전체 개관
실험은 총 4단계로 구성.
소요 시간은 대략 20~25분 정도로 예상.
- 가능한 시나리오 → 크게 3가지
- 한 줄 요약
Babel(2012)의 shadowing 과제를 따라가되, ai가 중간에 들어가고, 설문을 추가하여 상관 분석을 실시
- 제시되는 단어를 참가자가 발음하고 녹음.
- 발음이 제시되면, 따라하기.
- 제시되는 단어를 따라하고 녹음해서 초기와 비교.
- Hexaco short version & GAAIS(20개 문항, 리커트 척도, 240회 인용)


사람을 ai로 인지하면, 음성 수렴이 일어날까? (V)
AI 가 만들어낸 음성 데이터로도 음성 수렴이 일어날까?(사람과 ai의 발음이 질적으로 다른가?)
- 사람과 ai의 음성 데이터로 각각 수렴 정도 비교..
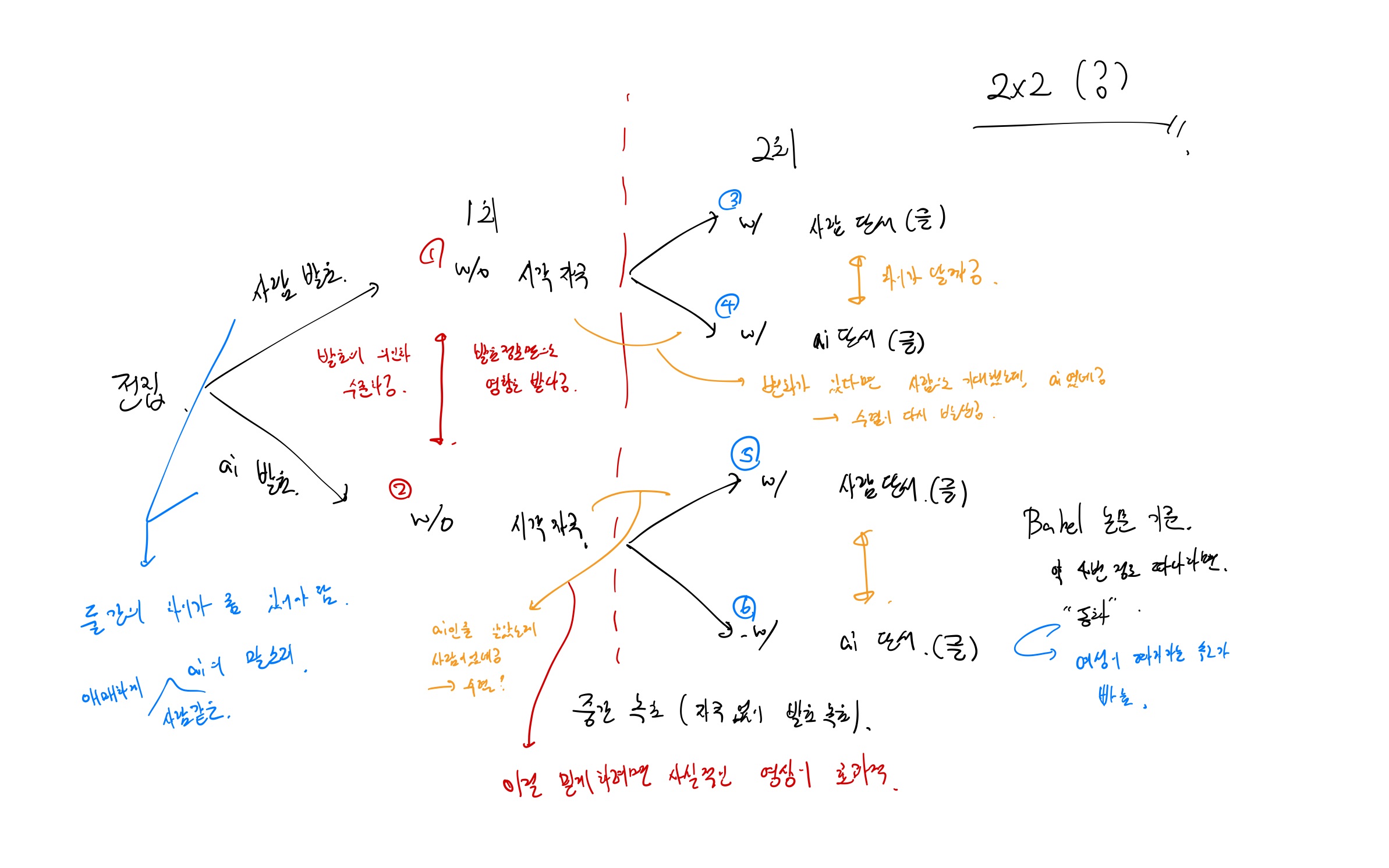
- ai 가 ai 인걸 알려주고, 사람이 사람인 걸 알려주면 변하나? 2단계의 trial을 2 stage로 나누고(각 stage 당 3회), 첫 번째 스테이지는 visual 자극 없이, 두 번째 stage는 시각 자극을 넣어서. 두 스테이지 사이에는 3단계 시행이 한 번 더 있는 걸로,,
if, 2*2로 설계한다면, 조건은 다음과 같이 나뉠 것이다.
| ai 발음 | 사람 발음 | |
|---|---|---|
| ai라고 제시 | Group A | Group B |
| 사람이라고 제시 | Group C | Group D |
- 모두에서 차이가 발생하지 않는다면, 음성수렴은 사람이 단지 주의 청각 자극을 모방하려는 습성이 있다,,
- (A,C), (B,D) 에서 차이가 보인다면 → ai의 발음과 사람의 발음이 차이가 있다는 것이 드러남 → 뭔지 정확하게 단정 지을 순 없지만, 사람과 ai의 발음에는 차이가 있다. 라는 결론.(뭔가 질적으로 다른지가 궁금, 언뜻 듣기에는 비슷하더라도 무의식적으로 구분할 수 있을까?)
- (A,B), (C,D)에서 차이가 보인다면, → 음성 수렴이라는 현상은 사람한테서만 관찰되는 현상이다.
곰곰이 생각해보면, 사람의 발음과 ai의 발음에 질적으로 차이가 있을 것 같지는 않아서,, 발음을 그냥 통일하는게 맞는 방향인 것 같다. → 모든 발음 자극을 하나의 주체가 하고(사람이 할까?, 만들까?) 이걸 속이는 것이 맞는 방향인 듯.
- AI 혹은 인간의 발음 자극이 제시됨.
- 동일한 사람의 얼굴이 제시되고, 하단에 다음 설명으로 발화자의 정체성을 공개
- 다음은 국립국어원에서 제공하는 표준 발음입니다. 듣고 따라해보세요.
- 다음은 AI가 제공하는 표준 발음입니다. 듣고 따라해보세요.
1단계: 주어인 시각 자극(단어)를 보고 읽기
화면에 제시된 단어를 읽고 음성을 녹음하는 단계.
참가자의 기존 습관대로 읽었으므로, 향후 3단계의 녹음 결과와 비교할 기준.
저빈도 단어일수록(잘 사용되지 않는 단어) 효과 관찰이 쉽다고 하므로(기존의 발음을 많이 안 하니, 습관이라고 할만한 것이 없음. from Babel(2012)) 저빈도 단어를 우선적으로 채택.
[어떠한 모음을 선택?]
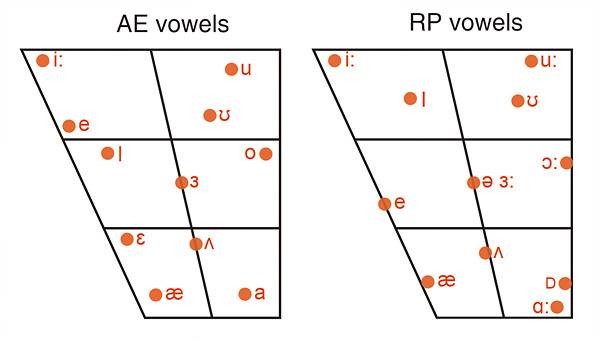
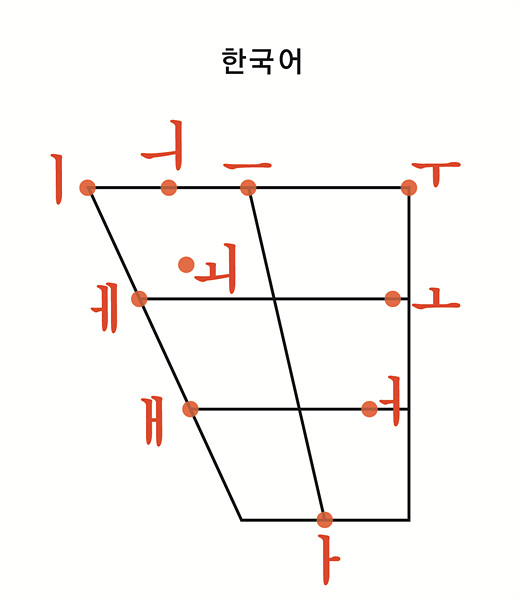
babel → low frequency vowel에서 움성 수렴이 잘 관찰됨.
→ 영어에서는 /ae/ 발음이 low frequency
babel에서 제시한 모음을 그대로 옮기면,
ㅏ,ㅐ,ㅣ, ㅗ, ㅜ 이렇게 5개의 모음들.
→ 모음 각각 10개씩 단어를 추출, 총 50개의 단어
Babel(2012)에서 제시한 5개의 모음들
[어떠한 단어를 사용하면 좋을까?]
국립 국어원 → 일상 대화 말뭉치 2023
위에서 선택한 모음을 가지되, 저 빈도 단어를 추출하여 단어 선택.
[단어 추출 소스]
- 국립국어원 → 일상 대화 말뭉치 2023 그래도 발음을 많이 안하는 단어들이 자극으로 조금 더 좋지 않을까?
- 2005년 현대 국어 사용빈도 조사.
Q. 굳이 빈도수가 적은 단어이어야 하는가? 발음이 어려운 단어는 어떠한가? 발음이 어려우면, 잘 안쓰는 단어일 것 같긴 한데,,
e.g. 왕밤빵 아예 쓰지 않아서 빈도수가 작은 풀을 검색하면 나올 것 같지 않은데,,
50개의 단어 말하기
1s * 50개 = 50s
고려요소
- 단어 길이가 비슷할 것.
- 모음의 포먼트를 비교할 거니까 받침이 없는게 나을라나?
2단계: 제시되는 발음을 듣고 따라하기
- 시각 자극 예시(prompt)
- “A short video clip of a single male(who are likely to be seen asian) speaker saying the word ‘자동차’ clearly. The background should be a uniform, plain color (e.g., light gray or white), and the speaker must maintain a neutral facial expression throughout. The clip should only contain the whole space of the male’s face(should contain mouth, nose, ears etc..) and the spoken word, with no audio distractions. audio is perfectly corrected with the given word “자동차. Also mouth movement should me matched. In addition, it is ont allowed to move the speaker. Perspective must be fixed.”
- “A 3 seconds short video clip of a single handsome male(who are likely to be seen korean) speaker saying the word ‘gamumm’ clearly. The background should be a uniform, plain color (e.g., light gray or white), and the speaker must maintain a neutral facial expression throughout. The clip should only contain the whole space of the male’s face(should contain eyes, mouth, nose, ears etc..) and the spoken word, with no audio distractions. audio is perfectly corrected with the given word “gamumm”. Also mouth movement should me matched. In addition, it is not allowed to move the speaker. Perspective must be fixed.”
2단계에서 발음되는 단어는 단어당 두 번씩 * 3세트 따라하게 함.
세트 간에는 주의를 돌리기 위해 빨간 스크린을 제시(Babel, 2012), 0.5s
→ 어짜피 청각 자극을 사용할거라면, 삐- 소리도 괜찮지 않을까?
한번 듣고 따라하기 3s
3s * 50단어 * 2회 * 3세트 = 900s = 15 min
이거 보다 적게 걸릴 것으로 예상.
단어들 제시 순서: Latin Square? or random?(Babel)
3단계: 제시되는 단어를 보고 읽기
1단계와 동일. → 50s
4단계: 후속 설문
AI에 대한 설문 혹은 성격에 대한 설문.
이후 상관 분석(타인에게서의 인정, 승인 욕구가 강한 사람들에게서 음성 수렴이 더 빨리 나타나기도,,)
3min
분석
언어학적 특성들(f1,f2)이 얼마나 닮게되었는지 유클리드 거리에서 이동정도 계산
위 닮아진 비율을 실험 요인들(성별, ai 등)과 상관
닮아진 비율을 성격 및 ai 관련 설문과 상관분석.
더 조사해봐야 겠지만, 일단 녹음을 하고 파일을 가지고 있으면, 분석은 이런 저런 피처들 찾아보기로,, 일단 f1,f2
[질문들]
-
한국어 자극 vs 영어 자극(발음)
-
소요되는 시간을 얼마나 잡아야 하는지 → 이걸 기준으로 총 단어의 수나, 요인적 설계 시 경우를 얼마나 세분화할지 정하기 위해
-
성격이나, ai에 대한 수용도 관련 설문(후속 설문)과 같이 엮어도 되는지.
-
성별 여부를 논문에 의하면 넣는게 좋을 것 같은데, 참가자를 모집하는 과정에서 괜찮을라나?
-
발음 데이터를 만들 때, 우리가 직접 녹음하는 방식으로 진행해도 되는지..?
-
총 참가자를 어느 정도로 설정하고 해야하는지. → 설계를 먼저하고 참여자를 맞추는 방식으로 하는 건지, 아니면 현실적으로 대략 정하고 맞춰서 설계하는지 궁금합니다.
-
ai의 의인화도 고려해보는건..?
-
음성학적 어떠한 특징들을 비교하면 좋은가? (f1, f2) 그 외의 다른..? → 이건 조사 중입니다…..
-
어떠한 단어들을 선별해야 하는가? 저빈도 단어를 사용하는 것이 좋다는 보고? ae 발음이 특이적이라고 하는데,, → 요것도 찾아보는 중입니다…..