RNN Applications
RNN Applications
Language Modeling
Language Modeling
Summary
다음 단어를 예측하는 task.
- NTP(Next Token Prediction)..
- 대표적인 benchmark task
- 많은 NLP task의 subcomponent 이다.
- predictive typing
- speech recognition
- handwriting recognition
- spelling/grammar correctopm
- machine translation
- etc..
formal 하게는 아래와 같이 정의됨.
원본 링크NOTE
give a sequence of words ,
compute the probability distribution of the next word :
where can be any word in voca
A system that does this called a Language Model.
- Language model : a system that assigns a probability to a piece of text.
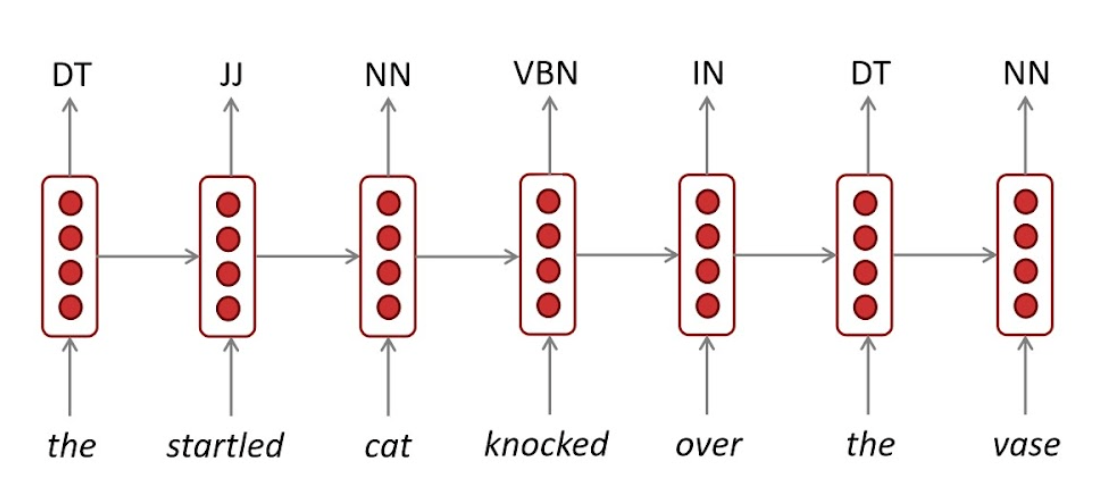
POS(part of speech) tagging
Summary
context 정보가 품사 tagging에 중요하기 때문에 RNN 계열이 사용됨.
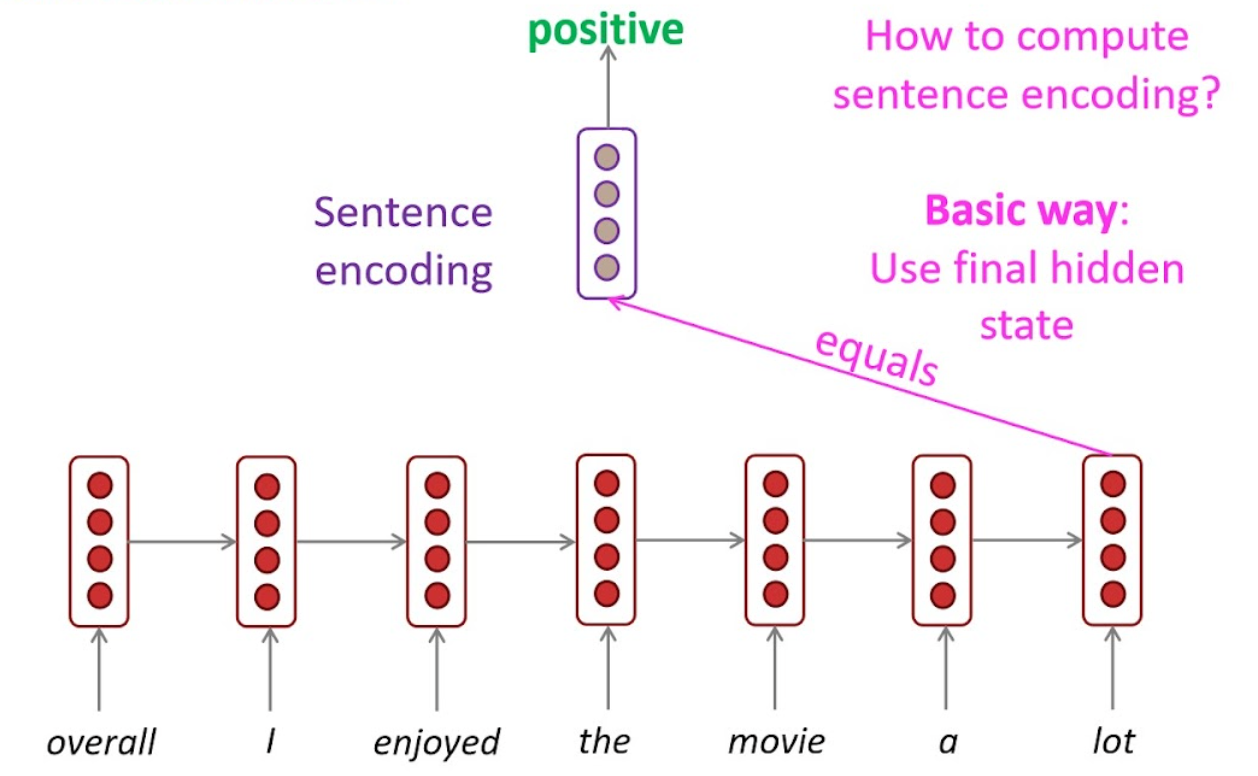
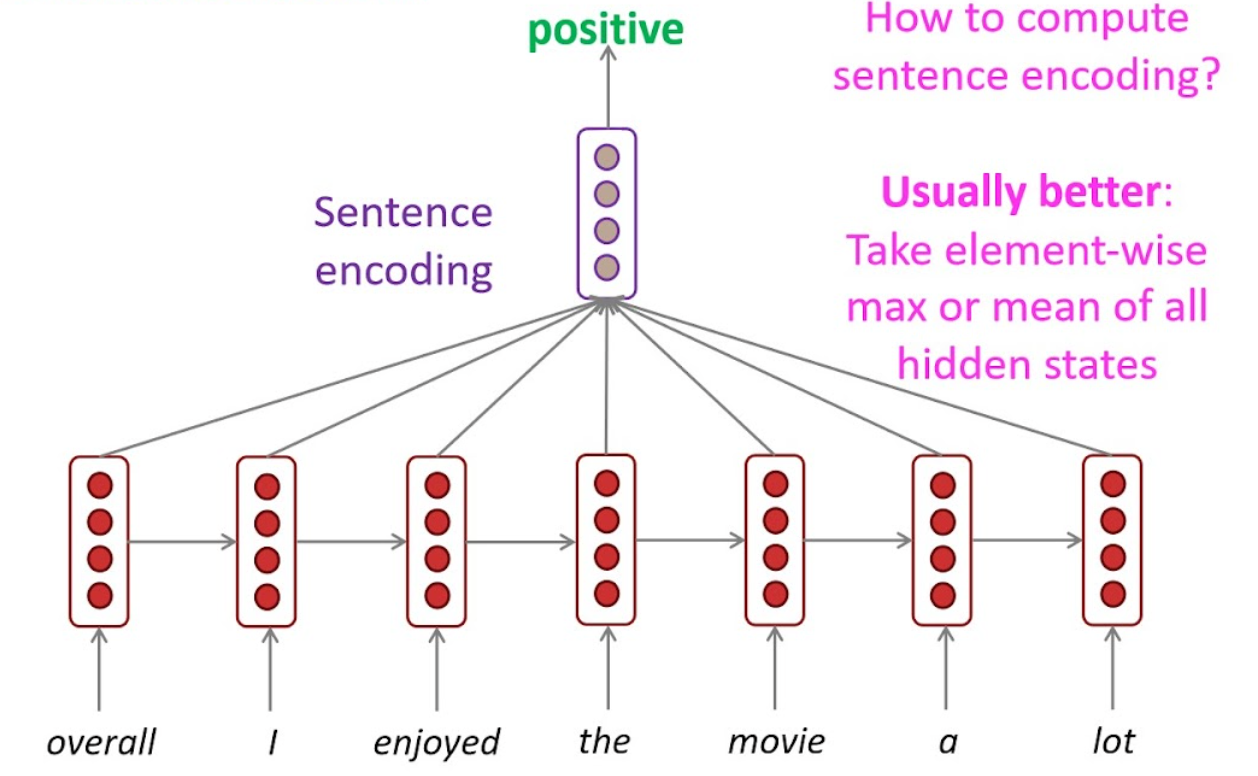
Sentiment classification
Summary
상품평이 긍/부정인지 판단.
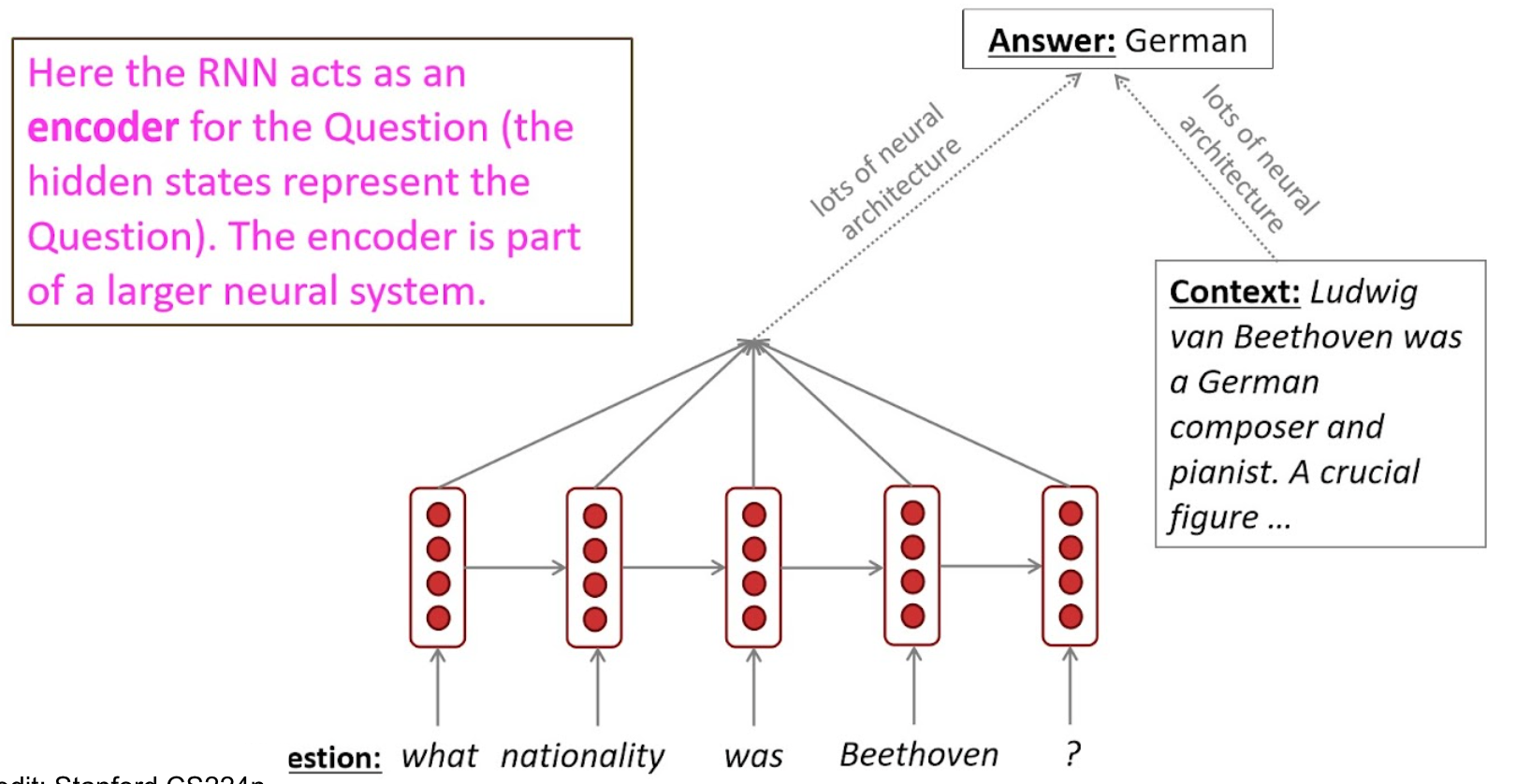
QA(Question Answering)
Summary
question에 context를 붙여서 answering.
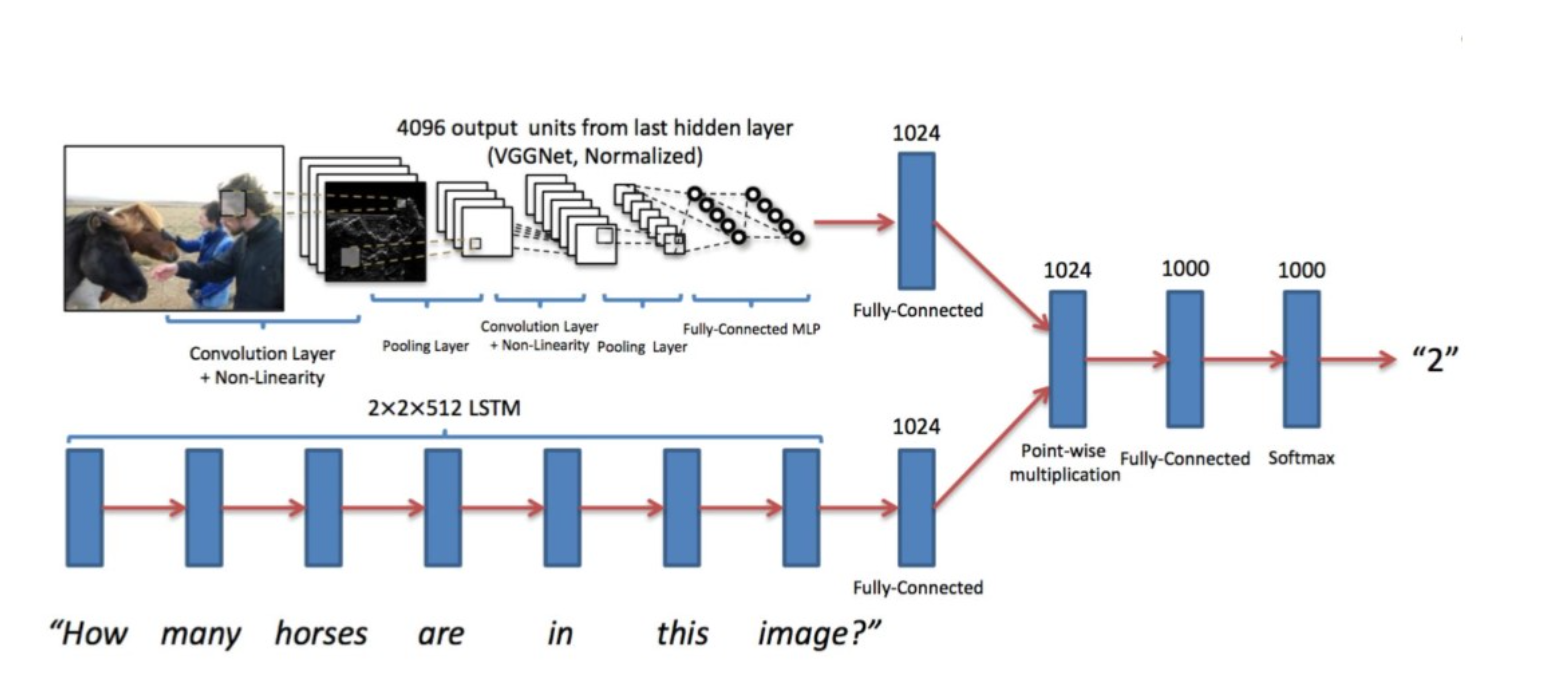
Visual Question Answering
Summary
QA에서 context가 img로 바뀐 task.
보이는 것처럼, CNN, RNN 모두 encoding하고 묶어준 뒤(add or concat, etc..), decoding.Tip
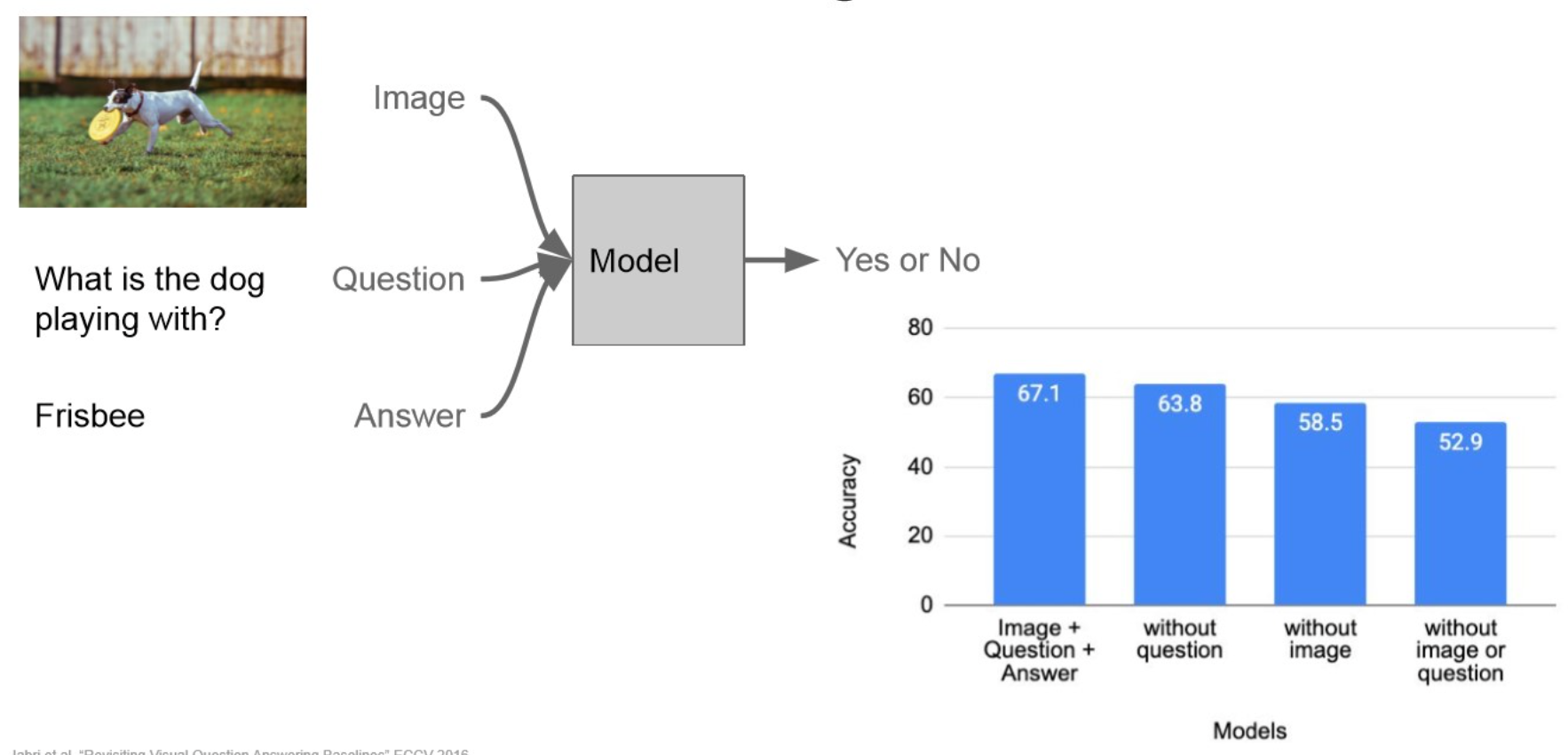
Visual Dialog:
VQA처럼 context에 visual source도 같이.
“multi-modal”Important
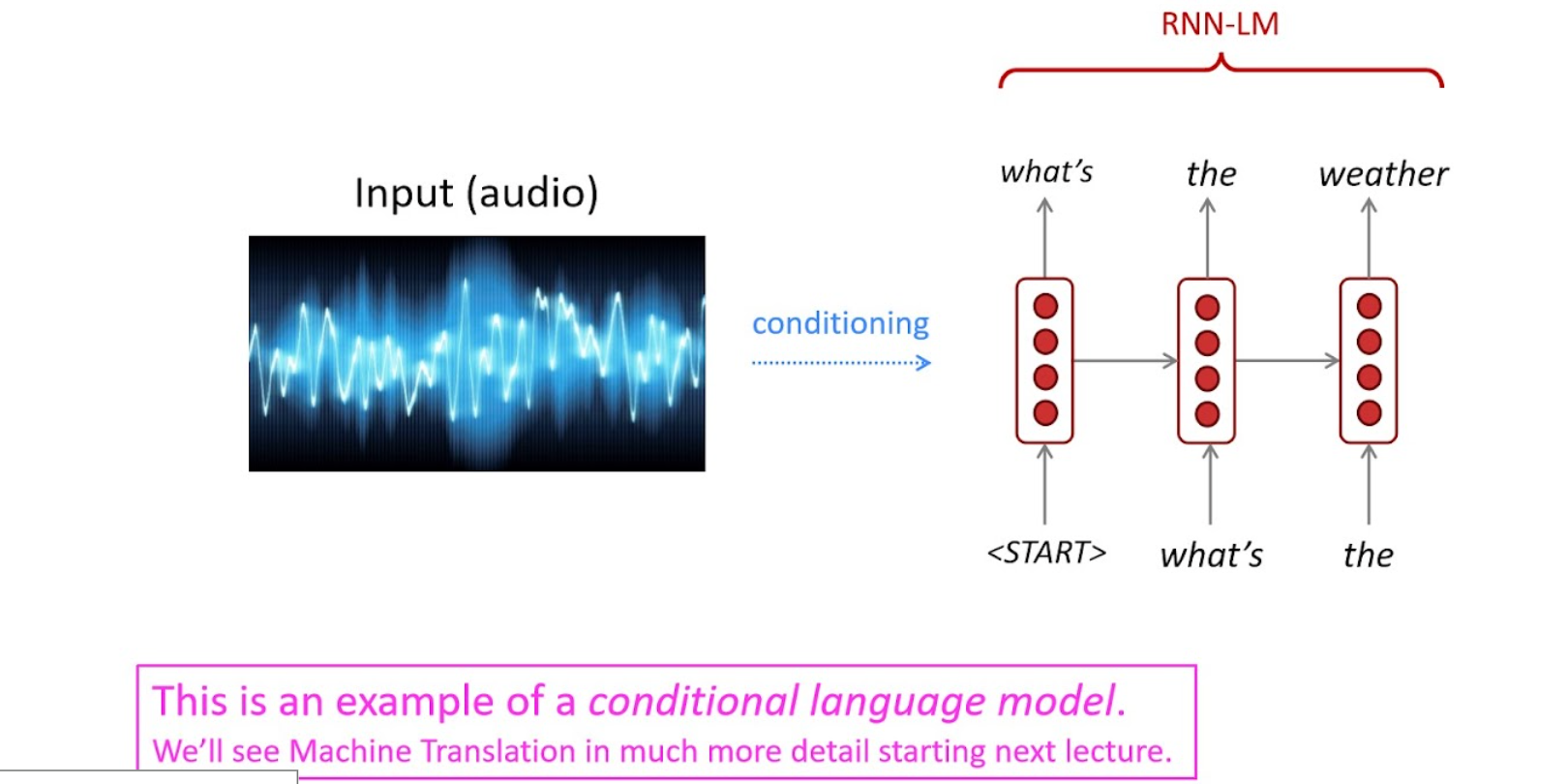
다른 과제들도 마찬가지이지만, dataset의 label이 편향되어 있다면, 모델 자체에도 평햔이 생김.Speech Recognition
Summary
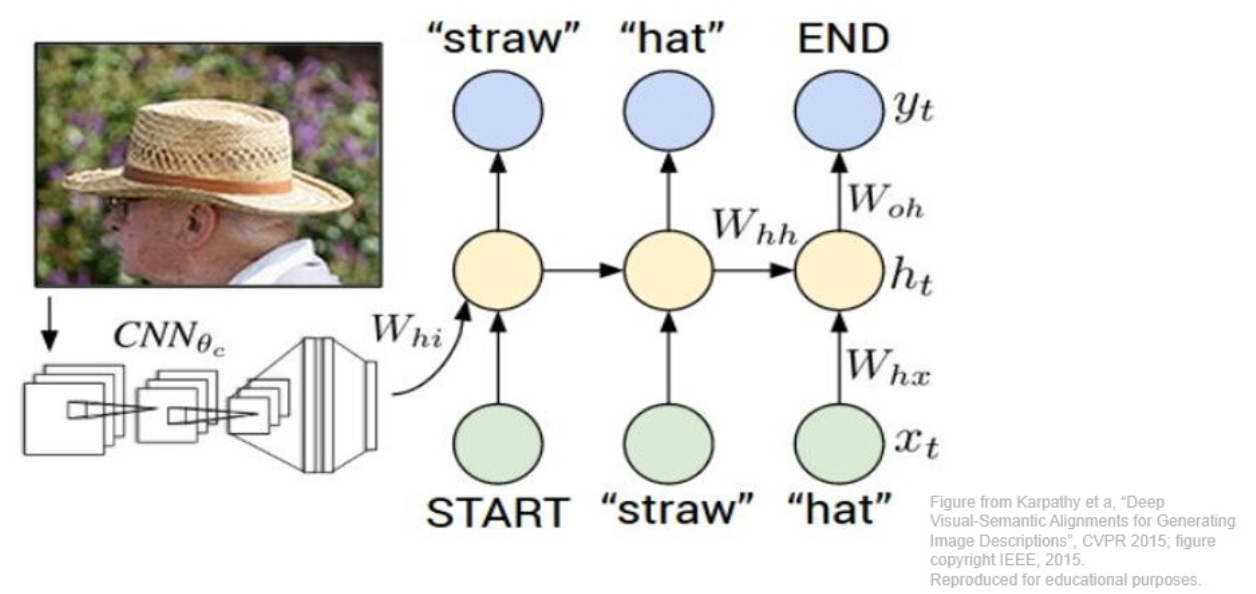
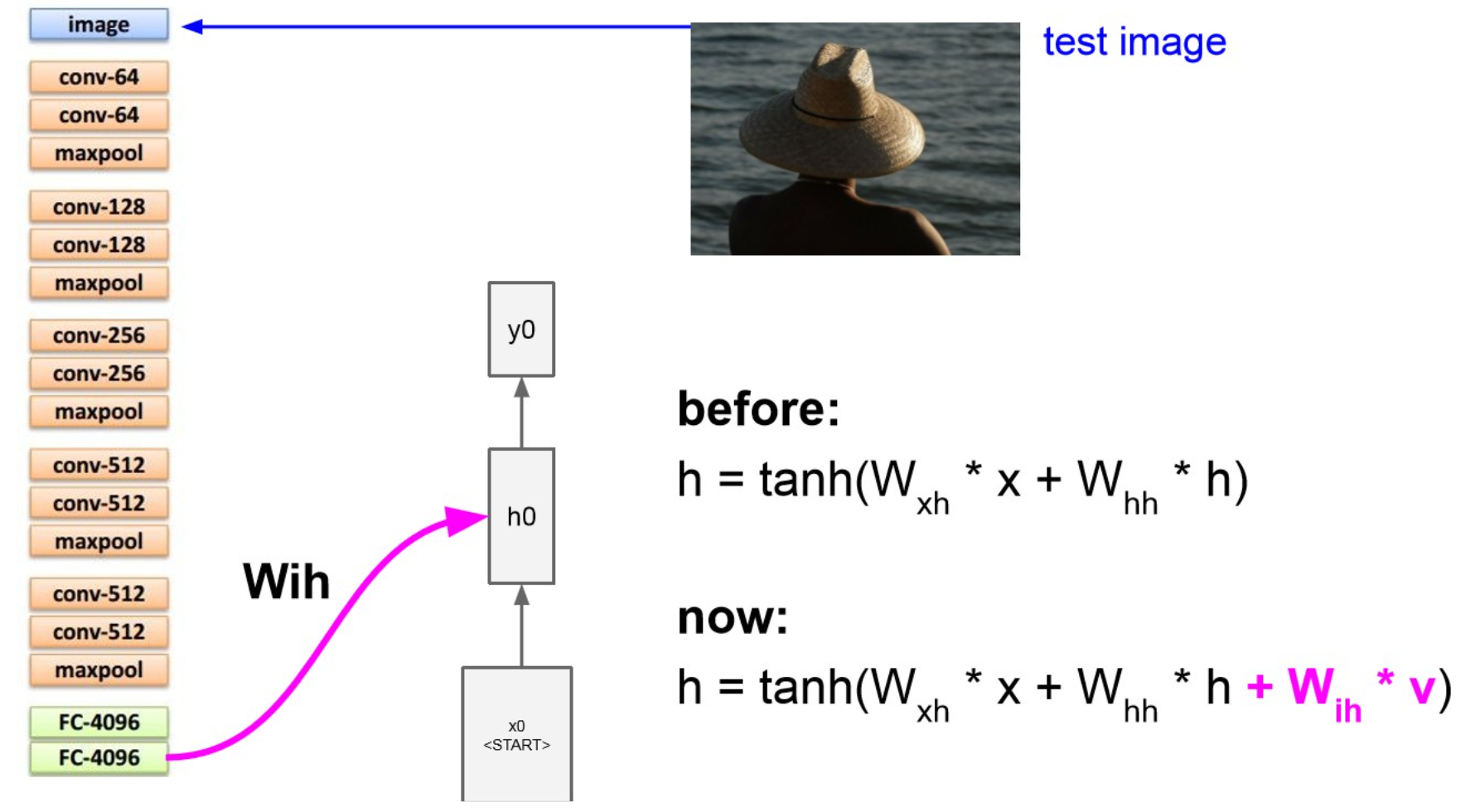
Image Captioning
Summary
speech recognition과 마찬가지로, conditioning이 들어감.
conditioning을 통해 img를 hidden state로 만들어 줌.
최종 목적은 img에 대한 description을 뽑아 내는 것.
- 앞 부분은 CNN, 뒷 부분은 RNN
NOTE
AlexNet과 같은 CNN base model을 돌리리다가, 마지막 softmax는 필요 없으니 그부분은 떼고,
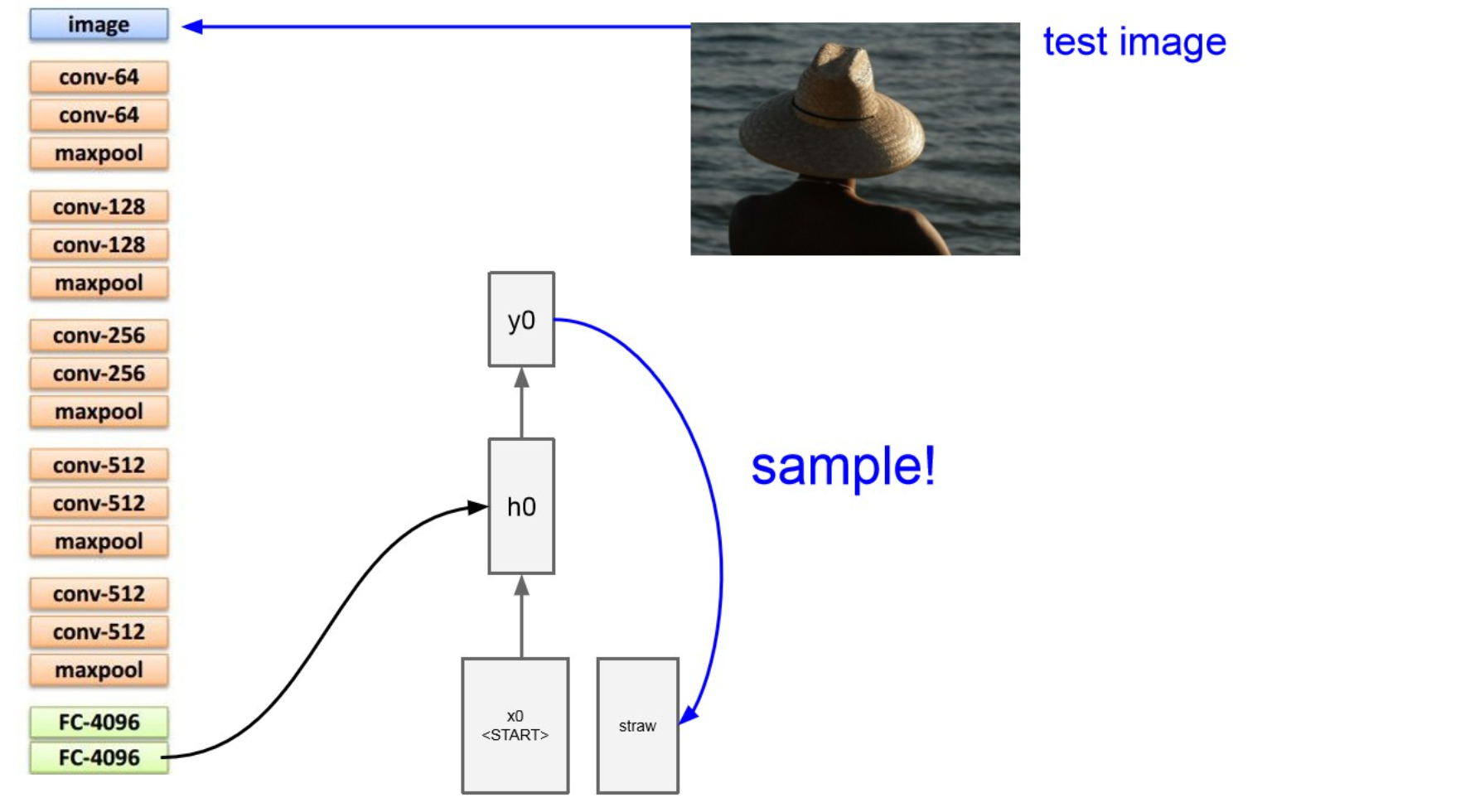
이후에 RNN에 넣는데, sos(start of seq) token 을 넣어주면서 text generate.
이후 generate 된 text를 sampling하면서 반복적으로 생성.
가 end token을 뱉으면 멈춤.Example
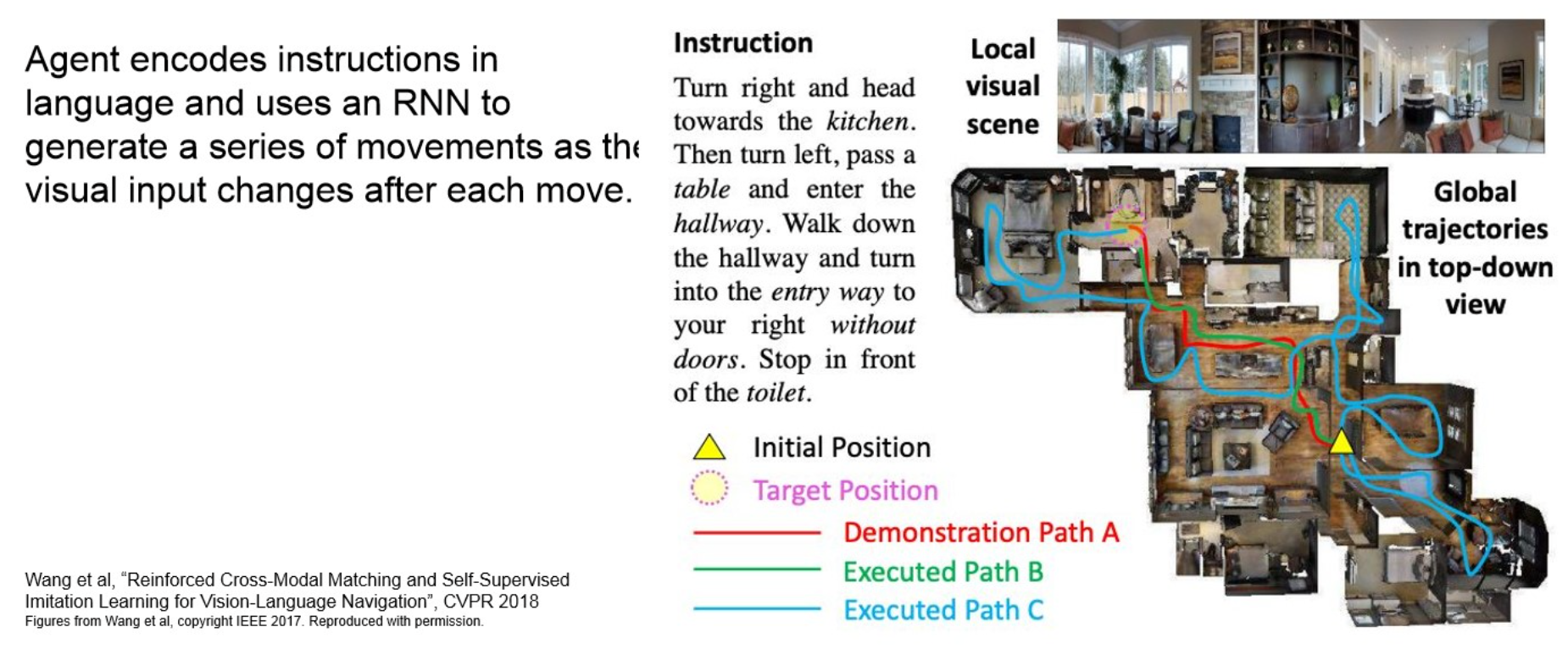
Visual Language Navigation
원본 링크Summary
기존의 visual information만 사용해서 navigate하는 것이 아니라, natural language source도 같이 사용.



Multi-layer RNN
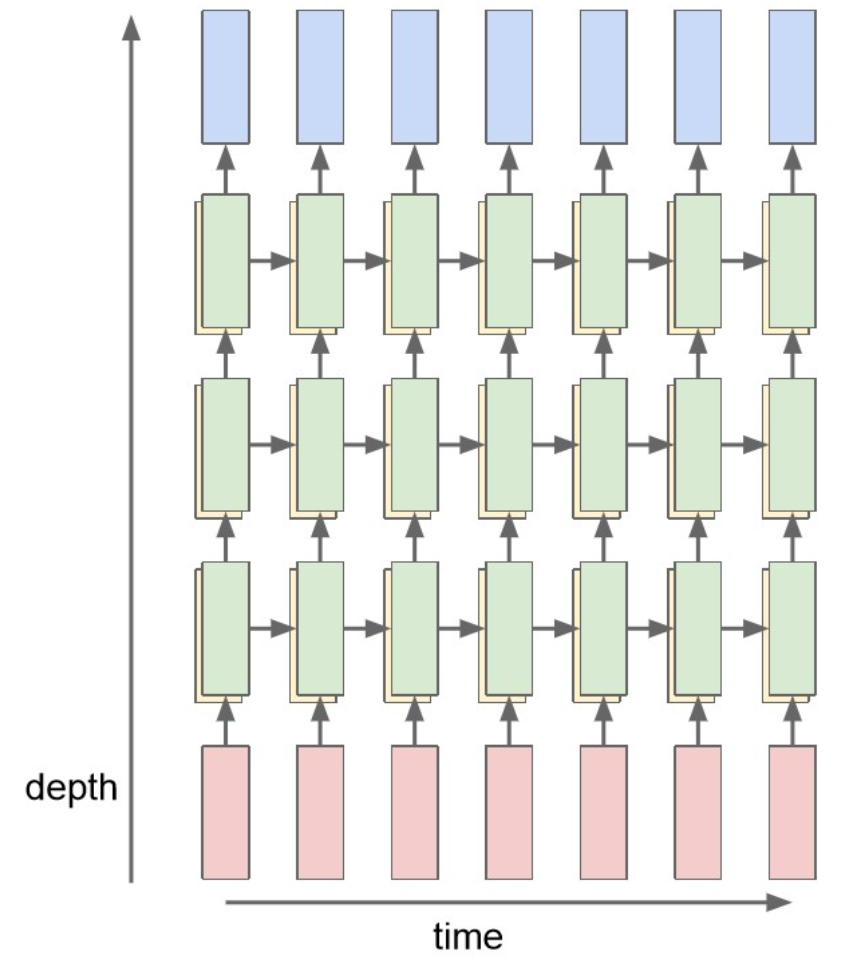
Multi-layer RNN
원본 링크Summary
CNN과 마찬가지로, RNN도 적층.
한 번 RNN을 통과한 output을 input 삼아 처리.
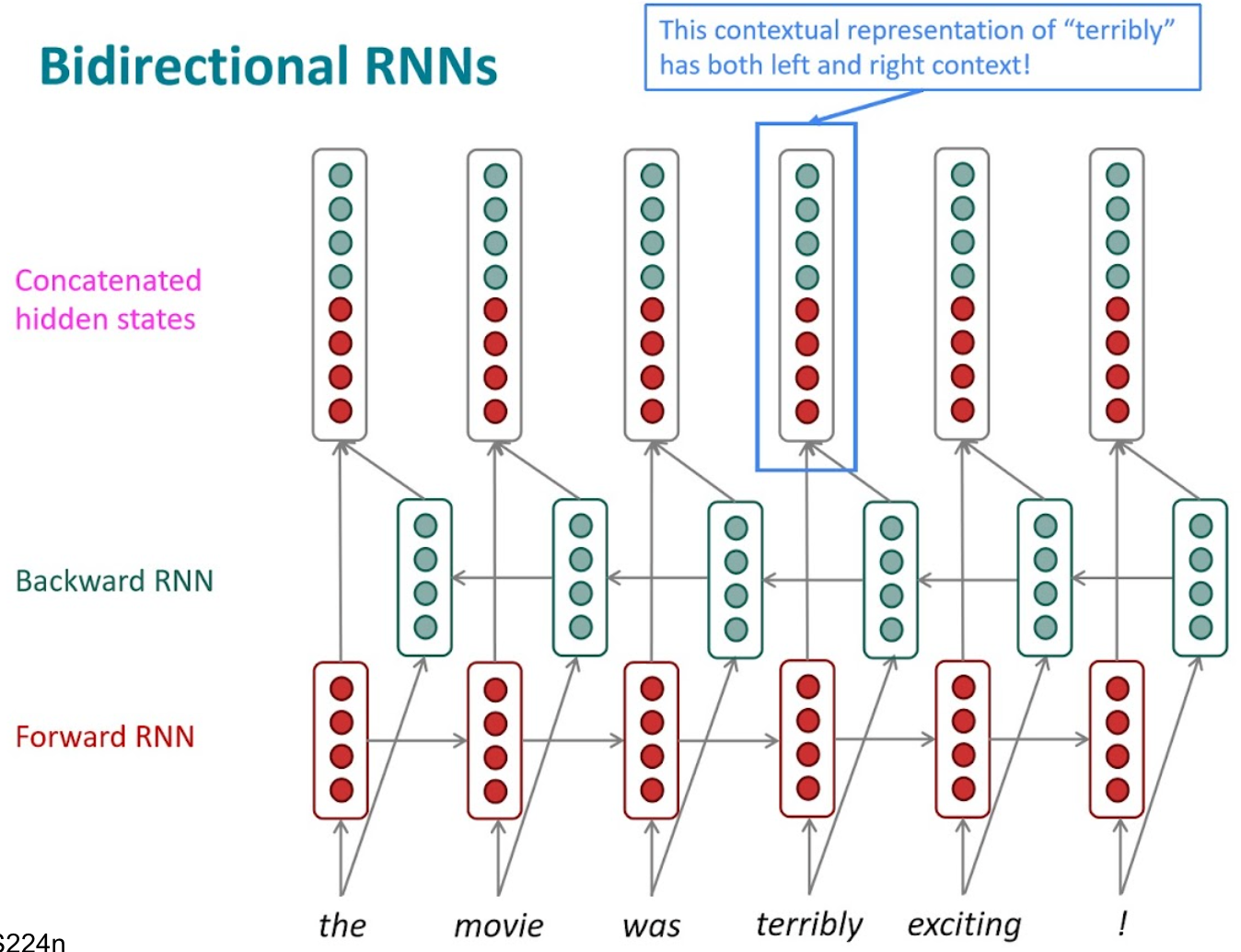
Bidirectional RNN
Bidirectional RNN
원본 링크Summary
input seq의 순서를 양 방향으로 처리.
forward는 일반적인 방향으로 넣고,
backward는 반대로 넣은 뒤
concat을 하던 아님, 더하던 등.
seq에 대한 “이해”가 주 목적일 때 채택.

Gated RNN
Gated RNN
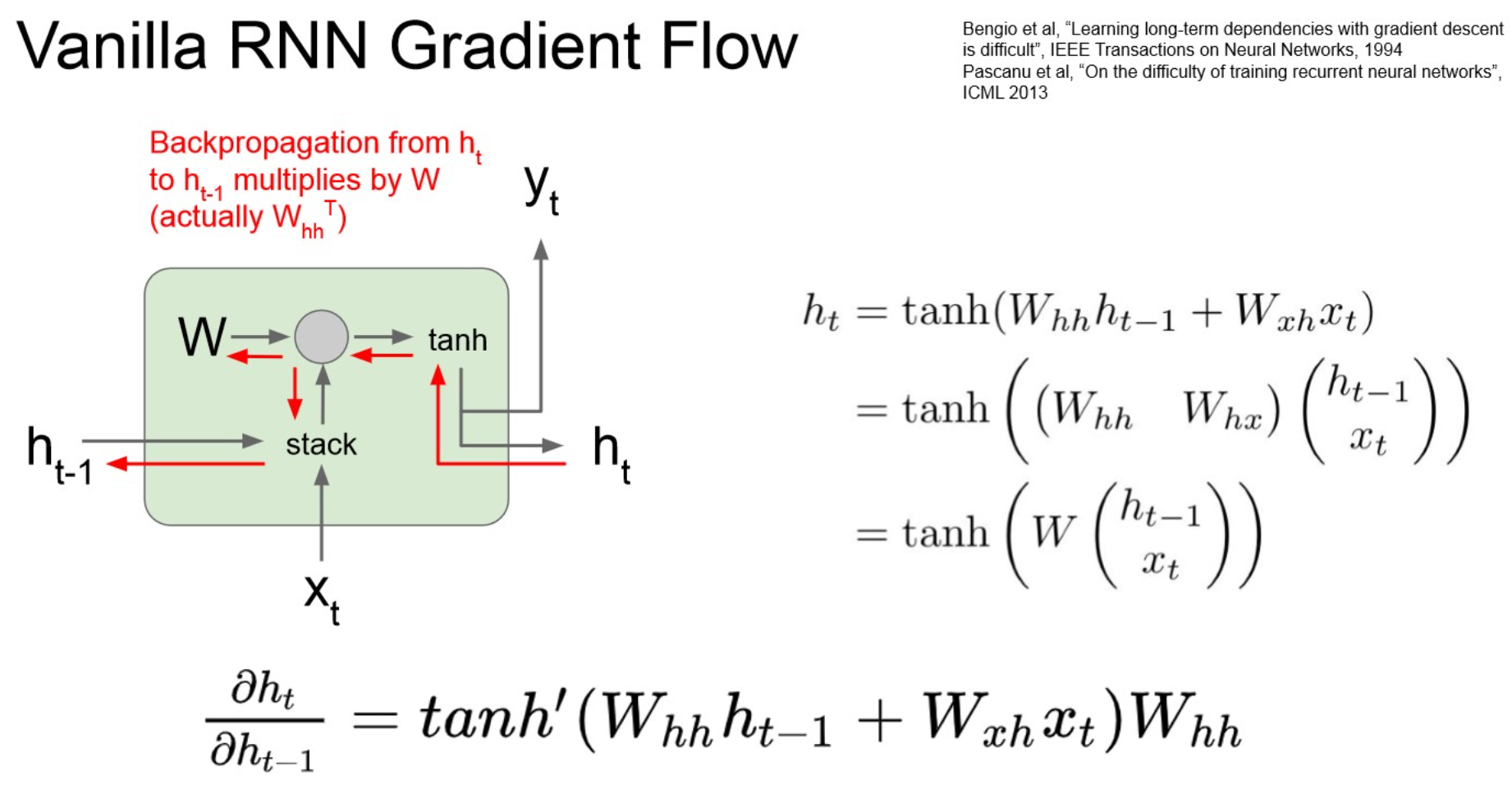
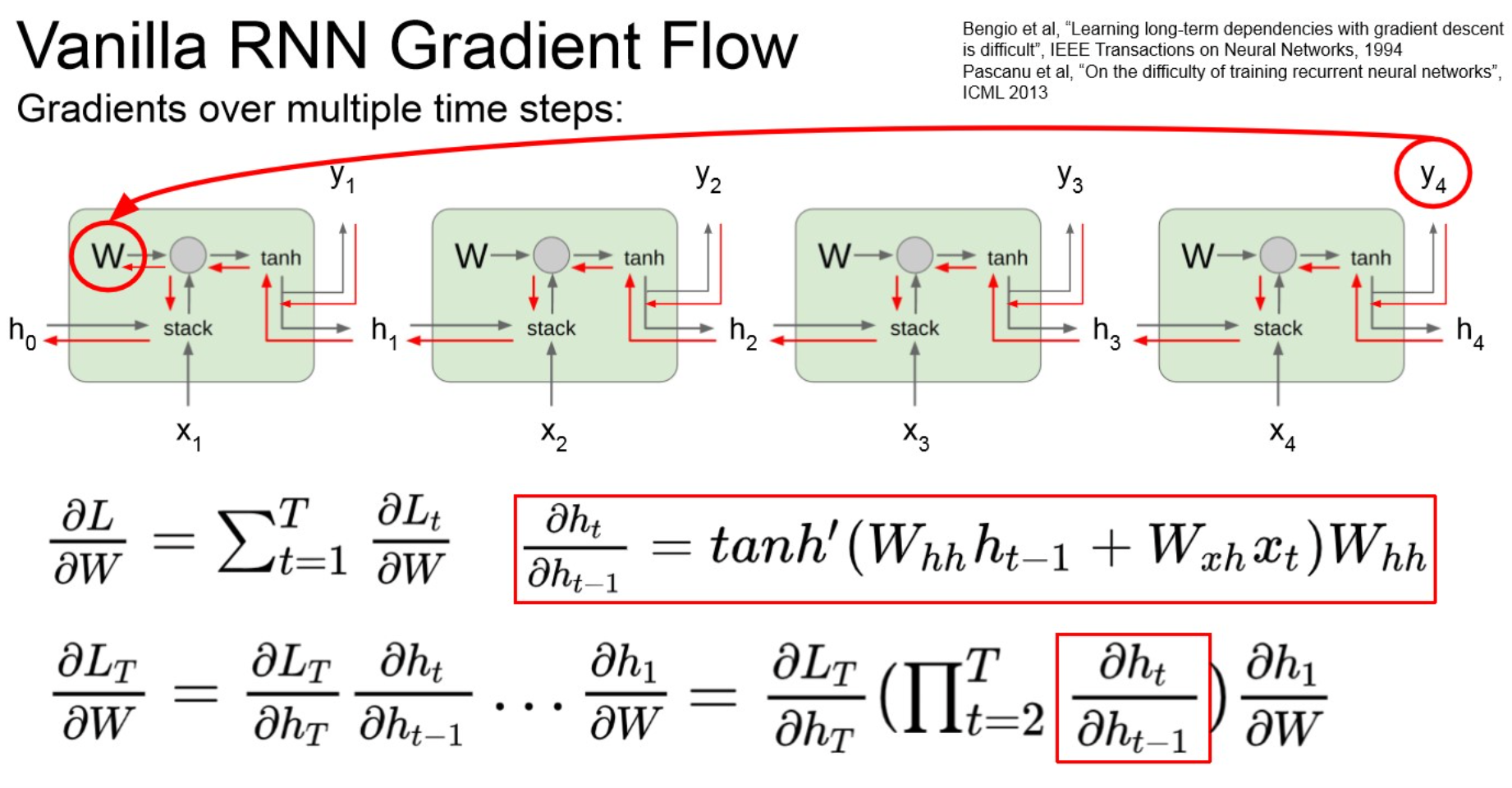
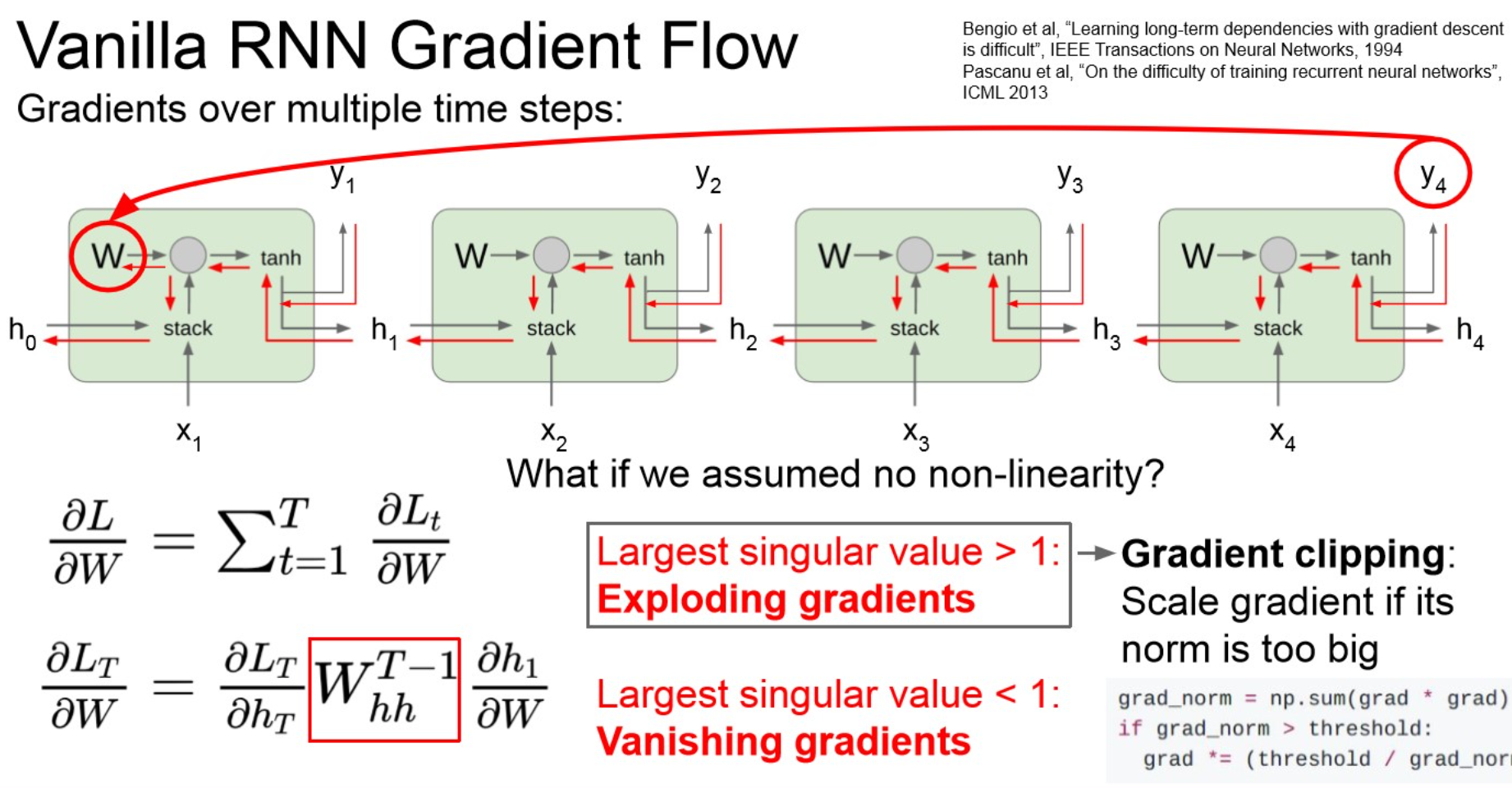
Comparing gradient flow to Vanilla RNN
Vanilla RNN gradient flow
Summary
Warning
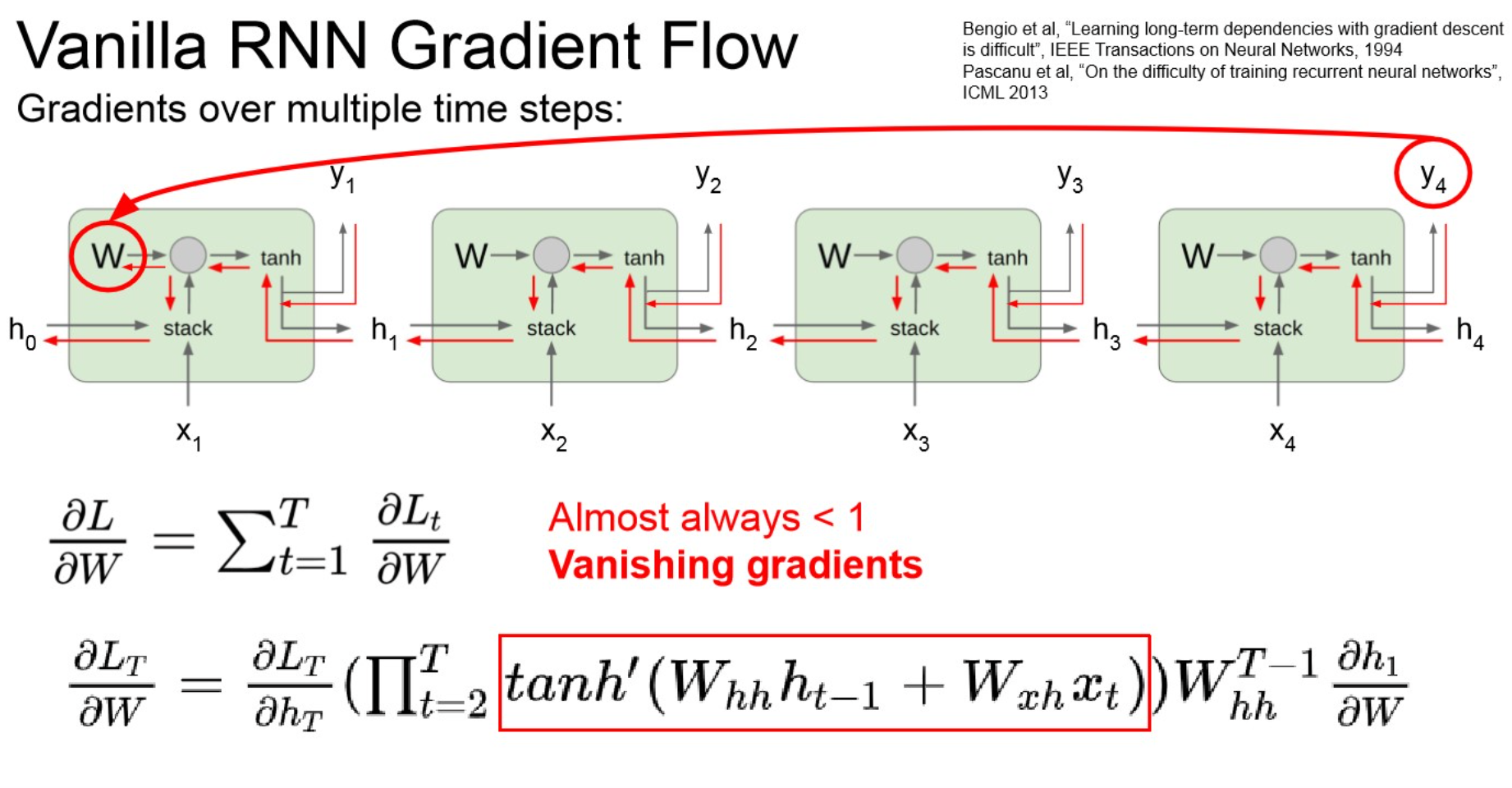
- vanishing gradient.
- layer가 deep해지니까, 1보다 작은 값들이 계속 곱해져서 0으로 수렴.
- learning되지 않음.
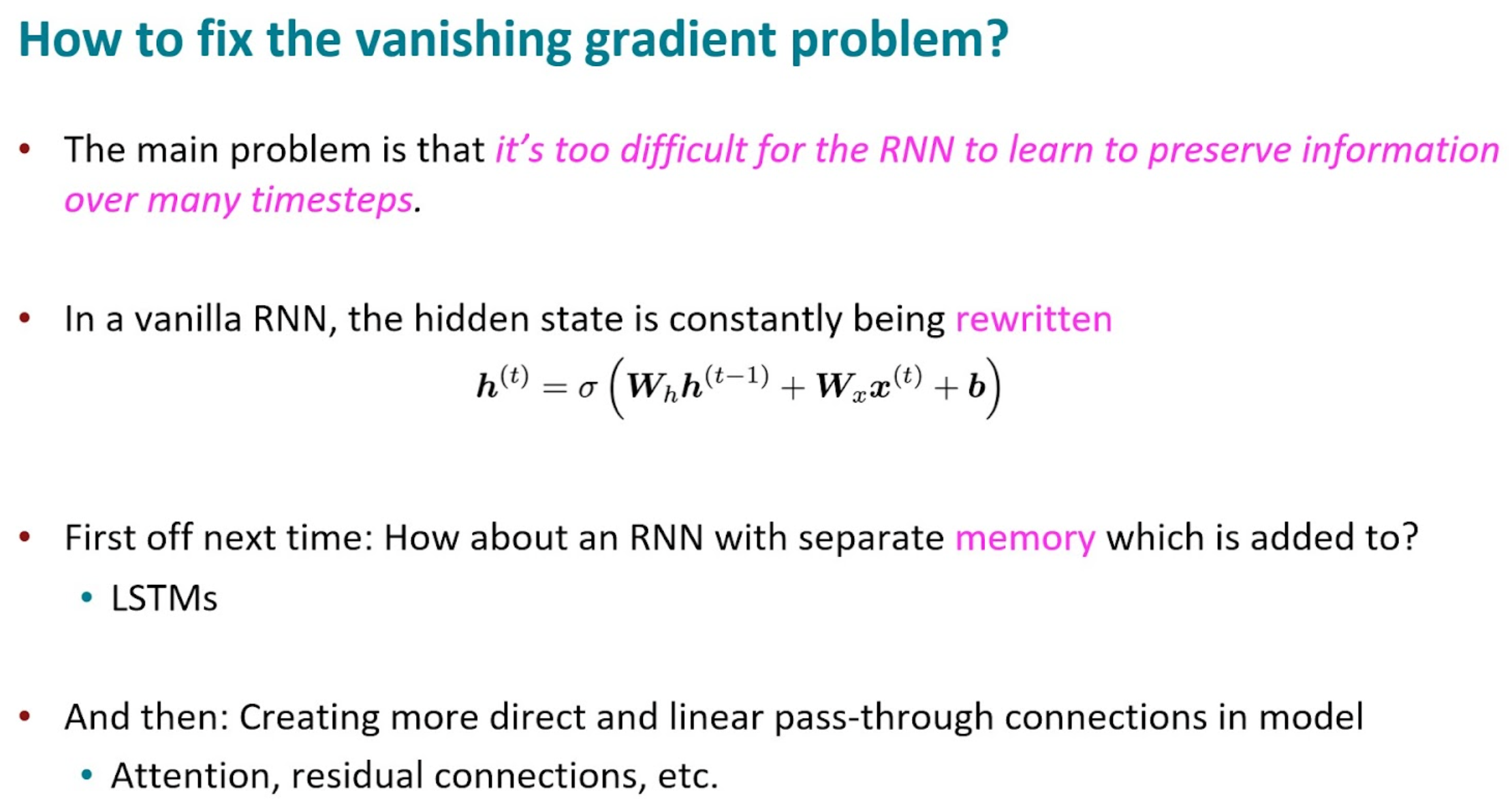
- RNN architecture 수정이 필요 → LSTM
Warning
만약 각 node에서 계산한 local gradient가 1보다 크다면,
- 이때는 gradient clipping이 권장됨.
Vanishing gradient
Summary
- long dependency를 유지할 수 없다. : 초기 input은 잊혀진다.
Exploding gradient
Summary
기본적으로 gradient가 너무 크면, 업데이트가 잘 되기 어려움.
LSTM
원본 링크Long Short Term Memory(LSTM)
Comparison to Vanilla RNN
Summary
Gates
원본 링크Summary


/../../../AI/Concepts/Architectures/RNN/assets/LSTM-structs.png)
/../../../AI/Concepts/Architectures/RNN/assets/LSTM-g-gate.png)
/../../../AI/Concepts/Architectures/RNN/assets/LSTM-i-gate.png)
/../../../AI/Concepts/Architectures/RNN/assets/LSTM-f-gate.png)
/../../../AI/Concepts/Architectures/RNN/assets/LSTM-o-gate.png)