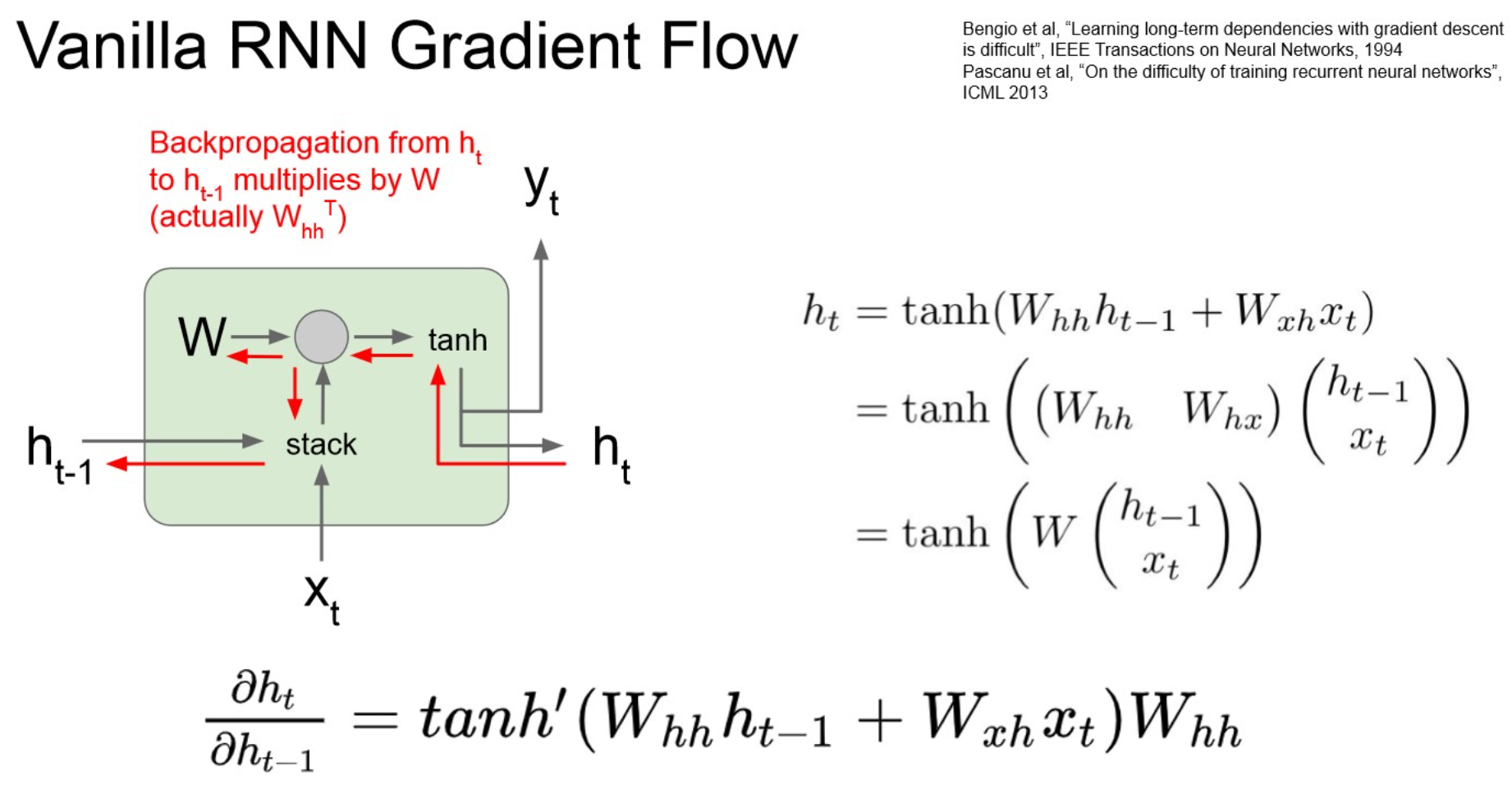
Comparing gradient flow to Vanilla RNN
Vanilla RNN gradient flow
Summary
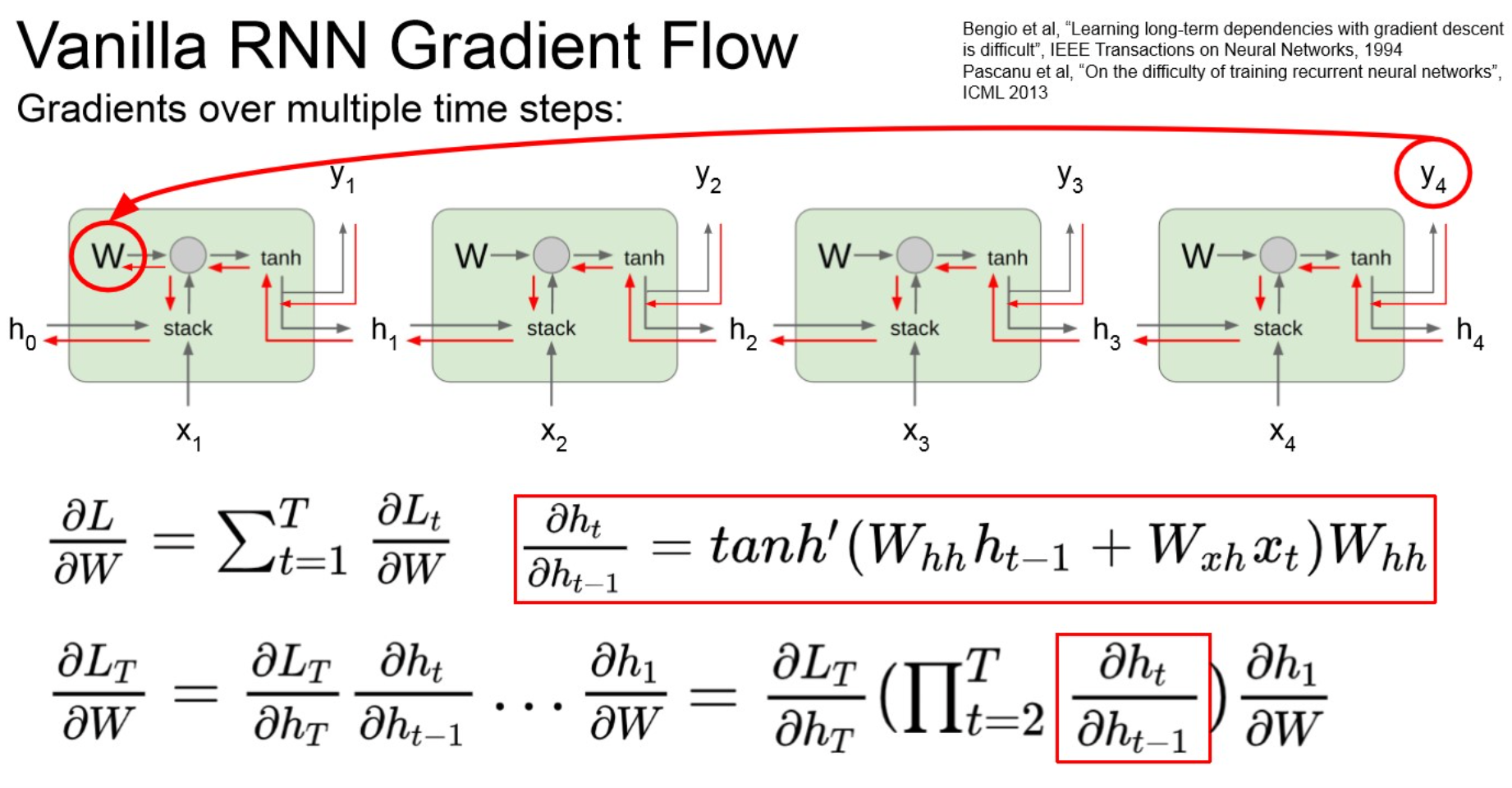
Warning
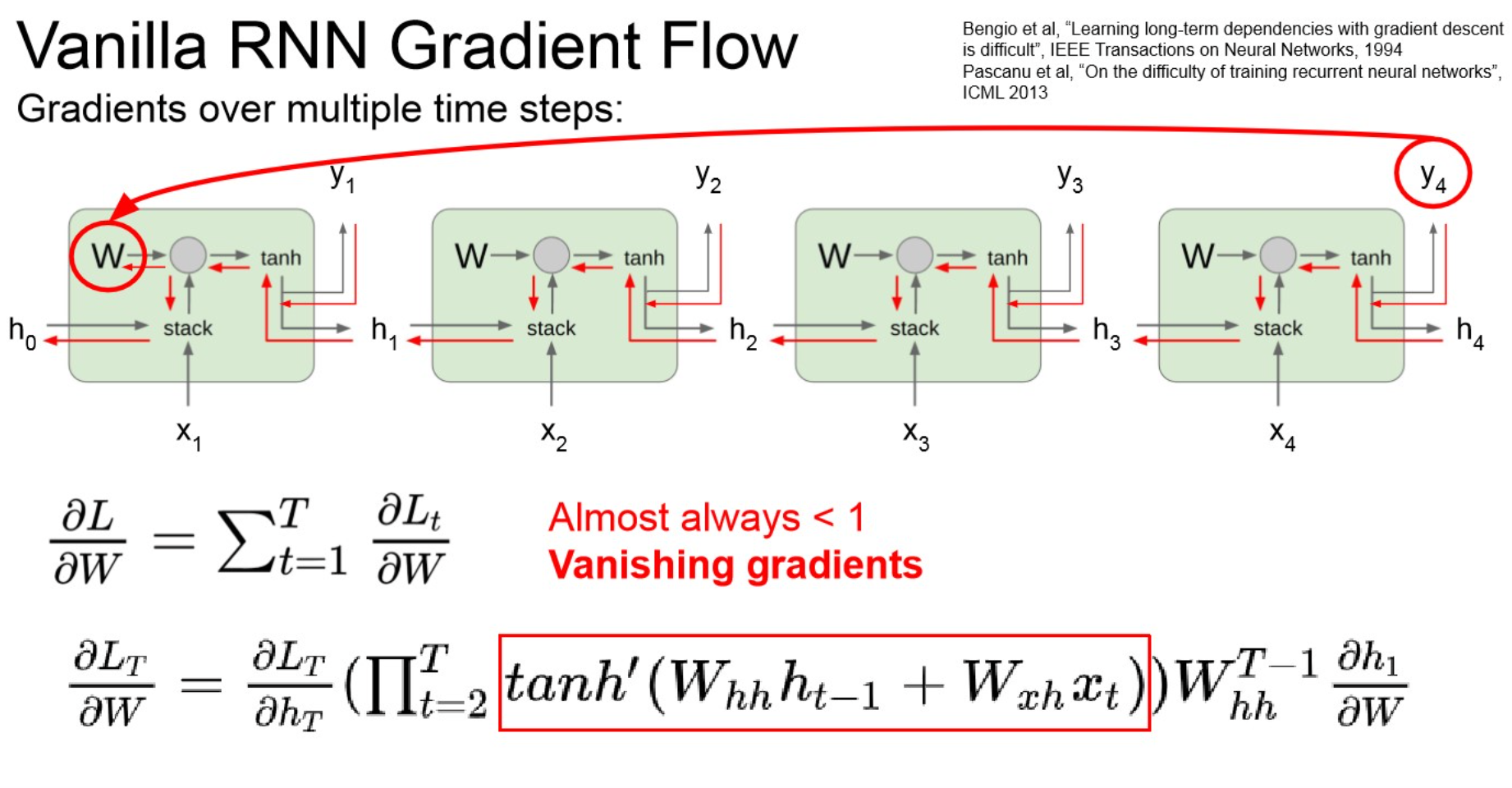
- vanishing gradient.
- layer가 deep해지니까, 1보다 작은 값들이 계속 곱해져서 0으로 수렴.
- learning되지 않음.
- RNN architecture 수정이 필요 → LSTM
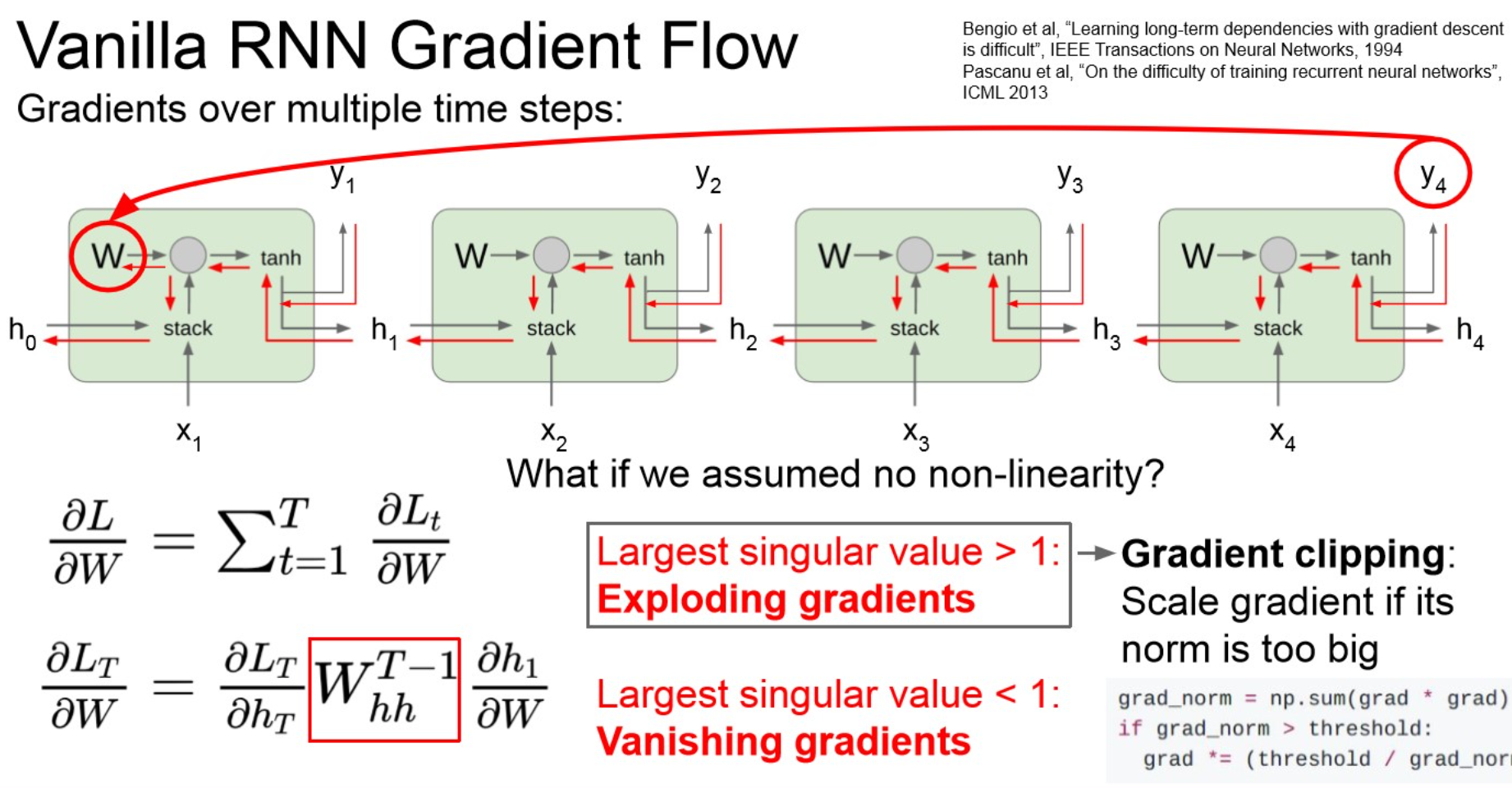
Warning
만약 각 node에서 계산한 local gradient가 1보다 크다면,
- 이때는 gradient clipping이 권장됨.
Vanishing gradient
Summary
- long dependency를 유지할 수 없다. : 초기 input은 잊혀진다.

Exploding gradient
Summary
기본적으로 gradient가 너무 크면, 업데이트가 잘 되기 어려움.

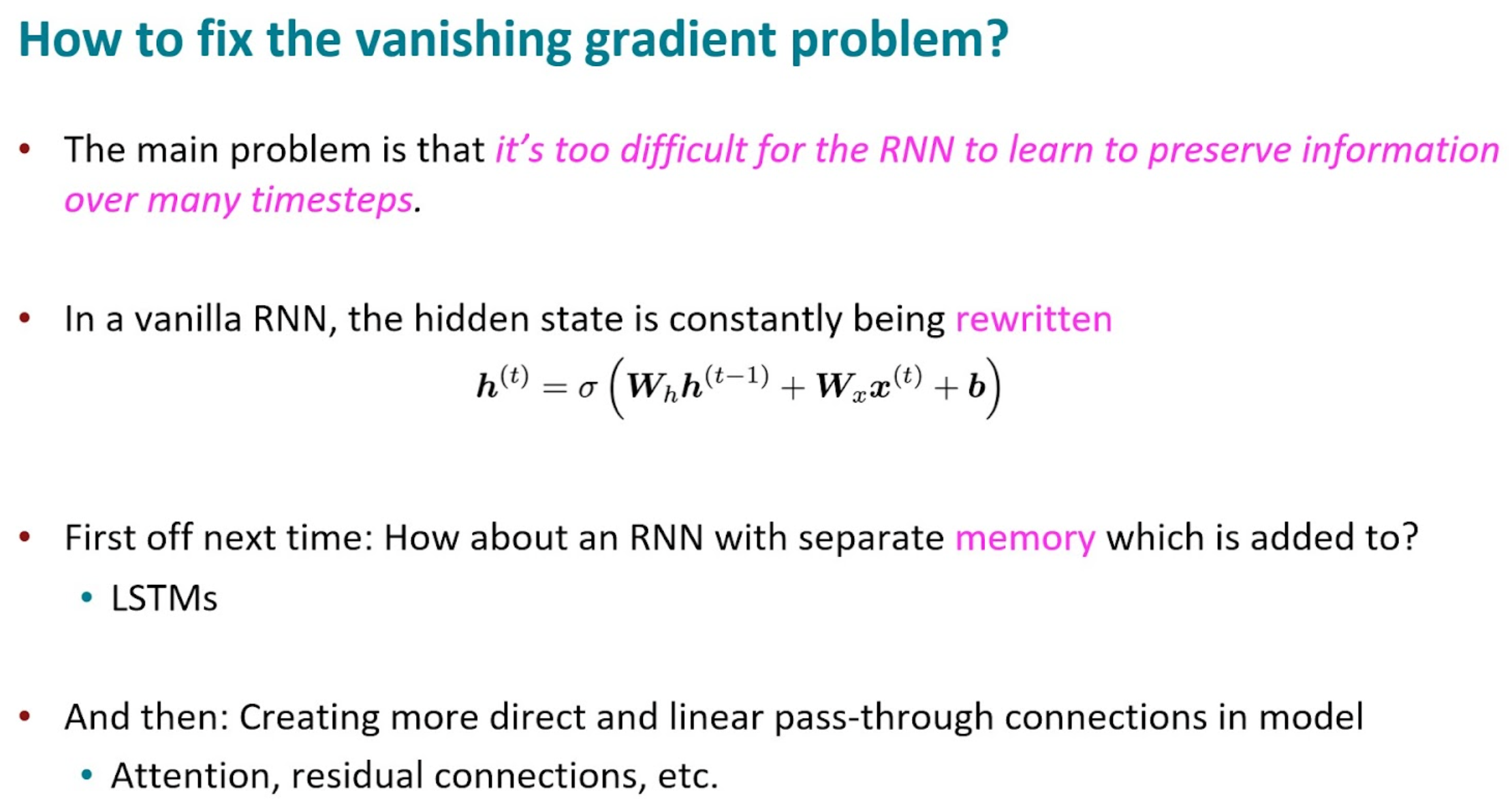
LSTM
Long Short Term Memory(LSTM)
Comparison to Vanilla RNN
Summary
Gates
원본 링크Summary
/../../../../../AI/Concepts/Architectures/RNN/assets/LSTM-structs.png)
/../../../../../AI/Concepts/Architectures/RNN/assets/LSTM-g-gate.png)
/../../../../../AI/Concepts/Architectures/RNN/assets/LSTM-i-gate.png)
/../../../../../AI/Concepts/Architectures/RNN/assets/LSTM-f-gate.png)
/../../../../../AI/Concepts/Architectures/RNN/assets/LSTM-o-gate.png)