Initialize w0, pick the lr η and mini-batch size ∣χbatch∣
random mini-batch 잡기. χ⊇{(x1,y1),⋯,(xB,yB)} (with B<<N)
모든 mini-batch에 대해 b/in1,2,⋯,B 에 대해, do:
Forward-pass xb and, get the y^b
Backward-pass, to get gradient ∇wLb(y^b,yb,wt)
Update gradients: wt+1=wt−ηB1∑b∇wLb(wt)
Validation Error가 커지면, step2로 가져 again. otherwise stop.
Remark
일반적으로, gpu 자원량보다 전체 train-set이 크기 때문에 mini-batch 처리를 사용한다.(chunking)
일반적으로, batch-size는 gpu가 허용하는 한, 크게 잡는다. (Goyal et al., 2017)
작은 batch-size는 gradient의 variance를 키운다. (noisy update)
Batch들은 random shuffle하거나, partitioning한다.
Introduces stochasticity, batch gradients approximate the true gradient
SGD gradient → GD gradient (prove)
Convergence of SGD
Definition of the Convergence of Series
A series is the sum of therms of an infinite sequence of numbers (a1,a2,...): sn=∑k=1nak where n→∞
A series is convergent if there exists a number s∗ such that for every small positive number ϵ, there exists an integer N such that for all n≥N: ∣sn−s∗∣<ϵ
이걸 SGD update에 적용해보면,
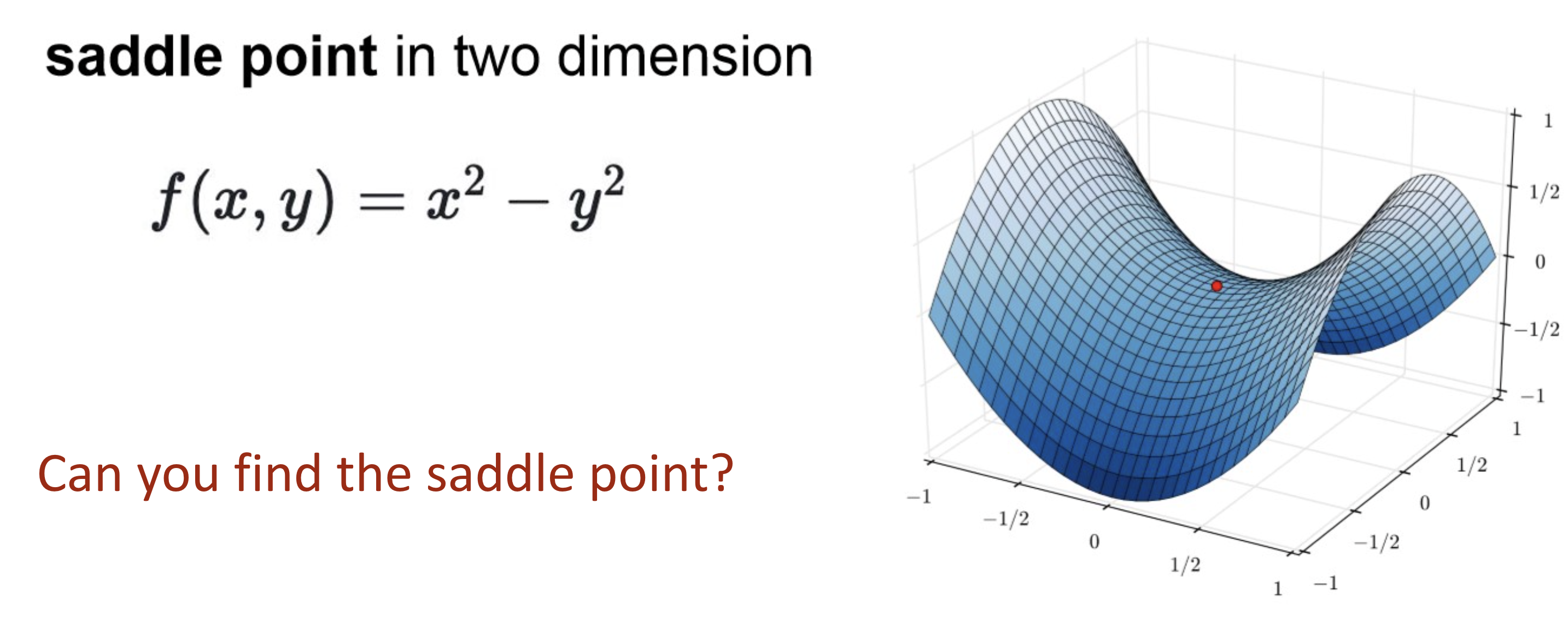
Problems with SGD
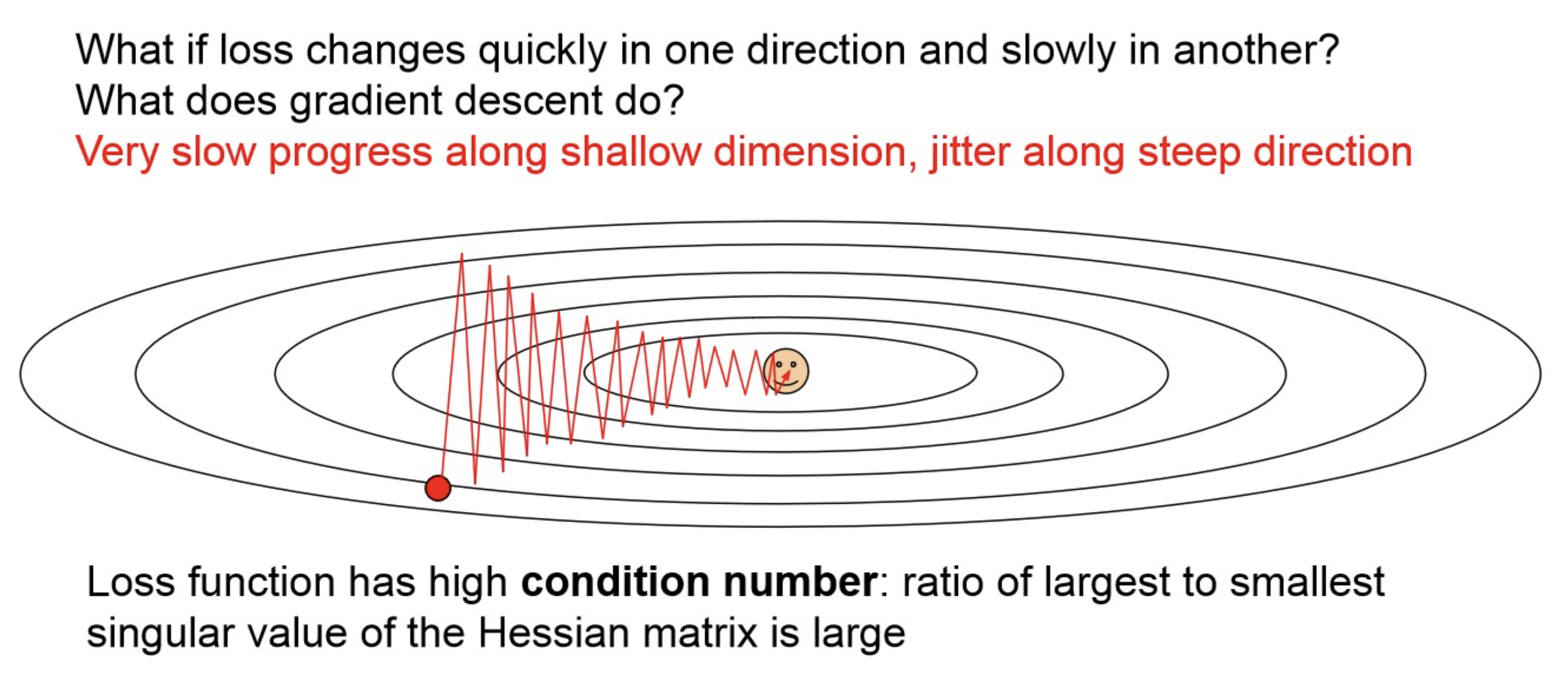
Gradient Jittering
그림과 같이 gradient가 한 dimension으로만 커서, iteration이 진행되면서, gradient가 큰 쪽은 진동, 작은 쪽은 느리게 진행. 즉, ideal한 방향으로 SGD가 진행되지 않는다. → Momentum 등으로 해결.
gradient를 계산하는데 모든 train-set이 한 번에 반영된 게 아니라, 한 번 gradient 계산 시에 batch 단위로 고려되다보니, “아주 운이 없게” batch에 좋지 못한 데이터들만 들어간다면, gradient가 완전 튀는 경우까지 발생할 수 있겠지.
Problems of SGD
Gradient scaled equally across all dimensions.
Requires conservative learning rate to avoid divergence
However, in this case the updates become very small → slow progress