Keywords: Agents, Efficiency, Agent-Memory, Tool-Learning, Planning
Projects: https://efficient-agents.github.io/
Code Repository: https://github.com/yxf203/Awesome-Efficient-Agents
0. Abstract
Summary
- 본 논문은 효율적인 에이전트 개발을 위한 메모리, 도구 학습, 계획 전략에 대한 종합적 조사를 제공한다.
- 저자들은 상하이 인공지능 실험실, 푸단 대학, 중국 과학기술대학 등 다양한 기관에서 공동 연구를 진행했다.
- 조사에서는 에이전트의 인지 능력 향상과 복잡한 작업 수행을 위한 기술적 접근 방법을 체계적으로 분석하고 있다.
- 특히, 메모리 최적화와 도구 활용을 통한 학습 효율성 향상이 핵심 주제로 강조된다.
- 계획 전략의 발전은 에이전트가 장기 목표 달성에 필요한 추론 능력을 강화하는 데 기여한다고 설명했다.
1 Introduction
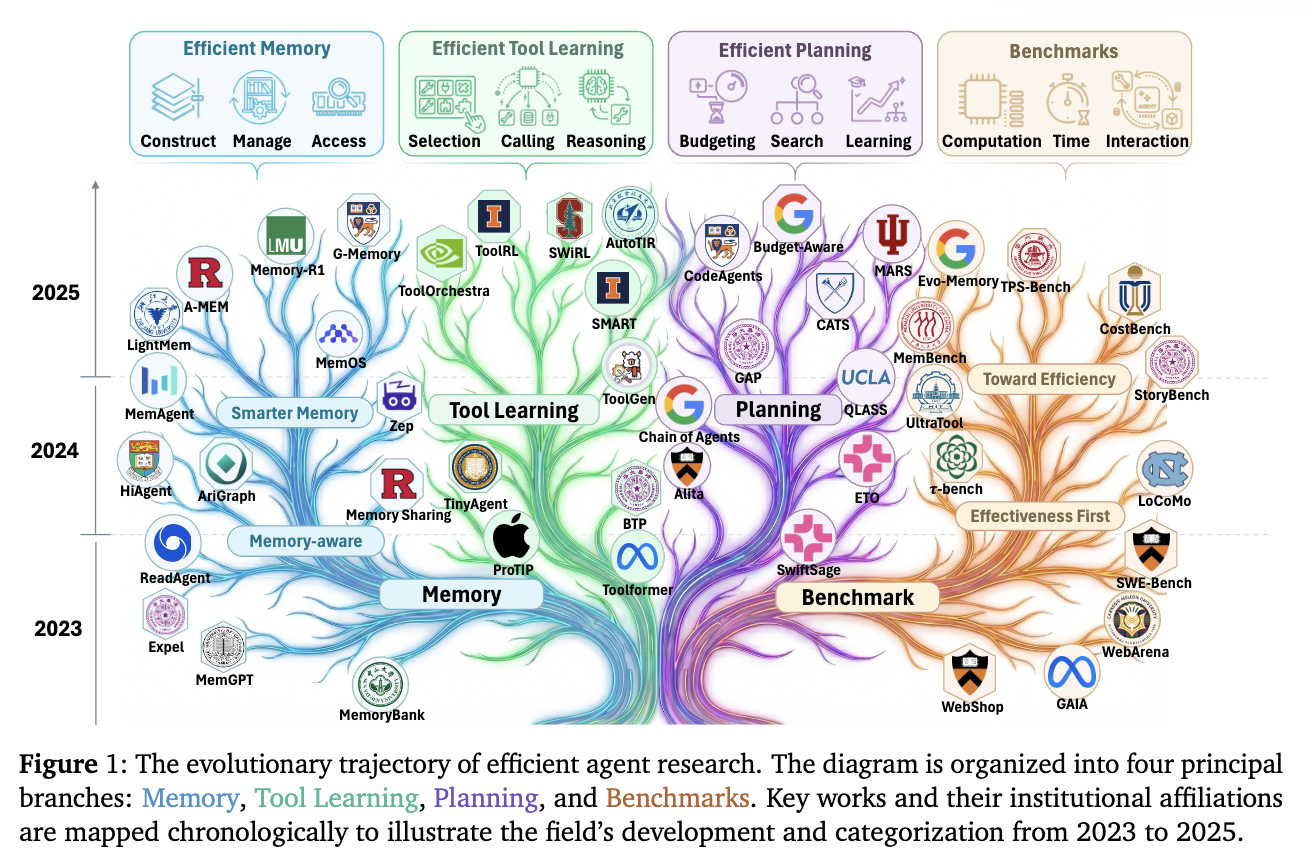
Summary
LLM이 개발되고 25년 이후 트렌드는 LLM을 base로하는 agent.
즉, passive하게 응답만 하는 걸 넘어서 일까지 해주는 agent로 발전해가는 중.문제는 LLM이 이걸 처리하다 보니, context로 전달해야 할 정보량이 너무 많아서 bottleneck.
- 메모리 관리, iterative한 도구 사용, complex planning 등이 중요한 개선 포인트들.
- agent는 너무 많은 리소스를 요구한다.
→ efficient한 agent의 개발이 필요.
Question
Efficient Agent :
- is not a smaller model, but as an agentic system optimized to maximize task sucess rates while minimizing resource consumption, including token usage, inference latency, and computational cost across memory, tool usage, and planning modules.
Check
본 논문은 따라서 효율적인 agent를 정의하기 위해 아래와 같은 3가지 축으로 접근.
- Efficient Memory: Techniques for compressing historical context, managing memory storage, and optimizing context retrieval.
- Efficient Tool Learning: Strategies to minimize the number of tool calls and reduce the latency of external interactions.
- Efficient Planning: Strategies to reduce the number of executing steps and API calls required to solve a problem.
2 Preliminaries
Summary
- 본 섹션에서는 언어 모델 기반 에이전트를 외부 도구 인터페이스와 명시적 메모리 성분을 갖는 부분 관찰 마르코프 의사결정 과정(POMDP)으로 모델링한다.
- 모델은 상태 공간(S), 관측 공간(O), 행동 공간(A), 전이 커널(P), 보상 함수(R), 할인 인자(γ) 및 외부 도구 집합(T), 도구 인터페이스(Ψ)를 포함한 수학적 구조 로 정의된다.
- 명시적 메모리는 메모리 상태 공간 , 메모리 업데이트 규칙(U), 초기 메모리 분포(ρ)를 통해 모델링되며, 이는 현재 메모리와 가용 정보를 기반으로 다음 메모리 상태로 전이된다.
- 도구 인터페이스(Ψ)는 도구 호출 실행 방식과 에이전트로 전달되는 도구 출력을 명시적으로 정의한다.
- 전체 모델은 환경 역학, 외부 도구, 메모리 시스템의 상호작용을 통합한 확장된 POMDP 프레임워크를 기반으로 구성된다.
2.1 Agent Formulation
Summary
- 본 섹션에서는 LLM 기반 에이전트를 외부 도구 인터페이스와 명시적 메모리 구성 요소가 포함된 부분 관찰 마르코프 의사결정 과정(POMDP)으로 모델링한다.
- 모델은 상태 공간 , 관찰 공간 , 행동 공간 , 전이 커널 , 보상 함수 , 할인 인자 등으로 구성되며, 외부 도구 집합 와 도구 인터페이스 를 통해 환경과 상호작용한다.
- 명시적 메모리는 메모리 상태 공간 , 메모리 업데이트 규칙 , 초기 메모리 분포 로 정의되어, 현재 메모리와 정보를 바탕으로 다음 상태로 전이된다.
Summary
LLM-based agent가 환경과 상호작용하는 모델을 POMDP(Partially Observable Markov Decision Process)로 정의.
: latent env space
: observable space
: agent action space
: env dynamics
: reward function
: discount factor
: discount factor
: external Tool set
: external Tool interface
: memory state space
: update rule which maps the current memory state to next memory state
: initial memory
2.2 From Pure LLMs to Agents
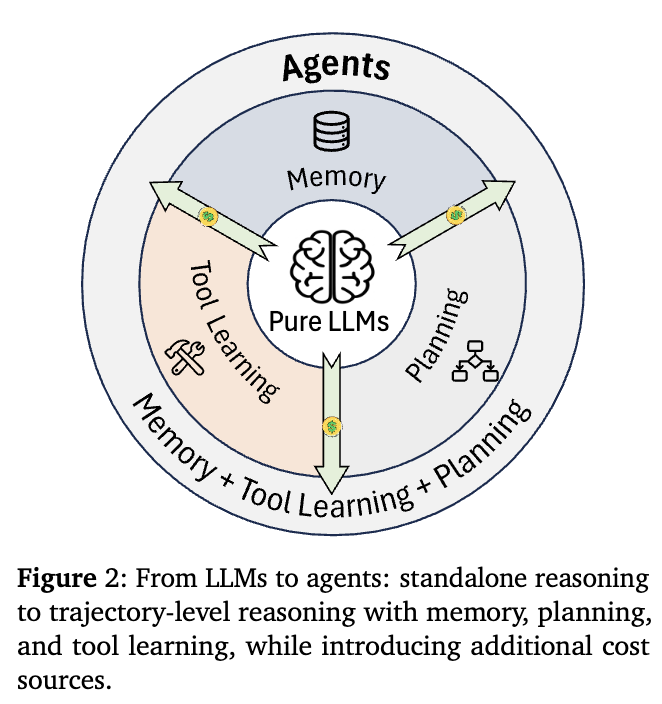
Summary
- 효율성은 비용-성능의 균형을 통해 정의되며, 낮은 비용으로 유사한 성능을 달성하거나 동일한 비용 내에서 높은 성능을 실현하는 것을 목표로 한다.
- LLM 기반 에이전트는 모델 압축이나 추론 가속화와 같은 기술을 사용하지만, 이는 에이전트 고유의 비효율 원인(예: 계획, 메모리)을 해결하는 기반 요소로 작용한다.
- 에이전트는 다단계 계획, 외부 도구 사용, 메모리 기반 의사결정 등의 기능을 통해 추가 비용(예: 도구, 메모리, 재시도)이 발생하며, 효율성 향상은 언어 생성뿐 아니라 도구/메모리 호출 빈도와 선택성 개선을 포함한다.
- 그림 2에 따르면, 에이전트는 토큰 생성 비용 외에도 도구 사용, 메모리 접근, 재시도 등으로 인한 추가 비용이 발생한다.
- 따라서 에이전트 효율성 개선은 단순한 언어 생성 감소보다, 궤적 내 도구 및 메모리 활용의 최적화를 통해 비용-성능 균형을 개선하는 데 초점을 맞춰야 한다.
Summary
LLM에서 memory, tool-learning, planning을 붙여서 agent를 만들 수 있다.
비용을 정리해보면,
이라면,: indicator
3 Efficient Memory
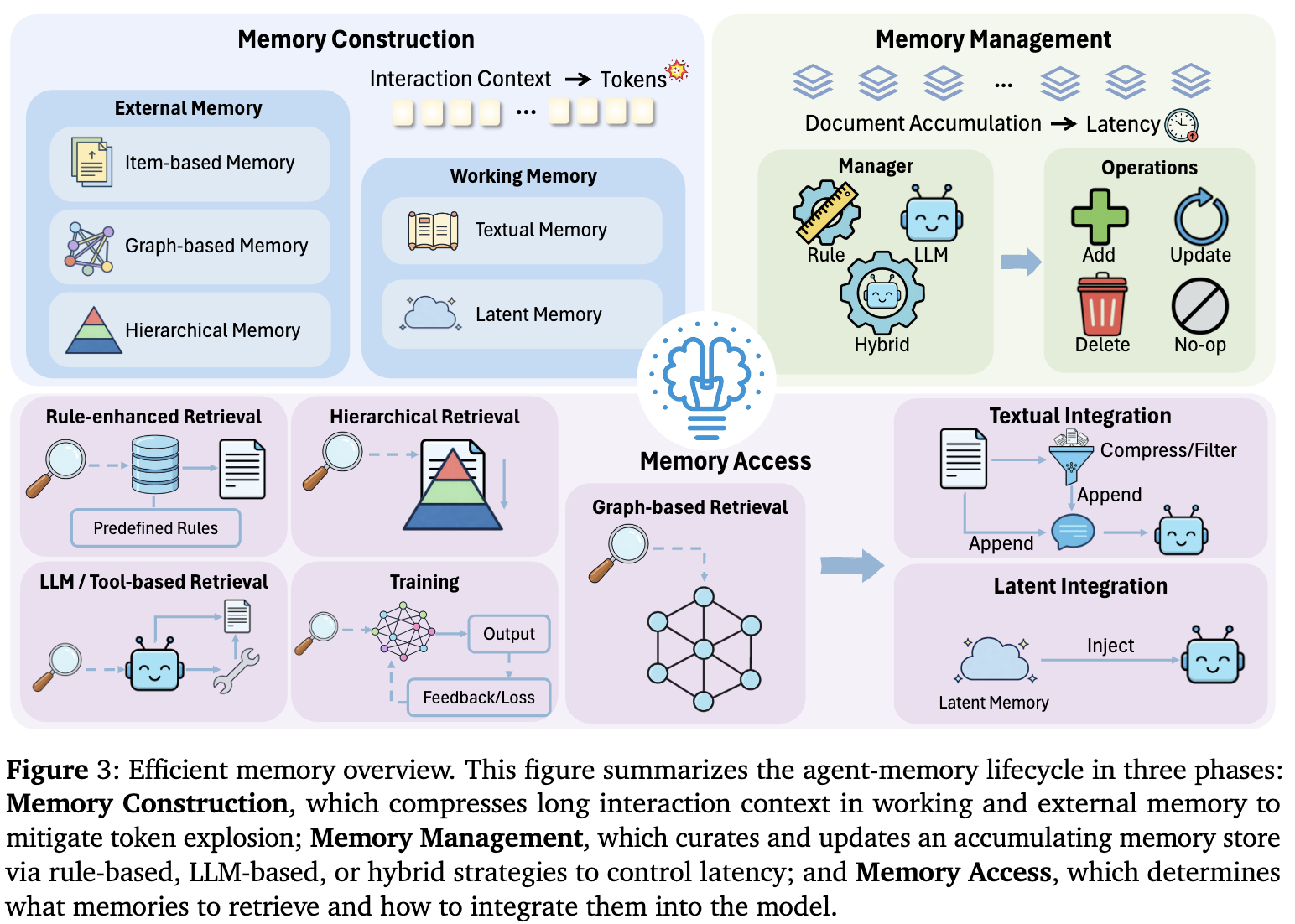
→ memory lifecycle
Summary
LLM 에이전트의 효율성 저하 원인은 긴 맥락과 장기 상호작용으로 인한 계산 및 토큰 오버헤드이다. Memory-augmented reasoning은 과거 경험을 저장·재사용하여 중복 계산을 줄이고 결정을 개선하는 핵심 메커니즘이다. 메모리 생명주기는 Memory Construction(맥락 압축), Memory Management(저장소 관리), Memory Access(정보 통합)의 3단계로 구성되며, 각 단계에서 오버헤드 최소화를 위한 효율 설계가 강조된다. 메모리는 시스템의 효율성-효과성 균형 개선에 필수적이다.
Summary
LLM-agent의 bottleneck으로 분류되는 한 가지 포인트 중 하나가 context 관리.(token-overhead)
- 기본적으로 긴 context를 long-horizontal interaction으로 가져가는 게 어려운 포인트
memory가 중요한 이유는 이전 경험이나 지식을 잘 carry해야,
- 반복적인 일을 덜 하고,
- inform한 decision을 더 하고,
이게 결국 compute-cost를 줄여준다.
- MemGen
- Titans
3.1 Memory Construction
Summary
- 긴 문맥 처리 및 장기 상호작용을 위한 핵심 과제는 방대한 정보를 효율적으로 관리하는 것으로, 단순히 역사 데이터를 프롬프트에 추가하는 방식은 토큰 사용량 증가와 성능 저하를 초래할 수 있다.
- LLM의 유한한 컨텍스트 윈도우와 무한한 잠재적 정보 간의 갈등을 해결하기 위해 메모리 구축 기법이 제안되었으며, 요약을 통한 정보 압축과 조직화가 주요 전략이다.
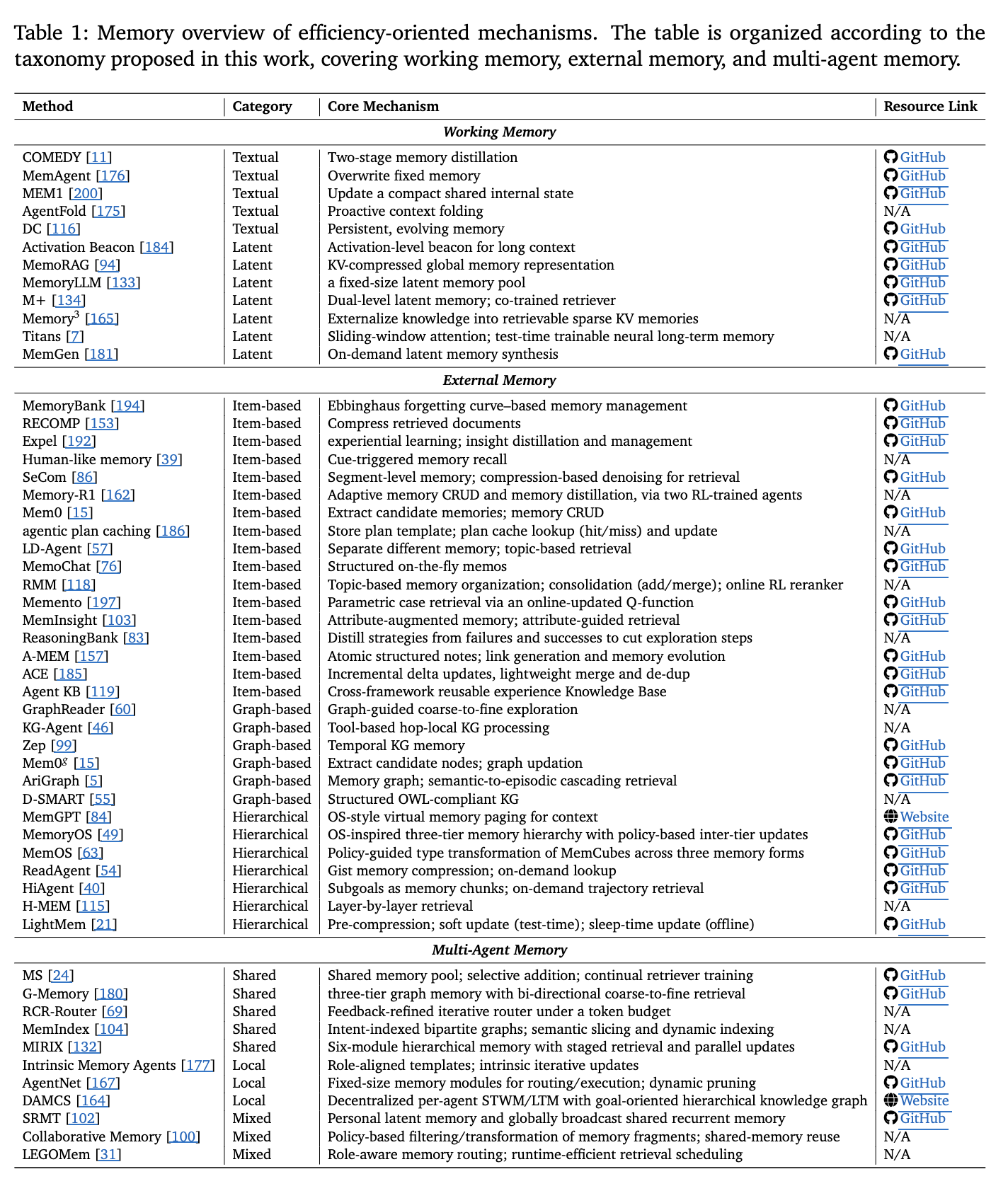
- 표 1은 작업 기반 메모리, 외부 메모리, 다중 에이전트 메모리로 분류된 효율성 중심 메커니즘을 정리한 것으로, 텍스트 기반 및 잠재 공간 기반 메모리 접근법을 포함한다.
- 다양한 연구는 메모리 업데이트, 압축, 주제 기반 조직화, 실시간 학습 등 다양한 방식으로 메모리 관리 및 검색 효율성을 향상시키는 방법을 제안하고 있다.
Summary
LLM-agent가 환경과 상호작용하여 얻은 정보를 어떻게/어떠한 형태로 저장할지 결정하는 step
External Memory: DB처럼 저장해두고, 필요하면 불러쓰는 메모리.
- Item-based, Graph-based, Hierarchical 로 구분됨.
- 방대한 memory를 저장할테니, 메모리 자체에 대한 내용보다 메모리들을 어떠한 구조로 정리할지도 같이 중요한 듯.
Working Memory: 작업에 관여하는 메모리, short-term.
- textual, latent memory로 구분.
Question
왜 memory를 “구축”해야 하나?
- 그냥 naive하게 context-window에 나열식으로 넣어버리면, token이 계속 소모되고, 결국 auto-regressive한 구조에서는 성능 bottleneck.
- 또한, long-context에 대해서는 Lost-in-the-middle 즉, 모델이 중간 맥락을 놓침.
3.1.1 Working Memory
Summary
- 워킹 메모리는 추론 시 직접적으로 사용되는 정보로, 텍스트 메모리와 라텐트 메모리로 구성되며, 텍스트 메모리는 프롬프트 내의 내용과 압축된 기억을 포함하고 라텐트 메모리는 KV 캐시, 은닉 상태 등 비토큰 형태의 신호로 표현된다.
- 텍스트 메모리 관리 기법으로는 COMEDY, MemAgent, AgentFold 등이 사용되며, 이들은 기억을 압축하거나 요약하여 문맥 길이를 줄이고 효율성을 높인다.
- 라텐트 메모리 기법은 Activation Beacon, MemoRAG, MemoryLLM 등이 대표적이며, 이들은 KV 공간에서의 압축, 외부 메모리 풀 통합, 신경 모듈 기반 학습을 통해 장기 정보를 효율적으로 처리한다.
- 이러한 방법들은 긴 상호작용 기록을 압축된 상태로 유지하고, 필요한 경우만 업데이트하여 정책에 노출시킴으로써 에이전트의 효율성을 향상시킨다.
Textual Memory
long-context를 보통 re-writting하거나 compressing 하는 전략을 사용.
- COMEDY: 2-staeg-distilation, LLM 사용해서 context summarization.
- 과거 대화에서 session별 memory를 추출한 후, key-event, user-profile, relationship changes를 중심으로 condensing.
- Fixed size state update :
- Proactive Context Folding :
- AgentFold: 이전 기록을 multi-scale summary로 만들어서 보관.
- multi-scale : AgentFold는 하나의 메모리를 가지는 데 그 메모리 내부에 다른 시간 압축도를 가진 것들이 공존. 어떤 component는 최근 step 하나만 압축된 게 있고, 어떠한 component는 5개 이상의 step이 하나로 압축된게 존재.
Latent Memory
context를 매번 다시 참조하지 않고, internal activation level에서 저장해두고 사용.
주로 압축의 대상들은 KV-cache, embedded-activation임.
방향은 세 가지 정도로,
- Compression in KV-space
- Activation Beacon : context chunking하고, beacon token을 삽입하게 한 다음, context의 KV를 beacon token에 압축되도록 distill 하여 저장. 압축이 완료되면, 원본 토큰의 KV는 폐기하고 beacon token에 대한 KV만 사용.
- MemoRAG : window 끝마다 memory token을 삽입하여 information carrier로 사용. 별도의 weight들을 사용해서 KV-activations를 memory token의 KV space로 distillation하여 이걸 전역 메모리 압축본으로 사용.(retrieval clue)
- External pool of latent memory & Attention injection
- MemoryLLM : fixed-size의 memory token pool을 유지하면서, 스스로 필요에 의해 update/retrieval한다.
- M+ : MemoryLLM의 확장판. cpu/gpu를 같이 사용하는 2-tier 장기기억 저장소를 구축.retriver를 같이 학습시켜, layer당 소수의 관련된 메모리 token만 가져올 수 있도록 설계.
- Memory3 : 모델이 context를 읽으면서 생성하는 KV 자체를 DB화하여 KnowledgeBase로 사용.
- Neural Learning Modules
아예 메모리를 담당하는 모듈을 만들자.
- Titans test-time에서 update할 수 있는 neural latent memory module.
- MemGen: latent memory를 RL-trained memory trigger와 weaver를 사용하여 만드는 방법.
Working Memory
- 외부에서 retrieval하는 과정이 없어, latency 측면에서 이득.
- context가 길어지면, memory를 많이 소비한다던지, 연산량이 느는 것은 여전함.
- textual은 일반적인 context 제한에서 logic-heavily 한 task에 적합하고, latent는 특별히 더 효율이 중요한 작업에서 좋다(token 재처리를 하지 않는).
Question
읽히는 흐름으로는 working 메모리는 구조 자체에 대한 고민은 잘 안하는 것 같음.(external-memory에 비해.)
- textual-memory는 뭔가 model이 이해를 잘하는 구조로 압축해야 하지 않을까?(단순 압축이 아니라.)
- 또, latent-memory 형식은 단순 embedding vector로만 표현되는데, 이게 하나의 단일 벡터로 표현되는 게 맞나? (Seq2Seq encoder에서 many-to-one으로 압축하는 부분이랑 맥락상으로 비슷할 수 도 있는데, 이 구조가 compression이니, 효율이 한계가 있을 것이라 예상됨.)
3.1.2 External Memory
Summary
외부 메모리는 문서 집합, 지식 그래프, RAG와 같은 검색 시스템에 저장된 토큰 수준의 정보로, 생성에 직접적으로 영향을 주지 않고 검색을 통해 프롬프트에 삽입된다. 항목 기반 메모리 시스템은 전체 경로나 경험을 저장하는 방식으로 인해 문맥 길이와 비효율성이 발생하지만, 메모리 추출, 압축, 요약 등의 방법을 통해 입력 토큰 소비를 줄이고 정보량을 유지하는 방식이 도입되고 있다. 구조화된 메모리 시스템은 주제 기반 메모리, 속성 부여된 메모리, 경험 라이브러리 등으로 구성되어 효율적인 검색과 정보 활용을 가능하게 하며, 그래프 기반 메모리 시스템은 장문의 텍스트나 지식 그래프 상호작용을 그래프 구조로 변환하여 다중 훅 증거를 효율적으로 관리한다.
Summary
외부에 지식을 저장하는 공간을 따로 만들어두고 거기서 필요할 때마다 가져다 쓰는 구조.
latent-form이 아니라, token-level 즉, 사람이 거의 읽을 수 있는 수준에 가깝게 정리해서 둠.pros :
- 외부 저장공간을 통한 무한한 지식 확장.
- 핵심만 검색하여 context overflow 방지.
cons:
- retrieval latency
- poor retrieval algorithm → noise detect
챗봇과 같은 방대한 량의 정보가 필요한 agent에 필수.
Item-based Memory
- MemoryBank: 일별 대화 기록을 저장하고, 사용자 profile과 같이 요약하여 저장해둠. 전체를 저장하다보니, high-token cost.
- Expel: MemoryBank과 같은 문제를 가지지만, 경험 자체가 아닌, trial & error에서 배우는 것을 distilation하여 natural-language형태로 저장.
이러한 시도에서 효율성을 찾아, memory-extraction, compress or summarization 등을 도입.- Human-like Memory: user dialogue에서 episodic memory를 뽑고, contents랑 context를 encapsulated해서 DB 구축.
- SeCom: long-term conversation을 segmentation을 해서 중요한 부분을 filtering하고, 압축해서, 나중에 효율적으로 불러올 수 있도록 구축.
- Memory-R1, Mem0: 중요 정보 추출하고 압축하여 사용.
- Memory-R1: 매 대화 턴마다 정보를 업데이트, 메모리에 대해 CRUD, distill을 수행.
- Mem0: 메세지 pair 단위로 처리. 최근 context랑 summarized된 내용 사용해서 저장.
- Agentic Plan Caching: 성공한 실행 로그를 plan으로 사용하여, 유사 작업 시 따로 Planning 대신, 그 log를 사용. 가벼운 LLM을 사용하여 log에서 noise를 제거하고, 추상화한 다음, 결과물을 (keyword, template)형태로 저장하여 cache.
- LD-agent: memory를 event/persona로 구분하여 저장.
- 단기 메모리에는 실시간 대화 맥락,
- 장기 메모리에는 페르소나와 요약된 event 정보를 저장해두어 사용.
- 한 세션이 끝난 후, extractor가 동작하여 session에서 persona, event를 압축하여 long-term memory에 저장.
Graph-based Memory
node & edge 형태로 메모리 구현.
동일한 entity에 대한 중복 언급을 하나의 node로만 처리하니, 중복을 쉽게 다룰 수 있어서 효율성 챙김.
multi-hop 추론에 꽤 적합한 구조.(edge를 타고 갈 수 있는 구조이니.)
- GraphReader : context를 chunking하고 key element랑 atomic fact로 구별하여 이걸로 graph를 그려 long-term dependencies, multi-hop reasoning에 강하게 만듦.
- KG-Agent: tool-call을 통해 얻은 entity-tools 간의 relation을 만들어서 task-specific subgraph 생성하여 사용.
- Zep: 시간 정보가 포함된 Knowledge Graph.
- Mem0g: new konwledge를 entity-related triplet으로 변환하여 DAG를 update.
- D-SMART: OWL(Web Ontology Language) 규격에 맞춘 Knowledge graph.
- AriGraph: Semantics knowledge, Episodic knowledge를 한 그래프로 처리.
Hierarchical Memory
계층적으로 메모리를 구성해서, 포괄적인 메모리에서 점차 세부적인 메모리로 접근할 수 있게 설계됨.
- System-oriented:
- OS의 메모리 관리에서 영감을 받아, 데이터 저장 위치와 계층을 정의하고 인터페이스를 구현해서 사용.
- MemGPT: 자주 쓰는 건, in-context형식으로 보관하고, 좀 덜 자주 사용하는 건 아카이브로 out-context 형태로 보관한다.
- MemoryOS: 계층을 short, mid, long으로 구분하여 사용함.
- MemOS(❓): MemCubes라는 표준 단위로 메모리 파편을 규격화해서, ??
- Content-oriented:
- information을 어떻게 요약하고 indexing할지 집중.
- ReadAgent: 문서를 페이지별로 나눈 뒤, 각 페이지를 짧은 Gist Memory(요약본)로 압축하여 필요할 때만 상세 내용을 찾아보게 함.
- HiAgent: 에이전트의 작업 과정을 Subgoals 단위로 요약하여 외부 메모리에 저장하고, 검색 시 이 요약을 가이드로 활용
- H-MEM: domain-category-memory trajectory-episode의 4단계 계층을 두어 점진적으로 최적화된 검색을 수행.
- LightMem: 입력된 데이터를 sensory → Short-term → Long-Term pipeline으로 처리, short-term을 주기적으로 요약해서 long-term으로 넘김.
Summary
- 외부 메모리는 모델 외부에 무제한의 장기 저장을 가능하게 하며, 타겟 리트리브를 통해 문맥 풀림을 줄이는 장점이 있다.
- 그러나 시스템 오버헤드와 리트리브 지연, 잡음 발생 등의 단점이 존재한다.
- 아이템 기반 메모리는 일반적인 장기 트래잭토리 에이전트에, 그래프 기반 메모리는 엔티티-관계 및 다중 훅 추론 작업에, 계층적 메모리는 초장기 역사나 대규모 문서에 필요한 조세-세부 리트리브에 적합하다.
3.2 Memory Management
Summary
- Human-like memory와 같은 일부 방법은 메모리 모듈에 새로운 기억을 지속적으로 추가하면서도 업데이트, 삭제, 병합과 같은 관리 작업을 수행하지 않아 메모리 공간이 급격히 증가하는 문제가 발생한다.
- 이로 인해 메모리 검색 또는 회상 속도가 현저히 저하되며, 이는 메모리 관리가 효율성에 매우 중요한 역할을 한다는 것을 보여준다.
- 따라서 메모리 관리 전략의 개발은 대규모 데이터 처리 시 필수적인 요소로 작용한다.
Summary
단순 memory를 stacking/concat하는 방식으로는 latency나 storage 문제가 있어, 정리하는 과정이 필요.
Manager: rule-based, LLM 혹은 hybrid 방식으로 누가 memory를 관리할지 정함.
Operations: DB 관리와 같이 CRUD와 비슷하게, Add, Update, Delete, No-op이 할 수 있는 연산.
- Retrieval만 memory access로 따로 구분.
3.2.1 Rule-based Management
Summary
- 규칙 기반 관리(Rule-based Management)는 사전 정의된 정적 규칙을 통해 메모리 업데이트, 제거, 병합을 수행하며, 메모리 크기 증가를 억제하고 비용 효율성을 제공한다.
- MemoryBank는 Ebbinghaus 이론을 기반으로 시간에 따라 메모리가 감쇠되도록 설계하고, 중요한 정보는 강화하며, H-MEM은 이를 확장해 사용자 피드백에 따른 동적 조절을 추가했다.
- A-MEM 실험 결과, 감쇠 곡선 기반 관리는 메모리 크기와 검색 시간을 줄이는 데 효과적이지만, 작업 성능 저하를 유발한다.
- FIFO 대체와 같은 트리거 기반 메모리 관리 전략도 사용되며, 이는 대규모 언어 모델(LLM) 기반 관리와 결합해 핵심 정보를 사전에 요약하거나 저장하는 방식으로 적용된다.
Summary
- 규칙 기반 관리의 주요 장점은 추가적인 LLM 호출 없이 빠르고 예측 가능한 저비용 메모리 관리가 가능하다는 점이다.
- 그러나 정적이고 작업에 무관한 규칙은 중요한 정보를 무심코 제거하거나 메모리의 수명을 줄여 정확도에 부정적인 영향을 줄 수 있다.
- 특히 정보 유지가 중요한 상황에서는 이러한 한계가 심각한 성능 저하로 이어질 수 있다.
Summary
Forgetting Curve based:
망각 곡선 개념 사용하여 오래된 기억을 잊게 함.
- MemoryBank : 처음으로 Ebbinghaus의 망각 곡선을 적용하여 오래된 기억에 패널티를 부과하여 덜 중요하게 처리되도록 함.
- H-MEM: 시간에 따른 기억퇴화 + user-feedback을 반영하여 긍정적 피드백을 받은 기억은 더 오래 유지되게 조절
- A-MEM:이 모델의 실험 결과로, 망각곡선 기반의 메모리 관리가 효율적이란 것을 증명. retrieval시간 감소, 메모리 효율적 제어라는 이점이 있지만, 동시에 단순히 시간만 가지고 정보를 잊게 하면, 중요 정보가 같이 지워질 수 있어, 성능이 심하게 저하될 수도 있다고 제언.
Trigger based memory maintenance
메모리 buffer가 다 차면 비우는 등 특정 조건에 기반하여 데이터 삭제 혹은 층위를 두어 관리하는 방법.
실전에서는 LLM-based management랑 같이 사용되는 경우가 흔함. →goto 3. 2. 3.LLM을 사용하지 않으니 경제적이나, 정보의 중요성이 고려되지 않은 방법이서 성능에 크게 문제가 될 수 있는 방법.
3.2.2 LLM-based Management
Summary
- LLM 기반 메모리 관리는 이산 작업 선택(ADD/DELETE 등)과 개방형 생성 두 가지 형태로 구분된다.
- 작업 선택 방식은 Memory-R1, Mem0, RMM 등이 기존 메모리에서 유사 항목을 검색한 후 ADD, UPDATE, DELETE 등의 작업을 선택해 업데이트하는 방식을 사용한다.
- 반면, A-MEM은 메모리 진화를 통해 유사 노트를 검색한 후 LLM이 직접 링크 생성 및 내용 수정을 통해 개방형 업데이트를 수행한다.
- ExpeL은 직접 목록 편집을 통해 ADD, EDIT, UPVOTE 등의 작업으로 오류 있는 통찰을 수정하거나 억제한다.
- 이들 접근법은 강화학습, 벡터 기반 검색, 생성형 업데이트 등 다양한 전략을 적용해 메모리 관리를 수행한다.
Summary
- LLM 기반 관리의 장점은 적응적이고 작업 인식적인 결정을 통해 가장 관련성 높은 정보를 유지하면서 효과적인 압축이나 병합을 가능하게 한다는 점이다.
- 단점으로는 관리 과정에서 추가적인 LLM 호출이 필요하여 계산 비용과 지연 시간이 증가한다.
Summary
LLM에게 CRUD 기능 모두 일임.
rule-based 보다는 작업 맥락을 반영하여 관리하니, adaptable하고 공간 효율적이지만, latency 및 연산량 수반.
Operation Selection
사전 정의된 CRUD 기능을 모델이 선택하여 하게 하는 방법. 전형적으로 많이 사용되었음.
- MEM0: 새로운 메세지에 대해 기존 memory에서 검색 후 add/delete 등을 할지 LLM이 결정하여 수행.
- Memory-R1: RL사용해서 같은 action selection을 잘하고 tune.
Open-ended Generation
memory 자체를 re-write하거나 summarize하는 방향으로 memory 관리.
A-MEM: 새로운 정보와 관련된 기존 memory node들을 검색하고 linking하거나 rewriting하여 memory update.
3.2.3 Hybrid Management
Summary
- 하이브리드 메모리 관리는 경량 규칙 기반 제어와 선택적 LLM 기반 작업을 결합하여 효율성과 효과성의 균형을 맞춘다.
- 계층별 관리(Tier-specific management): MemoryOS는 STM을 FIFO 페이지로 관리하고 MTM에서 Heat 점수로 제거/승격을 결정하며, LightMem은 센서리 버퍼가 가득 차면 토픽 분할을 트리거하고 온라인 소프트 업데이트와 오프라인 수면 시간 통합을 결합한다.
- 항목 수준 선택 및 정리(Item-level selection and pruning): Agent KB는 임베딩 유사도 임계값으로 중복을 줄이고 LLM 랭커로 더 나은 경험을 유지하며, ACE는 증분 델타 업데이트를 통해 불릿화된 컨텍스트를 유지하고 병합, 정리, 중복 제거를 수행한다.
- 수명 주기 정책(Lifecycle policies): MemOS는 MemCubes를 명시적 수명 주기 및 버전 추적으로 관리하며, 일반 텍스트 메모리, 활성화 메모리, 파라미터 메모리 간의 유형 인식 변환을 지원한다.
- 그래프 기반 메모리: Zep, Mem0g, AriGraph는 LLM이 의미적 충돌이나 오래된 내용을 판단하고, 규칙 기반 작업으로 그래프를 업데이트하는 유사한 패턴을 따른다.
Summary
- 하이브리드 관리의 장점은 저비용의 예측 가능한 규칙 기반 제어와 작업 인식적 LLM 결정을 균형 있게 결합하여, LLM을 필요할 때만 호출해 메모리를 효율적이고 관련성 있게 유지한다는 점이다.
- 단점으로는 계층 간 시스템 복잡성이 증가하고, 최적이 아닌 정책 상호작용이 발생할 수 있으며, LLM 호출 시 여전히 비용과 지연 시간이 추가된다.
Summary
Tier specific Management
Long, Mid, Short memory로 나누어 관리하되,
memory 등급을 바꾸거나, 데이터를 삭제하는 작업은 FIFO 같은 rule-based
요약 같은 중요 작업에 대해서는 LLM을 사용하는 방식.
MemGPT, MemoryOS, LightMem, MemoryOS
Item-level Selection and Pruning
단순한 중복 정보 처리는 embedding 유사도 기반과 같은 rule-based로 삭제하고,
해당 memory가 정말 도움이 되는지 혹은 모순이 있는지 판단하는 semantic decision은 LLM을 끼고 함.
Agent KB, ACE
Lifecycle & Graph Management
memory version 관리, archiving, 충돌 해결등을 metric 기반 정핵으로 자동화.
graph based memory에 대해서는 노드를 연결하는 구조적 작업은 rule-based로, node간 relationship의 타당도는 LLM으로 수행해서 그래프 자체의 일관성을 유지.
Pros:
- Cost and Latency가 위 두 방법의 elbow.
Cons:- policy가 복잡하여 policy 간 충돌의 위험 존재.
3.3 Memory Access
Summary
메모리 접근(Memory Access)은 대규모 메모리 뱅크에서 쿼리에 관련된 작은 부분집합만을 검색하고 사용하는 과정으로, 검색 지연 시간 및 토큰 비용과 다운스트림 생성 품질 간의 균형을 맞춘다. 이 섹션은 **메모리 선택(Memory Selection)**과 메모리 통합(Memory Integration) 두 가지 하위 주제로 구성된다.
Summary
query기반 indexing하여 반환할 정보를 찾아 반환.
- Retrieval: 방대한 memory 중 필요한 정보 검색.
- Integration: 검색된 memory를 LLM에 passing.
- 위에서 working memory의 구분에 따라 textual, latent integration으로 구분됨.
2 step으로 구성.
3.3.1 Memory Selection
Summary
- **메모리 선택(Memory Selection)**은 무엇을 검색할지와 어떻게 검색할지를 결정하며, 대부분의 방법은 쿼리와 컨텍스트를 임베딩으로 인코딩하고 유사도 검색으로 관련 정보를 선택하는 바닐라 검색을 따른다.
- 규칙 강화 검색(Rule-enhanced Retrieval): Generative Agents와 Human-like memory는 최근성과 경과 시간을 고려하고, Agent KB는 어휘 매칭과 의미 랭킹을 통합하며, LD-Agent는 의미 관련성, 명사 기반 토픽 겹침, 지수적 시간 감쇠를 결합한다.
- 그래프 기반 검색(Graph-based Retrieval): AriGraph와 Mem0g는 쿼리 관련 사실에 앵커를 걸고 이웃을 확장하여 로컬 서브그래프로 검색한다.
- LLM/도구 기반 검색(LLM or Tool-based Retrieval): MemGPT는 메모리 계층을 도구로 노출하고, GraphReader는 다양한 도구를 사전 정의하여 단계별로 메모리를 읽으며, D-SMART는 LLM이 그래프 작업을 선택하게 한다.
- 계층적 검색(Hierarchical Retrieval): HiAgent는 이전 서브목표의 세부 정보가 필요할 때 궤적을 회수하고, H-MEM은 각 메모리 임베딩이 다음 레이어의 관련 하위 메모리를 가리키며 재귀적으로 인덱싱한다.
- 학습 기반(Training): RMM은 온라인 RL로 학습 가능한 리랭커를 추가하고, Memento는 파라메트릭 Q-함수를 학습하여 과거 고보상 케이스를 선호한다.
Summary
적용 시나리오별 적합한 검색 방법:
- 규칙 강화 검색: 명확한 휴리스틱이나 제약이 있고 예산이 빠듯한 환경에 적합
- 그래프 기반 검색: 엔티티-관계 쿼리와 다중 홉 증거 연결에 적합
- LLM/도구 기반 검색: 정확성이 지연 시간보다 중요한 저빈도 고위험 쿼리에 적합
- 계층적 검색: 거칠게에서 세밀하게 조회가 필요한 매우 큰 메모리 뱅크에 적합
- 학습 기반 검색: 메모리 분포가 시간에 따라 변동하는 장기 실행 시스템에 적합
Memory Selection
**메모리 선택(Memory Selection)**은 무엇을 검색할지와 어떻게 검색할지를 결정하며, 대부분의 방법은 쿼리와 컨텍스트를 임베딩으로 인코딩하고 유사도 검색으로 관련 정보를 선택하는 바닐라 검색을 따른다.
적용 시나리오별 적합한 검색 방법:
- 규칙 강화 검색: 명확한 휴리스틱이나 제약이 있고 예산이 빠듯한 환경에 적합
- 그래프 기반 검색: 엔티티-관계 쿼리와 다중 홉 증거 연결에 적합
- LLM/도구 기반 검색: 정확성이 지연 시간보다 중요한 저빈도 고위험 쿼리에 적합
- 계층적 검색: 거칠게에서 세밀하게 조회가 필요한 매우 큰 메모리 뱅크에 적합
- 학습 기반 검색: 메모리 분포가 시간에 따라 변동하는 장기 실행 시스템에 적합
Rule-based Retrieval
규칙 강화 검색(Rule-enhanced Retrieval): Generative Agents와 Human-like memory는 최근성과 경과 시간을 고려하고, Agent KB는 어휘 매칭과 의미 랭킹을 통합하며, LD-Agent는 의미 관련성, 명사 기반 토픽 겹침, 지수적 시간 감쇠를 결합한다.
Graph-based Retrieval
그래프 기반 검색(Graph-based Retrieval):
- AriGraph와 Mem0g는 query 관련 facts에 앵커를 걸고 이웃을 확장하여 local sub-graph로 검색한다.
LLM or Tool-based Retrieval
LLM/도구 기반 검색(LLM or Tool-based Retrieval): MemGPT는 메모리 계층을 도구로 노출하고, GraphReader는 다양한 도구를 사전 정의하여 단계별로 메모리를 읽으며, D-SMART는 LLM이 그래프 작업을 선택하게 한다.
Hierarchical Retrieval
계층적 검색(Hierarchical Retrieval): HiAgent는 이전 서브목표의 세부 정보가 필요할 때 궤적을 회수하고, H-MEM은 각 메모리 임베딩이 다음 레이어의 관련 하위 메모리를 가리키며 재귀적으로 인덱싱한다.
Training
학습 기반(Training): RMM은 온라인 RL로 학습 가능한 리랭커를 추가하고, Memento는 파라메트릭 Q-함수를 학습하여 과거 고보상 케이스를 선호한다.
3.3.2 Memory Integration
Summary
- **메모리 통합(Memory Integration)**은 검색된 콘텐츠를 효율적으로 사용하는 방법을 결정하며, 필터링, 압축, 구조화된 삽입 기술을 활용하여 생성 중에 정보를 더 쉽고 저렴하게 사용할 수 있게 한다.
- 텍스트 통합(Textual Integration): DC-RS는 치트시트 저장소를 유지하고 유사도 기반 검색 후 컴팩트한 치트시트를 합성해 프롬프트에 삽입한다. Mem0은 메타데이터가 있는 짧은 자연어 레코드를 검색해 컴팩트한 메모리 블록으로 포맷팅하고, A-MEM은 Zettelkasten 스타일 노트로 상호작용 기록을 조직화하며, ACE는 세분화된 전략 불릿 라이브러리를 유지한다. RECOMP는 추출적 압축기와 추상적 압축기를 사용해 검색-압축-프리펜드 방식을 적용한다.
- 잠재 통합(Latent Integration): MemoryLLM은 모든 트랜스포머 레이어에 학습 가능한 메모리 토큰 풀을 삽입하고, M+는 CPU 상주 장기 메모리와 공동 학습된 검색기를 추가한다. Memory³는 KB를 명시적 키-값 메모리로 저장하고 디코딩 중 몇 개의 항목을 검색해 KV 캐시에 추가하며, MemoRAG는 긴 컨텍스트를 삽입된 메모리 토큰 위의 KV 캐시 전역 메모리로 압축한다.
Memory Integration
**메모리 통합(Memory Integration)**은 검색된 콘텐츠를 효율적으로 사용하는 방법을 결정하며, 필터링, 압축, 구조화된 삽입 기술을 활용하여 생성 중에 정보를 더 쉽고 저렴하게 사용할 수 있게 한다.
Textual Integration
텍스트 통합(Textual Integration): DC-RS는 치트시트 저장소를 유지하고 유사도 기반 검색 후 컴팩트한 치트시트를 합성해 프롬프트에 삽입한다. Mem0은 메타데이터가 있는 짧은 자연어 레코드를 검색해 컴팩트한 메모리 블록으로 포맷팅하고, A-MEM은 Zettelkasten 스타일 노트로 상호작용 기록을 조직화하며, ACE는 세분화된 전략 불릿 라이브러리를 유지한다. RECOMP는 추출적 압축기와 추상적 압축기를 사용해 검색-압축-프리펜드 방식을 적용한다.
Zettelkasten-like
하나의 메모에는 하나의 중요한 정보만.
이라는 철학.이러한 atomic한 정보를 graph로 시각화하고 사용해서 정보간 연결성을 활용하겠다는 의미.
Latent Integration
잠재 통합(Latent Integration): MemoryLLM은 모든 트랜스포머 레이어에 학습 가능한 메모리 토큰 풀을 삽입하고, M+는 CPU 상주 장기 메모리와 공동 학습된 검색기를 추가한다. Memory³는 KB를 명시적 키-값 메모리로 저장하고 디코딩 중 몇 개의 항목을 검색해 KV 캐시에 추가하며, MemoRAG는 긴 컨텍스트를 삽입된 메모리 토큰 위의 KV 캐시 전역 메모리로 압축한다.
3.4 Multi-Agent Memory
Summary
- LLM 기반 다중 에이전트 시스템(MAS)에서 초기 연구들(CAMEL 등)은 텍스트 통신 프로토콜에 초점을 맞추었으나, 최근 연구는 MAS에서의 메모리 개념에 명시적으로 집중하기 시작했다.
- 공유 메모리(Shared Memory): MS는 에이전트 단계를 Prompt-Answer 쌍으로 저장하고 LLM 평가자로 필터링한다. G-Memory는 다중 에이전트 경험을 3계층 그래프 계층으로 모델링하고, RCR-Router는 중요도 스코어러, 의미 필터, 토큰 예산 할당기로 라운드별 컨텍스트 라우팅을 수행한다. LatentMAS와 KVComm은 잠재 공유 메모리로 에이전트 간 컴팩트한 내부 상태 교환을 가능하게 한다.
- 로컬 메모리(Local Memory): Intrinsic Memory Agents는 역할 정렬 구조화 메모리 템플릿을 제공하고, AgentNet은 빈도, 최근성, 고유성 신호로 저유틸리티 궤적을 정리하며, DAMCS는 목표 지향 계층적 지식 그래프로 경험을 통합한다.
- 혼합 메모리(Mixed Memory): SRMT는 각 에이전트의 개인 메모리 벡터를 공유 순환 메모리와 결합하고, Collaborative Memory는 프라이빗/공유 계층의 동적 이분 접근 그래프를 사용하며, LEGOMem은 오케스트레이터를 위한 전체 작업 메모리와 작업 에이전트를 위한 하위 작업 메모리로 모듈형 절차적 메모리를 구축한다.
Multi-Agent Memory
LLM 기반 다중 에이전트 시스템(MAS)에서 초기 연구들(CAMEL 등)은 텍스트 통신 프로토콜에 초점을 맞추었으나, 최근 연구는 MAS에서의 메모리 개념에 명시적으로 집중하기 시작했다.
Shared Memory
공유 메모리(Shared Memory):
- MS는 에이전트 단계를 Prompt-Answer 쌍으로 저장하고 LLM 평가자로 필터링한다.
- G-Memory는 다중 에이전트 경험을 3계층 그래프 계층으로 모델링하고,
- RCR-Router는 중요도 스코어러, 의미 필터, 토큰 예산 할당기로 라운드별 컨텍스트 라우팅을 수행한다.
- LatentMAS와 KVComm은 잠재 공유 메모리로 에이전트 간 컴팩트한 내부 상태 교환을 가능하게 한다.
장점: 검증된 사실과 결정을 에이전트 간에 재사용할 수 있어 중복 작업과 재시도를 줄여 조정과 효율성을 향상시킨다.
단점: 동시 쓰기로 인한 불일치가 발생하기 쉽고, 통합과 접근 제어 없이는 노이즈가 많아지고 검색 비용이 높아질 수 있다.
Local Memory
로컬 메모리(Local Memory): Intrinsic Memory Agents는 역할 정렬 구조화 메모리 템플릿을 제공하고, AgentNet은 빈도, 최근성, 고유성 신호로 저유틸리티 궤적을 정리하며, DAMCS는 목표 지향 계층적 지식 그래프로 경험을 통합한다.
장점: 경량의 저노이즈 에이전트별 작업 공간으로 효율적인 검색과 역할별 프롬프팅을 지원한다.
단점: 에이전트 간에 공유되지 않아 유용한 결과가 전파되지 않을 수 있고 작업이 중복될 수 있다.
Mixed Memory
혼합 메모리(Mixed Memory):
- SRMT는 각 에이전트의 개인 메모리 벡터를 공유 순환 메모리와 결합하고,
- Collaborative Memory는 프라이빗/공유 계층의 동적 이분 접근 그래프를 사용하며,
- LEGOMem은 오케스트레이터를 위한 전체 작업 메모리와 작업 에이전트를 위한 하위 작업 메모리로 모듈형 절차적 메모리를 구축한다.
장점: 효율적인 에이전트별 로컬 상태와 공유 메모리를 통한 에이전트 간 지식 재사용을 결합하여 전문화와 조정 모두를 향상시킨다.
단점: 동기화 및 라우팅 복잡성이 추가되며, 공유 저장소에서 불일치나 노이즈가 여전히 발생할 수 있다.
3.5 Discussion
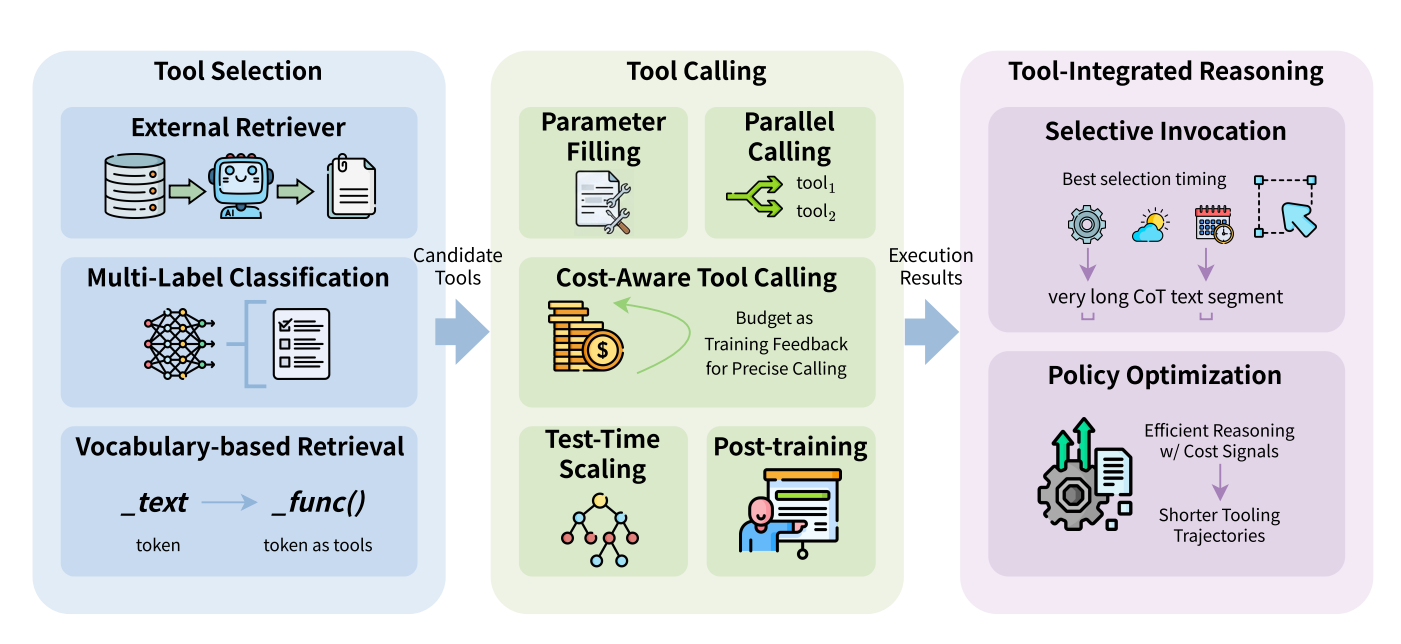
Figure 4: Efficient tool learning comprises three stages: Tool Selection identifies candidate tools via retrieval or classification; Tool Calling handles parameter filling and execution with a focus on cost-aware constraints and budget feedback and Tool-Integrated Reasoning optimizes efficient reasoning trajectories through selective invocation and policy optimization.
Summary
메모리 압축과 성능 간의 trade-off: 메모리 추출은 입력 토큰 사용량 같은 비용을 줄일 수 있지만, 중요한 정보 손실로 에이전트 성능이 저하될 수 있다. LightMem의 실험 결과는 과도한 압축이 정확도를 낮추고, 완만한 압축이 성능을 더 잘 유지하지만 비용이 높아짐을 보여준다.
온라인 vs 오프라인 메모리 관리:
- A-MEM은 상호작용 중 동기적으로 메모리를 업데이트하는 순수 온라인 시스템이지만,
- MemoryOS가 보여주듯 실시간 업데이트는 응답당 빈번한 LLM 호출로 높은 지연 시간과 비용을 초래한다.
- 반면 LightMem은 경량 온라인 캐시와 오프라인 통합을 결합하는 하이브리드 아키텍처를 채택하여 추론 시간을 크게 줄인다. 온라인 업데이트는 즉각적 적응을 보장하지만 지연과 비용이 증가하고, 오프라인 업데이트는 추론 오버헤드를 최소화하지만 느린 적응을 감수해야 한다.
4 Efficient Tool Learning
Summary
LLM을 두뇌처럼 사용한다고 했을 때, env와 직접적으로 상호작용할 수 있도록 팔, 다리 역할을 해줄 수 있는 tool들을 붙여주어야 agent처럼 쓸 수 있고, 문제는 어떻게 LLM에게 스스로 어떠한 tool을 사용할지 학습시킬 수 있는지이다. 또한, 복잡한 추론 task에서는 여러 번의 tool call이 바로 비용과 직결된 문제이기에 최적화가 필요한 부분이다.
Tool-Learning은 다음의 두 관점에서 시스템 전체의 효율성과 연관이 있는데,
- CoT와 비교시, 복잡한 추론 문제에서 시간적 이득을 가져갈 수 있다. 복잡한 문제에서는 CoT가 길어져서 연산 자원 및 시간이 소비되는데, 적절한 tool을 사용할 수 있다면, 그 시간을 호출함으로써, 도구 실행 결과로 대체할 수 있어 경제적.
- 더불어서, tool-calling 자체의 최적화도 고려되어야 한다. 불필요한 반복적인 호출을 줄일 수 있는 방향으로 개발되어야 하며, 최적의 호출 전략을 수립할 필요성이 있다. (시점, 횟수,비용)
4.1 Tool Selection
Summary
사용할 수 있는 도구들은 너무 많은텐데, 그걸 다 prompt에 넣을 수는 없다. 따라서 아래와 같은 세가지 방법들이 제안되어 왔다.
장점: 외부 검색기, MLC, 어휘 기반 방법 모두 대규모 후보에서의 검색에 매우 효율적이다. 외부 검색기는 미지의 도구에 대한 좋은 일반화 능력을 가진 플러그 앤 플레이 모듈이 될 수 있다.
단점: 외부 검색기는 MLC 및 어휘 기반 도구 토큰보다 더 많은 계산 오버헤드를 가진 대형 모델일 수 있으며, MLC 및 어휘 기반 도구 검색은 새 도구에 적응하기 위해 파인튜닝이 필요할 수 있다.
적용 시나리오: 후보 풀이 시간에 따라 많이 변하면 외부 검색기를 사용하는 것이 좋고, 후보 도구 집합이 비교적 고정되어 있으면 MLC 및 어휘 기반 방법이 더 나은 효율성을 위한 좋은 옵션이다.
External Retriever
user의 query를 각 도구에 매칭시켜주는 별개의 모델, retreiver를 사용하는 방식.
- Retriever-side Advance
- ProTIP: Contrastive Learning을 사용해서, query랑 tool-description을 같은 lantent-space에 embedding해서 cosine-similarity 기반의 도구 산출. 여러 복잡한 쿼리라면, query embedding에서 순차적으로 선택해 나아간 tool들의 embedding을 뺴면서 나머지 tool들을 선택해 나아가는 방식.
- AnyTool: divide-and-conquer과 비슷하게, tool-search를 계층적으로 진행.
- Tool-side Advance
- tool-description이나 문서를 최적화하여 retriever가 더 잘 tool-searching을 할 수 있도록 support.
- DRAFT : 기존에 적힌 description을 바탕으로 trial and error 방식으로 결과를 반영하여 description을 수정해나가는 방식. (성공 여부, log, return-value 등)
- Hybrid
- Toolshed: tool KnowledgeBase를 구축한 다음, RAG-tool fusion을 사용해서 top-k개의 도구를 선택.
- ToolScope: ToolScopeMerger를 사용해서 tool-description을 압축하여서 가용가능한 context-window를 확보하자는 전략.
Multi-Label Classification
tool-selection을 classification 문제로 해석하여 고정된 tool-set에 대해 소형 모델(DeBERTa)등을 사용해 도구 classification
fixed-set tools에 대한 classification이니 tool expand 되면 그때마다 selcetion-model을 재 학습시켜야 하는 번거로움이 존재.
Vocaulary-based Retrieval
어휘 기반 검색(Vocabulary-based Retrieval): ToolkenGPT는 대규모 외부 도구를 학습 가능한 토큰 임베딩(“toolken”)으로 간주하여 다음 토큰 예측으로 도구를 선택한다. Toolken+는 리랭킹 단계와 거부 toolken을 추가하고, ToolGen은 각 도구에 고유 토큰을 할당한다. CoTools는 toolken 수를 하나로 줄이고 검색기로 유사도를 계산한다.
4.2 Tool Calling
Summary
**도구 호출(Tool Calling)**은 후보가 선택된 후 실시간 에이전트 상호작용을 위해 호출 프로세스의 효율성이 중요해진다.
- 인플레이스 파라미터 채우기(In-Place Parameter Filling): Toolformer는 CoT 경로 내에서 도구 호출을 통합하고 응답 생성 중에 파라미터를 채운다. CoA는 중간 단계를 나타내는 기호적 추상화를 도입하여 Toolformer보다 30% 이상 추론 시간을 줄인다.
- 병렬 도구 호출(Parallel Tool Calling): LLMCompiler는 컴파일러 영감 프레임워크로 실행 계획을 공식화하고 함수를 병렬로 실행한다. LLM-Tool Compiler는 유사한 도구 작업을 런타임에 융합하고, CATP-LLM은 비용 인식을 계획 프로세스에 통합한다.
- 비용 인식 도구 호출(Cost-Aware Tool Calling): BTP는 도구 호출을 배낭 문제로 공식화하고, TROVE는 재사용 가능한 함수의 컴팩트한 도구 상자를 점진적으로 구축하며, ToolCoder는 도구 학습을 엔드투엔드 코드 생성 작업으로 공식화한다.
- 효율적인 테스트 시간 스케일링: ToolChain는 A 검색 전략을 활용하여 작업별 비용 함수로 잘못된 분기를 일찍 정리한다.
- 사후 학습을 통한 효율적인 도구 호출: OTC-PO는 도구 사용 패널티를 RL 목표에 통합하고, ToolOrchestra는 효율성 인식 보상으로 특수 오케스트레이터를 훈련한다.
Summary
장점: 위의 도구 호출 방법들은 서로 다른 측면에 초점을 맞추며 더 나은 효율성을 위해 동시에 적용할 수 있다. 하나의 궤적에 대해 인플레이스 파라미터 채우기, 비용 인식 도구 호출, 테스트 시간 스케일링, 비용 보상이 있는 사후 훈련이 효율성 향상에 효과적이며, 병렬 도구 호출은 하나의 궤적을 여러 분기로 분할하여 병렬로 호출을 완료할 수 있다.
단점: 테스트 시간 스케일링이 도구 호출 정확도를 향상시키고 궤적 길이를 줄일 수 있지만, 여전히 효능과 효율성 간의 트레이드오프가 존재한다. 또한 병렬 도구 호출은 병렬 작업 계획자가 작업 종속성을 찾지 못하면 반복적인 정제가 필요할 수 있다.
적용 시나리오: 에이전트가 계획-행동-반영 모드에서 전체 도구 호출 궤적을 계획하면 병렬 도구 호출이 분기를 미리 분할하는 데 적합하다. 비용 인식 도구 호출과 사후 훈련 방법은 도구 호출 횟수를 줄이는 좋은 전략이다. 효율적인 테스트 시간 스케일링은 정확한 궤적을 생성하여 증류에 적용 가능한 전략이다.
4.3 Tool-Integrated Reasoning
Summary
- **도구 통합 추론(Tool-Integrated Reasoning, TIR)**은 정적 내부 지식 의존에서 적응적 다중 턴 추론으로의 전환을 나타내며, 복잡한 문제 해결에서 높은 정확도와 계산 효율성 모두에 필요하다.
- 선택적 호출(Selective Invocation): TableMind는 도구 증강 테이블 추론을 위한 자율 프로그래매틱 에이전트로 반복적 계획-행동-반영 루프를 사용하며, SFT 워밍업 후 RL을 적용한다. SMART는 각 도구 호출의 필요성을 상세히 기술하는 CoT 데이터셋을 구축하고, Agent-FLAN은 에이전트 데이터를 능력별 하위 집합으로 분해하여 더 적은 훈련 토큰으로 성능을 향상시킨다.
- 비용 인식 정책 최적화(Cost-Aware Policy Optimization): TableMind는 RAPO 알고리즘으로 고품질 궤적을 우선시하고, ARTIST는 결과 기반 RL로 에이전트 추론을 결합하며, ReTool은 코드 인터프리터를 추론 루프에 직접 통합하고, ToolRL은 형식 보상과 정확성 보상을 결합한 보상 함수를 설계한다.
- 불필요한 도구 호출 최소화: A²FM은 적응형 정책 최적화로 즉시 답변할지 도구를 호출할지 결정하고, IKEA는 내부 지식에 먼저 의존하도록 적응형 검색 에이전트를 훈련하며, AutoTIR은 특정 보상 패널티로 불필요한 도구 사용을 억제하고, PORTool은 감쇠 인자로 최종 결과에 가까운 단계를 강조한다.
Summary
장점: 도구 통합 추론 전략은 도구 호출을 긴 추론 경로에 통합하여 작업 정확도를 높인다. 적절한 타이밍에 도구를 호출함으로써 TIR은 전체 훈련 샘플을 줄이는 데 매우 데이터 효율적이다.
단점: 특정 도구는 특수 환경이 필요하여 시스템 설계가 복잡해진다. 예를 들어, 코딩 에이전트는 생성된 코드를 검증하기 위해 샌드박스 환경이 필요하여 상당한 개발 복잡성을 초래한다.
적용 시나리오: 외부 리소스(브라우저, 검색 API, 코드 인터프리터 등)를 호출해야 하는 복잡한 작업에는 TIR이 다중 홉 추론으로 실제 환경과 상호작용하여 작업을 수행하는 좋은 선택이다. 모델의 내부 지식에 주로 의존하는 단순한 작업의 경우 TIR은 덜 효율적이고 추가적인 도구 호출 비용이 발생할 수 있다.
4.4 Discussion
Summary
- 효율적인 도구 사용의 진화는 단순히 도구 사용을 “가능하게” 하는 것에서 상호작용 루프를 “최적화”하는 것으로의 근본적인 전환을 반영한다.
- 효율적인 선택 및 호출 기술(검색, 병렬화 등)은 대규모 도구 집합의 구조적 병목 현상과 순차적 지연을 해결하는 반면, 도구 통합 추론은 에이전트의 의사결정 프로세스의 전략적 오버헤드를 대상으로 한다.
- 이 분야의 최전선은 성능과 비용의 파레토 최적화로 이동하고 있다: 정확도를 위해 도구 사용을 최대화하는 대신, 현대 에이전트들은 중복된 상호작용을 최소화하도록 RL을 통해 점점 더 훈련되고 있다.
- 미래의 효율성 향상은 모델의 내부 추론과 외부 도구 환경 간의 더 긴밀한 결합에서 비롯될 것이며, “행동”은 더 이상 별도의 단계가 아니라 모델의 인지 아키텍처의 통합된 비용 인식 구성 요소가 될 것이다.
5 Efficient Planning
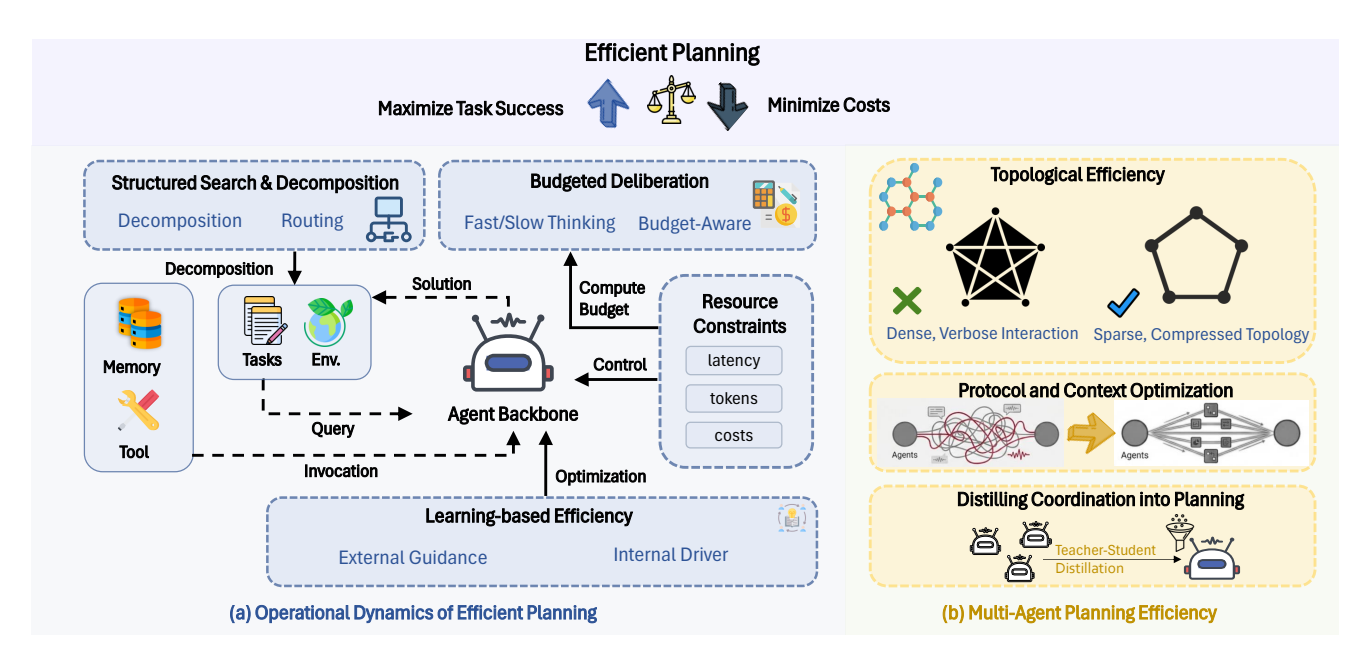
Figure 5: Overview of Efficient Planning. It aims to maximize task success while minimizing costs. (a) Single-agent methods optimize inference strategies (control, search, decomposition) or evolve via learning (policy, memory). (b) Multi-agent methods reduce overhead via topological optimization, context optimization, and coordination distillation.
Summary
- **효율적인 계획(Efficient Planning)**은 숙고를 무한한 추론이 아닌 자원 제약 제어 문제로 프레이밍하며, 단일 에이전트 추론의 깊이(검색 및 학습을 통해)와 다중 에이전트 협업의 폭(토폴로지 및 프로토콜을 통해)을 최적화한다.
- 목표: 지연 시간, 토큰 소비, 통신 오버헤드에 대한 제약 조건 하에서 작업 성공을 최대화한다.
- 이 관점은 풍부한 계산 자원을 가정하는 고전적 계획과 계획을 직접 텍스트 생성과 혼동하는 현대적 접근법과 구별된다. 효율적인 계획은 추론을 운영 제어로 개념화하여 에이전트가 정제된 계획의 한계 효용과 계산 비용 간의 균형을 지속적으로 맞춰야 한다.
- 그림 5에 따르면: (a) 단일 에이전트 방법은 추론 전략(제어, 검색, 분해)을 최적화하거나 학습(정책, 메모리)을 통해 진화하고, (b) 다중 에이전트 방법은 토폴로지 최적화, 컨텍스트 최적화, 조정 증류를 통해 오버헤드를 줄인다.
Summary
핵심 철학: deliberation을 무한한 inference가 아닌 자원 제약 제어 문제로 프레이밍
메커니즘: 단일 에이전트 추론의 깊이(검색 및 학습)와 다중 에이전트 협업의 폭(토폴로지 및 프로토콜)을 최적화
목표: 지연 시간, 토큰 소비, 통신 오버헤드 제약 하에서 작업 성공 최대화
5.1 Single-Agent Planning Efficiency
Summary
단일 에이전트 효율성은 유효한 솔루션에 도달하는 데 필요한 계산 비용(토큰, 지연 시간, 검색 단계)을 최소화하는 데 초점을 맞추며, 추론 시간 전략과 학습 기반 진화로 분류된다.
- Inference Strategy I - Adaptive Budgeting and Control:
- SwiftSage는 빠른 행동과 느린 계획을 분리하고,
- Reflexion과 ReST는 언어적 강화나 반복적 정제로 실패 분석을 상환하여 누적 상호작용 비용을 낮춘다.
- Inference Strategy II - Structured Search:
- LATS는 에이전트 롤아웃을 MCTS로 재프레이밍하고,
- CATS는 비용 인식을 검색 트리에 직접 통합하며,
- ToolChain는 A-star search를 사용한다.
- Inference Strategy III - Task Decomposition:
- ReWOO와 Alita는 계획과 실행을 분리하고,
- HuggingGPT와 ReSo는 하위 작업을 특수 모델에 라우팅하며,
- BudgetMLAgent는 비용을 위해 에이전트 라우팅을 최적화한다.
- Learning-Based Evolution - Policy Optimization:
- QLASS는 Q-값 비평가로 플래너를 안내하고,
- ETO는 시행착오 선호 학습(DPO)으로 정책을 정제하며,
- RLTR과 Planner-R1은 프로세스 수준 보상을 활용한다.
- Learning-Based Evolution - Memory and Skill Acquisition:
VOYAGER는 재계획을 피하기 위해 재사용 가능한 스킬 라이브러리를 구축하고,
GAP는 병렬화 가능한 액션을 식별한다.
장점: 적응형 제어는 추론 비용을 낮추고, 구조화된 검색은 탐색 효율성을 향상시키며, 작업 분해는 단계별 중복과 컨텍스트 오버헤드를 줄이고, 학습 기반 진화는 시간에 따라 계획 비용을 상환한다.
단점: 적응형 제어는 오작동할 수 있고, 구조화된 검색은 오버헤드를 도입하며, 작업 분해는 오류 전파 위험이 있고, 학습과 메모리는 훈련 및 유지 비용을 추가한다.
5.2 Multi-Agent Collaborative Efficiency
Summary
- 다중 에이전트 협업 효율성은 향상된 추론을 제공하지만 종종 이차 통신 비용이 발생하므로, 상호작용의 토폴로지와 프로토콜의 내용을 최적화하는 데 초점을 맞춘다.
- 토폴로지 효율성 및 희소화: Chain-of-Agents와 MacNet은 컨텍스트 성장을 거의 선형 복잡도로 제한하고, GroupDebate는 밀집 토론과 희소 요약을 번갈아 사용한다. AgentPrune, AgentDropout, SafeSieve는 저유틸리티 엣지를 동적으로 정리하거나 추론 중 그래프를 점진적으로 희소화한다.
- 프로토콜 및 컨텍스트 최적화: CodeAgents는 추론을 간결한 의사코드로 인코딩하고, Smurfs는 실패한 검색 분기를 버려 컨텍스트 비대화를 방지한다. Free-MAD와 ConsensAgent는 비판적 추론을 장려하는 프롬프트를 엔지니어링하고, SMAS는 중복 루프를 조기에 종료한다.
- 계획에 조정 증류: MAGDI와 SMAGDi는 복잡한 상호작용 그래프나 “소크라틱” 분해를 단일 학생 모델로 증류하고, D&R은 교사-학생 토론을 사용하여 DPO용 선호 트리를 생성한다. 이러한 접근법은 다양한 관점의 품질 이점을 유지하면서 단일 에이전트의 낮은 추론 비용으로 복귀한다.
장점: 토폴로지 희소화는 통신 비용을 줄이고, 프로토콜 압축은 컨텍스트 비대화를 방지하며, 조정 증류는 품질을 유지하면서 추론 비용을 낮춘다.
단점: 정리는 유용한 신호를 삭제할 수 있고, 압축은 핵심 세부 사항을 잃을 수 있으며, 증류는 훈련 비용을 추가하고 추론 시 다양성을 약화시킬 수 있다.
5.3 Discussion
Summary
- 효율적인 에이전트 계획은 추론을 무한한 생성 프로세스에서 예산 인식 제어 문제로 재프레이밍한다.
- 단일 에이전트 체제에서는 적응형 예산 책정부터 구조화된 검색까지의 추론 시간 전략과 정책 정제 및 스킬 메모리를 통해 비용을 상환하는 학습 기반 진화의 명확한 분류 체계가 관찰된다.
- 다중 에이전트 체제에서는 토폴로지 정리와 집단 지능의 증류에 초점이 맞춰진다.
- 두 체제 모두에서 통합 추세는 계산을 온라인 검색에서 오프라인 학습 또는 구조화된 검색으로 마이그레이션하여 에이전트가 엄격한 자원 제약 내에서 복잡한 목표를 달성할 수 있게 하는 것이다.
6 Benchmarks
Summary
이 서베이는 효율성에 초점을 맞추지만 effectiveness-first view을 채택.
즉, 저렴하지만 작업을 해결하지 못하거나 솔루션 품질을 크게 저해하는 방법은 의미 없다고 판단.
효율성을 두 가지 보완적 방식으로 특성화해서 봄.
- 고정된 비용 예산 하에서 효과성 비교
- 유사한 효과성 수준에서 비용 비교.
6.1 Memory
Summary
effectiveness benchmark:
크게 두 가지 축으로,
- 다운스트림 end-to-end 작업 성공(HotpotQA, Natural Questions, GAIA 등)을 통해 간접적으로
- 또는 memory task(LoCoMo, LongMemEval)을 통해 직접적으로 평가된다.
efficieny benchmark:
- Evo-Memory는 step-efficiency(몇 step만에 goal에 도달?)을 도입하고
- StoryBench는 run-time cost과 token consumption를 보고하며,
- MemBench는 read time과 write time(memory task per second)을 보고한다.
efficiency metric 분류:
- 토큰 소비 및 API 비용 - 토큰 사용량을 USD로 변환,
- 시간 기반 메트릭 - total run-time, end-too-end consumption time, search time 등,
- 자원 기반 메트릭 - GPU 메모리 사용량 등,
- 상호작용 기반 메트릭 - 응답당 평균 LLM 호출 수, 추론 단계 수 등.
6.2 Tool Learning
Summary
tool-learning은 아직 통일된 efficiency 벤치마크가 부족하며, 대부분의 평가는 effectiveness(효과성)를 우선시한다. 그러나 도구 사용은 종종 상호작용 비용을 지배하고 end-to-end 성공을 주도하므로 LLM 에이전트에 중요하다.
Benchmarks for Selection & Parameter Infilling:
- Seal-Tools는 대규모 도구와 사용 사례를 효율적으로 생성하고,
- MetaTool은 도구 사용 여부와 선택 결정 과정에 초점을 맞추며,
- BFCL과 API-Bank는 실제 응용 도구와 다중 턴 대화를 포함한다.
- NesTools는 중첩 도구 학습을 분류하고,
- ToolBench는 RapidAPI에서 16,000개 이상의 API를 수집한다.
- T-Eval은 계획, 추론, 검색을 포함한 6개 구성 능력으로 도구 활용을 분해하여 세분화된 벤치마크를 도입한다.
Tool-Learning with MCP(Model Context Protocol):
- MCP-RADAR는 도구 선택 효율성, 계산 자원 효율성, 실행 속도를 명시적으로 평가하고,
- MCP-Bench는 병렬성과 효율성 기준으로 에이전트 효율성을 평가한다.
Agentic Tool-Learning: SimpleQA는 사실적으로 정확한 짧은 답변 제공 능력을 평가하고, BrowseComp는 모델의 내부 지식으로 답변하기 어려운 도전적 질문을 생성하며, SealQA는 웹 검색 결과가 충돌하거나 노이즈가 많거나 도움이 되지 않는 사실 추구 질문을 평가한다.
6.3 Planning
Summary
Effectiveness Benchmark:
- 계획 효과성은 SWE-Bench, WebArena, WebShop 같은 에이전트 벤치마크에서 다운스트림 작업 성공을 통해 간접적으로 평가된다.
- PlanBench는 계획 효율성 평가를 도입했지만, 대부분의 기존 벤치마크는 순수 LLM 설정에 초점을 맞춰 LLM 기반 에이전트에 직접 적용하기 어렵다.
Efficiency Benchmark:
- Blocksworld 기반 벤치마크는 end-to-end 실행 시간, 계획 시도 횟수, 토큰 소비, 금전적 비용을 보고한다.
- TPS-Bench는 토큰 사용량, 엔드투엔드 시간, 도구 호출 턴을 사용하고, cost-of-pass(성공적 완료당 예상 금전적 비용)를 제안한다.
- CostBench는 동적 변화 하에서 비용 최적 도구 사용 계획을 벤치마킹하고 Cost Gap과 정답 궤적으로부터의 경로 편차로 효율성을 평가한다.
Efficiency Metrics in Planning Methods:
- 토큰 소비와 런타임 외에도, 검색 깊이와 폭 관점에서 SwiftSage는 시간 단계를,
- Reflexion은 시도 횟수를,
- LATS는 성공에 필요한 최저 평균 노드/상태 수를,
- CATS는 유효한 솔루션을 찾는 데 필요한 평균 반복 횟수를 보고한다.
- cost-of-pass 스타일 메트릭도 채택되고 있다.
7 Challenges and Future Directions
Summary
- Towards a unified efficiency evaluation framework for agent memory: 기존 방법과 벤치마크는 서로 다른 차원의 하위 집합과 이질적인 용어를 사용하여 메모리 효율성을 정량화한다. 토큰 기반 메트릭도 쿼리당, 메모리 작업당, 에피소드당 또는 메모리 저장소 구축용으로 정의될 수 있어 기존 효율성 수치를 논문 간에 직접 비교하기 어렵다.
- 에이전트 잠재 추론(Agentic Latent Reasoning): 중간 계산이 자연어 토큰이 아닌 연속적인 숨겨진 표현에서 수행되는 잠재 공간 추론에 대한 관심이 증가하고 있다. 잠재 추론은 토큰 오버헤드를 줄이고 다단계 계산 중 더 풍부한 고차원 정보를 보존할 수 있지만, 에이전트 시나리오의 추가 요구사항(도구 사용, 장기 계획, 메모리 관리, 행동 검증)은 아직 탐구되지 않았다.
- 배포 인식 에이전트 설계(Deployment-Aware Agentic Design): 다중 에이전트 설계는 진정한 다중 모델 배포 또는 단일 모델 역할극 파이프라인으로 실현될 수 있으며, 이러한 구현은 조정 오버헤드, 지연 시간, 신뢰성에서 크게 다르다. 미래 연구는 일치된 자원 예산 하에서 이러한 대안을 비교해야 한다.
- Efficiency Challlange and Directions for MLLM-baed Agents: 멀티모달 메모리, 계획 및 의사결정 향상, 다중 에이전트 시스템을 포함한 MLLM 기반 에이전트 방법이 빠르게 등장하고 있지만, 효율성은 상대적으로 탐구되지 않았다. 장기 멀티모달 작업은 시각적 기록 유지가 필요하여 메모리 유지와 추론 속도 간의 트레이드오프가 LLM 기반 에이전트보다 훨씬 심각하다.
8 Conclusion
Summary
- 본 서베이는 LLM에서 LLM 기반 에이전트로의 진화를 요약하고, 점점 더 복잡해지는 설정으로의 전환을 강조한다.
- 효율성에 중점을 두고 세 가지 핵심 구성 요소인 memory, tool-learning, planning을 검토하며, 겉보기에 다른 많은 방법들이 공유된 고수준 아이디어로 수렴됨을 발견했다.
- 효율성 지향 벤치마크와 벤치마크 및 방법론적 연구 전반에서 일반적으로 사용되는 메트릭을 요약한다.
- 핵심 과제와 미래 방향을 개요하며, 공정한 비교와 재현성을 가능하게 하기 위한 더 표준화되고 투명한 보고의 필요성을 강조한다.