Abstract
Summary
- LM task를 많이 수행하는 것은 근본적으로 NTP 능력만 키우는 게 아니라, 다른 specific한 task에 대한 능력도 같이 키우는 것이다.
- 본 논문에서는 수백만 웹페이지 소스로 부터 만든 WebText라는 새로운 Corpus를 사용해서 pre-train을 함. (Reddit에서 좋아요 3개 이상 달린 링크의 텍스트 소스)
- 지문 + 질문 형 셋인 CoQA에서 55 F1을 기록했는데, 지도학습을 한 4개의 모델들 중 3개를 이김.
- 즉, Zero-shot의 가능성을 또 보여줌.
- GPT-2는 약 1.5B 규모의 Transformer기반 모델이고, zero-shot performance는 규모의 log-scale정도로 비례한다고 함.
→ 결론적으로, 사람의 품이 많이드는 labeling을 하지 않아도 된다는 가능성을 제시.
Question
LM task가 NLI task 전반적 성능이랑 같이 올라간다는 점에서 생기는 의문.
BERT 기반의 모델에서 사용되는 가운데 빈칸 맞추는 과제도 다른 LM task 성능을 같이 올릴까?
→ 이걸 masked language modeling이라 하던가…?
I. Introduction
- 현재의 문제 : Narrow Experts:
- 대부분의 AI model들은 generalist가 아닌, 특정 도메인 혹은 task에 specific하게 fit된 모델들.
- 따라서 OOD에 대해 굉장히 취약함.
- Generalization이 모자른 이유는
- 단일 도메인에서 단일 task로만 학습하기 때문
- 따라서 가야할 지향점은 다양한 도메인과 task에서 성능을 측정하고 훈련할 수 있는 multi-task learner
- 기존의 Multi-task learner에 대한 접근은 ‘diverse한 set + 그에 맞는 objective’를 사람이 직접 설계하여 Scalability,확장성이 낮음.
- 본 논문에서는 LM task의 규모를 키우는 것 만으로 Multi-task 학습의 한 형태가 될 수 있다고 제안.
Summary
GPT1 논문 Improving Language Understandingby Generative Pre-Training에서 pre-train & SFT 패러다임을 보여줬다면, GPT2에서는 pre-train을 더 많이 시켜서 SFT에대한 필요성을 줄일 수 있다고 패러다임 변화를 주장. 즉, pre-train의 중요성을 강조.
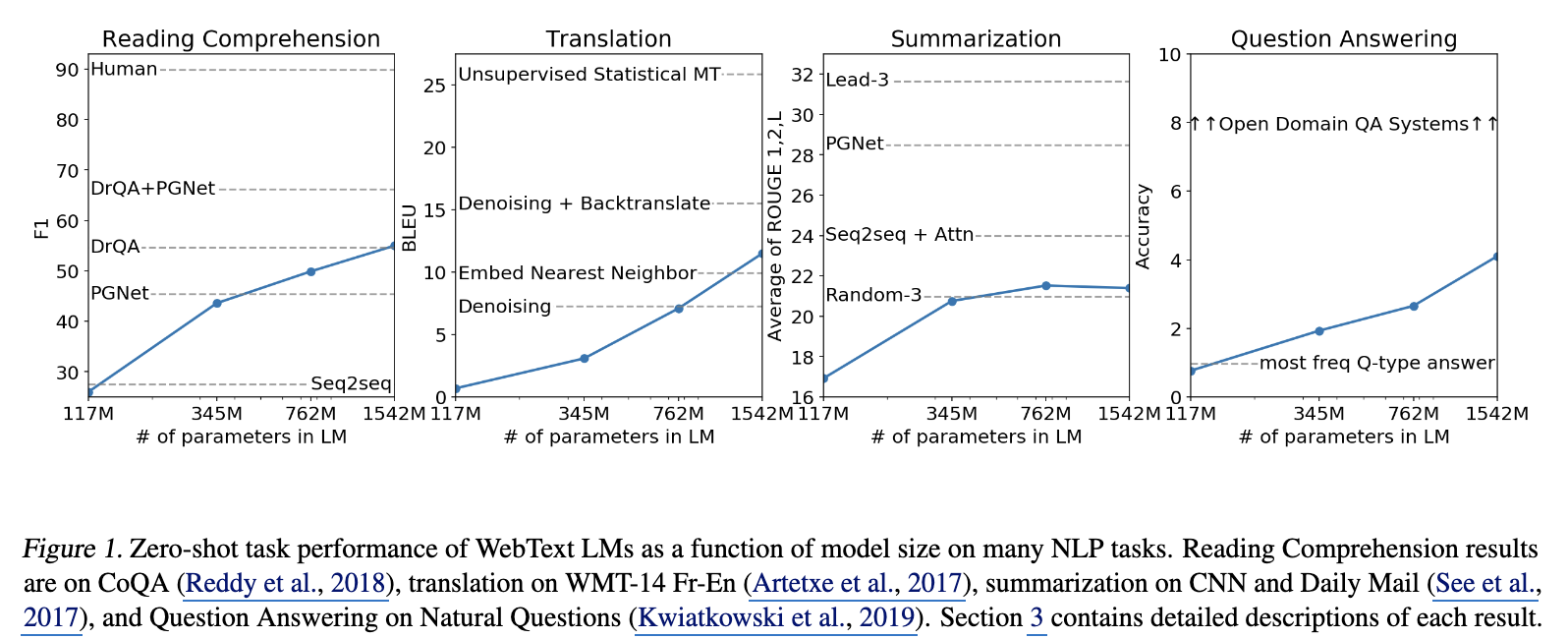
- Scaling Law : 모델 성능 및 데이터 크기에 log정도로 performance 비례
II. Approach
Hypothesis
LM task가 곧 SFT 없이 다양한 작업을 배울 수 있는 Multi-task learnable task이다.
이걸 loss space에서 생각해보면,
“Unsupervised learning의 Global minima가 supervised learning의 global minima와 동일할 수 있지 않을까”라고도 주장함.방대한 corpus내부에서 LM task를 학습하보면, 번역, 문답, 요약 등의 task에 대한 정답들도 포함되어 있을테니, 충분한 representation power,혹은 capacity만 모델에게 제공한다면 그 역시 pattern을 학습할 수 있지 않겠냐 라는 주장.
II-I. Training Dataset(WebText)
- 기존의 Language model들은 주로 뉴스, wki, 소설책 등 단일 도메인 소스로 학습되었는데, language model이 LM task 만으로 여러 NLP task에 대한 generalization performance를 갖추려면 도메인 폭도 넓어야 할 것.
- 기존 Common Crawl 방식은 양은 확보되나 중복이나, 저품질 text 가 많아서
- Reddit에서 좋아요 3개 이상 받은 것들만 고르고(Human-curated filtering)
- Wikipedia 링크는 제거하여(여러 evaluation task set들이 여기서 파생되었으니) 만들어짐
- 대략 : 45M 개의 링크에서 중복 제거 및 cleaning하여 8M 개의 문서에서 총 40GB로 구성된 WebText 만듦.
II-II. Input Representation
- General language model은 어떠한 문자열에 대해서든 확률을 계산하고 생성할 수 있어야하므로, word-level tokenizer는 고려 대상이 아니었음.
- Byte-Pair Encoding(BPE)를 고려했고,
- 보통 unicode 기준에서 BPE를 적용하는데, unicode에 등록된 voca는 약 15만 정도.
- unicode에서 BPE 시작하면 voca 풀이 15만개에서 늘어나는 거니까, 너무 많음.
- 본 논문에서는 UTF-8에서 시작.(256개)
- UTF-8로 pre-train corpus를 모두 tokenizing.
- 그 빈도를 기반으로 BPE
- BPE 알고리즘의 5만 번 merge하고, special token(end of text)하나 추가해서 총 voca는
- 256 + 50,000 + 1 = 50,257개
- 문제점 중 하나가 의미는 같지만, 문장부호가 붙은 단어들이 각각 별도의 token으로 만들어짐.
- e.g. dog. | dog! | dog?
- GPT2에서는 서로 다른 카테고리 간 merging은 막음.(문자와 문장 부호)
- 단, spacebar는 예외(압축 효율을 위해)
II-III. Model

-
Improving Language Understandingby Generative Pre-Training의 GPT 구조를 가져왔고, 모델 크기를 여러 개로 준비함.(117이 GPT1과 동일 규모.)
- 마찬가지로 Decoder-only-Transformer 구조이고,
- Layer Normalization layer를 sub-block 앞으로 가져옴.(학습 안정화를 위해, deep-residual net 논문에서 영감받음.)
- 기존에는 FFN 뒤에 있었음.
- GPT1 :
- GPT2 :
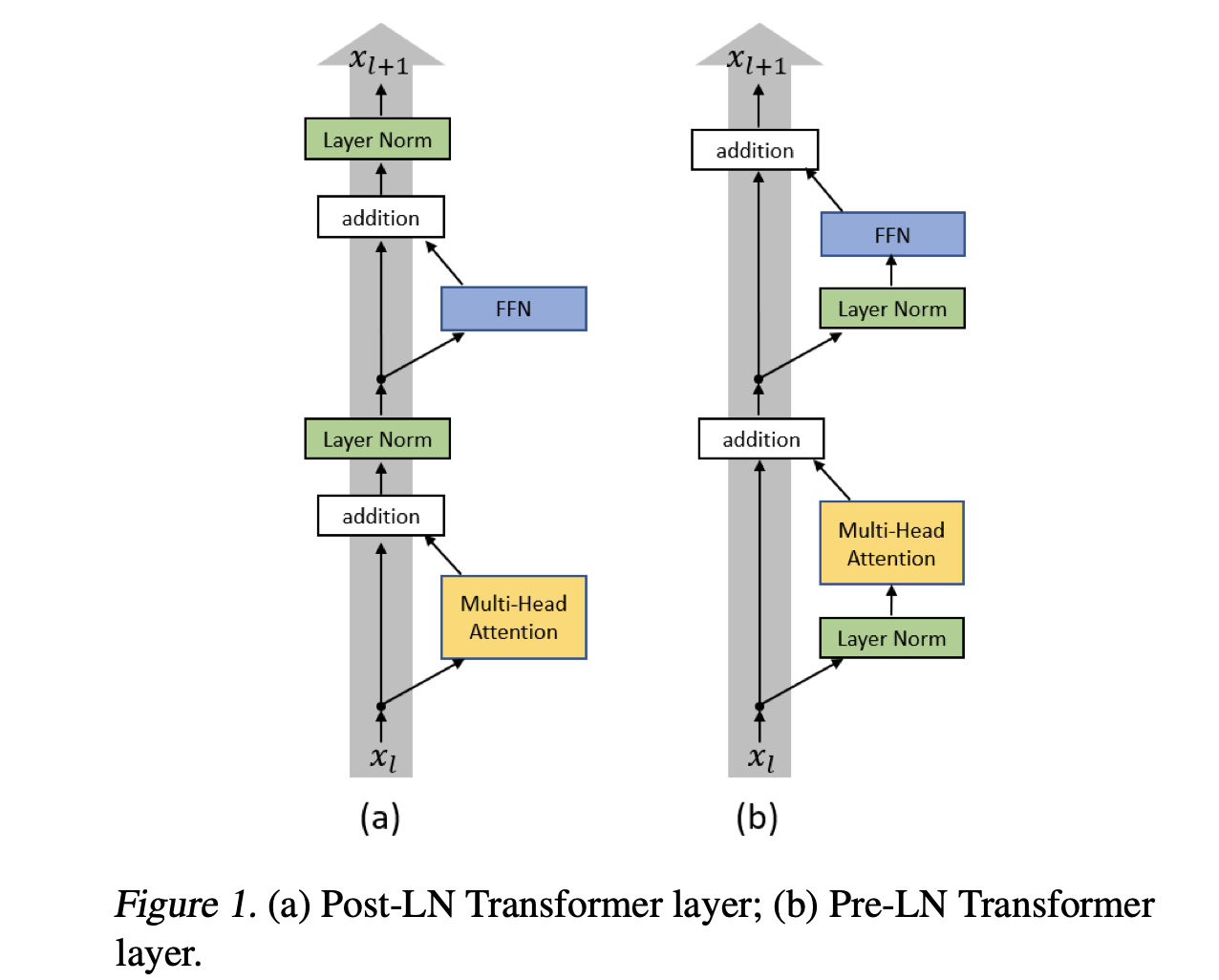
- Weight Initialization 개선
- 모델의 depth가 깊어지면, residual path에서 가중치가 누적되는 문제로 인해, residual layer의 초기 값에 을 곱해서 출력 값들의 분산 제어 및 초기 학습 안정성 높임. (은 layer 개수)
- Context window Size : 512 → 1024
- Batch size : 512
-
규모는 작은 순을로
- GPT1과 동일
- BERT Large 와 비슷
- 좀 더 큰
- 아주 많이 큰 버전
III. Experiments
III-I. Language Modeling
-
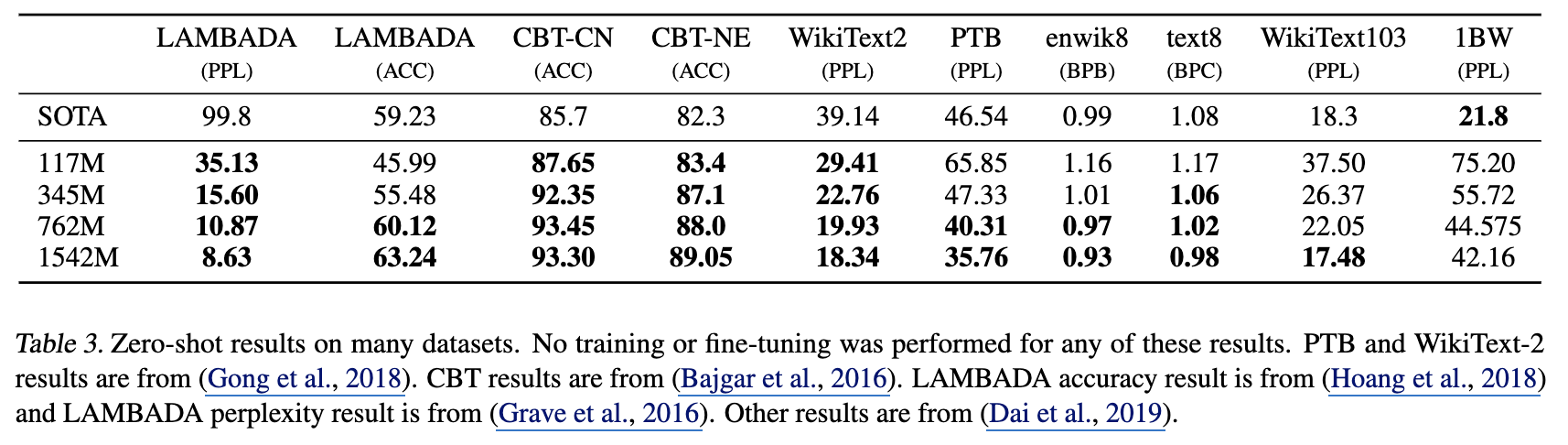
Zero-shot(SFT를 하지 않음. )으로도 여러 LM task에서 SOTA 차지.
- In-Context Learning(ICL) 개념이 제대로 정립된 건 GPT3 논문이라, 조금 맥락이 다를 수 있음.
-
제시된 8개 중 하나(1BW)에서는 SOTA를 차지하지 못했는데, 이는 모델의 강점인 Long-term-dependencies를 제대로 활용할 수 없었다고 함.
- 셋이 문장 단위로 shuffle되어있게 구성됨.
-
주요 성능 지표로는
- perplexity
- BPB(Bits per byte)
- BPC(Bits per character)
III-II. Children’s Book Test
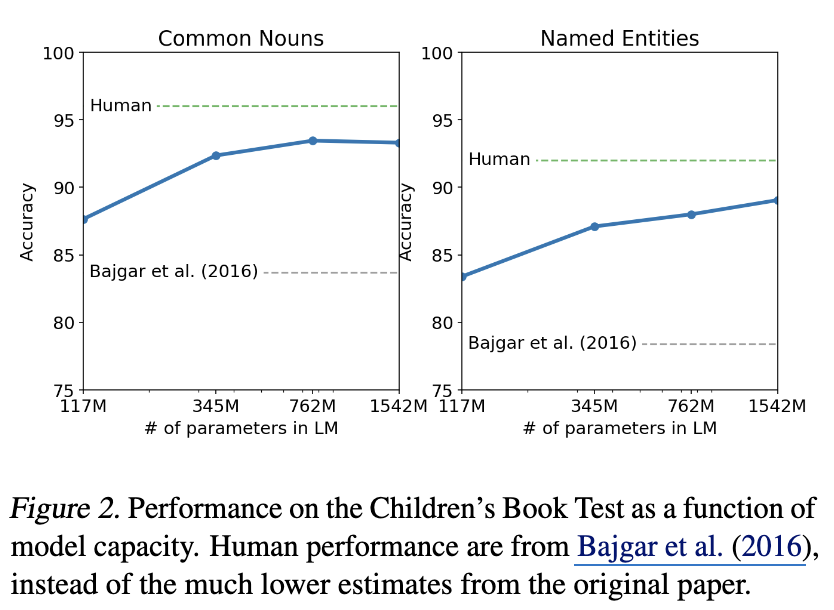
- 아동 도서에서 추출한 텍스트 기반의 Cloze task.
- 모델의 문맥 이해도를 파악하기 위해 고안됨.
- 평가 범주는
- Named Entity
- Nouns
- Verbs
- Preposition
- 이 있고, 제시된 10개의 옵션 중 단어를 하나 고르는 task.
Summary
이미 GPT1 체급으로 SOTA는 제쳤고, 사람보다는 모자른 상태.
Scaling Law 보임. log-linear 형태
III-III. LAMBADA
- Long-range-dependencies를 요구하는 task.
- 문제의 답을 해결하기 위해서는 아주 먼 앞 부분의 내용을 기억하고 이해해야 풀 수 있는 구조.
- 문장의 마지막 단어를 예측하는 과제.
- 사람이 정답을 맞추기 위해서도 최소 50 token 이상의 context가 필요하도록 설계됨.
- perplexity는 기존 대비 10%수준으로 낮췄고, accuracy는 2.5배 정도 높여, SOTA 차지.
- 추가적으로 stop-word filter 즉, 다음 예측하는 단어가 문장의 마지막 단어라는 필터를 적용하니 정확도가 10% 정도 더 상슴.
III-IV. Winograd Schema Challenge
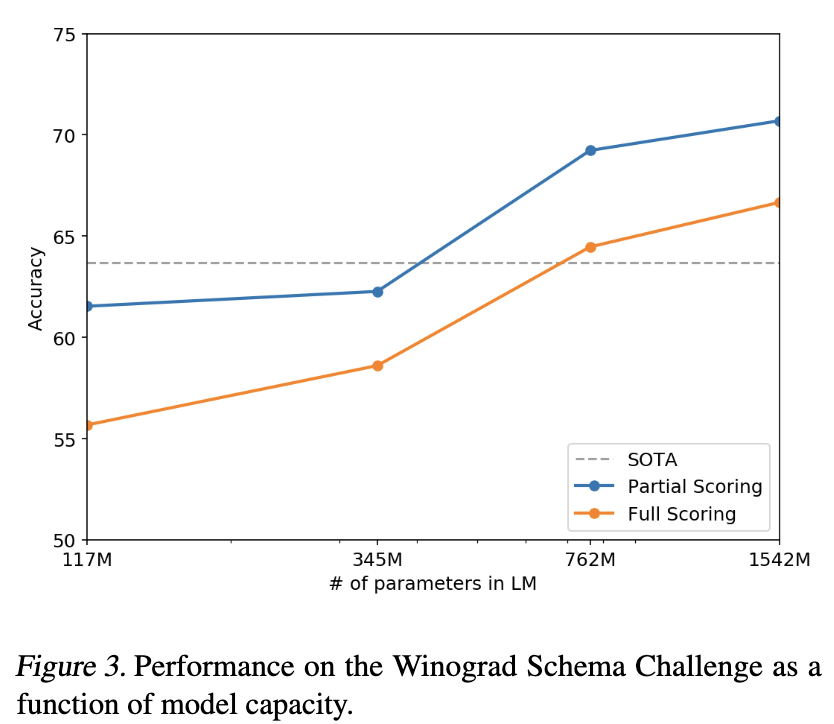
-
common-sense reasoning task.
- 문장 속 애매모호한 대명사 추론 문제.
- e.g. “그 트로피는 갈색 가방에 들어가지 않는다. 왜냐하면 그것이 너무 크기 때문이다.”
- (그것 = 트로피)
-
SOTA를 큰 모델들로 제쳤고.
-
Scaling-Law 보이고,
-
마찬가지로 Zero-shot으로 이겻다.
- 대명사를 후보 명사로 치환한 문장들의 log-prob를 비교하는 방식으로 채점.
-
근데 이 셋이 273개로 매우 작다는 것은 주의점.
III-V. Reading Comprehension
-
Dataset
- CoQA(Conversational Question Answering) : 7개의 서로 다른 도메인에 대한 문서와 그에 대한 자연어 대화로 구성됨.
- “왜?”와 같이 이전 conversational histor를 파악할 수 있어야 풀 수 있는 task.
- 마찬가지로 Zero-shot 환경에서
- “문서 + 대화기록 + 마지막 토큰 A:” 를 입력으로 넣어 답변을 생성하게 함.
-
비교 대상인 baseline 4개 중 3개를 이겼는데, 이들은 모두 SFT / SL 한 모델들
- 결국 SL이 필요 없을지도,,, 라는 해석.
-
한계점으로는
- BERT 기반의 모델(89 F1)이나 사람의 성능보다는 못함.
- 즉, 이 task는 NLU에 더 가깝다고 볼 수도.
- 또한, Who? 라는 질문에는 단순 사람이름을 무작위로 응답하는 패턴을 보임.
- 즉, Retrieval-based heuristics를 사용하는 경향이 보임.
- BERT 기반의 모델(89 F1)이나 사람의 성능보다는 못함.
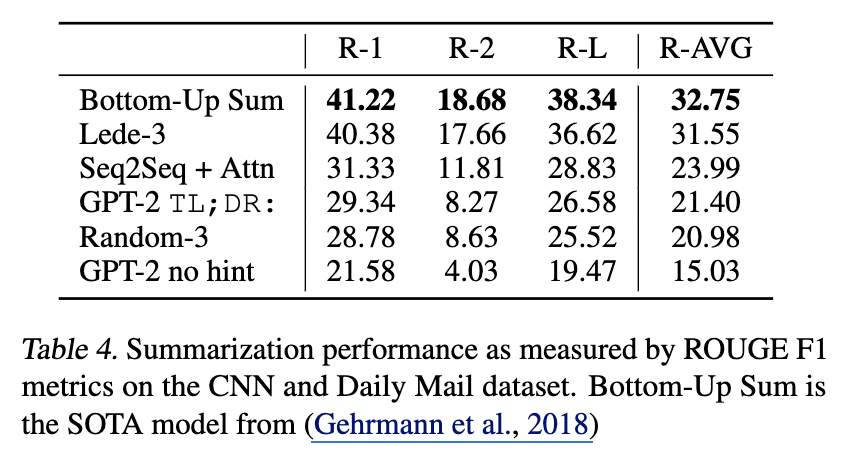
III-VI. Summarization
-
task prompting
- 자연어 프롬프트로 “요약해”라 하지 않고, 기사 본문 뒤에 “TL;DR”(Too Long;Didn’t Read의 약자)를 텍스트에 추가함. 이는 모델이 다음에 올 텍스트가 앞선 내용의 요약본일 확률이 높다고 판단하게 만드는 일종의 자연어 hint.
-
Dataset & Sampling
- CNN 및 Daily Mail 셋을 활용해서 평가함.
- Top-k random sampling()를 사용하여 너무 뻔한 단어만 선택하지 않으면서도 반복을 줄이고, 추상적인 요약을 하도록 유도.
-
Results
- 형태적으로는 원문과 유사했으나, 기사의 최근 부분에만 집중하거나, 구체적인 사실(사고 차량의 대수, 로고의 위치)를 혼동하는 모습을 확인.
- “TL;DR”을 제거 시 성능 지표가 꽤 하락하는 점은 natural-language hint만으로도 task를 수행해야 함을 이해하고 있다고 해석할 수 있음.
III-VII. Translation
-
ICL(In-context Learning) 형식으로 모델의 응답을 유도하기 위해,
- 모델에게 ‘영어 문장 = 프랑스어 문장’ 형식으로 context 만들어주고,
- 마지막에 ‘영어 문장 = ‘해서 model이 sentence complementation하도록 유도.
- 번역 문장은 greedy-decoding 됨.
-
Results
- WMT-14 English - French : 5 BLEU
- WMT-14 French - English : 11.5 BLEU
- 둘 다 모두 높은 성능은 아니다.
- 그러나, 모델에게 zero-shot(w/o SFT) 환경이었으며, pre-train corpus 정제 과정에서 의도적으로 프랑스어 문서를 제거했는데도 불구하고 관찰되었다는 점은 주목할 만함.
- 단, 그럼에도 불구하고 10MB정도의 불어 내용이 들어있긴 했다고 함.
- 단, 매우 적은 내용(일반 번역 비지도 방법에서 사용하는 양의 500배 적은 양)임에도 번역의 기초를 배웠다는 점은 놀라움.
- 그러나, 모델에게 zero-shot(w/o SFT) 환경이었으며, pre-train corpus 정제 과정에서 의도적으로 프랑스어 문서를 제거했는데도 불구하고 관찰되었다는 점은 주목할 만함.
III-VIII. Question Answering
- 마찬가지로 ICL 형식으로 진행됨.
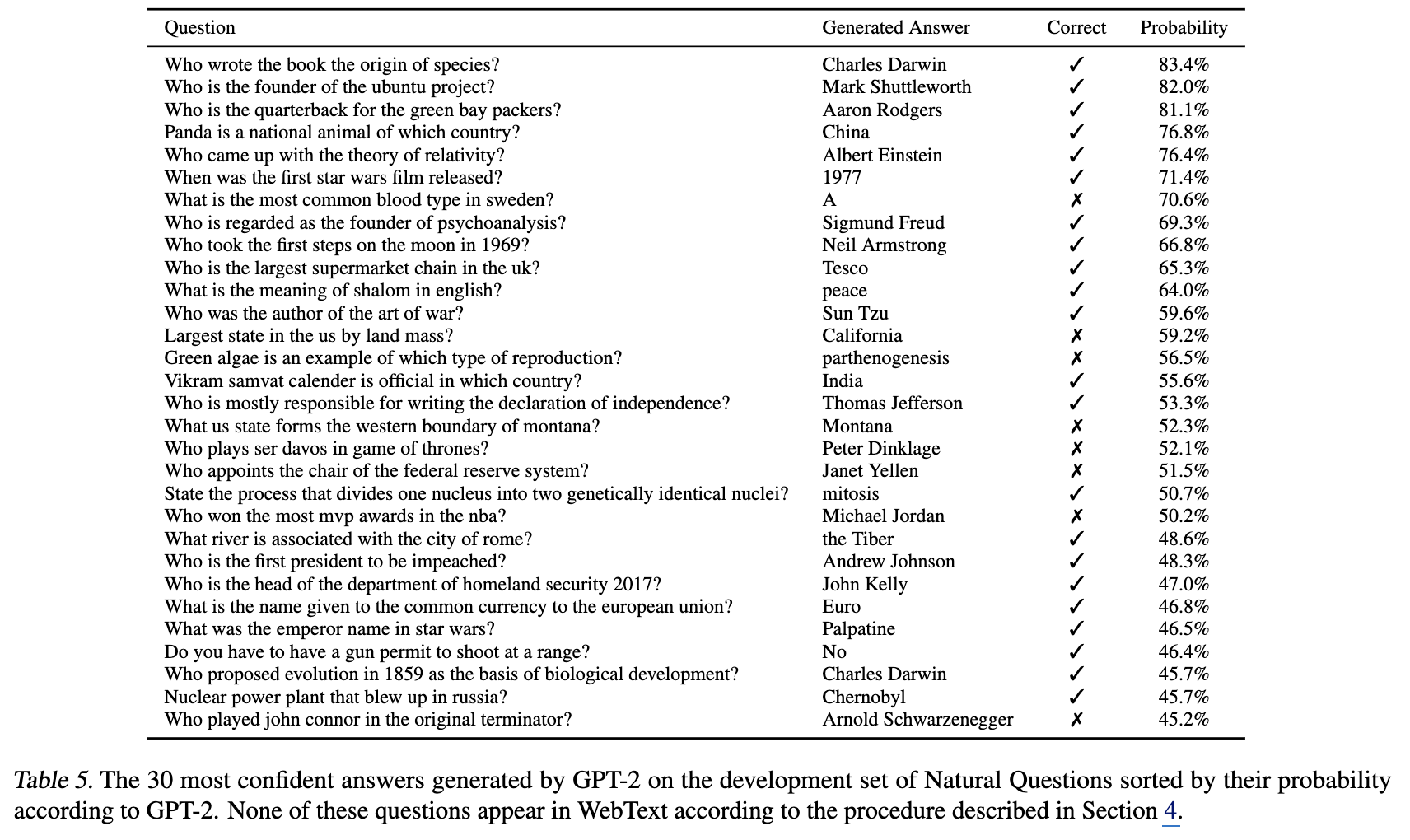
- Natural Questions 셋을 사용했고, 마찬가지로 zero-shot.
- 표에서 correct는 실제 정오.
- prob는 model의 answer에 대한 confidence라고 해석하면 ok.
- softmax 통과 시킨 확률 값을 가져온 것으로 보이며, greedy decoding의 결과로 보임.
- 또한, Calibration이 잘 되어 있음.
- Top 1% confidence를 보여준 질문들을 정렬해서 평균 값을 보니 약 61%의 정확도를 보임.
- 반면, 전체 평균 정확도는 4.1%
- 높게 확신한게 실제로 그 정답률이었음.
- softmax 통과 값이 높은 순으로 30개 정렬해봤는데, 보이는 것처럼, 높은 confidence를 보이는 건, 실제로도 꽤 정답률이 높았음.
- 즉, softmax-probability가 의미 없는 값이 아님.
- calibration이 잘 되어 있다 == model의 metacognition이 높다로 해석할 수도 있을 듯.
- Top 1% confidence를 보여준 질문들을 정렬해서 평균 값을 보니 약 61%의 정확도를 보임.
IV. Generalization vs Memorization
Question
Model이 LM-task랑 기타 과제들을 잘하는 건 알겠는데, 이게 ‘암기’인건지 ‘이해’인건지 알고 싶다.
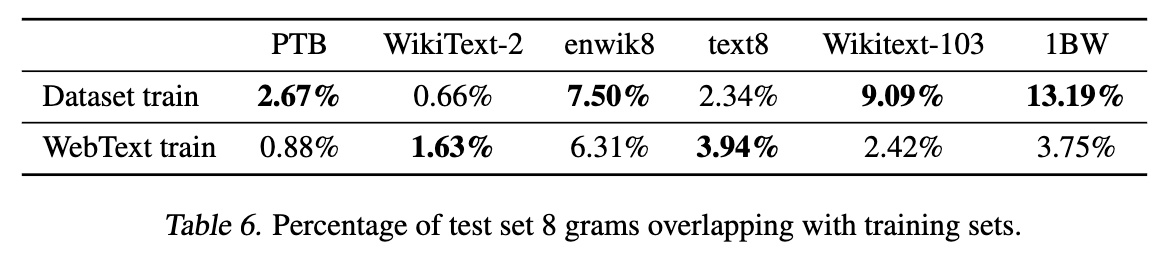
pre-train에 사용된 WebText와 benchmark set에 사용된 데이터 셋들 간 유사도를 비교.
가로축의 데이터들은 그 corpus의 test-set을 의미하고,
1행은 각 데이터 셋의 train 부분.
-
8-gram형태로 각 코퍼스들을 제가공하여 겹치는 비율을 검사.
- 일반적으로 표절 검사하는 분사에서 사용하는 n-gram 값이 보통 5~10이라고 한다.
-
전반적으로 WebText의 일치율이 낮다. 즉, 단순 memorization이라고 보는 것보다는 generalization이라고 보는게 맞지 않을까.
-
Scaling Law가 계속 보인다는 건 아직 underfitting이라는 것 아닌가.
V. Related Work
- Scaling Law :
- RNN 계열을 사용할 때에도 데이터 양을 키워보는 연구를 했는데, 비슷하게 ‘키우면 잘한다’는 결과가 보였다고 함. (Jozefowicz et al., 2016)
- RNN 계열, 1 Billion Word Benchmark
- 모델의 capacity와 데이터셋의 크기를 키우면 더 잘한다.
- (Hestness et al., 2017)
- RNN 계열을 사용할 때에도 데이터 양을 키워보는 연구를 했는데, 비슷하게 ‘키우면 잘한다’는 결과가 보였다고 함. (Jozefowicz et al., 2016)
- BERT와 비교.
- BERT가 NLU 과제는 더 잘하지만, SFT를 해야한다.
- GPT는 pre-train을 강화하여 SFT를 하지 않는 방향으로 간다.
VI. Discussion
Note
- 충분한 pretrain을 할 수 있다면, SL 굳이 필요 없다.
- pre-train은 단순히 시본적 representation을 학습하는 걸 넘어서, 충분한 양과 모델만 확보되면, 별도의 SL 없이 스스로 task를 수행하는 방법을 배울 수 있음을 입증.
- Reading Comprehension
- SL을 거친 모델들과 Zero-shot 모델이 대등할 수 있음을 보임.
- Summarization
- 요약의 형태를 띄기는 하나, 성능은 개선의 여지가 있음.
Scaling Law
- QA나 Translation과 같은 복잡한 작업은 일정 수준 이상의 파라미터를 확보해야 performance가 나오기 시작함. scaling 만으로도 학습할 수 있는 가능성이 증가.
- log-linear 정도의 비례 관계를 보임.
Future Direction
- performance가 목적이라면 fine-tuning은 필수. 다만, pre-train을 잘하면 zero-shot이더라도 일정 성능 확보가 된다는 걸 확인했으니, 모델의 잠재력 정도로 해석하는 것이 맞고, 이제 볼 것은 SFT를 할 시 성능 천장은 어디인지 check 하는 게 중요할 것.
- Uni-directional vs Bi-directional
- BERT 의 효율성을 GPT가 단순히 scaling(데이터, 모델 크기)으로 극복할 수 있을지는 의문.
VII. Conclusion
Summary
충분한 pretrain을 할 수 있다면, SL 굳이 필요 없다.