Classification
컴퓨터 비전 분야에서 중요한 task 중 하나로, 이미지 데이터의 label을 예측하는 task.
Challenge - Semantic Gap
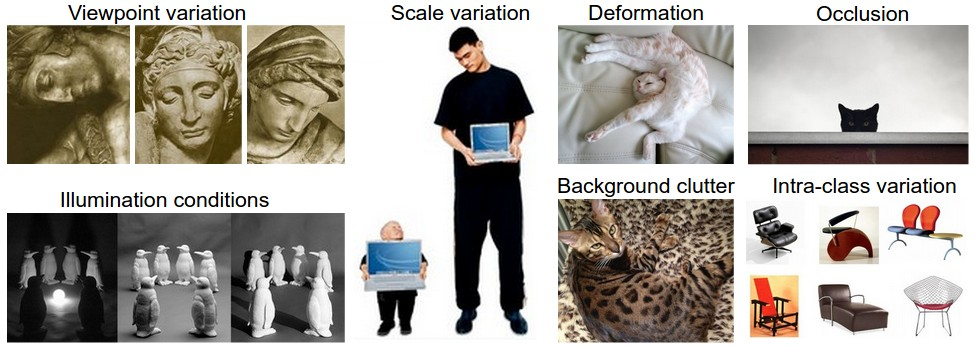
Semantic Gap
실제 모델이 읽는 값들은 (0, 255) x 3 channel (RGB)범위의 수치들이니, 사람이 이미지 정보 처리 하는 것과는 사뭇 다르다.
- Viewpoint variation : 관측점, 사진이 찍힌 각도에 따라 동일한 대상도 다르게 보인다.
- Illumination: 광량에 따라 대상의 색상 정보 파악이 확연히 다르다.
- Background Clutter: 배경 정보가 경계 구분에 어려움을 줄 수 있다.
- Occlusion : 중요한 정보가 누락될 수 있다.
- Deformation: 같은 객체더라도, 여러 모습이 존재한다.
- Intraclass variation: 같은 클래스 내에도 여러 변산이 존재한다.
- Context: 맥락이 인식에 영향을 준다.
Approach
Traditional Approach
- 예전에는 feature들을 hard coding하기도 했다고 한다.
- ex) Harris Corner Detection ← 이런 걸 보면 심리학의 “지온” 가설 같은 접근 같기도,,

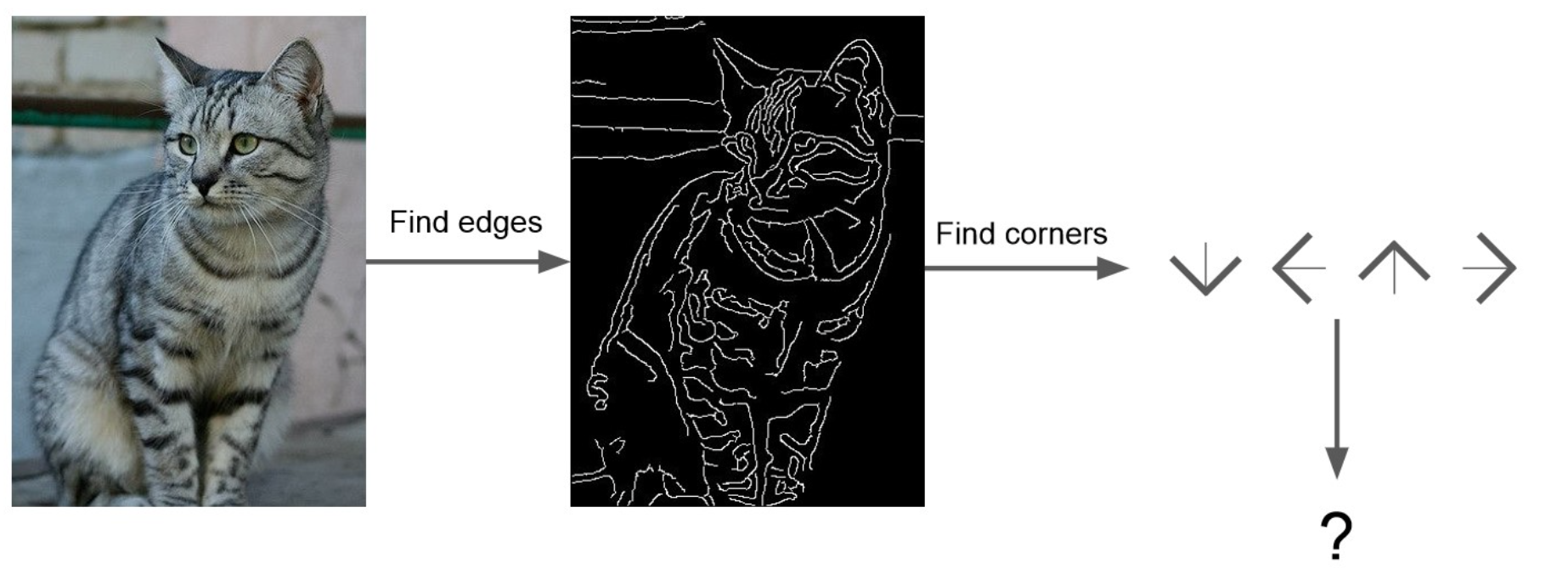
- 인접 pixel 간 값 차이가 큰 부분을 detect. → corner ~ boundary
Modern Approach
- Data-driven (End-to-End Learning) : DL, ML
- data 자체로 pattern 인식.
- Collect a dataset of images and labels ← big cost,,
- CIFAR10, COCO,
- Use ML algorithms to train a classifier
- Evaluate the classifier on unseen data