Summary
- semi-supervised learning framework 제안(pretrain-SFT)
- pre-train / fine-tune paradigm은 이전에도 있었으나,
- Transformer(decoder-only)를 pre-traine단에 사용한 점
- Fine-tuning을 위해 아키텍쳐를 번거롭게 바꾸지 않아도 된다는 점.(task-agnostic)
- pre-train의 산물로 얻을 수 있는 벡터 자체가 유동적일 수 있다는 점.
- GloVe 같은 모델을 사용했을 당시, fine-tuning이라는 건, 일단 학습이 된 GloVe로 추출한 벡터를 input으로 가지는 다른 모델을 또 학습 시킨다던지 하는 방향으로 하여, pre-train 모델의 weight가 바뀌지 않았음.
가 기존과는 차별점임.- Zero-Shot Behavior
I. Introduction
- supervised-learning을 하기에는 labeling 된 데이터가 부족하다.
- 어떠한 task를 사용해야 하는가?
- NLU(Natural language understanding)에 속하는 과제는 language modeling, machine translation 등 다양하게 있는데, 어떠한 작업이 후에 다른 task에 대한 fine-tune시 유리한지 붙투명.
- 어떻게 downstream-task에 맞게 fine-tune할 것인가.
- 기존에는 모델 구조를 바꾸거나 하는 복잡한 과정을 거침.
따라서 본 논문에서는 다음과 같은 2-step framework, semi-supervised learning을 제안.
- Generative Pre-training
- Language Modeling task로 전반적인 pre-training을 함.
- Discriminative Fine-tuning
- QA나 classification 과 같은 downstream-task에 맞게 fine-tuning.
II. Background
III. Framework
III-I. Unsupervised Pre-training
- 라벨이 없는 대규모 텍스트 데이터를 사용하여 언어의 구조와 패턴을 학습하는 단계.
- task : NTP(Next Token Prediction)
- formula : : Maximum Log Likelihood
- : 라벨이 없는 데이터(Unlabeled corpus)의 토큰 집합 입니다.
- : 컨텍스트 윈도우(Context window) 크기로, 예측을 위해 참고할 이전 단어의 개수
- : 신경망 파라미터 를 사용하여 계산한 조건부 확률
III-II. Supervised Fine-tuning
- pre-train된 파라미터를 바탕으로, 라벨이 있는 특정 데이터셋을 사용하여 down-stream task(분류, 추론 등)을 수행하도록 조정.
- Auxiliary Objective: fine-tuning 시 language modeling objective를 함께 학습시키면 모델의 일반화 능력이 좋아지고 학습이 빨라짐.
- 최종 학습 공식:
- : Target task의 정답률을 높이기 위한 손실 함수
- : 보조 학습 목표인 의 반영 비중을 조절하는 하이퍼파라미터
III-III. Task-specific input Transformation
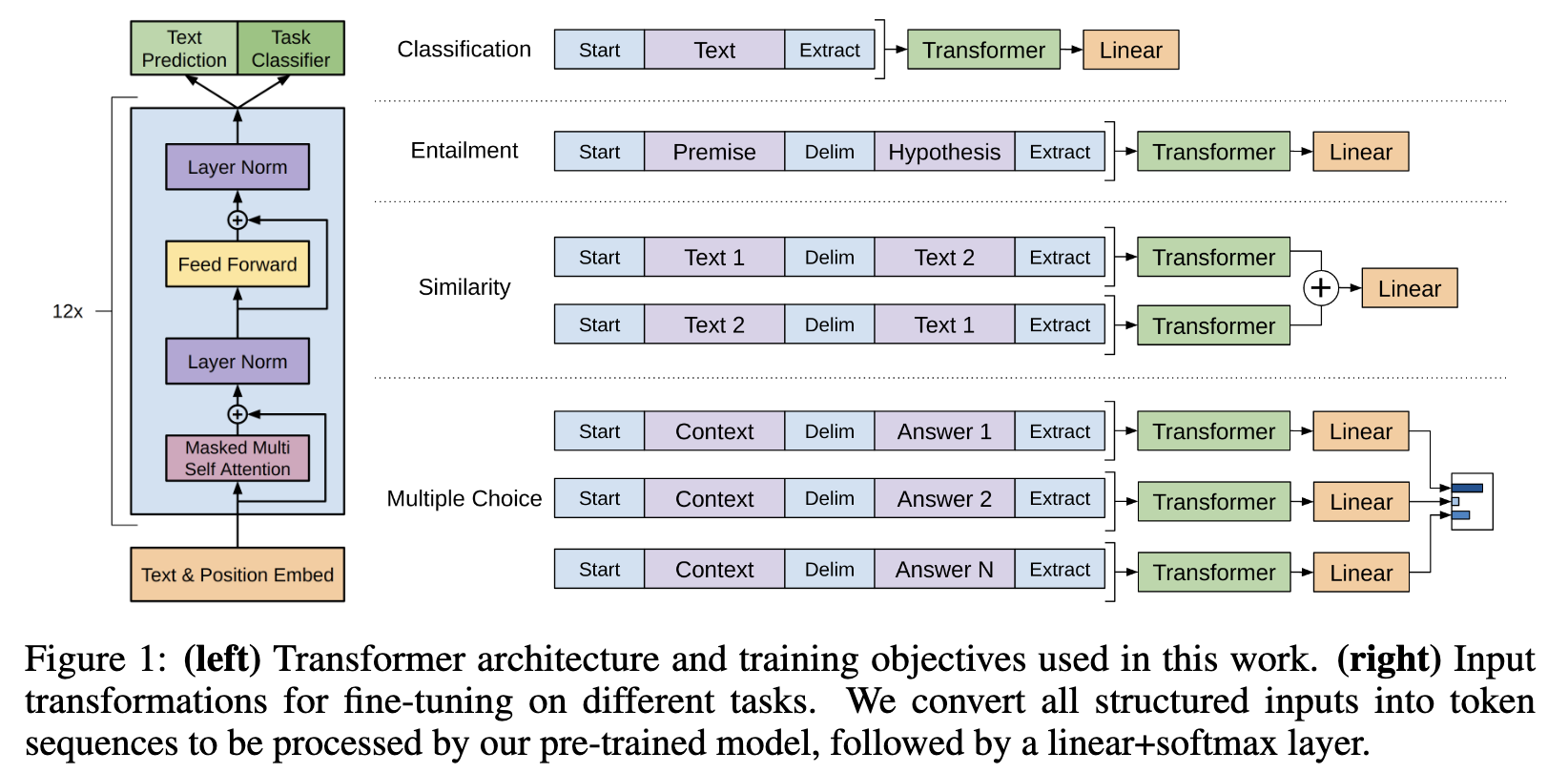
- downstream task를 GPT에 맞게 입력데이터를 sequence로 바꾸자.
- 그리고 downstream task만을 위한 linear head를 추가적으로 붙여줌.
- Loss를 보면 알 수 있듯이, LM task Loss랑 downstream task loss 둘 모두 고려함.
- 매커니즘: Traversal-style Approach
- 모든 input을 하나의 긴 token seq로 붙여나가고,
- start, end token을 각각 input 하나의 시작과 끝에 배치.
- 문장이나, 정보 간 구분을 위해서 delimeter로 $를 사용.
- 의의 :
- Architecture Agnostic : 최소한의 아키텍쳐 변경
- Transfer Efficiency : pre-train된 지식을 거의 가져가면 fine-tuning이 쉬움.
- LoRA나 Adapter와 비슷해보이나, 이 당시에는 full-fine-tuning 했을 것.
IV. Experiment
IV-I. Setup
Datasets
Pre-train
- BookCorpus : 7000권 이상의 미출판 도서로 구성.
Supervised Fine-Tuning

- NLI(Natural Language Inference) Task: SNLI, MultiNLI, Question NLI, RTE, SciTail(entailment task)
- QA(Question Answering) Task: RACE, Story Cloze (coherence task)
- Sentence similarity Task: MSR Paraphrase Corpus, Quora Question Pairs, STS
- Classification Task: SST-2, CoLA
Model Specification
- GELUs(Gaussian Error Linear Units)
- Byte-Pair Encoding(BPE)
- 12 x Decoder layer of Transformer
- 0.117B parameters
IV-II. Supervised Fine-tuning
Hyper-parameters
- LR :
- lr-decay : .2 with warmup
- .5
- batch-size : 32
- dropout : .1
- epochs : 3
Loss(Objective)
- transformer 뒤에 Linear-layer 하나 붙이고 softmax하여 수행.
- 위에서 언급한 것처럼 generalization 성능이 pre-train 시 loss를 같이 사용하는 게 도움이 된다는 것을 발견.
Performance
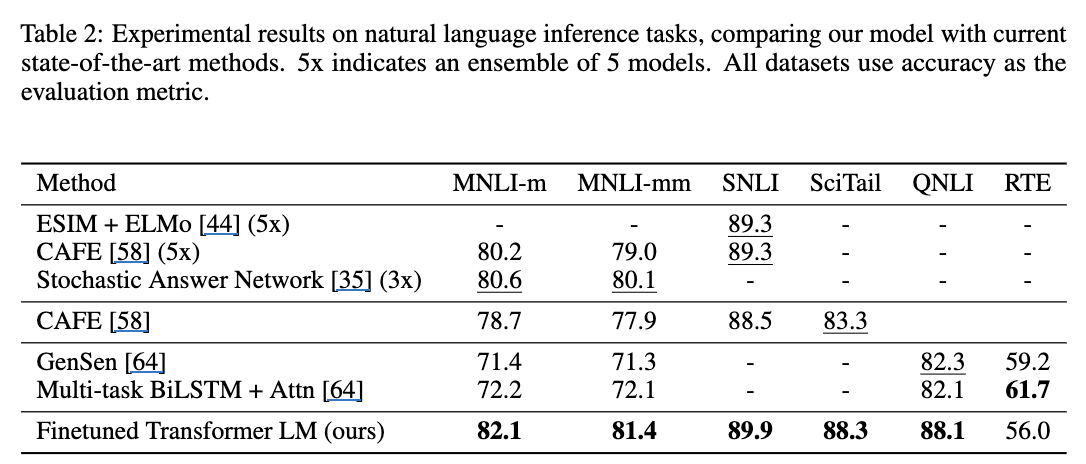
- NLI task 에서는 RTE만 빼고 SOTA.
- 상대적으로 모든 모델들이 공통적으로 가지고 있는 MNLI을 기준으로 보면, 그 task에서 lower performance를 보여주는 모델인 GenSen이나 BiLSTM모델이 RTE에서는 높은 performance를 보여줬으니, RTE 자체의 품질이 좋지 않다는 가능성이 존재하긴 함.
- 실제로 가장 작은 셋들 중 하나이기도 하고. 단순 data shift일지도.
- 다른 의문으로는 혹시 SFT 단계에서 task 순서가 중요하진 않나?
- 상대적으로 모든 모델들이 공통적으로 가지고 있는 MNLI을 기준으로 보면, 그 task에서 lower performance를 보여주는 모델인 GenSen이나 BiLSTM모델이 RTE에서는 높은 performance를 보여줬으니, RTE 자체의 품질이 좋지 않다는 가능성이 존재하긴 함.
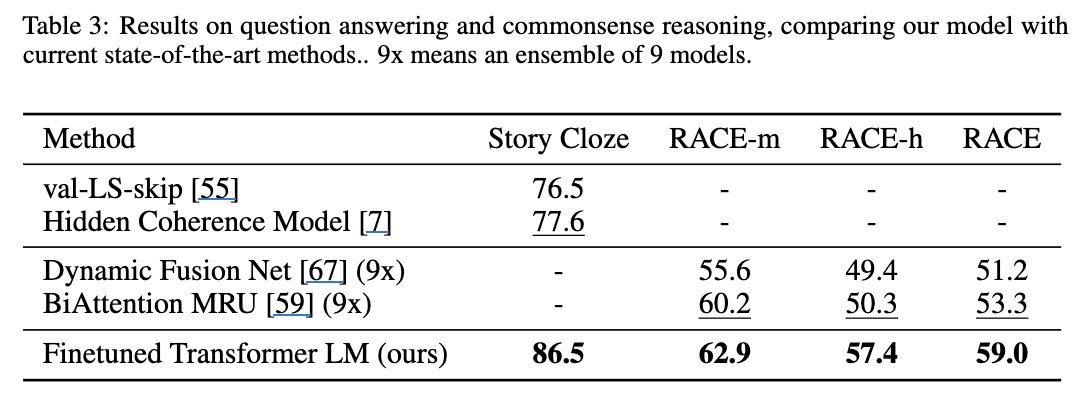
- QA task에서는 모든 과제에 대해 SOTA 갈아치움. 그것도 꽤 큰 폭으로.
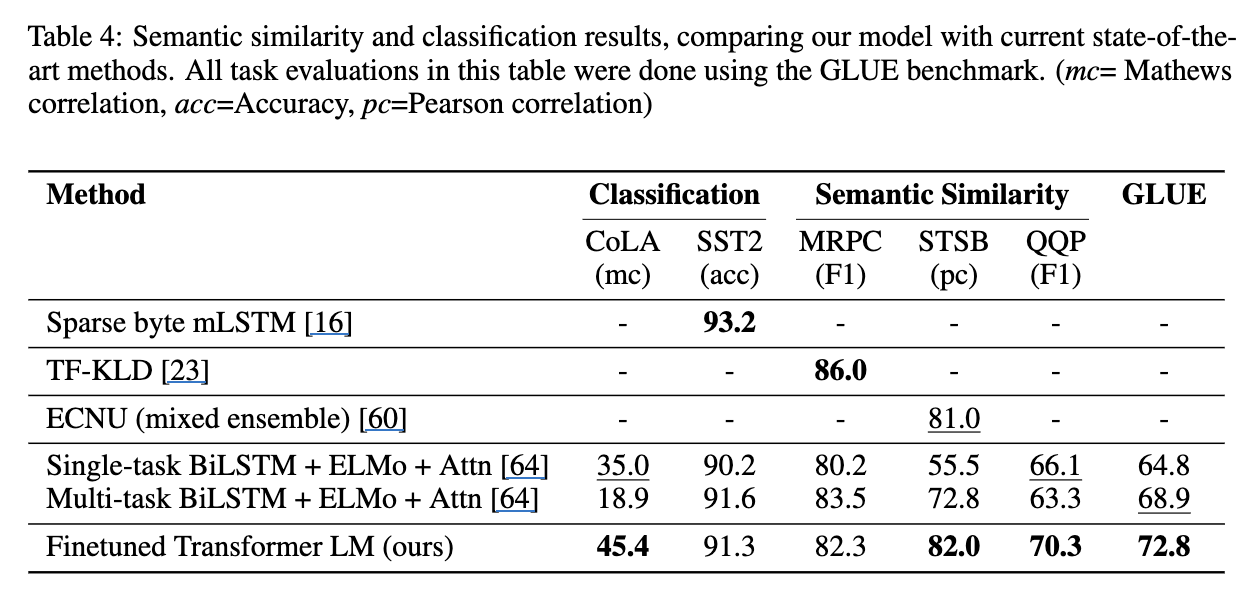
- SST-2, 거의 대부분 .9 근처라 크게 의미있을 것 같진 않고.
- 문장이 자연스러운지 아닌지 판단을 좀 더 잘하게됨.(CoLA)
- MRPC도 거의 비슷한 맥락으로 일정 수준의 성능은 확보된 것으로 보임.
또한, GPT가 SOTA를 가져가지 못한 모델들은 많은 셋들로 학습되어 보이지 않아, overfitting된 가능성도 베제할 수 없음. (표에서 점수가 확인되지 않으니까)
- 좀 재미있다고 느낀 점은 SS 과제의 경우, human-preference로 alignment하는 정도로도 해석이 살짝 될 것 같은데 꽤 잘하네?
V. Analysis
V-I. Impact of number of layers transferred
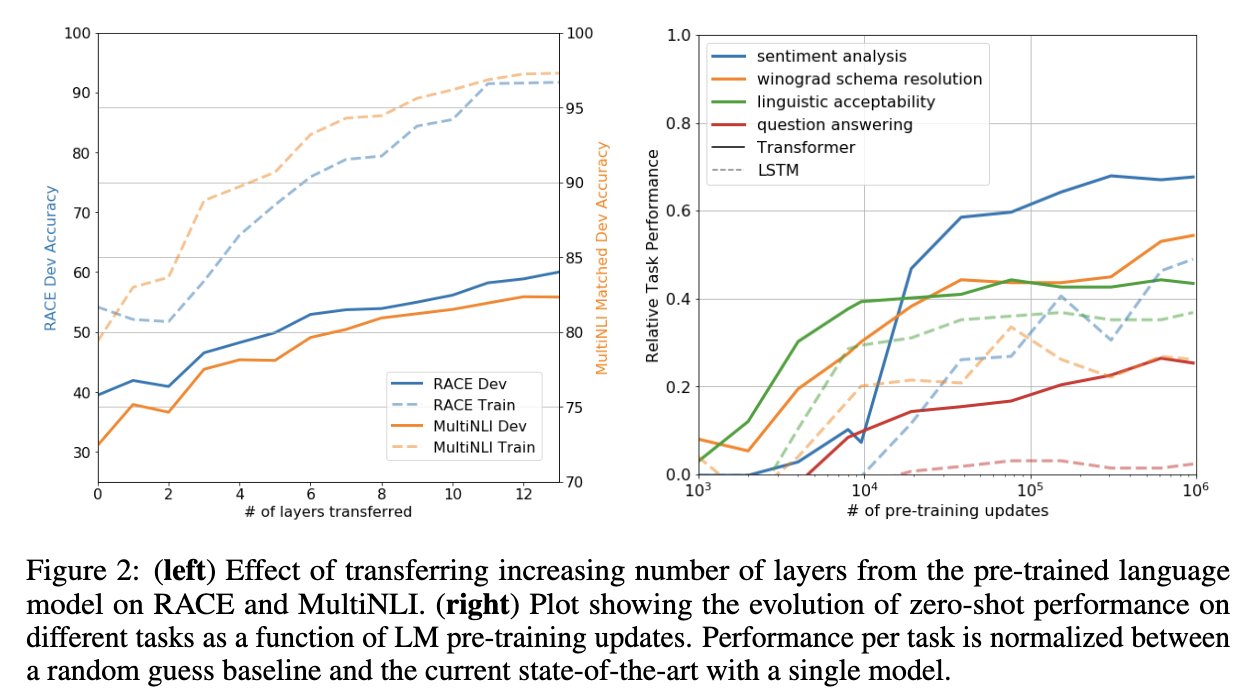
-
Fig2의 left
-
pre-train된 모델에서 layer 개수를 조절하며 떼어와서 linear 뒤에 붙여서 fine-tune.
- 즉, 총 학습된 12 layer의 GPT에서 특정 개수만큼의 layer만큼만 떼어서 가져옴
- 여기에 바로 linear를 붙이든가 해서 fine-tuning 진행함.
- 즉, layer 별로 어떠한 정보를 혹은 얼마만큼의 정보를 가지고 있는지 파악하기 위한 setting.
-
layer를 깊게 사용할수록 성능은 증가함.
- 즉, pre-train(LM task)를 하는게 어느정도 downstream task에도 영향을 준다.
-
비교 대상인 LSTM 대비 월등히 좋은 performance를 보여줌.
- 또한, learning curve 역시 좀 더 smooth하게 보이므로, 안정적인 것으로 해석됨.
V-II. Zero-shot Behavior
-
Fig2의 right
-
LM task를 하면서 단순히 NTP 하는 방법만 배우는 게 아니라, logical coherence, senetence silmilarity 등도 같이 해울 것이다
-
x축은 batch 처리 횟수.
-
SFT를 하지 않고 pre-train단계에서 task별 수행능력을 확인.
-
당시 GPT 성능은 문장 생성도 어려워서 약간의 heuristic을 사용해서 평가.
- 예를 들어 model에게 긍정/부정 평가를 시키고 싶으며, logit 단에서 positive/negative token의 크기 비교하는 식으로.
V-III. Ablation Study
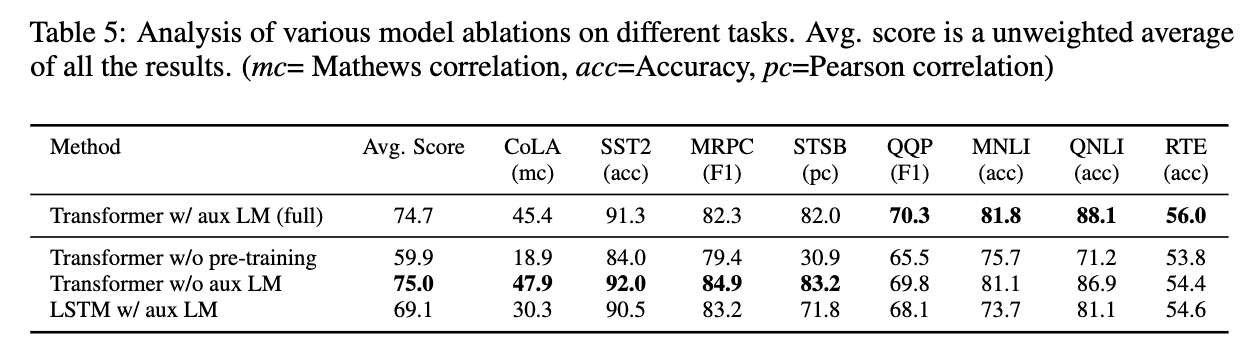
SFT 단계에서 pre-train의 loss를 같이 사용할지 말지 고민하는 study.
-
Fig1을 보면, Head가 2개인데, 그 모델 구조에서 어떻게 backward하는 게 가장 모델 performance를 올려주는 건지 확인
-
w/o pre-train vs full
- 당연히 pre-training하는게 성능에 도움을 많이 준다.
-
w/o aux vs full
- 다만, 큰 dataset에서는 도움이 되었는데, 작은 set에서는 효과가 미미.
-
Transformer vs LSTM : Transformer가 더 좋은 performance.
VI. Conclusion
Contribution
- Task-agnostic framework 제안.
- Could LM-task emergent zero-shot behavior?