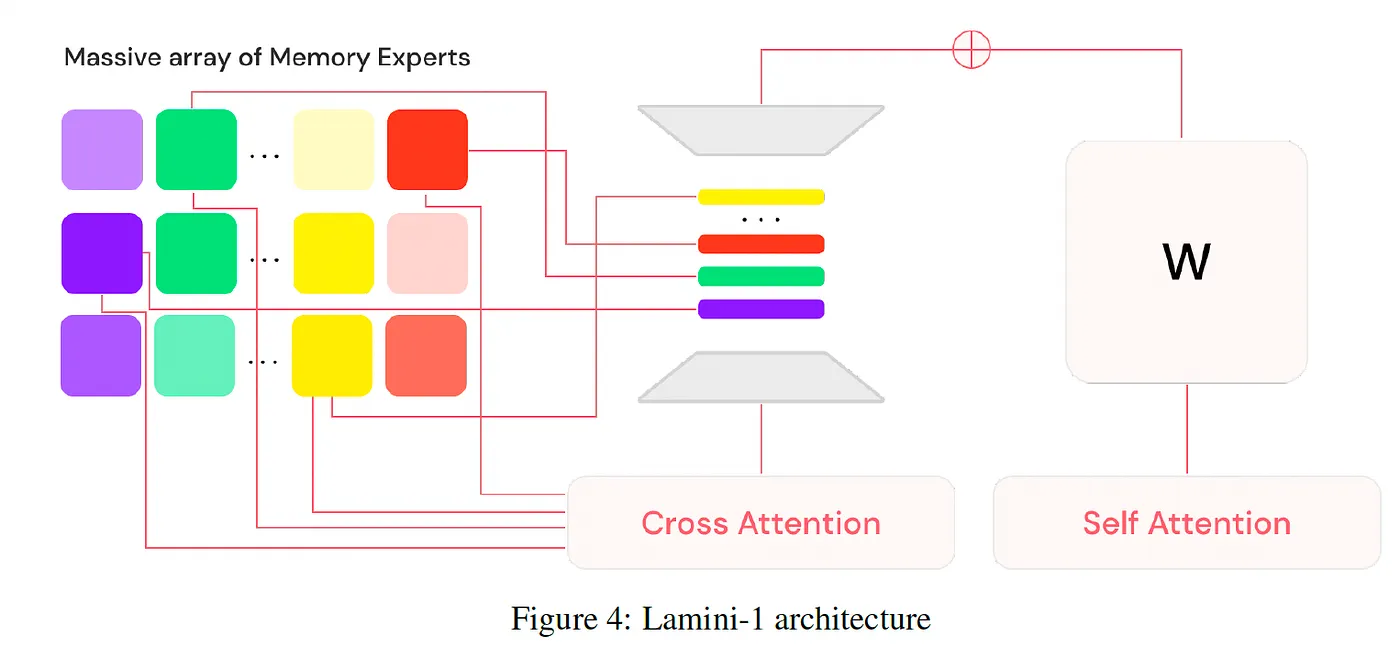
-
MoE architecture 변형. memory에 MoE를 적용하자고 MoME(Mixture of Memory Experts)
-
일반적인 MoE에서 ‘전문가’가 특정 논리 구조나 언어 패턴을 처리하는 MLP(Multi-Layer Perceptron) 층이라면, Lamini-1의 메모리 전문가는 특정 **데이터(사실 정보)**를 가중치(Weights) 형태로 기억하고 있는 **미세한 어댑터(Adapters)**들.
-
예시로, Llama-8B 모델을 backbone으로 사용하여 freeze하게 사용하고, MoME를 따르게 설계된 memory fragment들이 수백만개 중 32개 활성화되어 같이 연산을 수행함.
-
memory라는 건, LoRA와 비슷한 형태를 가졌는데, 일반적인 LoRA는 backbone의 모든 레이어에 대한 update 부분에 해당하는 matrix decomposition 산물들이었지만, 여기서는 특정 레이어의 아주 작은 단위로 구성을 한것으로 보임.
- 대략 8B 모델에 대한 전체 memory experts는 2B 정도라고 함.
Key Concepts
Memory Experts
-
저장 기준: 단순히 도메인(의료, 법률 등)으로 크게 나뉘는 것이 아니라, **데이터의 의미적 유사성(Semantic Similarity)**이나 특정 사실 단위로 나뉩니다.
-
작동 방식: 방대한 양의 사용자 데이터를 수만~수백만 개의 작은 조각으로 나누고, 각 조각을 전담하여 완벽하게 암기하는 ‘전문가 어댑터’를 만듭니다. 질문이 들어오면 모델은 인덱스를 검색해 해당 질문에 답할 수 있는 최적의 메모리 어댑터를 찾아냅니다.
-
기존 standard인 Mixture of Experts(MoE)는 router가 어떠한 expert module을 call할지 정하는데, router 없이 cross-attention으로 call 당할 expert를 선택.
Sparse Attention
- MoE 구조이기에 inference 시, sparse attention 즉, 추론 환경에서 모든 memory experts가 사용되지는 않는다.
- 단, backbone은 다 사용되겠지.
Key difference
- 암기(Memorization) 특화: 기존 모델들이 지식을 ‘학습(Learning)‘한다면, Lamini-1은 지식을 가중치 내에 ‘박아넣는(Embedding/Memorization)’ 방식입니다. 이를 통해 **RAG(검색 증강 생성)**보다 빠르고 정확하게 특정 사실을 인출할 수 있습니다.