Statistical Analysis
Evidence for phonetic and social selectivity in spontaneous phonetic imitation (Babel, 2012) 의 분석 방법을 참고.
- Linear Mixed Effects Model 사용하여 regression.
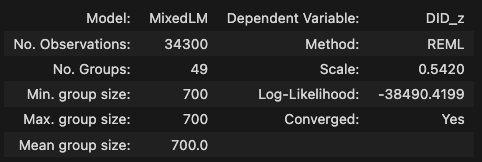
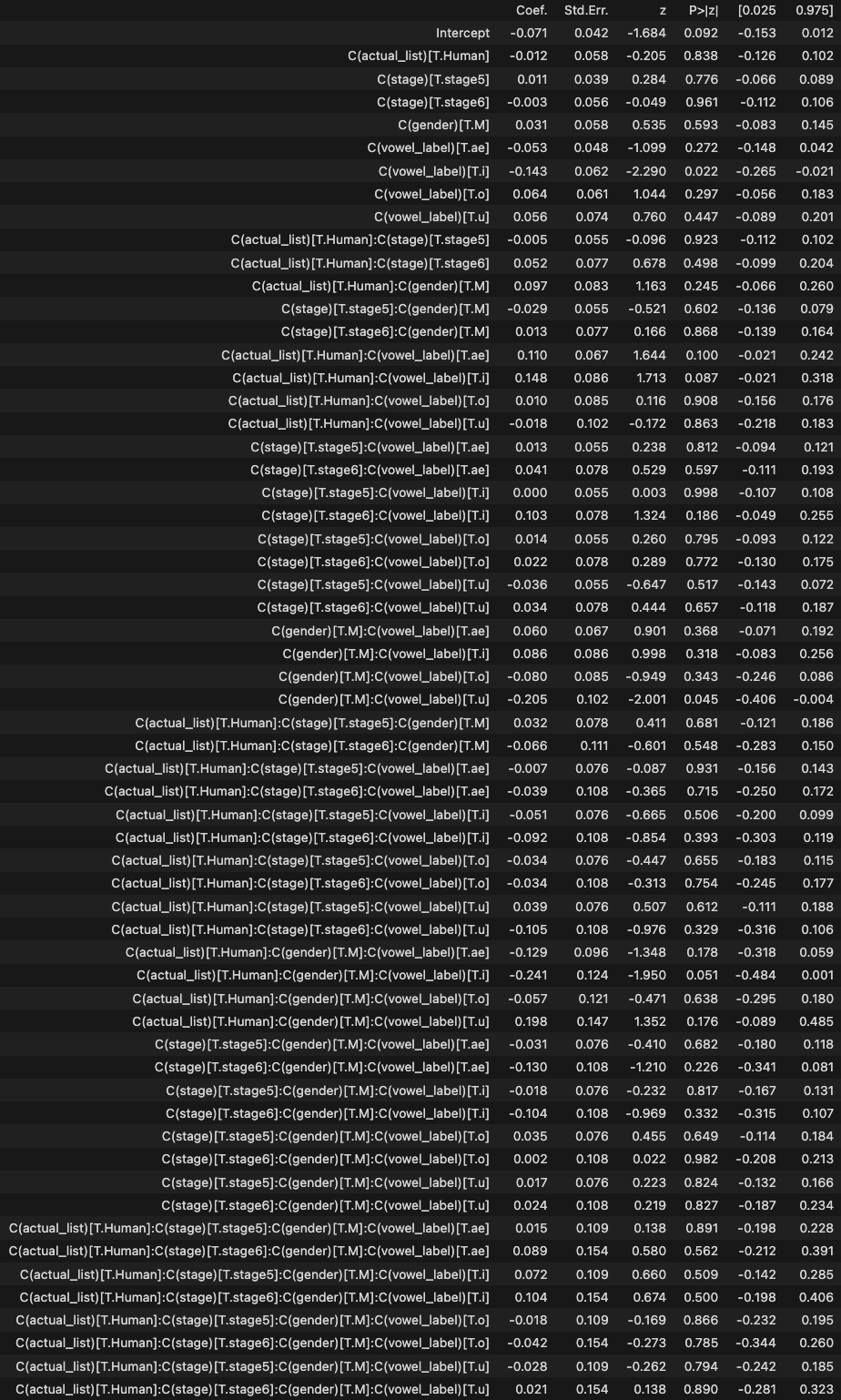
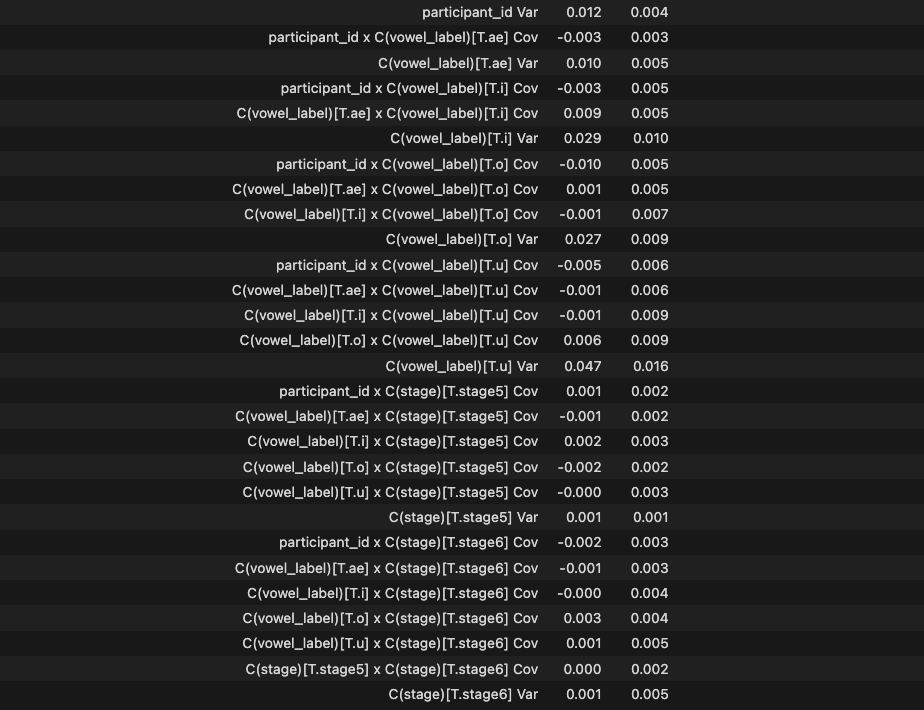
Mixed Linear Effect Model
- dependent: DID_z
- independent: gender(2), list(2), stage(4), vowel_label(5)
- subject-var: stage, vowel_label
Example
# LMM formula = 'DID_z ~ C(actual_list)*C(stage)*C(gender)*C(vowel_label)' model = MixedLM.from_formula(formula, data=analysis_df, groups='participant_id', re_formula='~C(vowel_label) + C(stage)' ).fit() # groups에 id print("--- Statsmodels를 이용한 ANOVA 결과 ---") model.summary()
Multi column
Plan
- 아래의 모든 분석은 vowel by vowel 로 진행
- 음성 수렴이 나타나는가? → gender effect 를 main으로 분석.
- Labeling이 음성 수렴에 영향을 주는가?
- post-task stage에서 다시 diverge하는지.
- pre-task block과 비교한 뒤, pre-task 대비 diverge하는지
- 바로 직전의 test block과 비교 시 발산하는지.
- 이것만 단독으로 보게 될 경우, Audio stimuli가 제거된 경우이니, 일반적인 음성 수렴의 경우에도 diverge하는 것이 일반적.