Summary
Working memory를 구현한 사례 중, textual memory 형태로 구현.
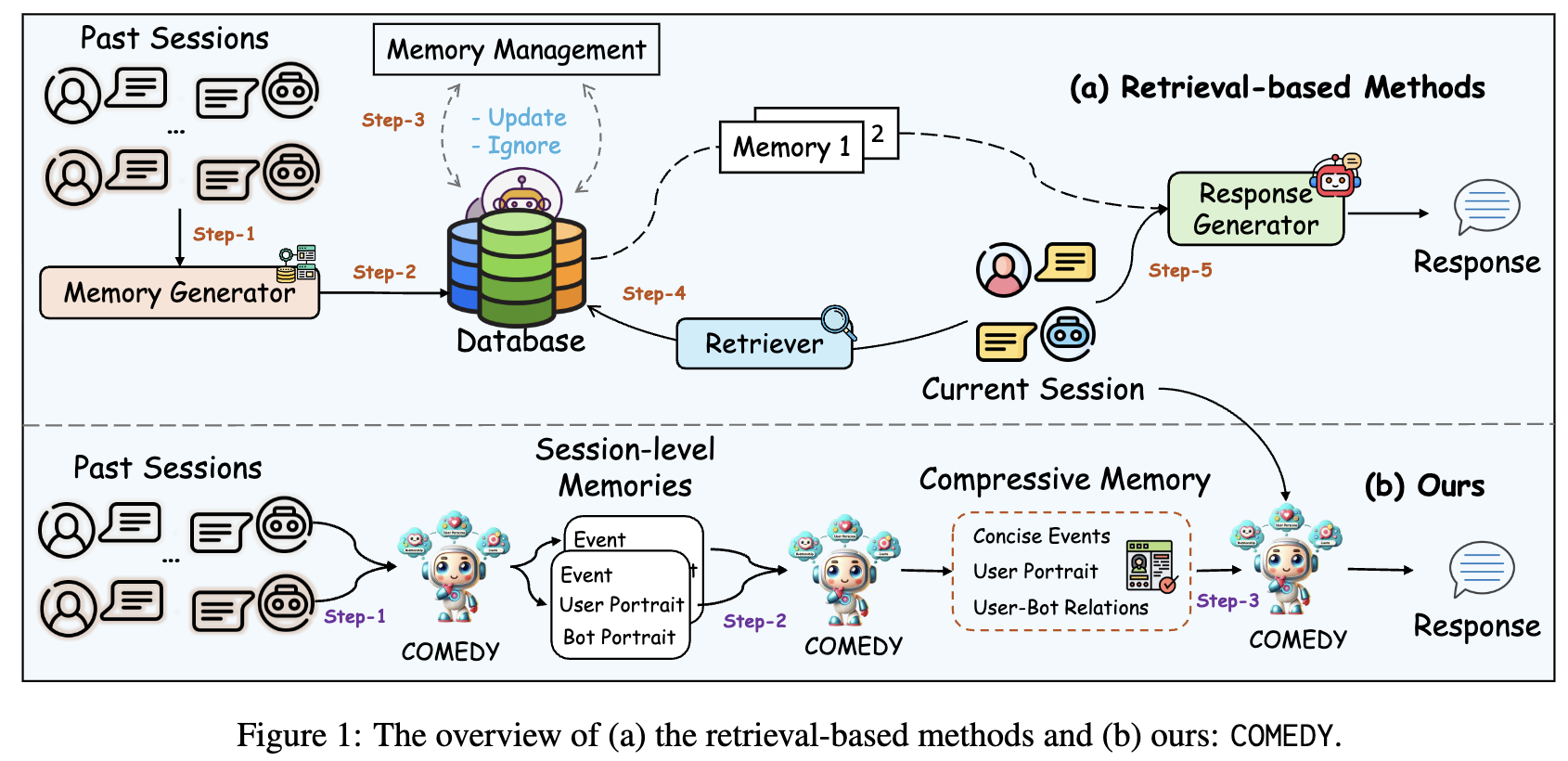
핵심 키워드는 one for all 즉, RAG처럼 external memory를 두지 않고, LLM에 SFT + DPO 조합 사용해서 LLM의 response 자체가 memory를 더 참고해서 답변하는 방향으로 tuning 해버리자.SFT 셋으로 (full, summarized-version text)를 pair로 주어 SFT.
DPO 수행해서 Human-preference alignment 수행. (DPO 시 preference가 높은 쪽은 이전 memory를 반영한 response를 높게 쳐주어 fit. )Train-task로는
- Summarization
- Compression
- Generation(memory based conversation) 이 세가지 task로 SFT. (Mixed-Task SFT)
by Moonlight
- 🚀 이 연구는 기존 retrieval 기반 방식의 한계를 극복하기 위해, retrieval 모듈이나 메모리 데이터베이스 없이 단일 LLM으로 메모리 생성, 압축, 응답 생성을 통합 관리하는 새로운 프레임워크인 COMEDY를 제안합니다.
- 🐬 COMEDY 개발을 위해 실제 사용자-챗봇 상호작용에서 파생된 중국 최대 규모의 장기 대화 데이터셋인 Dolphin을 구축했으며, 이는 세 가지 핵심 태스크를 지원하는 10만 개 이상의 샘플로 구성됩니다.
- 📈 COMEDY는 기존 방식보다 더 미묘하고 인간적인 대화 경험을 제공하며, 특히 DPO 훈련을 통해 대화의 기억력, 일관성, 인간다움 측면에서 뛰어난 성능을 입증하여 ChatGPT를 능가하고 GPT4와 비견할 만한 결과를 보여줍니다.