Abstract
Input Data를 Normalizing을 하는 것은 only 1st hidden layer에만 영향을 주는 건데, 다른 hidden layer에는? → BatchNorm이 하나의 방법.
Proposed by Ioffe, S., Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.(ICML)
Check
BatchNorm can
- normalize hidden layer inputs
- helps with exploding/vanishing gradient problem
- can increase training stability and convergence rate
- can be understood as additional(normalization) layers (with additional parameters)
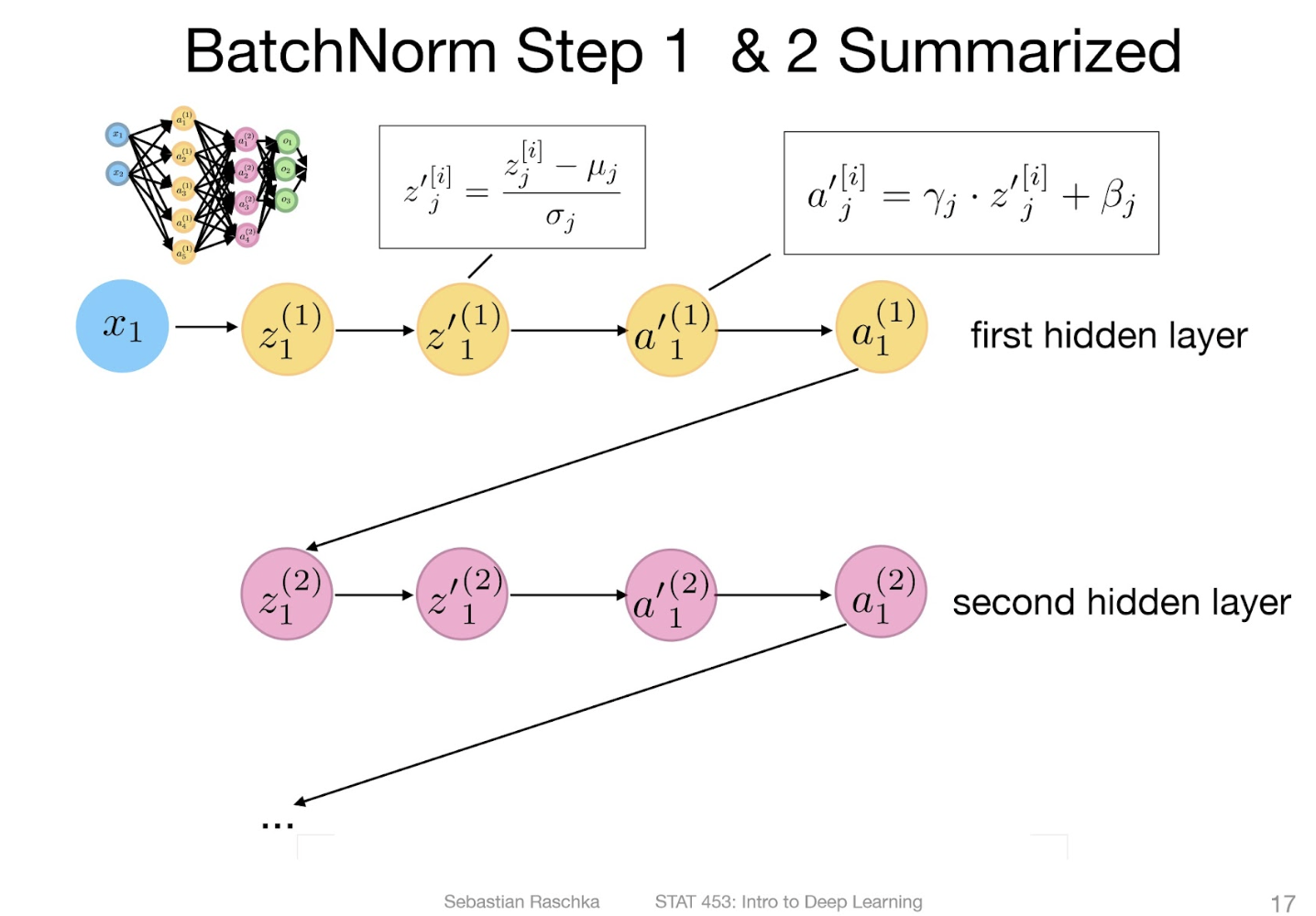
1-step process: normalize Net Inputs
- 마지막 normalization 식은 실제 implement 시 numerical stability를 보장하기 위해 미소 값을 더해서 사용한다. (ex: )
실제 implement 시,
2-step process: pre-activation scaling
실제 implement 시,
가 학습의 목표
- : spread, scale
- : mean
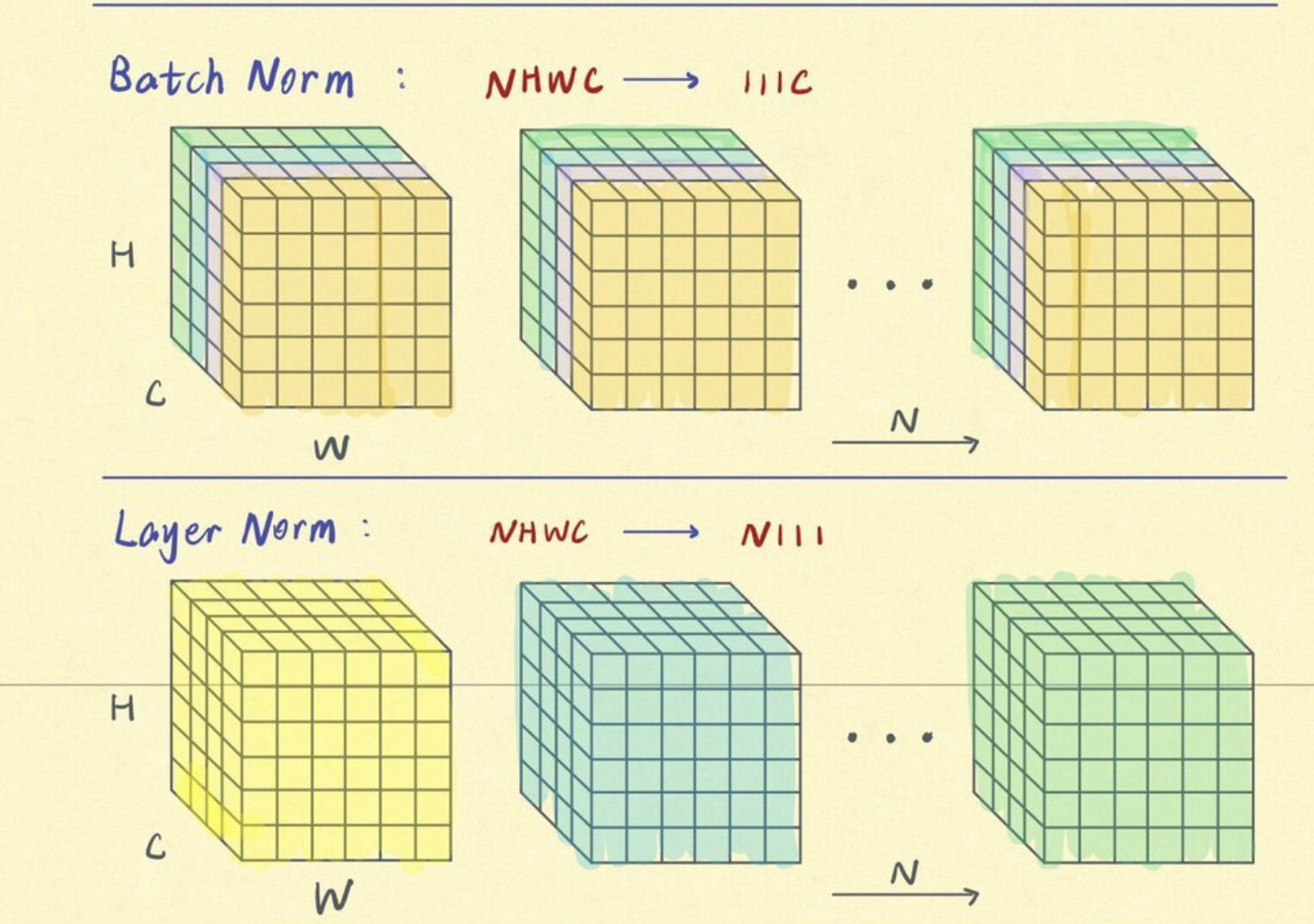
구조적으로 BatchNorm은 “standardization”을 (0-mean, unit variance) 방향으로도 할 수 있다.
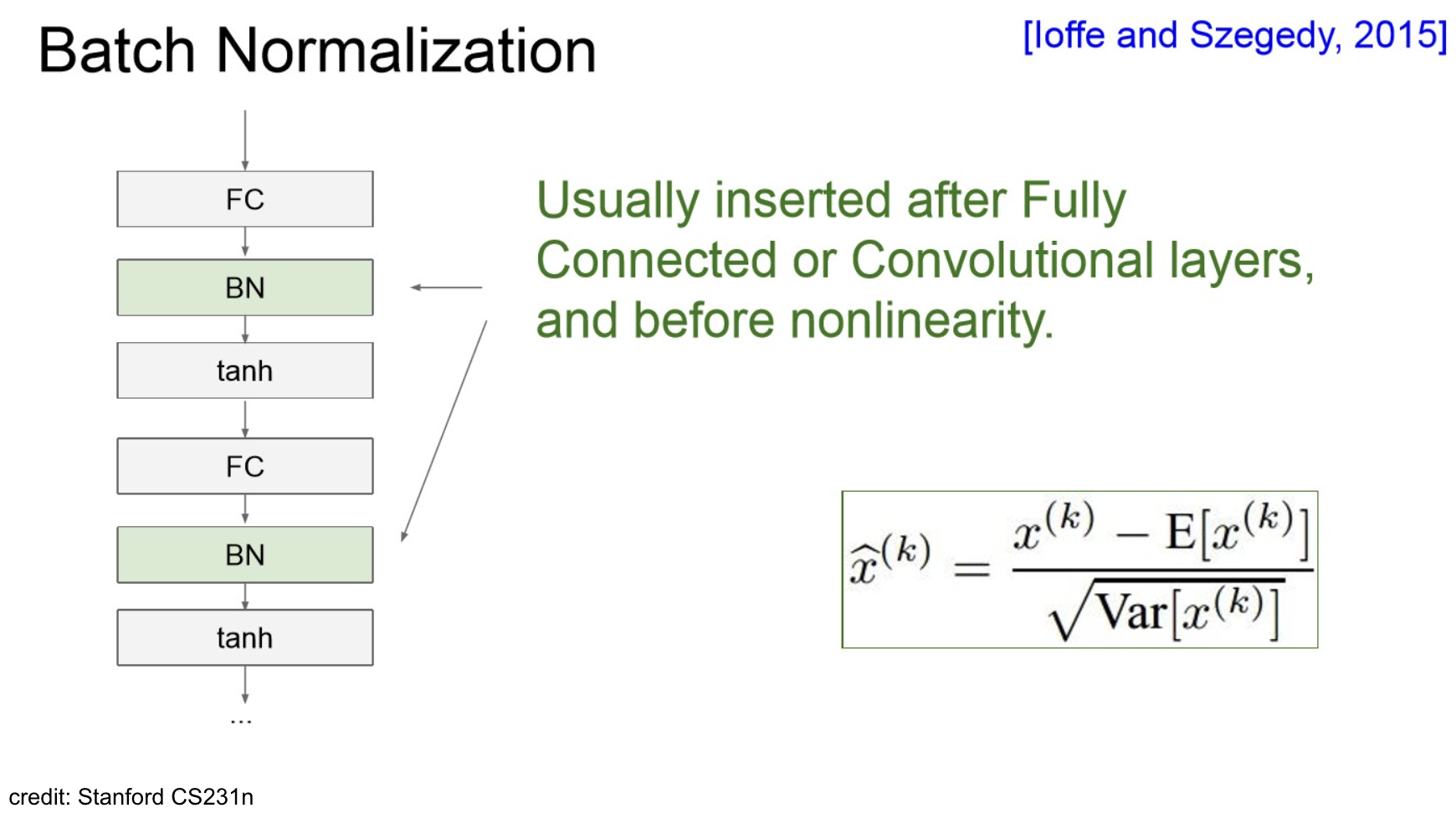
Order of layers:
Extension
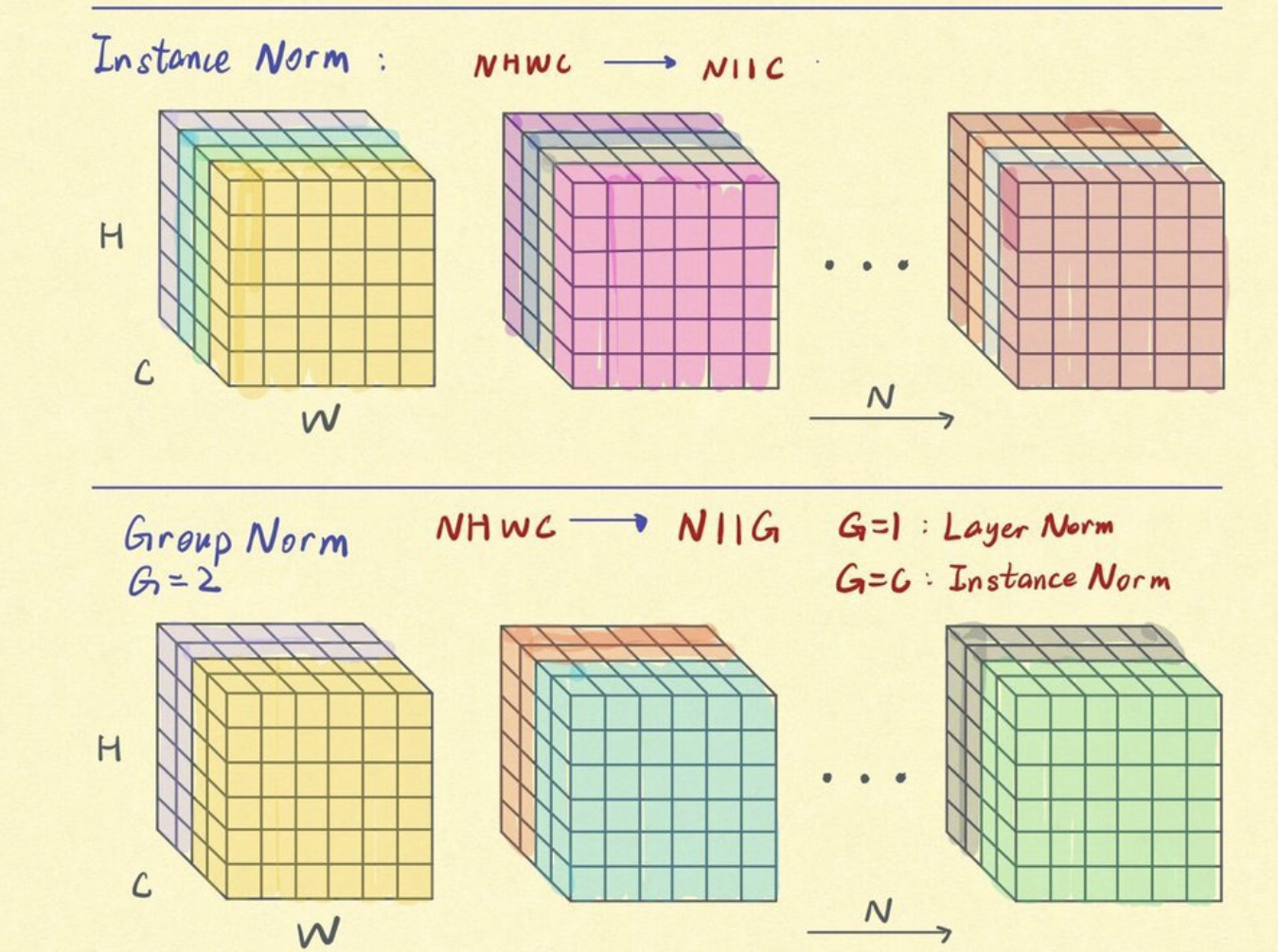
- LayerNorm
- GroupNorm
- InstanceNorm
NOTE