013 - p-hacking: What it is and how to avoid it!

drug A의 효능을 보기 위해 약을 안 먹은 집단과 A를 먹은 집단의 회복 일수를 plot.
별로 유의미한 차이가 나지 않아 반복.
반복 하다보니, p-value가 .05 수준에서 잡힘. Z는 유효한 약인가?
→ 아니다. (p-hacking)

회복 기간 분포를 아래와 같이 설정하고 샘플링을 통해 3개의 데이터를 가진 각각의 경우에 대해보면, 모두 95% 구간에 잡힌 걸 볼 수 있다.

이 때, 두 경우 각각에 대해 p-value를 구해보면, 매우 크게 나온다. 따라서 두 경우가 각각 다른 분포에서 나왔을 것이라 추정하는 것은 비합리적이다.
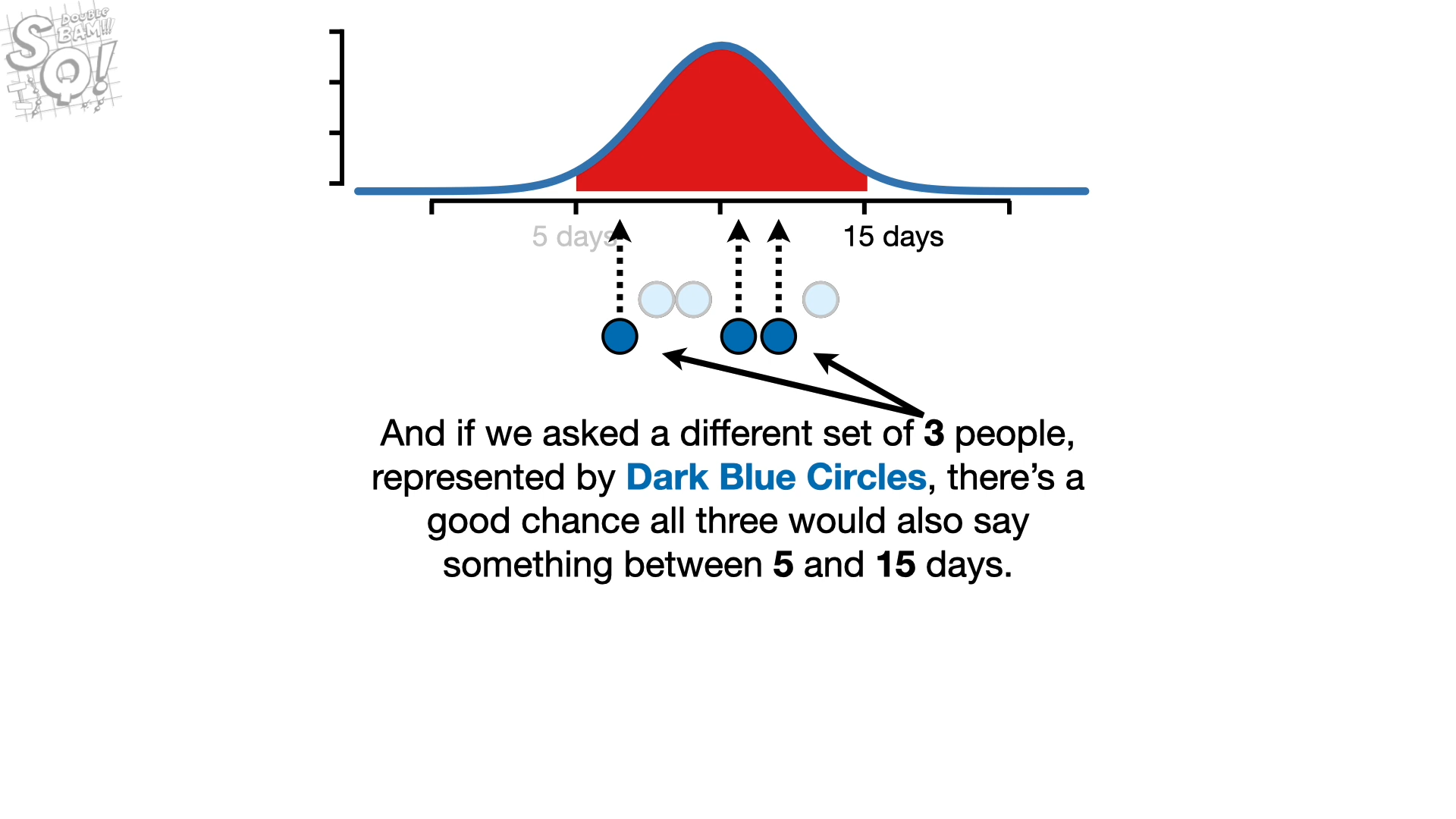
이렇게 한 분포에서 나왔다고 해석하는 것이 타당하다.
Transclude of P-Hacking_Notes_Screenshot_(1.png)
그런데 이러한 무작위 샘플링을 계속하다가 보면,
Transclude of P-Hacking_Notes_Screenshot_(2.png)
이렇게 차이가 좀 나는 경우가 발생할 수 있다. 그리고 이 경우에는 p-value가 낮겠지.
p-value만으로 해석하면, 두 경우가 다른 분포에서 나온 것으로 해석하는 것이 타당하지만, 우리는 실제 그렇게 하지 않았지.
→ p-value 해석에서 random sampling 반복해서 하면, .05 수준에서는 5%의 경우가 해당 해석과 다른 방향으로 나온다고 했는데(type-I error), 그 경우가 이 경우이다.
→ 이러한 문제를 multiple testing problem이라고 한다.
문제가 되는 것은 결국 false positive가 반복 시행시 늘어난다는 점인데, 이를 방지하기 위한 방법으로 FDR(False Discovery Rate), FWER(Fair-Wise Error Rate)를 조절하는 방법이 있다.
FWER: Bonferroni Method, Holm’s Method
FDR: BH method 등
→ 각각의 p-value를 모아서 정렬하고 각기 다른 threshold를 적용하여 reject여부 결정.
- detail
- Benjamini-Hochberg (BH) 절차
가장 널리 사용되는 FDR 조절 방법입니다.- 모든 p-value를 오름차순으로 정렬합니다.
- 각 p-value에 대해 다음 값을 계산합니다: (i/m) * α (여기서 i는 순위, m은 총 검정 수, α는 원하는 FDR 수준)
- p-value가 계산된 값보다 작거나 같은 가장 큰 i를 찾습니다.
- 이 i보다 작거나 같은 순위의 모든 귀무가설을 기각합니다.
- Benjamini-Hochberg (BH) 절차
다른 p-hacking의 사례로, 첫 계산 결과 p값이 유의 수준 근처였을 때, sampling을 더해서 결과를 내면, 유의수준 내로 들어올 수 있다.
→ 이러면 안된다고 한다. 왜냐하면, 첫 계산 결과로 이미 모든 데이터가 한 분포에서 기원했음을 알았기에, 추가된 것은 false positive로 해석해야하기 때문이다.
근데, 만약 sample을 2배로 키워버린다면 어떻게 될까? 이건 완전 별개 케이스로 생각하는 것이 옳을 것 같은데.
이러한 실수를 막기 위해 실험 집단의 최소 사이즈를 파악해야 하는데, 이를 위해 검증력(Power analysis)를 실험 전에 한다.