Schedule
Study Background
Keyword: 음성수렴, 인공지능, in-group-bias , out-group-bias , HCI
Q. 사람 간 대화 시 음성학적 특질이 닮아가는 현상이 보고되었는데, 이러한 수렴 현상이 인공지능과의 대화에서도 일어날까?
→ 인공지능에 대해 음성 수렴이 일어나지 않는다 ; 인공지능에 대한 out-group bias 존재.
- In -group bias : 같은 집단의 개체들을 고평가
- Out-group bias : 나의 집단이 아닌 것들은 다 비슷하다고 생각. 그러니 구분을 잘하지 못함.
Q. 인공지능과의 대화에서도 수렴이 일어나지 않는다면, 어떠한 요인이 작용한 것일까?
- 가설1. AI가 만들어내는 음성은 질적으로 사람의 소리와 다르다.
- 가설2. 음성학적 요소가 아닌, 대화 주체 정체성을 인지하는 것이 중요하다.
- 사람인지 아닌지 인지 하는 것.
Pre-study Survey
Target Papers
Recent Papers
Experiment Design
-
Babel(2012)의 shadowing 과제를 따라가되,
AI vs 사람 조건을 나누어 실험. -
설문을 추가하여 상관 분석을 실시
-
실험을 통해 검증해보고자 하는 주요한 factor
- 사람의 음성 정보와 AI가 만들어낸 음성 정보의 질적 차이
- 듣는 발음을 한 주체가 사람인지 AI인지 제공되는 인지정보 차이
- 사회심리학적 관점에서 이게 조금 더 타당. (LY에서 검증하고자 하는 가설.
-
전체 설계
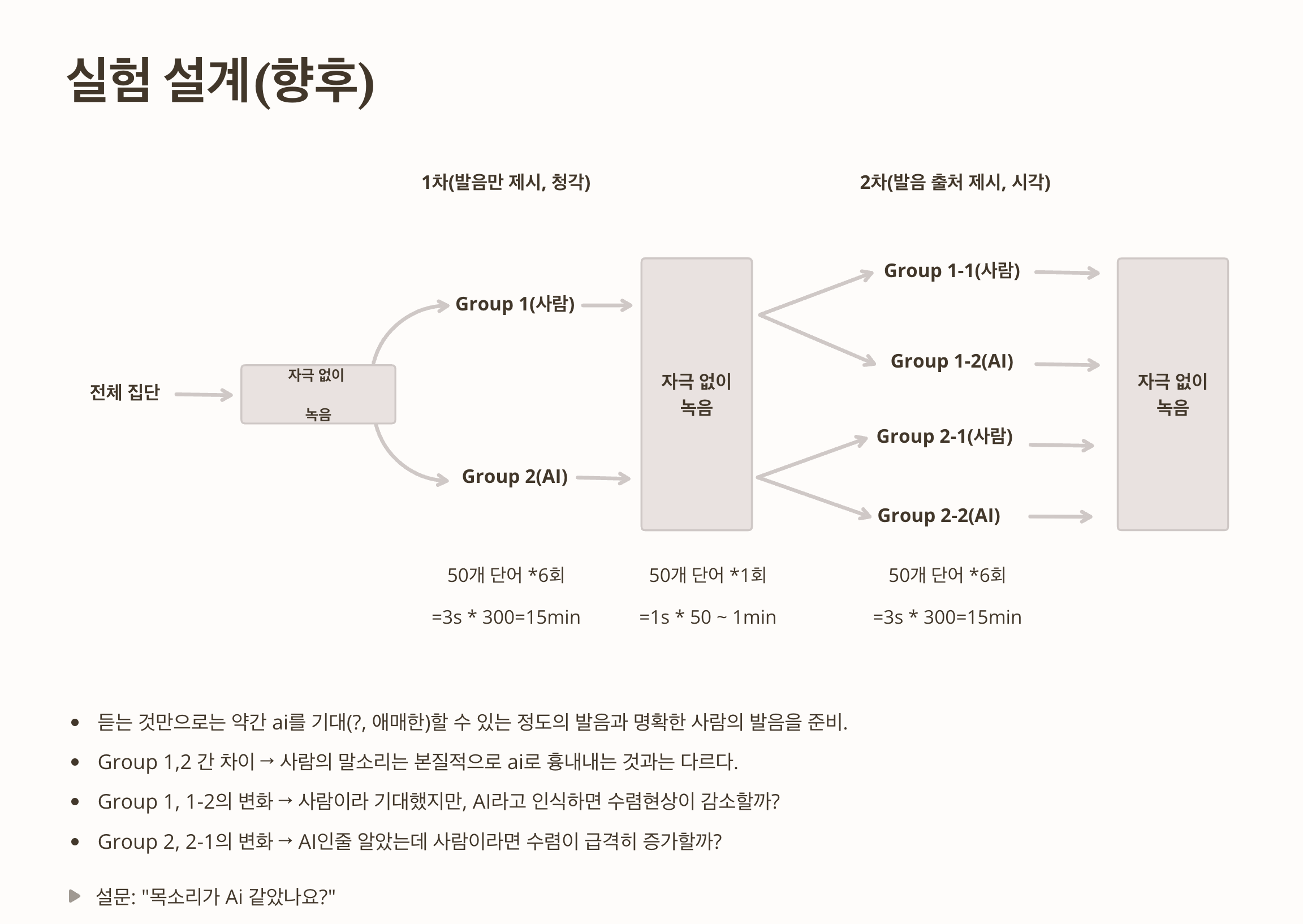
-
현재 LY 설계
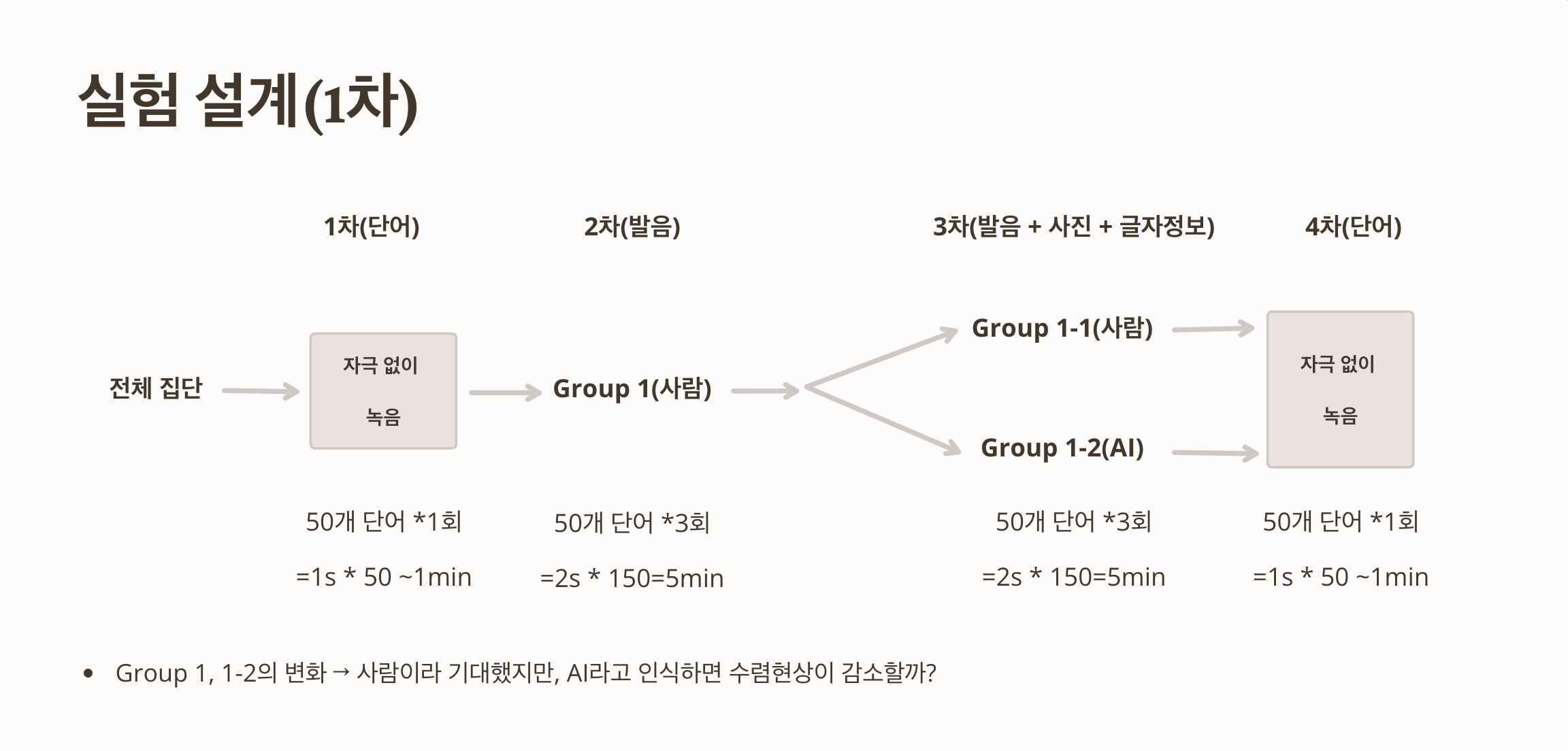
Stimuli
- Stimuli Preparation (Word Selection)
- Stimuli Preparation (Model Audio Recording)
- Stimuli Preparation (Model Audio Preprocessing)
Presentation Files
Analysis
진행 상황: 60명
50명의 설문 데이터 & 50명의 음성 데이터
6명은 실험 데이터로 빠진거고, 여기서 2명이 추가될 예정. 그러면 최종 52명
설문 안함: LY43(5/2), LY52(5/30) (2명 모두 근장이 받았는데, 설문을 하지 않았음.)
따라서 최종 설문+음성이 52명 데이터 될 듯.
분석 Metric
Formant
-
음성학과 음향학에서 사람의 성도 공명에 의해 형성되는 음향 스펙트럼 상의 넓은 주파수 대역의 peak.
-
사람이 말을 할 때, 성대에서 만들어진 기본 주파수(F0)가 성도 내 공명하면서 증폭되는 특정 주파수
-
특히 **모음(vowel)**과 관련이 많음.
-
일반적으로 3개 이상이 존재, (F1 → F3로 갈수록 높은 주파수)
- F1: 모음의 개방도(입 벌림)과 관련. 낮음 → 닫힌 모음, 높음 → 열린 모음
- F2: 혀의 전후 위치와 관련. 높은 값 → 앞쪽 모음(입에서)
- F3: 음성 음색의 개별성 등 추가적 특성.
-
계산 방법
- FFT(Fast Fourier Transform): 음성 파형 → 주파수 그래프로 변환(spectrogram)
- 주파수 그래프에서 진폭이 높은 peak을 찾음.
VOT(Voice Onset Time)
- 파열음(p,t,k,b) 자음을 산출할 때, 조음 기관이 개방되어 공기가 방출되는 순간부터 성대의 진동이 시작되는 순간까지의 시간 간격을 의미.
- 자음의 경우, VOT를 보는 것이 중요할 수 있어, 분석 예정.
Model Speaker Baseline → vowel formants(f1, f2)
총 50 단어.
분석 모음 총 5개: [a, ae, i, o, u] : [ㅏ, ㅔ, ㅣ, ㅗ, ㅜ]
| Vowel | F1-mean | F2-mean |
|---|---|---|
| a | 578.414245 | 1239.910385 |
| ae | 443.926535 | 1901.797140 |
| i | 348.367164 | 2079.479478 |
| o | 378.683382 | 893.053902 |
| u | 367.503783 | 1257.655762 |
Survey Results
- List1 : AI(text-info), List2 : Human(text-info)
- AI-Like: 1(매우 AI 같지 않다.) ~ 7(매우 AI 같다.)
- Human-Like : 1(매우 사람 같지 않다.) ~ 7(매우 사람 같다.)
두 그래프가 얼추 대칭처럼 보이지 않나..?
-
아마도 Human-Like에 6를 주면 8(1~7의 합)의 보수인 2를 AI-Like에 준 경향이 있다는 거겠지.
-
바로 위 분석과 일맥 상통. 각 group별 AI-Like, Human-Like의 합을 보면, 거의 8임.
-
결론: 참가자들은 성별 속성, model의 Humanness에 따라 Humanness Rating 차이가 없다.
- 다들 대부분 고만고만하게 AI 같기도 하지만, 사람이라고 인식했다.