classification에서 모델의 output으로 나온 score를 확률로 해석하고 싶은 경우, softmax function을 사용함. 기존 score들을 확률 값으로 변환하기 위해 exp function을 사용함. 즉, 이를 기존 classifier 마지막 layer에 붙이면, 각 클래스에 해당하는 개별 확률 값들을 얻을 수 있다.
→ 즉, softmax의 return은 모든 클래스에 해당하는 probability mass function
cross-entropy loss = softmax loss
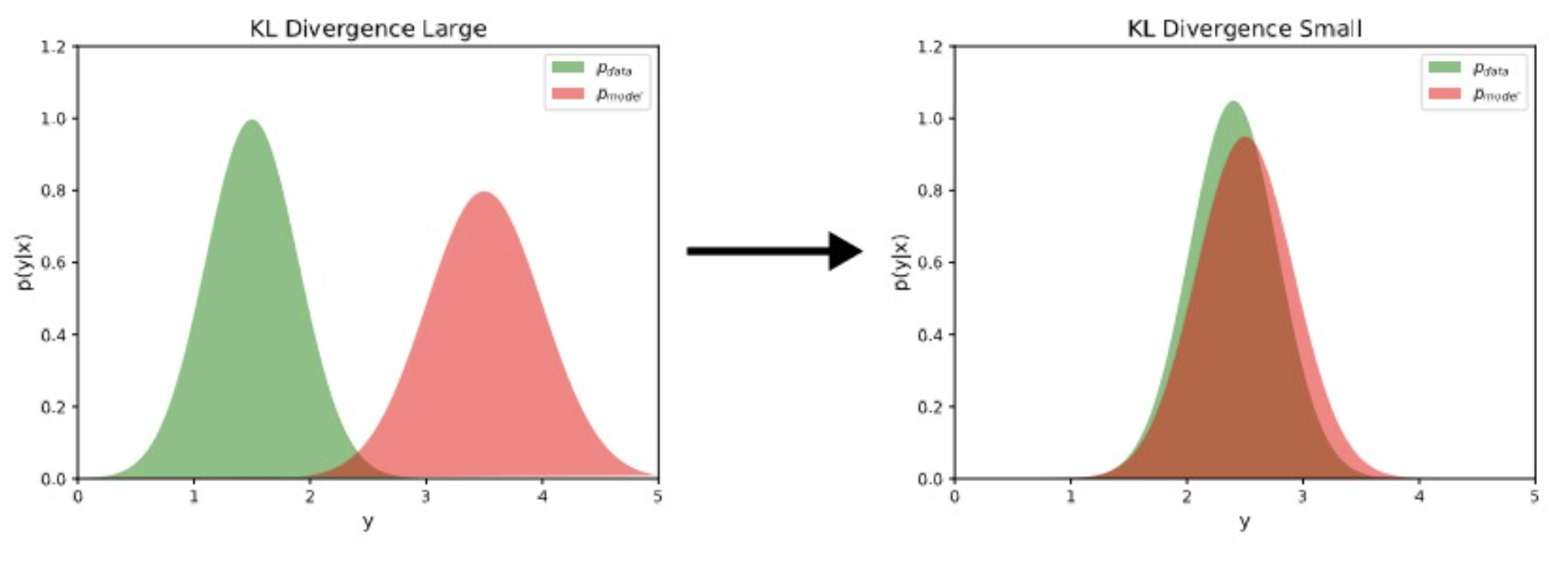
classification task 시 모델 학습은 모델이 예측한 output(p.m.f.) 이 label probability distribution에 가까워지도록 이루어져야 한다. 이는 두 확률 분포 간 유사도를 얘기해주는 KL divergence 관점에서 아래와 같이 visualize 된다. (KL- divergence가 작아진다.)
Detail Process
조금 자세히 보자면, 각 데이터별 모든 클래스에 대한 score를 exp function으로 양수화 시킨다.
Q1. What is the min/max possible value of softmax loss Li?
→ Since Li is formed as the negative log of probability, the range is [0,inf)
Q2. At initialization all sj will be approximately equal; what is the sotmax loss Li, assuming X classes?
→ Since the all classes are estimated as the same probabilities, each class is equally C1 therefore, each Li=logC