Sigmoid
- activation 중 하나로 대표적으로 많이 사용됨.
- range:
- Neuroscience interpretation as saturating “firing rate” of neurons
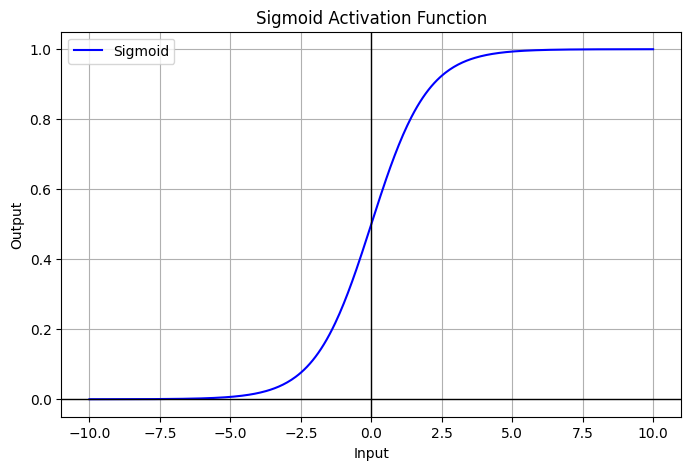
Problems
- Saturation “kills” gradient : 입력 값의 절댓값이 커질수록 기울기 소실
- 특히나 layer가 깊어질수록, chain-rule에 의해 곱해지는 term들이 많아질텐데, 그러면 앞 쪽에 있는 layer 들일수록 learning되지 않을 수 있지.
- Outputs are not zero-centered → introduces bias after the layer
- sigmoid와 그 gradient는 항상 positive이기 때문에 model wight의 bias
- 라 할 때, =
- 모든 gradient는 동일한 부호를 가짐.
다음과 같이 구현.
Sigmoid
def sigmoid(x: float) -> float: return 1 / (1 + np.exp(-x))