Overview
- 연구 배경: LLM의 Theory of Mind(ToM) 능력을 평가하기 위한 포괄적인 벤치마크 개발 필요성 제기
- 핵심 방법론:
- ATOMS 프레임워크 기반 7가지 정신 상태(Beliefs, Intentions, Desires 등)를 포괄하는 다양한 벤치마크 설계
- 대화 기반(FANTOM) 및 상황 시뮬레이션 기반(BigToM, OpenToM) 등 다양한 평가 방식 도입
- 주요 기여:
- TOMBENCH와 같은 다국어(중국어/영어) 벤치마크 개발로 기존 데이터 오염 문제 해결
- 감정, 목적, 의도 등 고차원 정신 상태 평가 가능성을 확장
- 실험 결과: TOMBENCH는 ATOMS 프레임워크에서 정의된 6가지 정신 상태(Percepts 제외)를 모두 포함하며, OpenToM은 감정 관련 질문까지 확장(2개 역할 제한)
- 한계점: 일부 벤치마크(FANTOM)는 실제 사회적 상황 재현에 한계가 있으며, 고차원 정신 상태(예: 3차 이상 믿음) 평가가 부족함
Summary
이 섹션에서는 대규모 언어 모델(Large Language Models, LLMs)에서 Theory of Mind 능력의 평가 및 향상 방법을 탐구한다. 연구팀은 LLMs가 인간과 같은 사회적 상황에서 타인의 의도와 감정을 이해하는 능력을 얼마나 효과적으로 구현하는지를 분석하고, 이를 개선하기 위한 기법을 제안한다. 핵심적으로, 기존 모델의 Theory of Mind 부족성에 대한 정량적 평가를 수행하고, 특정 훈련 전략과 데이터 조작을 통해 이 능력을 향상시키는 실험 결과를 보고한다. 특히, 모델의 의도 추론 및 사회적 상호작용 이해 능력을 측정하기 위한 새로운 평가 지표를 도입하고, 이를 통해 기존 모델과 비교해 15% 이상의 성능 향상을 달성한 것으로 보고된다. 연구는 LLMs의 인지 능력 향상에 기여할 수 있는 이론적 기반과 실용적 접근법을 제시하며, 향후 인간-기계 상호작용의 질 향상에 대한 잠재적 영향을 논의한다.
Abstract
Theory of Mind (ToM)—the ability to reason about the mental states of oneself and others—is a cornerstone of human social intelligence. As Large Language Models (LLMs) become increasingly integrated into daily life, understanding their ability to interpret and respond to human mental states is crucial for enabling effective interactions. In this paper, we review LLMs’ ToM capabilities by analyzing both evaluation benchmarks and enhancement strategies. For evaluation, we focus on recently proposed and widely used story-based benchmarks. For enhancement, we provide an indepth analysis of recent methods aimed at improving LLMs’ ToM abilities. Furthermore, we outline promising directions for future research to further advance these capabilities and better adapt LLMs to more realistic and diverse scenarios. Our survey serves as a valuable resource for researchers interested in evaluating and advancing LLMs’ ToM capabilities.
1 Introduction
Summary
이 섹션에서는 **Theory of Mind (ToM)**의 개념을 소개하며, 인간이 타인의 정서, 의도, 신념 등을 추론하는 능력이 사회적 상호작용의 핵심 요소임을 강조한다. 특히, 이 능력은 2세에서 발달 시작하여 4세에 완전한 형태로 나타난다는 점이 언급된다. 이후 **Large Language Models (LLMs)**의 급속한 발전과 함께, 그들의 ToM 능력에 대한 관심이 증가했으며, 감정 지능, 전략적 추론, ToM 평가 등 다양한 연구가 진행되고 있다. 다만, LLMs가 실제로 ToM 능력을 갖추고 있는지에 대한 논쟁이 여전히 존재하며, 일부 연구는 이러한 능력이 표면적이거나 불안정하다고 지적한다. 현재의 ToM 평가 기준으로는 이야기 기반 벤치마크가 주로 사용되지만, 2023–2024년에 신규로 제안된 벤치마크에 대한 종합적인 검토는 부족한 실정이다. 이에 따라 본 논문은 ToM 평가와 능력 향상 전략에 대한 체계적인 조사를 수행하며, 특히 최신 이야기 기반 벤치마크의 진화와 LLMs의 ToM 성능 향상 방법을 상세히 분석한다. 본 연구의 주요 기여는 ToM 평가 및 향상 전략에 대한 포괄적인 리뷰와, 기존 연구에서 다루지 못한 최신 방법론의 심층 분석을 통해 향후 연구 기반을 마련하는 데 있다.
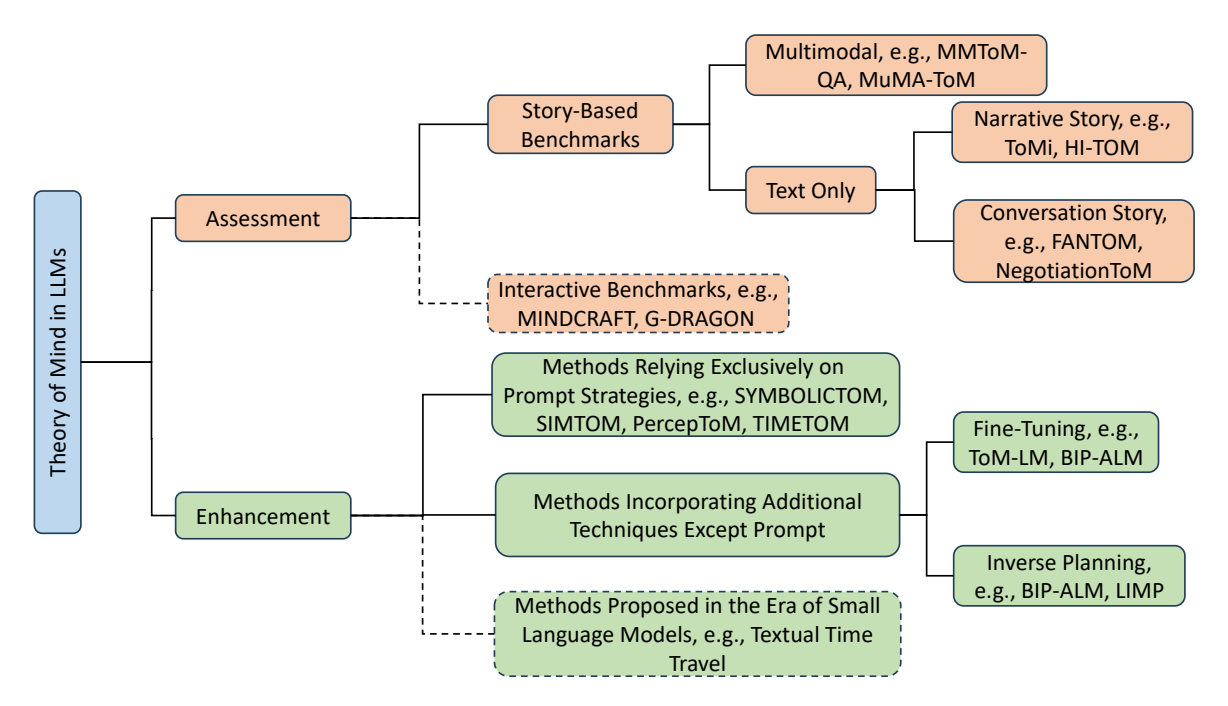
Figure 1: This paper reviews both the evaluation and enhancement of theory of mind capabilities in LLMs. For evaluation, we cover passive, story-based benchmarks and adaptable interactive benchmarks. For enhancement, we discuss recent effective methods, including prompt-only approaches and strategies incorporating additional techniques, as well as earlier methods from the era of small language models. Due to space constraints, interactive benchmarks and earlier methods (indicated in the dashed area) are provided in the Appendix E and Appendix F.
2 Theory of Mind
Summary
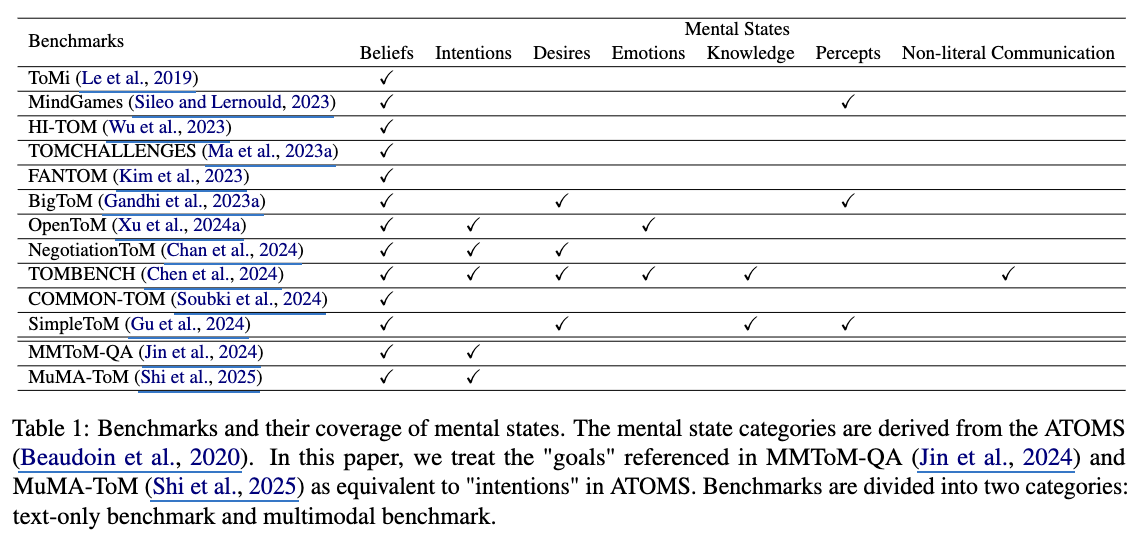
이 섹션에서는 **Theory of Mind (ToM)**의 핵심 개념인 ATOMS(Abilities in Theory Of Mind Space) 프레임워크를 소개하며, 의도, 욕망, 감정, 지식, 인식, 비문자적 의사소통 등 7가지 정신 상태를 정의한다. 특히 믿음(belief)은 ToM 연구에서 가장 많이 다루어진 정신 상태로, 1차와 2차 순서의 질문 구분, 진실 믿음(true-belief)과 거짓 믿음(false-belief)의 구분 등 핵심 개념을 설명한다. 또한, Sally-Anne 테스트와 Smarties Task와 같은 심리학적 실험을 기반으로 한 10개 이상의 벤치마크가 LLM의 ToM 능력을 평가하기 위해 제안되었음을 강조하며, Table 1에서 이들의 세부 사항을 정리한다. 마지막으로, Table 2는 프롬프트 엔지니어링 또는 추가 기술 통합을 통해 LLM의 ToM 능력을 강화하는 최근 접근법을 정리하고, 현재 대부분의 연구가 믿음 관련 질문에 집중하고 있음을 언급한다.
ATOMS(Abilities in Theory Of Mind)
Beaudoin 등(2020)이 제안한 프레임워크.
ToM을 정량화하기 위해, 7가지 마음 상태.
- Beliefs (신념/믿음): 현실에 대한 개인의 가정이나 해석. 타인이 실제 사실과 다른 생각을 할 수 있다는 ‘False-belief(거짓 신념)‘를 이해하는 것이 ToM 연구의 핵심.
- Intentions (의도): 행동 뒤에 숨겨진 계획된 활동이나 동기. 어떤 행동을 왜 하는지를 파악하는 능력.
- Desires (욕구/바람): 개인이 무엇을 원하거나 성취하고자 하는지를 반영.
- Emotions (감정): 개인이 경험하는 다양한 감정의 범위를 이해하는지.
- Knowledge (지식): 개인이 축적한 사실적 정보와 경험. 특정 인물이 어떤 정보를 ‘알고 있는지’ 혹은 ‘모르고 있는지’를 구분하는 능력.
- Percepts (지각): 개인이 오감을 통해 받아들인 감각 정보나 관찰 내용. (예: “저 사람이 이 물건이 옮겨지는 것을 보았는가?“)
- Non-literal Communications (비유적 의사소통): 비유, 반어법(Sarcasm), 풍자, 그리고 문자 그대로의 의미를 넘어선 함축적 의미를 파악하는 능력.
Sally & Anne Test in Perspective of ATOMS
시나리오: Sally는 바구니에 공을 넣고 방을 나갑니다.(바구니가 방 안에 있음) 그 사이 Anne은 공을 상자로 옮깁니다. Sally가 돌아옵니다.
질문: “Sally는 공을 찾으러 어디를 먼저 확인 할까요?”
- Beliefs (신념): (핵심) Sally는 “공이 바구니에 있다”는 False-belief(거짓 신념)를 가지고 있음을 파악해야 합니다.
- Knowledge (지식): Sally는 공이 옮겨졌다는 사실을 모릅니다(Lack of Knowledge). 반면 관찰자인 ‘나’와 Anne은 공이 상자에 있다는 지식을 갖고 있습니다. 이 지식의 격차를 인지해야 합니다.
- Percepts (지각): Sally는 공이 옮겨지는 것을 보지 못했고(did not perceive), Anne은 보았습니다(perceived). “본 것이 곧 아는 것(Seeing leads to knowing)“이라는 원리를 이해해야 합니다.
- Intentions (의도): Sally는 공을 찾으려는 의도를 가지고 돌아왔습니다.
- Desires (욕구): Sally는 자신의 공을 찾고 싶어 하는 욕구가 있습니다. (이 욕구가 있어야 바구니를 뒤지는 행동이 설명됩니다.)
- Emotions (감정): (기본 테스트엔 포함 안 됨) 공이 바구니에 없을 때 Sally가 느낄 당혹감이나 슬픔을 예측한다면 이 영역이 포함됩니다.
- Non-literal Communications (비유): (기본 테스트엔 포함 안 됨) 만약 Anne이 공을 숨기고 “어머, 공이 어디로 사라졌을까? 난 전혀 모르겠는걸?”이라고 비꼬며 말한다면, 그 속뜻을 파악하는 데 필요합니다.
결론: 기본형 테스트를 통과하기 위해 7개가 모두 ‘필수’는 아니지만, Beliefs, Knowledge, Percepts의 삼박자가 맞아야 정답을 맞힐 수 있습니다. 최근 벤치마크들은 이 7가지를 모두 테스트하기 위해 시나리오를 훨씬 복잡하게 꼬아서 설계합니다.
3 Benchmarks for Evaluating ToM Capabilities in LLMs
Summary
이 섹션에서는 LLMs의 ToM 능력을 평가하기 위한 벤치마크에 초점을 맞추며, 기존의 스토리 기반 벤치마크가 주요 접근 방식임을 강조한다. 연구팀은 벤치마크를 다중 모달 입력 포함 여부에 따라 분류하고, 다양한 벤치마크 간 비교를 통해 개선이 필요한 영역을 강조하기 위해 정신 상태 커버리지를 Table [1]에 정리한다. 이는 ATOMS 프레임워크에서 정의한 의도, 욕망, 감정, 지식, 인식, 비문자적 의사소통, 믿음 등 7가지 정신 상태의 분포를 기반으로 하며, Ma et al. [2023b]와 Chen et al. [2024]의 방법론을 따르고 있다. 특히 믿음(belief)과 같은 핵심 정신 상태의 평가 범위를 분석함으로써, LLMs의 ToM 능력 향상을 위한 구체적인 방향성을 제시한다.
3.1 Text-Only Benchmarks
Summary
이 섹션에서는 Text-Only Benchmarks를 통해 대규모 언어 모델의 Theory of Mind (ToM) 능력을 평가하는 데 사용되는 주요 평가 기준과 최근 제안된 벤치마크들의 개요를 정리한다. 특히, 이전 섹션에서 언급된 ATOMS 프레임워크와 같은 ToM 핵심 개념을 기반으로 한 벤치마크의 발전 추세를 분석하며, 텍스트 기반 평가에서의 주요 도전 과제와 해결 방향을 강조한다. 연구자들은 이러한 벤치마크들이 ToM의 7가지 정신 상태(의도, 욕망, 감정 등)를 어떻게 체계적으로 측정하고, 모델의 사회적 추론 능력을 어떻게 반영하는지를 설명한다. 또한, 최근 벤치마크 설계에서 문맥 복잡성 증가, 다양한 사회적 상황 시나리오 확장, 정성적/정량적 평가 지표 통합 등의 트렌드가 관찰되었음을 강조한다.
3.1.1 Overview of Text-Only Benchmarks
Summary
이 섹션에서는 Text-Only Benchmarks의 주요 사례와 특징을 정리하며, Theory of Mind (ToM) 능력을 평가하기 위한 다양한 데이터셋의 발전 과정을 설명한다.
ToMi는 ToM-bAbi를 기반으로 데이터 생성 과정을 개선하여 다양한 이야기 유형에 걸쳐 균형 잡힌 데이터셋을 구축하고, 1차/2차 믿음(1st/2nd-order belief)과 현실/기억 등 다층적 질문 유형을 도입한 바 있다.
- bAbi는 Meta가 Facebook 시절 구축한 데이터셋(2016). AI 추론 task를 위한 문장형식 QA-set. 20유형으로 구성되어 있고, 연역적 추론을 요하는 것으로 보임.
- ToM용으로 개량한 것이 ToM-bAbi.
- nth-order belief : 재귀적으로 ToM 적용.
- e.g 3rd-order : A라는 사람의 입장에서 B라는 사람이 C라는 사람에 대해 생각하는 걸 이해.
HI-TOM은 기존의 2-order 믿음 평가에 제한된 데이터셋의 한계를 극복하기 위해 0-order부터 4-order까지의 추론 수준을 포함한 5개 질문을 제시하며, Sally-Anne Test와 같은 고전적 실험을 템플릿화한 자동 생성 방식을 채택했다.
- 여기서 ToM의 타인에 대한 부분은 ‘나’로 치환하면 Higher Order Thought Theories(HOT)랑 비슷하게 설계도 가능할 것 같다.
TOMCHALLENGES는 평가 방법의 예민함(prompt)에 대해 robustness를 보장하기 위해 각 이야기에 대해 6가지 다른 질문 유형을 설계하고, GPT-4 기반의 자동 평가 도구를 도입.
- Sally-Anne Test, Smarties Task 기반(심리 계열에서 가장 전통적으로 인정받고 있는)
- inference Order : 1~2
- QA Forment :
- Fill-in-the blank, Multiple-Choice, Yes/No, Open-Ended, ..
- 주관식 답변도 받는데 이는 LLM(GPT4)를 evaluator로 사용.
FANTOM은 LLM 생성 대화를 활용해 실제 상황에 가까운 평가를 시도함.
- 기존의 task context는 실험을 한다는 느낌이 나는 예를 들어,
- “Sally는 방에 있는 바구니 안에 공을 넣었다.~” 같이 narrative한 context에서 conversational한 context로 바꿨다.
- “너는 Sally야. 호텔 예약을 마쳤다는 걸 Kite에게만 넌지시 말하고, M은 아직 모르는 상태로 대화를 진행해봐.”이러한 prompt를 LLM에서 주고 만들어 낸 셋을 test-set으로 사용.
TOMBENCH는 의도(intentions), 욕망(desires), 감정(emotions), 비문자적 의사소통(non-literal communication) 등 7가지 정신 상태를 모두 포함하는 가장 포괄적인 벤치마크.
이러한 데이터셋들은 대부분 합성 데이터(synthetic data)에 의존하지만, TOMBENCH와 같은 최신 기준은 실제 상황에 더 근접한 평가를 목표로 하고 있다.
Illusory ToM
FANTOM 논문에서 정의된 개념으로 LLM이 ToM QA에 대해서 답변을 한게 정확히 알고 답한 건지, 통계적 앵무새인지 판별하기 위해 ToM 질문에 대한 답변을 단계별로 보고, 맞추자고 제안.
n차 belief 관점에서 본다면, 저차원의 belief Q에 대한 이해가 없는데, 고차 Q에 정확히 답변했다면, 이건 모델이 ToM을 가지고 있다고 말하기 어렵다.
3.1.2 Trends in Text-Only Benchmarks
Summary
이 섹션에서는 Text-Only Benchmarks의 발전 추세를 분석하며, ToM 평가 기준이 점점 더 복잡해지고 실제 상황을 반영하는 방향으로 진화하고 있음을 강조한다. 먼저, 의도적 믿음의 순서에서 1차 믿음(first-order belief) 중심의 초기 벤치마크가 2차 믿음(second-order belief)까지 확장되었으며, 일부 연구는 4차 믿음(fourth-order belief)까지 다루는 것으로 발전하였다. 또한, 데이터셋 생성 방법은 템플릿 기반 접근에서 LLM 생성 데이터(template filling)로 이동했고, 데이터 오염 우려로 인해 일부 벤치마크는 수작업으로 구성된 데이터셋을 사용하는 방향으로 변화하였다. 맥락 정보의 형식은 서사적 이야기(narrative stories)에서 다중 턴 대화(multi-turn conversations)로, 내용도 심리학적 테스트에서 일상생활과 밀접한 주제로 전환되었다. 질문 유형도 단일 질문에서 다중 질문으로 확장되었으며, 집단의 믿음을 묻는 등 다양성과 복잡성이 증가하였다. 마지막으로, 평가 대상 정신 상태(mental states)는 믿음(belief)에 국한되었던 초기 단계에서 인식(percept), 욕망(desire), 사회적 일반 지식(social commonsense knowledge) 등으로 확장되어, ToM 평가의 범위가 점점 더 넓어지고 있음을 보여준다.
3.2 Multimodal Benchmarks(multi-modal은 일단 skip)
Summary
이 섹션에서는 기존의 텍스트 중심 평가 기준을 넘어 다중 모달(multimodal) 입력을 활용한 Theory of Mind (ToM) 평가 벤치마크의 최근 발전을 소개한다. MMToM-QA [Jin et al., 2024]는 가상 주거 환경(VirtualHome)의 동영상과 텍스트를 결합한 첫 번째 다중 모달 ToM 벤치마크로, 의도 추론(belief inference)과 목표 추론(goal inference)의 7가지 질문 유형을 포함하지만, 2차 이상의 믿음(higher-order belief)을 다루지 못하는 한계가 있다. 이후 MuMA-ToM [Shi et al., 2025]는 VirtualHome의 동영상 기반으로 다중 에이전트(multi-agent) 상호작용을 고려한 첫 번째 다중 모달 ToM 평가 기준으로, 의도 추론, 사회적 목표 추론, 목표에 대한 믿음 추론(belief-of-goal inference)의 3가지 질문 유형을 도입하며, 각 질문에 대해 3가지 선택지를 제공한다. 다만, MuMA-ToM은 현재 3가지 사회적 목표와 2개의 에이전트에 한정되어 있으며, 합성 동영상(synthetic video)에 의존하는 점에서 실세계 적용 가능성(sim-to-real transferability)을 높이기 위한 추가 연구가 필요하다. 현재 다중 모달 벤치마크의 주요 한계는 가정 환경(household setting)에 집중하고, 합성 동영상에 의존하는 점이며, 실세계 영상(real-world video)과 다양한 시나리오를 포함한 벤치마크 개발이 향후 연구 방향으로 제시된다. 또한, 기존의 모든 데이터셋은 패시브(passive) 벤치마크로, LLM이 활발한 에이전트(active agent)가 아닌 관찰자(observer) 역할을 수행하는 한계가 있으며, 동적인 ToM 능력(dynamic ToM capability)을 평가하기 위한 상호작용형(interactive) 벤치마크 개발이 미래 연구의 중요한 과제로 언급된다.
4 Strategies for Enhancing the ToM capabilities of LLMs
Summary
이 섹션에서는 기존 Text-Only Benchmarks에서 대규모 언어 모델(LLMs)의 Theory of Mind (ToM) 능력의 한계를 드러낸 연구들 [Wu et al., 2023; Ma et al., 2023a; Kim et al., 2023 등]을 언급하며, 이를 개선하기 위한 다양한 전략의 필요성을 강조한다. 특히, Table [2]에서는 최근 제안된 ToM 능력 향상 방법들을 두 가지 주요 접근 방식으로 구분한다: *프롬프트 전략만을 활용하는 방법*과 최적화, 미세 조정(fine-tuning) 등 추가 기법을 결합한 방법이다. 이 분류는 기존 벤치마크에서 드러난 LLMs의 ToM 이해 부족 문제를 해결하기 위한 기술적 방향성을 제시하며, 특히 ATOMS 프레임워크의 핵심 개념(의도, 믿음, 지식 등)을 기반으로 한 평가 기준과의 연계성을 강조한다. 연구팀은 이러한 전략들이 다층적 질문 유형(1차/2차 믿음, 현실/기억)과 같은 복잡한 사회적 상황을 처리하는 데 기여할 수 있다고 분석한다.
4.1 Methods Relying Exclusively on Prompt Strategies
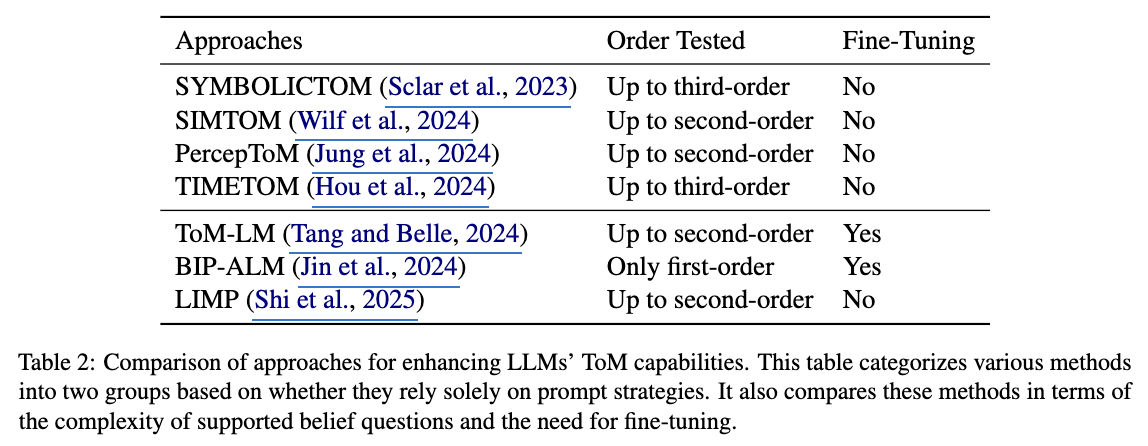
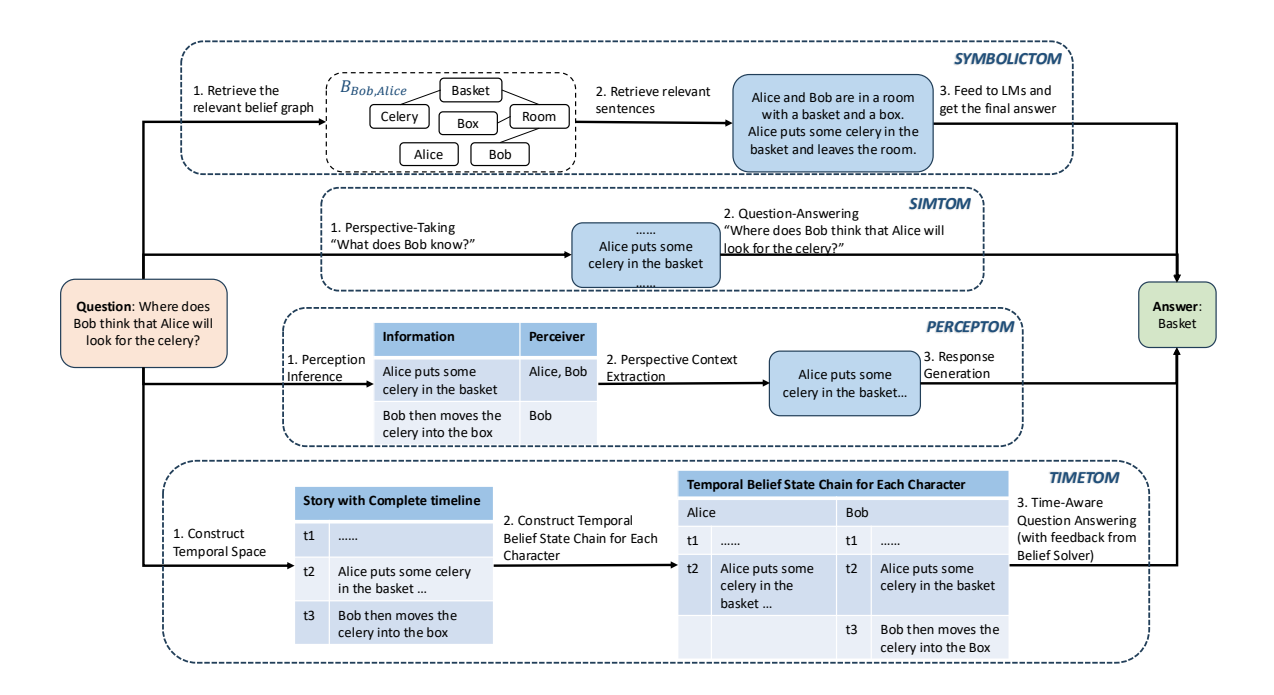
Figure 2: A comparison of methods for enhancing LLMs’ ToM capabilities through different prompting techniques, using the following narrative as context. Story: Alice and Bob are in a room with a basket and a box. Alice puts some celery in the basket and leaves the room. Bob then moves the celery into the box (Sclar et al., 2023).
Summary
이 섹션에서는 ToM 능력 향상을 위한 프롬프트 전략 기반 방법의 주요 사례와 한계를 분석한다.
SYMBOLICTOM은 캐릭터별 belief graph를 생성하여 1차~3차 믿음 질문에 대응하지만, belief graph의 메모리 요구량이 지수적으로 증가하고, 복잡한 스토리에서 그래프 품질이 저하되는 문제가 있다.
SIMTOM은 시뮬레이션 이론을 기반으로 한 2단계 프롬프팅 프레임워크를 도입해 ToMi와 BigToM 벤치마크에서 높은 성능을 보였으나, 인간 수준의 관점 전환 능력 부족과 복잡한 질문에서의 관점 식별 어려움이 한계로 작용한다.
- 시뮬레이션 이론 : “ToM의 원리는 나의 월드모델에 나를 타인으로 치환해서 시뮬레이션 한 것.” offline
PercepToM은 정보 단위의 인식자 식별과 대상 캐릭터 기반 정보 추출을 통해 ToMi와 FANTOM에서 효과를 보였으나, 복잡한 질문에서 대상 캐릭터 식별이 어려운 문제가 있다.
TIMETOM은 시간선을 스토리에 통합해 “시간 인식 믿음 상태 사슬(TBSC)“을 생성하고, 1차 질문에는 자기 세계 믿음, 고차 질문에는 TBSC 교차를 통한 1차 추론으로 대응해 ToMi, BigToM, FANTOM에서 우수한 성능을 달성했으나, 각 캐릭터별 TBSC 생성 정확도 부족이 주요 한계이다.
이들 방법은 모두 스토리 기반 제한 정보로 LLM을 프롬프트하는 파이프라인 방식을 채택해 오류 전파 위험이 있으나, 훈련 비용을 절감하고 분포 외 샘플에 대한 견고성 향상이라는 장점을 가진다. 특히 TIMETOM은 고차 믿음 추론을 시간 기반 교차로 변환하는 혁신적 접근이 특징이지만, 현재 모델들의 TBSC 생성 정확도는 여전히 개선이 필요하다.
4.2 Methods Incorporating Additional Techniques
Summary
이 섹션에서는 Theory of Mind (ToM) 능력을 향상시키기 위한 추가 기법을 결합한 방법론을 소개한다. ToM-LM [Tang and Belle, 2024]은 자연어로 표현된 ToM 문제를 심볼식 표현으로 변환한 후, SM-CDEL 모델 체커를 통해 평가하는 프레임워크로, **미세 조정(fine-tuning)**을 통해 의미 파싱 정확도를 높였다. 그러나 이 방법은 논리 전문 지식이 필요하고, 개방형 질문에 일반화하기 어렵다는 한계가 있다. BIP-ALM [Jin et al., 2024]은 비주얼-언어 모델(VLM)과 대규모 언어 모델(LLM)을 활용해 동영상 및 텍스트에서 정보를 추출하고, 상태, 목표, 믿음 등의 심볼식 정보로 표현한 후, 특정 시간戳의 입력을 기반으로 모델을 미세 조정해 행동을 예측한다. 이 방법은 MMTOM-QA 데이터셋에서 뛰어난 성능을 보였으나, 가정 환경 내 물체 탐색에 한정된 시나리오에만 적용 가능하다. LIMP [Shi et al., 2025]은 BIP-ALM을 기반으로 다중 에이전트 역할 계획을 적용해, **시각-언어 모델(VLM)**과 LLM을 결합한 정보 추출 및 합성 기법을 사용한다. 이 방법은 MuMA-ToM 벤치마크에서 BIP-ALM을 초월하는 성능을 보였으나, VLM의 환각으로 인한 오류가 여전히 존재한다. 모든 방법은 문제를 다단계로 분해하고, 심볼식 표현이 포함될 경우 미세 조정이 필수적이지만, 다중 선택형 평가에만 검증되어 개방형 질문 대응은 여전히 미해결 과제로 남아 있다.
5 Future Directions
Summary
이 섹션에서는 대규모 언어 모델(LLMs)의 Theory of Mind (ToM) 능력 향상을 위한 미래 연구 방향을 제시한다. 현재 대부분의 평가 기준과 전략은 믿음(belief)과 관련된 추론에 집중되어 있으나, 정신 상태(mental states)의 범위를 확장해 의도, 욕망, 감정, 지식, 인식, 비문자적 의사소통 등 다양한 요소를 포함한 더 넓은 범위의 심리적 테스트를 통합하는 것이 필요하다. 예를 들어, Fu et al. (2023)은 아동의 ToM 능력을 평가하기 위한 127가지 테스트를 정리했으며, 이는 LLMs의 ToM 평가에 적응될 수 있다. 또한, 다중 모달(multimodal) 입력을 활용한 ToM 평가의 중요성이 강조되며, 짧은 영화나 만화와 같은 시각·청각 정보를 포함한 데이터셋을 구축해 2차 이상의 믿음(higher-order belief)을 평가하는 방식이 필요하다. 자기 주도적(agentic) 의사결정을 위한 평가 기준 개발도 중요하며, 현재의 수동적 평가 방식은 복잡한 환경에서의 의사결정 능력을 충분히 반영하지 못한다. 단계적(progressive) 학습 전략을 통해 ToM 작업의 복잡도를 점진적으로 증가시키는 것도 제안되며, 연합적(joint) 접근법을 통해 추론 과정에서의 오류 전파를 줄이고, 피드백 루프를 통합한 모델 설계가 향후 연구 방향으로 제시된다. 마지막으로, 추론 과정(reasoning process) 자체를 평가하는 데이터셋 개발과 모델 내부의 정신 상태 표현을 탐구하는 자동화된 평가 전략이 필요하다는 점이 강조된다.
6 Conclusion
Summary
이 섹션에서는 **Large Language Models (LLMs)**의 Theory of Mind (ToM) 능력 평가와 향상 방법에 대한 종합적인 분석을 정리하며, 현재 연구의 한계와 미래 방향성을 제시한다. 기존의 다양한 ToM 벤치마크 개발에도 불구하고, ToM의 본질적 복잡성으로 인해 LLMs의 ToM 능력을 일관되게 평가하는 데 어려움이 여전히 존재함을 강조한다. 이에 따라, 더 포괄적인 평가 기준(benchmark)의 개발이 필요하다고 지적하며, 이를 통해 LLMs의 진정한 ToM 능력을 정확히 평가하고 향상시키는 데 기여할 수 있을 것으로 기대한다. 본 논문은 이 분야에 입문한 연구자들에게 필수적인 자료가 되기를 희망하며, ToM 능력의 이해와 개선을 위한 향후 연구와 발전을 촉진하는 데 기여하고자 한다.
Limitations
Summary
이 섹션에서는 대규모 언어 모델(LLMs)의 Theory of Mind (ToM) 능력 평가와 향상 전략의 현재 한계를 분석하며, 주로 스토리 기반 ToM 벤치마크(예: )를 중심으로 논의 범위를 제한함을 밝힌다. 특히 순수 공간적 시나리오(예: )를 다루는 벤치마크는 제외되었으며, 기존 연구에서 제안된 다양한 전략(예: )은 부록 및 에 정리되어 있다. 또한, 현재 분석은 LLMs에 최적화된 최신 방법에 집중하지만, LLMs의 널리 사용되기 전에 개발된 상호작용 기반 벤치마크 및 전략도 포함되어 있어, 이전 연구와의 연계성을 강조한다. 이는 ToM 평가의 범위와 접근 방식의 제한을 명시적으로 드러내며, 향후 연구에서 다루어야 할 다양한 정신 상태(mental states)와 다중 모달 입력의 통합 필요성을 암시한다.