Perceptron을 여러 층 쌓은 것.
중간 중간 non-linear function을 사용하여 perceptron을 엮어 더 complex한 function을 approximation 할 수 있음.
Terminology
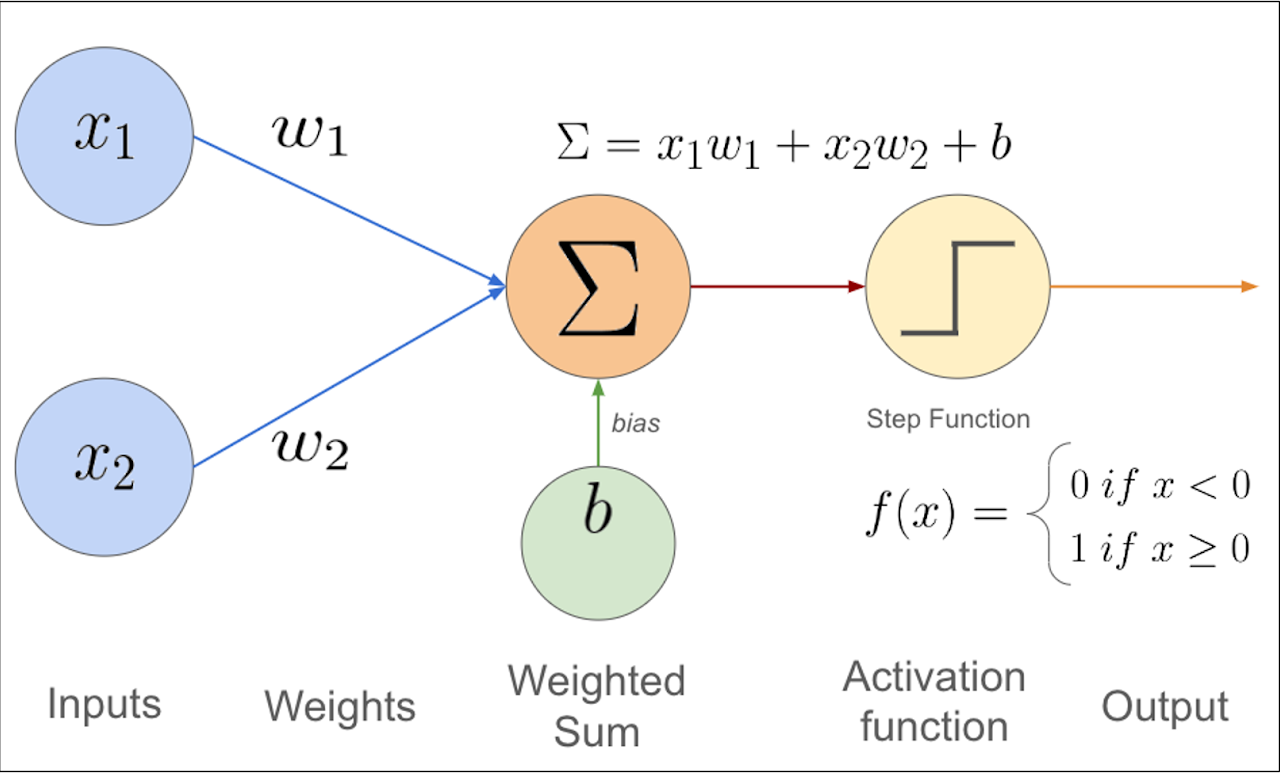
Net input(z) = weighted inputs, activation function에 들어갈 값
Activations(a) = activation function(Net input); a=σ(z)
Label output(y^) = threshold()activations of the last layer; y^=f(a)
Special Cases
In perceptron: activation function = threshold function(step function)
위의 그림에서는 threshold가 0으로 잡혀있음.
In linear regression: activation(a) = net input(z) = output(y^)
threshold → bias 항으로 몰기
0 & \text{if}\; z \leq \theta \\
1 & \text{if}\; z > \theta
\end{cases}
이를 정리해보면,
0 & \text{if}\; z - \theta \leq 0 \\
1 & \text{if}\; z - \theta > 0
\end{cases}
여기서 −θ 를 bias 취급하자.
이를 다시 말하면,
기존 σ(∑i=1mxiwi+b)=σ(xTw+b)=y^
input data에서 x[0]=1, w0=−θ 취급하면 notation이 아래와 같이 간단해진다. σ(∑i=0mxiwi)=σ(xTw)=y^
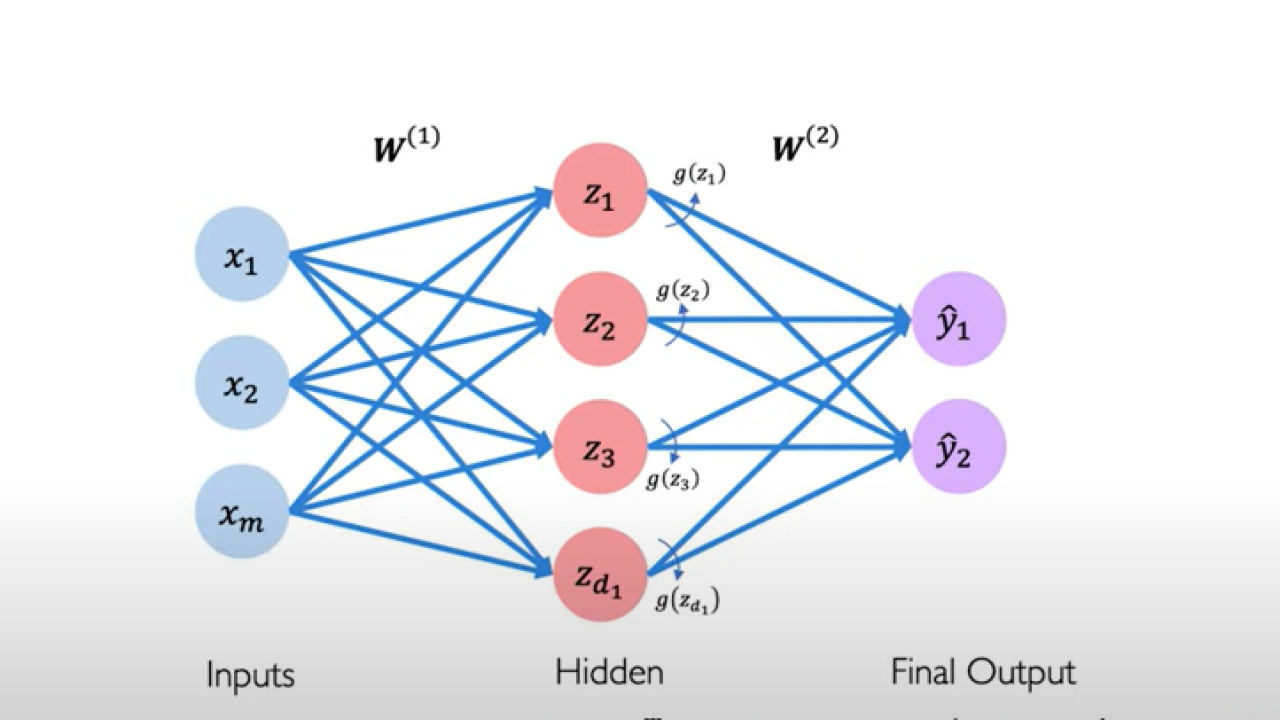
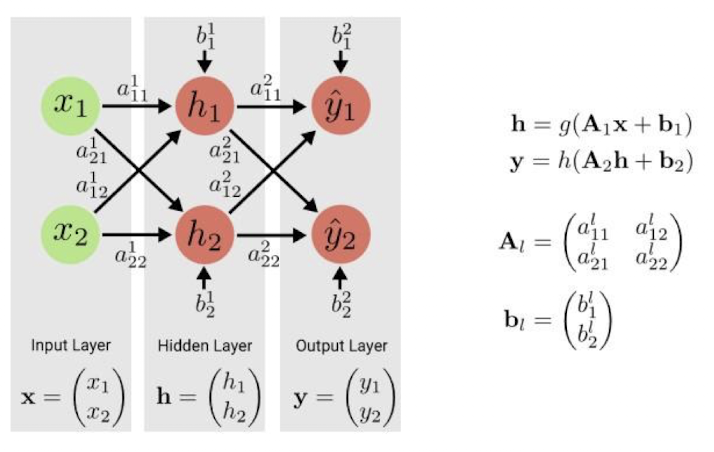
MLP - 1 layer
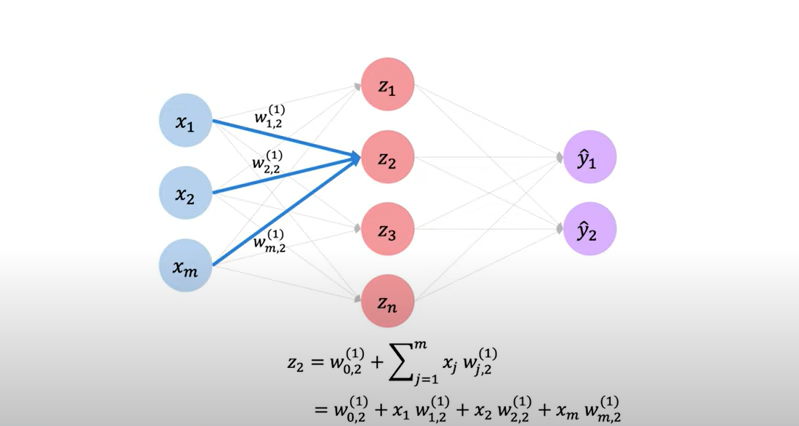
zi=W0,i(1)+∑j=1mxjWj,i(1) y^i=g(W0,i(2)+∑j=1d1zjWj,i(2))
where W0,i(1), W0,i(2) are bias
앞에 언급한 대로, W0,2(1) 는 bias이므로 input data의 dim을 1 늘리고(x[0]=1) 로 처리.
Why do we stack more layers?
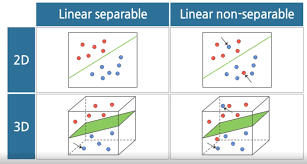
기본적으로 보이는 바와 같이 NN이 깊어질수록 activation을 많이 통과하고 그만큼 non-linearity를 더 부여할 수 있으니 더 complex한 function들을 근사할 수 있지.
또한, 데이터를 linearly separable 하게 바꿀 수도 있지.(e.g. kernel trick 처럼)
data를 Linearly-separable 한 space에 embedding 가능.
MLP - 2 layer
Learning MLP
이전에는 manual 하게 파라미터 값들을 define 해주었는데, 이조차도 모델이 스스로 조정하게 하는 걸 학습”Learning” 이라고 함.
parameter가 많아지면, manual 하게 지정해주는게 intractable
automatic하게 data로부터 학습하게 할 수 있다는 장점
→ 이러한 접근을 “data-driven approach” or “end-to-end learning” 이라고 함.
Learning Algorithm pseudo-code
Let D=(⟨x[1],y[1]⟩,⟨x[2],y[2]⟩,⋯⟨x[n],y[n]⟩)∈(Rm×{0,1})n