Summary
working memory를 textual memory 형태로 구현.
infinity-long-context를 성능 저하 없이 선형 시간 복잡도로 처리하는 방법을 다룸.
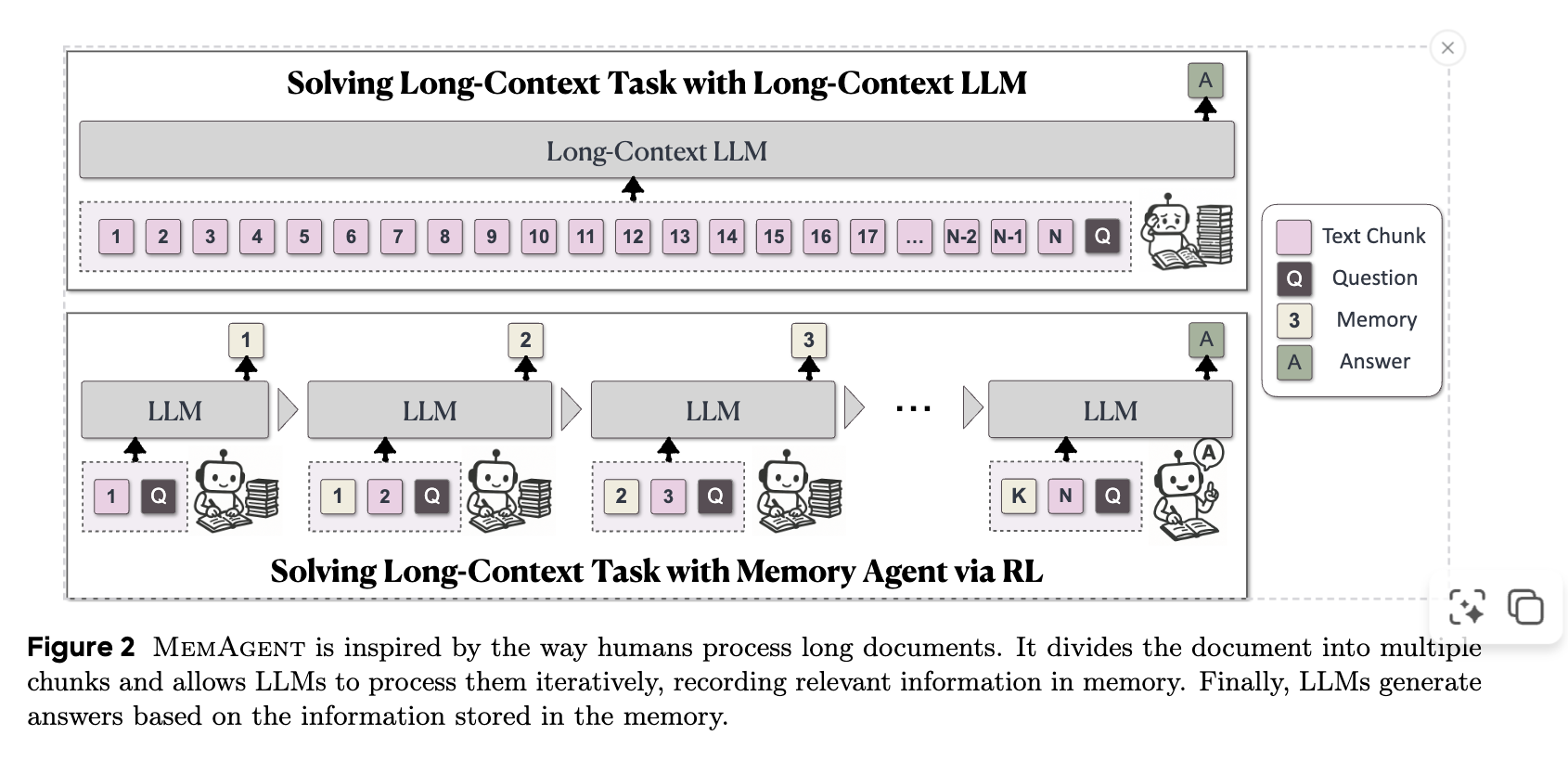
기존 방식들은 길이 외삽법(length extrapolation), sparse/linear attention, 또는 context compression을 사용하지만, 이들은 성능 저하, 느린 처리 속도, 처음부터 훈련 필요, 또는 기존 생성 프로세스와의 호환성 문제와 같은 한계가 있었음. 인간이 long-context를 처리하는 방식, 즉 핵심 개념을 추상화하고 관련 없는 정보를 버리는 방식에서 영감을 얻어 MemAgent라는 agent workflow를 제안.MemAgent는 텍스트를 여러 segment로 나누고, 고정된 길이의 memory를 overwrite하는 전략으로 업데이트함. 이 메모리는 일반적인 token sequence로 context window 내에 존재하며, 이는 기본 LLM의 생성 프로세스를 변경하지 않고도 유연성을 제공.
inferenece 과정을 2가지로 구분하는데,
Context-Processing 모듈: 모델은 input text를 chunk 단위로 순회하며 처리. 각 chunk를 읽은 후, 모델은 이전 메모리를 현재 chunk에서 얻은 중요한 정보로 업데이트하여 새로운 메모리()를 생성. fixed-memory size이므로, 각 chunk당 연산 비용은 이며, 전체 프로세스의 복잡도는 입력 길이(number of chunks)에 대해 엄격히 으로 유지됨.
Answer-Generation 모듈: 모든 chunk 처리가 완료되면, 모델은 최종적으로 업데이트된 메모리와 문제 진술(problem statement)만을 사용하여 최종 답변을 생성한다.
간단히 얘기하자면, chunk와 이전 memory를 합쳐서 input으로 사용하면서 auto-regressive하게 LLM에세 sentence-completion을 시켜 다음 메모리로 사용하는 것.
Question
그러면 결국, chunking을 한 단위 내애서 attention을 하여 총 chunk 개수만큼 한다는 건데, 시간 복잡도를 두 개 비교해보면?
→ 결론적으로는 chunk치는게 더 낫다.
→ auto-regressive한 연산 수가 늘더라도 한 번의 attention-map 사이즈가 제곱배로 줄어들어 이득.
- 표준 LLM: 전체 연산량
- MemAgent: 전체 연산량
- (N: 전체 토큰 수, k: 청크 수, C: 청크 크기 + 메모리 크기)
by Moonlight
- MemAgent는 RL 기반 memory agent를 도입하여 LLM의 long-context 능력을 재구성, 긴 문서를 선형적인 복잡도로 효율적으로 처리합니다.
- 📚 이 접근 방식은 텍스트를 segment 단위로 처리하고 RL을 통해 동적으로 업데이트되는 고정 길이의 memory를 사용하여 무한한 길이의 문서를 O(N) linear time complexity로 다룰 수 있습니다.
- 🚀 MemAgent는 8K context window에서 훈련되었음에도 불구하고 3.5M QA task에서 5% 미만의 성능 손실로 탁월한 extrapolation 능력을 입증하며, 기존 long-context 모델들을 능가합니다.