Summary
Reward 라고 하는 값을 long-term으로 봤을 때 maximize 하도록 function을 학습하는 기법이다.
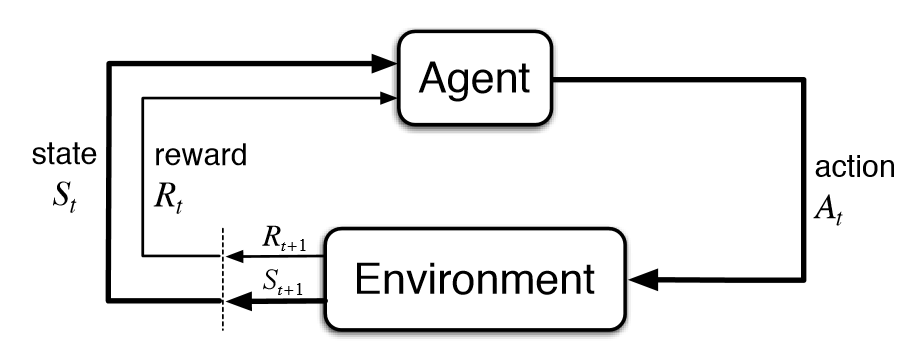
기본적인 paradigm은 Env(환경)에 Agent를 넣고 둘 간의 interaction을 보는 것이다.
주고 받는 정보는 아래와 같으며, agent가 action을 함으로써 state가 transition되고, env로부터 reward가 계산되며 계속 action을 하는 방향으로 학습된다.ex) games, Go, chess, etc…
Important
long-term의 reward를 극대화하는 것이 목표이므로, 단기적 손실은 희생(sacrifice)한다.