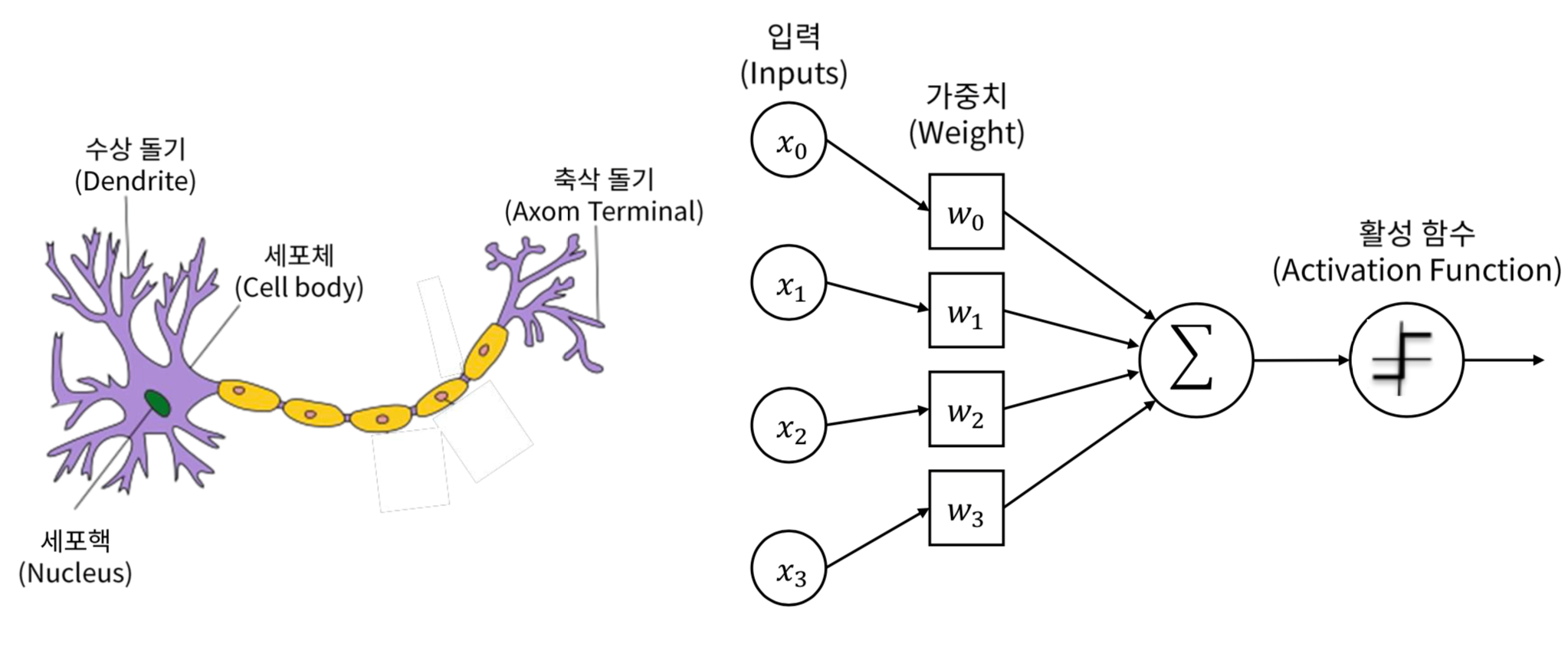
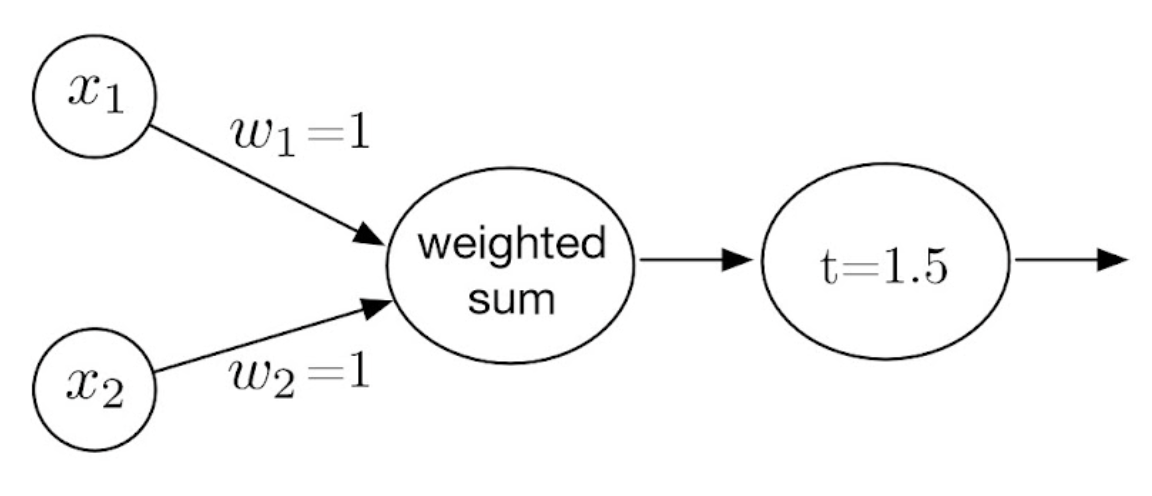
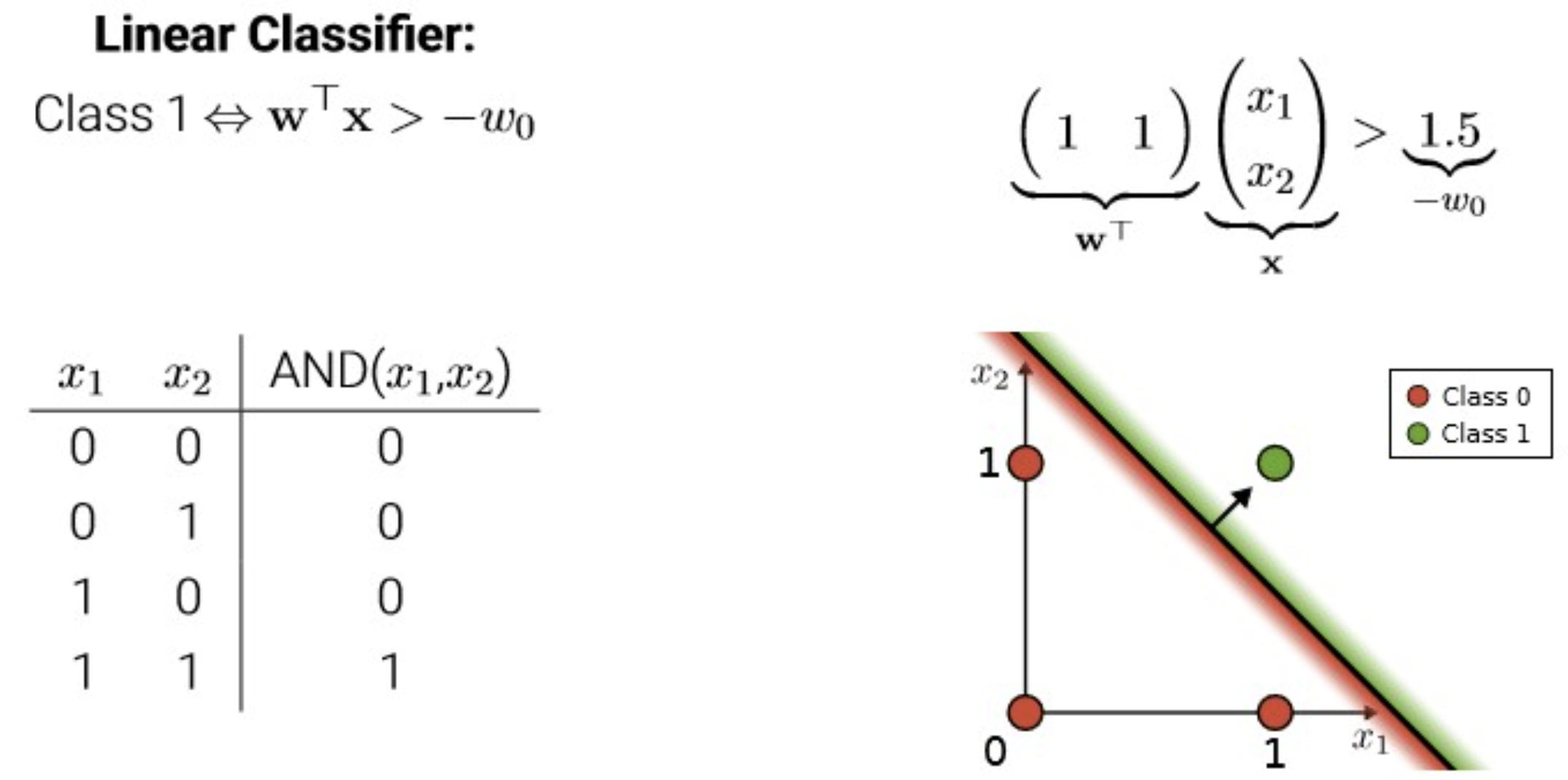
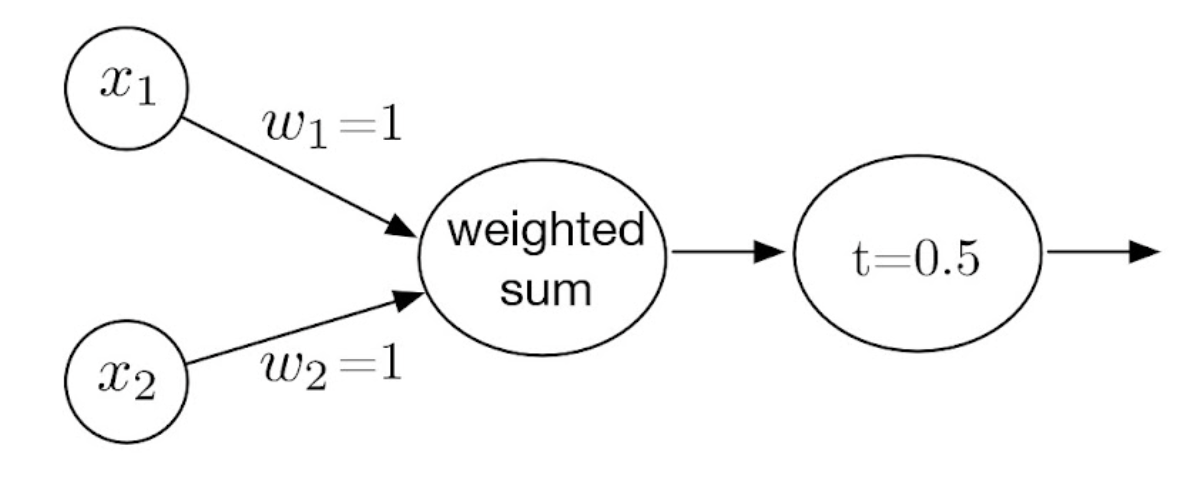
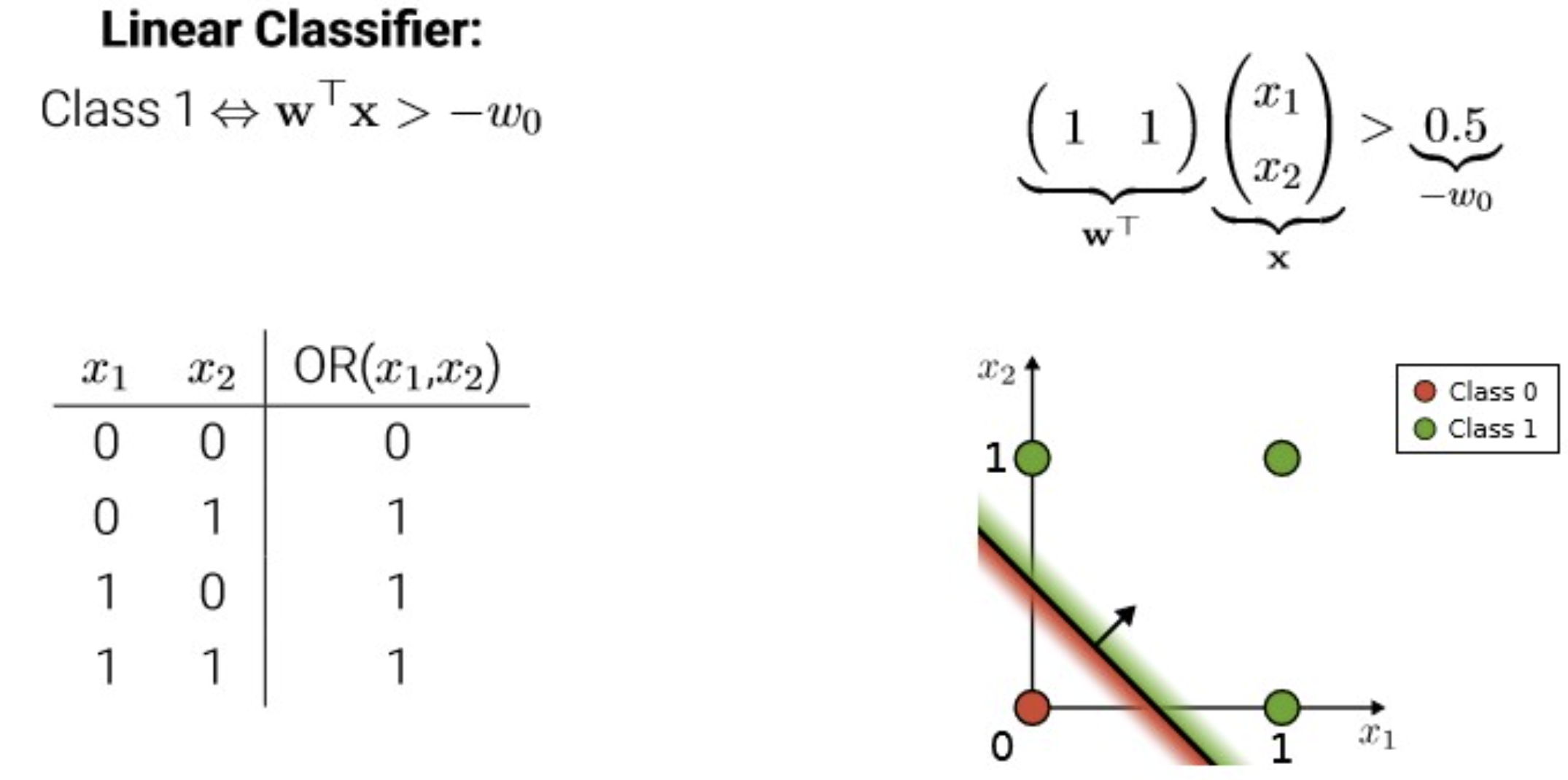
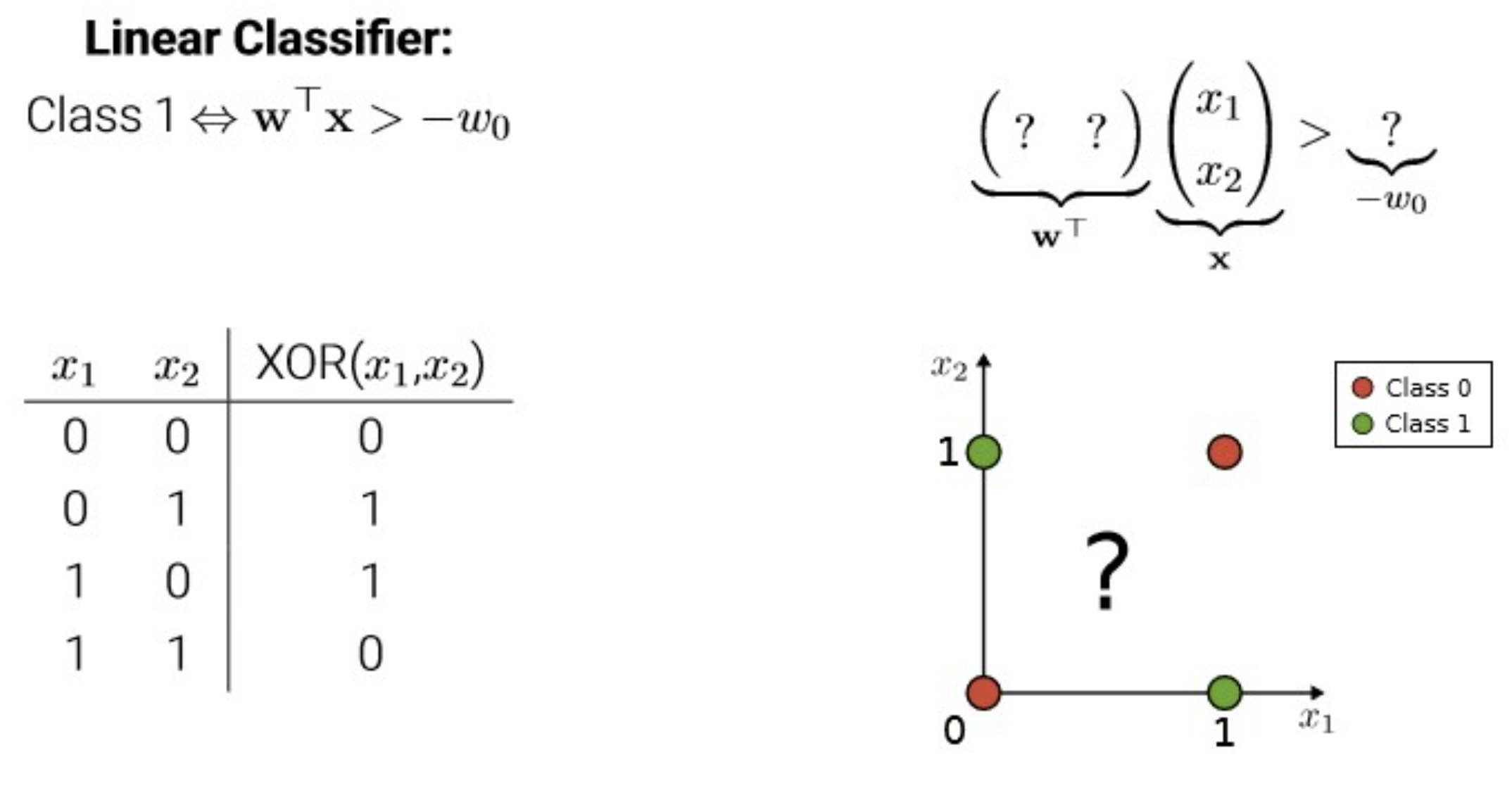
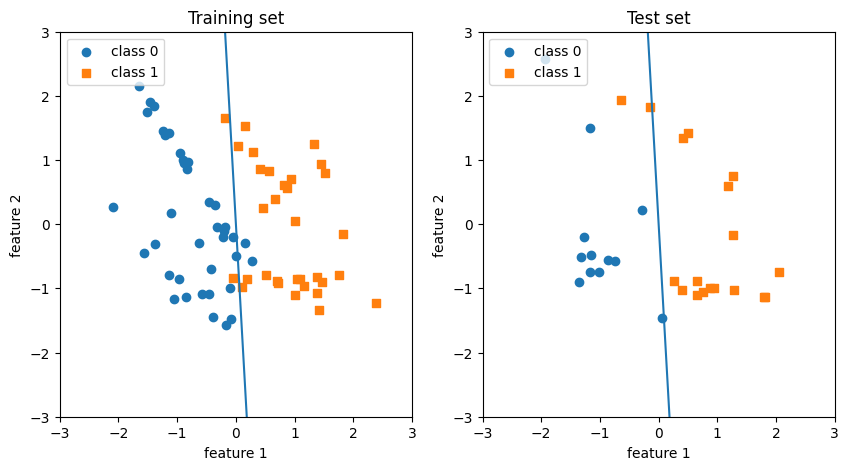
perceptron을 사용하려고 설정하는 것은 여기서 model을 building 하는 단계.
ML as a function approximation
Modeling the relation between input and output using computational components.
How?
→ parameterize the function and learn them from data.
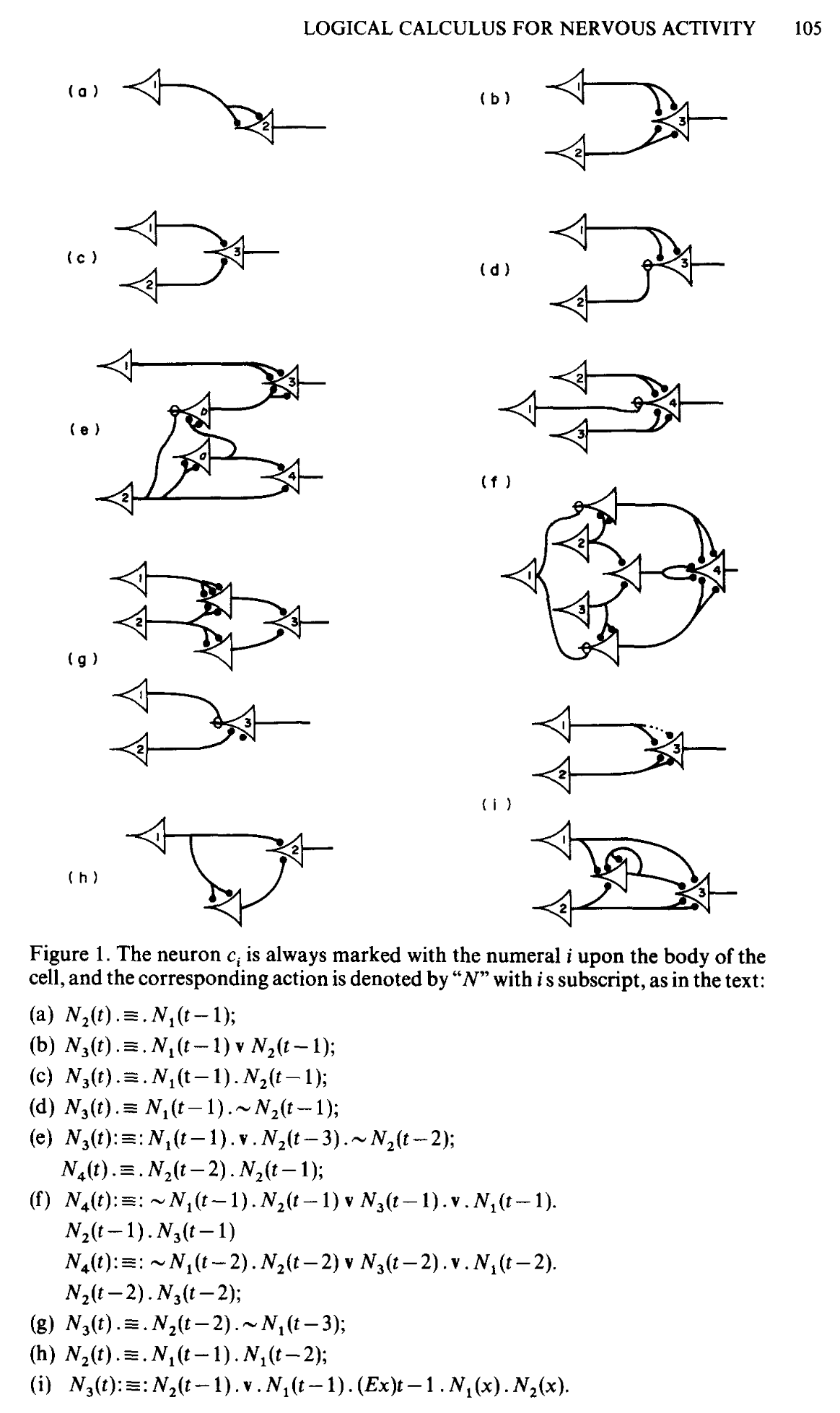
Neuron Model - A logical calculus of the ideas immanet in nervous activity
Abstract
Abstract
Because of the “all-or-none” character of nervous activity, neural events and the relations among them can be treated by means of propositional logic. It is found that the behavior of every net can be described in these terms, with the addition of more complicated logical means for nets containing circles; and that for any logical expression satisfying certain conditions, one can find a net behaving in the fashion it describes. It is shown that many particular choices among possible neurophysiological assumptions are equivalent, in the sense that for every net behaving under one assumption, there exists another net which behaves under the other and gives the same results, although perhaps not in the same time. Various applications of the calculus are discussed.
뉴런의 실무율(0 or 1) 특성을 논리 회로로 볼 수 있지 않을까? 에서 출발하여 이를 구조화 함.
다른 학문들(심리, 신경과학, 뇌 등)에서 다뤄지는 촉진, 억제 등의 활동이 근본적으로 equivalent 하다는 것을 주장.
이름 그대로 위의 perceptron을 multi-layer 쌓아서 적층한 구조. 각 layer에서 다음 layer로 넘어가는 과정에서 non-linear function을 통과하니, 이때 점차 model에 non-linearity가 생김. 따라서 이러한 구조가 3층이상으로 깊게 쌓이면 Deep-Neural-Network이라 함.
SIMD(Single Instruction Multiple Data)
—
여러 개의 data를 vector 형식으로 묶어서 처리하자!
**
파이썬으로 구현해보기!
Perceptron
class Perceptron(): def __init__(self, num_features): self.num_features = num_features self.weights = np.zeros((num_features, 1), dtype=float) self.bias = np.zeros(1, dtype=float) def forward(self, x): # $\hat{y} = xw + b$ linear = np.dot(x, self.weights) + self.bias # comp. net input # train에서 보면, y[i] 차원으로 데이터가 들어오니, vec * vec 연산. # linear = x @ self.weights + self.bias predictions = np.where(linear > 0., 1, 0) # step function - threshold return predictions # 'ppp' exercise def backward(self, x, y): # pred랑 ground_truth 값 비교. return y - self.forward(x) # 중간 중간 reshape이 과연 필요할까? def train(self, x, y, epochs): for e in range(epochs): for i in range(y.shape[0]): errors = self.backward(x[i].reshape(1, self.num_features), y[i]).reshape(-1) self.weights += (errors * x[i]).reshape(self.num_features, 1) self.bias += errors def evaluate(self, x, y): predictions = self.forward(x).reshape(-1) accuracy = np.sum(predictions == y) / y.shape[0] return accuracy
A set is convex if any line segment connecting 2 points in lies entirely within .