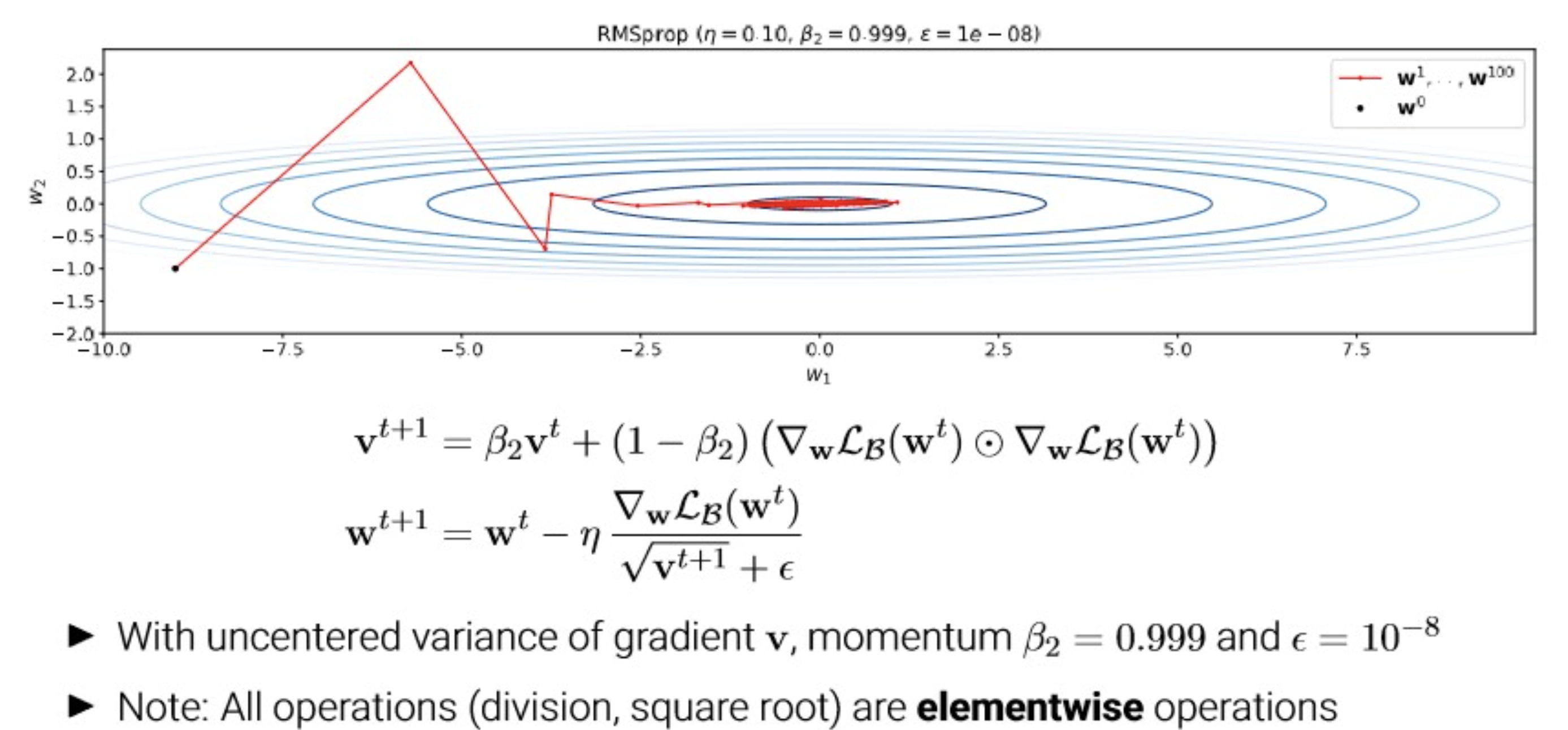
RMSProp?
“Leaky AdaGrad”.
AdaGrad의 lr 소실 문제를 EMA 적용하여 해결.(by Hinton)
Code
epsilon = 1e-7 grad_squared = 0 while True: dx = compute_gradient(x) grad_squared = decay_rate * grad_squared + (1 - decay_rate) * dx * dx # 여기가 AdaGrad랑 다름! x -= learning_rate * dx / (np.sqrt(grad_squared)+ epsilon)
Check
Motivation
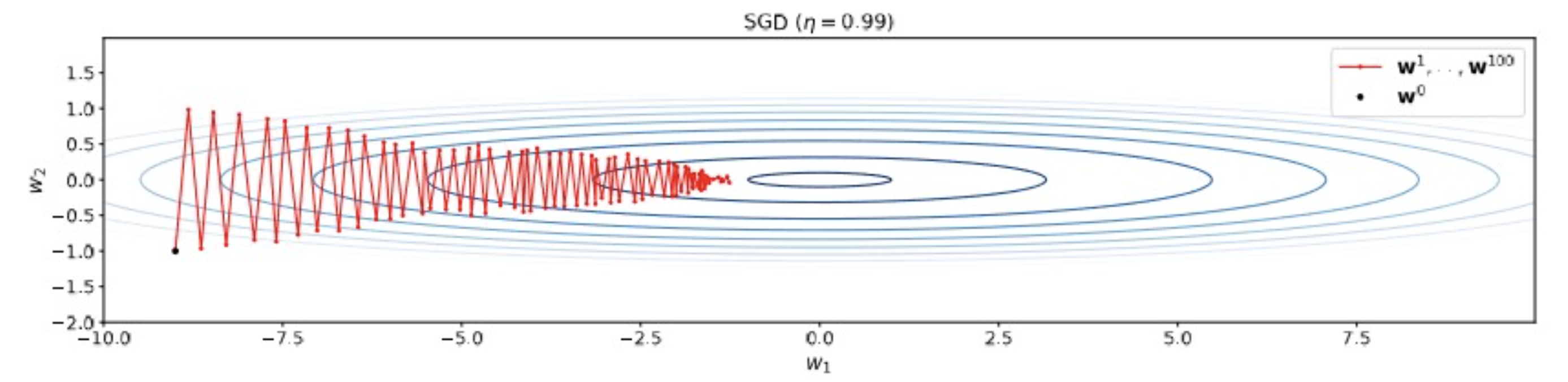
- gradient가 uneven하여, conservative한 lr이 필요.
- SGD 예시에서 봤던, 불균형한 dimension 별 gradient scale.
- Idea: “divide lr by moving average of squared gradients..”
RMSProp
- Division by running average of squared gradients adjusted per-weight step size
- → Division in direction will be large in direction will be small.
- This allows for increasing the lr compared to vanilla SGD
- However: In first iterations, moving average biased towards 0.