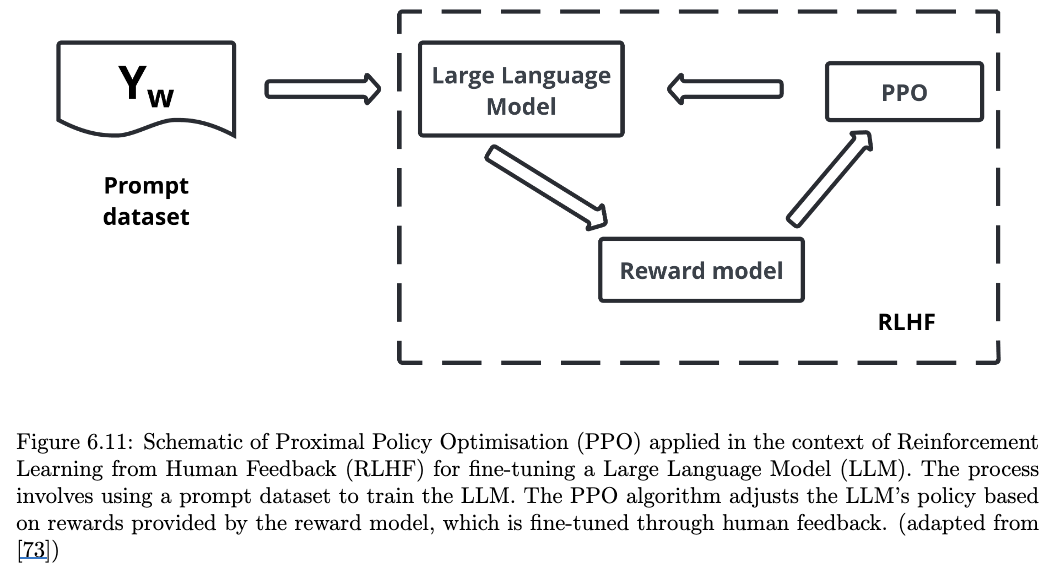
Summary
일반적으로 pre-train 이후, SFT를 한 다음 human preference alignment를 위한 기법.
다음과 같이 표현할 수 있다.
pre-requisite:
- pre-train과 SFT를 마친 backbone(reference model)
일반적으로 RL을 direct하게 하지 않고, SFT를 거친다고 한다. direct하게 하면 생각보다 불안정하고 잘 안된다고 함.
- reward model 준비
- reward model : 하나의 query에 대한 multiple answer 중 human-preference를 잘 반영한 answer를 높게 평가하는 모델
- 일반적으로 SFT까지 마친 backbone에 한 번 더 SFT하여 사용.
- transformer-arch를 따르면 decoding을 위해서 마지막 output이 classification layer니까, 그걸 떼고, regression layer로 변경하여 SFT
-하나의 query에 대한 2가지 answer 중 preference를 평가해주는 모델들의 loss는 다음과 같이 정의해서 사용한다.
- : 좋은 답변에 대해 모델이 매긴 점수
- : 나쁜 답변에 대해 모델이 매긴 점수
- : sigmoid
- 좋고 나쁜 상대적 우위쌍을 만드는 과정을 사람이 진행.
- Critic Model 준비:
- critic model : actor model이 token을 생성하면, 그 state에서의 value(expected reward)를 계산하는 모델.
- backbone은 마찬가지로 SFT까지 한 모델을 가져온다.
- reward model과 마찬가지로, classification layer를 regression layer로 교체.
- MSE Loss :
- Q. critic model의 loss가 위와 같이 정의가 된다면, ground-truth가 RM에 의존한다는 건데, RM이 제공할 수 있는 값은 완결된 문장에 대해서만이지 않나? 그렇다면 문장 중간 위체에서 Return에 해당하는 값은 어떻게 정의해두었나?
- RM 점수가 문장 중간에는 정의되어 있지 않으므로 으로 설정하고 사용. 학습이 진행되면서 backprop으로 학습되길 바라는 구간.
이후 task: Proximal Policy Optimization(PPO) 를 사용해서 SFT 마친 모델이 human-preference를 학습할 수 있도록 함.
- 언어 모델로써의 능력은 잃지 않기 위해 Loss에 SFT까지만 한 모델의 parameter와 KL-divergence도 손실에 추가함.
- 사전에 준비한 두 모델(RM, reference model(SFT))는 freeze
- policy-model (Actor): reference model과 copy한 모델로 학습시킬 대상.
- critic model(Critic): PPO 동안 Actor랑 같이 학습되는 모델로, actor가 token을 뽑아낼 때마다 최종 score(RL의 Value)의 expectation을 뎨측하도록 학습.
- Why Critic Model:
- LLM의 응답 품질을 평가하는 건, 문장이 완결되어야 할 수 있는데, 때문에 token 하나로 문장에 대한 평가가 확 바뀔 수 있고, 어느 시점의 token이 거기에 큰 contribution을 하는지 알 필요가 있음. 따라서 critic model이 필요.
- critic model이 계산하는 것이 Advantage()