Summary
Tip
Warning
마찬가지로, bottle-neck 문제가 있다.
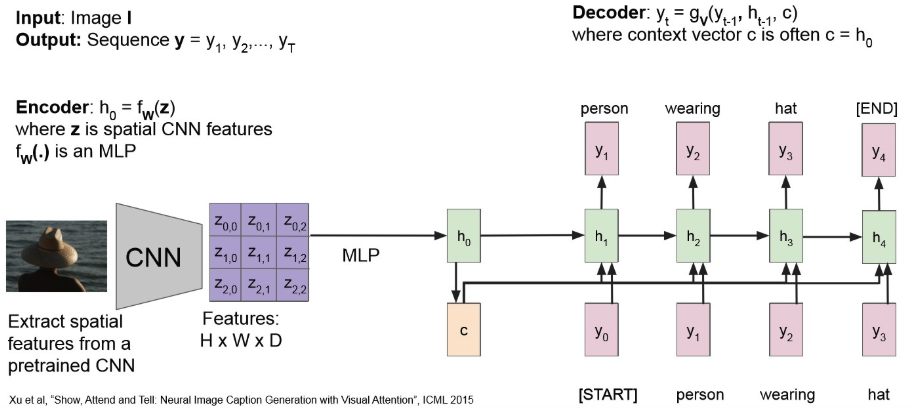
(Many-to-One) architecture를 따르다보니, input 정보를 하나의 context vector로 압축하는게 쉬운 일은 아니다.또한, 기존 RNN 문제인 long-term dependency 문제 역시 존재.
→ Attention을 적용해보자!
Check
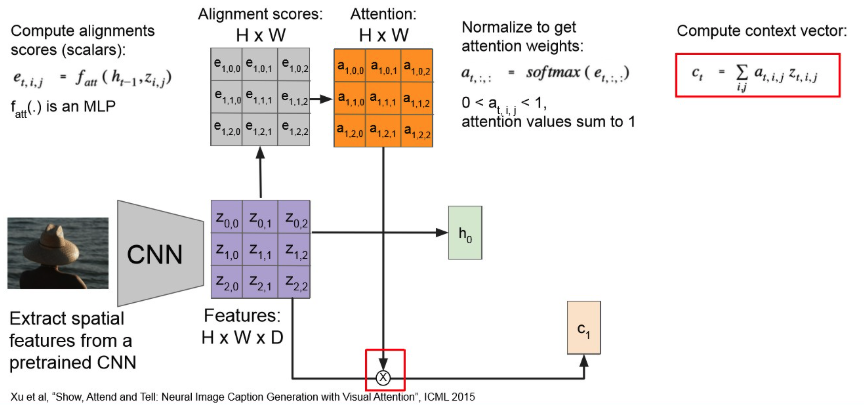
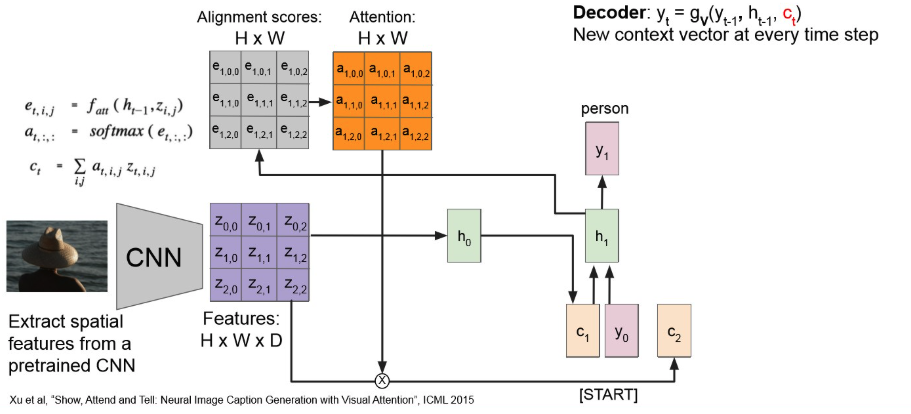
Attention : 모든 time step 마다 context vector를 생성.
→ 각 time-step 마다 context vector에 기여하는 img-region이 다르다!
- attention 수행하여 attention map 만들고,
- 이를 기존 Feature map이랑 element-wise mul 해준뒤,
- MLP 통과 시켜 context-vector 얻는다.
- 이를 RNN에 넣어서 seq generattion
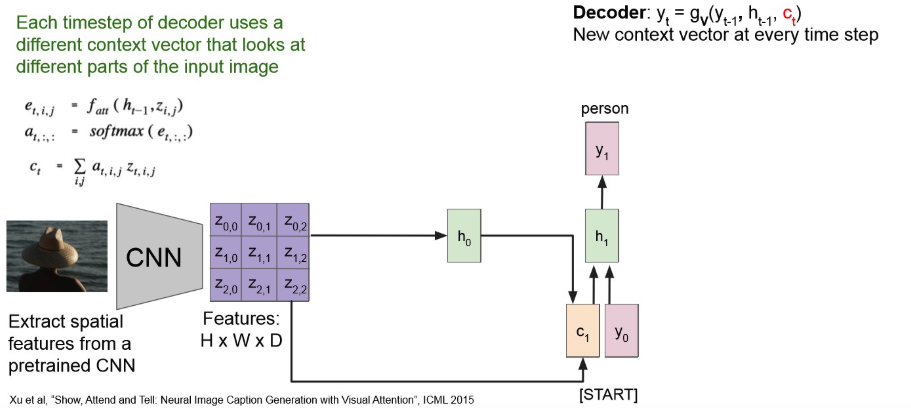
그러면 첫 output은 다음과 같이 나오고,
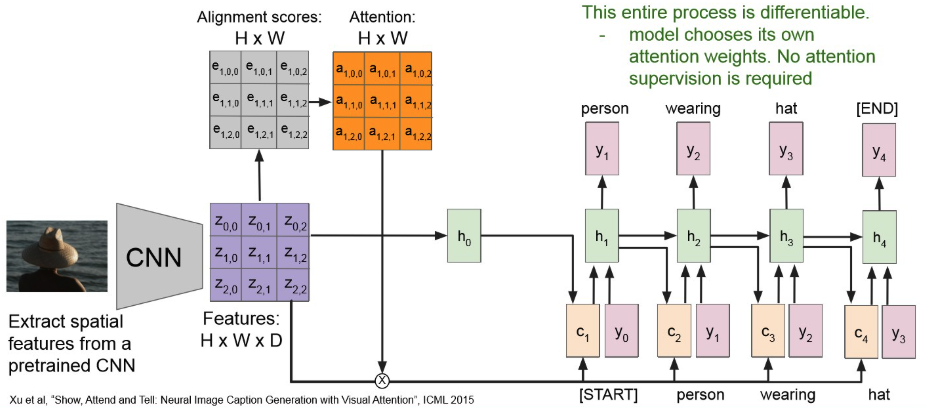
이를 반복해서 다음 context vector는 아래처럼 만들어진다.
계속 반복해보면,
Note
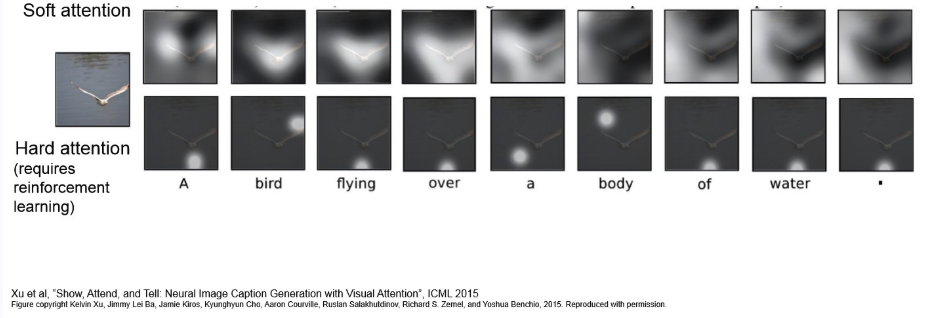
- Soft-Attention : input의 모든 부분에 대해 Weighted-Sum을 구하는 방식.
- 모든 input region에 대해 0~1 사이 확률 값(attention score)를 부여하고, 이를 합쳐 context vector를 생성.
- Differentiable하여 기존 Backpropagation을 통해 learnable.
- input이 클 경우, cost-expensive
- Hard-Attention: input 중 특정 영역을 sampling.
- 확률 분오에 따라 특정 region을 하나 선택. 선택되지 않은 곳은 0으로 치환.
- Non-differentiable.
- 일반적 Backpropagation을 사용할 수 없어서, 강화학습의 REINFORCE(? 공부하자.) 같은 걸 사용한다.
- inference 시, 연산 비용은 적을 수 있으나, 학습 과정이 까다롭고 variance가 클 수 있다고 한다.