048 - StatQuest: One or Two Tailed P-Values
약 효과를 검증하려고 하는데, 아래와 같이 one-sided, two-sided 경우에 따라 p-value 가 threshold 기준을 통과하냐 마냐가 달라진다. 이때는 어떻게 해야할까?

단반향 검정은 신약이 기존의 약보다 처치 효능이 낮은 방향에 대해서는 검증을 하지 않는다.
Transclude of One_or_Two_Tailed_P-Values_Notes_Screenshot_(1.png)
근데 데이터를 열어보니, 약효가 있는 방향으로 대부분의 데이터가 편향되어 있다면, 굳이 반대방향(신약이 기존 약의 효능보다 못하다)의 검증을 고려해야 하나?

고려해야 한다. 왜냐하면, 우리가 데이터를 보고 통계를 조작한다면, p-hacking이다. 따라서 우리는 데이터를 보기 전에 사용할 통계방법을 정해야 한다. → 결국 two-sided p-test
예시로 이해해보자. 아래와 같은 분포에서 두 표본을 추출한다고 생각해보자.

대부분의 경우에서 p>.05일 것이다. 한 분포에서 추출했으니, 그만큼 겹치는 부분에서 뽑히기가 쉬울 테니.

하지만, 많이 sampling을 하다보면, 아래처럼 두 표본 간 차이가 크게 sampling 될 때도 있을 것인데, 이러한 경우를 false positive(type 1 err)라 한다.
→ 실제로 같은 분포에서 기인했지만(영가설이 옳지만), 영가설을 기각(두 표본이 다른 분포에서 기인했을 것이라 추정)한 경우
우리가 통계 검정을 .05 수준에서 진행한다면, 이걸 1만 번 t-test를 했을 때, 위와 같은 false positive를 얻을 경우가 500번이라는 것이다.
만 번 검정에 대한 각각의 p-value를 모아 histogram을 그리면,
Transclude of One_or_Two_Tailed_P-Values_Notes_Screenshot_(2.png)
저 빨간 건 fp인데, 왜냐면, 실제는 영가설을 기각하면 안되니까.
이 상황을 조금만 바꿔보자.
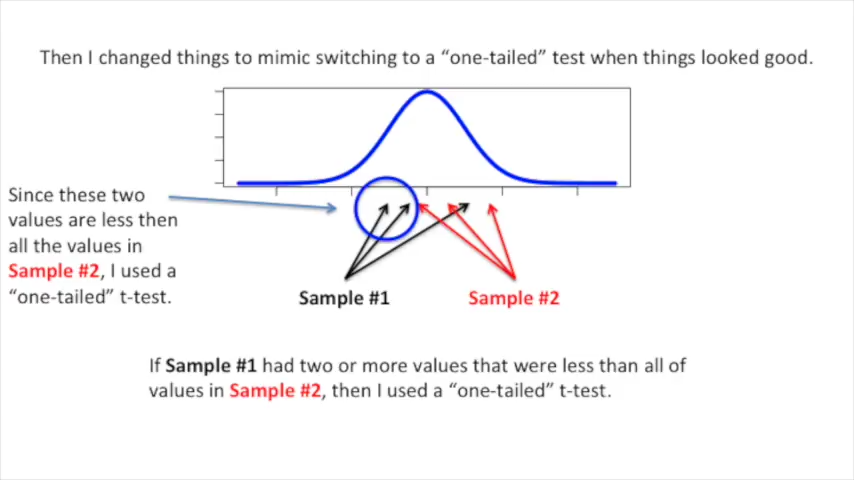
전체적으로 데이터가 좀 분산되게,,
그러면 p-value 분포가 아래와 같이 바뀌게 된다.

전보다 fp가 늘었다.
fp가 5% → 8%로 늘어났다. 우리가 threshold를 .05로 유지했음에도 불구하고
따라서 사용할 방법을 정하는 것을 무조건 데이터를 보기 이전에 해야한다.