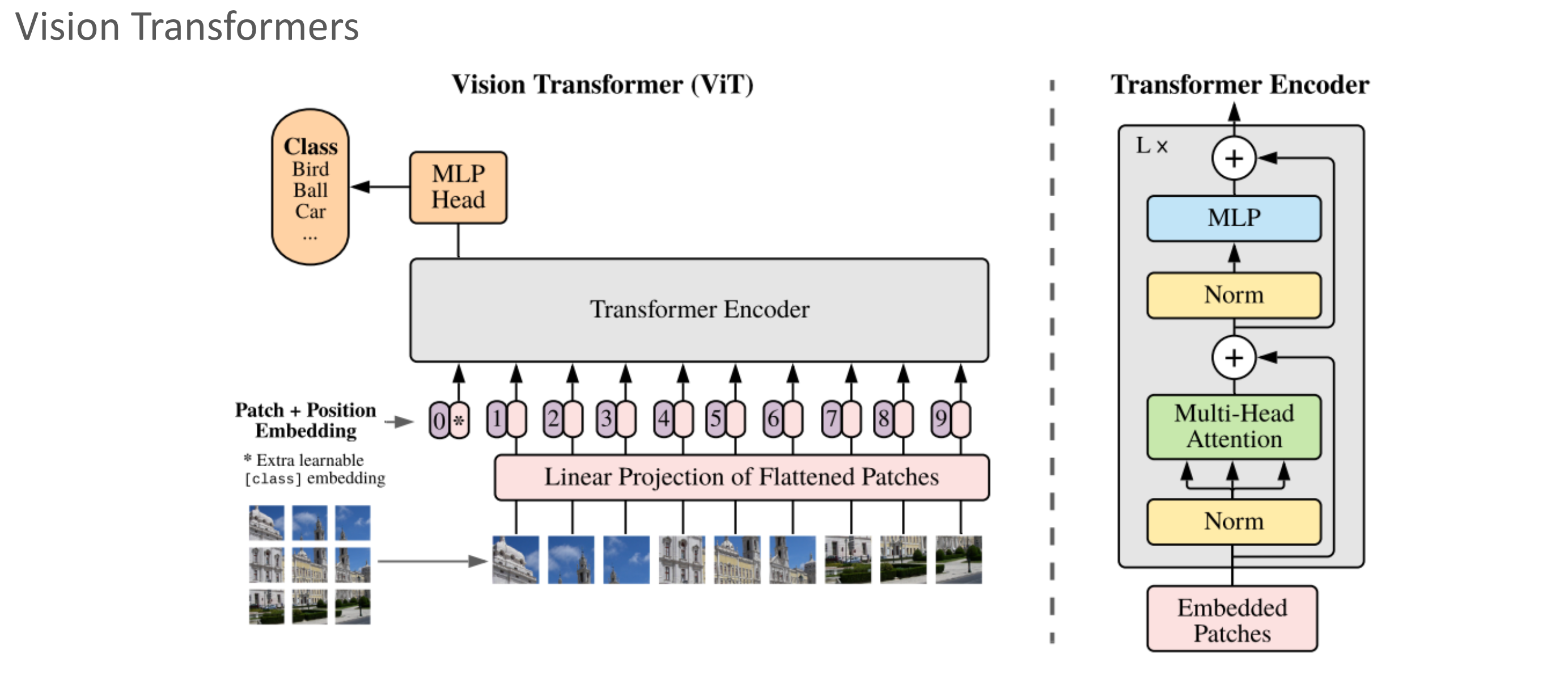
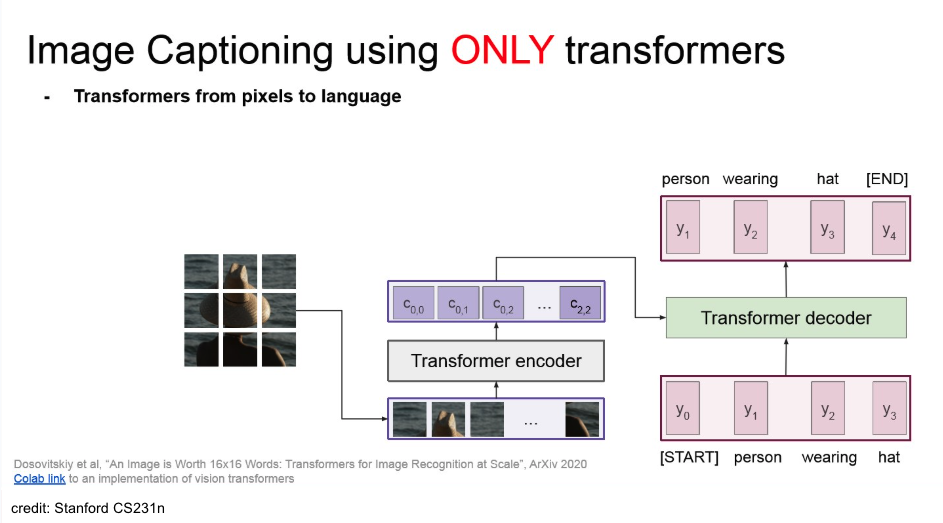
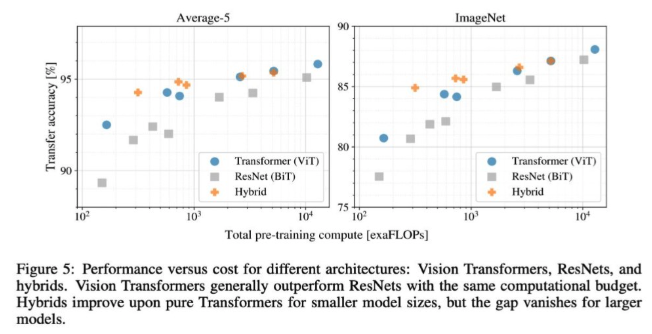
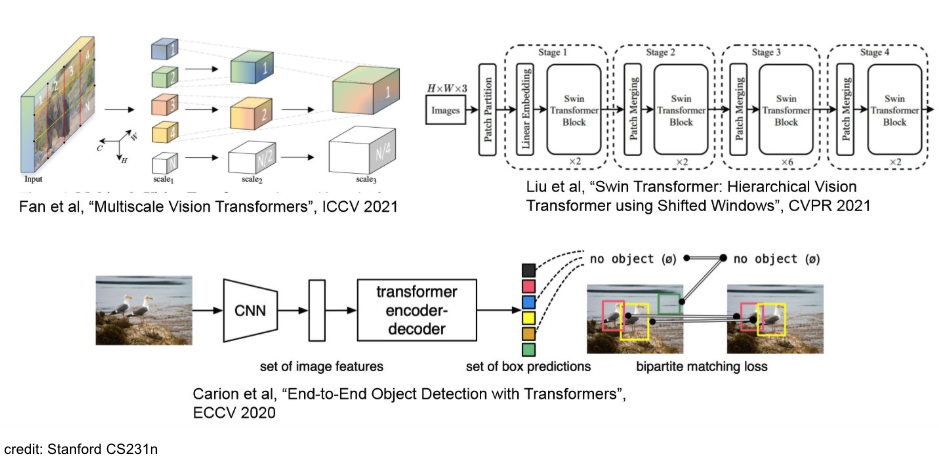
Summary transformer model의 attention을 사용해서 만든 vision model. img를 patch로 분할하고 바로 transformer에 넣음. Example in Image Captioning Example Tip 2020년 쯤부터 기존 NLP에서만 사용되던 transformer가 Vision 분야에서도 사용되기 시작함. 최근에는 CNN, ResNet 보다도 ViT를 훨씬 선호함. 정확도가 높으니까.