016 - Power Analysis, Clearly Explained!!!
저번 영상과 마찬가지로, 약 테스트를 할거다. A, B가 있고, 약을 먹고 회복 일수를 y축 값으로 놓으면 아래와 같이 그려진다. 단순히 A가 더 낫다고 할 수 없는게 p-value=.06이 나와서 통계적으로 유의미하지 않았다. 즉, 두 표본이 모두 동일한 모집단에서 기인했다고 보는 해석을 배제할 만큼 충분치 않다는 말이다.

만약, p-value가 거의 근사하게 잡혔다고, 표본 크기를 늘려 다시 통계 검정을 시행했다면 p-hacking임을 명심해라. 이 대신 더 좋은 방법인 power-analysis를 제안. → 다음 실험의 적절한 표본 사이즈를 제공.
Power는 아래의 two factor에 의해 결정.
- how much overlap there is between the two distribution we want to identify with our study
- sample size
예시로, 검정력은 .8 수준으로 맞추고 싶다는 말은, 적어도 80%의 확률로 정확하게 영가설을 기각하겠다는 의미이다. → type 2 : true positive = 1:4
그래서 만약 두 집단이 실제로, 분포가 많이 상이하다면, 적은 수의 sample size로도 원하는 power를 얻을 것.
Transclude of Power_Analysis_Notes_Screenshot_(1.png)
적은 수의 표본들이 각 모집단의 평균을 잘 구분되게 대표해서.
반면, 많이 비슷하다면, 큰 sample size가 요구됨.

예시로 생각해보면, 표본의 평균으로 모집단의 평균을 예측하려고 할 경우, 표본의 크기가 너무 작으면, 추정하는 모집단의 평균이 실제 모집단의 평균과 괴리가 있을 가능성이 더 크기(표본 크기가 큰 경우보다) 때문에
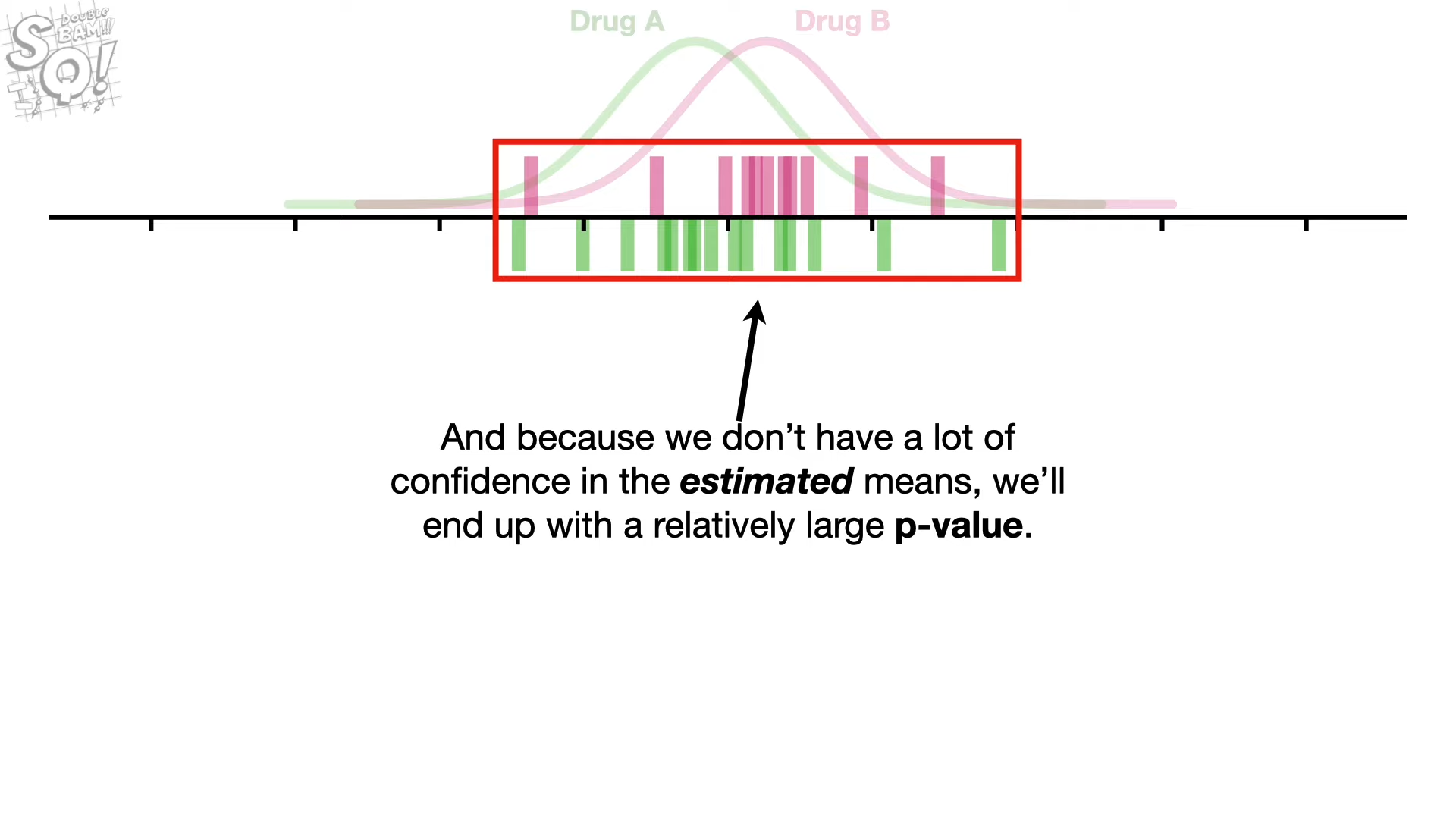
우리는 추정하는 평균(표본의 평균으로 계산됨)에 대해 신뢰할 수 없고, 큰 p-value를 얻게되는데(두 상이한 모집단 분포가 실제로는 다르지만, 평균이 비슷하여) 영가설을 정확하게 기각할 수 없다.
: 이러한 하나의 분포에서 두 표본이 모두 기인했다고 하는 주장을 기각할 수 없다.
Transclude of Power_Analysis_Notes_Screenshot_(11.png)
표본의 크기가 커져야 모집단의 대표성을 더 가진다.
Transclude of Power_Analysis_Notes_Screenshot_(2.png)
점점 표본 크기를 키워보면,,(중심극한 정리에 의해)
Transclude of Power_Analysis_Notes_Screenshot_(4.png)
추정한 모집단의 평균이 실제 모집단의 평균과 유사해지고, 그림에서 볼 수 있듯이 표본들로부터 추정한 모평균(표본 평균)들이 overlap 되지 않는 것들을 확인할 수 있다. → 이는 또한 높은 확률로 정확하게 영가설을 기각할 수 있는 근거가 되어준다.(추정한 모평균이 실 모평균과 가까워지니까.)
→ 다른 말로 하면, 집단의 분포가 많이 겹쳐도 표본의 크기를 키우면, 높은 검정력을 얻을 수 있다.
그리고 중심극한정리: 모집단의 분포가 어떻든 크기가 커지고 많이 추출할 수록, 표본 평균의 분포는 정상분포를 그린다. 그래서 어떠한 분포든 상관 없다.
Transclude of Power_Analysis_Notes_Screenshot_(5.png)
-
실제로 power analysis 적용 방법
-
목표 power 값 정하기 / common = .8
-
threshold 값 정하기 / common = .5
-
overlap 추정하기
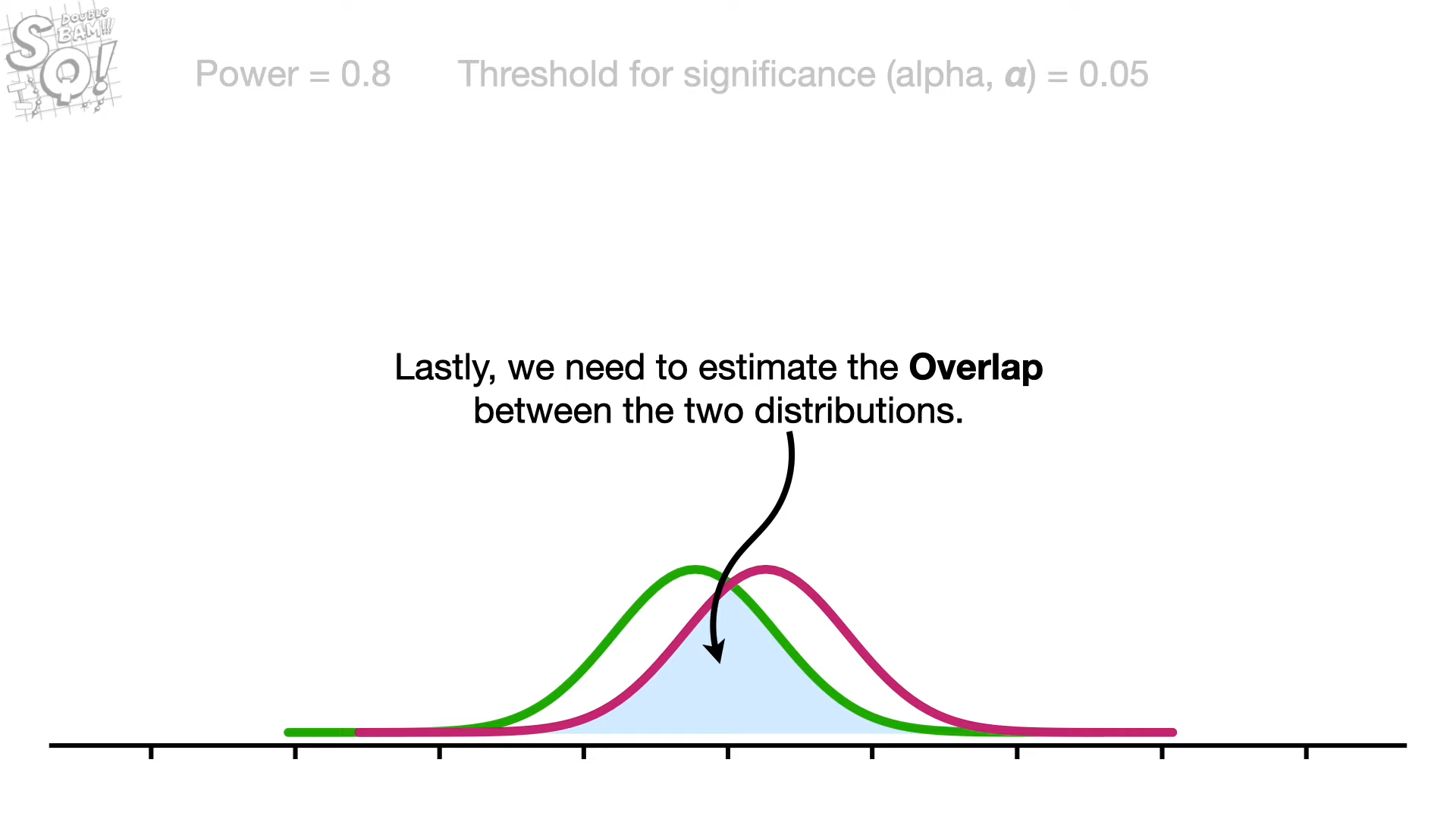
overlap은 두 분포간 평균의 차이, 각각의 std의 영향을 받는데,
일반적은 방법은 effect size라는 metric으로 합쳐서 사용한다.
Transclude of Power_Analysis_Notes_Screenshot_(2
1.png)Transclude of Power_Analysis_Notes_Screenshot_(3
.png)Transclude of Power_Analysis_Notes_Screenshot_(4
1.png)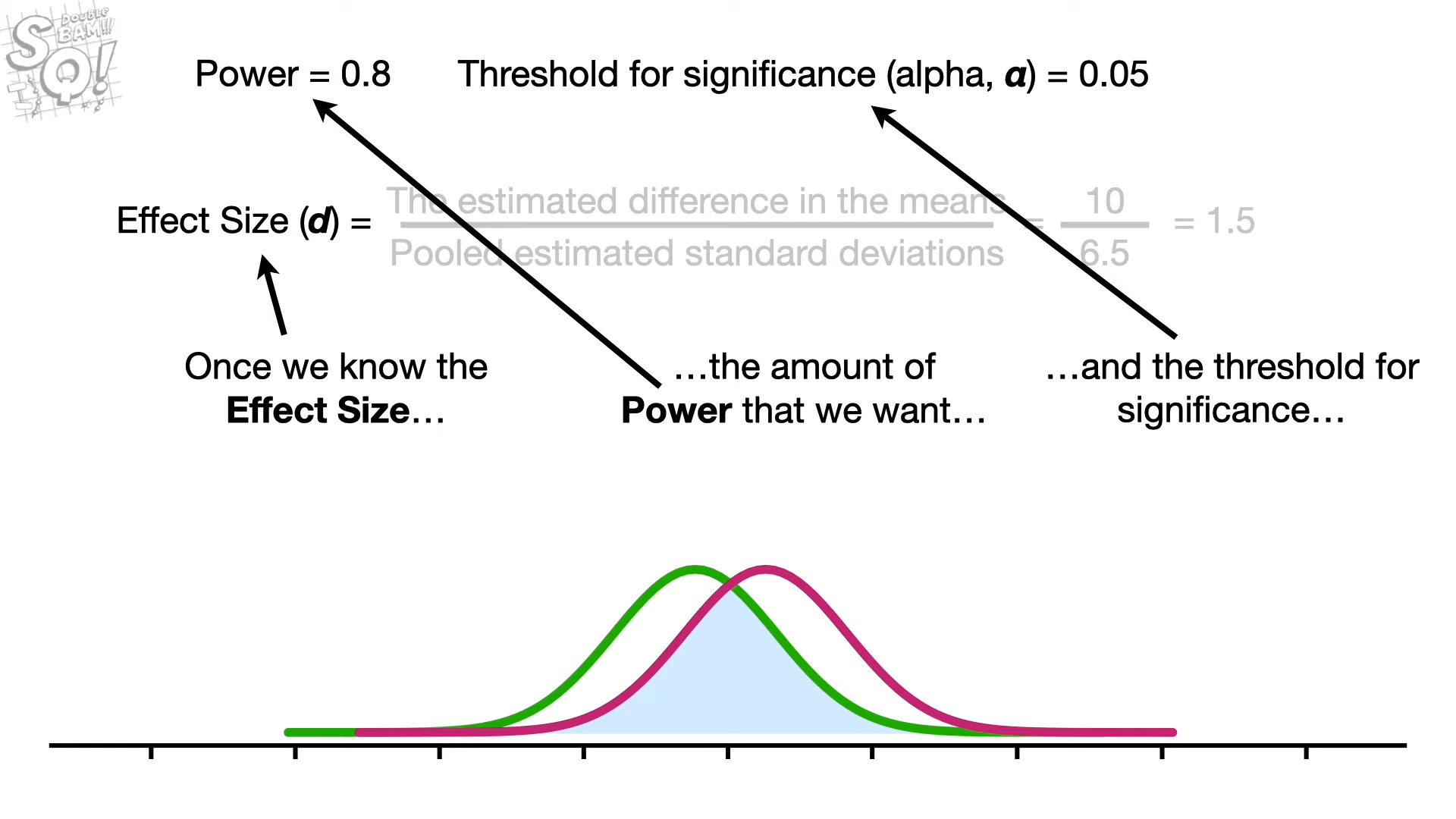
위 세 수치로 sample-size를 구할 수 있다.
-