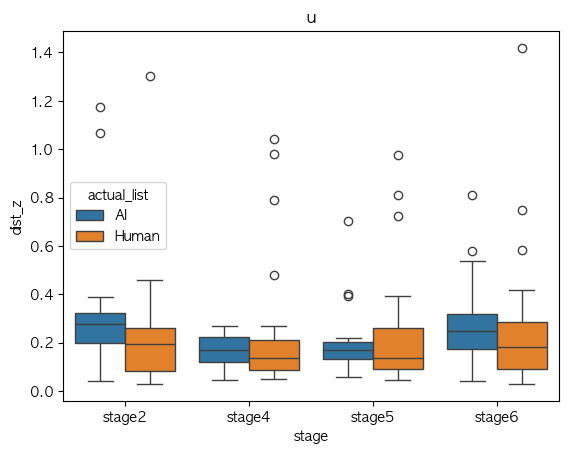
u
Multi column
Mean-val
Phone Identity Of Model(exp list) stage2 stage4 stage5 stage6 가설 지지 여부 a AI 0.478310 0.324896 0.318313 0.455947 X Human 0.486659 0.325267 0.337925 0.421505 X ae AI 0.374968 0.359365 0.337394 0.331823 X Human 0.320407 0.325478 0.340655 0.365667 X i AI 0.500838 0.289216 0.279718 0.407559 X Human 0.376717 0.309786 0.248917 0.349673 V o AI 0.239698 0.202051 0.248765 0.253516 V Human 0.314206 0.310111 0.295548 0.315131 V u AI 0.309456 0.161390 0.193886 0.275194 V Human 0.230785 0.241911 0.239557 0.266359 V Median-val
Phone Identity Of Model(exp list) stage2 stage4 stage5 stage6 가설 지지 여부 a AI 0.434393 0.281231 0.286207 0.475222 V Human 0.458477 0.299897 0.289329 0.366543 V ae AI 0.347552 0.323733 0.351349 0.332473 V Human 0.257598 0.288433 0.285531 0.257959 V i AI 0.397274 0.258481 0.246181 0.321188 X Human 0.366669 0.266127 0.229474 0.344216 V o AI 0.221304 0.223043 0.235388 0.240119 V Human 0.223637 0.253730 0.232407 0.293193 V u AI 0.275822 0.170931 0.170819 0.249657 X Human 0.195052 0.135310 0.137476 0.183026 X
- Mean 값 기준으로 단순 경향 분석에서는 boxplot이랑 좀 상반되게 나오기긴 하는데,
- 이럴만한 이유는 샘플 수가 작다는 점??
Statistical Analysis
ANOVA + Tukey-HSD
현재 보려고 하는 변수들은 총 2가지 → perceived Identity of Model,
- Babel(2012) paper 참고하여 분석 어떻게 하는지 확인해보고, 저번에 발표자료로 쓴 선행 연구 정리된 표에서 AXB 말고 우리가 하는 Euclidean-distance 중심으로 수렴 판단하는 선행 연구들에서 분석 어떻게 하는지 확인할 것.