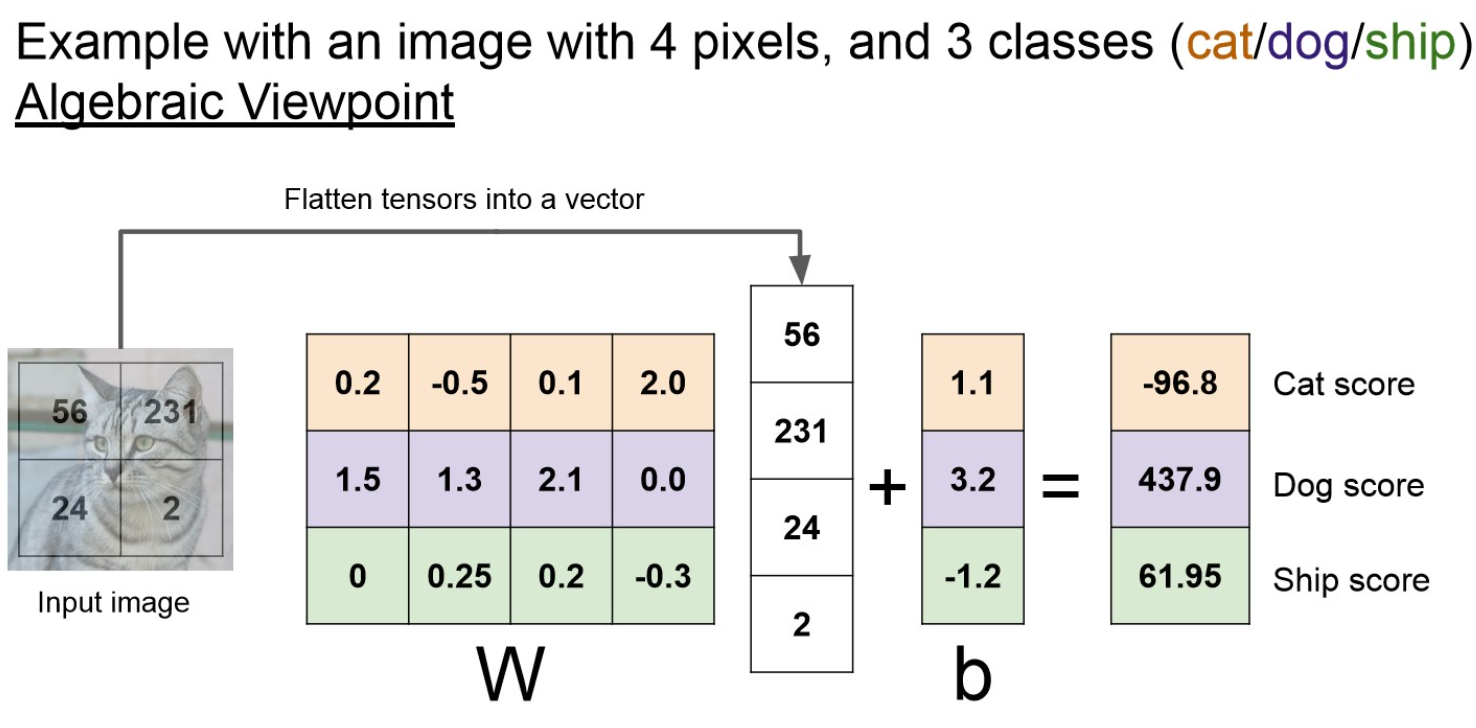
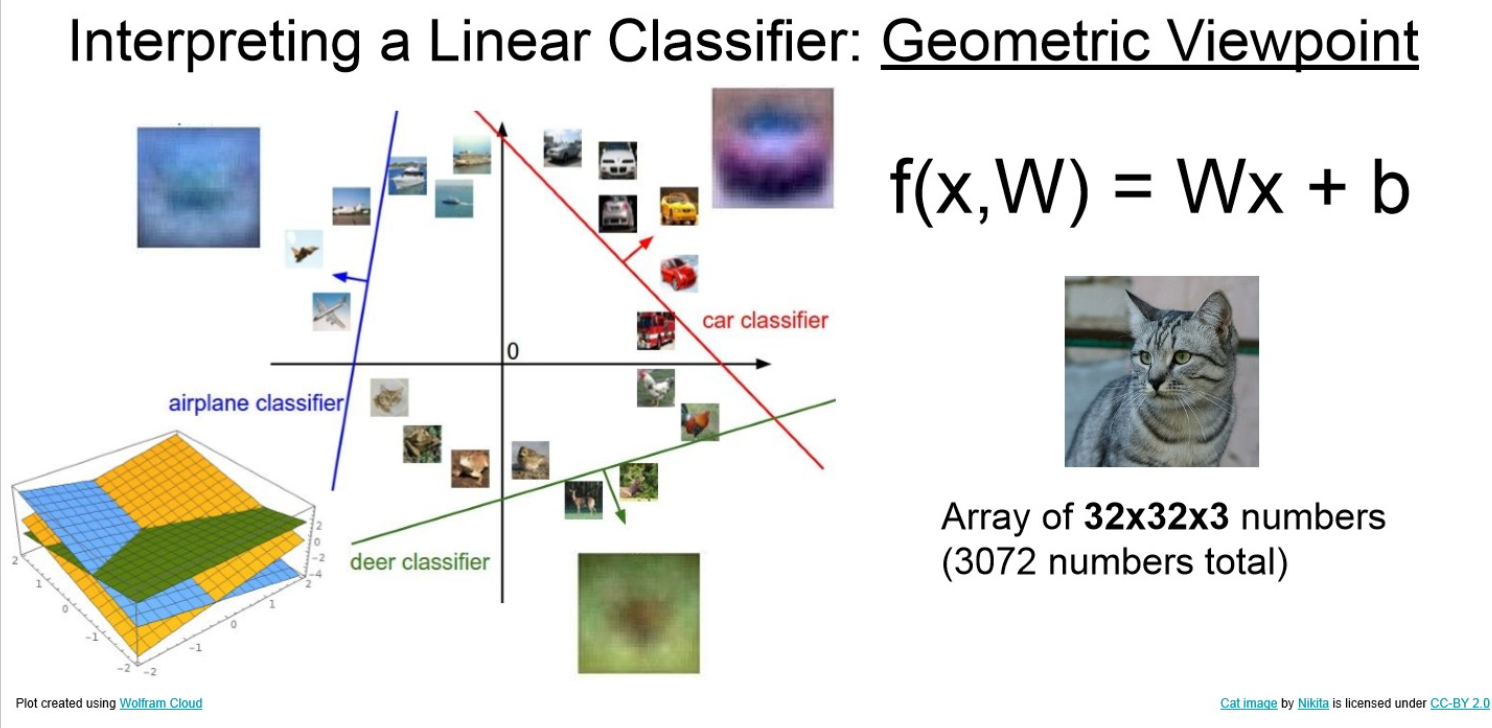
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
Learning 이라는 것은 “Loss”를 “Optimization” 하는 것.
model의 output이랑 target(label)이 최대한 비슷할 때 이 값이 작아지는 방향으로 보통 define함.
확률 분포 간 차이로 볼 수도 있다.
classification task에서는 마지막 layer가 분류할 target class 개수랑 dim이 같은데, 이를 softmax하면 확률 분포가 model의 최종 output이라고 볼 수 잇다.
따라서 learning은 output probability distribution과 target probability distribution을 최대한 비슷하게 해주는 방향으로 진행되어야 한다.
확률 분포 차이를 나타내는 지표로 KL-divergence라는 지표를 쓸 수 있고, metric 조건을 정확히 만족하진 못하지만, 대략 distance 개념 정도로 이해할 수 있다.
d > 0, d(x, x)=0 → x=0, triangular-ineq
How to design a good loss function?
Abstract
A loss function can be any differentiable function that we wish to optimize
Deriving the cost function from the Maximum Likelihood Estimation (MLE) principle removes the burden of manually designing the cost function for each model.
Consider the output of the neural network as parameters of a distribution over yi
w^ML=wargmaxpmodel(y∣X,w) =i.i.dwargmax∏pmodel(yi∣Xi,w) =wargmax∑logpmodel(yi∣Xi,w) (: log-likelihoood 로 변환)
Regression Loss
Regression - estimation target
regression이란, 결국 fw:RN→R
즉, output은 real-value 한 개.
logistic regression의 경우, linear regression의 output을 확률값 범위로 고정해주는 activation function(tanh)을 적용한 걸로 볼 수도 있는데, classification task에 수행할 수 있다는 점을 잘 기억하자!
→ ouput 값이 확률 값의 범위에 무조건 떨어지니까.
수식으로는 아래와 같이 model 을 define하고, h(x)=σ(w⊤x+b)
model의 output을 posterior 해석.
h(\mathrm{x}) & \text{if}\; y = 1 \\
1 - h(\mathrm{x}) & \text{if}\; y = 0
\end{cases}$$
이걸 좀 compact 하게 한 줄로 써보면,
$$P(y|\mathrm{x}) = a^y(1-a)^{(1-y)}$$
위의 식에서 여러 개의 데이터가 i.i.d. 가정을 통해 뽑혔다고 한다면, P(y[1],⋯,y[n]∣x[1],⋯,x[n])=∏P(y[i]∣x[i])
여기서, MLE L(w)=P(y∣x;w) =∏P(y[i]∣x[i];w) ∏(σ(z[i]))y[i](1−σ(z[i]))(1−y[i])
where z[i]=w⊤x+b
실제 compute 할 때에는 log 씌우는 게 값이 stable하여 log를 씌운 이후 계산한다고 하는데 정확히 어떠한 말일까..?
l(w)=logL(w) =∑[y[i]log(σ(z[i]))+(1−y[i])log(1−σ(z[i]))]
또한, 값을 maximizing 하는 것 보다는 minimizing 하는게 편하기 때문에(??) negative log-likelihood를 minimizing 한다. L(w)=−l(w) =−∑[y[i]log(σ(z[i]))+(1−y[i])log(1−σ(z[i]))]
Expand to Multiple Classes
Categorical distribution을 다음과 같이 정의 p(y=c)=μc
따라서 probability distribution은 p(y)=∏μcyc
로 표현될 수 있고, y: One-hot vector로 yc∈{0,1}
CE(Cross-Entropy) Loss?
Let Pmodel(y∣x,w)=∏fw(c)(x)yc
then we obtain, w^ML=wargmax∑logpmodel(yi∣xi,w)
=wargmax∑log∏fw(c)(x)yc
=wargmin∑i=1N∑c=1C−yi,clogfw(c)(xi)
In other words, we minimize the cross-entropy loss(CE loss).
The target y=(0,0,⋯,0,⋯,0)⊤ is a One-hot vector with yc its c’th element.
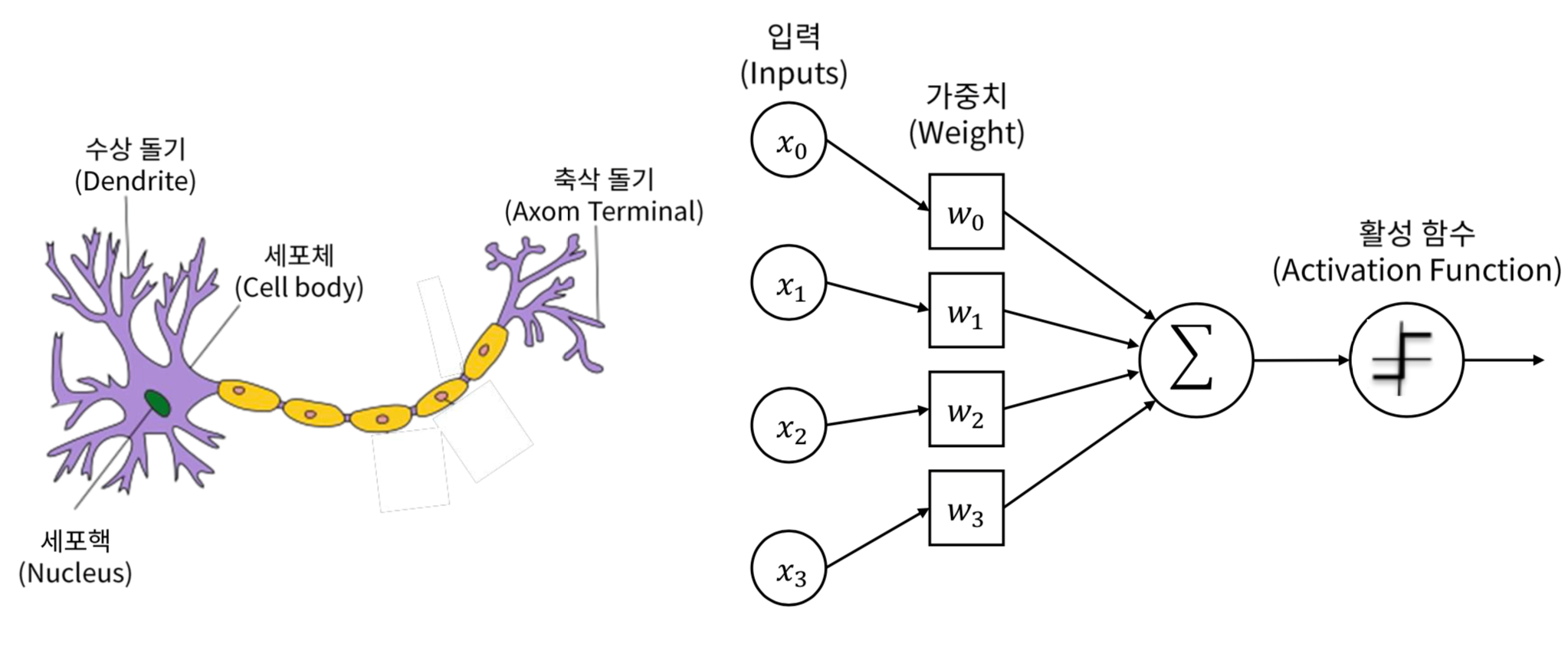
이름 그대로 위의 perceptron을 multi-layer 쌓아서 적층한 구조. 각 layer에서 다음 layer로 넘어가는 과정에서 non-linear function을 통과하니, 이때 점차 model에 non-linearity가 생김. 따라서 이러한 구조가 3층이상으로 깊게 쌓이면 Deep-Neural-Network이라 함.
SIMD(Single Instruction Multiple Data)
—
여러 개의 data를 vector 형식으로 묶어서 처리하자!
**
파이썬으로 구현해보기!
Perceptron
class Perceptron(): def __init__(self, num_features): self.num_features = num_features self.weights = np.zeros((num_features, 1), dtype=float) self.bias = np.zeros(1, dtype=float) def forward(self, x): # $\hat{y} = xw + b$ linear = np.dot(x, self.weights) + self.bias # comp. net input # train에서 보면, y[i] 차원으로 데이터가 들어오니, vec * vec 연산. # linear = x @ self.weights + self.bias predictions = np.where(linear > 0., 1, 0) # step function - threshold return predictions # 'ppp' exercise def backward(self, x, y): # pred랑 ground_truth 값 비교. return y - self.forward(x) # 중간 중간 reshape이 과연 필요할까? def train(self, x, y, epochs): for e in range(epochs): for i in range(y.shape[0]): errors = self.backward(x[i].reshape(1, self.num_features), y[i]).reshape(-1) self.weights += (errors * x[i]).reshape(self.num_features, 1) self.bias += errors def evaluate(self, x, y): predictions = self.forward(x).reshape(-1) accuracy = np.sum(predictions == y) / y.shape[0] return accuracy
Perceptron을 여러 층 쌓은 것.
중간 중간 non-linear function을 사용하여 perceptron을 엮어 더 complex한 function을 approximation 할 수 있음.
Terminology
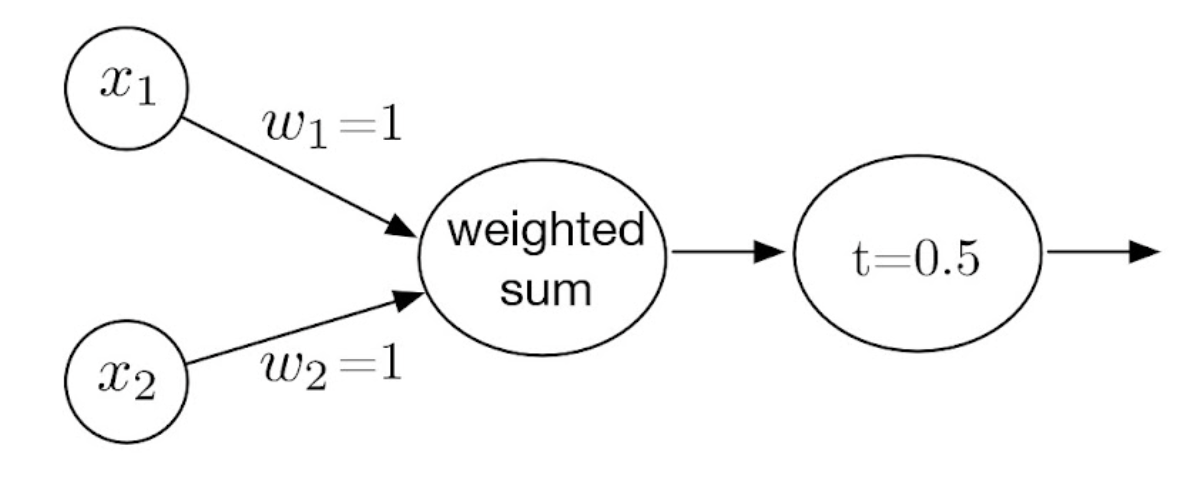
Net input(z) = weighted inputs, activation function에 들어갈 값
Activations(a) = activation function(Net input); a=σ(z)
Label output(y^) = threshold()activations of the last layer; y^=f(a)
Special Cases
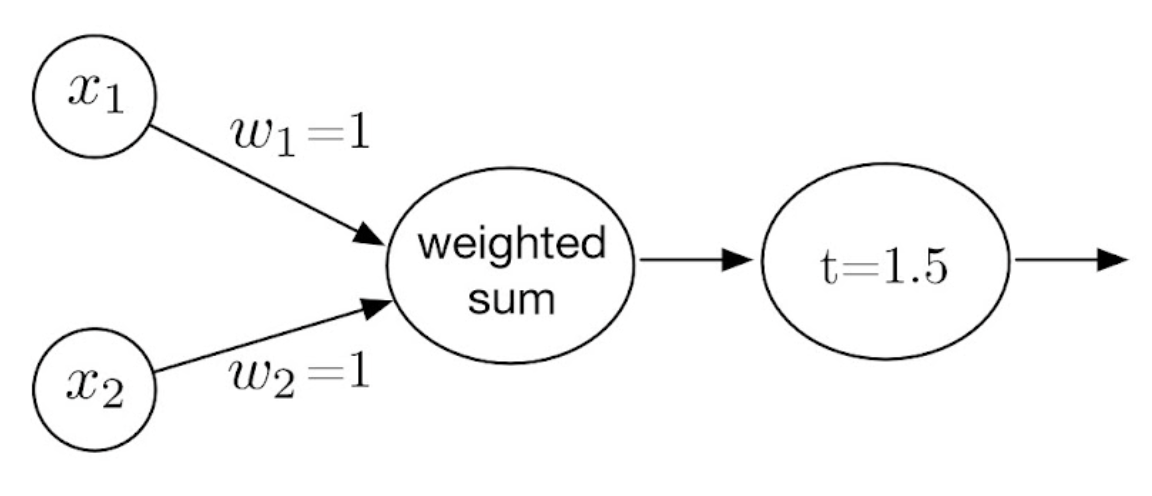
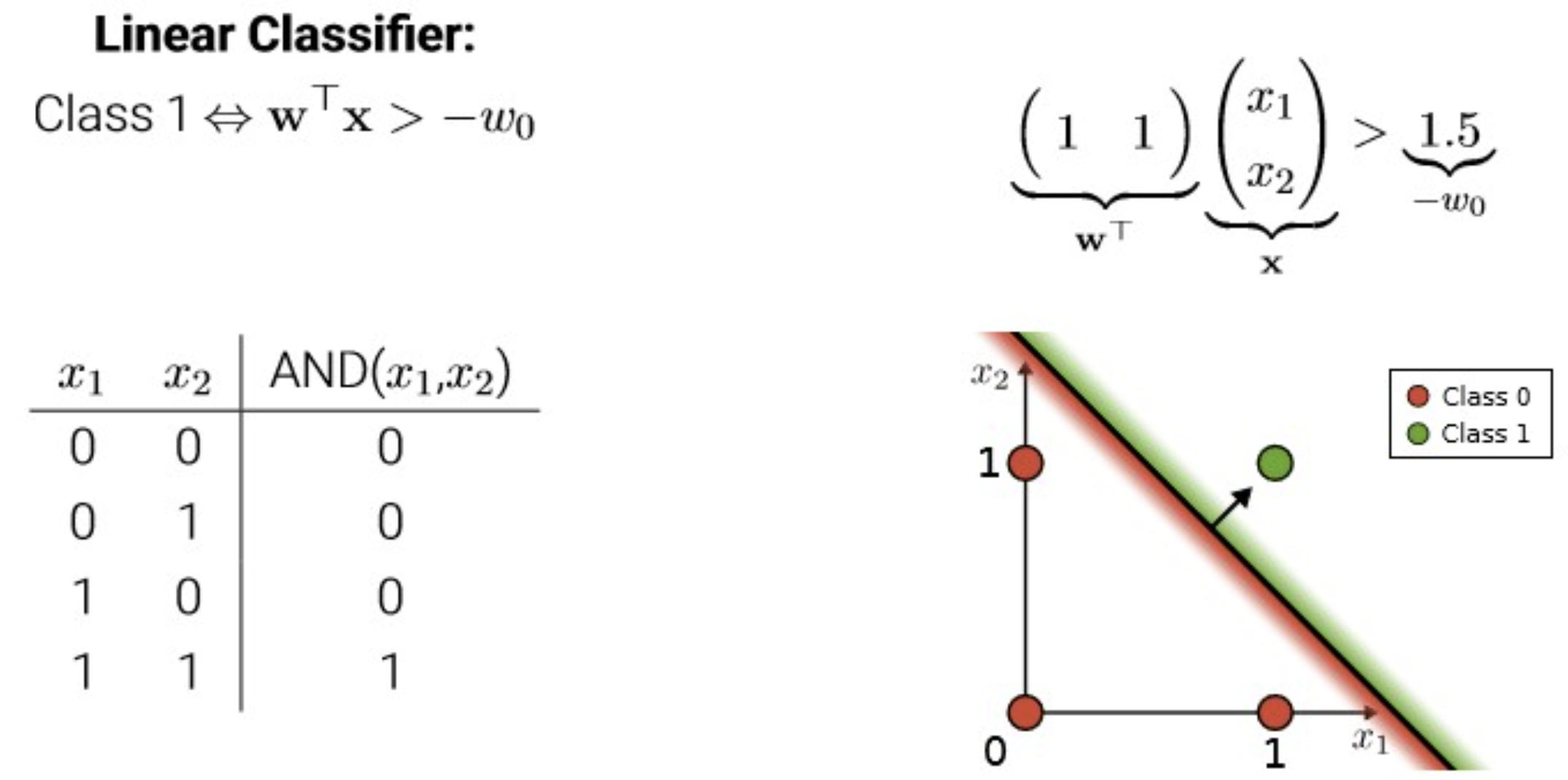
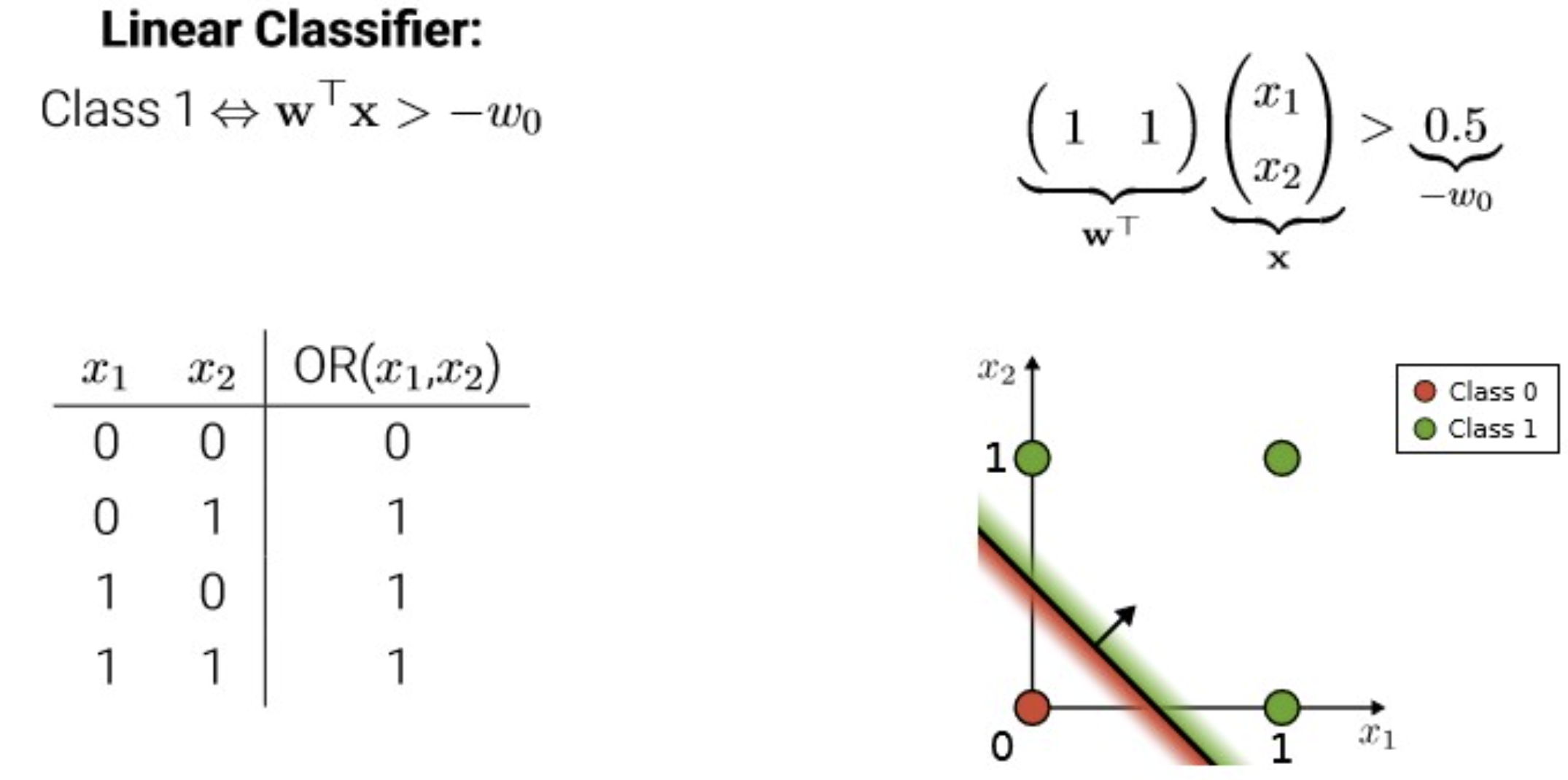
In perceptron: activation function = threshold function(step function)
위의 그림에서는 threshold가 0으로 잡혀있음.
In linear regression: activation(a) = net input(z) = output(y^)
threshold → bias 항으로 몰기
0 & \text{if}\; z \leq \theta \\
1 & \text{if}\; z > \theta
\end{cases}
이를 정리해보면,
0 & \text{if}\; z - \theta \leq 0 \\
1 & \text{if}\; z - \theta > 0
\end{cases}
여기서 −θ 를 bias 취급하자.
이를 다시 말하면,
기존 σ(∑i=1mxiwi+b)=σ(xTw+b)=y^
input data에서 x[0]=1, w0=−θ 취급하면 notation이 아래와 같이 간단해진다. σ(∑i=0mxiwi)=σ(xTw)=y^
MLP - 1 layer
zi=W0,i(1)+∑j=1mxjWj,i(1) y^i=g(W0,i(2)+∑j=1d1zjWj,i(2))
where W0,i(1), W0,i(2) are bias
앞에 언급한 대로, W0,2(1) 는 bias이므로 input data의 dim을 1 늘리고(x[0]=1) 로 처리.
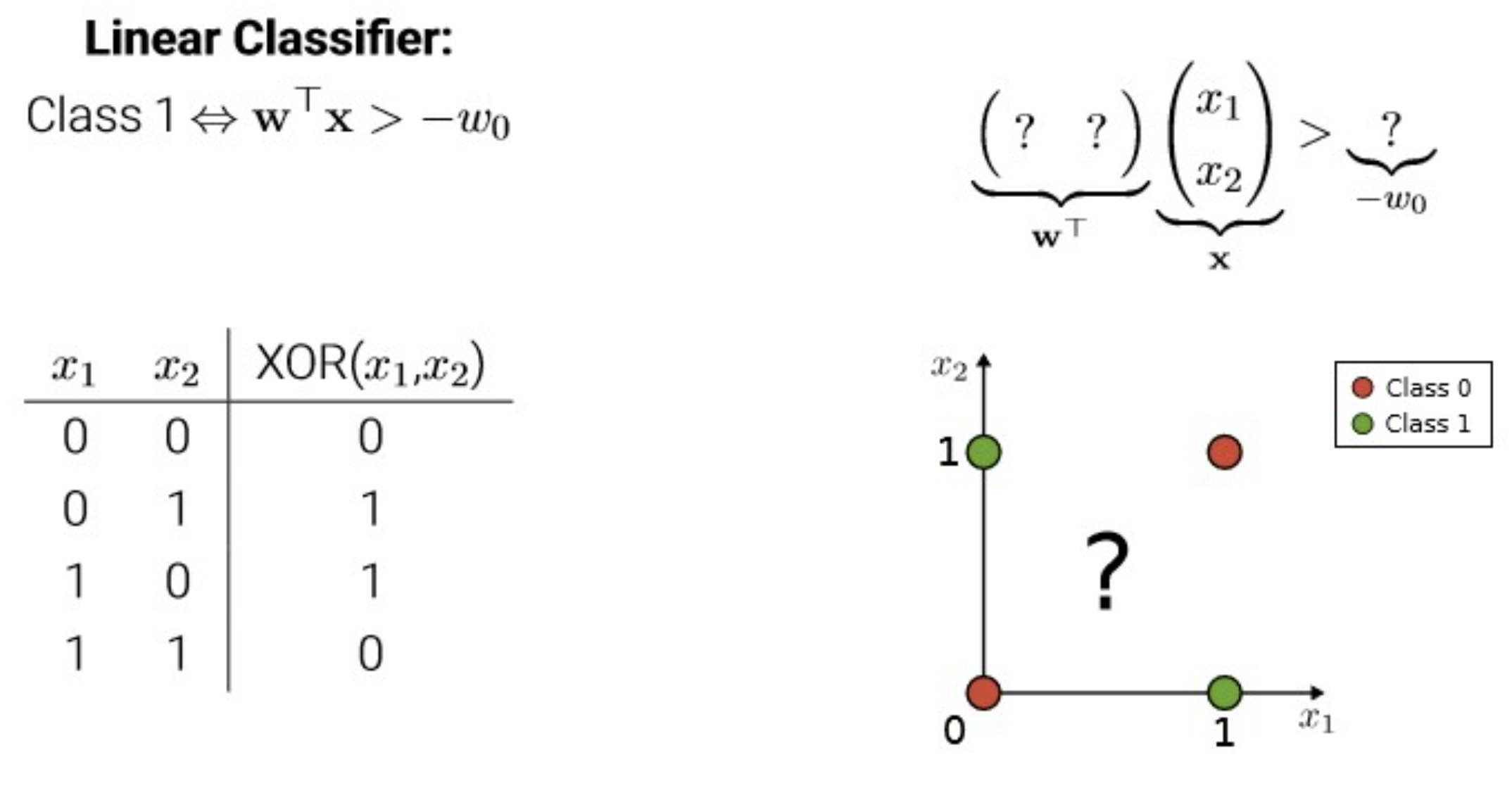
Why do we stack more layers?
기본적으로 보이는 바와 같이 NN이 깊어질수록 activation을 많이 통과하고 그만큼 non-linearity를 더 부여할 수 있으니 더 complex한 function들을 근사할 수 있지.
또한, 데이터를 linearly separable 하게 바꿀 수도 있지.(e.g. kernel trick 처럼)
data를 Linearly-separable 한 space에 embedding 가능.
MLP - 2 layer
Learning MLP
이전에는 manual 하게 파라미터 값들을 define 해주었는데, 이조차도 모델이 스스로 조정하게 하는 걸 학습”Learning” 이라고 함.
parameter가 많아지면, manual 하게 지정해주는게 intractable
automatic하게 data로부터 학습하게 할 수 있다는 장점
→ 이러한 접근을 “data-driven approach” or “end-to-end learning” 이라고 함.
Learning Algorithm pseudo-code
Let D=(⟨x[1],y[1]⟩,⟨x[2],y[2]⟩,⋯⟨x[n],y[n]⟩)∈(Rm×{0,1})n


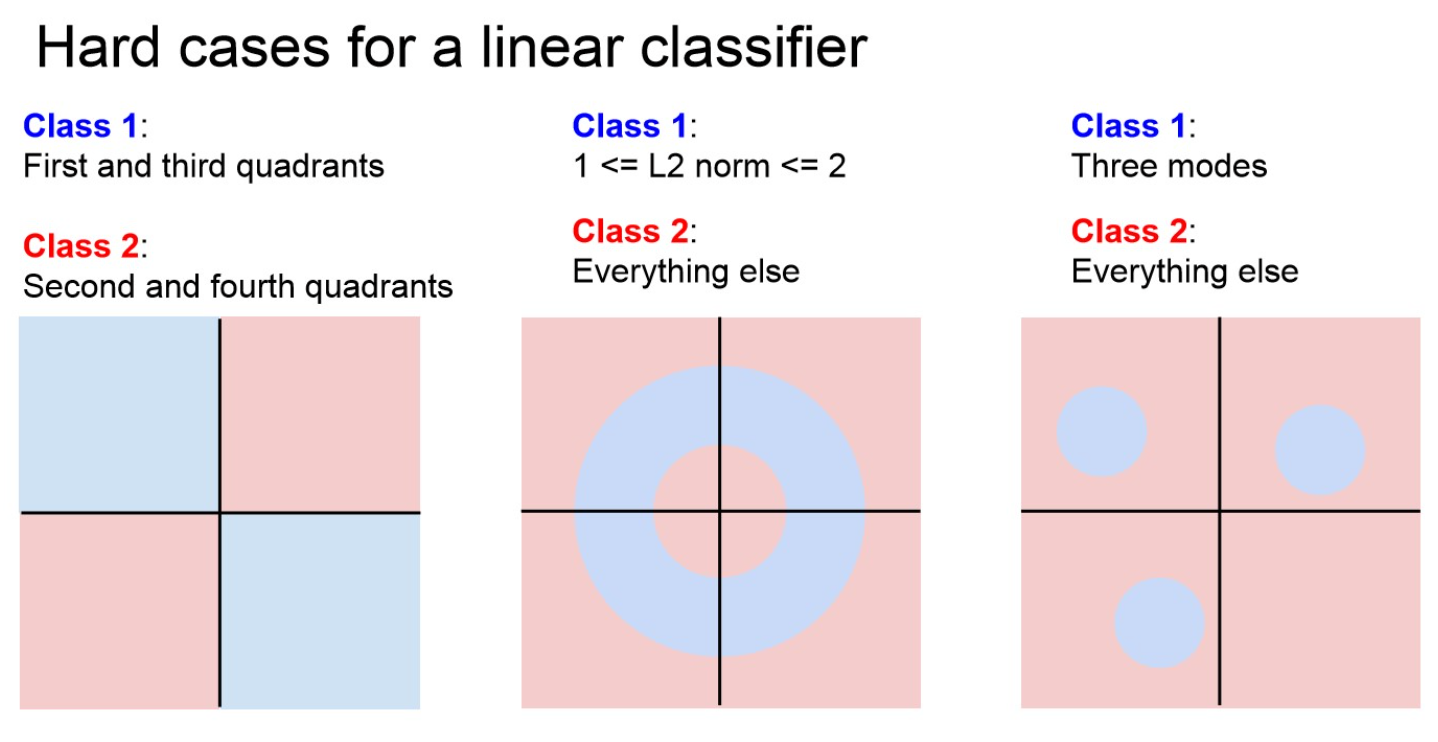







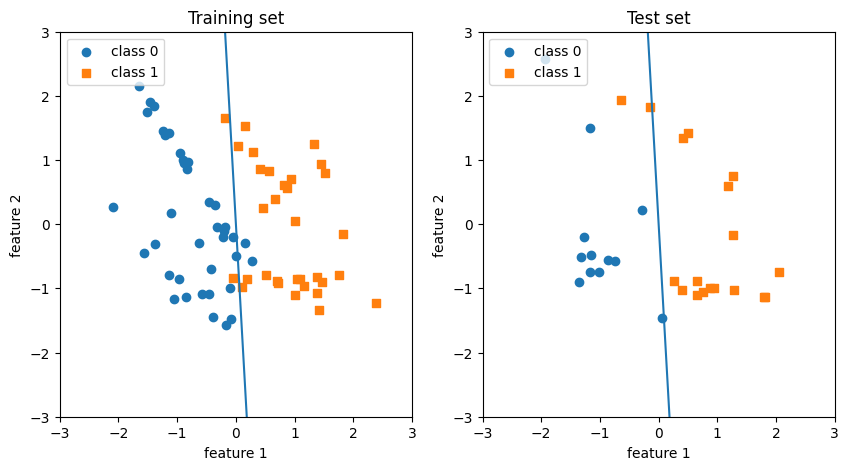
A set is convex if any line segment connecting 2 points in lies entirely within .
/../../../AI/Concepts/assets/MLP-perceptron-terminology.png)
/../../../AI/Concepts/assets/MLP-1layer.png)
/../../../AI/Concepts/assets/MLP-1layer-ex2.png)
/../../../AI/Concepts/assets/linearly-separable-dim-incr.png)
/../../../AI/Concepts/assets/MLP-2layer-ex.png)