
Summary
에이전트가 긴 multi-turn task에서 constant memory로 작동할 수 있도록 하는 end-to-end RL framework인 MEM1을 제안.
을 사용해서 턴이 진행될 때마다 그 내부 정보를 업데이트 및 압축하며 메모리로 동작하도록 구성. 즉, textual memory. 이 token 사이 정보를 이전 context를 대체하는 용도로 사용해서 이전 context는 discard. 따라서 information loss가 좀 치명적임.따라서 ‘잘’ 즉, 이후 행동을 위해 필요한 내용들까지 포함해서 IS token 사이에 잘 압축하기 위해 RL을 사용하여 최종 리워드가 높아지는 방식으로 압축되게 유도.
agentic이라기 보단, LLM에 해서 IS라는 special token의 기능을 추가했다고 보는 게 맞을 듯.
단순 RL, PPO랑 REINFORCE++ 사용했다고 함.
by Moonlight
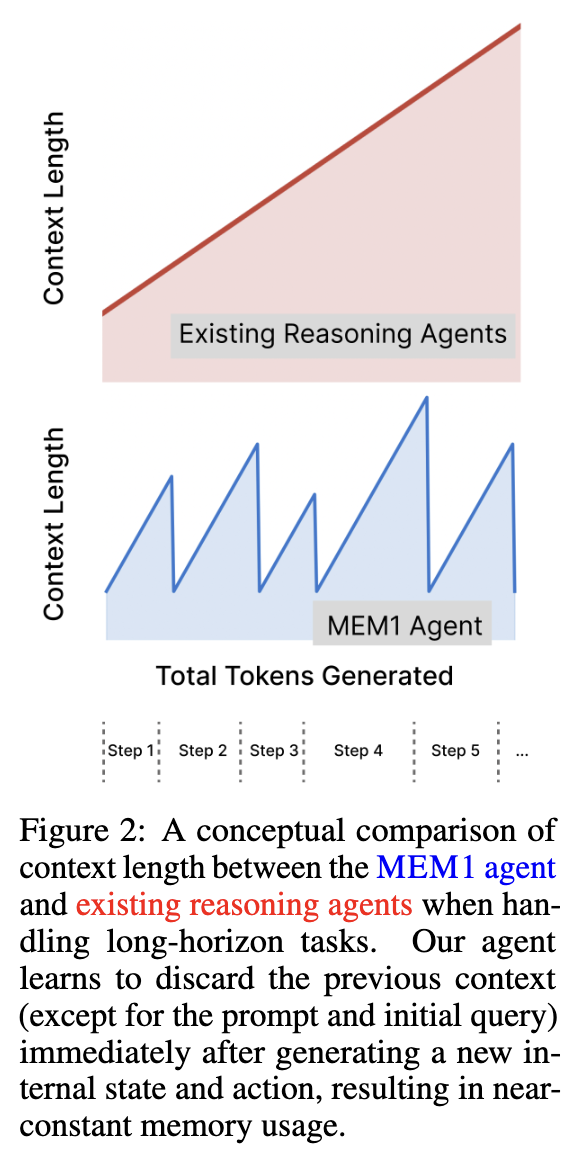
- MEM1은 장기 상호작용 LLM 에이전트의 무한한 컨텍스트 증가 문제를 해결하기 위해, 추론과 메모리 통합을 통해 일정한 크기의 내부 상태를 유지하는 강화 학습(RL) 프레임워크입니다.
- ✨ 이 프레임워크는 각 턴마다 이전 컨텍스트를 제거하고 새로운 관찰을 통합하여 내부 상태()를 업데이트하며, 정책 최적화를 위해 마스크된 궤적(masked trajectory) 접근 방식을 사용합니다.
- 🏆 다양한 멀티턴 QA 및 WebShop 환경에서의 실험 결과, MEM1은 메모리 사용량과 추론 시간을 크게 줄이면서도 기존 모델 대비 성능을 크게 향상시키며 훈련 범위를 넘어선 작업에 대한 강력한 일반화 능력을 보였습니다.